1. Introduction
Automatic vehicle make and model recognition (VMMR) aims to offer innovative services to improve the efficiency and safety of transportation networks. These services include intelligent traffic analysis and management, electronic toll collection, emergency vehicle notifications, the automatic enforcement of traffic rules, etc. In recent years, several authors have proposed and implemented different approaches and techniques to present solutions to the various challenges of VMMR such as the similar appearance of different vehicle models [
1,
2], variations in the images due to weather conditions or resolution [
3,
4,
5], recognition through different key points or regions [
6,
7], etc. However, most of these solutions are designed within a
closed-set approach, where it is assumed that all query data are well represented by the training set, and therefore these solutions lack mechanisms to detect during testing when an input sample does not belong to any of the predefined classes. These unforeseen situations are very likely to happen in real-life scenarios and drastically weaken the robustness of the models.
Every day, we have more and more access to labeled data, which makes data-hungry algorithms such as classification algorithms that employ supervised learning improve their classification accuracy by having more training information. However, it is unrealistic to think that we will be able to train these algorithms to recognize any object that may be presented to them. In the specific case of this application domain, it is estimated that there are currently more than 3300 vehicle makes in the world, for which models have been added and removed from the market, modifying the design in each generation and producing different versions of the same vehicle, which has made it very difficult to have a database containing enough examples of all the existing vehicles in circulation to correctly train a model. This limitation is very common in real-world recognition/classification tasks such as VMMR and, in most cases, results in misclassified vehicles because the algorithms were not prepared to deal with objects of unknown (novel) classes.
To solve this problem, some strategies have been proposed, such as periodically retraining the algorithms, incorporating an incremental update mechanism [
8,
9], using zero-shot [
10,
11] or one-shot (few-shot) [
12,
13] learning, etc. Although these strategies provide models with greater flexibility or the possibility of eventually increasing their classification potential, they do not address the fundamental problem of recognizing a novel class during testing (
open-set problem). Scheirer et al. were the first to describe a more realistic scenario in which new classes not seen in training appear in testing and require classifiers not only to accurately classify objects of known classes but also to effectively deal with classes not considered in the training set [
14]. They formalized this problem as
open-set recognition (OSR) and proposed a solution called 1-vs-Set machine, where the risk of labeling a sample as known if it is far from the known data (
open space) is measured, and its objective is to minimize this risk (
open-space risk) by rejecting queries that lie beyond the reasonable support of the known data.
OSR led to extensive research that mostly focused on more effectively limiting the
open-space risk [
15,
16,
17,
18], and little research was developed around efficiently performing
open-set recognition and simultaneously discovering new classes hidden in the rejected instances. Some of the proposed solutions employed incremental learning [
19], transfer learning [
20,
21], or clustering [
22,
23]. Although they achieved good results, most of them present limitations such as the determination of the number of new classes in a later or separate event from the recognition of novel instances, or the use of examples of unknown classes during validation, pretraining, or retraining stages as a strategy to fine-tune their representations/parameters; however, in OSR, there is almost never information of unknown classes.
In the specific case of VMMR, few works have been proposed that, although not described within an OSR framework, have mechanisms to deal with new classes. One of these studies was conducted by Nazemi et al. [
3] from an anomaly detection approach. Their base system is capable of classifying 50 specific vehicle models, to which they added an anomaly detection based on a confidence threshold to identify vehicles that do not belong to any of these 50 classes. The “anomalies” are further classified based on their dimensions within two new classes: “unknown heavy” and “unknown light”. Another approach was proposed by Kezebou et al. [
12], with a few-shot learning approach requiring between 1 and 20 images for the generation of new classes.
In this paper, we propose to approach VMMR as an OSR problem extended for new class discovery. Since the known classes are supported by numerous well-labeled examples, we can very effectively train an image classification algorithm that employs supervised learning like convolutional neural networks (CNNs), which are the most widely used tool for this task. While these networks cannot deal with the recognition of new classes, their ability to extract meaningful features can be exploited to design a mechanism that can detect objects of new classes based on the distribution of feature vectors in the embedded space that, when aggregated between feature extraction and classification, would adopt an OSR approach. However, feature vectors are usually of high dimensionality, their distribution is not always clear, and there is no assurance that the behavior will be maintained in instances of unknown classes, which can complicate the representation and interpretation of the space to detect new classes. To tackle these problems, we propose to train a CNN with contrastive learning using the contrastive loss function during the training stage to reorganize the space where the feature vectors are mapped. Instead of separating the images with a hyperplane, the contrastive loss function brings similar images in near space (in terms of, e.g., Euclidean distance, cosine similarity, or some other metric) and moves dissimilar images away, generalizing this behavior on new unseen data.
Although there are CNN architectures such as VGG16, AlexNet, etc., that have achieved state-of-the-art results in the most well-known benchmarks such as ImageNet, CIFAR-100, etc., we propose a new CNN architecture designed from images of the application domain of this work (VMM) and the contrastive loss function using a neuroevolution technique to ensure consistent distribution of feature vectors within the embedded space, which serves as the main guide for a probabilistic model and a clustering algorithm that carry out the detection of objects of new classes and simultaneously discover their classes.
The remainder of this paper is organized as follows:
Section 2 presents the related work.
Section 3 describes the proposed methodology to approach VMMR as an OSR problem with an extension for new class discovery. This section also presents the proposed global scheme and delves deeper into each stage, detailing how the techniques of neuroevolution, contrastive loss function, the probabilistic model, and clustering are linked so as to achieve the general purpose.
Section 4 details the tests performed, including the parameters and justifications for each test and the results obtained at each stage with their respective interpretation. Finally, the conclusions are drawn, and future work is discussed in
Section 5.
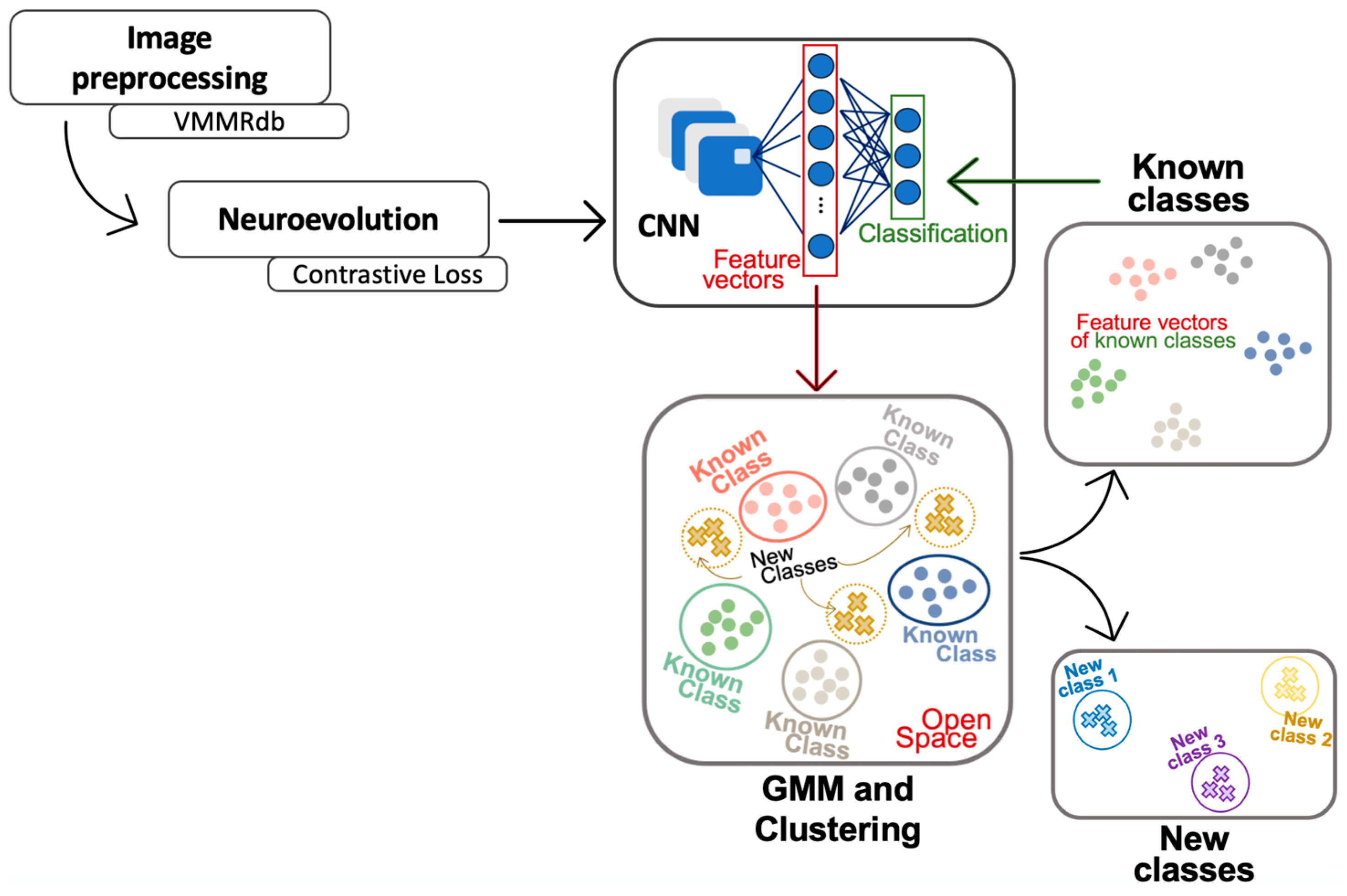
3. Materials and Methods
This section describes the methodology proposed to approach VMMR as an OSR problem with an extension for new class discovery.
Figure 1 shows the overall process of our proposal, and the following subsections describe the process in detail, covering the following objectives:
Employ an NE algorithm and contrastive learning to design a domain-specific CNN that generates feature vectors spatially close in terms of cosine distance if the instances belong to the same class and distant if they belong to different classes, preserving this behavior in instances of unknown classes.
Implement a mechanism between the feature extraction and classification sections of the CNN capable of detecting objects of unknown classes and simultaneously discovering their classes, taking the mapping of feature vectors, described in the previous objective, as the main guide.
Run a series of tests using the test set that includes images of classes with which the CNN was designed and trained (known) and images of new classes (unknown) to test that the algorithm is able to detect objects of unknown classes and simultaneously discover their classes.
Classify images of known classes with a classification accuracy above 90%.
3.1. Dataset
The VMMRdb database [
37] (available at
https://github.com/faezetta/VMMRdb, accessed on 13 March 2023) was used in this work since it is one of the most cited in the specialized literature [
12,
38,
39]. Only eight classes from the VMMRdb database were used and were manually filtered to retain only unduplicated images showing the rear view of the vehicles (i.e., samples of each class were not balanced). The filtered images were transformed to grayscale, resized to 28 × 28 pixels, and normalized with a mean of 0.456 and a standard deviation of 0.224.
Of the eight classes, five classes were used as “known classes”: Chevrolet Silverado 2004, Ford Explorer 2002, Ford Mustang 2000, Honda Civic 2002, and Nissan Altima 2005. A sample of six images of each “known class” was used in the NE process to design the domain-specific CNN for VMMR. For the training of the resulting CNN from the NE process, the largest number of examples per class was needed, which had to be the same among different classes. However, due to the number of available samples in the database and the image filtering mentioned above, the final number of functional samples per “known class” varied between 75 and 250 images. Among the functional samples, three images of each class were kept for testing the complete OSR framework, and the rest were subjected to a data augmentation process to balance the number of examples per class, resulting in 250 images of each “known class”. Furthermore, 200 images were used to train the CNN and model the “known classes” with a Gaussian mixture model (GMM), and the remaining 50 images were used to test the CNN classification accuracy and define the threshold of “known classes” in the GMM.
From the three remaining classes chosen from the database (Acura RSX 2003, Chevrolet Avalanche 2009, and Ford Escape 2011), three images of each class were chosen to only be used during the testing stage to represent “unknown classes” and validate that the proposed approach can detect them and discover their classes.
3.2. Neuroevolution and Contrastive Loss
One of the main objectives of this work is to exploit the ability of a CNN to extract meaningful features for designing a mechanism to detect objects of unknown classes based on the distribution of the feature vectors in the embedded space. To facilitate the interpretation of the embedded space, feature vectors extracted using the CNN are considered to be spatially close in terms of cosine similarity if they belong to the same class and spatially distant if they belong to different classes, maintaining this behavior even if the classes are unknown. According to the state-of-the-art review, adding the contrastive loss function to the CNNs causes the feature vectors to be mapped in near space (in terms of, e.g., Euclidean distance, cosine similarity, or some other metric) if they are similar and far if they are dissimilar.
Although there are CNN architectures such as VGG16, AlexNet, etc., that have achieved state-of-the-art results in the most well-known benchmarks such as ImageNet, CIFAR-100, etc., we propose a new domain-specific architecture that would generate the previously described behavior in feature vectors, using the images mentioned in
Section 3.1, an NE algorithm called DeepGA [
33] (shown in Algorithm 1), and SupCon [
35] expressed in Equation (2).
In [
35], the authors made their PyTorch implementation of SupCon generally available (
https://t.ly/supcon, accessed on 13 March 2023), and this was used in this work as a loss function in the CNNs generated in the NE process with DeepGA. (Originally, the negative log-likelihood loss was used.) The fitness function of DeepGA (Algorithm 1, line 15) was also modified to measure the desired behavior in feature vectors since optimization was the objective of our study. Thus, as the fitness function, we used the value of SupCon in the last training epoch of each generated CNN. Since the loss function decreases as the desired output is approached, DeepGA was set to work as a minimization problem, i.e., as the generated CNNs approached the desired target, the value of the loss/fitness function decreased.
The hybrid coding employed in DeepGA allows the algorithm to consider the number of fully connected layers and their corresponding number of neurons in its search for the best solution. However, during the NE process, it was detected that leaving the number of fully connected layers to DeepGA only increased the complexity and execution time since with only two fully connected layers, classification accuracies above 90% were achieved. To limit the number of fully connected layers during the evolutionary process, the first level of the mutation operator was modified. At the first level of the mutation operator, if , a new block is added, and if , the added block is a fully connected layer; then, the operator was modified so that if , no block is added. This modification is shown in line 4 of Algorithm 2, which shows the mutation operator of DeepGA. This ensures that, during the whole evolutionary process, the generated networks only have two fully connected layers, allowing the algorithm’s search to focus on the blocks of convolutional layers since they would be in charge of generating the feature vectors with the desired behavior.
To access the feature vectors generated using the CNNs, the CNN class of DeepGA, which builds the model for training and testing, was modified. As output, this class only generated the probabilities of the images belonging to the different classes. The modification consisted of the addition of the flattened outputs of the convolutional block (feature vectors) to the original output to be able to access them in the next process (i.e., to distinguish objects from new classes and simultaneously discover these classes).
The last modification to the DeepGA algorithm was an improvement in image reading. The PyTorch ImageFolder function was used to be able to read the images of all classes in a single process instead of reading the images of each class individually.
| Algorithm 1: DeepGA pseudocode. |
1 Input: A population P of N individuals. The number of generations T,
2 crossover rate CXPB, mutation rate MUPB, tournament size TSIZE.
3 Output:
4 Initialize population (training the networks).
5 t ← 1
6 while t ≤ T do
7 Select N/2 parents with probabilistic tournament selection
8 Offs ← {}
9 while |Offs| < N/2 do
10 Select two random parents p1 and p2.
11 if random(0,1) ≤ CXPB then
12 O1, O2 ← Crossover(p1, p2) // Crossover
13 if random(0,1) ≤ MUPB then
14 Mutation(O1, O2) // Mutation (modified)
15 fitness(O1, O2) (Equation (1)) // Evaluation (modified)
16 P ← P ∪ Offs
17 Select the best N individuals in P as survivals.
18 end
19 end |
| Algorithm 2: Mutation process DeepGA. |
1 if random(0,1) ≤ MUPB then
2 if random(0,1) ≤ U1 then // Adding a new block
3 if random(0,1) ≤ 𝑈2 then
4 A convolutional block is added // Removed
5 else
6 A fully connected block is added
7 else // Restarting a block
8 if random(0,1) ≤ W1 then
9 Restarting a convolutional block
10 else
11 Restarting a fully connected block |
3.3. Neuroevolved CNN
The CNN architecture with the best fitness generated using DeepGA and SupCon was split to fulfill two purposes. First, the goal was to train the convolutional block with the contrastive loss function and the fully connected block with the cross-entropy loss function, using the full test set described in
Section 3.1 (200 images of each of the five “
known classes”), and to perform a classification accuracy test momentarily assuming a closed-set environment to validate that a good classification accuracy could be obtained since it is an essential point for OSR. Second, we sought to have the feature extraction process and the classification process separate since the detection of new class objects and the discovery of their classes must be accomplished between these events.
3.4. Gaussian Mixture Model (GMM) and Clustering
The main objective of this work is to approach VMMR as an OSR problem with an extension for the discovery of new classes. To achieve this, we divided our strategy into two phases, both relying on the consistent distribution of feature vectors in the embedded space generated using DeepGA and SupCon.
The first phase consisted of extracting the feature vectors from the images used to train the CNN and validating its classification accuracy. The feature vectors were compressed using principal component analysis (PCA) where the second and third components, which contributed 27.81 and 20.97 to the percentage of variance, respectively, were selected to perform a linear regression on the original feature vectors to obtain their projections. As mentioned in
Section 3.1, with the same proportion of data with which the CNN was trained and tested (80–20%), the 2D projections of the feature vectors were used to model each “
known class” with a Gaussian mixture model (GMM) and define a recognition threshold of “
known classes”. In the test stage, where objects of both known and unknown classes were included, the GMM divided the objects as a group of unknown classes that did not pass the threshold and subsets of known classes whose probabilities matched the “
known class” models. The above only served as a partial guide in the recognition of new class objects since, in the second phase of the strategy, a multiobjective clustering algorithm with automatic determination of the number of clusters (MOCKs) was employed and optimized with a multiobjective evolutionary algorithm (MOEA), called NSGA-II [
40].
In the second phase, the clustering algorithm grouped the feature vectors extracted using the domain-specific CNN without any modification in their dimensionality. Since the GMM can determine the objects of known classes and their respective classes with some confidence, due to the threshold, we compared the subgroups of known classes generated using the GMM with the solutions of MOCK/NSGA-II to select the individual from the population with the highest similarity, where different criteria were used. First, the solutions that grouped the instances that the GMM determined as known and were in the same structures (subgroups) as the GMM had a higher score (one point for each shared structure). Although all the solutions of the clustering algorithm were optimal for the problem, we selected the solution that had the highest score (higher match with the GMM in the known classes) and was closest to the knee point as the “best solution”.
Finally, we determined which clusters of the “best solution” contain known objects and separated them from the clusters containing unknown objects in a similar way to how the solutions were scored. Then, since the GMM also detected the objects of unknown classes (the objects that did not pass the threshold) with some confidence, those clusters that only contained objects that the GMM determined as unknown were automatically determined as new classes. After these processes, if there were still undetermined clusters as known or unknown, the number of known and unknown instances within the undetermined clusters were counted (according to the GMM determination), and the clusters were defined in the same category as that containing the majority of instances or as unknown if it contained the same number of examples to try to mitigate the open-set risk.
At the end of this strategy, the objects of the clusters that were determined as known were entered into the CNN’s fully connected block to be classified, and the clusters that were determined to be unknown were the newly discovered classes of the objects detected as unknown.
The original version of the MOCK algorithm was proposed in 2004 by Handl et al. [
41] and employed the MOEA called PESA-II. In 2016, Martinez-Peñaloza et al. [
42] managed to improve the results by using the MOEA NSGA-II instead of PESA-II. In the MOCK version improved with NSGA-II, individuals are ranked and sorted according to their non-dominated level, and a crowding distance is used to perform niching. This distance is calculated for each member to be used by the selection operator to maintain a diverse front by ensuring that each member stays a crowding distance apart. Algorithm 3 shows NSGA-II’s pseudocode.
| Algorithm 3: NSGA-II pseudocode. |
1 Initialize Population
2 Generate random population -size M
3 Evaluate Objective values
4 Assign Rank (level) Based on Pareto Dominance -”sort”
5 Generate Child Population
6 Binary Tournament Selection
7 Recombination and Mutation
8 for i = 1 to Number of Generations do
9 for each Parent and Child in Population do
10 Assign Rank (level) Based on Pareto –”sort”
11 Generate sets of non-dominated fronts
12 Loop (inside) by adding solutions to next generation starting
13 from the “first” front until M individuals found determine
14 crowding distance between points on each front
15 end
16 Select points (elitist) on the lower front (with lower rank) and
17 are outside a crowding distance. Create next generation
18 Binary Tournament Selection
19 Recombination and Mutation
20 end |
4. Experiments and Results
This section describes the experiments and results obtained from our proposal to approach VMMR as an OSR problem with an extension for new class discovery.
For the neuroevolution process of CNNs performed with DeepGA [
33] and SupCon [
35], as mentioned in
Section 3.1, six images of each “
known class” taken from the VMMRdb [
37] database were used.
The parameters described in
Table 1 were used to initialize the population. Due to time constraints, it was not possible to use a parameter calibration program. Then, the parameters for the evolutionary process were calibrated manually. The parameters with which the best results were obtained, and which were used to generate the CNNs are shown in
Table 2. The different values that each hyperparameter could have during the evolutionary process were the same as those established by the author of DeepGA and are presented in
Table 3.
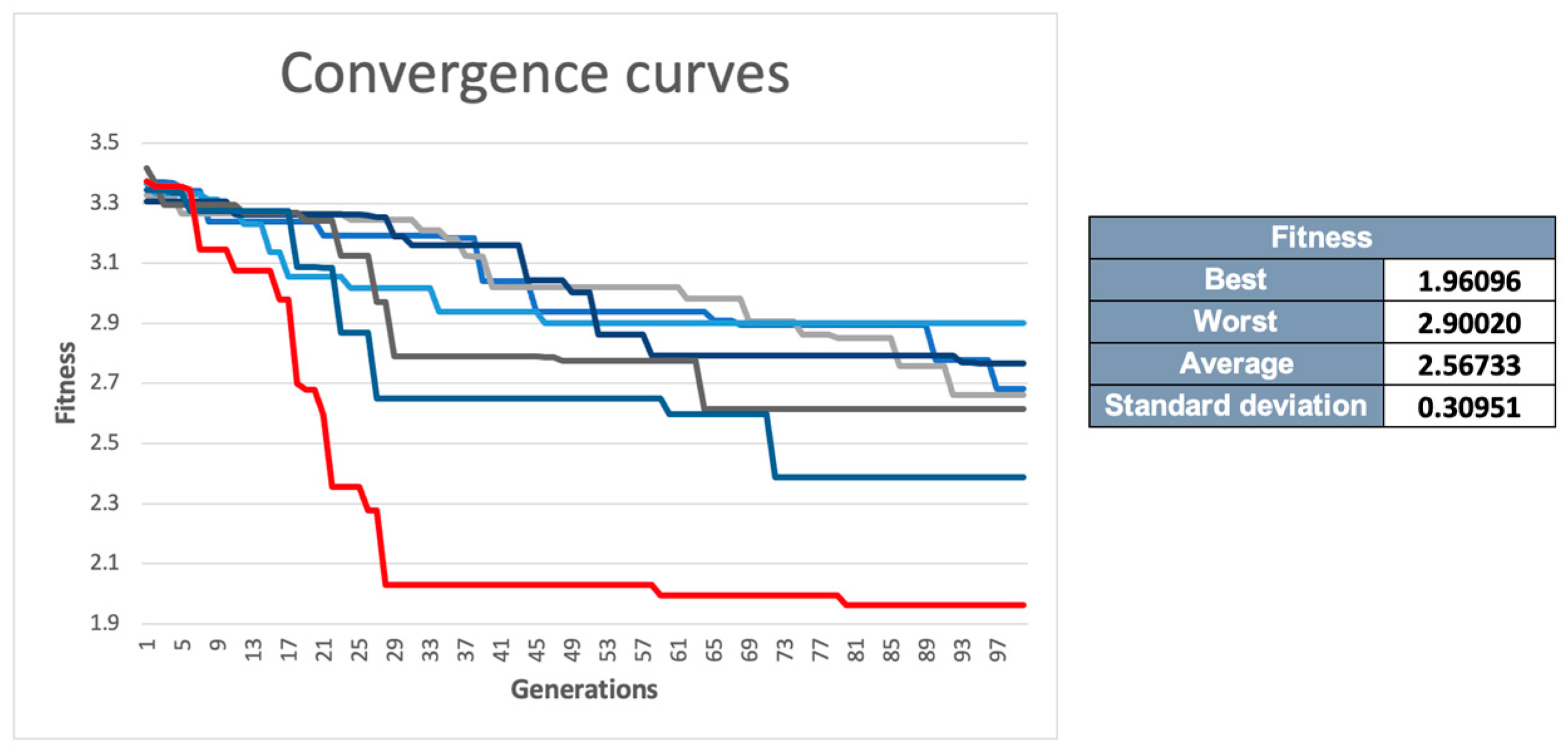
Seven executions of the NE process with DeepGA and SupCon were performed.
Figure 2 shows the convergence curves of the seven executions and a short analysis of the fitness values obtained in each one. As can be seen, all the executions started with a fitness within a range of 3.3 and 3.5, and most reached premature convergence or stalled at local optima. However, one of the executions (marked in red) achieved a more accurate search space that led to a fitness value of 1.96096.
The CNN with the best fitness obtained in the NE process (henceforth referred to as the “domain-specific CNN”) had a value of 1.96096, which was the value of SupCon in the last training epoch of the CNN (its justification is explained in
Section 3.2 in more detail) and took 7 h to execute in the Visual Studio Code editor running on a MacBook Pro with a 2.2 GHz Quad-Core Intel Core i7 processor with 16 GB 1600 MHz DDR3 of memory.
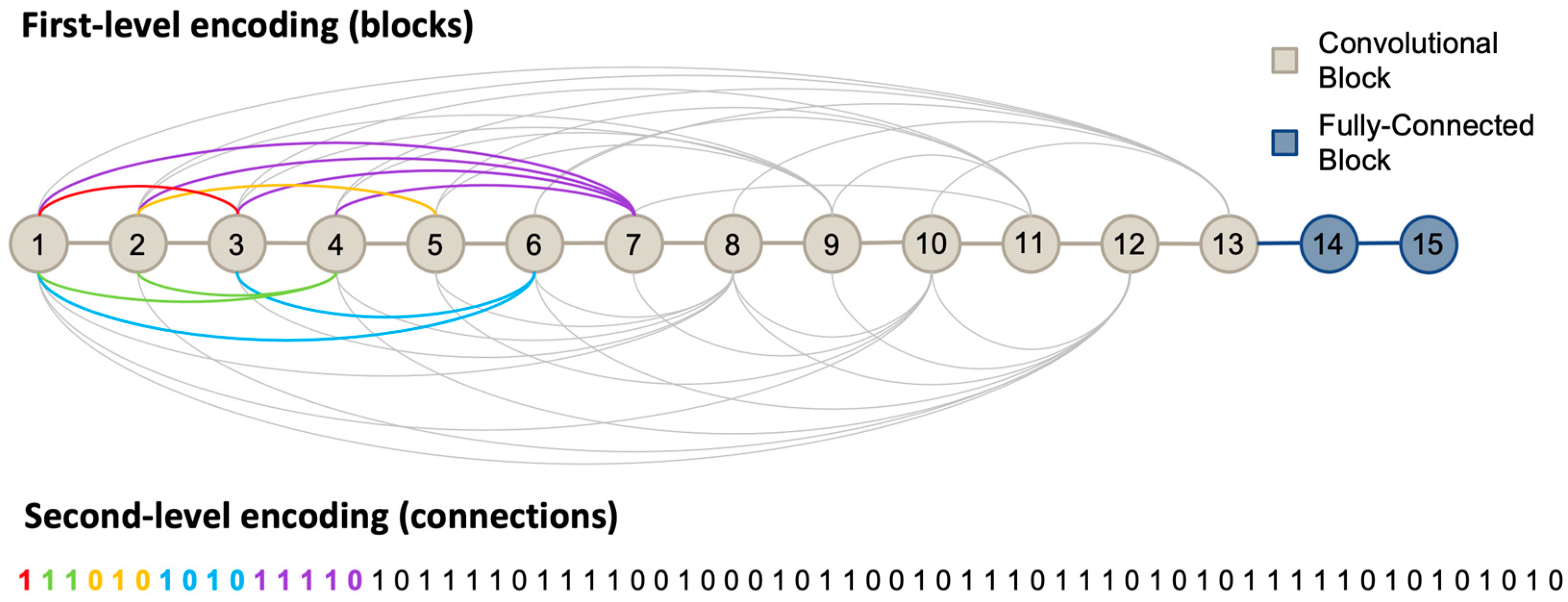
Figure 3 illustrates the architecture in terms of its encoding. In the first level, it can be observed that the architecture has 13 convolutional blocks (each one consisting of a single convolutional layer) and 2 fully connected blocks (each one comprising a single layer and a fully connected layer). The last convolutional block/layer generates feature vectors of 288 features. At the second level, the binary string defines the connectivity between convolutional blocks. Each bit represents the connectivity of a previous non-consecutive layer, starting from the third block. For a better understanding, we will explain three examples to understand the connections. The third convolutional block (first bit marked in red) can only have connections with previous blocks that are not its immediately previous consecutive block, so the third block cannot have a connection with the second convolutional block, but it can with the first one, which is why only one bit is assigned to it, and the bit value is 1. This means that there is a connection, which is represented by the red line on the first level. The next two bits (green) are for the fourth block, which can have a connection with the first or second block, and since the bit values are 1, both connections exist (represented by the green lines on the first level). A different case is shown in the next three bits (highlighted in yellow) assigned to the fifth block, which can have connections with the first, second, and third blocks; however, of those three bits, only the second one has a value of 1, which means that the fifth block only connects to the second block.
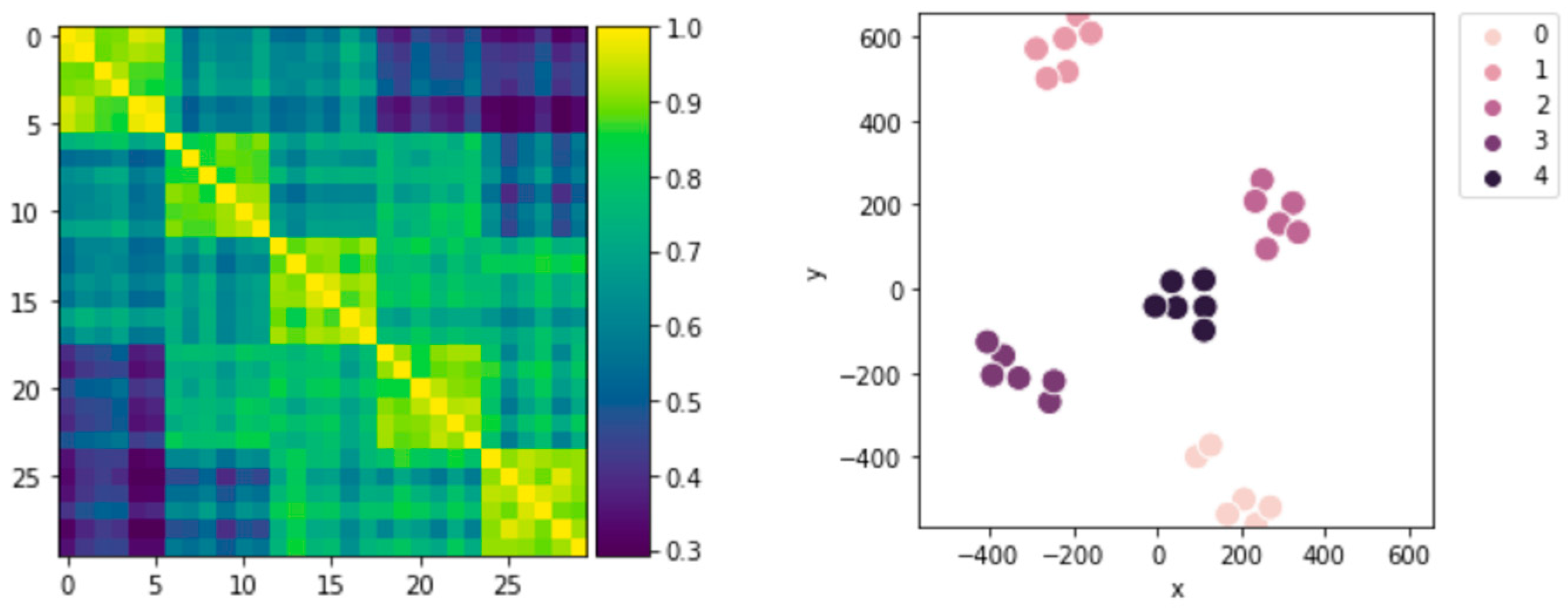
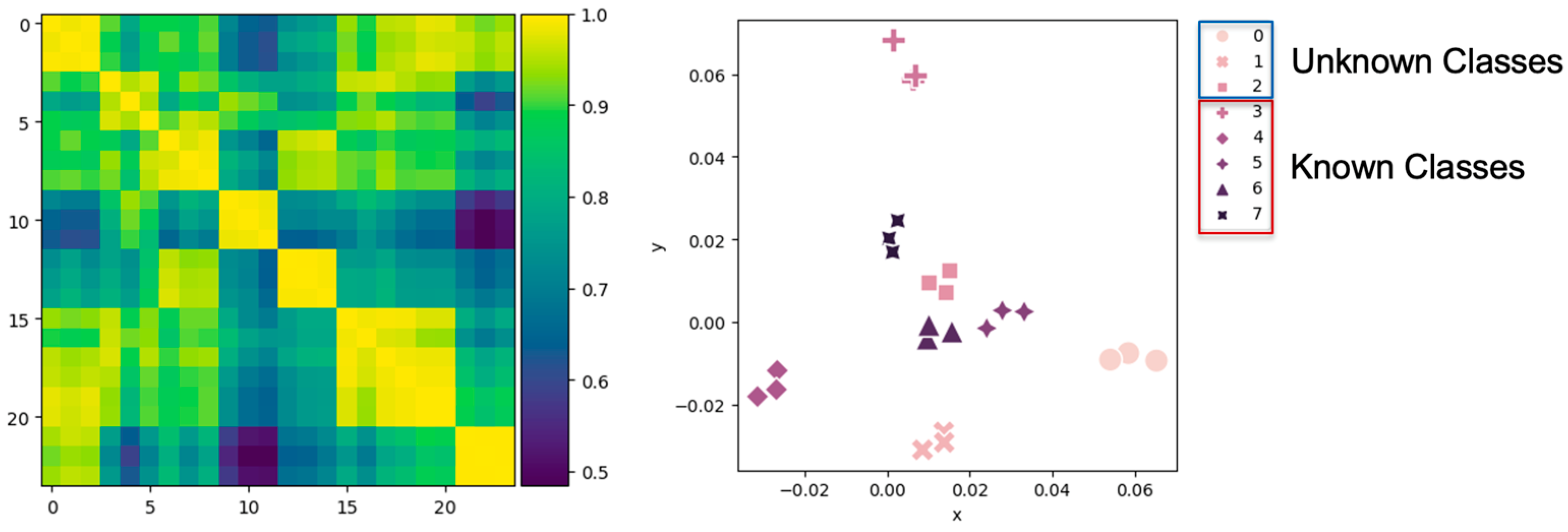
To verify that the domain-specific CNN could generate the feature vectors extracted spatially close in terms of cosine similarity if they belong to the same class and far apart if they belong to different classes, a distance matrix using cosine similarity as the metric was generated with the feature vectors obtained in the last training epoch of the domain-specific CNN. On the same feature vectors, the t-SNE [
43] technique was used to reduce the dimensionality from 288 to 2 in order to visualize them in a two-dimensional plane. The results of the distance matrix and t-SNE are shown in
Figure 4. By means of these two techniques, it could be seen that the desired behavior in the feature vectors was achieved.
As mentioned in
Section 3.3, the domain-specific CNN was split to train the convolutional block with the contrastive loss function and the fully connected block with the cross-entropy loss function. For the training process, 1000 images of rear views of vehicles of the five “
known classes” (200 images of each class) were used. A classification accuracy test was performed using 250 images of rear views of vehicles of the five “
known classes” (50 images of each class) momentarily assuming a closed-set environment to validate that good classification accuracy was being achieved since it is an essential point for OSR. A 90% classification accuracy was reached during this test; more details regarding the data used are presented in
Section 3.1.
The next test was to verify that the domain-specific CNN could generate feature vectors spatially close in terms of cosine similarity if they belong to the same class and far apart if they belong to different classes. This behavior was maintained in objects of unknown classes since the detection of objects of new classes and the discovery of their classes depended on this behavior. For this, the testing images, both the nine testing images of “
unknown classes” shown in
Figure 5 on the right and the fifteen images of the five “
known classes” shown in
Figure 5 on the left, were entered into the convolutional block of the domain-specific CNN to extract their feature vectors. To visualize the results, which are shown in
Figure 6, a distance matrix using cosine similarity as the metric was generated, and a two-dimensional projection was performed using linear regression with the two components described in
Section 3.4.
Figure 6 shows that the domain-specific CNN managed to generate feature vectors close in terms of cosine similarity if they belonged to the same class and distant if they belonged to different classes and managed to maintain such behavior even in objects of “
unknown classes”.
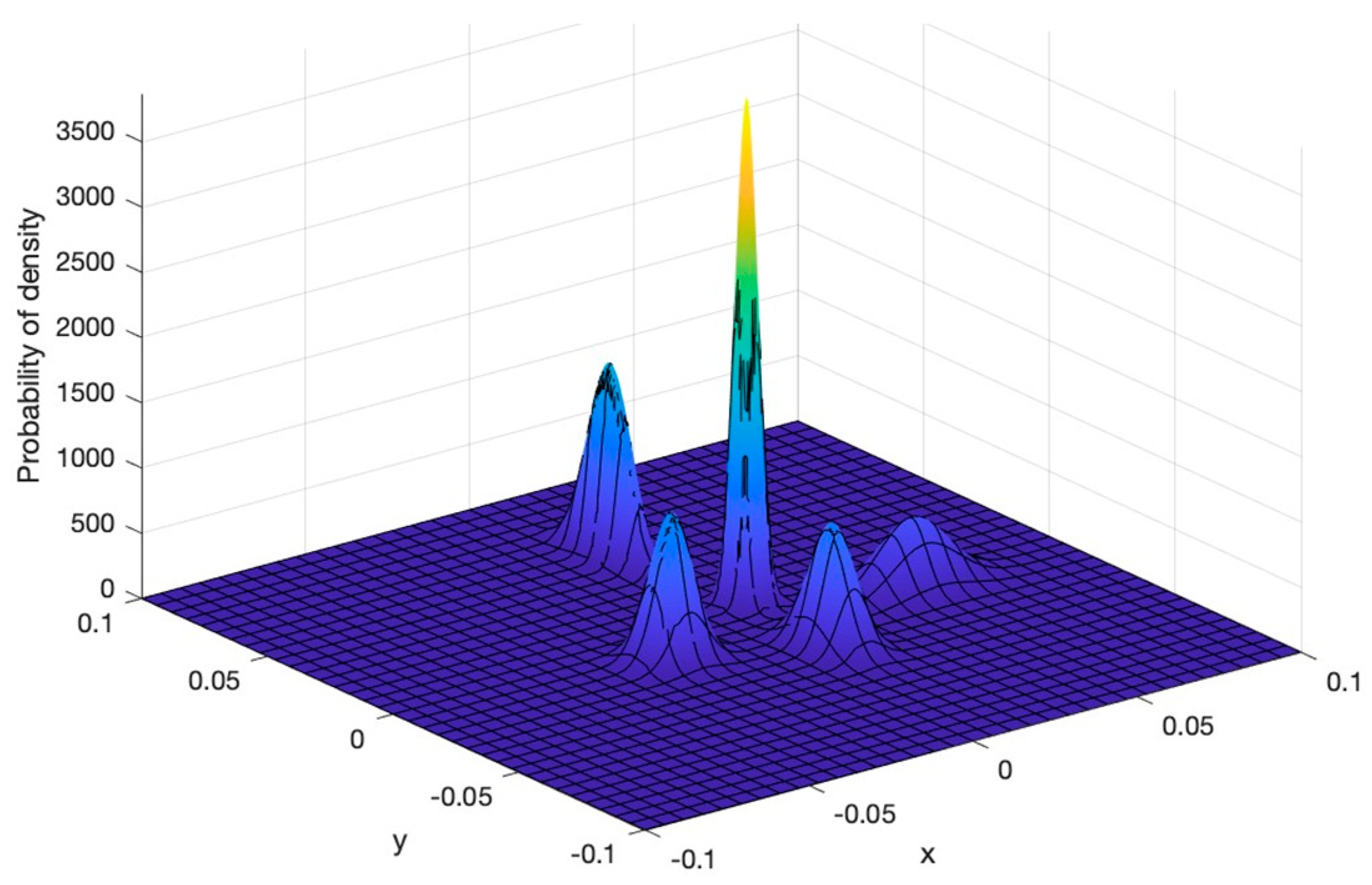
Later, the feature vectors of the images used to train the domain-specific CNN and validate its classification accuracy were compressed to two dimensions, and a linear regression was performed on these feature vectors to obtain their projections using the two components described in
Section 3.4. With the projections of the 1000 images used to train the domain-specific CNN, we modeled the “
known Classes” using a GMM, and the distribution of the Gaussians is shown in
Figure 7. We then defined a “
known class” recognition threshold within the GMM with a value of 9.999, using the projections of the 250 images that were used in the domain-specific CNN classification accuracy test.
Finally, the strategy proposed in
Section 3.4 was carried out to detect the objects of new classes and discover their classes. The first step was to enter the two-dimensional projections used in
Figure 6, which contain objects of both known and unknown classes (
Figure 5), into the GMM to obtain their density probabilities. As its output, the model provided the probability of each object belonging to the known classes, and the threshold allowed us to set a probability limit for known or unknown classes. As can be seen in
Table 4, the objects of known classes were correctly identified within their classes, and in the case of the objects of unknown classes, it can be seen that with the limit marked by the threshold, eight of the nine objects were correctly identified as unknown. A clearer representation of the results obtained can be seen in
Figure 8, which indicates that the GMM divided the objects as a set of unknown classes that did not pass the threshold as well as the subsets of known classes whose probabilities matched the known class models.
As previously mentioned, the GMM results were the first phase of the strategy and only served as a partial guide in the recognition of objects of unknown classes. In the second phase of the strategy, a clustering algorithm called MOCK was used, which was enhanced with NSGA-II. For the second phase, the 24 feature vectors without projection (288 features) were entered into the clustering algorithm. For execution, the algorithm was run with the parameters shown in
Table 5.
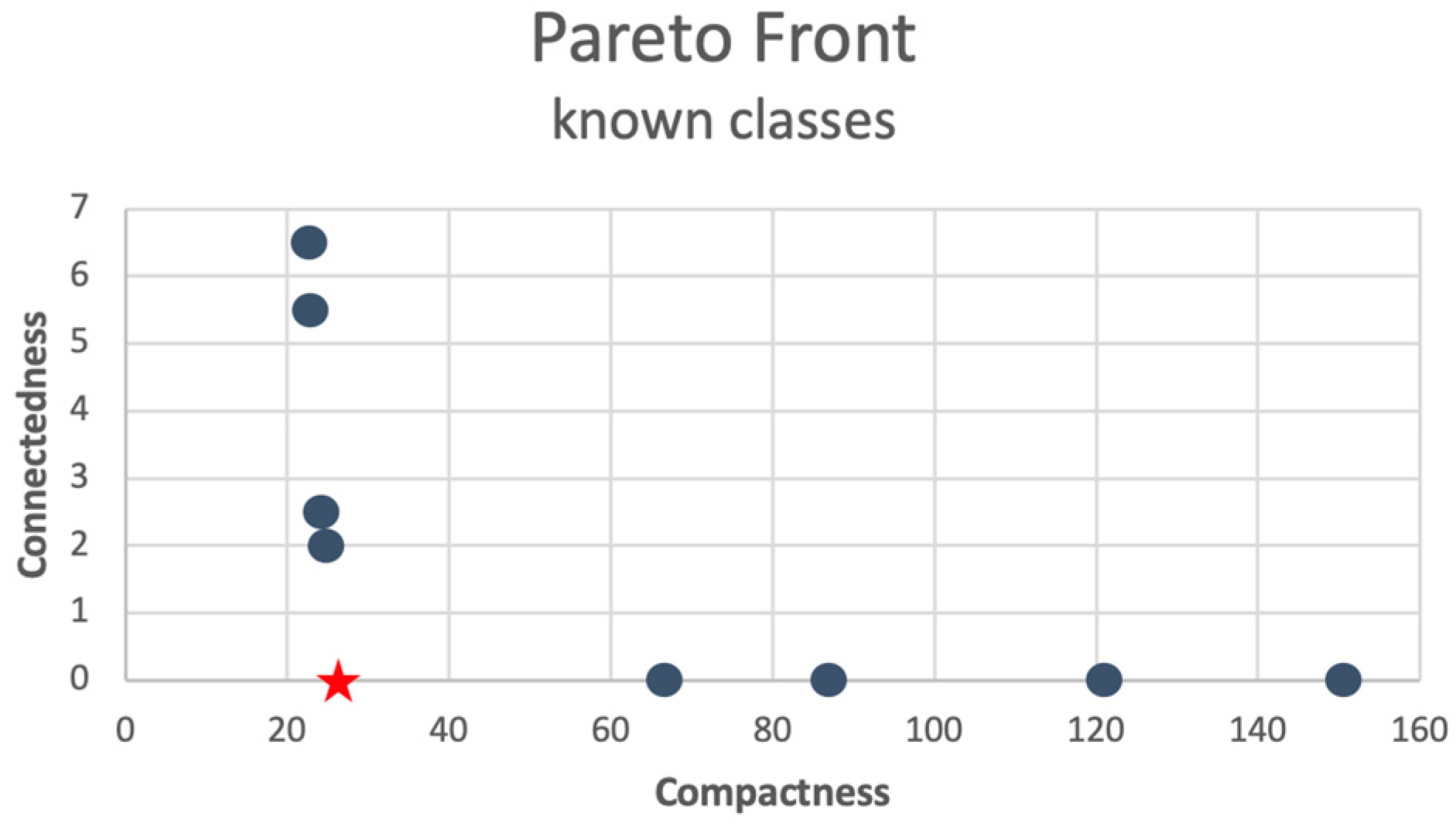
The nine final individuals of the clustering process are shown in
Figure 9 in terms of their fitness values, and
Figure 10 shows how the vectors were grouped in different structures.
Subsequently, the comparison described in
Section 3.4 was performed to select the “best solution”. The individuals generated using the MOCK/NSGA-II algorithm (
Figure 10) and the known class subgroups generated using the GMM (
Figure 8) were compared. The results of this comparison are shown in
Table 6. It can be seen that Solutions 1, 2, 3, and 5 have four structures shared with the subgroups of known classes generated with the GMM. However, since the solution closest to the knee point was selected as the “best solution”, Solution 5 was chosen (marked with *), which in this case, was found to be the knee point, marked in red in
Figure 10.
Given the “best solution”, the four clusters with shared structures with the known class subgroups generated with the GMM were determined as “
known classes”. Then, the clusters containing only objects that the GMM determined as unknown, shown in
Figure 8, were determined as “
new classes”. The result of these processes can be seen in
Figure 11.
Since there were still unspecified clusters as
known or
new, we counted the number of known and unknown instances (as determined using the GMM) in the indeterminate clusters and defined the clusters in the same category as that comprising the majority of instances. Thus, we obtained five groups of “
known classes” and three “
new classes”, as shown in
Figure 12. Given the data in
Table 4, we can confirm that indeed the vectors of the “new classes” corresponded to the instances of unknown objects and that they were grouped in the same structure as their “unknown class”, thus confirming that both the “new classes” of objects of “unknown classes” can indeed be discovered.
Finally, the objects of known classes were entered into the classification section of the domain-specific CNN where a classification accuracy of 100% was obtained. Given the classification results obtained, we calculated the critical values of true positive (TP), false positive (FP), and false negative (FN) of both known and unknown classes. Subsequently, we calculated the micro-F1 score since it is one of the most commonly used metrics in OSR algorithms. The results obtained are shown in
Table 7.
5. Discussion and Conclusions
The main contribution of this work is to present a strategy to approach the VMMR as an OSR problem that is extended to the discovery of new classes, taking the distribution of feature vectors generated using a domain-specific CNN as the main guideline. This work seeks to highlight the importance of generating domain-specific OSR strategies and the need to apply them to real-world classification/recognition problems such as VMMR in order to obtain classifiers that are not only more accurate but also more robust, as they are prepared to face real-life scenarios. Although we focused on VMMR, the proposed methodology can be used as a benchmark for future domain-specific OSR problems and can be applied to other domains like handwritten digit recognition, chest X-ray classification, etc.
For the development of this work, we considered four main objectives to fulfill the purpose of approaching VMMR as an OSR problem extended for new class discovery. The fulfillment of our first objective could be validated with the results shown in
Figure 6, where it can be seen that the CNN designed through the NE process with contrastive loss managed to map within the embedded space the feature vectors close in terms of cosine distance if they belonged to the same classes and far away if they belonged to different classes, maintaining this behavior for both known and unknown classes.
The second objective was described in detail in
Section 3.4, which is the theoretical part of the third objective. In the
Section 4, the proposed methodology was described step by step, and the experiments carried out validated that the proposed mechanism is able to detect objects of unknown classes and simultaneously discover their classes. One point to highlight is that our strategy is not restricted by training data, as it can be adjusted as these data change. More precisely, by using contrastive learning to train the feature extraction of the domain-specific CNN, the distribution of feature vectors is not only guided by “known classes” but is able to perform a consistent mapping even for objects of “unknown classes”, which allows us to effectively detect objects of known classes and discover their classes simultaneously.
From the outset, we decided to employ a CNN not only to exploit the powerful ability of CNNs to extract meaningful features but also because these networks are known to be powerful classifiers. Therefore, since our domain-specific CNN was trained with numerous well-labeled examples, we could rely on its accuracy in classifying instances of known classes. Therefore, the last objective was met by achieving 100% classification accuracy of the images of the known classes in the test set.
Overall, the entire algorithm achieved a micro-F1 score of 1.00 by accurately classifying instances of known classes and effectively discovering the classes of instances whose classes were not included in the training. In a closed-set context, which is where most classification algorithms are developed, all instances of unknown classes would have been classified into some known class, so the model would not have been able to achieve a classification accuracy higher than 62.5% with the test set used in this work since 9 of the 24 test images belonged to unknown classes. The poor classification accuracy in this specific context, which simulates a real-life scenario, would be due to the incomplete knowledge of the world and not due to the classification potential that the classifier could achieve. Therefore, in this work, we proposed to add a mechanism to one of the most used image classifiers such as CNNs in order to detect objects of unknown classes and identify these classes. This highlights the possibility to expand the classification potential of CNNs and increase their robustness to work more effectively in real-life scenarios, thus enabling these classifiers not only to react to queries but also to continue learning even after being trained.
One of the limitations of this work was that due to time constraints, the neuroevolution algorithm was executed only seven times with the specified parameters, and it is left as future work to create a statistically more representative sample of executions and use a parameter calibration algorithm to possibly have better and more efficient results. It is also left as future work to increase the number of “known classes” to be able to classify more models with the domain-specific CNN and apply other OSR strategies to the VMMR problem for a more representative comparison.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}