Using Machine Learning Algorithms for Accurate Received Optical Power Prediction of an FSO Link over a Maritime Environment

 ,
,  , ,
, ,
Abstract
:1. Introduction
2. Materials and Methods
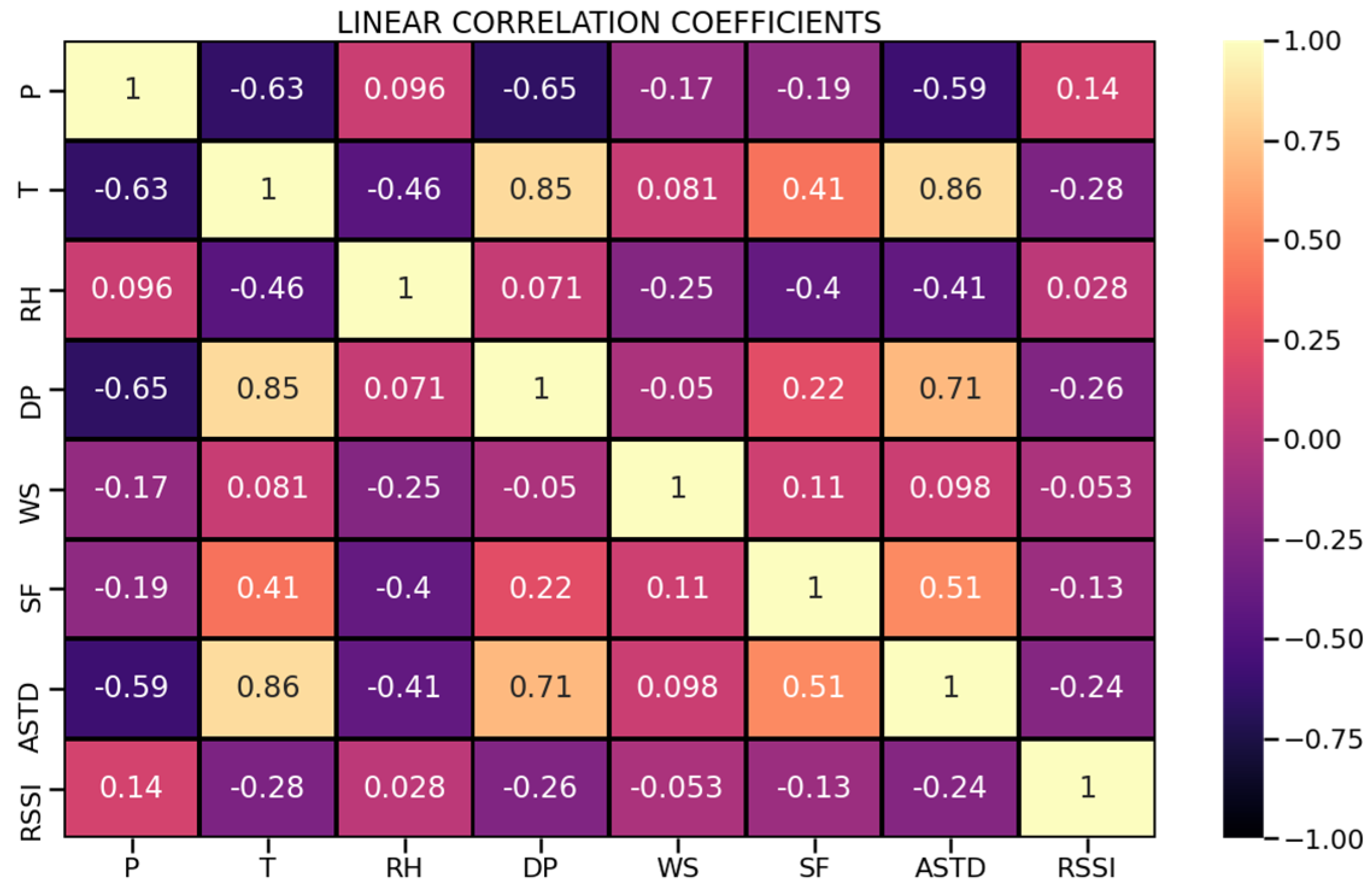
2.1. Assessing Model Accuracy
2.2. Machine Learning Based FSO Research Background
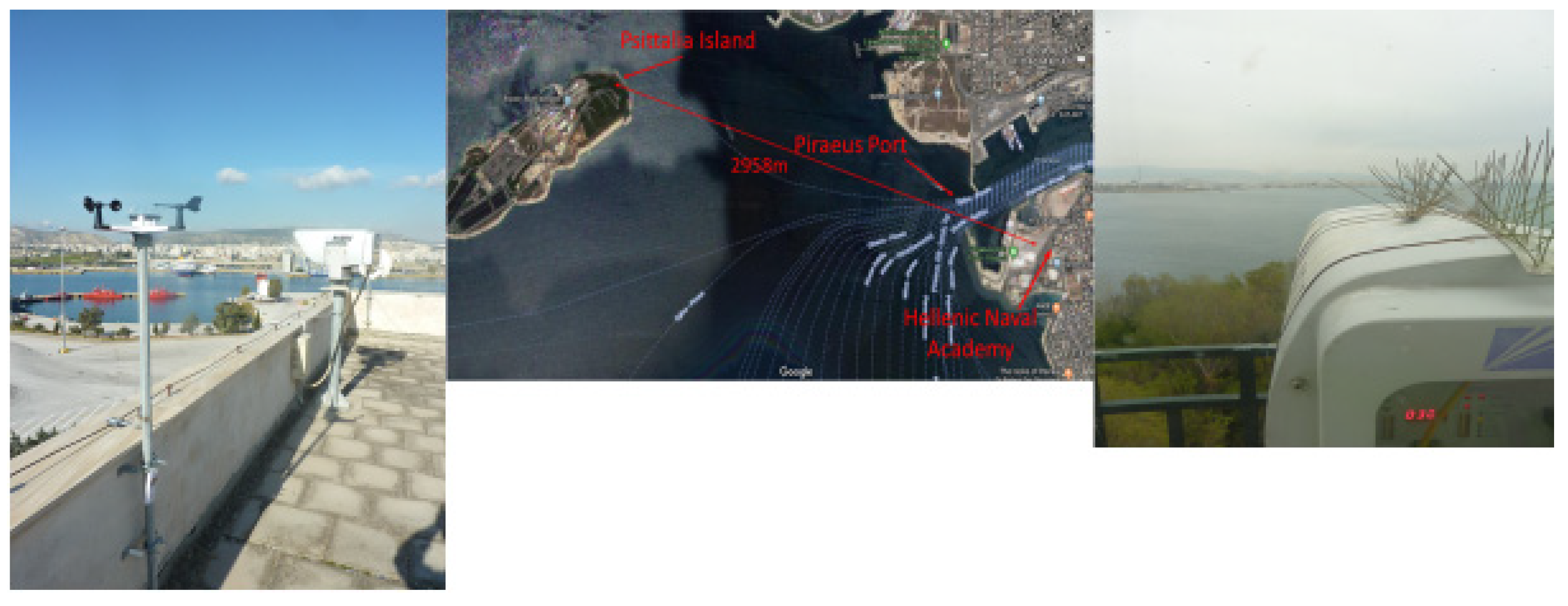
2.3. Measurement Systems Overview
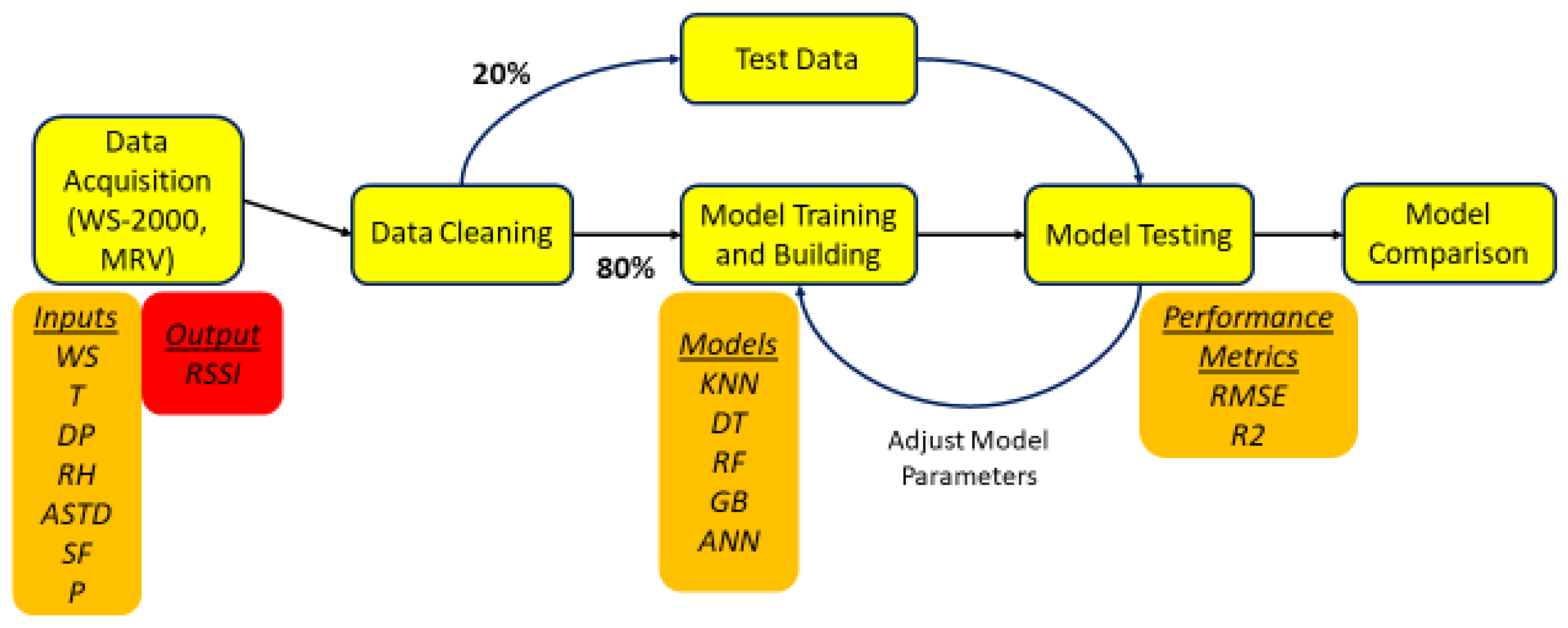
2.4. Methodology of Analysis
3. Results and Discussion
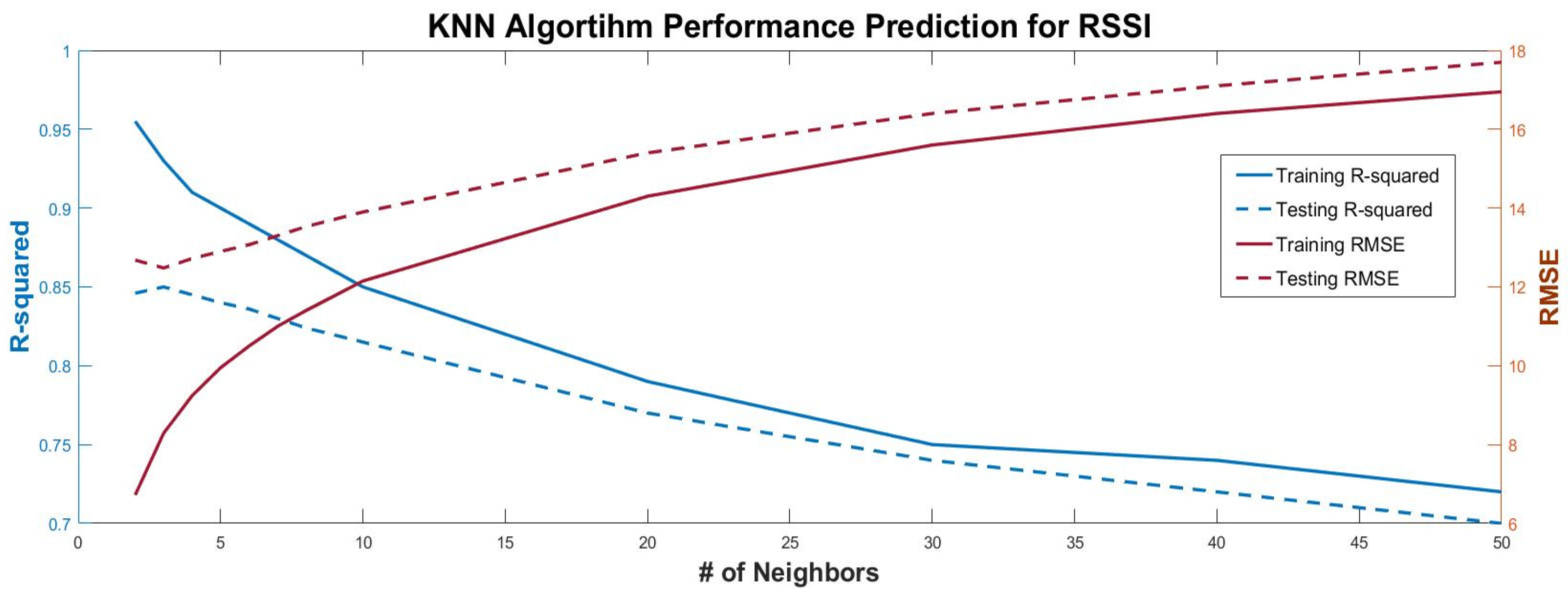
3.1. K-Nearest Neighbors Regression
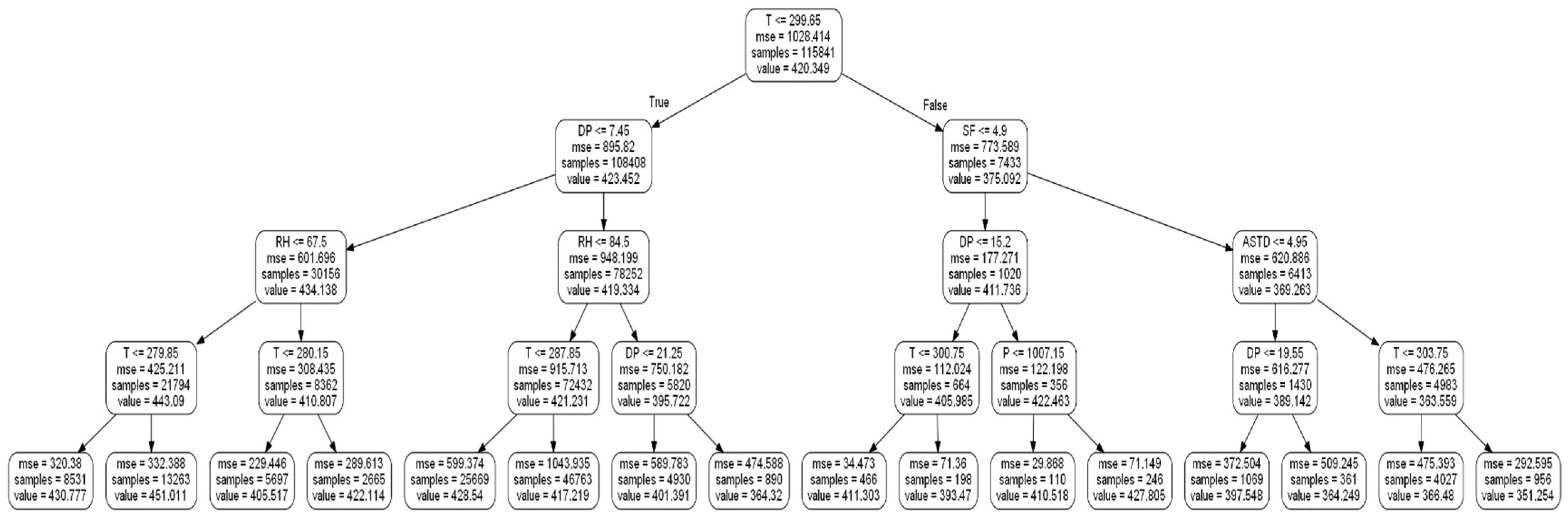
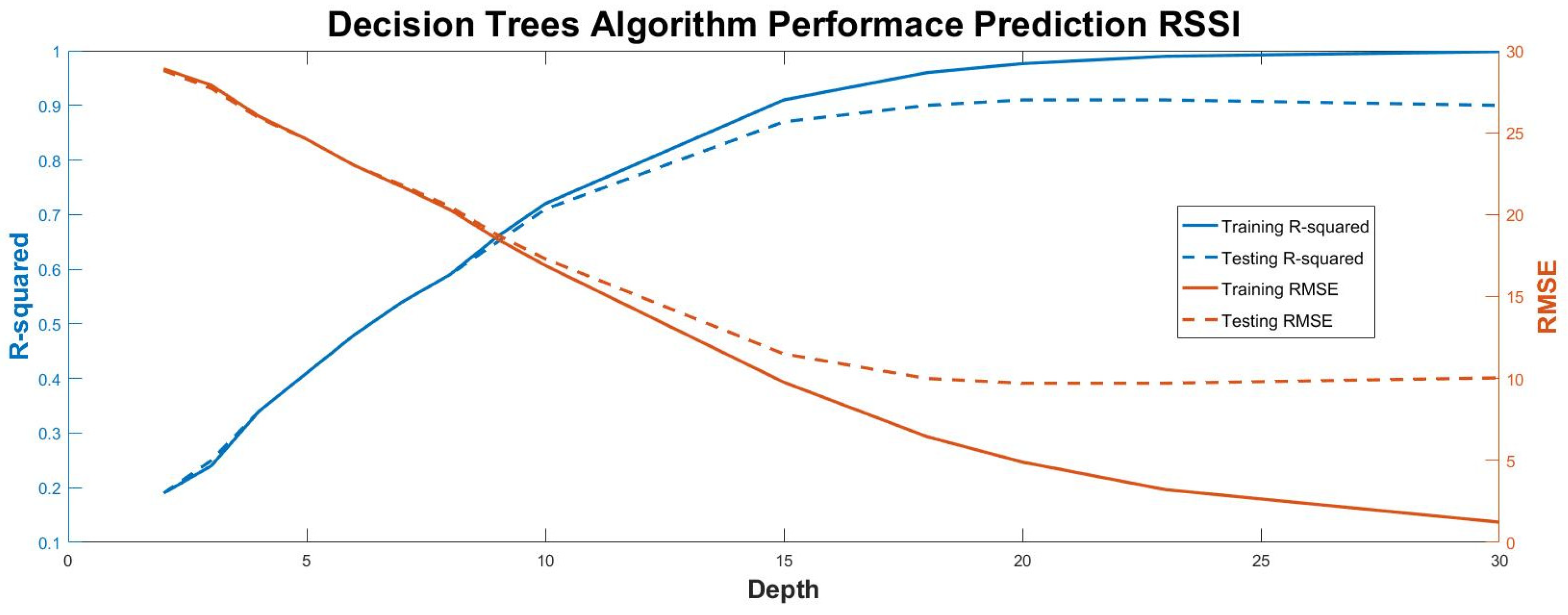
3.2. Decision Trees
- Predictor space division into J distinct and non-overlapping regions, R1, R2, … RJ. The criterion to determine the optimal split point is to minimize the RSS given by,where yRj is the mean response for the training observations in the j-th box.
- For every observation falling into a certain region, the prediction emerges from the response mean value based on the training observations that belong to the same region.
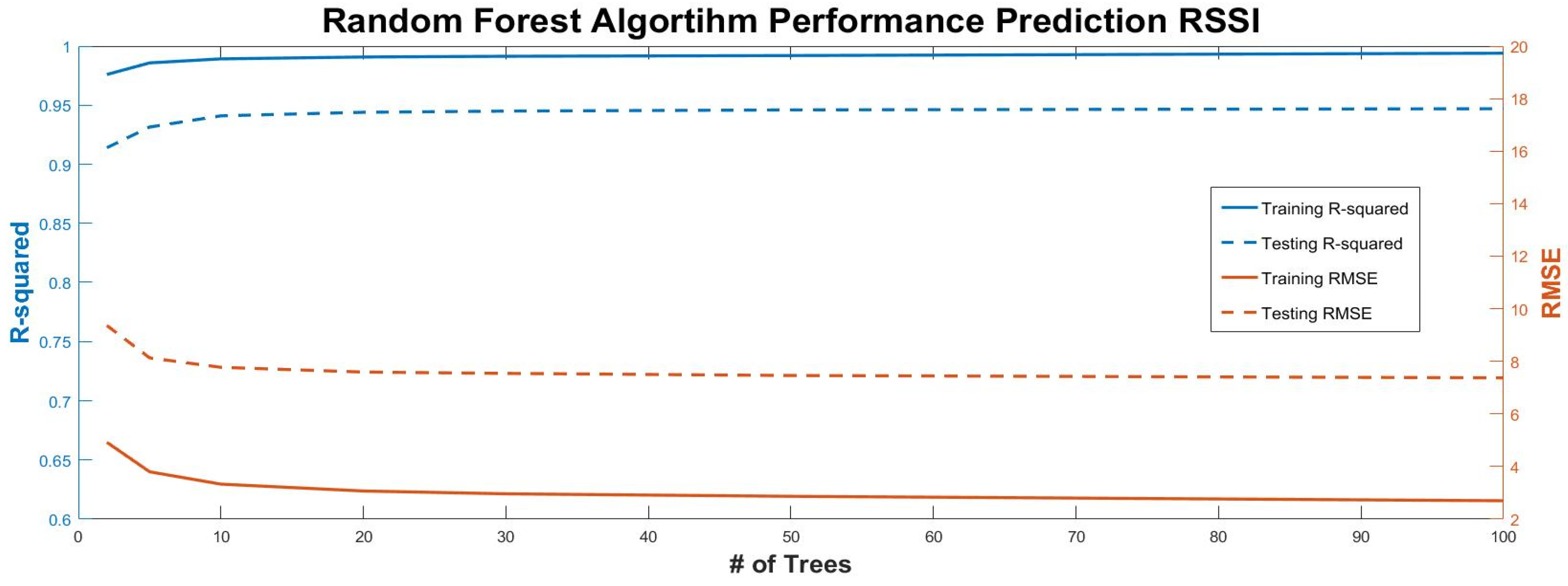
3.3. Random Forest
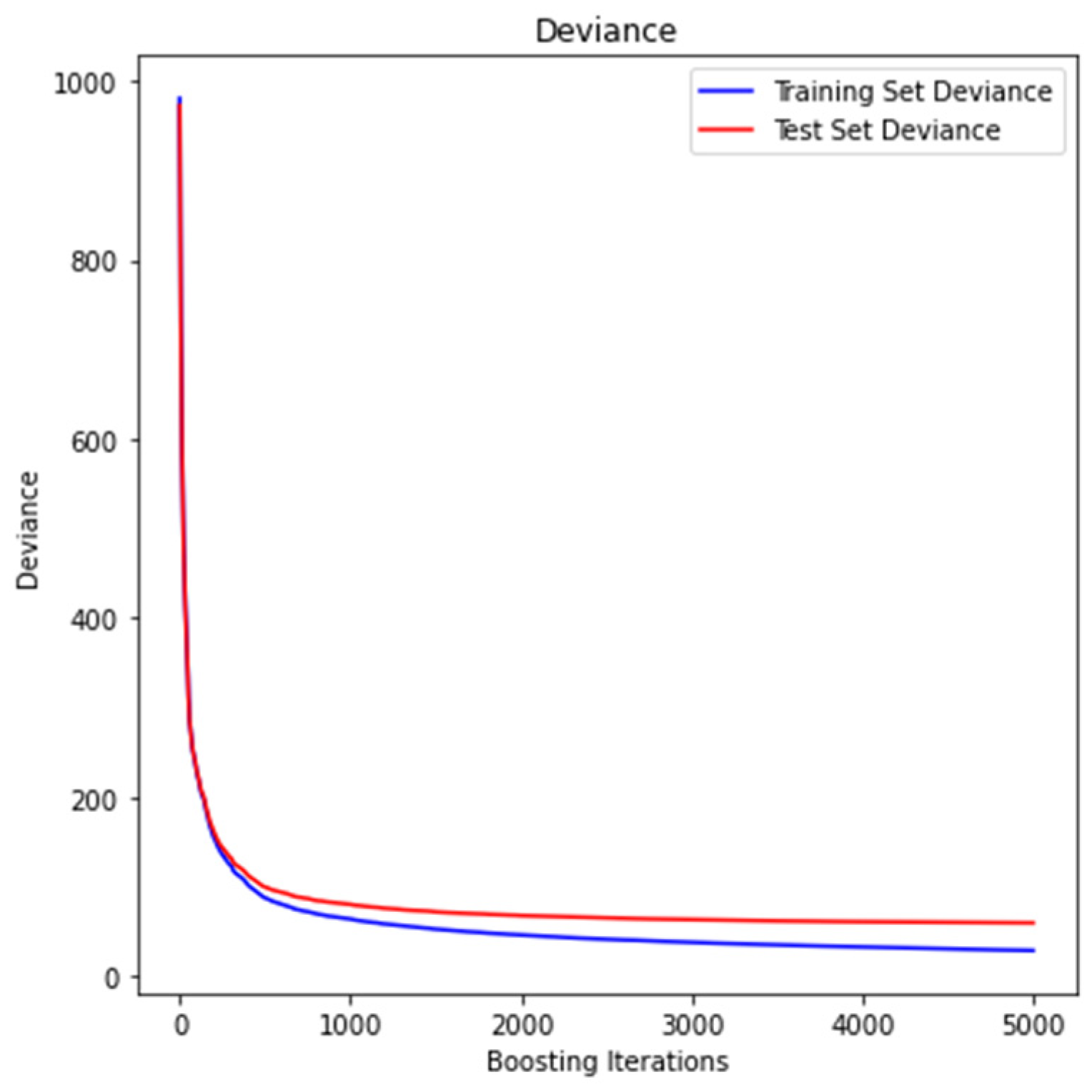
3.4. Gradient Boosting Regression
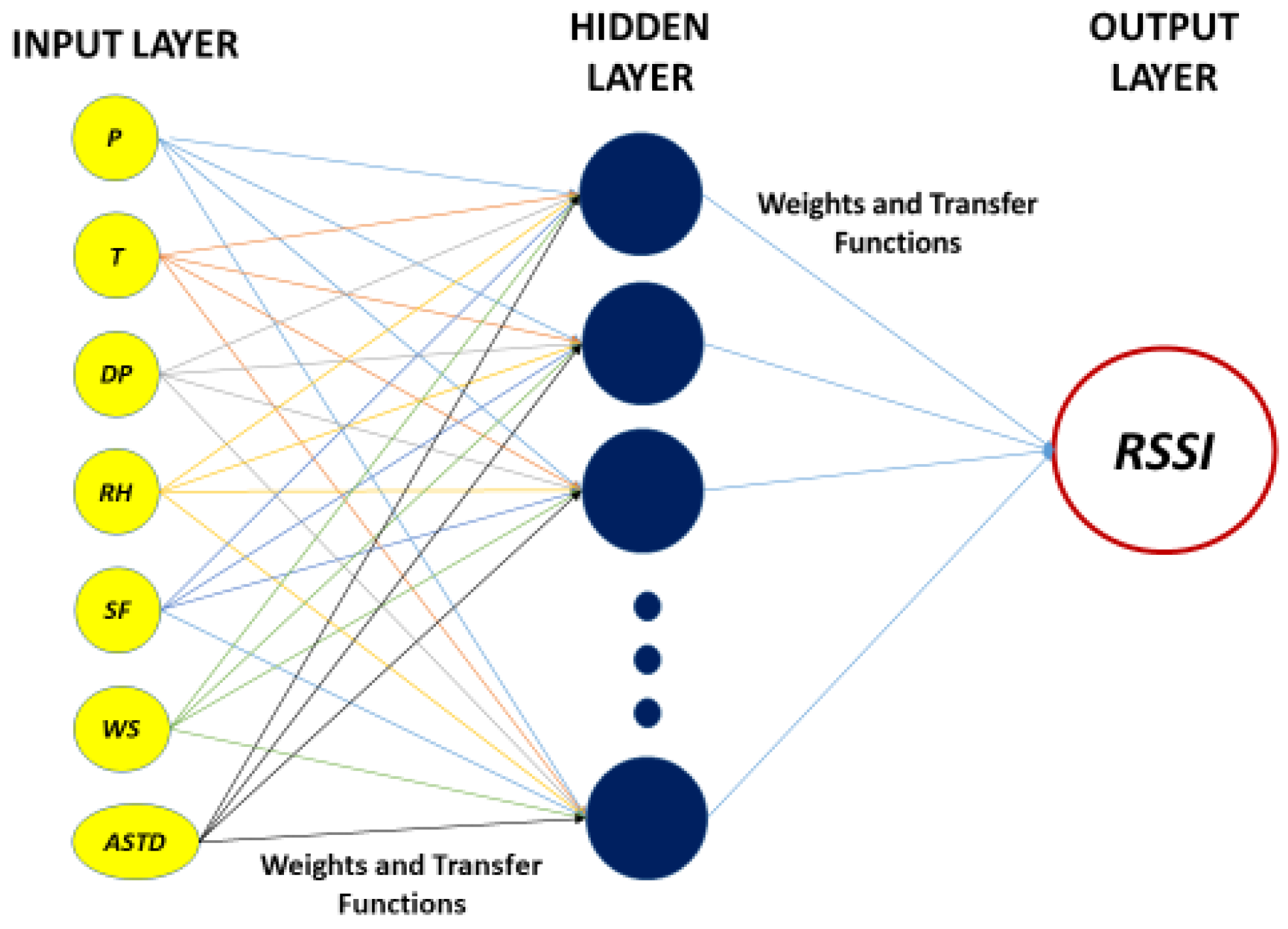
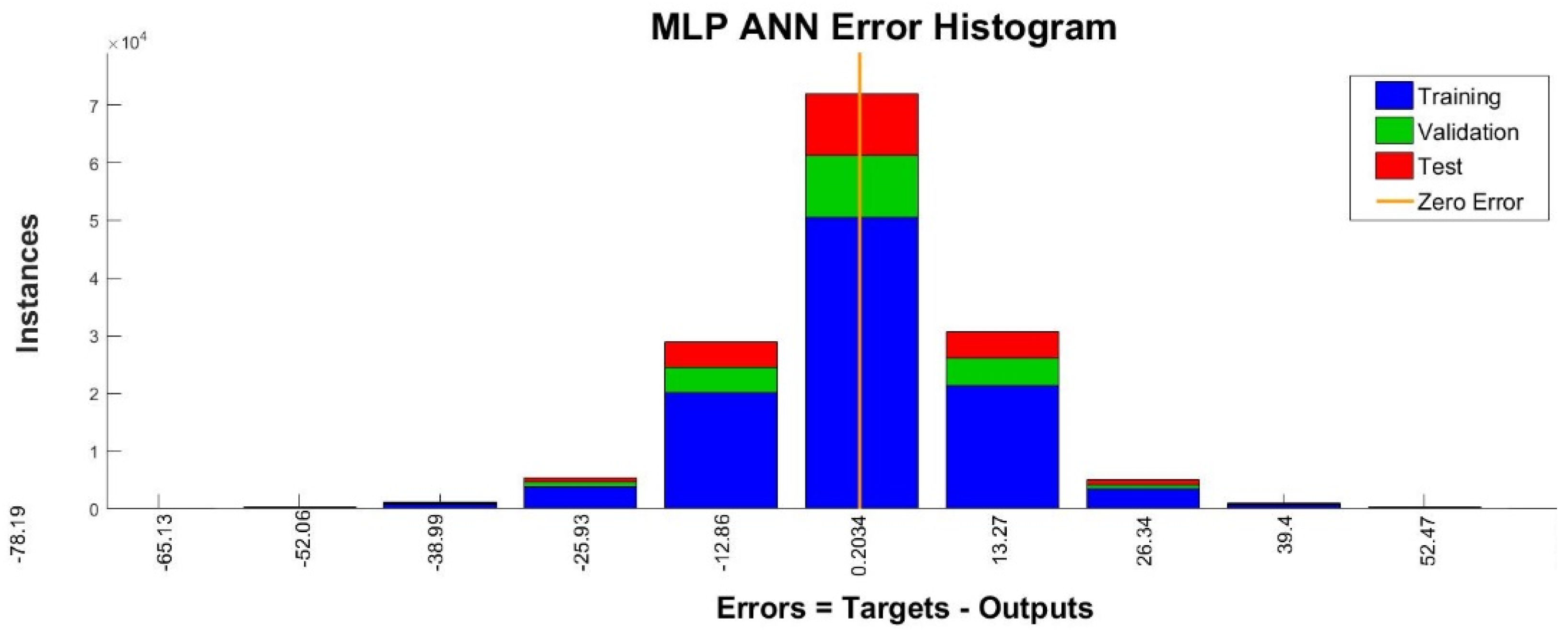
3.5. Artificial Neural Network
3.6. Model Comparison and Discussion
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Ghassemlooy, Z.; Popoola, W.O. Terrestrial Free-Space Optical Communications, Mobile and Wireless Communications Network Layer and Circuit Level Design; Fares, S.A., Adachi, F., Eds.; InTechOpen: London, UK, 2010; ISBN 978-953-307-042-1. [Google Scholar]
- Khalingi, M.A.; Uysal, M. Survey on Free Space Optical Communication: A Communications Theory Perspective. IEEE Commun. Surv. Tutor. 2014, 16, 2231–2258. [Google Scholar]
- Andrews, L.C.; Phillips, R.L.; Hopen, C.Y. Laser Beam Scintillation with Applications, 2nd ed.; SPIE Optical Engineering Press: Bellingham, WA, USA, 2001. [Google Scholar]
- Majumdar, A.K. Free-space laser communication performance in the atmospheric channel. J. Opt. Fiber Commun. Rep. 2005, 2, 345–396. [Google Scholar] [CrossRef]
- Kaushal, H.; Jain, V.K.; Kar, S. Free Space Optical Communication; Springer: New Delhi, India, 2017. [Google Scholar] [CrossRef]
- Barrios, R.; Dios, F. Wireless Optical Communications through the Turbulent Atmosphere: A Review, Optical Communications Systems; Das, N., Ed.; InTech: Rijeka, Croatia, 2012; ISBN 978-953-51-0170-3. [Google Scholar]
- Oh, E.S.; Ricklin, J.C.; Gilbreath, G.C.; Vallestero, N.J.; Eaton, F.D. Optical Turbulence Model for Laser Propagation and Imaging Applications. Proc. SPIE 5160, Free-Space Laser Communications and Active Laser Illumination III; SPIE: Bellingham, WA, USA, 2004. [Google Scholar] [CrossRef]
- Oh, E.S.; Ricklin, J.C.; Gilbreath, G.C.; Doss-Hammel, S.; Eaton, F.D.; Moore, C.; Murphy, J.; Oh, Y.H.; Stell, M. Estimating Optical Turbulence Using the PAMELA Model. Proc. SPIE 5550, Free-Space Laser Communications IV; SPIE: Bellingham, WA, USA, 2004. [Google Scholar] [CrossRef] [Green Version]
- Vetelino, F.S.; Young, C.; Grant, K.; Wasiczko, L.; Burris, H.; Moore, C.; Mahon, R.; Suite, M.; Corbett, K.; Clare, B.; et al. Initial Measurements of Atmospheric Parameters in a Marine Environment. Proc. SPIE 6215, Atmospheric Propagation III; SPIE: Orlando, FL, USA, 2006. [Google Scholar] [CrossRef]
- Wasiczko, L.M.; Moore, C.I.; Burris, H.R.; Suite, M.; Stell, M.; Murphy, J.; Gilbreath, G.C.; Rabinovich, W.; Scharpf, W. Characterization of the Marine Atmosphere for Free-Space Optical Communication. In Proceedings of the SPIE 6215, Atmospheric Propagation III, Orlando (Kissimmee), FL, USA, 17 May 2006. [Google Scholar]
- Gilbreath, G.C.; Rabinovich, W.S.; Moore, C.I.; Burris, H.R.; Mahon, R.; Grant, K.J.; Goetz, P.G.; Murphy, J.L.; Suite, M.R.; Stell, M.F.; et al. Progress in Laser Propagation in a Maritime Environment at the Naval Research Laboratory. Proc. SPIE 5892. Free-Space Laser Communications V; SPIE: Bellingham, WA, USA, 2005. [Google Scholar] [CrossRef]
- Burris, H.R.; Moore, C.I.; Swingen, L.A.; Vilcheck, M.J.; Tulchinsky, D.A.; Mahond, R.; Wasiczko, L.M.; Stell, M.F.; Suite, M.R.; Davis, M.A.; et al. Latest Results from the 32km Maritime Lasercom Link at the Naval Research Laboratory, Chesapeake Bay Lasercom Test Facility. Proc. SPIE 5793. Atmospheric Propagation II; SPIE: Bellingham, WA, USA, 2005. [Google Scholar] [CrossRef]
- Moore, C.I.; Burris, H.R.; Rabinovich, W.S.; Wasiczko, L.; Suite, M.R.; Swingen, L.A.; Mahon, R.; Stell, M.F.; Gilbreath, G.C.; Scharpf, W.J. Overview of NRL’s Maritime Laser Communication Test Facility. Proc. SPIE 5892. Free-Space Laser Communications V; SPIE: Bellingham, WA, USA, 2005. [Google Scholar] [CrossRef]
- De Jong, A.N.; Schwering, P.B.; Benoist, K.W.; Gunter, W.H.; Vrahimis, G.; October, F.J. Long-Term Measurements of Atmospheric Point Spread Functions over Littoral Waters, as Determined by Atmospheric Turbulence. Infrared Imaging Systems: Design, Analysis, Modeling and Testing. Proc. of SPIE; SPIE: Cardiff, UK, 2012; Volume 8355. [Google Scholar]
- Ali, R.N.; Jassim, J.M.; Jasim, K.M.; Jawad, M.K. Experimental Study of Clear Atmospheric Turbulence Effects on Laser Beam Spreading on Free Space. Int. J. Appl. Eng. Res. 2017, 12, 24. [Google Scholar]
- Qing, C.; Wu, X.; Li, X.; Zhu, W.; Qiao, C.; Rao, R.; Mei, H. Use of weather and forecasting model outputs to obtain near-surface refractive index structure constant over the ocean. Opt. Express 2016, 24, 12. [Google Scholar] [CrossRef]
- Qing, C.; Wu, X.; Li, X.; Huang, H.; Tian, Q.; Zhu, W.; Rao, R. Estimating the surface layer refractive index structure constant over snow and sea ice using Monin-Obukhov similarity theory with a mesoscale atmospheric model. Opt. Express 2016, 24, 18. [Google Scholar] [CrossRef]
- Van de Boer, A.; Moene, A.F.; Graf, A.; Simmer, C.; Holtslag, A.A.M. Estimation of the refractive index structure parameter from single-level daytime routine weather. Appl. Opt. 2014, 53, 26. [Google Scholar] [CrossRef]
- Frehlich, R.; Sharman, R.; Vandenberghe, F.; Yu, W.; Liu, Y.; Knievel, J.; Jumper, G. Estimates of Cn2 from numerical weather prediction model output and comparison with thermosonde data. J. Appl. Meteorol. Climatol. 2010, 49, 1742–1755. [Google Scholar] [CrossRef]
- Bourazani, D.; Stasinakis, A.N.; Nistazakis, H.E.; Varotsos, G.K.; Tsigopoulos, A.D.; Tombras, G.S. Experimental Accuracy Investigation for Irradiance Fluctuations of FSO Links Modeled by Gamma Distribution. In Proceedings of the 8th International Conference from Scientific Computing to Computational Engineering, Athens, Greece, 4–7 July 2018. [Google Scholar]
- Garrido-Balsells, J.M.; Lopez-Martinez, F.J.; Castillo-Vazquez, M.; Jurado-Navas, A.; Puerta-Notario, A. Performance analysis of FSO communications under LOS blockage. Opt. Express 2017, 25, 25278–25294. [Google Scholar] [CrossRef] [Green Version]
- Kong, L.; Xu, W.; Hanzo, L.; Zhang, H.; Zhao, C. Performance of a Free Space Optical Relay-Assisted Hybrid RF/FSO System in Generalized M-Distributed Channels. IEEE Photonics J. 2015, 7, 5. [Google Scholar] [CrossRef]
- Alheadary, W.G.; Park, K.-H.; Alfaraj, N.; Guo, Y.; Stegenburgs, E.; Ng, T.K.; Ooi, B.S.; Alouini, M.-S. Free-space optical channel characterization and experimental validation in a coastal environment. Opt. Express 2018, 26, 6614–6628. [Google Scholar] [CrossRef] [Green Version]
- Latal, J.; Vitasek, J.; Hajek, L.; Vanderka, A.; Koudelka, P.; Kepak, S.; Vasinek, V. Regression Models Utilization for RSSI Prediction of Professional FSO Link with Regards to Atmosphere Phenomena. In Proceedings of the 2016 International Conference on Broadband Communications for Next Generation Networks and Multimedia Applications (CoBCom), Graz, Austria, 14–16 September 2016. [Google Scholar]
- Hajek, L.; Vitasek, J.; Vanderka, A.; Latal, J.; Perecar, F.; Vasinek, V. Statistical prediction of the atmospheric behavior for free space optical link. In Proceedings of the SPIE 9614, Laser Communication and Propagation through the Atmosphere and Oceans IV, San Diego, CA, USA, 4 September 2015. [Google Scholar]
- Lionis, A.; Cohn, K.; Pogue, C. Experimental Design of a UCAV-based High Energy Laser Weapon. Nausivios Chora J. 2016, 6, 3–17. [Google Scholar]
- Lionis, A.; Peppas, K.; Nistazakis, H.E.; Tsigopoulos, A.D.; Cohn, K. Experimental Performance Analysis of an Optical Communication Channel over Maritime Environment. Electronics 2020, 9, 1109. [Google Scholar] [CrossRef]
- Lionis, A.; Peppas, K.; Nistazakis, H.E.; Tsigopoulos, A.D.; Cohn, K. Statistical Modeling of Received Signal Strength for an FSO Channel over Maritime Environment. Opt. Commun. 2020, 489, 126858. [Google Scholar] [CrossRef]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning with Applications in R; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Wang, D.; Song, Y.; Li, J.; Qin, J.; Yang, T.; Zhang, M.; Chen, X.; Boucouvalas, A. Data-driven Optical Fiber Channel Modeling: A Deep Learning Approach. J. Lightwave Technol. 2020, 38, 4730–4743. [Google Scholar] [CrossRef]
- Liu, J.; Wang, P.; Zhang, X.; He, Y.; Zhou, X.; Ye, H.; Li, Y.; Xu, S.; Chen, S.; Fan, D. Deep learning based atmospheric turbulence compensation for orbital angular momentum beam distortion and communication. Opt. Express 2019, 27, 16671–16688. [Google Scholar] [CrossRef]
- Amirabadi, M.; Kahaei, M.; Nezamalhosseini, S.A.; Vakili, V.T. Deep Learning for channel estimation in FSO communication system. Opt. Commun. 2020, 459, 124989. [Google Scholar] [CrossRef] [Green Version]
- Lohani, S.; Glasser, R. Turbulence correction with artificial neural networks. Opt. Lett. 2018, 43, 2611–2614. [Google Scholar] [CrossRef]
- Lohani, S.; Knutson, E.M.; Glasser, R.T. Generative machine learning for robust free-space communication. Commun. Phys. 2020, 3, 177. [Google Scholar] [CrossRef]
- Mishra, P.; Sonali; Dixit, A.; Jain, V.K. Machine Learning Techniques for Channel Estimation in Free Space Optical Communication Systems. In Proceedings of the 2019 IEEE International Conference on Advanced Networks and Telecommunications Systems (ANTS), Goa, India, 16–19 December 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Jellen, C.; Burkhardt, J.; Brownell, C.; Nelson, C. Machine learning informed predictor importance measures of environmental parameters in maritime optical turbulence. Appl. Opt. 2020, 59, 6379–6389. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Basu, S. Using an artificial neural network approach to estimate surface-layer optical turbulence at Mauna Loa, Hawaii. Opt. Lett. 2016, 41, 2334–2337. [Google Scholar] [CrossRef] [PubMed]
- Haluška, R.; Šuľaj, P.; Ovseník, Ľ.; Marchevský, S.; Papaj, J.; Doboš, Ľ. Prediction of Received Optical Power for Switching Hybrid FSO/RF System. Electronics 2020, 9, 1261. [Google Scholar] [CrossRef]
- Tóth, J.; Ovseník, L.; Turán, J.; Michaeli, L.; Márton, M. Classification prediction analysisof RSSI parameter in hard switching process for FSO/RF systems. Measurement 2017. [Google Scholar] [CrossRef]
- Xu, R.; Lv, P.; Xu, F.; Shi, Y. A survey of approaches for implementing optical neural networks. Opt. Laser Technol. 2021, 136, 106787. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Cifuentes, J.; Marulanda, G.; Bello, A.; Reneses, J. Air Temperature Forecasting Using Machine Learning Techniques: A Review. Energies 2020, 13, 4215. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Min Value | Mean Value | Max Value |
|---|---|---|---|
| RSSI | 187 | 420.4 | 517 |
| p (hPa) | 987.7 | 1040.6 | 1015 |
| T (°C) | 273.8 | 306 | 288.7 |
| RH (%) | 22 | 63.5 | 94 |
| DP (°C) | −5.5 | 11.3 | 24.6 |
| WS (m/s) | 0 | 2.95 | 25.8 |
| SF (W/m2) | 0 | 140.1 | 1149.5 |
| ASTD (°C) | −11.1 | −1.39 | 10 |
| Approach | R2 | RMSE | ||||
|---|---|---|---|---|---|---|
| Training | Validation | Test | Training | Validation | Test | |
| Baseline | 0.36 | - | 0.05 | - | - | - |
| KNN | 0.93 | - | 0.85 | 8.29 | - | 12.48 |
| DT | 0.9764 | - | 0.91 | 4.9 | - | 9.71 |
| RF | 0.994 | - | 0.947 | 2.7 | - | 7.37 |
| GBR | - | - | 0.9417 | - | - | 7.71 |
| ANN | 0.9496 | 0.9468 | 0.94867 | 10.06 | 10.19 | 10.17 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lionis, A.; Peppas, K.; Nistazakis, H.E.; Tsigopoulos, A.; Cohn, K.; Zagouras, A. Using Machine Learning Algorithms for Accurate Received Optical Power Prediction of an FSO Link over a Maritime Environment. Photonics 2021, 8, 212. https://doi.org/10.3390/photonics8060212
Lionis A, Peppas K, Nistazakis HE, Tsigopoulos A, Cohn K, Zagouras A. Using Machine Learning Algorithms for Accurate Received Optical Power Prediction of an FSO Link over a Maritime Environment. Photonics. 2021; 8(6):212. https://doi.org/10.3390/photonics8060212
Chicago/Turabian StyleLionis, Antonios, Konstantinos Peppas, Hector E. Nistazakis, Andreas Tsigopoulos, Keith Cohn, and Athanassios Zagouras. 2021. "Using Machine Learning Algorithms for Accurate Received Optical Power Prediction of an FSO Link over a Maritime Environment" Photonics 8, no. 6: 212. https://doi.org/10.3390/photonics8060212