
An Integrated Methodology for Enhancing Reverse Logistics Flows and Networks in Industry 5.0


Abstract
:1. Introduction
2. Key Literature
3. Research Context and Framework
- Can a combination of binary logistic regression and decision trees provide a more robust and efficient framework for predicting and optimizing reverse logistics flows? This question seeks to examine the effectiveness of integrating these two methodologies to handle the intricacies of reverse logistics data.
- What are the practical implications of the proposed integrated methodology in real-world industrial settings? This includes evaluating the methodology’s adaptability, scalability, and effectiveness in different industrial sectors.
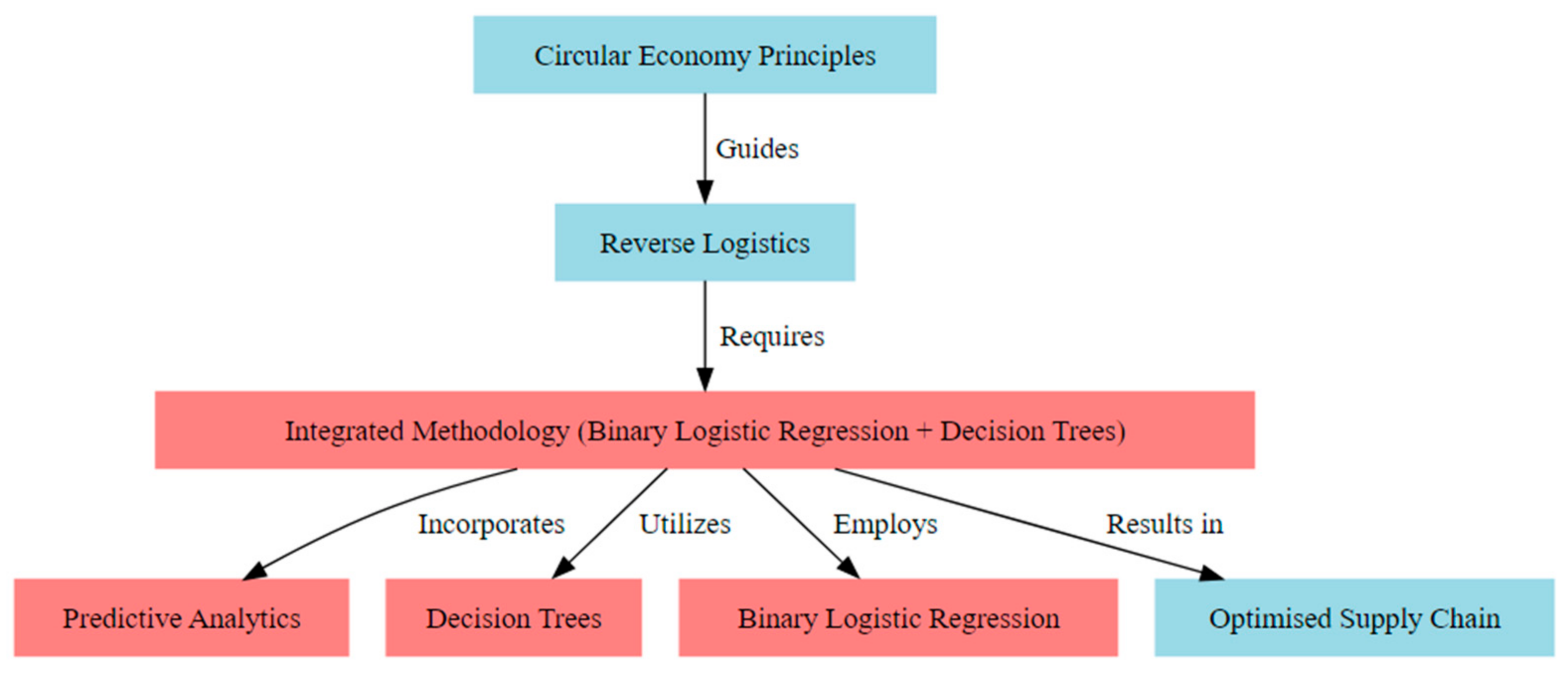
- Circular Economy Principles (CE): These are the guiding principles that emphasize the importance of resource efficiency, waste reduction, and sustainability in industrial operations. They guide the reverse logistics processes.
- Reverse Logistics (RL): Central to achieving a circular economy, it addresses product returns, remanufacturing, recycling, and waste reduction. It requires an integrated methodology for optimization.
- Integrated Methodology (IM): This is the core of the research, combining binary logistic regression and decision trees to predict and optimize reverse logistics flows and networks. It incorporates predictive analytics, utilizes decision trees, and employs binary logistic regression.
- Predictive Analytics (PA): Leveraging data analytics to forecast returns, optimize inventory management, and reduce waste.
- Decision Trees (DT): Used to capture complex patterns and interactions among predictors, providing a comprehensive understanding of decision-making processes.
- Binary Logistic Regression (BLR): Widely used to predict binary outcomes based on categorical or binary predictors, offering insights into the relationship between predictors and optimization outcomes.
- Optimized Supply Chain (OS): The result of applying the integrated methodology, leading to enhanced operational efficiency and sustainability in the circular economy landscape.
- Probabilistic Decision Making: The logistic regression component of the methodology provides probabilistic predictions based on the input data. This aspect enhances the decision-making process by quantifying the likelihood of different outcomes, thereby aiding organizations in making informed choices about their reverse logistics strategies.
- Improvement over Extremization: The goal of employing logistic regression in this context is to improve the predictability and reliability of the reverse logistics process. It is about enhancing the accuracy of predicting the optimal pathways for returned products (recycle, refurbish, dispose), rather than seeking to extremize any variable or outcome.
- Comprehensive Approach to Optimization: The integrated methodology aims at a holistic improvement of reverse logistics processes. This encompasses not just predictive accuracy but also encompasses aspects like resource allocation efficiency, waste reduction, and alignment with sustainability goals, which are crucial in the context of a circular economy.
- Practical Application: The focus of the methodology is on practical application in the real world. The term “optimization” is therefore used in a more applied and pragmatic sense, referring to the enhancement of operational processes in reverse logistics, rather than a strict mathematical optimization process.
- Adaptability and Evolution: The methodology is designed to be adaptable and evolve over time. As new data become available or as the dynamics of the reverse logistics process change, the models can be updated and refined, leading to continuous improvement or “optimization” in their application.
4. Methodology
- Decision Trees for Feature Transformation
- b.
- Logistic Regression on Transformed Features
- P(y = 1∣Z) is the probability of the target variable y being 1 given the features Z. β0, β1, …, βm are the parameters of the logistic regression model.
- c.
- Final Model
4.1. Application Scenarios
4.1.1. Technological Influence
- IoT Integration: The Internet of Things (IoT) offers the real-time tracking and monitoring of products throughout their lifecycle. By embedding sensors and smart tags, companies can gain insights into when a product is nearing its end-of-life or when it is malfunctioning. This proactive approach can streamline the return process, ensuring timely refurbishment or recycling.
- a is the intercept;
- b1 is the coefficient for the IoT data;
- e is the base of natural logarithms.
- AI Utilization: Artificial Intelligence (AI) can predict return patterns by analyzing historical data. Machine learning models can forecast which products are more likely to be returned based on factors like purchase history, customer feedback, and product type.
- Blockchain Adoption: Blockchain can enhance transparency and traceability in reverse logistics. By maintaining a decentralized ledger of all transactions, stakeholders can verify and audit product returns without intermediaries, ensuring authenticity and reducing fraudulent returns.
4.1.2. Joint Influences
- Supply Chain Configuration (SCC): The design and structure of a supply chain can impact reverse logistics [62]. For instance, a centralized supply chain might have a single return center, which can be efficient for bulk processing but might be slower due to transportation times. On the other hand, a decentralized supply chain might have multiple return centers, offering quicker processing but potentially higher management complexity.
- Organizational Characteristics (OC): The culture, policies, and strategies of an organization can influence its approach to reverse logistics. A proactive organization might invest in advanced return management systems, offer easy return policies to customers, and prioritize sustainability by promoting recycling and refurbishment.
4.2. Application Case Examples
- Data Collection
- Product Type: Smartphone, Laptop, Tablet;
- Return Reason: Defect, End-of-Life, Upgrade;
- Product Age: In months;
- Physical Condition: Graded from 1 (Poor) to 5 (Excellent);
- Functional Condition: Working, Not Working;
- Outcome: Recycled, Refurbished, Disposed.
- Decision Trees for Feature Transformation
- Most end-of-life smartphones that are not working are recycled.
- Laptops returned due to defects and are in excellent physical condition are often refurbished.
- Logistic Regression on Transformed Features
- The decision tree assigns this instance to a particular leaf node, say z5;
- Using the logistic regression model, the probability of this smartphone being recyclable is calculated. If P(Recycled∣Z = 1) is high, the manufacturer will opt to recycle the smartphone.
5. Application
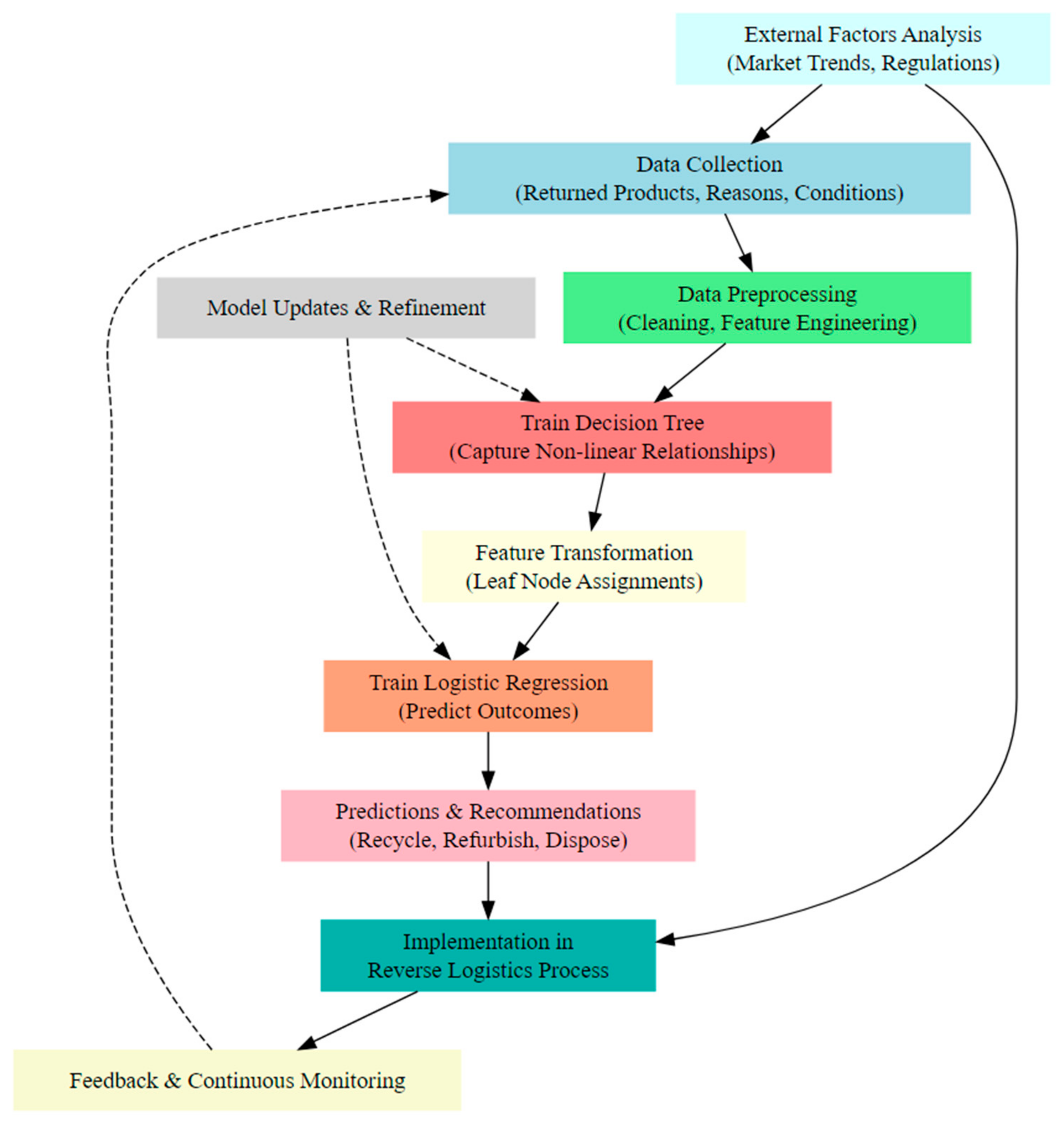
- Data Collection → Data Pre-processing: After gathering the necessary data, the next step is to pre-process it. This relationship indicates that raw data need to be cleaned and transformed before they can be used for modeling.
- Data Pre-processing → Train Decision Tree: Once the data are pre-processed, they are used to train a decision tree. This relationship emphasizes the importance of clean data for effective modeling.
- Train Decision Tree → Feature Transformation: The decision tree’s structure and leaf node assignments are used to transform the original features. This relationship highlights the integration of decision tree outcomes into the next modeling step.
- Feature Transformation → Train Logistic Regression: The transformed features serve as inputs for the logistic regression model. This relationship shows the sequential nature of the integrated methodology.
- Train Logistic Regression → Predictions and Recommendations: After training, the logistic regression model is used to make predictions and provide recommendations. This relationship underscores the model’s practical application.
- Predictions and Recommendations → Implementation in Reverse Logistics Process: The model’s recommendations are then implemented in the reverse logistics process. This relationship emphasizes the action-oriented nature of the model’s outcomes.
- Implementation in Reverse Logistics Process → Feedback and Continuous Monitoring: After implementing the recommendations, the outcomes are continuously monitored, and feedback is gathered. This relationship indicates the importance of tracking the effectiveness of the implemented decisions.
- Feedback and Continuous Monitoring → Data Collection (Dashed Arrow): Feedback from the monitoring process can lead to new data collection, refining the initial data set and improving model accuracy. This relationship represents the iterative nature of the process.
- External Factors Analysis → Data Collection and Implementation in Reverse Logistics Process: External factors can influence both the data collection process and the implementation of decisions. These relationships highlight the importance of considering external market trends, regulations, and other factors.
- Model Updates and Refinement (Dashed Arrows to Train Decision Tree and Train Logistic Regression): The model is regularly updated and refined based on new data and feedback. These relationships emphasize the iterative nature of model training and the importance of continuous improvement.
6. Case Study
- Step 1—Feature Transformation Using Decision Trees: The decision tree algorithm is applied to the dataset to identify patterns and relationships within the features. Decision trees work by making sequential, hierarchical decisions about the data, effectively splitting it into branches and leaves based on feature values.
- Leaf Node Assignments: Each data point (customer in this case) ends up in a leaf node, and these assignments become new features. Essentially, the path a data point takes through the tree (which leaf it ends up in) becomes a concise summary of its characteristics.
- Purpose of step: This step simplifies complex relationships in the data, making it easier to identify unique groups or patterns that are significant for predicting returns or cancellations in banking products and services.
- Step 2—Binary Logistic Regression on Transformed Features: The new features created from the decision tree (leaf node assignments) are used as input for a logistic regression model.
- Predictive Modeling: The logistic regression model calculates the probability using the logistic function. This process assigns each instance in the dataset to a particular leaf node, which is then used as a new binary feature in the logistic regression model. The logistic regression model is then applied to these transformed features. The model learns the coefficients during the training process, which are used to calculate the probability of each class. For a given instance with features, the probability of it being in class “1” (i.e., return/cancellation) is calculated using the logistic function.
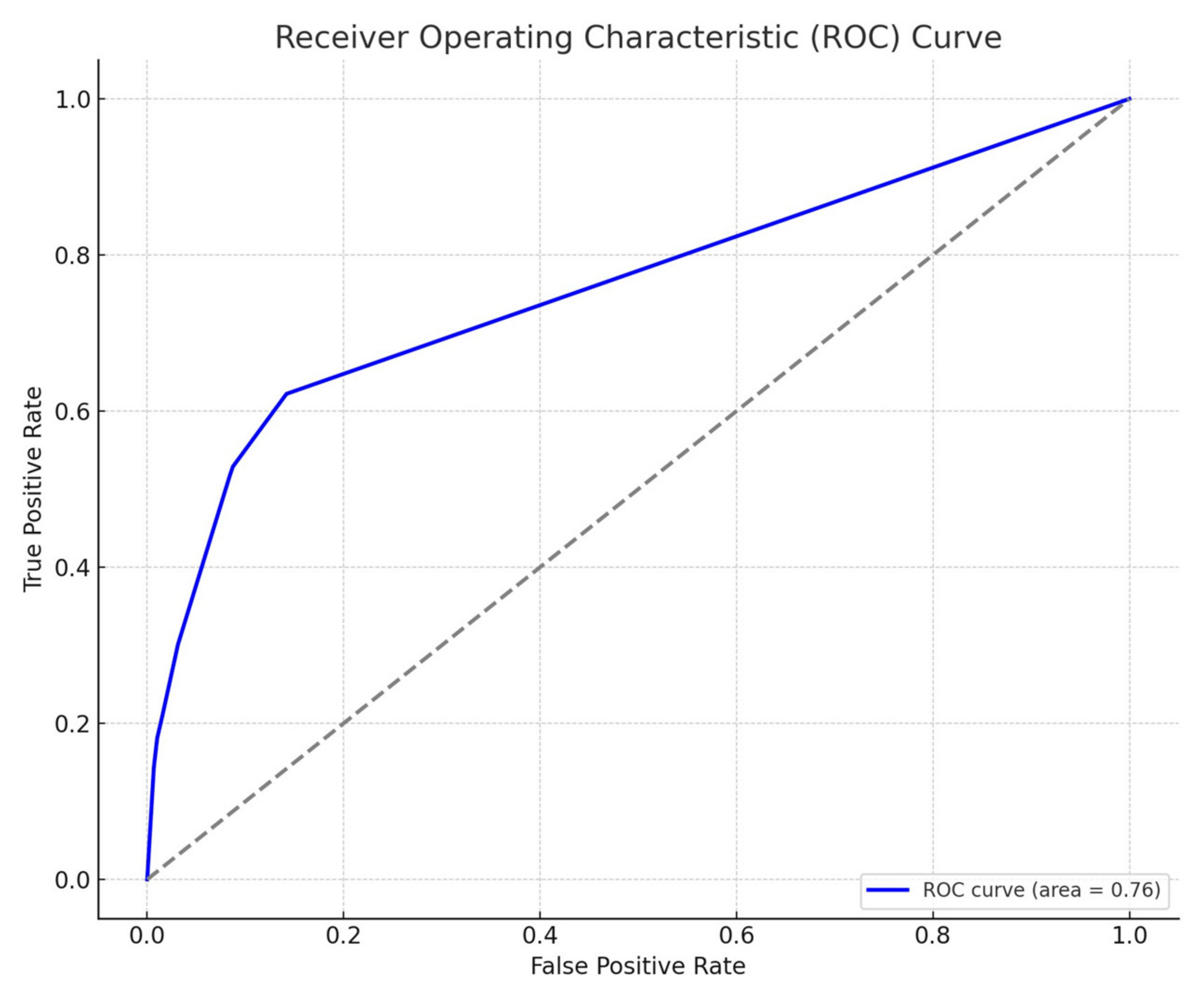
- Model Evaluation: The Receiver Operating Characteristic (ROC) curve is a graphical plot that illustrates the diagnostic ability of a binary classifier system as its discrimination threshold is varied. It plots the true positive rate (TPR) against the false positive rate (FPR), providing insight into the trade-off between benefit (true positives) and cost (false positives).
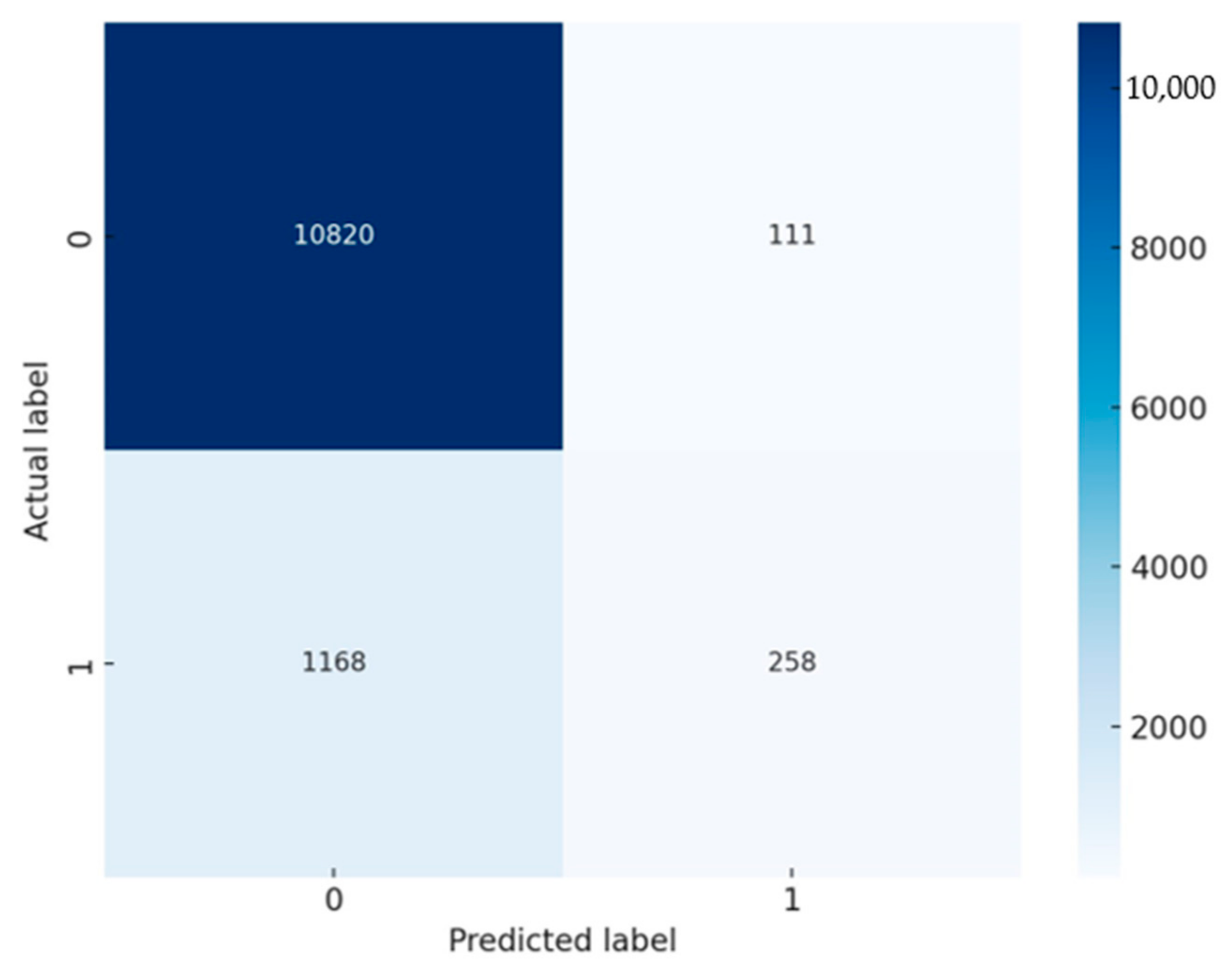
- Confusion Matrices: A confusion matrix is a table used to describe the performance of a classification model on a set of test data for which the true values are known. It allows the visualization of the performance of an algorithm, showing the actual vs. predicted classifications.
- Step 3—Interpretation for Reverse Logistics Optimization: By examining the ROC curve and confusion matrix, we can understand how well the model distinguishes between customers likely to return or cancel a product and those who are not. These insights can identify patterns or characteristics common among customers who return or cancel products.
- Application: The bank can use these insights to proactively address issues leading to returns or cancellations, tailor their services to reduce such instances, and improve overall customer satisfaction and retention. It can also aid in the efficient allocation of resources for managing returns and cancellations, reducing operational costs, and improving profitability.
- Continuous Improvement: The results from the model can be used to refine strategies continuously. For instance, understanding which features or customer segments are more prone to returns can guide more targeted customer engagement strategies or product improvements.
- Results of applying the integrated methodology:
- ▪
- Model Discrimination: With an AUC of 0.76, the logistic regression model is considered to have a good ability to discriminate between customers who will return/cancel a product and those who will not. This level of performance is quite satisfactory for many practical applications.
- ▪
- Threshold Selection: The bank can use the ROC curve to select an appropriate threshold that balances the TPR and FPR according to their operational objectives. For example, if the bank wants to minimize the risk of missing returns/cancellations, they may choose a threshold that maximizes the TPR, even if it increases the FPR.
- ▪
- Risk Management: The ROC curve does not show the costs of false positives or false negatives, which are critical in the banking context. The bank must consider the cost–benefit trade-off of different thresholds to implement a cost-effective strategy.
- ▪
- True negatives (TNs, top-left, 10,820): The model correctly predicted “no return/cancellation” for 10,820 customers. This indicates that for a large majority, the logistic regression model successfully identified customers who continued with their banking product without cancellation.
- ▪
- False positives (FPs, top-right, 111): In 111 cases, the model incorrectly predicted that customers would cancel or return the product, but they did not. These are Type I errors that could lead to unnecessary follow-up actions by the bank, potentially wasting resources.
- ▪
- False negatives (FNs, bottom-left, 1168): The model failed to identify 1168 customers who actually did return or cancel their product. These Type II errors are particularly significant because they represent missed opportunities for the bank to intervene and potentially retain the customer.
- ▪
- True positives (TPs, bottom-right, 258): The model correctly identified 258 customers who returned or canceled their product. While this shows the model’s ability to detect true return/cancellation cases, it may also indicate room for improvement given the number of false negatives.
- Step 4—Interpretation of Reverse Logistics Optimization
- Resource Allocation: Understanding the model’s performance helps in strategically allocating resources. For instance, customers identified as high risk (TPs) can be targeted with personalized communication, loyalty programs, or customized financial advice to prevent churn.
- Process Improvement: Patterns identified from TP and FN can shed light on specific product features or customer service aspects that may be leading to dissatisfaction. These insights are valuable for driving process improvements and product enhancements.
- Customer Relationship Management: Accurate TN predictions allow the bank to maintain regular engagement strategies without additional investment, while FPs, though not ideal, can be seen as opportunities to strengthen customer relationships.
- Risk Mitigation Strategies: The bank can develop specialized risk mitigation strategies for different customer segments based on the model’s findings, thereby enhancing the overall efficiency of its reverse logistics processes.
- Continuous Monitoring and Model Refinement: The insights gained from the model’s current performance should feed into a cycle of continuous improvement, where the model is regularly updated and refined with new data and customer feedback.
7. Implications and Future Directions
- Complexity of Reverse Logistics Data: Reverse logistics data often encompass a multitude of variables, including product type, return reason, product condition, etc. A single model might not capture the intricate relationships and interactions among these variables. The combination of decision trees for feature transformation and logistic regression for prediction offers a robust approach to handle this complexity.
- Nonlinear Relationships: Decision trees are adept at capturing nonlinear relationships and interactions between features. By transforming the original features into a format that highlights these relationships, the subsequent logistic regression model can make more accurate predictions.
- Interpretability: Decision trees provide a visual and intuitive representation of the decision-making process. This makes it easier for stakeholders to understand and trust the model’s recommendations. On the other hand, logistic regression offers a probabilistic perspective, allowing decision makers to quantify the likelihood of different outcomes.
- Flexibility: This integrated methodology is adaptable. As new data become available or as the dynamics of the reverse logistics process change, the models can be updated and refined to reflect these changes.
- Optimization of Resources: By accurately predicting the optimal pathway for returned products (recycle, refurbish, dispose), resources can be allocated more efficiently, leading to cost savings and reduced environmental impact.
- Ensemble Learning Benefits: Combining multiple models often results in better performance than relying on a single model. This ensemble approach can lead to improved predictive accuracy and generalization to new, unseen data.
- Alignment with Circular Economy Principles: The circular economy emphasizes resource optimization, waste reduction, and sustainability. By optimizing reverse logistics processes, this methodology directly supports these principles, ensuring that products and materials are reused, recycled, or refurbished to the maximum extent possible.
- Competitive Advantage: Implementing an advanced and integrated methodology can provide companies with a competitive edge. Efficient reverse logistics can lead to enhanced customer satisfaction, reduced costs, and a stronger brand image centered on sustainability.
- Scalability: As the volume of returned products grows, traditional decision-making processes might become overwhelmed. This methodology offers a scalable solution that can handle large datasets and provide timely recommendations.
- Risk Mitigation: By accurately predicting the best course of action for returned products, companies can mitigate risks associated with inventory build-up, environmental penalties, and customer dissatisfaction.
- Businesses: Organizations engaged in manufacturing and supply chain operations stand to gain significantly from this methodology. By optimizing reverse logistics processes, businesses can achieve cost savings, enhance operational efficiency, and reduce environmental impact. The ability to predict the optimal pathway for returned products enables better resource allocation and waste management, directly contributing to bottom-line improvements and sustainability goals.
- Customers and End-users: Customers benefit from more efficient and sustainable business practices. Efficient reverse logistics processes can lead to enhanced customer satisfaction, particularly when dealing with returns and recalls. Moreover, a commitment to sustainability and reduced environmental impact enhances brand perception, fostering customer loyalty.
- Supply Chain Managers and Decision Makers: This group gains a powerful tool for strategic planning and risk mitigation. The methodology’s predictive capabilities offer valuable insights into future challenges and opportunities in reverse logistics, aiding in proactive decision making. This results in more effective management of inventory, reduced risks of environmental penalties, and improved customer relations.
- Environmental Advocacy Groups and Regulatory Bodies: By aligning with the principles of the circular economy, the methodology supports global efforts towards sustainability. The reduction in waste and more efficient use of resources contribute to broader environmental goals, earning the support of environmental advocates and meeting regulatory standards.
- Researchers and Academics: The methodology presents a fertile ground for further research, particularly in refining its application with real-world data and integrating advanced machine learning techniques. Academics can explore its scalability and adaptability across different industries and supply chain scenarios.
- Technology Developers and Data Scientists: Professionals in these fields can explore the integration of more complex AI-driven techniques, enhancing the model’s performance. The methodology also presents opportunities for developing user-friendly interfaces and custom solutions tailored to specific industry needs.
- Society at Large: As businesses adopt more sustainable practices, the broader societal benefits include reduced environmental degradation and a move towards a more sustainable circular economy model. This contributes to the overall well-being and health of communities and ecosystems.
- Investors and Stakeholders: For investors and stakeholders in companies that adopt this methodology, the benefits include enhanced company valuation due to improved efficiency, sustainability practices, and potentially higher returns on investment due to cost savings and improved market position.
- Model Refinement with Real-World Data: While the proposed methodology offers a robust framework, its validation with diverse real-world datasets can further refine its predictive accuracy. Future research can focus on applying the methodology across various industries and geographies to understand its universal applicability.
- Incorporation of Advanced Machine Learning Techniques: The integration of more advanced machine learning techniques, such as neural networks or support vector machines, can be explored to enhance the model’s performance, especially in capturing complex nonlinear relationships.
- Temporal Analysis: Investigating the methodology’s performance over time, especially in rapidly changing supply chain environments, can provide insights into its adaptability and long-term relevance.
- Comparative Studies: A comparative analysis of the integrated methodology with other predictive models can offer a deeper understanding of its strengths and potential areas of improvement.
- Integration with Other Supply Chain Processes: Exploring the methodology’s applicability in other areas of the supply chain, beyond reverse logistics, can broaden its scope and utility.
- Environmental and Social Impact Assessment: Future research can delve into quantifying the environmental and social benefits of optimized reverse logistics processes achieved through the methodology, aligning with the broader goals of the circular economy.
- Stakeholder Engagement and Acceptance: Understanding the perceptions and acceptance levels of various stakeholders, from supply chain managers to end consumers, can provide insights into the methodology’s practical implementation challenges and strategies to overcome them.
- Economic Impact Analysis: A detailed economic analysis can be conducted to quantify the cost savings, return on investment, and overall economic impact of implementing the integrated methodology in real-world scenarios.
- Customization and Personalization: Exploring ways to customize the methodology based on specific industry needs or company sizes (e.g., SMEs vs. large corporations) can make it more versatile and user-friendly.
- Regulatory and Ethical Considerations: As data-driven decision making becomes more prevalent, understanding the regulatory landscape and ethical considerations associated with data usage, especially in the context of reverse logistics, will be crucial.
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Definition |
|---|---|
| X | Set of independent variables or features in the dataset. |
| y | Dependent variable or target outcome to be predicted. |
| os | Oversampling technique (SMOTE) used for balancing the dataset. |
| X_train, X_test | Training and testing subsets of the independent variables X. |
| y_train, y_test | Training and testing subsets of the dependent variable y. |
| dt | Decision tree model used for segmentation and prediction. |
| y_pred | Predicted outcomes of the model. |
| roc_auc_score | Performance metric measuring the model’s ability to distinguish between classes. |
| Pr | Probability of a specific event occurring. |
| β0, β1, …, βm | Parameters or coefficients of the logistic regression model. |
| e | Base of the natural logarithm, used in logistic regression formulas. |
| Z | Transformed feature set derived from the decision tree’s leaf node assignments. |
| SMOTE | Synthetic Minority Over-sampling Technique for balancing an imbalanced dataset. |
| nodes | New categorical variable derived from the decision tree’s node assignments. |
| df | DataFrame representing the structured data table used for analysis. |
| df_n | DataFrame containing dummy variables from the “nodes” categorical variable. |
| lr0, lr1 | Different logistic regression models: lr0 might exclude decision tree nodes; lr1 includes them. |
| Init | List of initial features used in logistic regression before including decision tree node dummies. |
| ModelLift0, ModelLift1 | Results from model lift analysis for different models. ModelLift0 refers to the model without decision tree nodes; ModelLift1 refers to that with nodes. |
| Node ID | Feature | Threshold | Left Child Node ID | Right Child Node ID | Leaf Node Prediction |
|---|---|---|---|---|---|
| 2 | euribor3m | −1.670749 | 3 | 4 | NaN |
| 3 | Leaf node | NaN | NaN | NaN | 0 (No Return) |
| 4 | Leaf node | NaN | NaN | NaN | 0 (No Return) |
| 5 | nr_employed | −2.028160 | 6 | 7 | NaN |
| 6 | Leaf node | NaN | NaN | NaN | 1 (Return) |
| 7 | Leaf node | NaN | NaN | NaN | 1 (Return) |
| 8 | cons_conf_idx | −1.328265 | 9 | 12 | NaN |
| 9 | euribor3m | −1.298868 | 10 | 11 | NaN |
| 10 | Leaf node | NaN | NaN | NaN | 0 (No Return) |
| 11 | Leaf node | NaN | NaN | NaN | 0 (No Return) |
| 12 | pdays | −5.087916 | 13 | 14 | NaN |
| 13 | Leaf node | NaN | NaN | NaN | 0 (No Return) |
| 14 | Leaf node | NaN | NaN | NaN | 0 (No Return) |
- Feature Transformation Using Decision Trees
- Code Explanation:

- b.
- Binary Logistic Regression on Transformed Features
- Code Explanation:

- c.
- Visualization—ROC Curve
- Code Explanation:

- d.
- Visualization—Confusion Matrix
- Code Explanation:

References
- Zhang, X.; Zou, B.; Feng, Z.; Wang, Y.; Yan, W. A Review on Remanufacturing Reverse Logistics Network Design and Model Optimization. Processes 2022, 10, 84. [Google Scholar] [CrossRef]
- Ghobakhloo, M. Industry 4.0, digitization, and opportunities for sustainability. J. Clean. Prod. 2020, 252, 119869. [Google Scholar] [CrossRef]
- Ghobakhloo, M.; Iranmanesh, M.; Vilkas, M.; Grybauskas, A.; Amran, A. Drivers and barriers of Industry 4.0 technology adoption among manufacturing SMEs: A systematic review and transformation roadmap. J. Manuf. Technol. Manag. 2022, 33, 1029–1058. [Google Scholar] [CrossRef]
- Ghasemi, P.; Hemmaty, H.; Pourghader Chobar, A.; Heidari, M.R.; Keramati, M. A multi-objective and multi-level model for location-routing problem in the supply chain based on the customer’s time window. J. Appl. Res. Ind. Eng. 2023, 10, 412–426. [Google Scholar] [CrossRef]
- Schoenenberger, L.; Schmid, A.; Tanase, R.; Beck, M.; Schwaninger, M. Structural analysis of system dynamics models. Simul. Model. Pract. Theory 2021, 110, 102333. [Google Scholar] [CrossRef]
- Edwards-Jones, G.; Davies, B.; Hussain, S.S. Ecological Economics: An Introduction; John Wiley & Sons: Hoboken, NJ, USA, 2009. [Google Scholar]
- Stewart, T.J.; Durbach, I. Dealing with uncertainties in MCDA. In Multiple Criteria Decision Analysis: State of the Art Surveys; Springer: Berlin/Heidelberg, Germany, 2016; pp. 467–496. [Google Scholar] [CrossRef]
- Sellitto, M.A.; Murakami, F.K. Industrial symbiosis: A case study involving a steelmaking, a cement manufacturing, and a zinc smelting plant. Chem. Eng. Trans. 2018, 70, 211–216. [Google Scholar] [CrossRef]
- Green, K.W.; Zelbst, P.J.; Meacham, J.; Bhadauria, V.S. Green supply chain management practices: Impact on performance. Supply Chain Manag. Int. J. 2012, 17, 290–305. [Google Scholar] [CrossRef]
- Gupta, M.C. Environmental management and its impact on the operations function. Int. J. Oper. Prod. Manag. 1995, 15, 34–51. [Google Scholar] [CrossRef]
- Huscroft, J.R.; Hazen, B.T.; Hall, D.J.; Skipper, J.B.; Hanna, J.B. Reverse logistics: Past research, current management issues, and future directions. Int. J. Logist. Manag. 2013, 24, 304–327. [Google Scholar] [CrossRef]
- Sellitto, M.A.; Hermann, F.F.; Blezs, A.E., Jr.; Barbosa-Póvoa, A.P. Describing and organizing green practices in the context of Green Supply Chain Management: Case studies. Resour. Conserv. Recycl. 2019, 145, 1–10. [Google Scholar] [CrossRef]
- Fleischmann, M.; Krikke, H.R.; Dekker, R.; Flapper, S.D. A characterisation of logistics networks for product recovery. Omega 2000, 28, 653–666. [Google Scholar] [CrossRef]
- Daugherty, P.J.; Richey, R.G.; Genchev, S.E.; Chen, H. Reverse logistics: Superior performance through focused resource commitments to information technology. Transp. Res. Part E Logist. Transp. Rev. 2005, 41, 77–92. [Google Scholar] [CrossRef]
- Lippmann, S. Supply chain environmental management: Elements for success. Corp. Environ. Strategy 1999, 6, 175–182. [Google Scholar] [CrossRef]
- Wei, M.S.; Huang, K.H. Recycling and reuse of industrial wastes in Taiwan. Waste Manag. 2001, 21, 93–97. [Google Scholar] [CrossRef]
- Sasikumar, P.; Kannan, G. Issues in reverse supply chains, part I: End-of-life product recovery and inventory management–an overview. Int. J. Sustain. Eng. 2008, 1, 154–172. [Google Scholar] [CrossRef]
- Rogers, D.S.; Tibben-Lembke, R. An examination of reverse logistics practices. J. Bus. Logist. 2001, 22, 129–148. [Google Scholar] [CrossRef]
- Tibben-Lembke, R.S.; Rogers, D.S. Differences between forward and reverse logistics in a retail environment. Supply Chain Manag. Int. J. 2002, 7, 271–282. [Google Scholar] [CrossRef]
- Kim, K.; Song, I.; Kim, J.; Jeong, B. Supply planning model for remanufacturing system in reverse logistics environment. Comput. Ind. Eng. 2006, 51, 279–287. [Google Scholar] [CrossRef]
- King, A.M.; Burgess, S.C.; Ijomah, W.; McMahon, C.A. Reducing waste: Repair, recondition, remanufacture or recycle? Sustain. Dev. 2006, 14, 257–267. [Google Scholar] [CrossRef]
- Ding, L.; Wang, T.; Chan, P. Forward and reverse logistics for circular economy in construction: A systematic literature review. J. Clean. Prod. 2023, 388, 135981. [Google Scholar] [CrossRef]
- Ni, Z.; Chan, H.K.; Tan, Z. Systematic literature review of reverse logistics for e-waste: Overview, analysis, and future research agenda. Int. J. Logist. Res. Appl. 2023, 26, 843–871. [Google Scholar] [CrossRef]
- Mishra, A.; Dutta, P.; Jayasankar, S.; Jain, P.; Mathiyazhagan, K. A review of reverse logistics and closed-loop supply chains in the perspective of circular economy. Benchmark. Int. J. 2023, 30, 975–1020. [Google Scholar] [CrossRef]
- Mallick, P.K.; Salling, K.B.; Pigosso, D.C.; McAloone, T.C. Closing the loop: Establishing reverse logistics for a circular economy, a systematic review. J. Environ. Manag. 2023, 328, 117017. [Google Scholar] [CrossRef] [PubMed]
- Xin, C.; Wang, J.; Wang, Z.; Wu, C.H.; Nawaz, M.; Tsai, S.B. Reverse logistics research of municipal hazardous waste: A literature review. Environ. Dev. Sustain. 2022, 24, 1495–1531. [Google Scholar] [CrossRef]
- Moosavi, J.; Naeni, L.M.; Fathollahi-Fard, A.M.; Fiore, U. Blockchain in supply chain management: A review, bibliometric, and network analysis. Environ. Sci. Pollut. Res. 2021, 1–5. [Google Scholar] [CrossRef] [PubMed]
- Tian, G.; Lu, W.; Zhang, X.; Zhan, M.; Dulebenets, M.A.; Aleksandrov, A.; Fathollahi-Fard, A.M.; Ivanov, M. A survey of multi-criteria decision-making techniques for green logistics and low-carbon transportation systems. Environ. Sci. Pollut. Res. 2023, 30, 57279–57301. [Google Scholar] [CrossRef]
- Moosavi, J.; Fathollahi-Fard, A.M.; Dulebenets, M.A. Supply chain disruption during the COVID-19 pandemic: Recognizing potential disruption management strategies. Int. J. Disaster Risk Reduct. 2022, 75, 102983. [Google Scholar] [CrossRef]
- Liu, Z.; Li, Z.; Chen, W.; Zhao, Y.; Yue, H.; Wu, Z. Path optimization of medical waste transport routes in the emergent public health event of COVID-19: A hybrid optimization algorithm based on the immune–ant colony algorithm. Int. J. Environ. Res. Public Health 2020, 17, 5831. [Google Scholar] [CrossRef]
- Li, R.; Chen, Y.; Song, J.; Li, M.; Yu, Y. Multi-Objective Optimization Method of Industrial Workshop Layout from the Perspective of Low Carbon. Sustainability 2023, 15, 12275. [Google Scholar] [CrossRef]
- Giallanza, A.; Puma, G.L. Fuzzy green vehicle routing problem for designing a three echelons supply chain. J. Clean. Prod. 2020, 259, 120774. [Google Scholar] [CrossRef]
- Özkır, V.; Başlıgil, H. Multi-objective optimization of closed-loop supply chains in uncertain environment. J. Clean. Prod. 2013, 41, 114–125. [Google Scholar] [CrossRef]
- Homayouni, Z.; Pishvaee, M.S.; Jahani, H.; Ivanov, D. A robust-heuristic optimization approach to a green supply chain design with consideration of assorted vehicle types and carbon policies under uncertainty. Ann. Oper. Res. 2023, 324, 395–435. [Google Scholar] [CrossRef]
- Ferri, G.L.; Gisele de Lorena Diniz, C.; Glaydston Mattos, R. Reverse logistics network for municipal solid waste management: The inclusion of waste pickers as a Brazilian legal requirement. Waste Manag. 2015, 40, 173–191. [Google Scholar] [CrossRef]
- Alós, J.D.S.; Milan, G.S.; Eberle, L. The Reverse Logistics operation of solid waste pos-consumption of electronic products for domestic use in Brazil. Rev. Adm. UFSM 2023, 16, e2. [Google Scholar] [CrossRef]
- Mantzaras, G.; Voudrias, E.A. An optimization model for collection, haul, transfer, treatment and disposal of infectious medical waste: Application to a Greek region. Waste Manag. 2017, 69, 518–534. [Google Scholar] [CrossRef]
- Kargar, S.; Paydar, M.M.; Safaei, A.S. A reverse supply chain for medical waste: A case study in Babol healthcare sector. Waste Manag. 2020, 113, 197–209. [Google Scholar] [CrossRef] [PubMed]
- Tirkolaee, E.B.; Goli, A.; Ghasemi, P.; Goodarzian, F. Designing a sustainable closed-loop supply chain network of face masks during the COVID-19 pandemic: Pareto-based algorithms. J. Clean. Prod. 2022, 333, 130056. [Google Scholar] [CrossRef]
- Tirkolaee, E.B.; Abbasian, P.; Weber, G.W. Sustainable fuzzy multi-trip location-routing problem for medical waste management during the COVID-19 outbreak. Sci. Total Environ. 2022, 756, 143607. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, Z.; Jiao, P.; Zhu, S. Two-stage stochastic programming approach for limited medical reserves allocation under uncertainties. Complex Intell. Syst. 2021, 7, 3003–3013. [Google Scholar] [CrossRef]
- Wang, Z.; Huang, L.; He, C.X. A multi-objective and multi-period optimization model for urban healthcare waste’s reverse logistics network design. J. Comb. Optim. 2021, 42, 785–812. [Google Scholar] [CrossRef]
- Samadhiya, A.; Kumar, A.; Agrawal, R.; Kazancoglu, Y.; Agrawal, R. Reinventing reverse logistics through blockchain technology: A comprehensive review and future research propositions. Supply Chain Forum Int. J. 2023, 24, 81–102. [Google Scholar] [CrossRef]
- Tiwari, S.; Bahuguna, P.C.; Walker, J. Industry 5.0: A macro-perspective approach. In Handbook of Research on Innovative Management Using AI in Industry 5.0; IGI Global: Hershey, PA, USA, 2022; pp. 59–73. [Google Scholar] [CrossRef]
- Adel, A. Future of industry 5.0 in society: Human-centric solutions, challenges and prospective research areas. J. Cloud Comput. 2022, 11, 40. [Google Scholar] [CrossRef] [PubMed]
- Xu, X.; Lu, Y.; Vogel-Heuser, B.; Wang, L. Industry 4.0 and Industry 5.0—Inception, conception and perception. J. Manuf. Syst. 2021, 61, 530–535. [Google Scholar] [CrossRef]
- Paschek, D.; Luminosu, C.T.; Ocakci, E. Industry 5.0 challenges and perspectives for manufacturing Systems in the Society 5.0. In Sustainability and Innovation in Manufacturing Enterprises: Indicators, Models and Assessment for Industry 5.0; Springer: Berlin/Heidelberg, Germany, 2022; pp. 17–63. [Google Scholar] [CrossRef]
- Teunter, R.H. A reverse logistics valuation method for inventory control. Int. J. Prod. Res. 2001, 39, 2023–2035. [Google Scholar] [CrossRef]
- Rachih, H.; Mhada, F.; Chiheb, R. Simulation optimization of an inventory control model for a reverse logistics system. Decis. Sci. Lett. 2022, 11, 43–54. [Google Scholar] [CrossRef]
- Bolis, S.; Maggi, R. Logistics strategy and transport service choices: An adaptive stated preference experiment. Growth Chang. 2003, 34, 490–504. [Google Scholar] [CrossRef]
- Huang, F.L. Alternatives to logistic regression models when analyzing cluster randomized trials with binary outcomes. Prev. Sci. 2023, 24, 398–407. [Google Scholar] [CrossRef]
- Lombardo, L.; Cama, M.; Conoscenti, C.; Märker, M.; Rotigliano, E.J.N.H. Binary logistic regression versus stochastic gradient boosted decision trees in assessing landslide susceptibility for multiple-occurring landslide events: Application to the 2009 storm event in Messina (Sicily, southern Italy). Nat. Hazards 2015, 79, 1621–1648. [Google Scholar] [CrossRef]
- Kotsiantis, S.B. Decision trees: A recent overview. Artif. Intell. Rev. 2013, 39, 261–283. [Google Scholar] [CrossRef]
- Gupta, S.K.; Khang, A.; Somani, P.; Dixit, C.K.; Pathak, A. Data Mining Processes and Decision-Making Models in the Personnel Management System. In Designing Workforce Management Systems for Industry 4.0: Data-Centric and AI-Enabled Approaches; CRC Press: Boca Raton, FL, USA, 2023; p. 85. [Google Scholar]
- Yilmaz, K.G.; Belbag, S. Prediction of consumer behavior regarding purchasing remanufactured products: A logistics regression model. Int. J. Bus. Soc. Res. 2016, 6, 1. [Google Scholar] [CrossRef]
- Mutang, J.A.; Haron, S.A. Factors predicting recycling behaviour among Malaysian. Southeast Asia Psychol. J. 2012, 31, 1. [Google Scholar]
- Tüylü, A.N.; Eroğlu, E. Using Machine Learning Algorithms for Forecasting Rate of Return Product in Reverse Logistics Process. Alphanumer. J. 2019, 7, 143–156. [Google Scholar] [CrossRef]
- Lickert, H.; Wewer, A.; Dittmann, S.; Bilge, P.; Dietrich, F. Selection of suitable machine learning algorithms for classification tasks in reverse logistics. Procedia CIRP 2021, 96, 272–277. [Google Scholar] [CrossRef]
- Dumitrescu, E.; Hué, S.; Hurlin, C.; Tokpavi, S. Machine learning for credit scoring: Improving logistic regression with non-linear decision-tree effects. Eur. J. Oper. Res. 2022, 297, 1178–1192. [Google Scholar] [CrossRef]
- Liu, H.; Setiono, R. Feature transformation and multivariate decision tree induction. In Lecture Notes in Computer Science, Proceedings of the International Conference on Discovery Science, Fukuoka, Japan, 14–16 December 1998; Springer: Berlin/Heidelberg, Germany, 1998. [Google Scholar] [CrossRef]
- Szymanski, A. Combining Logistic Regression and Decision Tree, Making Logistic Regression Less Linear. 2020. Available online: https://towardsdatascience.com/combining-logistic-regression-and-decision-tree-1adec36a4b3f (accessed on 26 November 2023).
- Govindan, K.; Soleimani, H.; Devika, K. Reverse logistics and closed-loop supply chain: A comprehensive review to explore the future. Eur. J. Oper. Res. 2015, 240, 603–626. [Google Scholar] [CrossRef]




| Reverse Channel | Description |
|---|---|
| Product Returns | This channel deals with the return of products due to various reasons such as defects or customer dissatisfaction. Effective communication and cost-effective reverse logistics processes are crucial in this channel. Product returns offer opportunities for material and component recovery, adding value to the supply chain [12]. |
| Product Recalls | Occurring when products are found defective or unsafe, this channel emphasizes the need for timely and efficient recall processes. Collaboration and communication are key factors in managing product recalls effectively [12]. |
| End-of-Life Product Management | This involves the recycling or disposal of products at the end of their useful life. Designing products for recyclability and ease of disassembly, coupled with effective collection and sorting processes, is essential in this channel [12]. |
| Resale | A used product finds a new purpose but generally in a context where it holds lesser value compared to its original use. An example is repurposing an urban bus for agricultural activities. Studies elaborating on resale include [13,14]. |
| Reuse | This process involves reassigning a used product to a new role without any repairs, maintaining its original value. An example is relocating a used vehicle to a different setting where it continues to function as intended. Key references discussing direct reuse include [15,16,17]. |
| Refurbishment | Refurbishing involves cleaning and repairing failed components in products or machines. The focus is on restoring functionality rather than complete rebuilding [18]. |
| Remanufacturing | This process involves the assembly of a new product by combining retrieved parts with new components. The new product meets the original specifications and delivers performance equivalent to the original. This approach is commonly applied in the refurbishment of industrial machinery, as highlighted in studies by [19,20,21]. |
| Authors | Review Focus |
|---|---|
| Ding et al. (2023) [22] | This review explores the extant literature on forward logistics and reverse logistics in the construction industry. |
| Ni et al. (2023) [23] | This review conducted a content analysis of 162 papers from 1998 to 2021 and identified six main research themes on e-waste RL: (1) e-waste legislation and policy, (2) barriers, critical success factors, and solutions, (3) e-waste RL network design decisions, (4) e-waste RL system evaluations and frameworks, (5) consumer e-waste return behavior, (6) technology-based e-waste RL initiatives. |
| Mishra et al. (2023) [24] | This review explores various aspects of reverse logistics and closed-loop supply chains in implementing and achieving circular economy (CE) initiatives. |
| Mallick et al. (2023) [25] | This review explores 116 scholarly articles published between 2011 and 2021 to identify attributes related to the design and implementation of RL systems. |
| Xin et al. (2022) [26] | This review focusses on the extant literature of reverse logistics of municipal hazardous waste (RLMHW) in the past three decades, and then establishes a framework of studies on RLMHW. |
| Item | Transformation |
|---|---|
| Nature of Data | Reverse logistics data can be diverse, ranging from categorical data (like product type, return reason codes) to continuous data (like return quantities, time taken for a return). |
| Normalisation and Scaling | Given that logistic regression is sensitive to the scale of input features, it’s essential to normalize or scale the features so that they have a similar scale. For instance, transforming all numerical features to have values between 0 and 1. |
| Encoding Categorical Variables | Decision trees and logistic regression require numerical input features. Categorical data, like product types or return reasons, need to be converted into a numerical format. Techniques like one-hot encoding or label encoding can be used. |
| Feature Engineering | This involves creating new features from the existing ones to capture intricate patterns in the data better. For instance, from the date of purchase and date of return, one can engineer a feature called ’days_to_return’. |
| Dimensionality Reduction | In cases where the dataset has a large number of features, it might be beneficial to reduce the dimensionality. Techniques like Principal Component Analysis (PCA) can transform the original features into a set of new features (principal components) that retain most of the data’s variance. |
| Temporal Features | Given the dynamic nature of supply chains, time-based features can be crucial. For instance, features capturing seasonal trends, month of the year, or day of the week can be derived to understand periodic patterns in returns. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dabo, A.-A.A.; Hosseinian-Far, A. An Integrated Methodology for Enhancing Reverse Logistics Flows and Networks in Industry 5.0. Logistics 2023, 7, 97. https://doi.org/10.3390/logistics7040097
Dabo A-AA, Hosseinian-Far A. An Integrated Methodology for Enhancing Reverse Logistics Flows and Networks in Industry 5.0. Logistics. 2023; 7(4):97. https://doi.org/10.3390/logistics7040097
Chicago/Turabian StyleDabo, Al-Amin Abba, and Amin Hosseinian-Far. 2023. "An Integrated Methodology for Enhancing Reverse Logistics Flows and Networks in Industry 5.0" Logistics 7, no. 4: 97. https://doi.org/10.3390/logistics7040097