
Surface Defect Detection System for Carrot Combine Harvest Based on Multi-Stage Knowledge Distillation

Abstract
:1. Introduction
2. Related Works
2.1. Lightweight Convolutional Neural Network
2.2. Object Detection
2.3. Knowledge Distillation
3. Materials and Methods
3.1. Test Materials Acquisition
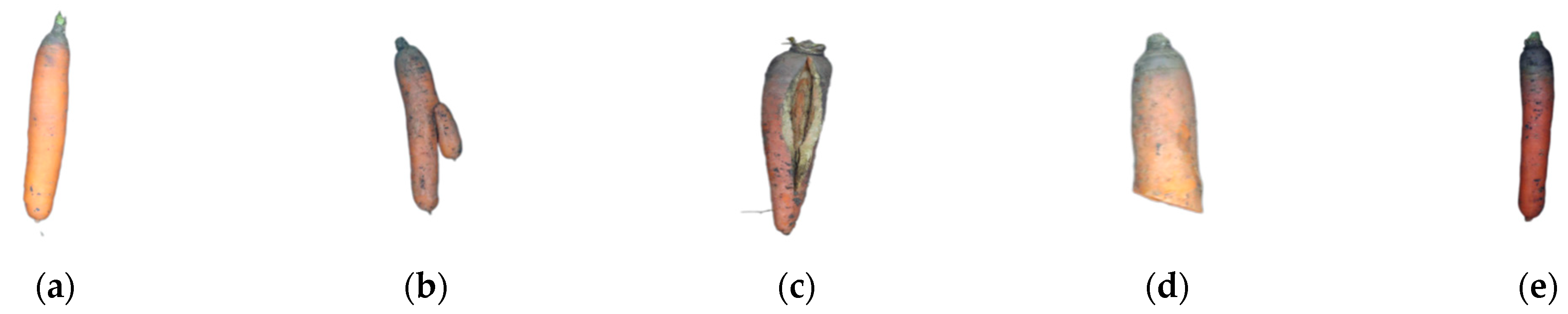
3.2. Dataset Construction
3.2.1. System Design and Image Acquisition and Division
3.2.2. Data Preprocessing and Data Enhancement
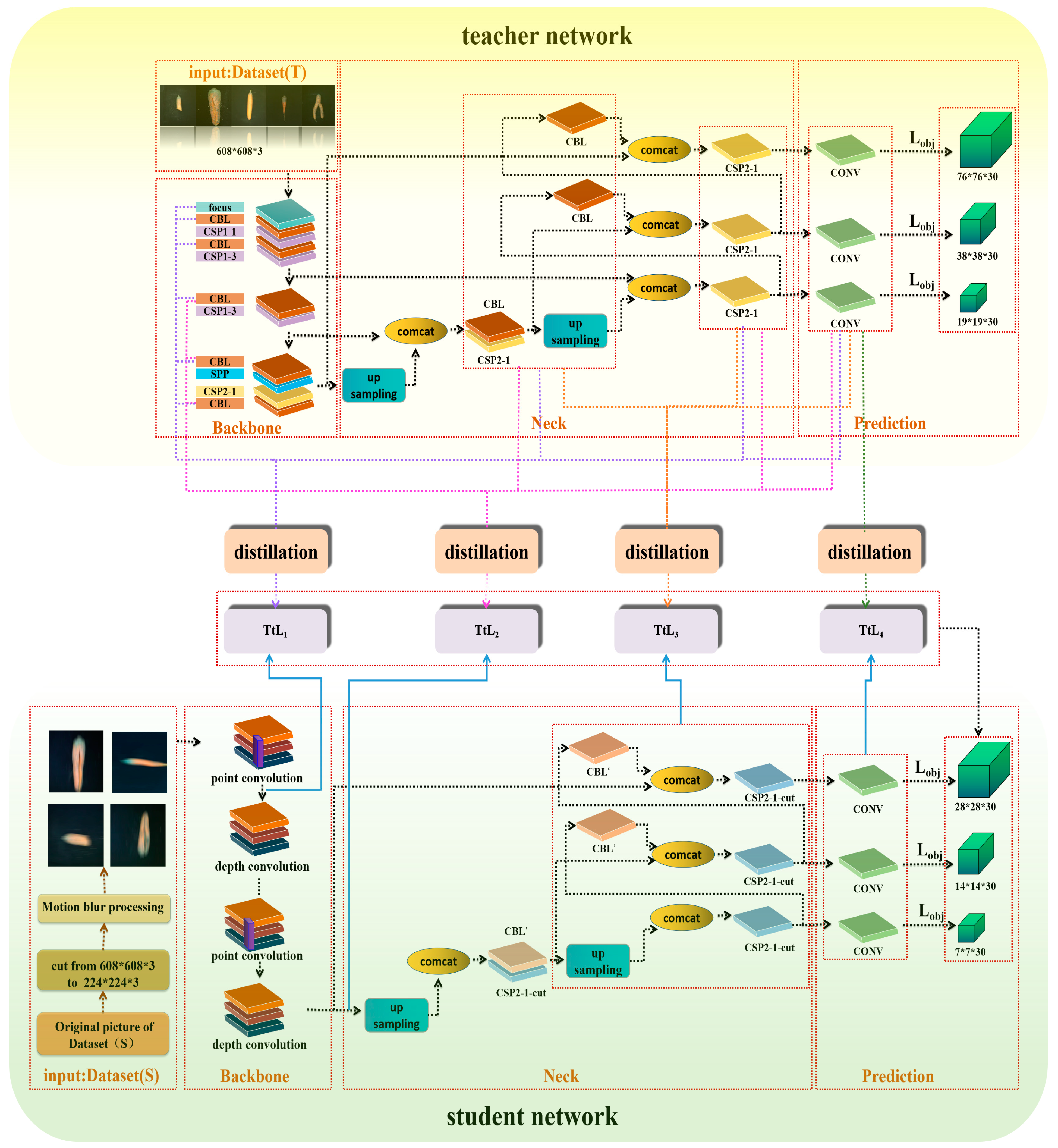
3.3. Improved Multi-Stage Knowledge Distillation Carrot Surface Defect Detection Network
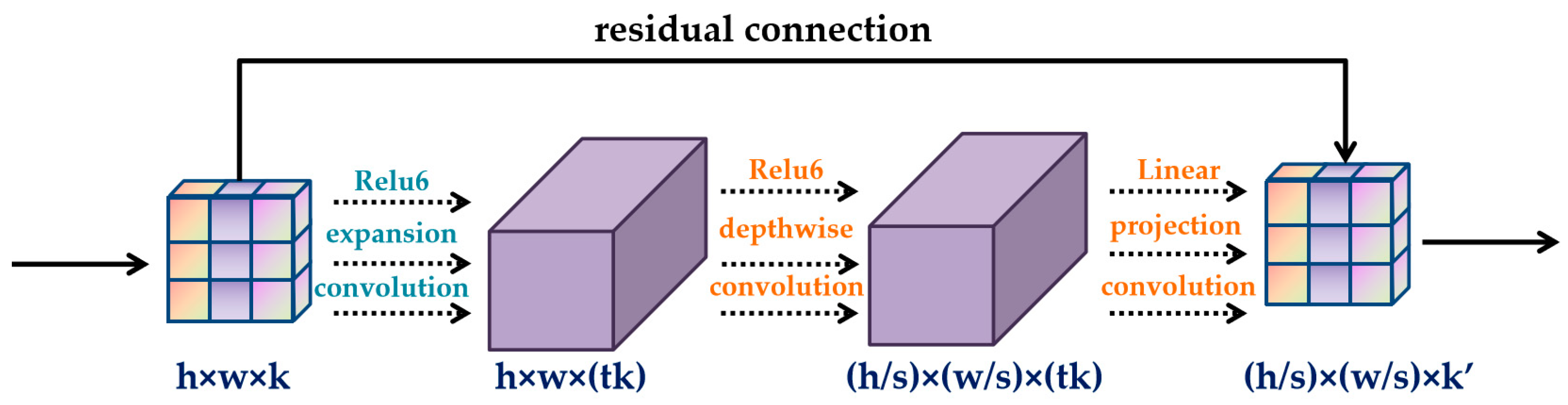
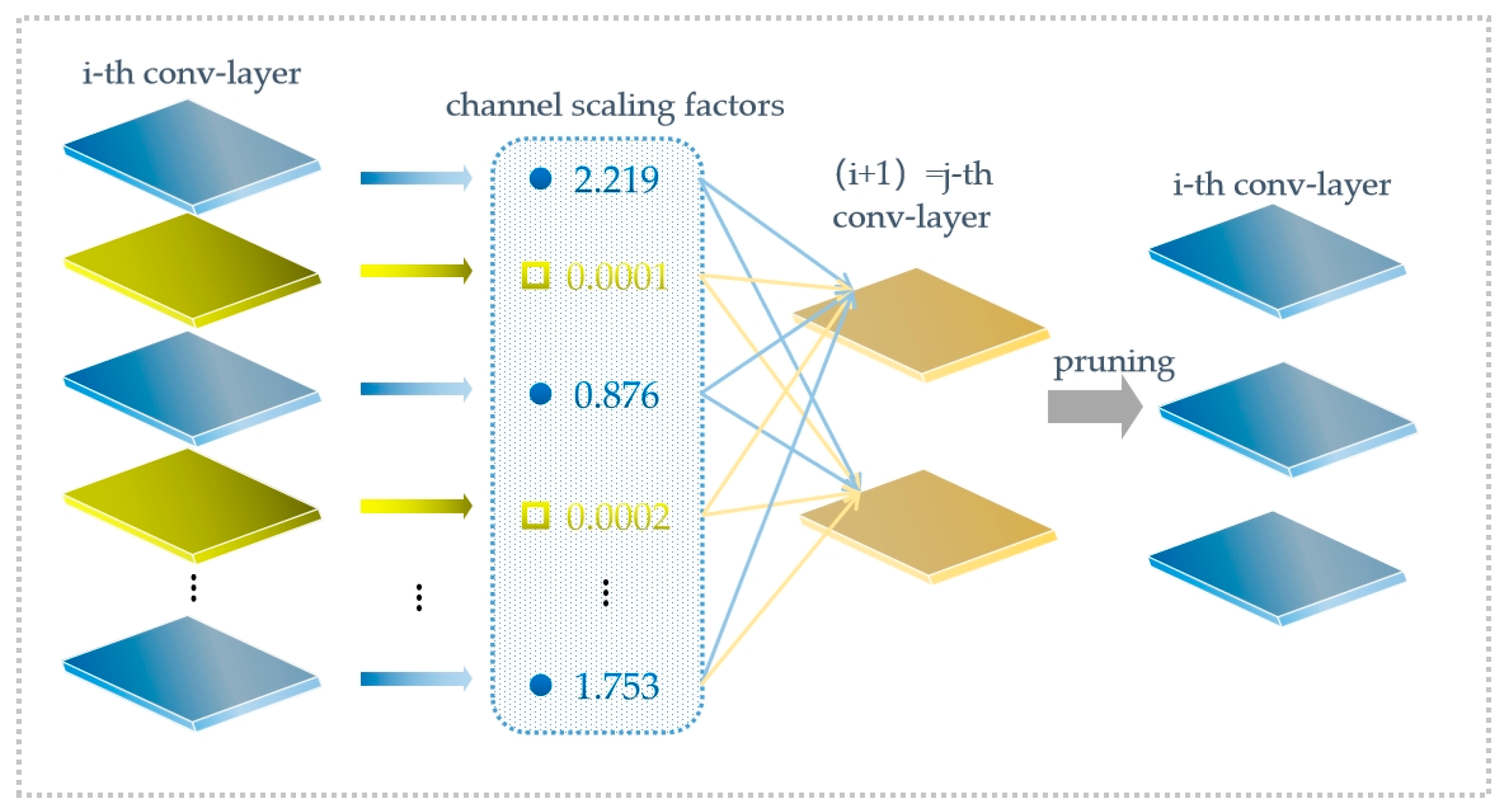
3.3.1. Improvement of the Student Network
3.3.2. Innovation of the Knowledge Distillation
3.4. Operation Flow
3.5. Evaluation
3.5.1. Basic Indicators
3.5.2. mAP
4. Results
4.1. Effect of Teacher Network Scale on Distillation Effect
4.2. Effect of Student Network on Knowledge Distillation Effect
4.2.1. Effect of Student Network Backbone
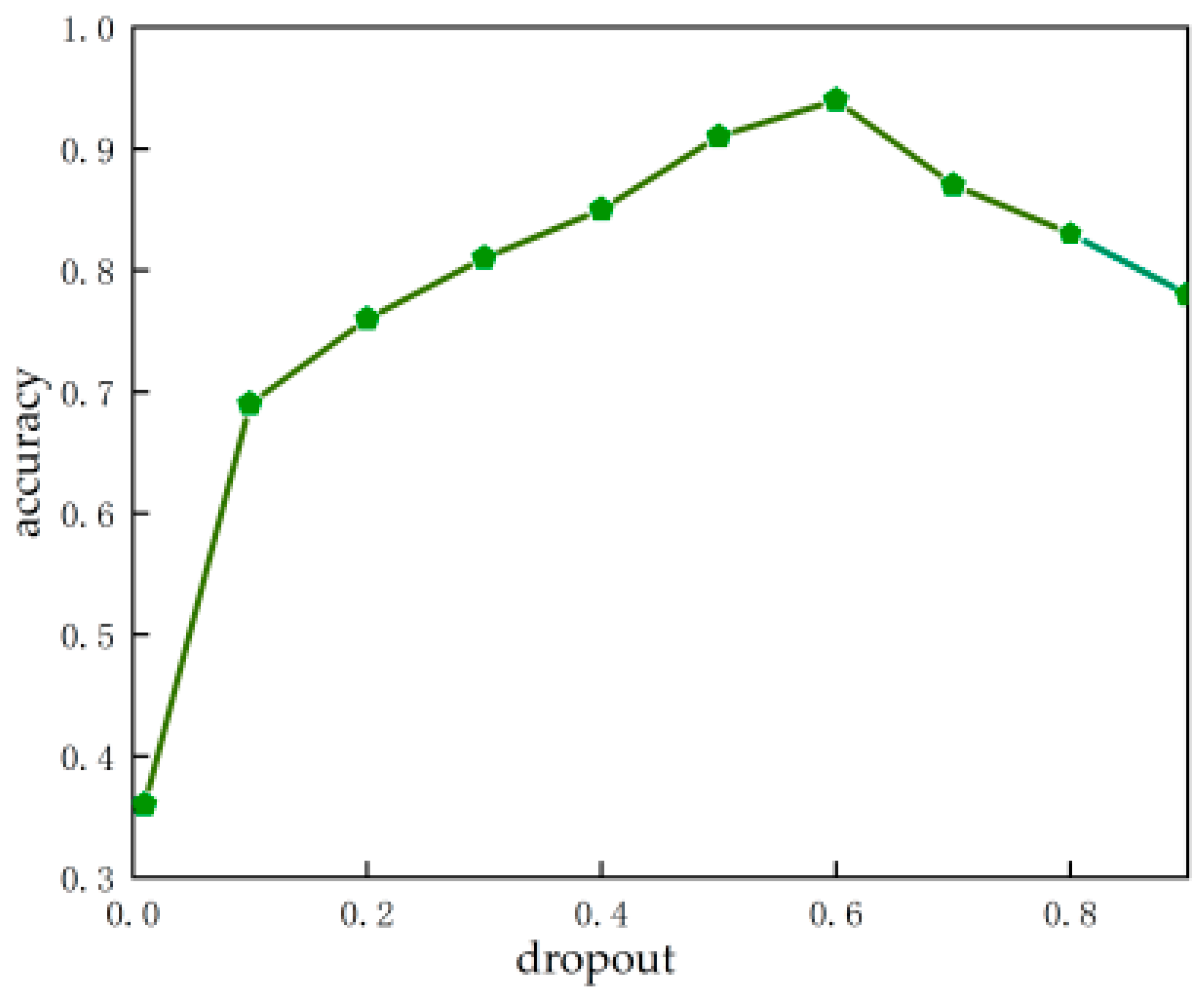
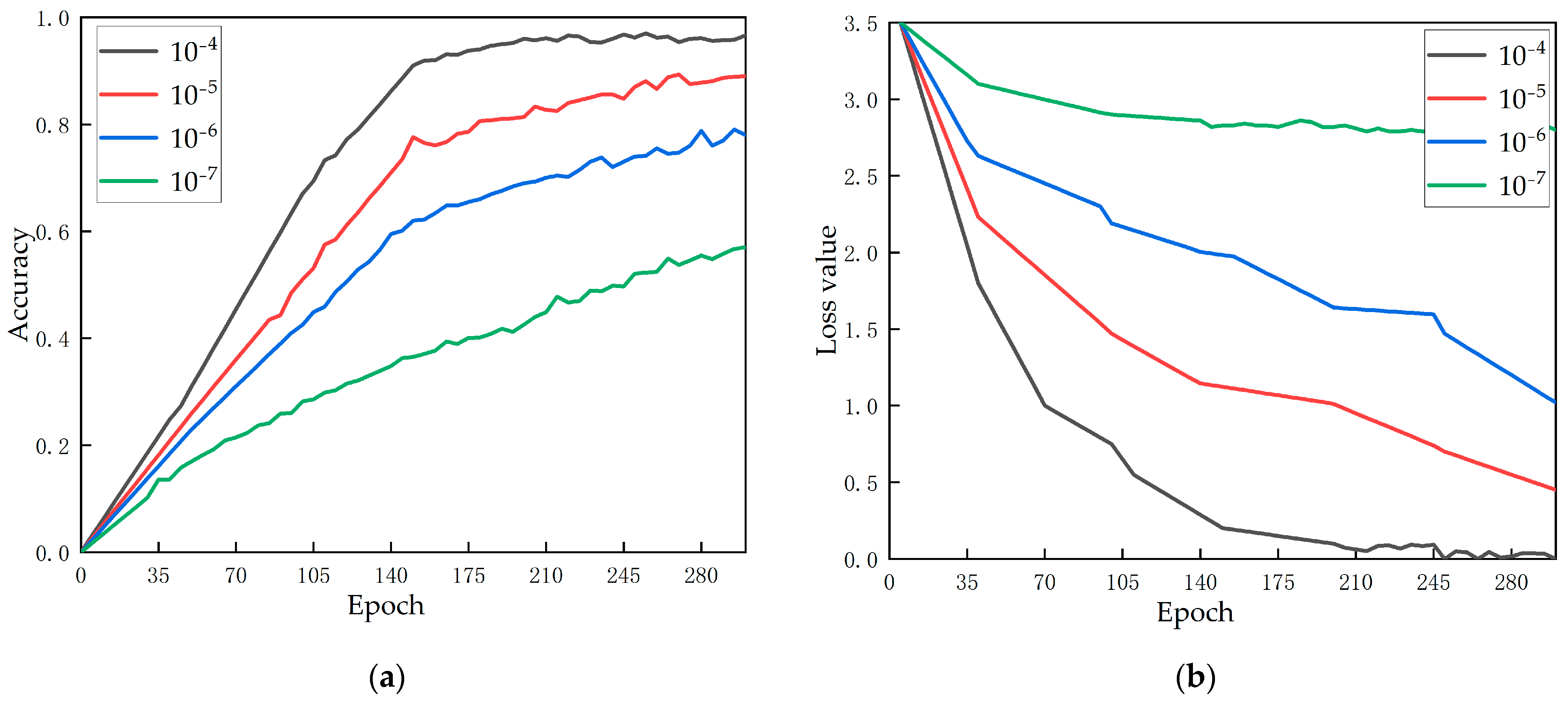
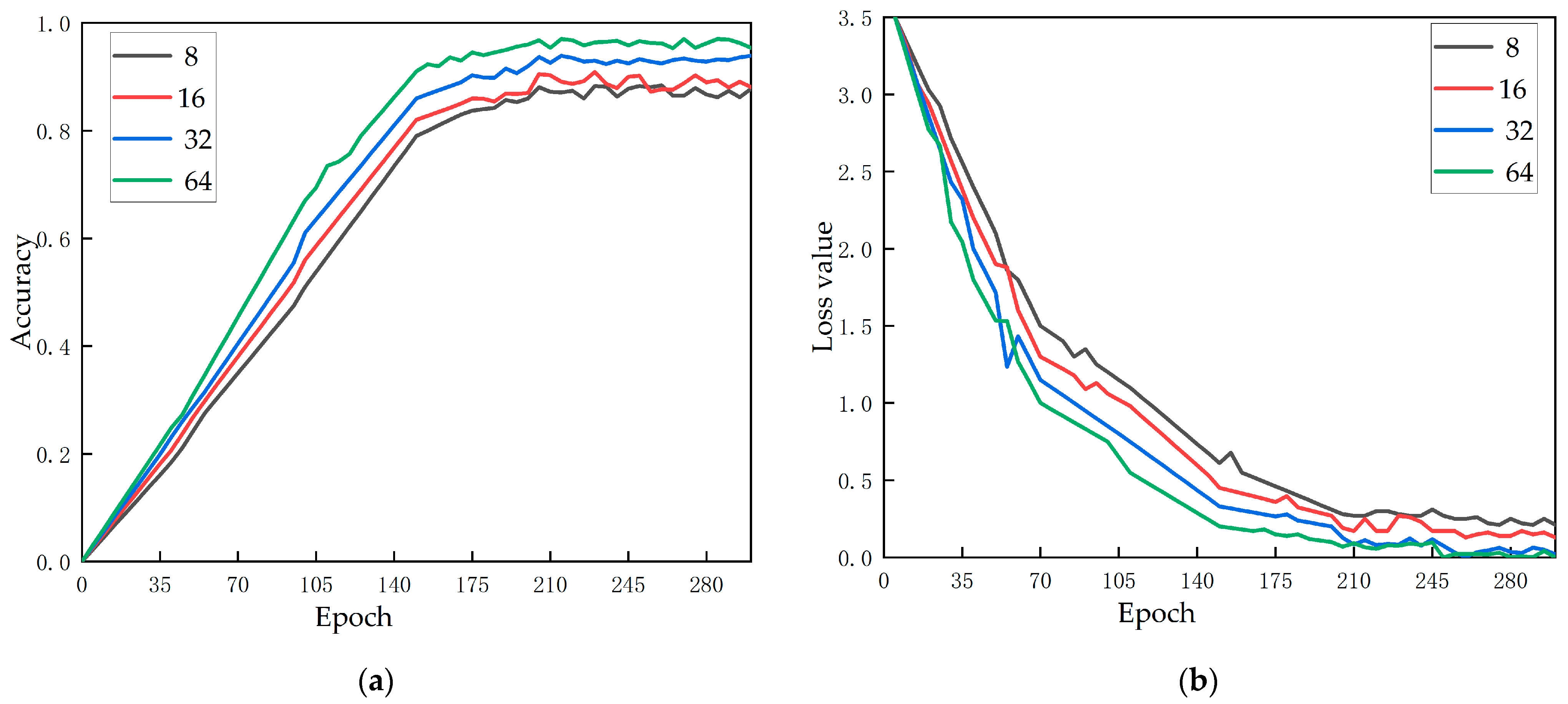
4.2.2. Effect of Student Network Model Hyperparameters
- Effect of the dropout ratio
- Effects of the learning rate
- Effect of the batch size
4.3. Effectiveness Evaluation of Knowledge Distillation
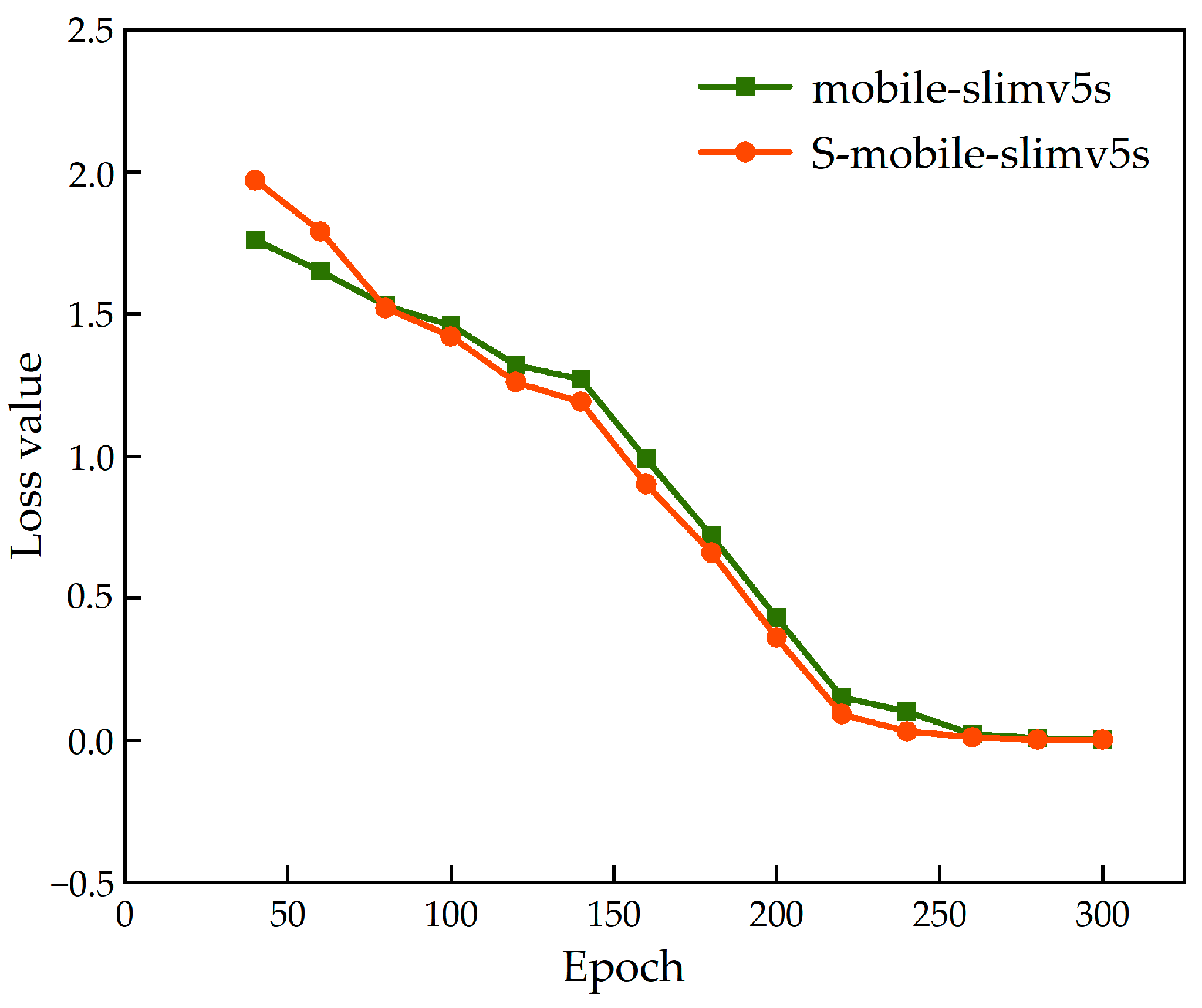
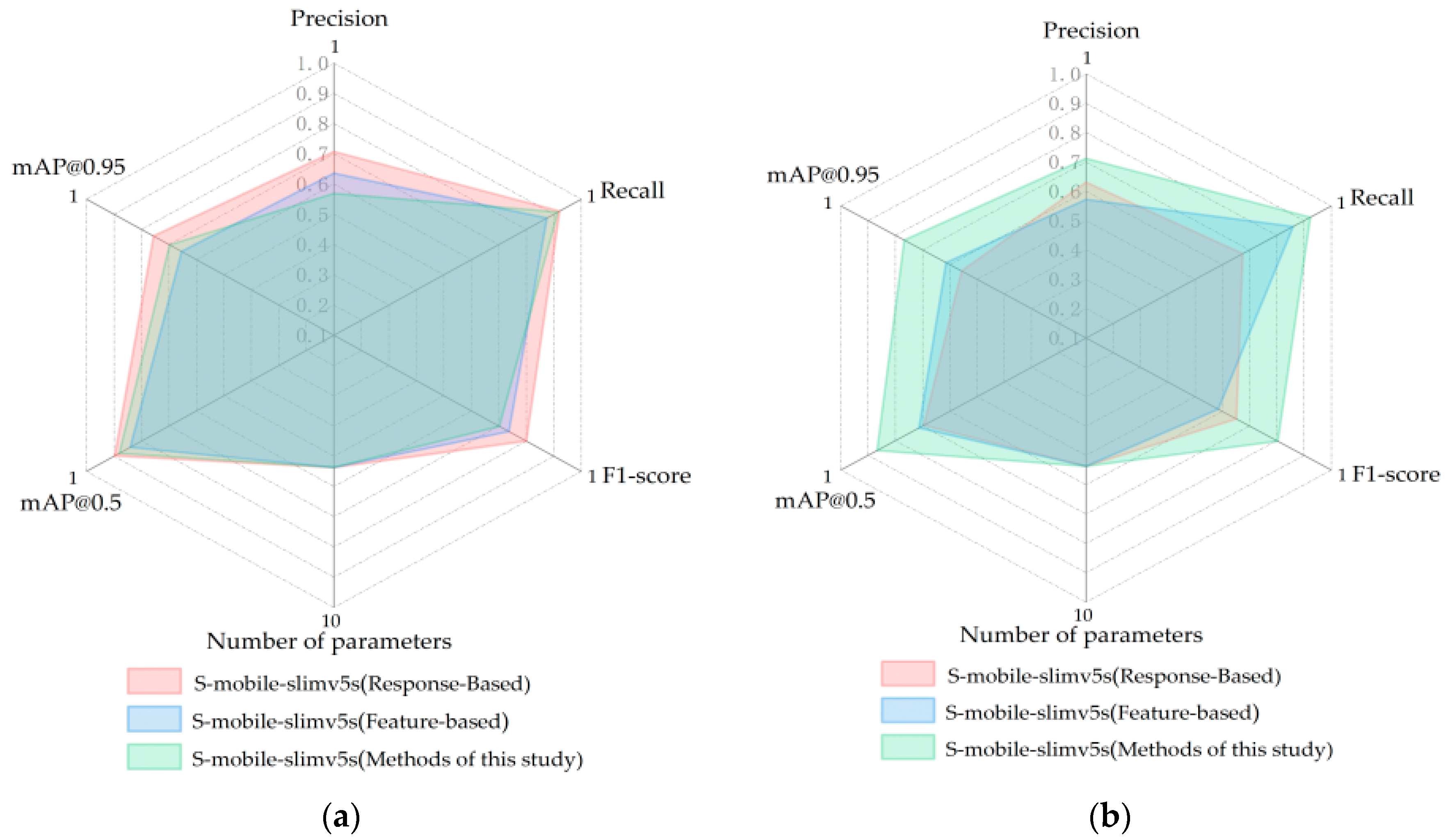
4.3.1. Comparative Test on the Effectiveness of Multi-Stage Knowledge Distillation
4.3.2. Feature Extraction Visualization
4.4. Overall Evaluation of Model Performance
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sharma, K.D.; Karki, S.; Thakur, N.S.; Attri, S. Chemical composition, functional properties and processing of carrot—A review. J. Food Sci. Technol. 2012, 49, 22–32. [Google Scholar] [CrossRef]
- FAO. Available online: http://www.fao.org (accessed on 1 June 2022).
- Le Clerc, V.; Briard, M.J.C.; Crops, R.A. Carrot disease management. In Carrots and Related Apiaceae Crops; CABI: Wallingford, UK, 2020; Volume 33, pp. 115–129. [Google Scholar]
- Xie, W.; Wei, S.; Zheng, Z.; Yang, D. A CNN-based lightweight ensemble model for detecting defective carrots. Biosyst. Eng. 2021, 208, 287–299. [Google Scholar] [CrossRef]
- Xie, W.; Wei, S.; Zheng, Z.; Chang, Z.; Yang, D. Developing a stacked ensemble model for predicting the mass of fresh carrot. Postharvest Biol. Technol. 2022, 186, 11846. [Google Scholar] [CrossRef]
- Chaudhari, D.; Waghmare, S. Machine Vision Based Fruit Classification and GradingA Review. In Proceedings of the 4th International Conference on Communications and Cyber-Physical Engineering, ICCCE 2021, Hyderabad, India, 9–10 April 2021; pp. 775–781. [Google Scholar]
- Wu, Z.; Yang, R.; Gao, F.; Wang, W.; Fu, L.; Li, R. Segmentation of abnormal leaves of hydroponic lettuce based on DeepLabV3+for robotic sorting. Comput. Electron. Agric. 2021, 190, 106443. [Google Scholar] [CrossRef]
- Calixto, R.R.; Pinheiro Neto, L.G.; Cavalcante, T.d.S.; Nascimento Lopes, F.G.; de Alexandria, A.R.; Silva, E.d.O. Development of a computer vision approach as a useful tool to assist producers in harvesting yellow melon in northeastern Brazil. Comput. Electron. Agric. 2022, 192, 106554. [Google Scholar] [CrossRef]
- Ni, H.; Zhang, J.; Zhao, N.; Wang, C.; Lv, S.; Ren, F.; Wang, X. Design on the Winter Jujubes Harvesting and Sorting Device. Appl. Sci. 2019, 9, 5546. [Google Scholar] [CrossRef]
- Zou, X.; Zhao, J.; Li, Y.; Holmes, M. In-line detection of apple defects using three color cameras system. Comput. Electron. Agric. 2010, 70, 129–134. [Google Scholar] [CrossRef]
- Blasco, J.; Aleixos, N.; Molto, E. Computer vision detection of peel defects in citrus by means of a region oriented segmentation algorithm. J. Food Eng. 2007, 81, 535–543. [Google Scholar] [CrossRef]
- Liming, X.; Yanchao, Z. Automated strawberry grading system based on image processing. Comput. Electron. Agric. 2010, 71, S32–S39. [Google Scholar] [CrossRef]
- Han, Z.; Deng, L.; Xu, Y.; Feng, Y.; Geng, Q.; Xiong, K. Image processing method for detection of carrot green-shoulder, fibrous roots and surface cracks. Trans. Chin. Soc. Agric. Eng. 2013, 29, 156–161. [Google Scholar]
- Deng, L.; Du, H.; Han, Z. A carrot sorting system using machine vision technique. Appl. Eng. Agric. 2017, 33, 149–156. [Google Scholar] [CrossRef]
- Xie, W.; Wang, F.; Yang, D. Research on Carrot Grading Based on Machine Vision Feature Parameters. IFAC-Pap. 2019, 52, 30–35. [Google Scholar] [CrossRef]
- Chen, J.; Zhang, D.; Nanehkaran, Y.A.; Li, D. Detection of rice plant diseases based on deep transfer learning. J. Sci. Food Agric. 2020, 100, 3246–3256. [Google Scholar] [CrossRef] [PubMed]
- Azarmdel, H.; Jahanbakhshi, A.; Mohtasebi, S.S.; Munoz, A.R. Evaluation of image processing technique as an expert system in mulberry fruit grading based on ripeness level using artificial neural networks (ANNs) and support vector machine (SVM). Postharvest Biol. Technol. 2020, 166, 111201. [Google Scholar] [CrossRef]
- Zhang, M.; Jiang, Y.; Li, C.; Yang, F. Fully convolutional networks for blueberry bruising and calyx segmentation using hyperspectral transmittance imaging. Biosyst. Eng. 2020, 192, 159–175. [Google Scholar] [CrossRef]
- Wang, Z.; Jin, L.; Wang, S.; Xu, H. Apple stem/calyx real-time recognition using YOLO-v5 algorithm for fruit automatic loading system. Postharvest Biol. Technol. 2022, 185, 111808. [Google Scholar] [CrossRef]
- Jahanbakhshi, A.; Momeny, M.; Mahmoudi, M.; Radeva, P. Waste management using an automatic sorting system for carrot fruit based on image processing technique and improved deep neural networks. Energy Rep. 2021, 7, 5248–5256. [Google Scholar] [CrossRef]
- Zhu, H.; Yang, L.; Fei, J.; Zhao, L.; Han, Z. Recognition of carrot appearance quality based on deep feature and support vector machine. Comput. Electron. Agric. 2021, 186, 106185. [Google Scholar] [CrossRef]
- Xie, W.; Wei, S.; Zheng, Z.; Jiang, Y.; Yang, D. Recognition of Defective Carrots Based on Deep Learning and Transfer Learning. Food Bioprocess Technol. 2021, 14, 1361–1374. [Google Scholar] [CrossRef]
- Deng, L.; Li, J.; Han, Z. Online defect detection and automatic grading of carrots using computer vision combined with deep learning methods. Lwt-Food Sci. Technol. 2021, 149, 111832. [Google Scholar] [CrossRef]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Li, Z.; Wu, X.; Wang, J.; Guo, Y. Weather-degraded image semantic segmentation with multi-task knowledge distillation. Image Vis. Comput. 2022, 127, 104554. [Google Scholar] [CrossRef]
- Wang, Z.; Li, Z.; He, D.; Chan, S. A Lightweight Approach for Network Intrusion Detection in Industrial Cyber-Physical Systems Based on Knowledge Distillation and Deep Metric Learning. Expert Syst. Appl. 2022, 206, 117671. [Google Scholar] [CrossRef]
- Biswas, S.; Bowyer, K.W.; Flynn, P.J. Multidimensional Scaling for Matching Low-Resolution Face Images. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2019–2030. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective Kernel Networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 510–519. [Google Scholar]
- Ma, T.; Tian, W.; Xie, Y. Multi-level knowledge distillation for low-resolution object detection and facial expression recognition. Knowl.-Based Syst. 2022, 240, 108136. [Google Scholar] [CrossRef]
- Ornek, M.N.; Ornek, H.K. Developing a deep neural network model for predicting carrots volume. J. Food Meas. Charact. 2021, 15, 3471–3479. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Qi, J.; Liu, X.; Liu, K.; Xu, F.; Guo, H.; Tian, X.; Li, M.; Bao, Z.; Li, Y. An improved YOLOv5 model based on visual attention mechanism: Application to recognition of tomato virus disease. Comput. Electron. Agric. 2022, 194, 106780. [Google Scholar] [CrossRef]
- Zhang, D.Y.; Luo, H.S.; Wang, D.Y.; Zhou, X.G.; Li, W.F.; Gu, C.Y.; Zhang, G.; He, F.M. Assessment of the levels of damage caused by Fusarium head blight in wheat using an improved YoloV5 method. Comput. Electron. Agric. 2022, 198, 107086. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Romero, A.; Ballas, N.; Kahou, S.E.; Chassang, A.; Gatta, C.; Bengio, Y. Fitnets: Hints for thin deep nets. arXiv 2014, arXiv:1412.6550. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer. arXiv 2016, arXiv:1612.03928. [Google Scholar]
- Chen, Z.; Le, Z.; Cao, Z.; Guo, J. Distilling the Knowledge from Handcrafted Features for Human Activity Recognition. IEEE Trans. Ind. Inform. 2018, 14, 4334–4342. [Google Scholar] [CrossRef]
- Kataria, D.; Chahal, K.K.; Kaur, P.; Kaur, R. Carrot plant—A potential source of high value compounds and biological activities: A review. Proc. Indian Natl. Sci. Acad. 2016, 82, 1237–1248. [Google Scholar] [CrossRef]
- Liu, Z.; Li, J.; Shen, Z.; Huang, G.; Yan, S.; Zhang, C. Learning efficient convolutional networks through network slimming. In Proceedings of the Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2736–2744. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.-T.; Sun, J. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. In Proceedings of the Computer Vision—ECCV 2018, Munich, Germany, 8–14 September 2018; pp. 122–138. [Google Scholar]
- Howard, A.; Sandler, M.; Chen, B.; Wang, W.; Chen, L.C.; Tan, M.; Chu, G.; Vasudevan, V.; Zhu, Y.; Pang, R.; et al. Searching for MobileNetV3. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. GhostNet: More Features from Cheap Operations. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1577–1586. [Google Scholar]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv 2012, arXiv:1207.0580. [Google Scholar]
- Liu, Z. Soft-shell shrimp recognition based on an improved AlexNet for quality evaluations. J. Food Eng. 2020, 266, 109698. [Google Scholar] [CrossRef]
- Qin, Z.; Yu, F.; Liu, C.; Chen, X. How convolutional neural network see the world-A survey of convolutional neural network visualization methods. arXiv 2018, arXiv:1804.11191. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Zhang, W.; Wang, J. Adaptive Multi-Teacher Multi-level Knowledge Distillation. Neurocomputing 2020, 415, 106–113. [Google Scholar] [CrossRef]
- Xiong, Y.; Liu, H.; Gupta, S.; Akin, B.; Bender, G.; Wang, Y.; Kindermans, P.J.; Tan, M.; Singh, V.; Chen, B. MobileDets: Searching for Object Detection Architectures for Mobile Accelerators. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Sutaji, D.; Yıldız, O. LEMOXINET: Lite ensemble MobileNetV2 and Xception models to predict plant disease. Ecol. Inform. 2022, 70, 101698. [Google Scholar] [CrossRef]
- Chen, Z.; Yang, J.; Chen, L.; Jiao, H. Garbage classification system based on improved shufflenet v2. Conserv. Recycl. 2022, 178, 106090. [Google Scholar] [CrossRef]
- Guo, J.; He, G.; Deng, H.; Fan, W.; Xu, L.; Cao, L.; Feng, D.; Li, J.; Wu, H.; Lv, J.; et al. Pigeon cleaning behavior detection algorithm based on light-weight network. Comput. Electron. Agric. 2022, 199, 107032. [Google Scholar] [CrossRef]
- Li, S.; Zhang, S.; Xue, J.; Sun, H. Lightweight target detection for the field flat jujube based on improved YOLOv5. Comput. Electron. Agric. 2022, 202, 107391. [Google Scholar] [CrossRef]
- Khan, M.S.; Alam, K.N.; Dhruba, A.R.; Zunair, H.; Mohammed, N. Knowledge distillation approach towards melanoma detection. Comput. Biol. Med. 2022, 146, 105581. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Wang, Y.; Zhang, J. Low-Light Image Enhancement with Knowledge Distillation. Neurocomputing 2022, 518, 332–343. [Google Scholar] [CrossRef]
- Xie, J.; Lin, S.; Zhang, Y.; Luo, L. Training convolutional neural networks with cheap convolutions and online distillation. arXiv 2019, arXiv:1909.13063. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Classes | Quantity of Carrots |
|---|---|---|
| 1 | Normal | 1138 |
| 2 | Bifurcate | 909 |
| 3 | Cracking | 964 |
| 4 | Breakage | 942 |
| 5 | Greenroot | 1047 |
| Evaluation Metric | Calculation Formula |
|---|---|
| Precision | |
| Recall | |
| Accuracy | |
| F1-Measure | |
| Specificity |
| Teacher Network | Model | Precision | Recall | F1-Score | mAP@0.5 | mAP@0.95 | Number of Parameters (Million) |
|---|---|---|---|---|---|---|---|
| yolo-v5s as the teacher networks | T-yolo-v5s | 0.736 | 0.946 | 0.828 | 0.909 | 0.827 | 15.36 |
| mobile-slimv5s | 0.496 | 0.809 | 0.614 | 0.819 | 0.613 | 5.07 | |
| S-mobile-slimv5s | 0.512 | 0.923 | 0.659 | 0.879 | 0.766 | 5.37 | |
| yolo-v5m as the teacher networks | T-yolo-v5m | 0.765 | 0.957 | 0.850 | 0.911 | 0.841 | 20.72 |
| mobile-slimv5s | 0.496 | 0.809 | 0.614 | 0.819 | 0.613 | 5.07 | |
| S-mobile-slimv5s | 0.567 | 0.772 | 0.604 | 0.723 | 0.675 | 5.41 | |
| yolo-v5l as the teacher networks | T-yolo-v5l | 0.823 | 0.972 | 0.891 | 0.932 | 0.867 | 49.9 |
| mobile-slimv5s | 0.496 | 0.809 | 0.614 | 0.819 | 0.613 | 5.07 | |
| S-mobile-slimv5s | 0.517 | 0.714 | 0.599 | 0.741 | 0.701 | 5.46 |
| Model | Precision | Recall | F1-Score | Accuracy | Number of Parameters (Million) | Loss (Epoch = 300) |
|---|---|---|---|---|---|---|
| T-yolo-v5s | 0.736 | 0.946 | 0.828 | 0.976 | 15.36 | 0.00032 |
| S-shufflenetv2-yolo-v5s | 0.659 | 0.974 | 0.786 | 0.883 | 7.59 | 0.00016 |
| S-mobile-slimv5s | 0.512 | 0.923 | 0.659 | 0.901 | 5.37 | 0.00006 |
| S-mobilenetv3-yolo-v5s | 0.455 | 0.903 | 0.605 | 0.903 | 6.84 | 0.00013 |
| S-GhostNet-yolo-v5s | 0.536 | 0.917 | 0.677 | 0.829 | 6.85 | 0.00024 |
| Model | mAP@0.50 | mAP@0.95 | Precision | Recall |
|---|---|---|---|---|
| T-yolo-v5s | 0.909 | 0.827 | 0.736 | 0.946 |
| mobile-slimv5s | 0.762 | 0.764 | 0.581 | 0.857 |
| S-mobile-slimv5s | 0.881 | 0.793 | 0.569 | 0.915 |
| Model | mAP@0.50 | mAP@0.95 | Precision | Recall |
|---|---|---|---|---|
| T-yolo-v5s | 0.875 | 0.758 | 0.834 | 0.928 |
| mobile-slimv5s | 0.819 | 0.613 | 0.496 | 0.809 |
| S-mobile-slimv5s | 0.879 | 0.766 | 0.512 | 0.923 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, W.; Song, C.; Song, K.; Wen, N.; Sun, X.; Gao, P. Surface Defect Detection System for Carrot Combine Harvest Based on Multi-Stage Knowledge Distillation. Foods 2023, 12, 793. https://doi.org/10.3390/foods12040793
Zhou W, Song C, Song K, Wen N, Sun X, Gao P. Surface Defect Detection System for Carrot Combine Harvest Based on Multi-Stage Knowledge Distillation. Foods. 2023; 12(4):793. https://doi.org/10.3390/foods12040793
Chicago/Turabian StyleZhou, Wenqi, Chao Song, Kai Song, Nuan Wen, Xiaobo Sun, and Pengxiang Gao. 2023. "Surface Defect Detection System for Carrot Combine Harvest Based on Multi-Stage Knowledge Distillation" Foods 12, no. 4: 793. https://doi.org/10.3390/foods12040793