
Identification of Defective Maize Seeds Using Hyperspectral Imaging Combined with Deep Learning
 ,
,
Abstract
:1. Introduction
2. Materials and Methods
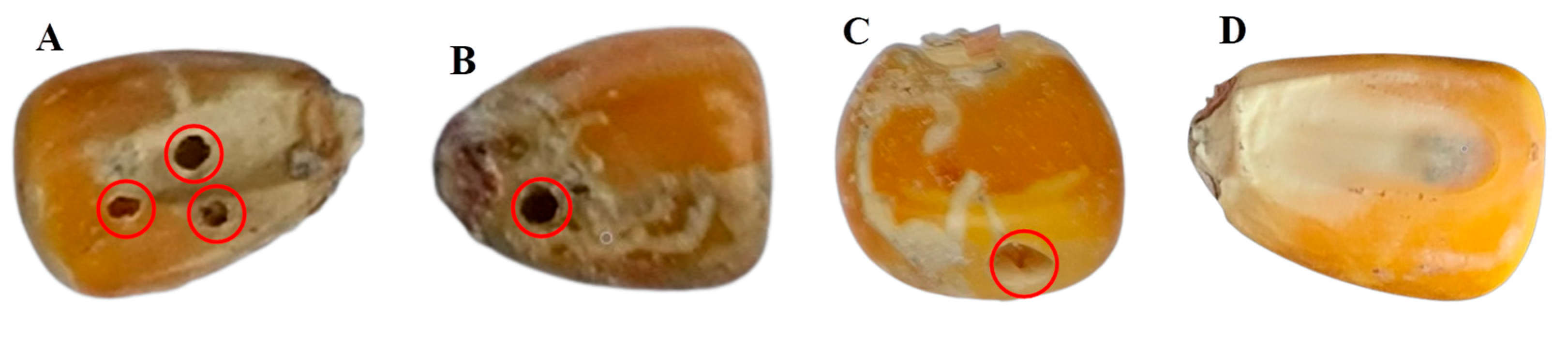
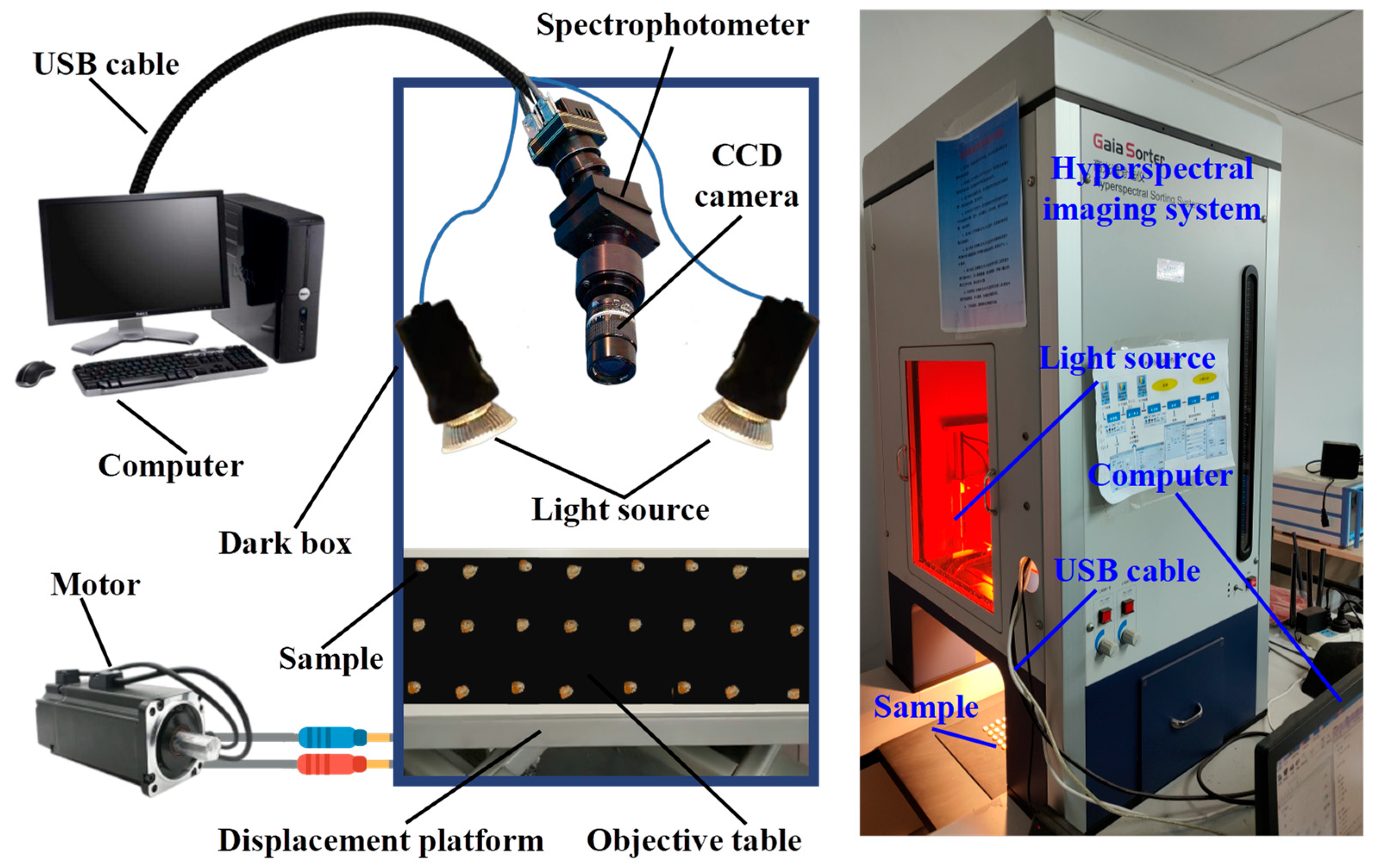
2.1. Sample Preparation and Hyperspectral Image Acquisition
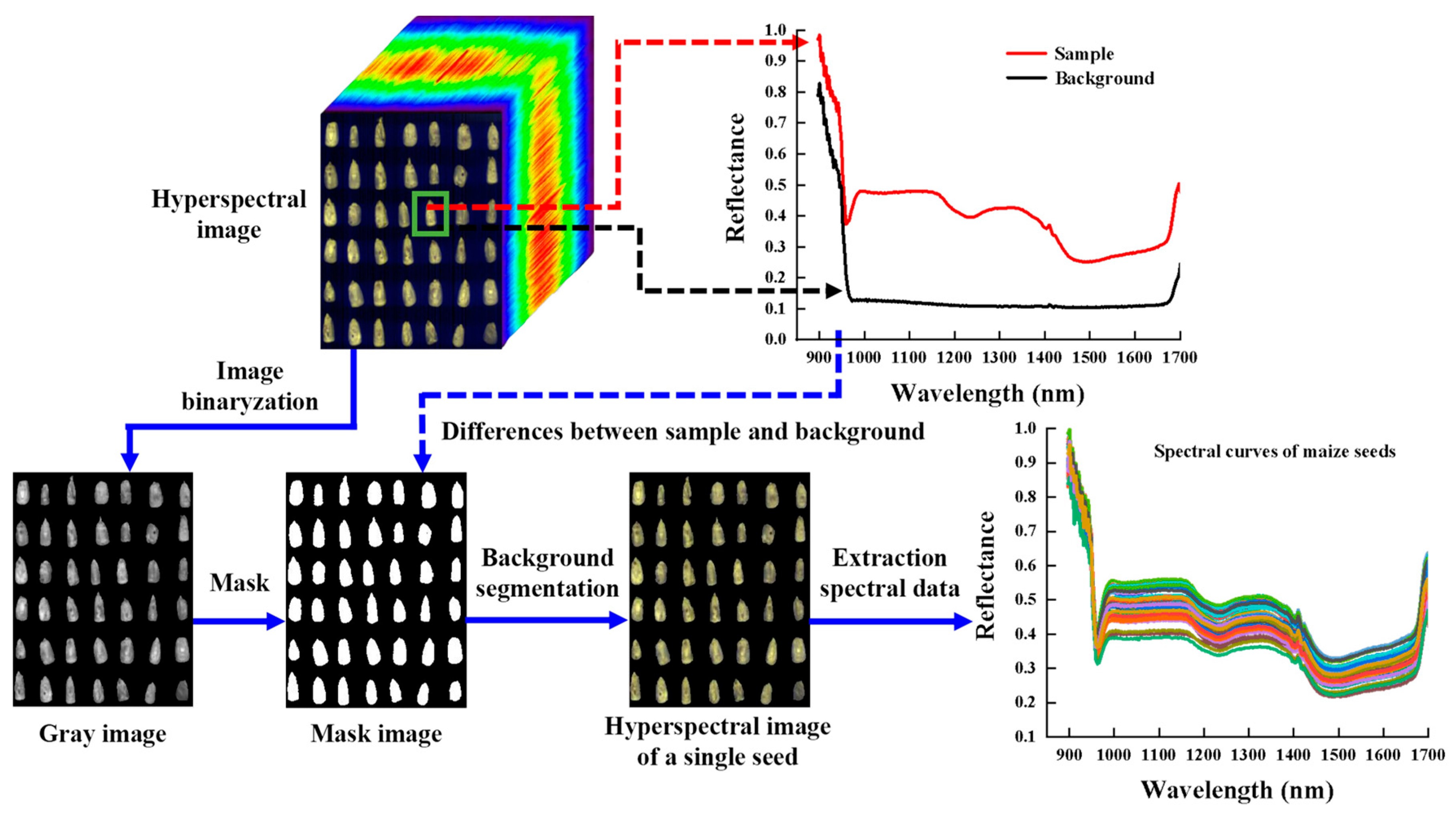
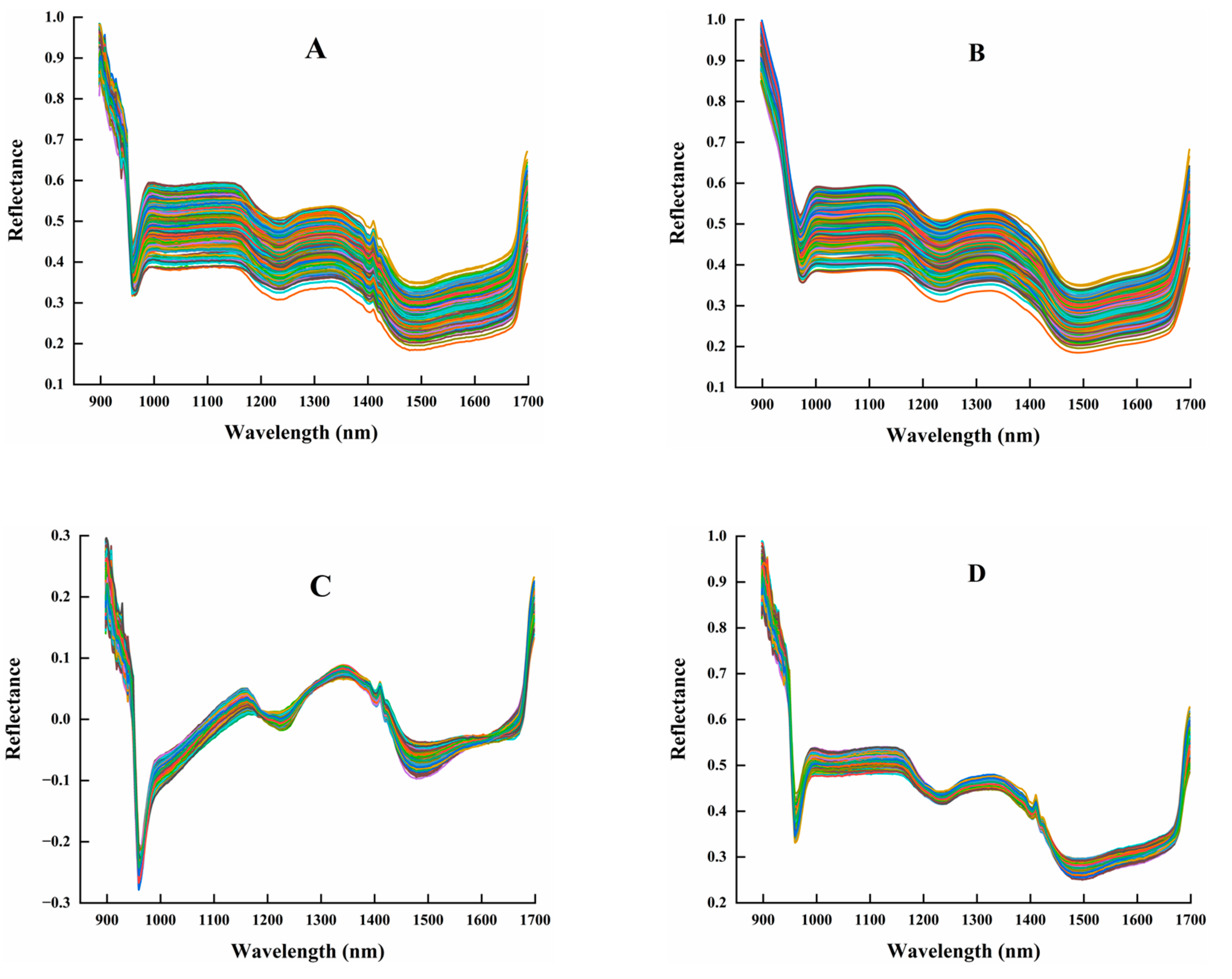
2.2. Spectral Data Extraction and Preprocessing
2.3. Traditional Feature Selection and Machine Learning Methods
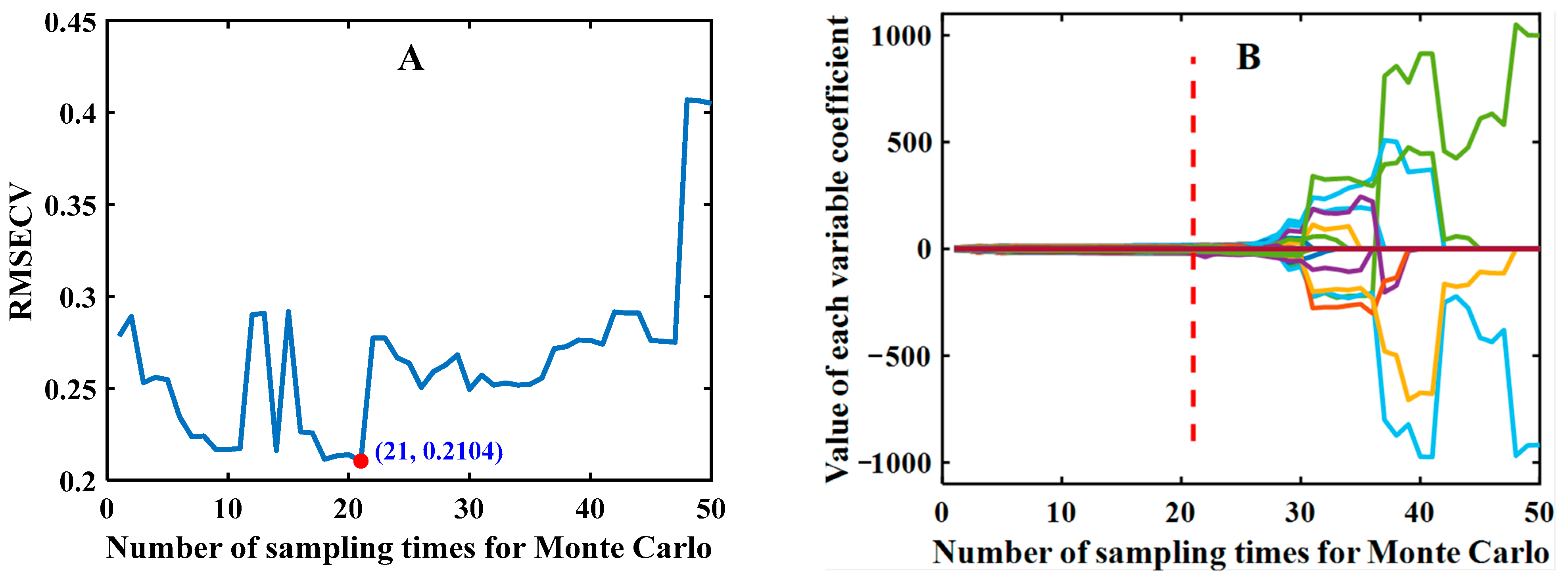
2.3.1. Feature Selection Method
2.3.2. Machine Learning Method
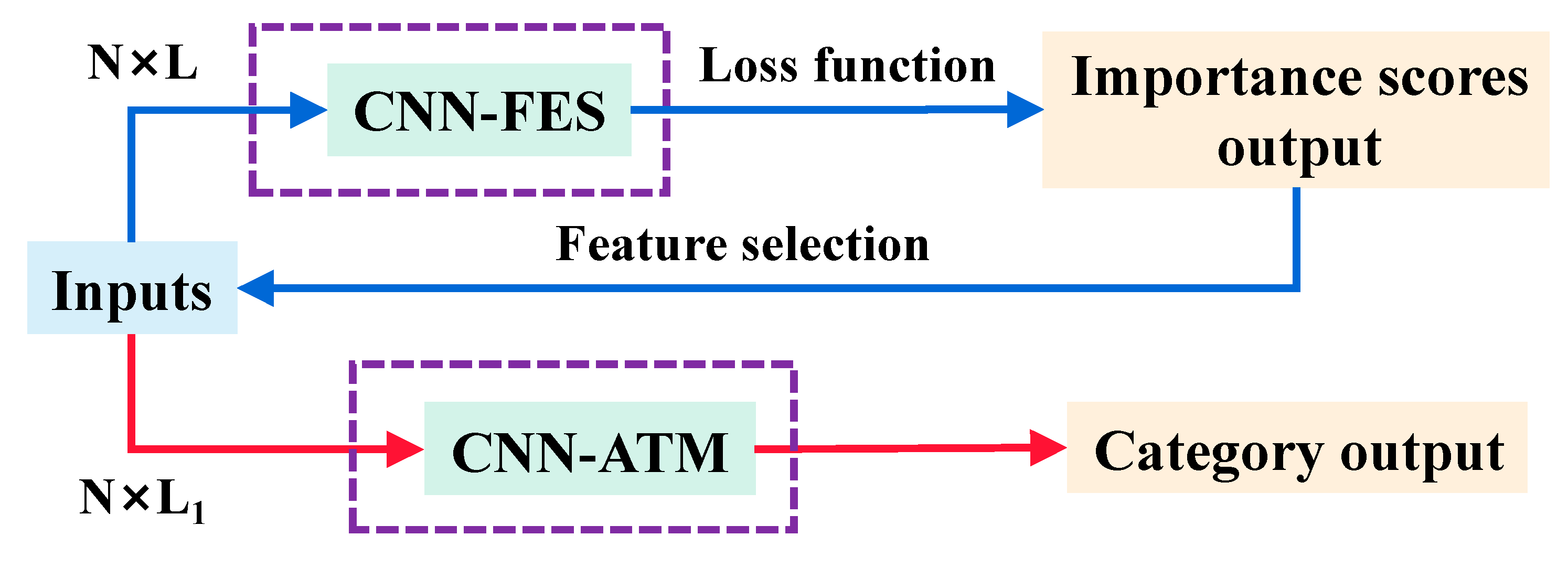
2.4. Convolutional Neural Network Architecture for Feature Selection and Classification
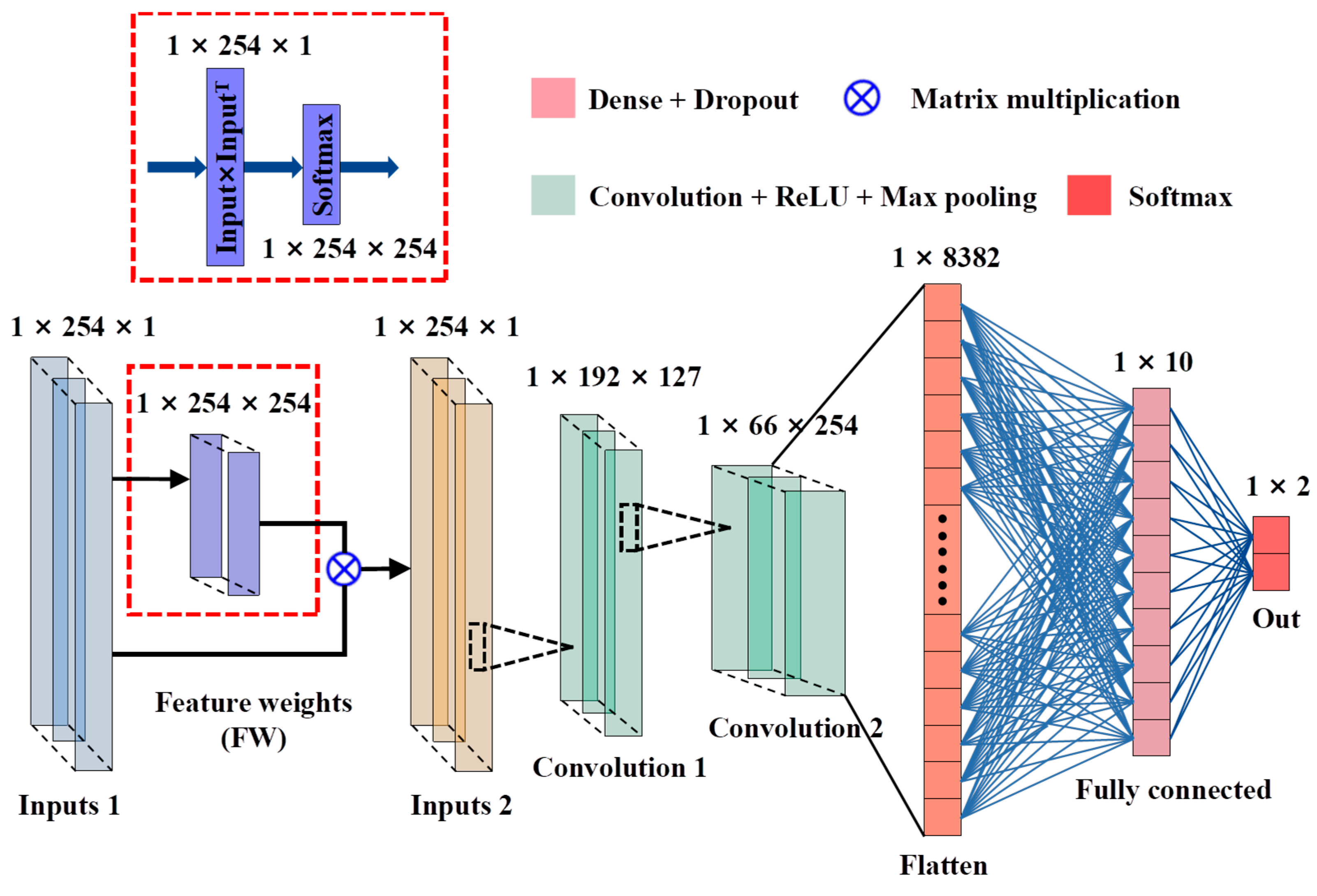
2.4.1. CNN Architecture Based on the Feature Selection Mechanism
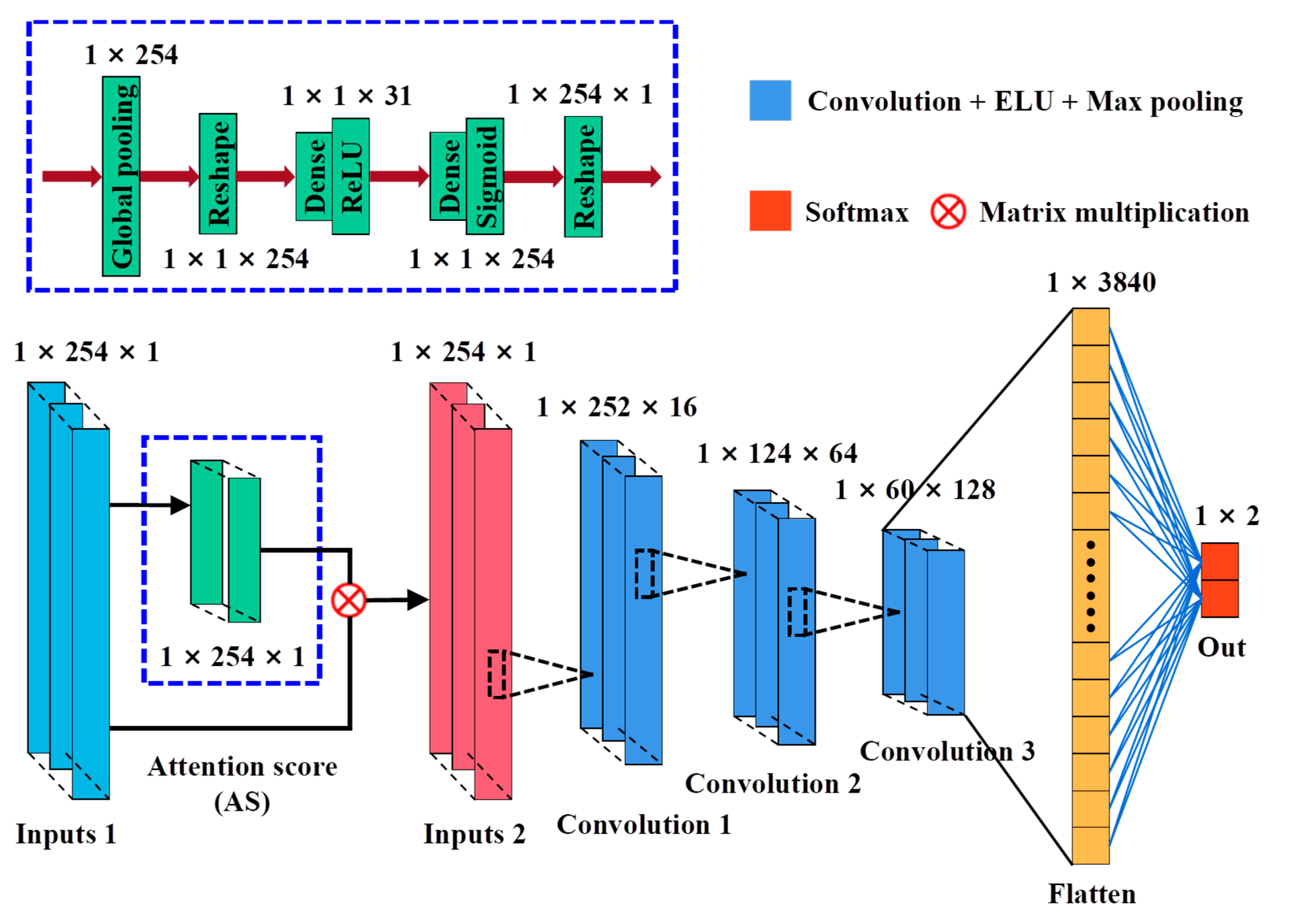
2.4.2. CNN Architecture Based on Attention Classification Mechanism
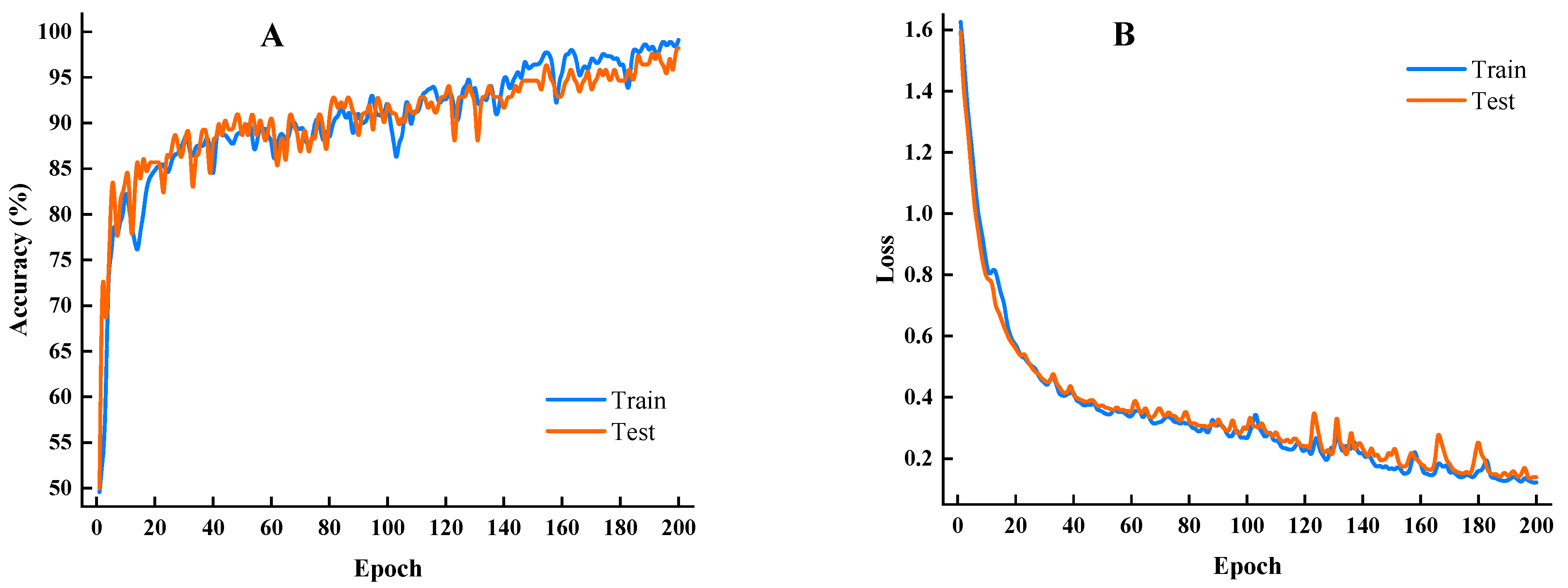
2.5. Model Training Process and Evaluation Metric
3. Results and Discussion
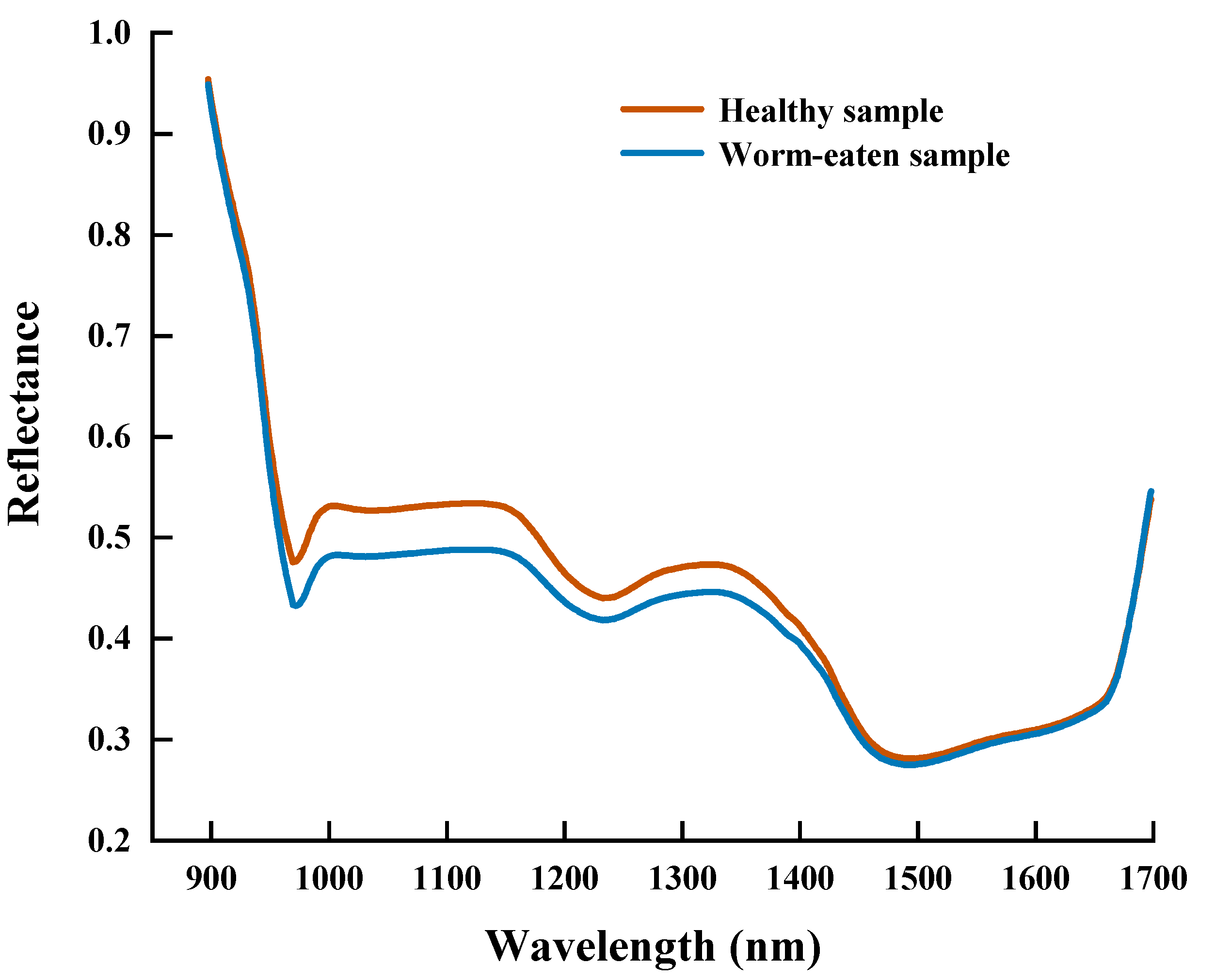
3.1. Spectral Data Analysis
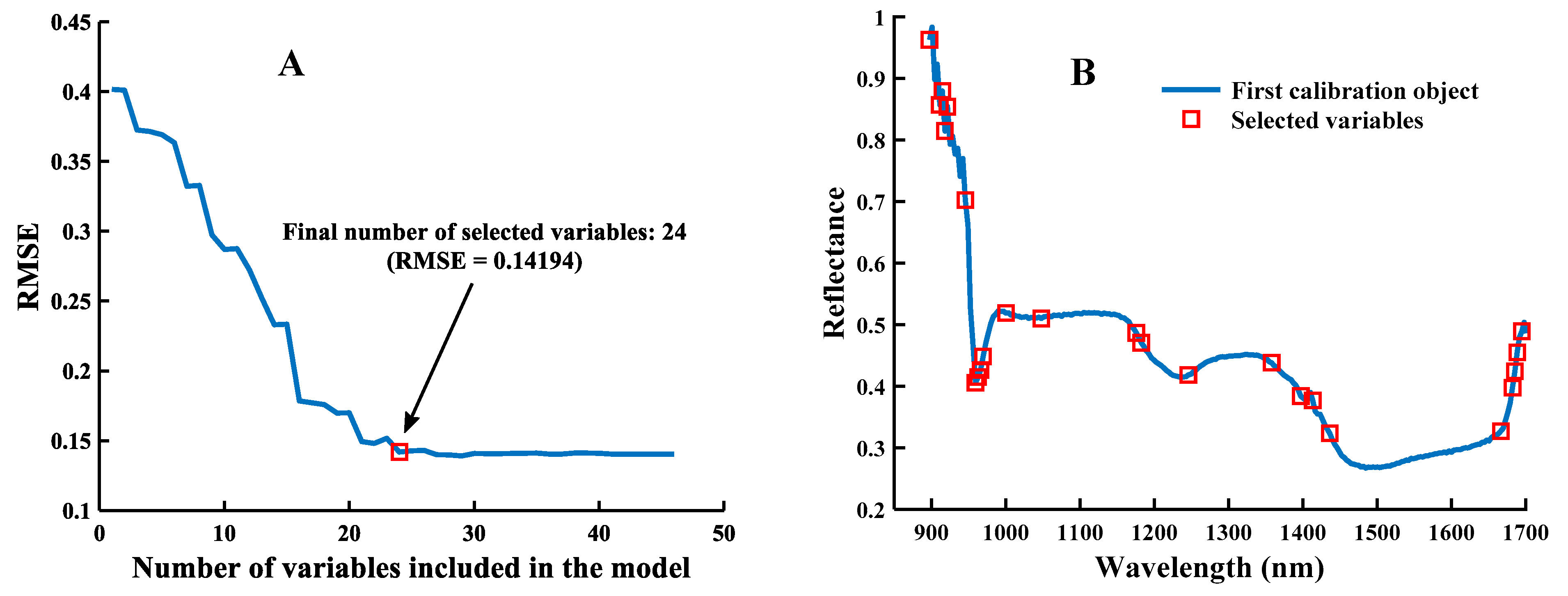
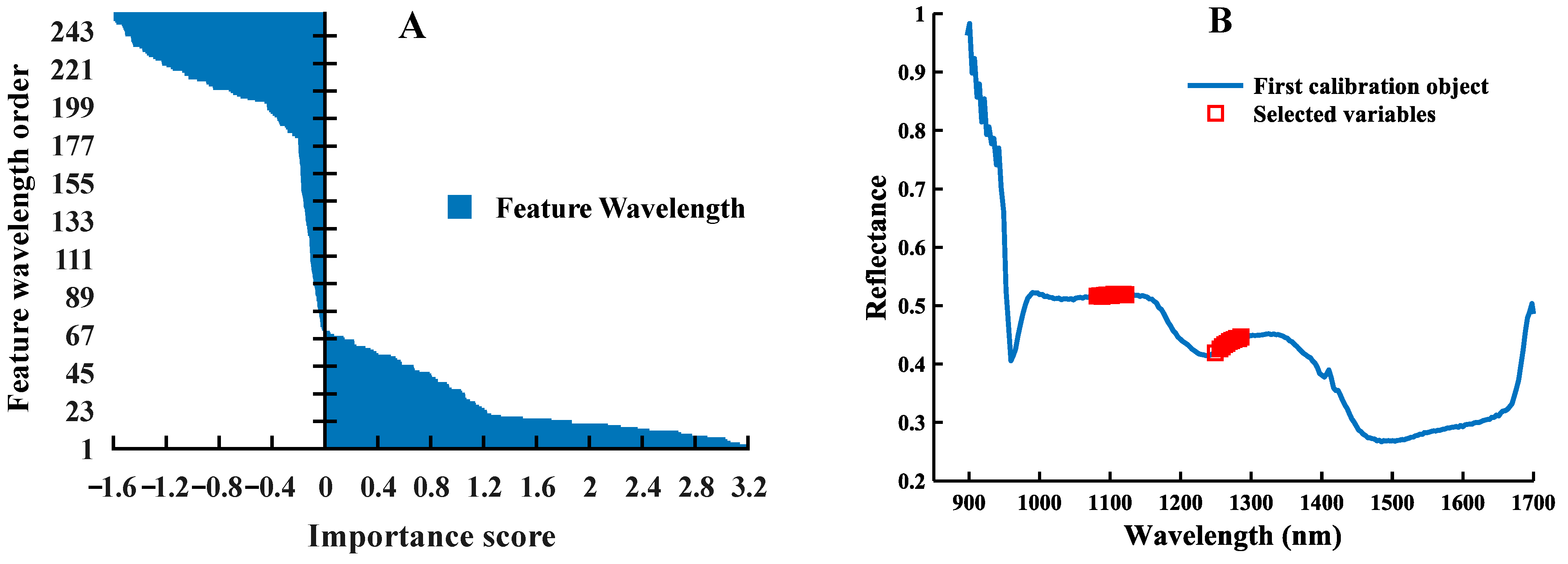
3.2. Results of Feature Wavelength Selection
3.3. Analysis of Modeling Results
3.3.1. Detection Results Based on Full Wavelength
3.3.2. Detection Results Based on Feature Wavelength
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, Z.; Fan, S.; Wu, J.; Zhang, C.; Xu, F.; Yang, X.; Li, J. Application of Long-Wave near Infrared Hyperspectral Imaging for Determination of Moisture Content of Single Maize Seed. Spectrochim. Acta—Part A Mol. Biomol. Spectrosc. 2021, 254, 119666. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Tian, X.; Fan, S.; Zhang, C.; Li, J. Maturity Determination of Single Maize Seed by Using Near-Infrared Hyperspectral Imaging Coupled with Comparative Analysis of Multiple Classification Models. Infrared Phys. Technol. 2021, 112, 103596. [Google Scholar] [CrossRef]
- Wang, L.; Liu, J.; Zhang, J.; Wang, J.; Fan, X. Corn Seed Defect Detection Based on Watershed Algorithm and Two-Pathway Convolutional Neural Networks. Front. Plant Sci. 2022, 13, 730190. [Google Scholar] [CrossRef] [PubMed]
- Yu, L.; Liu, W.; Li, W.; Qin, H.; Xu, J.; Zuo, M. Non-Destructive Identification of Maize Haploid Seeds Using Nonlinear Analysis Method Based on Their near-Infrared Spectra. Biosyst. Eng. 2018, 172, 144–153. [Google Scholar] [CrossRef]
- Yang, G.; Wang, Q.; Liu, C.; Wang, X.; Fan, S.; Huang, W. Rapid and Visual Detection of the Main Chemical Compositions in Maize Seeds Based on Raman Hyperspectral Imaging. Spectrochim. Acta—Part A Mol. Biomol. Spectrosc. 2018, 200, 186–194. [Google Scholar] [CrossRef]
- Elmasry, G.; Mandour, N.; Al-Rejaie, S.; Belin, E.; Rousseau, D. Recent Applications of Multispectral Imaging in Seed Phenotyping and Quality Monitoring—An Overview. Sensors 2019, 19, 1090. [Google Scholar] [CrossRef] [Green Version]
- Zhang, C.; Zhao, Y.; Yan, T.; Bai, X.; Xiao, Q.; Gao, P.; Li, M.; Huang, W.; Bao, Y.; He, Y.; et al. Application of Near-Infrared Hyperspectral Imaging for Variety Identification of Coated Maize Kernels with Deep Learning. Infrared Phys. Technol. 2020, 111, 103550. [Google Scholar] [CrossRef]
- Feng, L.; Zhu, S.; Liu, F.; He, Y.; Bao, Y.; Zhang, C. Hyperspectral Imaging for Seed Quality and Safety Inspection: A Review. Plant Methods 2019, 15, 91. [Google Scholar] [CrossRef] [Green Version]
- Sellami, A.; Tabbone, S. Deep Neural Networks-Based Relevant Latent Representation Learning for Hyperspectral Image Classification. Pattern Recognit. 2022, 121, 108224. [Google Scholar] [CrossRef]
- Alimohammadi, F.; Rasekh, M.; Afkari Sayyah, A.H.; Abbaspour-Gilandeh, Y.; Karami, H.; Rasooli Sharabiani, V.; Fioravanti, A.; Gancarz, M.; Findura, P.; Kwaśniewski, D. Hyperspectral Imaging Coupled with Multivariate Analysis and Artificial Intelligenceto the Classification of Maize Kernels. Int. Agrophys. 2022, 36, 83–91. [Google Scholar] [CrossRef]
- Zhang, X.; Liu, F.; He, Y.; Li, X. Application of Hyperspectral Imaging and Chemometric Calibrations for Variety Discrimination of Maize Seeds. Sensors 2012, 12, 17234–17246. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Zeng, S.; Wu, G.; Li, H.; Chen, F. Rice Seed Purity Identification Technology Using Hyperspectral Image with Lasso Logistic Regression Model. Sensors 2021, 21, 4384. [Google Scholar] [CrossRef] [PubMed]
- Cui, H.; Cheng, Z.; Li, P.; Miao, A. Prediction of Sweet Corn Seed Germination Based on Hyperspectral Image Technology and Multivariate Data Regression. Sensors 2020, 20, 4744. [Google Scholar] [CrossRef] [PubMed]
- Huang, L.; Li, T.; Ding, C.; Zhao, J.; Zhang, D.; Yang, G. Diagnosis of the Severity of Fusarium Head Blight of Wheat Ears on the Basis of Image and Spectral Feature Fusion. Sensors 2020, 20, 2887. [Google Scholar] [CrossRef]
- Nagasubramanian, K.; Jones, S.; Sarkar, S.; Singh, A.K.; Singh, A.; Ganapathysubramanian, B. Hyperspectral Band Selection Using Genetic Algorithm and Support Vector Machines for Early Identification of Charcoal Rot Disease in Soybean Stems. Plant Methods 2018, 14, 86. [Google Scholar] [CrossRef] [Green Version]
- Pang, L.; Wang, J.; Men, S.; Yan, L.; Xiao, J. Hyperspectral Imaging Coupled with Multivariate Methods for Seed Vitality Estimation and Forecast for Quercus Variabilis. Spectrochim. Acta—Part A Mol. Biomol. Spectrosc. 2021, 245, 118888. [Google Scholar] [CrossRef]
- Song, D.; Gao, D.; Sun, H.; Qiao, L.; Zhao, R.; Tang, W.; Li, M. Chlorophyll Content Estimation Based on Cascade Spectral Optimizations of Interval and Wavelength Characteristics. Comput. Electron. Agric. 2021, 189, 106413. [Google Scholar] [CrossRef]
- Zhang, L.; Sun, H.; Rao, Z.; Ji, H. Non-Destructive Identification of Slightly Sprouted Wheat Kernels Using Hyperspectral Data on Both Sides of Wheat Kernels. Biosyst. Eng. 2020, 200, 188–199. [Google Scholar] [CrossRef]
- Zheng, Z.; Liu, Y.; He, M.; Chen, D.; Sun, L.; Zhu, F. Effective Band Selection of Hyperspectral Image by an Attention Mechanism-Based Convolutional Network. RSC Adv. 2022, 12, 8750–8759. [Google Scholar] [CrossRef]
- Yuan, D.; Jiang, J.; Gong, Z.; Nie, C.; Sun, Y. Moldy Peanuts Identification Based on Hyperspectral Images and Point-Centered Convolutional Neural Network Combined with Embedded Feature Selection. Comput. Electron. Agric. 2022, 197, 106963. [Google Scholar] [CrossRef]
- Sharma, A.; Lysenko, A.; Boroevich, K.A.; Vans, E.; Tsunoda, T. DeepFeature: Feature Selection in Nonimage Data Using Convolutional Neural Network. Brief. Bioinform. 2021, 22, bbab297. [Google Scholar] [CrossRef] [PubMed]
- Gao, T.; Chandran, A.K.N.; Paul, P.; Walia, H.; Yu, H. Hyperseed: An End-to-End Method to Process Hyperspectral Images of Seeds. Sensors 2021, 21, 8184. [Google Scholar] [CrossRef] [PubMed]
- Yu, Z.; Fang, H.; Zhangjin, Q.; Mi, C.; Feng, X.; He, Y. Hyperspectral Imaging Technology Combined with Deep Learning for Hybrid Okra Seed Identification. Biosyst. Eng. 2021, 212, 46–61. [Google Scholar] [CrossRef]
- Pang, L.; Wang, L.; Yuan, P.; Yan, L.; Yang, Q.; Xiao, J. Feasibility Study on Identifying Seed Viability of Sophora Japonica with Optimized Deep Neural Network and Hyperspectral Imaging. Comput. Electron. Agric. 2021, 190, 106426. [Google Scholar] [CrossRef]
- Gao, J.; Zhao, L.; Li, J.; Deng, L.; Ni, J.; Han, Z. Aflatoxin Rapid Detection Based on Hyperspectral with 1D-Convolution Neural Network in the Pixel Level. Food Chem. 2021, 360, 129968. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Zhang, L.; Sun, H.; Rao, Z.; Ji, H. Discrimination of Unsound Wheat Kernels Based on Deep Convolutional Generative Adversarial Network and Near-Infrared Hyperspectral Imaging Technology. Spectrochim. Acta—Part A Mol. Biomol. Spectrosc. 2022, 268, 120722. [Google Scholar] [CrossRef]
- Li, Z.; Zhou, G.; Song, Q. A Temporal Group Attention Approach for Multitemporal Multisensor Crop Classification. Infrared Phys. Technol. 2020, 105, 103152. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, Z.; Feng, L.; Ma, Y.; Du, Q. A New Attention-Based CNN Approach for Crop Mapping Using Time Series Sentinel-2 Images. Comput. Electron. Agric. 2021, 184, 106090. [Google Scholar] [CrossRef]
- Eshkabilov, S.; Lee, A.; Sun, X.; Lee, C.W.; Simsek, H. Hyperspectral Imaging Techniques for Rapid Detection of Nutrient Content of Hydroponically Grown Lettuce Cultivars. Comput. Electron. Agric. 2021, 181, 105968. [Google Scholar] [CrossRef]
- Yang, J.; Sun, L.; Xing, W.; Feng, G.; Bai, H.; Wang, J. Hyperspectral Prediction of Sugarbeet Seed Germination Based on Gauss Kernel SVM. Spectrochim. Acta—Part A Mol. Biomol. Spectrosc. 2021, 253, 119585. [Google Scholar] [CrossRef]
- Zhang, L.; Sun, H.; Rao, Z.; Ji, H. Hyperspectral Imaging Technology Combined with Deep Forest Model to Identify Frost-Damaged Rice Seeds. Spectrochim. Acta—Part A Mol. Biomol. Spectrosc. 2020, 229, 117973. [Google Scholar] [CrossRef] [PubMed]
- Araújo, M.C.U.; Saldanha, T.C.B.; Galvão, R.K.H.; Yoneyama, T.; Chame, H.C.; Visani, V. The Successive Projections Algorithm for Variable Selection in Spectroscopic Multicomponent Analysis. Chemom. Intell. Lab. Syst. 2001, 57, 65–73. [Google Scholar] [CrossRef]
- Sun, J.; Zhou, X.; Hu, Y.; Wu, X.; Zhang, X.; Wang, P. Visualizing Distribution of Moisture Content in Tea Leaves Using Optimization Algorithms and NIR Hyperspectral Imaging. Comput. Electron. Agric. 2019, 160, 153–159. [Google Scholar] [CrossRef]
- Zhang, Y.; Gao, J.; Cen, H.; Lu, Y.; Yu, X.; He, Y.; Pieters, J.G. Automated Spectral Feature Extraction from Hyperspectral Images to Differentiate Weedy Rice and Barnyard Grass from a Rice Crop. Comput. Electron. Agric. 2019, 159, 42–49. [Google Scholar] [CrossRef]
- Li, H.; Liang, Y.; Xu, Q.; Cao, D. Key Wavelengths Screening Using Competitive Adaptive Reweighted Sampling Method for Multivariate Calibration. Anal. Chim. Acta 2009, 648, 77–84. [Google Scholar] [CrossRef] [PubMed]
- Feng, Z.-H.; Wang, L.-Y.; Yang, Z.-Q.; Zhang, Y.-Y.; Li, X.; Song, L.; He, L.; Duan, J.-Z.; Feng, W. Hyperspectral Monitoring of Powdery Mildew Disease Severity in Wheat Based on Machine Learning. Front. Plant Sci. 2022, 13, 828454. [Google Scholar] [CrossRef] [PubMed]
- Long, Y.; Huang, W.; Wang, Q.; Fan, S.; Tian, X. Integration of Textural and Spectral Features of Raman Hyperspectral Imaging for Quantitative Determination of a Single Maize Kernel Mildew Coupled with Chemometrics. Food Chem. 2022, 372, 131246. [Google Scholar] [CrossRef] [PubMed]
- Saeidan, A.; Khojastehpour, M.; Golzarian, M.R.; Mooenfard, M.; Khan, H.A. Detection of Foreign Materials in Cocoa Beans by Hyperspectral Imaging Technology. Food Control 2021, 129, 108242. [Google Scholar] [CrossRef]
- Zhang, L.; Sun, H.; Li, H.; Rao, Z.; Ji, H. Identification of Rice-Weevil (Sitophilus oryzae L.) Damaged Wheat Kernels Using Multi-Angle NIR Hyperspectral Data. J. Cereal Sci. 2021, 101, 103313. [Google Scholar] [CrossRef]
- Arun Kumar, M.; Gopal, M. Least Squares Twin Support Vector Machines for Pattern Classification. Expert Syst. Appl. 2009, 36, 7535–7543. [Google Scholar] [CrossRef]
- Zhang, J.; Yang, Y.; Feng, X.; Xu, H.; Chen, J.; He, Y. Identification of Bacterial Blight Resistant Rice Seeds Using Terahertz Imaging and Hyperspectral Imaging Combined with Convolutional Neural Network. Front. Plant Sci. 2020, 11, 821. [Google Scholar] [CrossRef] [PubMed]
- Svetnik, V.; Liaw, A.; Tong, C.; Christopher Culberson, J.; Sheridan, R.P.; Feuston, B.P. Random Forest: A Classification and Regression Tool for Compound Classification and QSAR Modeling. J. Chem. Inf. Comput. Sci. 2003, 43, 1947–1958. [Google Scholar] [CrossRef] [PubMed]
- Zhou, L.; Zhang, C.; Taha, M.F.; Wei, X.; He, Y.; Qiu, Z.; Liu, Y. Wheat Kernel Variety Identification Based on a Large Near-Infrared Spectral Dataset and a Novel Deep Learning-Based Feature Selection Method. Front. Plant Sci. 2020, 11, 575810. [Google Scholar] [CrossRef] [PubMed]
- Altmann, A.; Toloşi, L.; Sander, O.; Lengauer, T. Permutation Importance: A Corrected Feature Importance Measure. Bioinformatics 2010, 26, 1340–1347. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Peng, Y.; Qiao, X.; Zhuang, Q. Discriminant Analysis and Comparison of Corn Seed Vigor Based on Multiband Spectrum. Comput. Electron. Agric. 2021, 190, 106444. [Google Scholar] [CrossRef]
- Ma, T.; Tsuchikawa, S.; Inagaki, T. Rapid and Non-Destructive Seed Viability Prediction Using near-Infrared Hyperspectral Imaging Coupled with a Deep Learning Approach. Comput. Electron. Agric. 2020, 177, 105683. [Google Scholar] [CrossRef]
- Gente, R.; Busch, S.F.; Stubling, E.-M.; Schneider, L.M.; Hirschmann, C.B.; Balzer, J.C.; Koch, M. Quality Control of Sugar Beet Seeds with THz Time-Domain Spectroscopy. IEEE Trans. THz Sci. Technol. 2016, 6, 754–756. [Google Scholar] [CrossRef]
- Sendin, K.; Manley, M.; Williams, P.J. Classification of White Maize Defects with Multispectral Imaging. Food Chem. 2018, 243, 311–318. [Google Scholar] [CrossRef]
- Ge, H.; Jiang, Y.; Zhang, Y. THz Spectroscopic Investigation of Wheat-Quality by Using Multi-Source Data Fusion. Sensors 2018, 18, 3945. [Google Scholar] [CrossRef]
- Sanchez, L.; Farber, C.; Lei, J.; Zhu-Salzman, K.; Kurouski, D. Noninvasive and Nondestructive Detection of Cowpea Bruchid within Cowpea Seeds with a Hand-Held Raman Spectrometer. Anal. Chem. 2019, 91, 1733–1737. [Google Scholar] [CrossRef] [PubMed]
- Sendin, K.; Manley, M.; Marini, F.; Williams, P.J. Hierarchical Classification Pathway for White Maize, Defect and Foreign Material Classification Using Spectral Imaging. Microchem. J. 2021, 162, 105824. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Algorithm (Number) | Feature Wavelengths (nm) |
|---|---|---|
| DE | SPA (23) | 911, 922, 925, 935, 959, 970, 980, 987, 1000, 1142, 1183, 1345, 1397, 1413, 1436, 1657, 1682, 1685, 1689, 1692, 1695, 1698, 1701 |
| CARS (34) | 956, 1256, 1259, 1262, 1269, 1272, 1276, 1282, 1286, 1292, 1295, 1299, 1302, 1305, 1309, 1312, 1315, 1318, 1322, 1328, 1355, 1358, 1361, 1364, 1368, 1371, 1374, 1378, 1381, 1423, 1619, 1644, 239, 1666 | |
| CNN-FES (24) | 1239, 1243, 1249, 1252, 1256, 1259, 1262, 1266, 1269, 1272, 1276, 1279, 1282, 1286, 1289, 1292, 1295, 1299, 1302, 1305, 1312, 1368, 1381, 1407 | |
| MSC | SPA (24) | 897, 911, 915, 918, 922, 946, 959, 963, 966, 970, 1000, 1048, 1176, 1183, 1246, 1358, 1397, 1413, 1436, 1666, 1682, 1685, 1689, 1695 |
| CARS (29) | 980, 990, 1017, 1024, 1028, 1031, 1045, 1243, 1266, 1269, 1276, 1279, 1282, 1289, 1305, 1315, 1361, 1364, 1371, 1374, 1378, 1384, 1420, 1436, 1439, 1443, 1578, 1619, 1632 | |
| CNN-FES (24) | 897, 911, 915, 918, 922, 946, 959, 963, 966, 970, 1000, 1048, 1176, 1183, 1246, 1358, 1397, 1413, 1436, 1666, 1682, 1685, 1689, 1695 |
| Method | Model | Time (s) | ||||||
|---|---|---|---|---|---|---|---|---|
| Train | Test | Train | Test | Train | Test | |||
| DE | LDA | 100 | 97.50 | 100 | 96.55 | 100 | 98.39 | 1.36 |
| RF | 98.93 | 93.33 | 97.93 | 89.06 | 100 | 98.21 | 1.34 | |
| SVM | 98.21 | 96.67 | 97.24 | 93.55 | 99.26 | 100 | 1.38 | |
| CNN-ATM | 98.21 | 98.33 | 98.59 | 100 | 97.83 | 96.67 | 11.73 | |
| MSC | LDA | 100 | 95.00 | 100 | 93.33 | 100 | 96.67 | 1.37 |
| RF | 99.29 | 91.67 | 98.61 | 87.50 | 100 | 96.43 | 1.36 | |
| SVM | 95.00 | 95.83 | 92.11 | 93.44 | 98.44 | 98.31 | 1.35 | |
| CNN-ATM | 97.86 | 98.21 | 98.59 | 100 | 96.38 | 98.39 | 12.18 | |
| Method | Feature Select | Model | Time (s) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Train | Test | Train | Test | Train | Test | ||||
| DE | SPA | LDA | 99.28 | 100 | 100 | 100 | 98.55 | 100 | 1.38 |
| RF | 97.14 | 92.50 | 99.30 | 100 | 94.93 | 85.48 | 1.37 | ||
| SVM | 98.57 | 98.33 | 98.59 | 100 | 98.55 | 96.77 | 1.38 | ||
| CNN-ATM | 98.57 | 96.67 | 97.18 | 100 | 97.10 | 93.55 | 8.38 | ||
| CARS | LDA | 98.93 | 100 | 100 | 100 | 97.83 | 100 | 1.36 | |
| RF | 100 | 92.50 | 100 | 100 | 98.28 | 87.10 | 1.37 | ||
| SVM | 98.57 | 99.17 | 98.59 | 100 | 98.55 | 98.39 | 1.35 | ||
| CNN-ATM | 92.14 | 95.00 | 89.44 | 94.83 | 94.93 | 95.16 | 9.55 | ||
| CNN-FES | LDA | 99.64 | 100 | 100 | 100 | 99.28 | 100 | 1.37 | |
| RF | 100 | 91.67 | 100 | 91.38 | 100 | 89.06 | 1.35 | ||
| SVM | 95.36 | 97.50 | 95.07 | 100 | 95.65 | 95.16 | 1.34 | ||
| CNN-ATM | 93.57 | 97.48 | 98.55 | 100 | 91.30 | 93.55 | 8.36 | ||
| MSC | SPA | LDA | 97.50 | 99.17 | 100 | 100 | 94.93 | 98.39 | 1.34 |
| RF | 98.93 | 89.17 | 99.30 | 93.10 | 98.55 | 85.48 | 1.38 | ||
| SVM | 96.43 | 97.50 | 99.30 | 100 | 93.48 | 95.16 | 1.38 | ||
| CNN-ATM | 94.29 | 92.50 | 98.59 | 96.55 | 89.86 | 88.71 | 9.17 | ||
| CARS | LDA | 98.21 | 99.17 | 100 | 100 | 96.38 | 98.39 | 1.37 | |
| RF | 98.93 | 92.50 | 100 | 96.55 | 97.83 | 88.71 | 1.36 | ||
| SVM | 97.50 | 98.33 | 99.30 | 95.65 | 100 | 96.77 | 1.34 | ||
| CNN-ATM | 97.50 | 97.50 | 96.48 | 98.28 | 98.55 | 96.77 | 8.86 | ||
| CNN-FES | LDA | 98.93 | 99.17 | 100 | 100 | 97.83 | 98.39 | 1.36 | |
| RF | 100 | 90.00 | 100 | 93.10 | 100 | 87.10 | 1.36 | ||
| SVM | 91.79 | 94.17 | 94.37 | 94.83 | 89.13 | 93.55 | 1.37 | ||
| CNN-ATM | 98.21 | 97.50 | 100 | 98.28 | 96.38 | 96.77 | 8.50 | ||
| Agricultural Product Type | Device Type | Sample Size | Spectral Range | Accuracy | References |
|---|---|---|---|---|---|
| Sugar beet seed | Terahertz time-domain spectroscopy | 100 | 0.25–0.35 THz | 87.00% | [48] |
| Maize kernel | Multispectral imaging | 910 | 375–970 nm | 83.00% | [49] |
| Wheat kernel | Terahertz time-domain spectroscopy | 240 | 0.1–3.5 THz | 96.00% | [50] |
| Cowpea seed | Raman spectroscopy | 105 | 400–1800 nm | 93.70% | [51] |
| Maize kernel | Hyperspectral imaging | 240 | 953–2517 nm | 93.30% | [52] |
| Maize seed | Hyperspectral imaging | 400 | 900–1700 nm | 97.50% | This study |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, P.; Sun, W.; Xu, K.; Zhang, Y.; Tan, Q.; Qing, Y.; Yang, R. Identification of Defective Maize Seeds Using Hyperspectral Imaging Combined with Deep Learning. Foods 2023, 12, 144. https://doi.org/10.3390/foods12010144
Xu P, Sun W, Xu K, Zhang Y, Tan Q, Qing Y, Yang R. Identification of Defective Maize Seeds Using Hyperspectral Imaging Combined with Deep Learning. Foods. 2023; 12(1):144. https://doi.org/10.3390/foods12010144
Chicago/Turabian StyleXu, Peng, Wenbin Sun, Kang Xu, Yunpeng Zhang, Qian Tan, Yiren Qing, and Ranbing Yang. 2023. "Identification of Defective Maize Seeds Using Hyperspectral Imaging Combined with Deep Learning" Foods 12, no. 1: 144. https://doi.org/10.3390/foods12010144