
Prediction Interval for Compound Conway–Maxwell–Poisson Regression Model with Application to Vehicle Insurance Claim Data

Abstract
:1. Introduction
2. Compound CMP Regression Model
3. Parameter Estimation
3.1. Independent Compound Regression Model
3.2. Dependent Compound Regression Model
4. Prediction Intervals
5. Numerical Illustration
5.1. Simulation Study
- Generate , from the CMP distribution given in Equation (3) with mean by fixing and . Obtain .
- For each generate from the gamma distribution given in Equation (5) with mean by fixing and where for the independent compound regression model and for the dependent compound regression model. Compute and obtain .
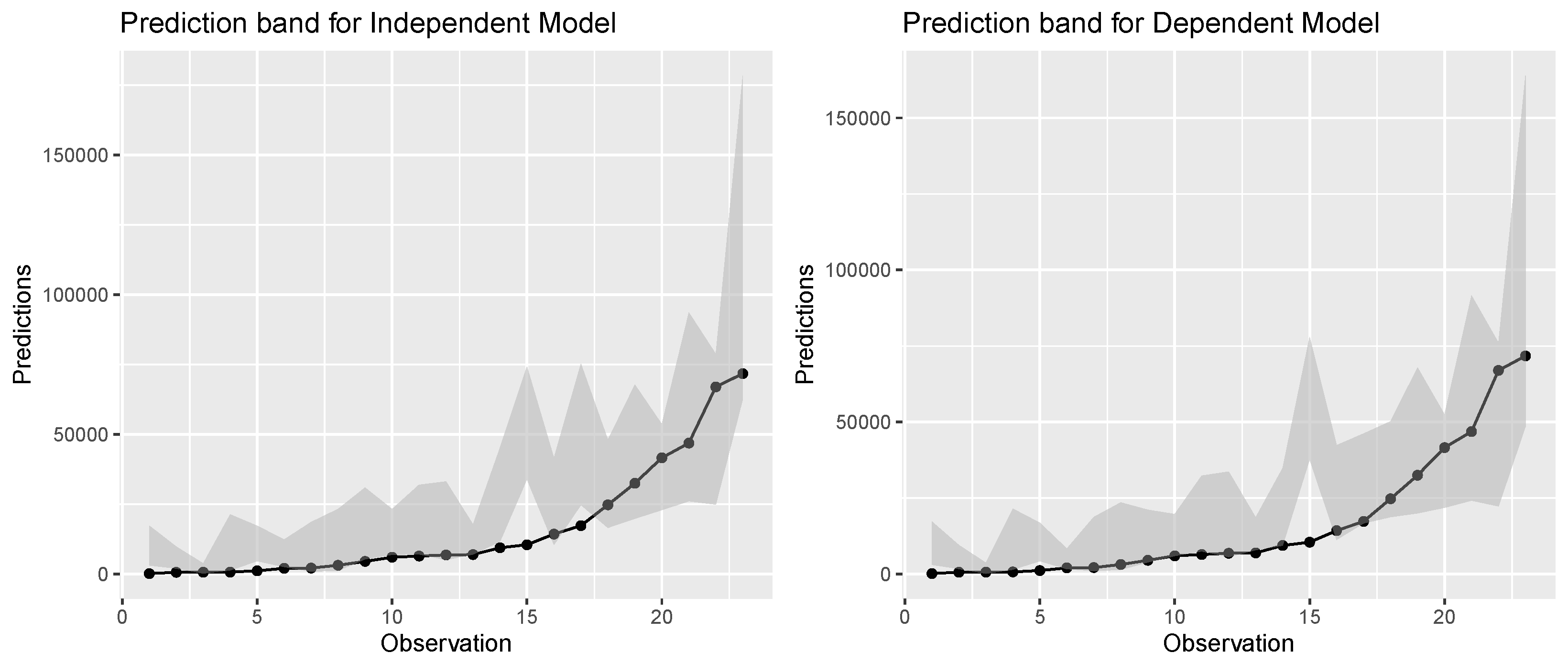
5.2. Real-Life Application
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Gómez-Déniz, E.; Pérez-Rodríguez, J.V. Modelling distribution of aggregate expenditure on tourism. Econ. Model. 2019, 78, 293–308. [Google Scholar] [CrossRef]
- Klugman, S.A.; Panjer, H.H.; Willmot, G.E. Loss Models: From Data to Decisions; John Wiley & Sons: New York, NY, USA, 2012; Volume 715. [Google Scholar]
- Bahnemann, D. Distributions for Actuaries; Casualty Actuarial Society: Arlington, VA, USA, 2015; Volume 2. [Google Scholar]
- Jørgensen, B.; Paes De Souza, M.C. Fitting Tweedie’s compound Poisson model to insurance claims data. Scand. Actuar. J. 1994, 1994, 69–93. [Google Scholar] [CrossRef]
- Consul, P.C.; Jain, G.C. A generalization of the Poisson distribution. Technometrics 1973, 15, 791–799. [Google Scholar] [CrossRef]
- Shmueli, G.; Minka, T.P.; Kadane, J.B.; Borle, S.; Boatwright, P. A useful distribution for fitting discrete data: Revival of the Conway-Maxwell-Poisson distribution. J. R. Stat. Soc. Ser. (Appl. Stat.) 2005, 54, 127–142. [Google Scholar] [CrossRef]
- Conway, R.W.; Maxwell, W.L. A queuing model with state dependent service rates. J. Ind. Eng. 1962, 12, 132–136. [Google Scholar]
- Sellers, K.F.; Borle, S.; Shmueli, G. The COM-Poisson model for count data: A survey of methods and applications. Appl. Stoch. Model. Bus. Ind. 2012, 28, 104–116. [Google Scholar] [CrossRef]
- Sellers, K.F.; Premeaux, B. Conway-Maxwell-Poisson regression models for dispersed count data. Wiley Interdiscip. Rev. Comput. Stat. 2021, 13, e1533. [Google Scholar] [CrossRef]
- Saavithri, V.; Priyadharshini, J.; Banu, Z.P. Compound COM-Poisson Distribution with Binomial Compounding Distribution. Available online: https://www.internationaljournalssrg.org/uploads/specialissuepdf/ICRMIT/2018/MTT/ICRMIT-P122.pdf (accessed on 15 January 2023).
- Frees, E.W.; Gao, J.; Rosenberg, M.A. Predicting the frequency and amount of health care expenditures. N. Am. Actuar. J. 2011, 15, 377–392. [Google Scholar] [CrossRef]
- Andersen, D.A.; Bonat, W.H. Double generalized linear compound Poisson models to insurance claims data. Electron. J. Appl. Stat. Anal. 2017, 10, 384–407. [Google Scholar]
- Delong, Ł; Lindholm, M.; Wüthrich, M.V. Making Tweedie’s compound Poisson model more accessible. Eur. Actuar. J. 2021, 11, 185–226. [Google Scholar] [CrossRef]
- Ribeiro, E.E., Jr.; Zeviani, W.M.; Bonat, W.H.; Demétrio, C.G.; Hinde, J. Reparametrization of COM-Poisson regression models with applications in the analysis of experimental data. Stat. Model. 2020, 20, 443–466. [Google Scholar] [CrossRef]
- Jorgensen, B. The Theory of Dispersion Models; CRC Press: Boca Raton, FL, USA, 1997. [Google Scholar]
- De Jong, P.; Heller, G.Z. Generalized Linear Models for Insurance Data; Cambridge University Press: Cambridge, UK, 2008. [Google Scholar]
- Garrido, J.; Genest, C.; Schulz, J. Generalized linear models for dependent frequency and severity of insurance claims. Insur. Math. Econ. 2016, 70, 205–215. [Google Scholar] [CrossRef] [Green Version]
- Ribeiro, E.E., Jr. Cmpreg: Reparametrized COM-Poisson Regression Models, R Package Version 0.0.1; Available online: https://rdrr.io/github/JrEduardo/cmpreg/ (accessed on 15 January 2023).
- Dutang, C.; Charpentier, A. CASdatasets: Insurance Datasets. 2019. R Package Version 1.0-11. Available online: http://cas.uqam.ca/ (accessed on 15 January 2023).


{kind=link}
| m | Independent Model | Dependent Model | |
|---|---|---|---|
| 25 | −1.6 | 0.6667 | 0.9444 |
| 0 | 0.7777 | 0.8333 | |
| 1.6 | 0.8400 | 0.8400 | |
| 50 | −1.6 | 0.7353 | 0.8529 |
| 0 | 0.6500 | 0.7000 | |
| 1.6 | 0.7656 | 0.8297 | |
| 100 | −1.6 | 0.6615 | 0.9077 |
| 0 | 0.7088 | 0.9493 | |
| 1.6 | 0.7777 | 0.9393 |
| m | |||
|---|---|---|---|
| 25 |  |  |  |
| 50 |  |  |  |
| 100 |  |  |  |
| m | |||
|---|---|---|---|
| 25 |  |  |  |
| 50 |  |  |  |
| 100 |  |  |  |
| Covariates | CMP Regression Model | Gamma Regression Model (Independent Case) | Gamma Regression Model (Dependent Case) |
|---|---|---|---|
| (Intercept) | 1.5007 (< 2 × 10) | 5.7421 (< 2 × 10) | 5.7754 (< 2 × 10) |
| OwnerAge21–24 | 1.5885 (< 2 × 10) | −0.2010 (0.0670) | −0.1800 (0.0964) |
| OwnerAge25–29 | 2.6237 (< 2 × 10) | −0.1129 (0.2705) | −0.0497 (0.6357) |
| OwnerAge30–34 | 2.7585 (< 2 × 10) | −0.3276 (0.0034) | −0.2542 (0.0262) |
| OwnerAge35–39 | 2.8854 (< 2 × 10) | −0.3150 (0.0047) | −0.2271 (0.0496) |
| OwnerAge40–49 | 3.5362 (< 2 × 10) | −0.2722 (0.0081) | −0.1140 (0.3528) |
| OwnerAge50–59 | 3.3678 (< 2 × 10) | −0.1854 (0.0843) | −0.0590 (0.6219) |
| OwnerAge60+ | 3.0280 (< 2 × 10) | −0.3054 (0.0036) | −0.2120 (0.0553) |
| ModelB | 1.0255 (< 2 × 10) | 0.0584 (0.4260) | 0.1414 (0.0877) |
| ModelC | 0.6930 (< 2 × 10) | 0.1083 (0.1387) | 0.1500 (0.0450) |
| ModelD | −0.1889 (0.00485) | 0.4041 (6.01 × 10) | 0.3762 (2.40 × 10) |
| CarAge10+ | −1.9174 (< 2 × 10) | −0.8138 (< 2 × 10) | −0.9494 (5.87 × 10) |
| CarAge4–7 | −0.1558 (6.65 × 10) | −0.0615 (0.3959) | −0.0727 (0.3089) |
| CarAge8–9 | −1.4876 (< 2 × 10) | −0.4188 (8.64 × 10) | −0.5323 (2.02 × 10) |
| NClaims | - | - | −0.0010 (0.0301) |
| −0.8374 (< 2 × 10) | - | - | |
| - | 0.0667 | 0.0644 | |
| AIC | 984.7148 | 1125.6 | 1123.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Merupula, J.; Vaidyanathan, V.S.; Chesneau, C. Prediction Interval for Compound Conway–Maxwell–Poisson Regression Model with Application to Vehicle Insurance Claim Data. Math. Comput. Appl. 2023, 28, 39. https://doi.org/10.3390/mca28020039
Merupula J, Vaidyanathan VS, Chesneau C. Prediction Interval for Compound Conway–Maxwell–Poisson Regression Model with Application to Vehicle Insurance Claim Data. Mathematical and Computational Applications. 2023; 28(2):39. https://doi.org/10.3390/mca28020039
Chicago/Turabian StyleMerupula, Jahnavi, V. S. Vaidyanathan, and Christophe Chesneau. 2023. "Prediction Interval for Compound Conway–Maxwell–Poisson Regression Model with Application to Vehicle Insurance Claim Data" Mathematical and Computational Applications 28, no. 2: 39. https://doi.org/10.3390/mca28020039