
An Automated Image Processing Module for Quality Evaluation of Milled Rice
 , , ,
, , ,
Abstract
:1. Introduction
2. Materials and Methods
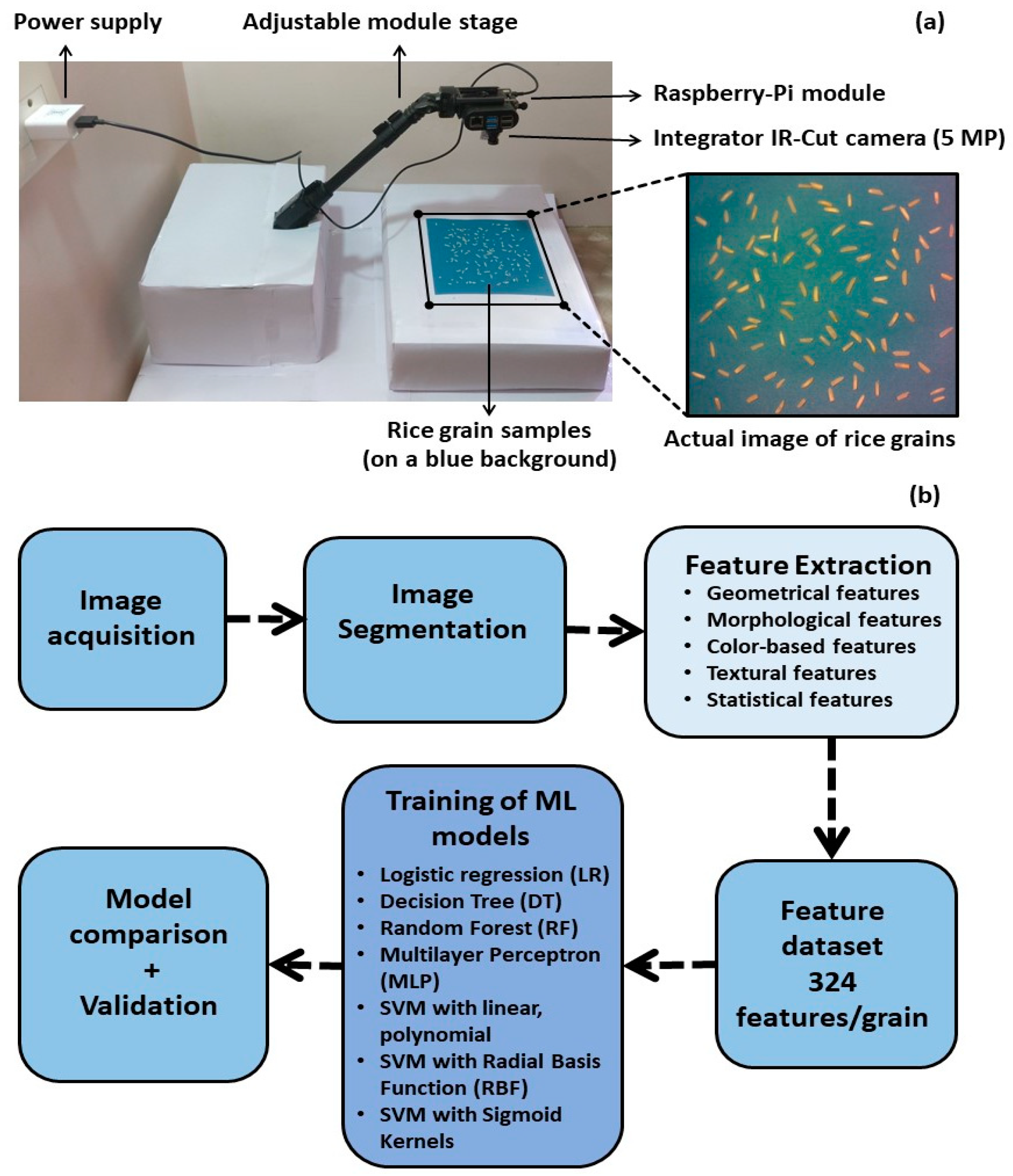
2.1. Raspberry-Pi-Based Machine Vision System
2.2. Sample Collection
2.3. Imaging System
2.4. Dataset Details
2.5. Image Post-Processing
2.5.1. Image Segmentation
2.5.2. Feature Extraction
2.5.3. Geometrical and Morphological Features
2.5.4. Color-Based Features
2.5.5. Textural Features
2.5.6. Statistical Features Using GLCM
2.5.7. Feature Dataset
2.6. Experiments
2.6.1. Model Training
2.6.2. Machine Learning (ML) Models
2.6.3. Decision Tree (DT) Classifier
2.6.4. Random Forest (RF) Classifier
3. Model Comparisons and Discussion
3.1. Performance Metrics
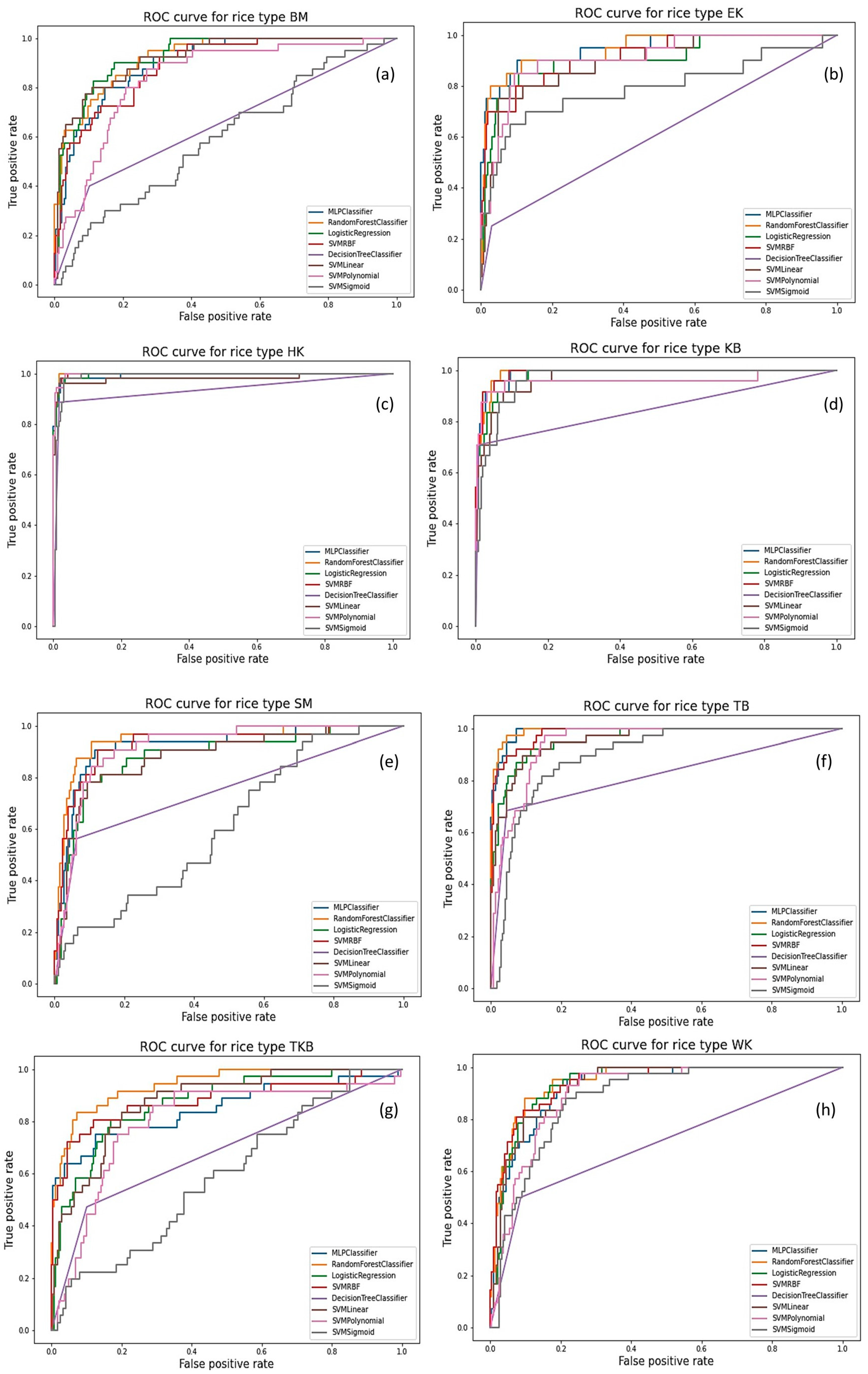
3.2. Receiver Operator Characteristic (ROC) Curves
3.3. Rice Variety Classification Using the RF Classifier
3.4. Validation of the RF Classifier
3.5. Qualitative Comparison of ML Models
4. Conclusions and Future Scope
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Śliwińska-Bartel, M.; Burns, D.T.; Elliott, C. Rice Fraud a Global Problem: A Review of Analytical Tools to Detect Species, Country of Origin and Adulterations. Trends Food Sci. Technol. 2021, 116, 36–46. [Google Scholar] [CrossRef]
- Mittal, S.; Dutta, M.K.; Issac, A. Non-Destructive Image Processing Based System for Assessment of Rice Quality and Defects for Classification According to Inferred Commercial Value. Measurement 2019, 148, 106969. [Google Scholar] [CrossRef]
- Bhupendra, K.; Moses, K.; Miglani, A.; Kumar Kankar, P. Deep CNN-Based Damage Classification of Milled Rice Grains Using a High-Magnification Image Dataset. Comput. Electron. Agric. 2022, 195, 106811. [Google Scholar] [CrossRef]
- Meenu, M.; Decker, E.A.; Xu, B. Application of Vibrational Spectroscopic Techniques for Determination of Thermal Degradation of Frying Oils and Fats: A Review. Crit. Rev. Food Sci. Nutr. 2021, 62, 5744–5765. [Google Scholar] [CrossRef]
- Meenu, M.; Xu, B. Application of Vibrational Spectroscopy for Classification, Authentication and Quality Analysis of Mushroom: A Concise Review. Food Chem. 2019, 289, 545–557. [Google Scholar] [CrossRef]
- Kalra, S.; Meenu, M.; Kumar, D. Damage Detection in Eggshell Using Lamb Waves. Smart Innov. Syst. Technol. 2022, 239, 1–8. [Google Scholar] [CrossRef]
- Meenu, M.; Zhang, Y.; Kamboj, U.; Zhao, S.; Cao, L.; He, P.; Xu, B. Rapid Determination of β-Glucan Content of Hulled and Naked Oats Using near Infrared Spectroscopy Combined with Chemometrics. Foods 2021, 11, 43. [Google Scholar] [CrossRef] [PubMed]
- Kiratiratanapruk, K.; Temniranrat, P.; Sinthupinyo, W.; Prempree, P.; Chaitavon, K.; Porntheeraphat, S.; Prasertsak, A. Development of Paddy Rice Seed Classification Process Using Machine Learning Techniques for Automatic Grading Machine. J. Sens. 2020, 2020, 7041310. [Google Scholar] [CrossRef]
- Meenu, M.; Guha, P.; Mishra, S. Impact of Infrared Treatment on Quality and Fungal Decontamination of Mung Bean (Vigna radiata L.) Inoculated with Aspergillus spp. J. Sci. Food Agric. 2018, 98, 2770–2776. [Google Scholar] [CrossRef]
- Vithu, P.; Moses, J.A. Machine Vision System for Food Grain Quality Evaluation: A Review. Trends Food Sci. Technol. 2016, 56, 13–20. [Google Scholar] [CrossRef]
- Dhakshina Kumar, S.; Esakkirajan, S.; Bama, S.; Keerthiveena, B. A Microcontroller Based Machine Vision Approach for Tomato Grading and Sorting Using SVM Classifier. Microprocess. Microsyst. 2020, 76, 103090. [Google Scholar] [CrossRef]
- Meenu, M.; Kurade, C.; Neelapu, B.C.; Kalra, S.; Ramaswamy, H.S.; Yu, Y. A Concise Review on Food Quality Assessment Using Digital Image Processing. Trends Food Sci. Technol. 2021, 118, 106–124. [Google Scholar] [CrossRef]
- Wu, Y.; Lin, Q.; Chen, Z.; Wu, W.; Xiao, H. Fractal Analysis of the Retrogradation of Rice Starch by Digital Image Processing. J. Food Eng. 2012, 109, 182–187. [Google Scholar] [CrossRef]
- Izquierdo, M.; Lastra-Mejías, M.; González-Flores, E.; Pradana-López, S.; Cancilla, J.C.; Torrecilla, J.S. Visible Imaging to Convolutionally Discern and Authenticate Varieties of Rice and Their Derived Flours. Food Control. 2020, 110, 106971. [Google Scholar] [CrossRef]
- Xu, X.; Xu, S.; Jin, L.; Song, E. Characteristic Analysis of Otsu Threshold and Its Applications. Pattern Recognit. Lett. 2011, 32, 956–961. [Google Scholar] [CrossRef]
- Bradski, G. The OpenCV Library. Dr. Dobb’s J. Softw. Tools 2000, 120, 122–125. [Google Scholar]
- Sun, H.; Yang, J.; Ren, M. A Fast Watershed Algorithm Based on Chain Code and Its Application in Image Segmentation. Pattern Recognit. Lett. 2005, 26, 1266–1274. [Google Scholar] [CrossRef]
- Pathak, B.; Barooah, D. Texture Analysis Based on the Gray-Level Cooccurrence Matrix Considering Possible Orientations. Int. J. Adv. Res. Electr. Electron. Instrum. Eng. 2013, 2, 4206–4212. [Google Scholar]
- Deswal, M.; Sharma, N. A Fast HSV Image Color and Texture Detection and Image Conversion Algorithm. Int. J. Sci. Res. 2014, 3, 1279–1284. [Google Scholar]
- Van der Walt, S.; Schönberger, J.L.; Nunez-Iglesias, J.; Boulogne, F.; Warner, J.D.; Yager, N.; Gouillart, E.; Yu, T. Scikit-Image: Image Processing in Python. PeerJ 2014, 2014, e453. [Google Scholar] [CrossRef]
- Haralick, R.M.; Dinstein, I.; Shanmugam, K. Textural Features for Image Classification. IEEE Trans. Syst. Man Cybern. 1973, SMC-3, 610–621. [Google Scholar] [CrossRef] [Green Version]
- Yang, P.; Yang, G. Feature Extraction Using Dual-Tree Complex Wavelet Transform and Gray Level Co-Occurrence Matrix. Neurocomputing 2016, 197, 212–220. [Google Scholar] [CrossRef]
- Haralick, R.M.; Sternberg, S.R.; Zhuang, X. Image Analysis Using Mathematical Morphology. IEEE Trans. Pattern Anal. Mach. Intell. 1987, PAMI-9, 532–550. [Google Scholar] [CrossRef]
- Koklu, M.; Ozkan, I.A. Multiclass Classification of Dry Beans Using Computer Vision and Machine Learning Techniques. Comput. Electron. Agric. 2020, 174, 105507. [Google Scholar] [CrossRef]
- Singh, S.; Giri, M. Comparative Study Id3, Cart And C4.5 Decision Tree Algorithm: A Survey. Int. J. Adv. Inf. Sci. Technol. 2014, 3, 47–52. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Pettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-Learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- LearnOpenCV. “Otsu’s Thresholding Technique.” LearnOpenCV, n.d. Available online: https://learnopencv.com/otsus-thresholding-technique/ (accessed on 5 February 2023).



{kind=link}
{kind=link}
| Performance Metric | MLP | RF | LR | DT | SVM RBF | SVM Linear | SVM Polynomial | SVM Sigmoid |
|---|---|---|---|---|---|---|---|---|
| Accuracy | 0.734 | 0.771 | 0.768 | 0.676 | 0.773 | 0.764 | 0.705 | 0.699 |
| Precision | 0.730 | 0.767 | 0.739 | 0.646 | 0.762 | 0.742 | 0.728 | 0.718 |
| Recall | 0.728 | 0.760 | 0.739 | 0.655 | 0.751 | 0.748 | 0.683 | 0.669 |
| F1-score | 0.728 | 0.761 | 0.738 | 0.649 | 0.753 | 0.743 | 0.693 | 0.678 |
| Performance Metric | BM | EK | HK | KB | SM | TB | TKB | WK |
|---|---|---|---|---|---|---|---|---|
| Recall | 0.888 | 0.785 | 0.590 | 0.908 | 0.786 | 0.796 | 0.674 | 0.746 |
| Precision | 0.949 | 0.634 | 0.564 | 0.939 | 0.843 | 0.746 | 0.666 | 0.784 |
| F1-score | 0.917 | 0.701 | 0.576 | 0.923 | 0.813 | 0.770 | 0.670 | 0.765 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kurade, C.; Meenu, M.; Kalra, S.; Miglani, A.; Neelapu, B.C.; Yu, Y.; Ramaswamy, H.S. An Automated Image Processing Module for Quality Evaluation of Milled Rice. Foods 2023, 12, 1273. https://doi.org/10.3390/foods12061273
Kurade C, Meenu M, Kalra S, Miglani A, Neelapu BC, Yu Y, Ramaswamy HS. An Automated Image Processing Module for Quality Evaluation of Milled Rice. Foods. 2023; 12(6):1273. https://doi.org/10.3390/foods12061273
Chicago/Turabian StyleKurade, Chinmay, Maninder Meenu, Sahil Kalra, Ankur Miglani, Bala Chakravarthy Neelapu, Yong Yu, and Hosahalli S. Ramaswamy. 2023. "An Automated Image Processing Module for Quality Evaluation of Milled Rice" Foods 12, no. 6: 1273. https://doi.org/10.3390/foods12061273