Tensor Dictionary Learning with an Enhanced Sparsity Constraint for Sparse-View Spectral CT Reconstruction


Abstract
:1. Introduction
2. Fundamental Theory Methods
2.1. Tensor Dictionary Learning
2.2. TDL for Spectral CT Reconstruction
2.3. L0-Norm of the Image Gradient
3. Methods
3.1. Mathematical Model
3.2. Solution
| Algorithm 1 The l0-norm of image gradient algorithm |
| Input:B1m, B2m, γ1, γ2, τ1(0) = 2γ1, τ2(0) = 2γ2, τmax = 105, k1, k2 |
| for c = 1:C |
| while (τ1 ≤ τmax) |
| do |
| same as Equation (23); |
| Update B1r+1 same as Equation (24); |
| τ1 = k1τ1, r = r + 1 |
| end while |
| while (τ2 ≤ τmax) |
| do |
| using Equation (23); |
| Update B2r+1 using Equation (24); |
| τ2 = k2τ2, r = r + 1 |
| end while |
| B1m+1 = B1r, B2m+1 = B2r |
| end for |
| Output: Return intermediate result B1m+1, B2m+1 |
| Algorithm 2 The pseudocodes of the proposed algorithm |
| Input: parameters: η, ε, K, L, a, σ1, σ2. Initialization of X(0), |
| B← 0, T← 0; xprior reconstructing from broad-spectrum projection data |
| Part I: Dictionary training |
| Normalize the projection data; |
| Reconstruct image from normalized projection utilizing FBP; |
| Extract patches and train a global tensor dictionary D |
| Part II: Image reconstruction |
| while not satisfy the stopping criteria |
| do |
| Update based on Equation (17); |
| Update B1m+1, B2m+1 using Algorithm 1; |
| Update T1m+1, T2m+1 using Equations (15) and (16); |
| Update nm+1 based on Equation (8); |
| Update αm+1 using MOMP algorithm; |
| Positive constraint on ; |
| end while |
| Denormalize the image tensor. |
| Output: reconstructed image X |
4. Results
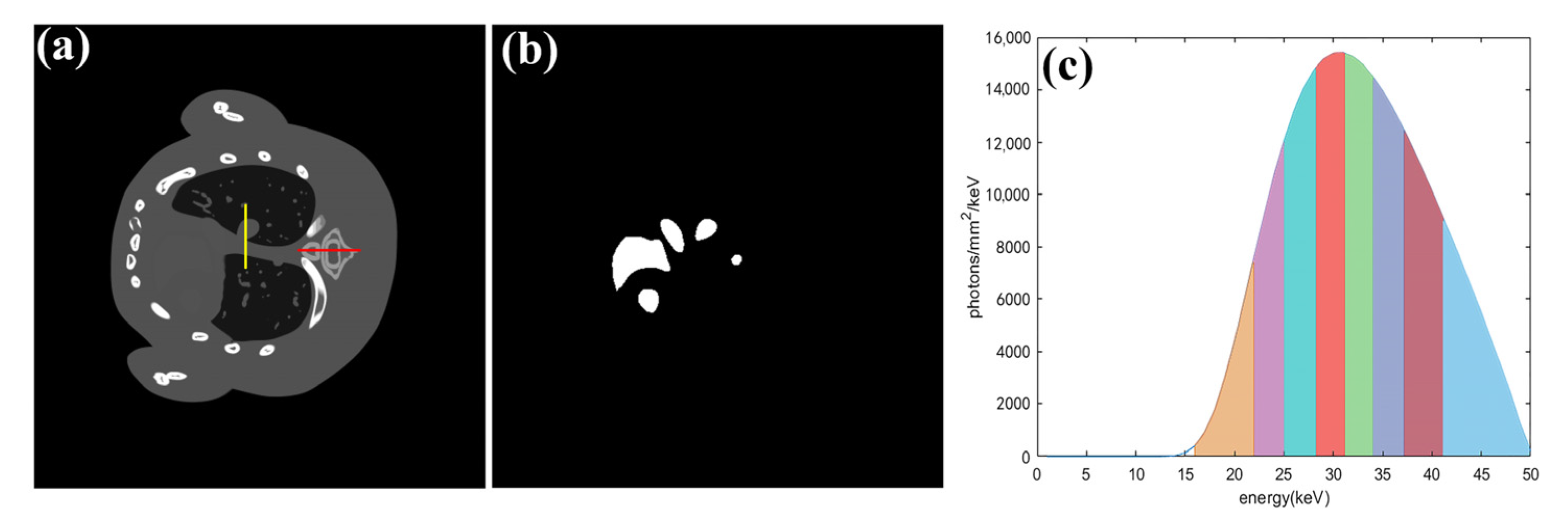
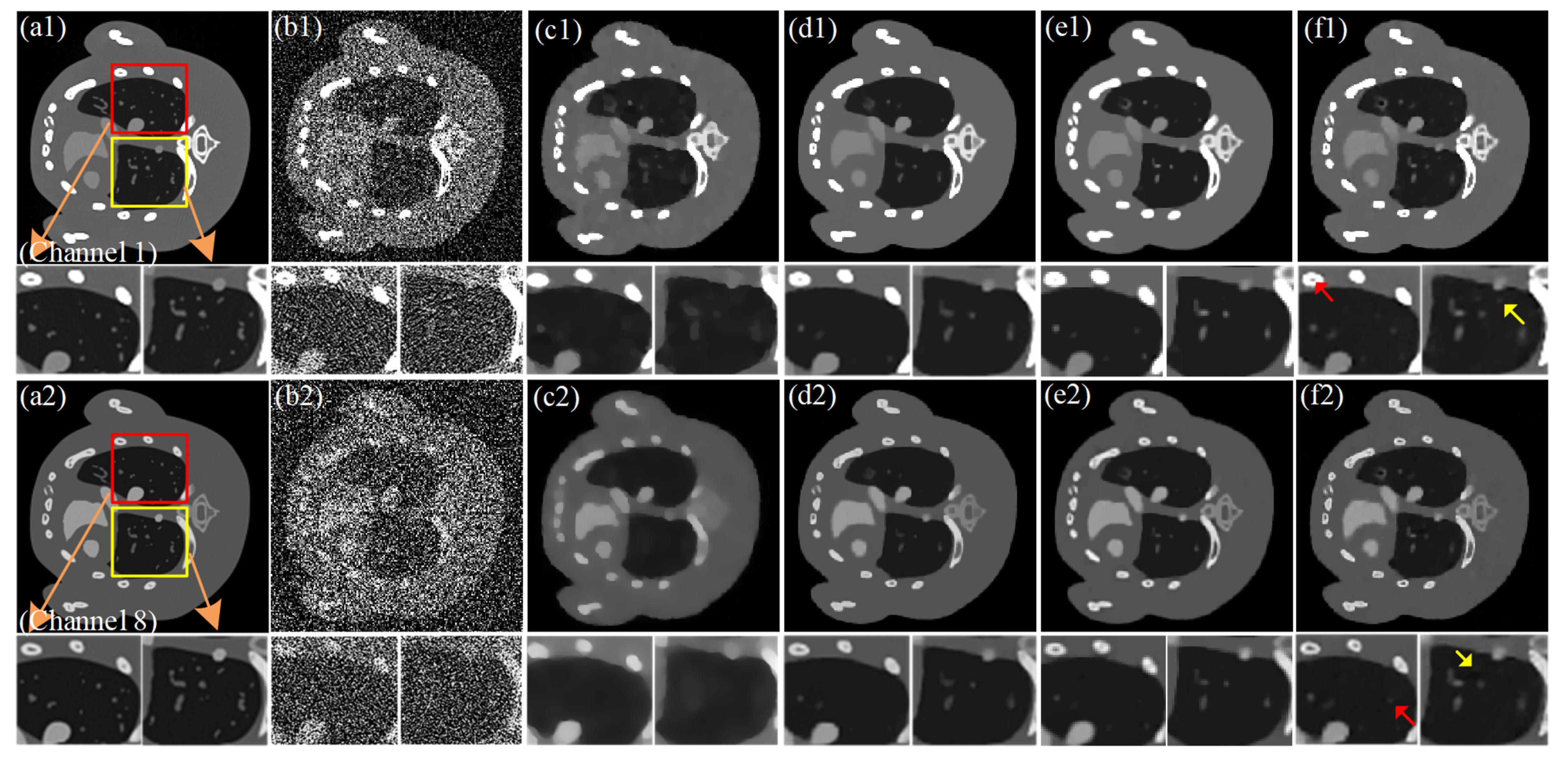
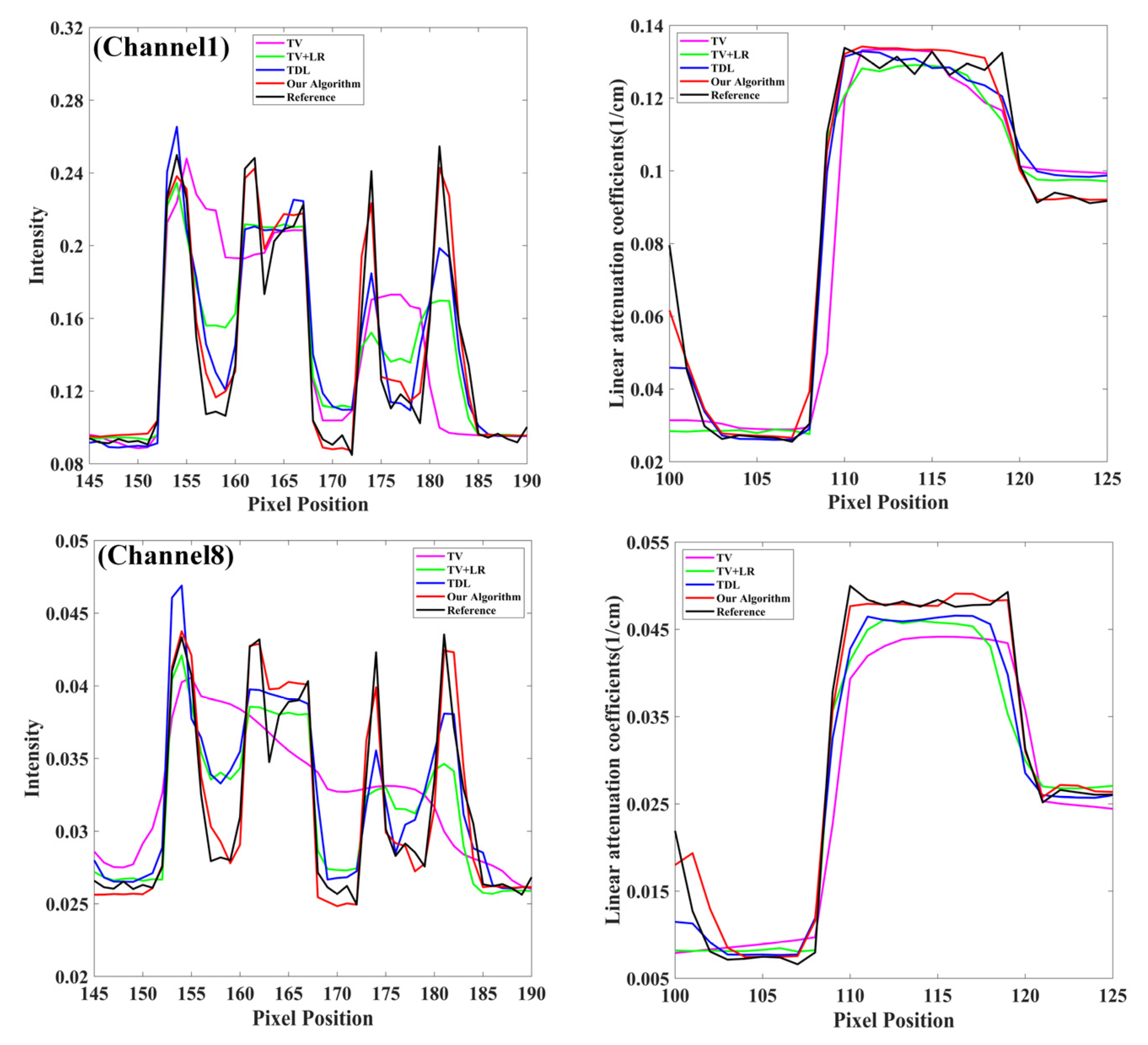
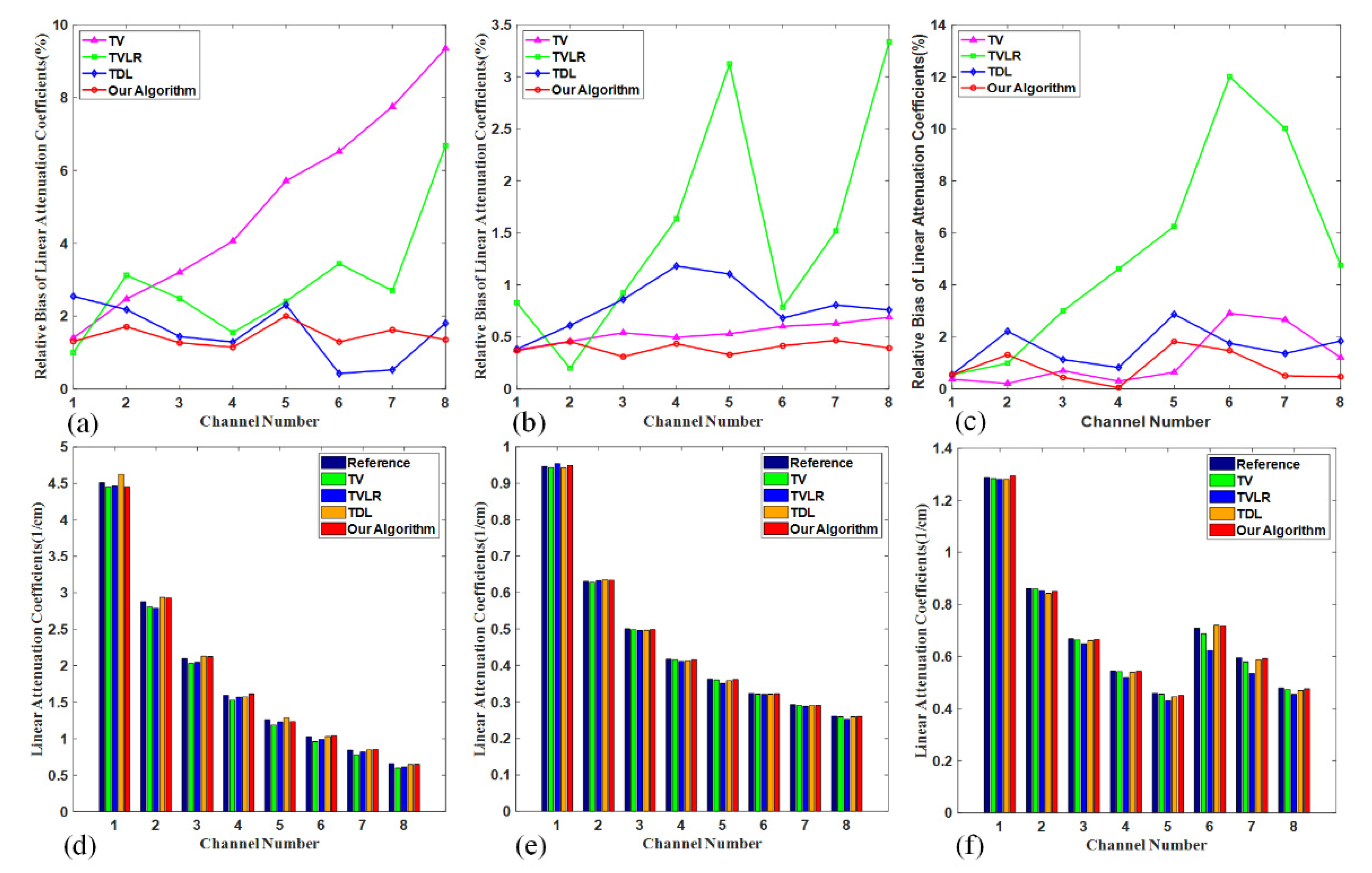
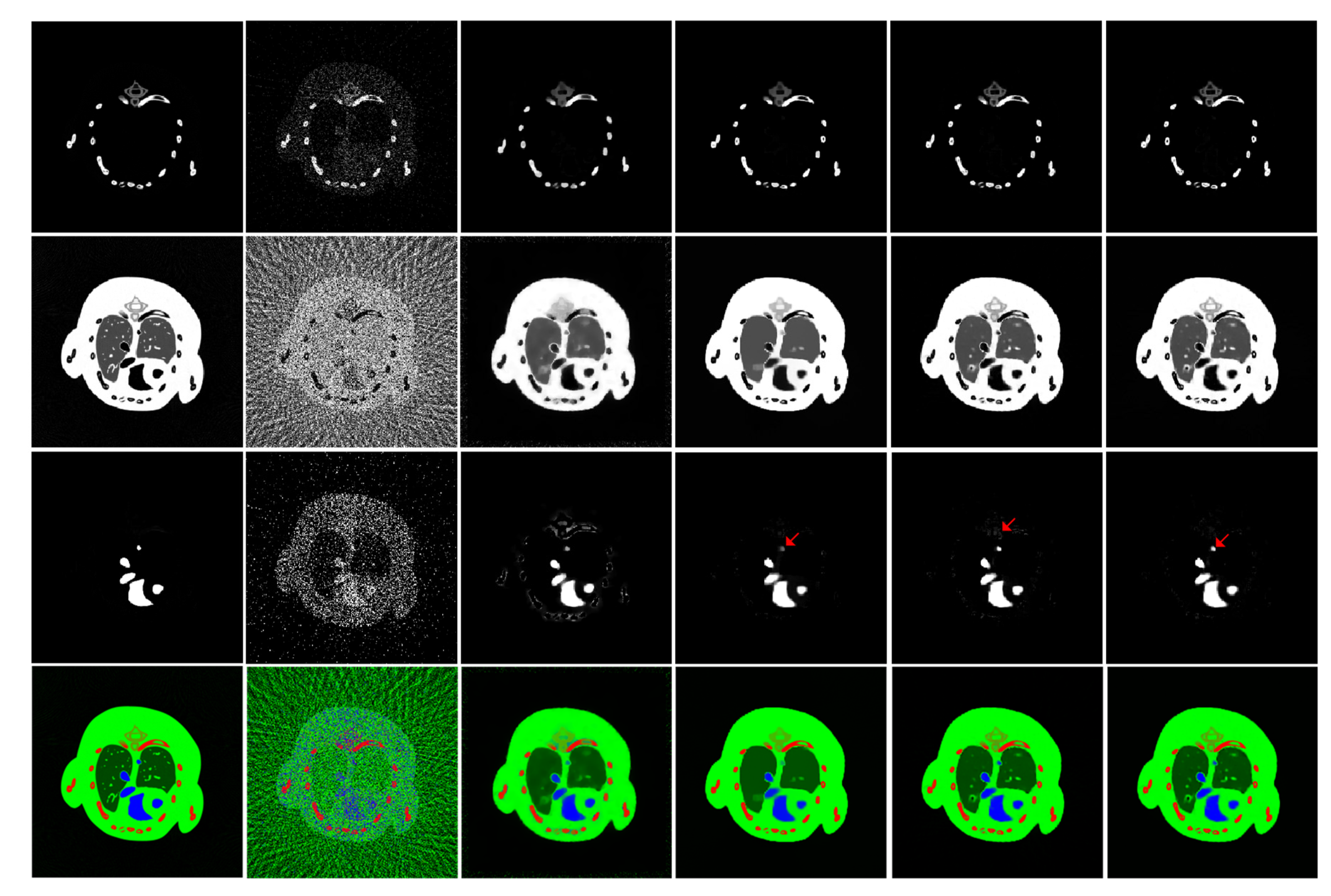
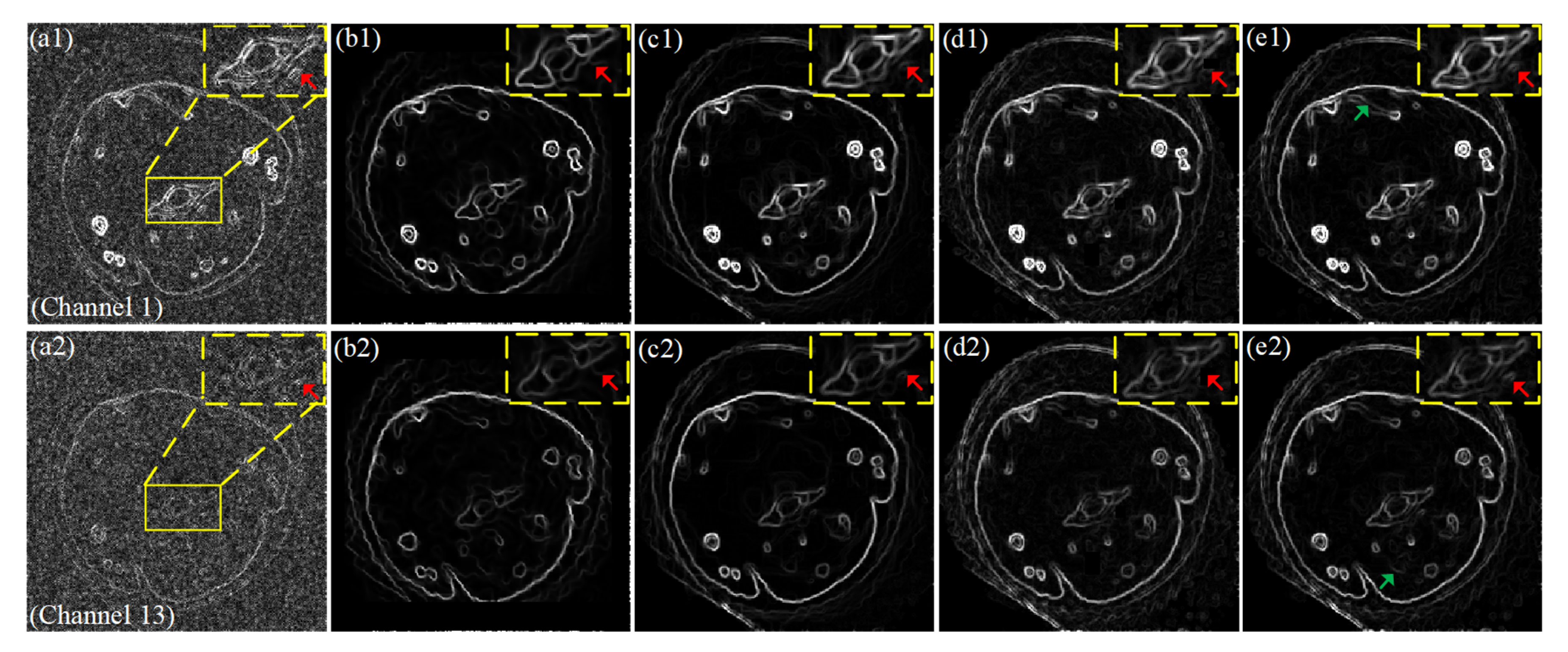
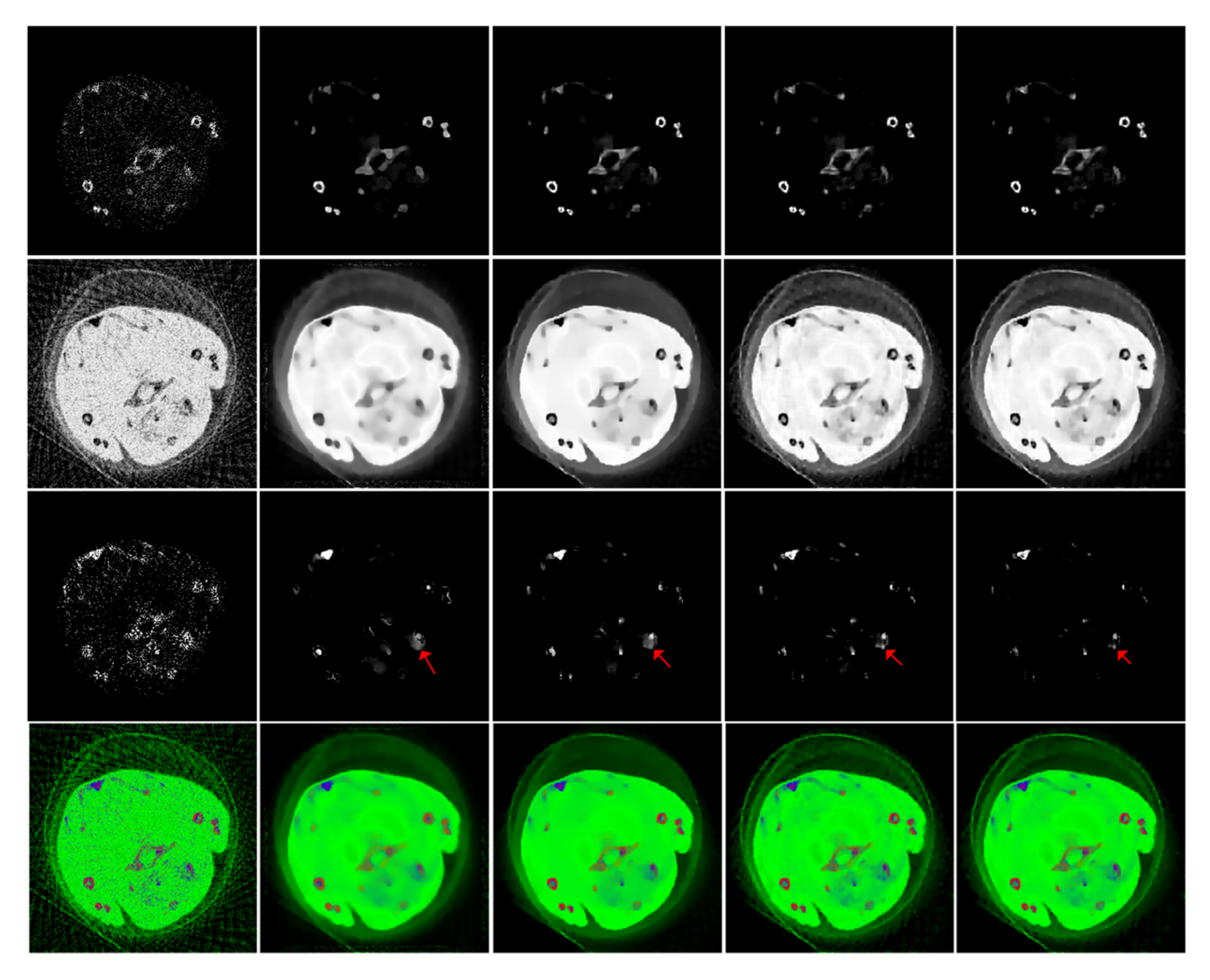
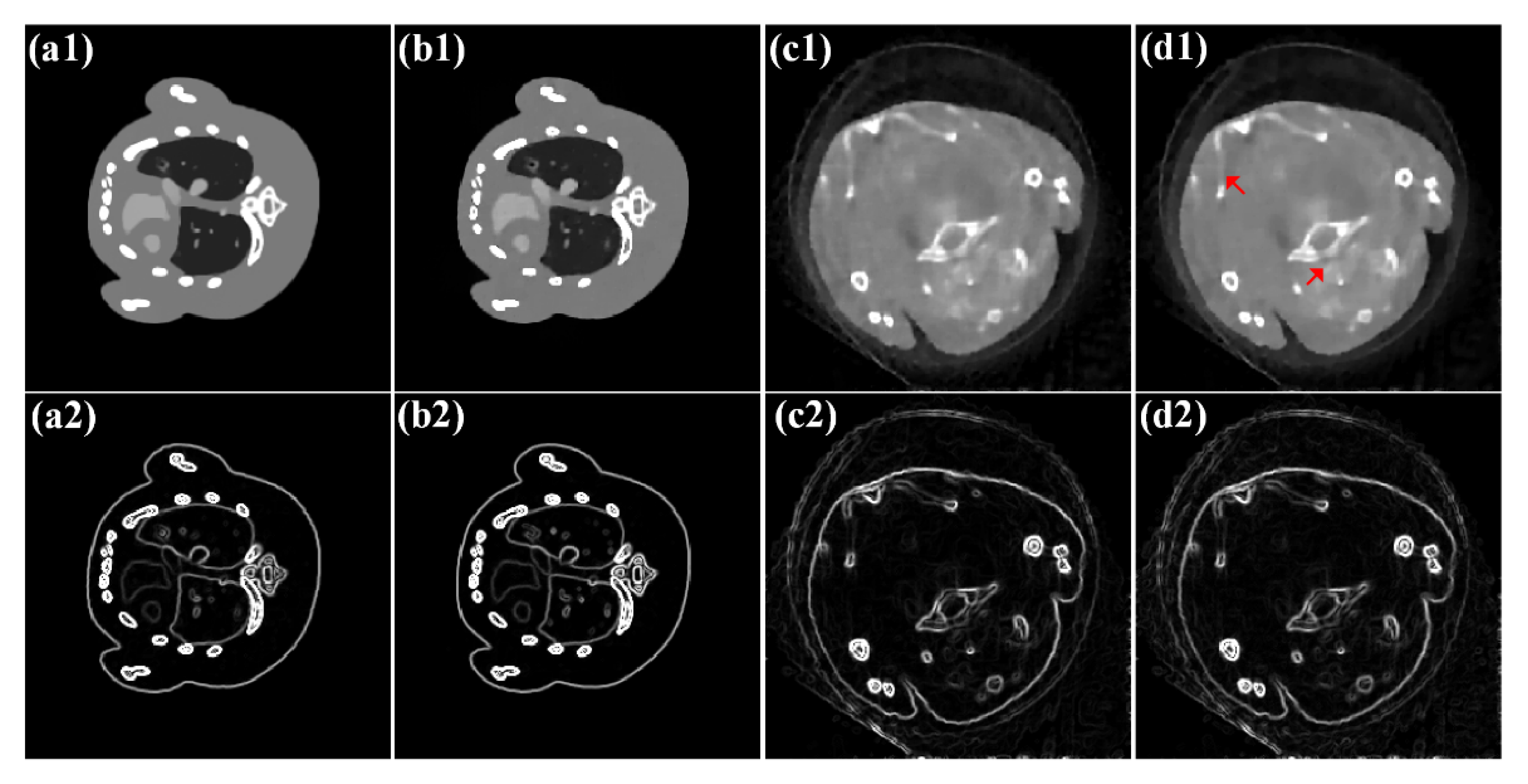
4.1. Numerical Simulation Study
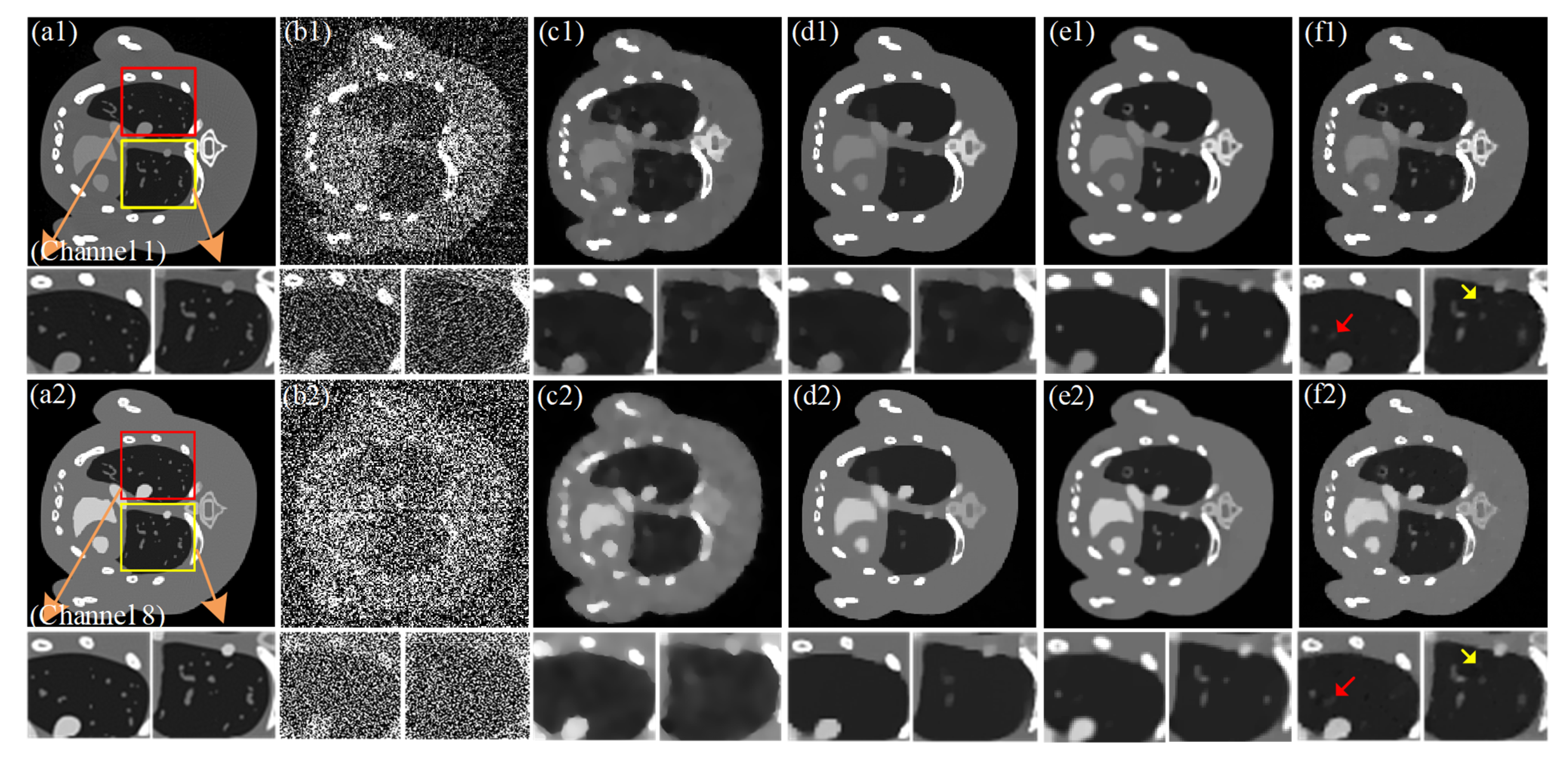
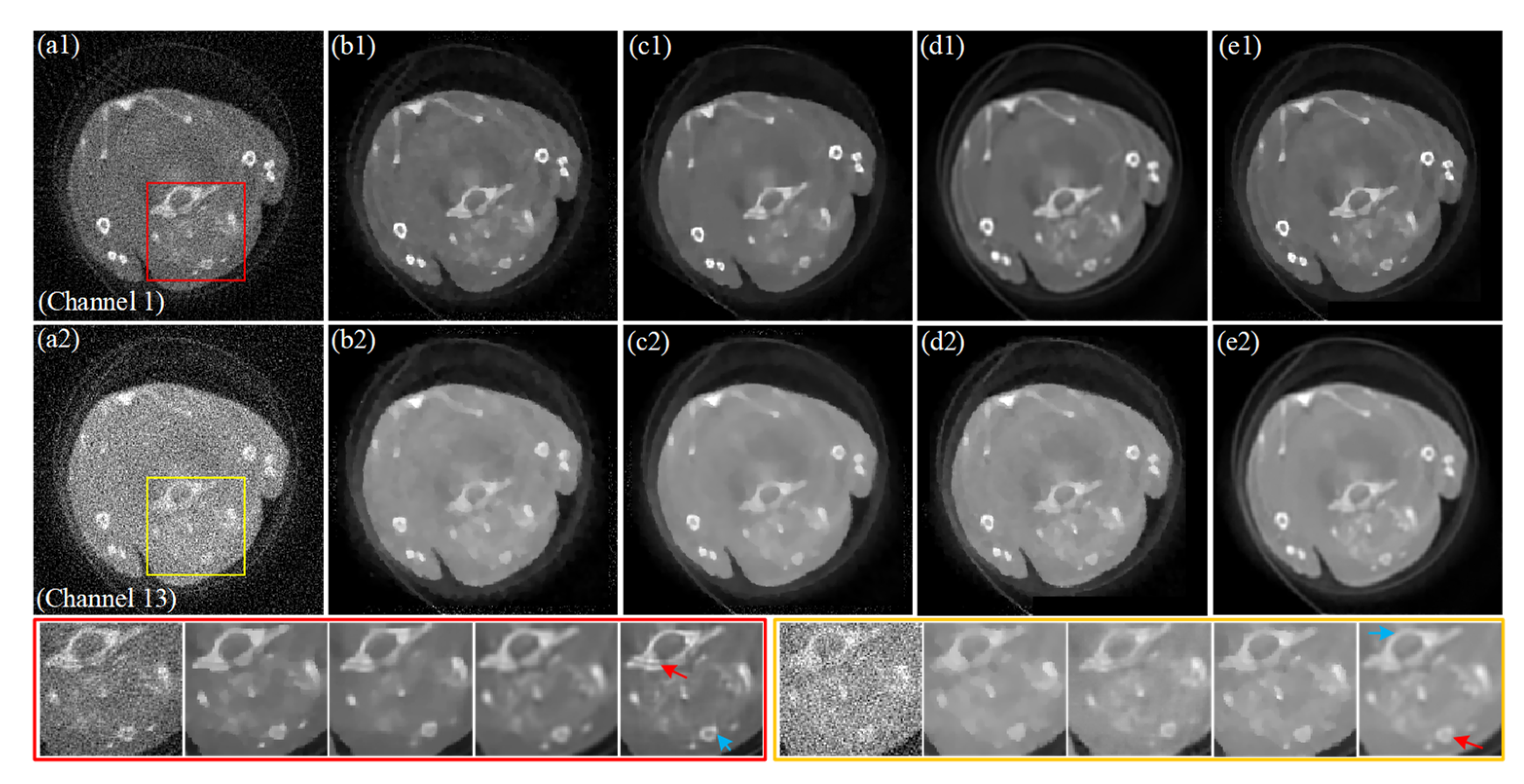
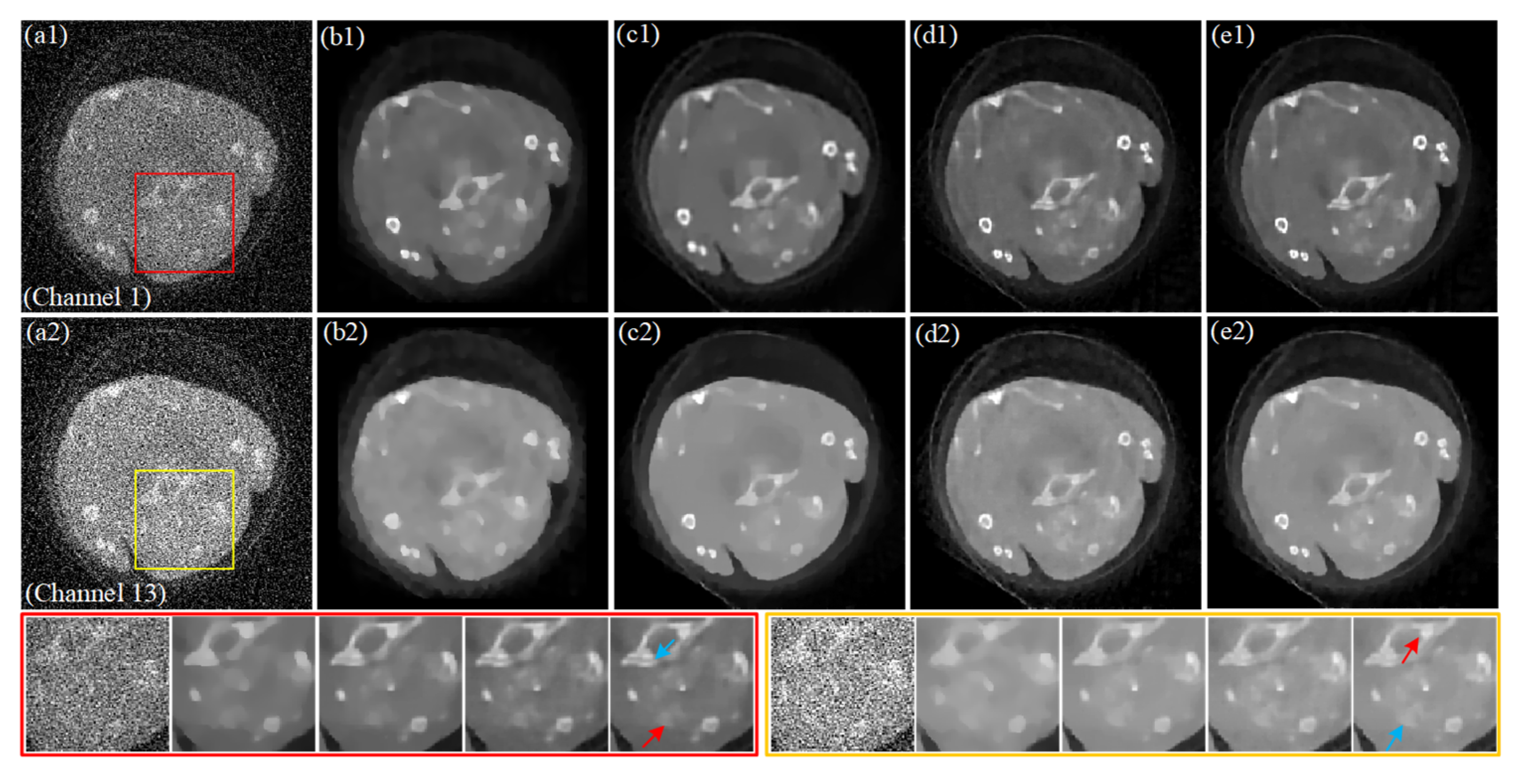
4.2. Preclinical Mouse Study
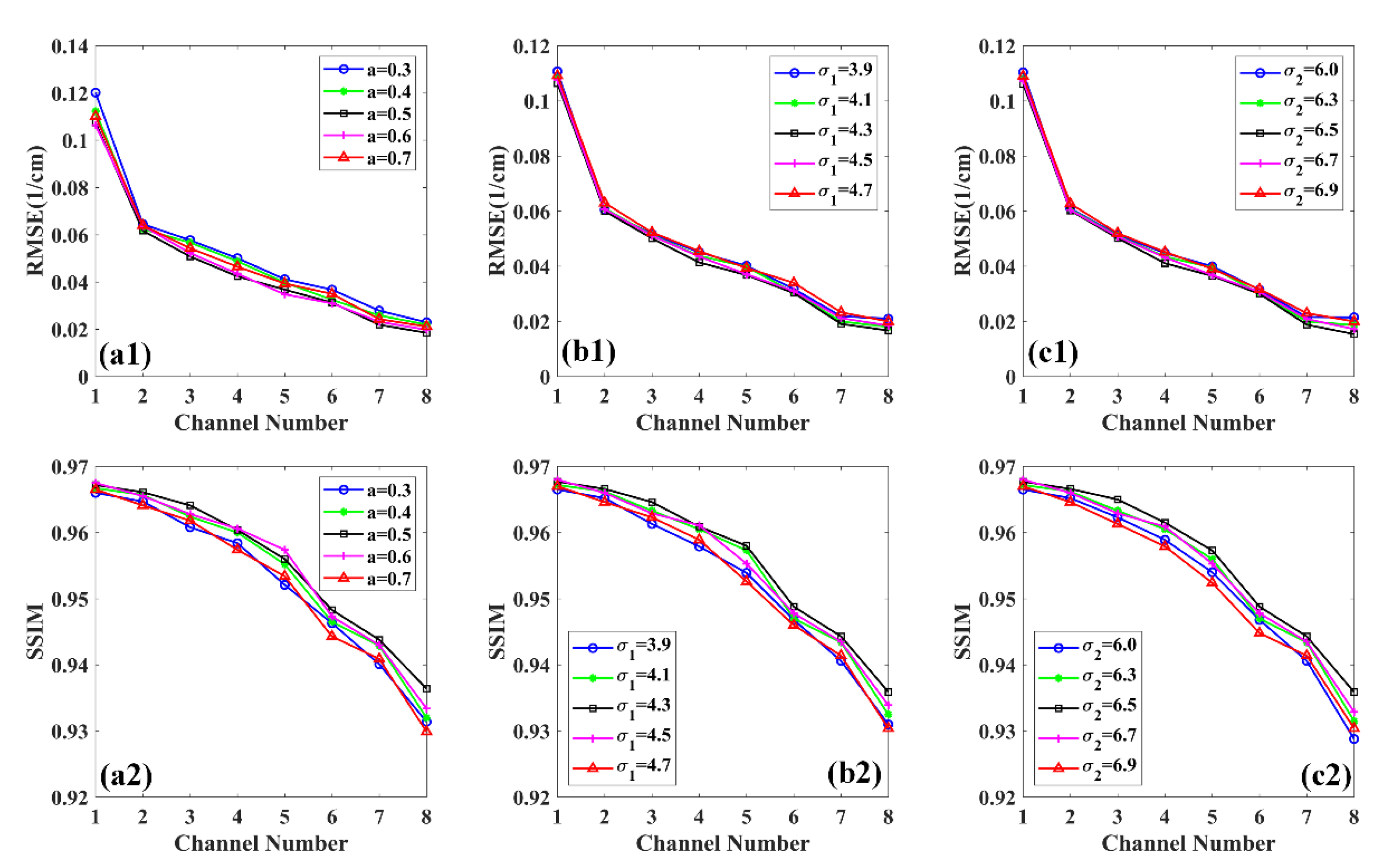
4.3. Parameters Analysis
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, G.; Yu, H.; De Man, B. An outlook on X-ray CT research and development. Med. Phys. 2008, 35, 1051–1064. [Google Scholar] [CrossRef] [Green Version]
- Nakano, M.; Haga, A.; Kotoku, J.; Magome, T.; Masutani, Y.; Hanaoka, S.; Kida, S.; Nakagawa, K. Cone-beam CT reconstruction for non-periodic organ motion using time-ordered chain graph model. Radiat. Oncol. 2017, 12, 1–14. [Google Scholar] [CrossRef]
- Brooks, R.A.; Di Chiro, G. Beam hardening in X-ray reconstructive tomography. Phys. Med. Biol. 1976, 21, 390–398. [Google Scholar] [CrossRef]
- Zhao, W.; Li, D.; Niu, K.; Qin, W.; Peng, H.; Niu, T. Robust Beam Hardening Artifacts Reduction for Computed Tomography Using Spectrum Modeling. IEEE Trans. Comput. Imaging 2018, 5, 333–342. [Google Scholar] [CrossRef]
- Brenner, D.J.; Hall, E.J. Computed tomography—An increasing source of radiation exposure. N. Engl. J. Med. 2013, 357, 2277–2284. [Google Scholar] [CrossRef] [Green Version]
- Nikzad, S.; Pourkaveh, M.; Vesal, N.J.; Gharekhanloo, F. Cumulative radiation dose and cancer risk estimation in common diagnostic radiology procedures. Iran. J. Radiol. 2018, 15, 60955. [Google Scholar] [CrossRef]
- Lee, T.S.; Tsui, B. Task-Based Evaluation of Image Reconstruction Methods for Defect Detection and Radiation Dose Reduction in Myocardial Perfusion SPECT. IEEE Trans. Radiat. Plasma Med. Sci. 2018, 3, 89–95. [Google Scholar] [CrossRef]
- Wang, Q.; Zhu, Y.; Yu, H. Locally linear constraint based optimization model for material decomposition. Phys. Med. Biol. 2017, 62, 8314–8340. [Google Scholar] [CrossRef]
- Wang, M.; Zhang, Y.; Liu, R.; Guo, S.; Yu, H. An adaptive reconstruction algorithm for spectral CT regularized by a reference image. Phys. Med. Biol. 2016, 61, 8699–8719. [Google Scholar] [CrossRef]
- Taguchi, K.; Iwanczyk, J.S. Vision 20/20: Single photon counting X-ray detectors in medical imaging. Med. Phys. 2013, 40, 100901. [Google Scholar] [CrossRef]
- Xi, Y.; Chen, Y.; Tang, R.; Sun, J.; Zhao, J. United iterative reconstruction for spectral computed tomography. IEEE Trans. Med. Imaging 2015, 34, 769–778. [Google Scholar] [CrossRef]
- Xu, Q. Image reconstruction for hybrid true-color micro-CT. IEEE Trans. Biomed. Eng. 2012, 59, 1711. [Google Scholar] [CrossRef] [Green Version]
- Liu, H.; Ge, W.; Yu, H.; Lei, X.; Xu, Q. Dictionary Learning Based Reconstruction with Low-Rank Constraint for Low-Dose Spectral CT. Med. Phys. 2016, 43, 3701. [Google Scholar]
- Wu, W.; Yu, H.; Chen, P.; Luo, F.; Liu, F.; Wang, Q.; Zhu, Y.; Zhang, Y.; Feng, J.; Yu, H. Dictionary learning based image-domain material decomposition for spectral CT. Phys. Med. Biol. 2020, 65, 245006. [Google Scholar] [CrossRef]
- Kong, H.; Lei, X.; Lei, L.; Zhang, Y.; Yu, H. Spectral CT Reconstruction Based on PICCS and Dictionary Learning. IEEE Access 2020, 8, 133367–133376. [Google Scholar] [CrossRef]
- Zhao, B.; Gao, H.; Ding, H.; Molloi, S. Tight-frame based iterative image reconstruction for spectral breast CT. Med. Phys. 2013, 40, 031905. [Google Scholar] [CrossRef]
- Kim, K.; Ye, J.C.; Worstell, W.; Ouyang, J.; Rakvongthai, Y.; Fakhri, G.E.; Li, Q. Sparse-view spectral CT reconstruction using spectral patch-based low-rank penalty. IEEE Trans. Med. Imaging 2015, 34, 748–760. [Google Scholar] [CrossRef]
- Chu, J.; Cong, W.; Li, L.; Wang, G. Combination of current-integrating/photon-counting detector modules for spectral CT. Phys. Med. Biol. 2013, 58, 7009–7024. [Google Scholar] [CrossRef]
- Rigie, D.S.; La Rivière, P.J. Joint reconstruction of multi-channel, spectral CT data via constrained total nuclear variation minimization. Phys. Med. Biol. 2015, 60, 1741–1762. [Google Scholar] [CrossRef] [Green Version]
- Semerci, O.; Hao, N.; Kilmer, M.E.; Miller, E.L. Tensor-based formulation and nuclear norm regularization for multienergy computed tomography. IEEE Trans. Image Process. 2014, 23, 1678–1693. [Google Scholar] [CrossRef] [Green Version]
- Gao, H.; Yu, H.; Osher, S.; Wang, G. Multi-energy CT based on a prior rank, intensity and sparsity model (PRISM). Inverse Probl. 2011, 27, 115012. [Google Scholar] [CrossRef] [Green Version]
- Liang, L.; Chen, Z.; Wang, G.; Chu, J.; Gao, H. A tensor PRISM algorithm for multi-energy CT reconstruction and comparative studies. J. X-ray Sci. Technol. 2014, 22, 147–163. [Google Scholar]
- Wu, W.; Hu, D.; An, K.; Wang, S.; Luo, F. A High-Quality Photon-Counting CT Technique Based on Weight Adaptive Total-Variation and Image-Spectral Tensor Factorization for Small Animals Imaging. IEEE Trans. Instrum. Meas. 2021, 70, 1–14. [Google Scholar] [CrossRef]
- Wu, W.; Chen, P.; Vardhanabhuti, V.; Wu, W.; Yu, H. Improved Material Decomposition with a Two-step Regularization for spectral CT. IEEE Access 2019, 7, 158770–158781. [Google Scholar] [CrossRef]
- Hu, D.; Wu, W.; Xu, M.; Zhang, Y.; Liu, J.; Ge, R.J.; Chen, Y.; Luo, L.; Coatrieux, G. SISTER: Spectral-Image Similarity-Based Tensor with Enhanced-Sparsity Reconstruction for Sparse-View Multi-Energy CT. IEEE Trans. Comput. Imaging 2020, 6, 477–490. [Google Scholar] [CrossRef]
- Yu, Z.; Leng, S.; Li, Z.; Mccollough, C.H. Spectral prior image constrained compressed sensing (spectral PICCS) for photon-counting computed tomography. Phys. Med. Biol. 2016, 61, 6707. [Google Scholar] [CrossRef] [Green Version]
- Niu, S.; Zhang, Y.; Ma, J.; Wang, J. WE-FG-207B-05: Iterative Reconstruction Via Prior Image Constrained Total Generalized Variation for Spectral CT. Med. Phys. 2016, 43, 3835. [Google Scholar] [CrossRef]
- Wang, S.; Wu, W.; Feng, J.; Liu, F.; Yu, H. Low-dose spectral CT reconstruction based on image-gradient L0 -norm and adaptive spectral PICCS. Phys. Med. Biol. 2020, 65, 245005. [Google Scholar] [CrossRef]
- Xu, Q.; Yu, H.Y.; Mou, X.Q.; Zhang, L.; Hsieh, J.; Wang, G. Low-dose X-ray CT reconstruction via dictionary learning. IEEE Trans. Med. Imaging 2012, 31, 1682–1697. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Mou, X.; Wang, G.; Yu, H. Tensor-Based Dictionary Learning for Spectral CT Reconstruction. IEEE Trans. Med. Imaging 2017, 36, 142–154. [Google Scholar] [CrossRef] [Green Version]
- Peng, Y.; Meng, D.; Xu, Z.; Gao, C.; Yang, Y.; Zhang, B. Decomposable nonlocal tensor dictionary learning for multispectral image denoising. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2949–2956. [Google Scholar] [CrossRef]
- Gong, X.; Chen, W.; Chen, J. A Low-Rank Tensor Dictionary Learning Method for Hyperspectral Image Denoising. IEEE Trans. Signal Process. 2020, 68, 1168–1180. [Google Scholar] [CrossRef]
- Tan, S.; Zhang, Y.; Wang, G.; Mou, X.; Cao, G.; Wu, Z.; Yu, H. Tensor-based dictionary learning for dynamic tomographic reconstruction. Phys. Med. Biol. 2015, 60, 2803–2818. [Google Scholar] [CrossRef] [Green Version]
- Wu, W.; Zhang, Y.; Wang, Q.; Liu, F.; Chen, P.; Yu, H. Low-dose spectral CT reconstruction using image gradient ℓ0–norm and tensor dictionary. Appl. Math. Model. 2018, 63, 538–557. [Google Scholar] [CrossRef]
- Li, X.; Lu, C.; Yi, X.; Jia, J. Image Smoothing via L0 Gradient Minimization. ACM Trans. Graph. 2011, 30, 1–12. [Google Scholar]
- Biswas, S.; Hazra, R. A new binary level set model using L0 regularizer for image segmentation. Signal Process. 2020, 174, 107603. [Google Scholar] [CrossRef]
- Yuan, G.; Ghanem, B. ℓ0 TV: A Sparse Optimization Method for Impulse Noise Image Restoration. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 352–364. [Google Scholar] [CrossRef] [Green Version]
- Duan, G.; Wang, H.; Liu, Z.; Deng, J.; Chen, Y.W. K-CPD: Learning of overcomplete dictionaries for tensor sparse coding. In Proceedings of the 21st International Conference on Pattern Recognition (ICPR2012), Tsukuba, Japan, 11–15 November 2012; pp. 493–496. [Google Scholar]
- Boyd, S.; Parikh, N.; Chu, E.; Peleato, B.; Eckstein, J. ADMM slide. Found. Trends Mach. Learn. 2010, 3, 1–122. [Google Scholar] [CrossRef]
- Liu, Q.; Liang, D.; Song, Y.; Luo, J.; Zhu, Y.; Li, W. Augmented lagrangian-based sparse representation method with dictionary updating for image deblurring. SIAM J. Imaging Sci. 2013, 6, 1689–1718. [Google Scholar] [CrossRef]
- Yu, W.; Wang, C.; Huang, M. Edge-preserving reconstruction from sparse projections of limited-angle computed tomography using ℓ0-regularized gradient prior. Rev. Sci. Instrum. 2017, 88, 043703. [Google Scholar] [CrossRef]
- Ren, D.; Zhang, H.; Zhang, D.; Zuo, W. Fast total-variation based image restoration based on derivative alternated direction optimization methods. Neurocomputing 2015, 170, 201–212. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, L.; Zhang, L.; Mou, X.; Zhang, D. FSIM: A Feature Similarity Index for Image Quality Assessment. IEEE Trans. Image Process. 2011, 20, 2378–2386. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wu, W.; Chen, P.; Wang, S.; Vardhanabhuti, V.; Liu, F.; Yu, H. Image-Domain Material Decomposition for Spectral CT Using a Generalized Dictionary Learning. IEEE Trans. Radiat. Plasma Med. Sci. 2021, 5, 537–547. [Google Scholar] [CrossRef] [PubMed]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Views | Channel | RMSE | SSIM | FSIM | ||||
|---|---|---|---|---|---|---|---|---|
| Method | 1st | 8th | 1st | 8th | 1st | 8th | ||
| 80 | TV | 0.1646 | 0.0436 | 0.9167 | 0.8752 | 0.9036 | 0.8616 | |
| TVLR | 0.1488 | 0.0389 | 0.9302 | 0.9071 | 0.9214 | 0.8961 | ||
| TDL | 0.1403 | 0.0322 | 0.9398 | 0.9128 | 0.9281 | 0.9024 | ||
| Ours | 0.1216 | 0.0213 | 0.9501 | 0.9255 | 0.9458 | 0.9137 | ||
| 160 | TV | 0.1486 | 0.0372 | 0.9313 | 0.8982 | 0.9237 | 0.8863 | |
| TVLR | 0.1364 | 0.0283 | 0.9423 | 0.9123 | 0.9352 | 0.9014 | ||
| TDL | 0.1251 | 0.0239 | 0.9528 | 0.9235 | 0.9426 | 0.9135 | ||
| Ours | 0.1075 | 0.0187 | 0.9672 | 0.9364 | 0.9513 | 0.9308 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Sun, X.; Zhang, Y.; Pan, J.; Chen, P. Tensor Dictionary Learning with an Enhanced Sparsity Constraint for Sparse-View Spectral CT Reconstruction. Photonics 2022, 9, 35. https://doi.org/10.3390/photonics9010035
Li X, Sun X, Zhang Y, Pan J, Chen P. Tensor Dictionary Learning with an Enhanced Sparsity Constraint for Sparse-View Spectral CT Reconstruction. Photonics. 2022; 9(1):35. https://doi.org/10.3390/photonics9010035
Chicago/Turabian StyleLi, Xuru, Xueqin Sun, Yanbo Zhang, Jinxiao Pan, and Ping Chen. 2022. "Tensor Dictionary Learning with an Enhanced Sparsity Constraint for Sparse-View Spectral CT Reconstruction" Photonics 9, no. 1: 35. https://doi.org/10.3390/photonics9010035