
Computation of the Distribution of the Sum of Independent Negative Binomial Random Variables


Abstract
:1. Introduction
1.1. Sum of Negative Binomials
1.2. Normal and Negative Binomial Approximations
1.3. Finite-Sum Exact Expression
1.4. Approximation by Convolution
1.5. Saddlepoint Approximation
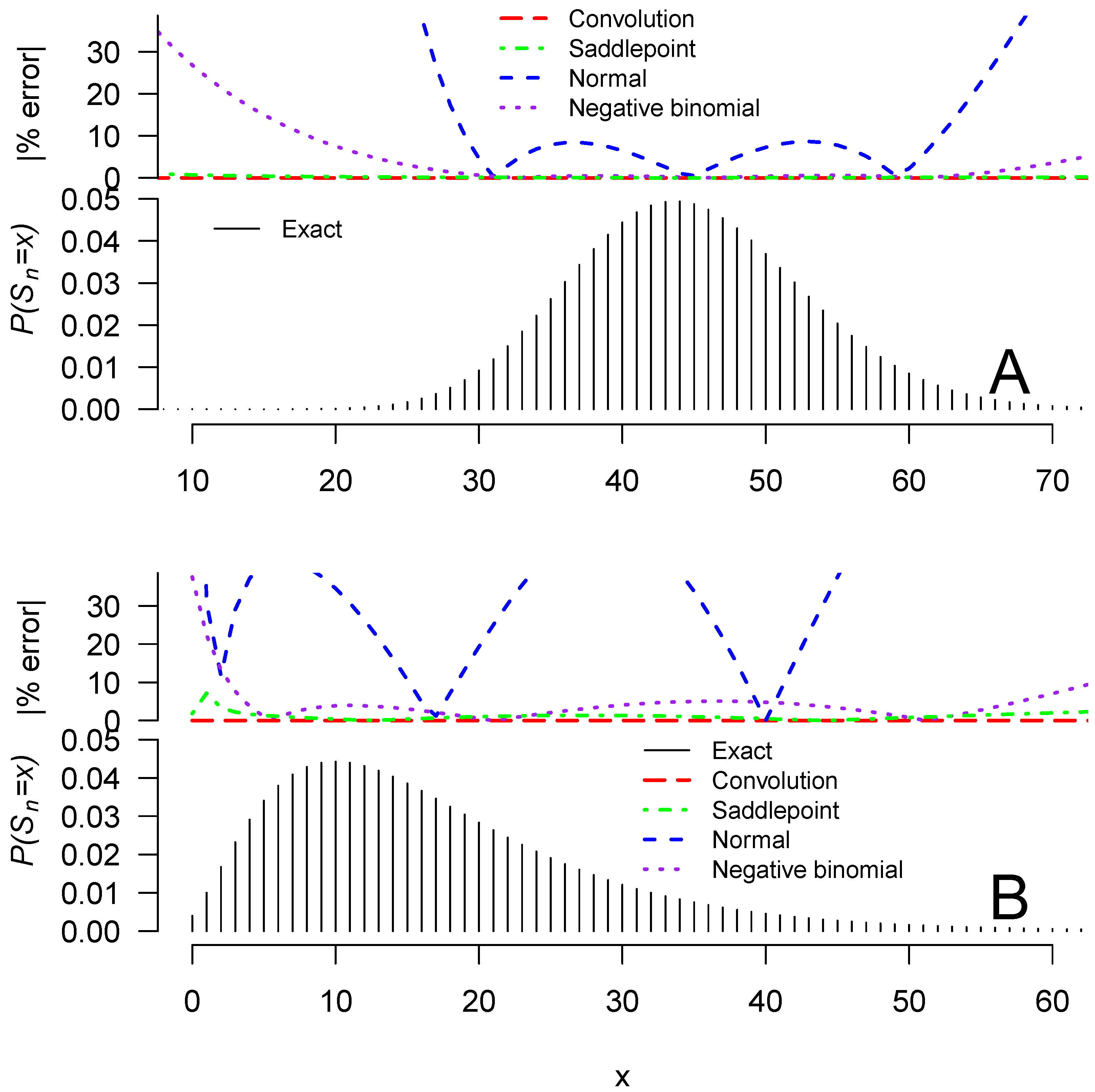
2. Computations
2.1. Normal and Negative Binomial Approximations
2.2. Finite-Sum Exact Expression
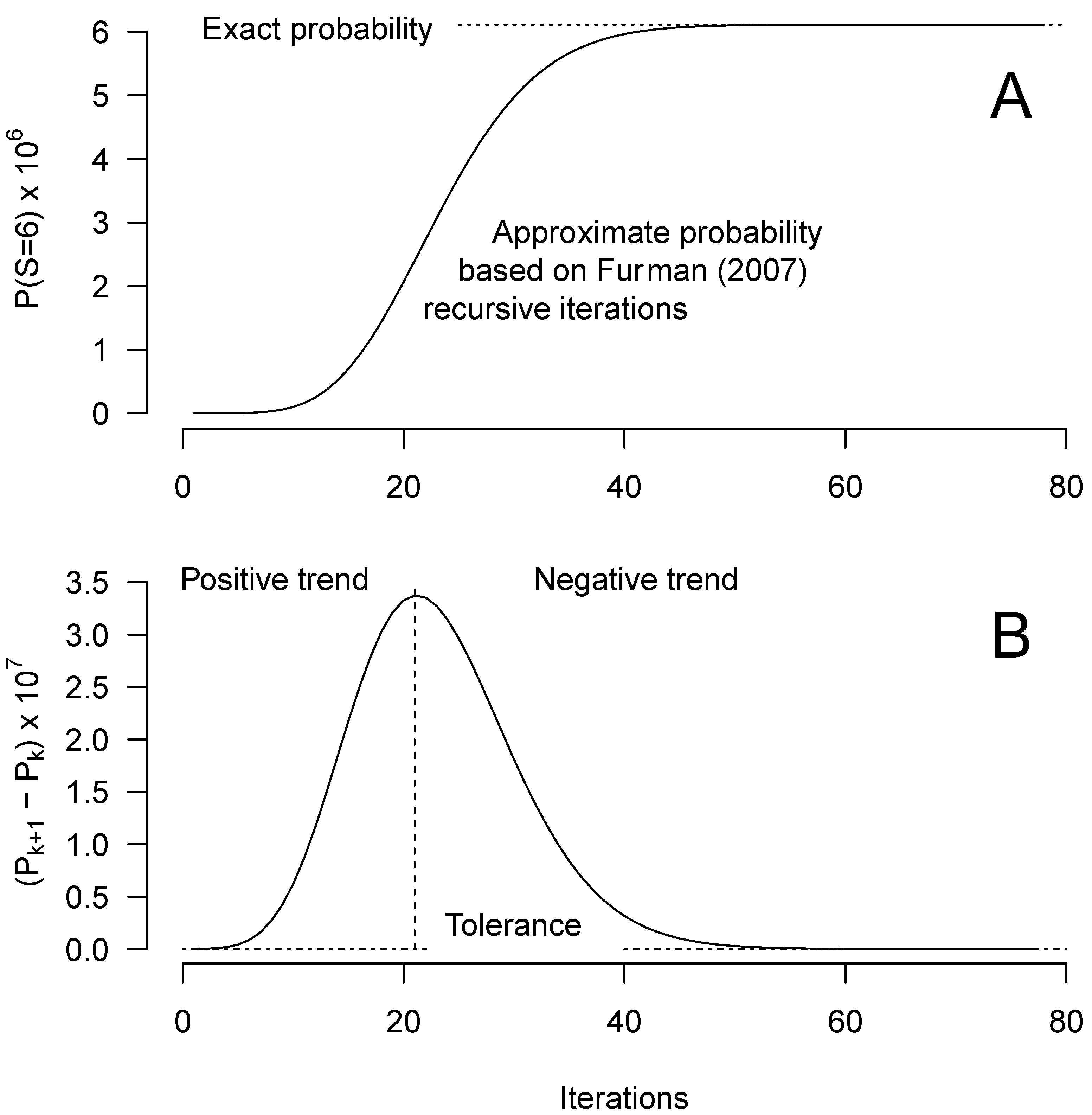
2.3. Approximation by Convolution
2.4. Saddlepoint Approximation
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Fisher, R.A.; Corbet, A.S.; Williams, C.B. The relation between the number of species and the number of individuals in a random sample of an animal population. J. Anim. Ecol. 1943, 12, 42–58. [Google Scholar] [CrossRef]
- Carlson, T. Negative binomial rationale. Proc. Casualty Actuar. Soc. 1962, 49, 177–183. [Google Scholar]
- Power, J.H.; Moser, E.B. Linear model analysis of net catch data using the negative binomial distribution. Can. J. Fish. Aquat. Sci. 1999, 56, 191–200. [Google Scholar] [CrossRef]
- Girondot, M. Optimizing sampling design to infer marine turtles seasonal nest number for low-and high-density nesting beach using convolution of negative binomial distribution. Ecol. Indic. 2017, 81, 83–89. [Google Scholar] [CrossRef]
- Omeyer, L.C.M.; McKinley, T.J.; Bréheret, N.; Bal, G.; Balchin, G.P.; Bitsindou, A.; Chauvet, E.; Collins, T.; Curran, B.K.; Formia, A.; et al. Missing data in sea turtle population monitoring: A Bayesian statistical framework accounting for incomplete sampling. Front Mar. Sci. 2022, 9, 817014. [Google Scholar] [CrossRef]
- Makun, H.J.; Abdulganiyu, K.A.; Shaibu, S.; Otaru, S.M.; Okubanjo, O.O.; Kudi, C.A.; Notter, D.R. Phenotypic resistance of indigenous goat breeds to infection with Haemonchus contortus in northwestern Nigeria. Trop. Anim. Health Prod. 2020, 52, 79–87. [Google Scholar] [CrossRef] [PubMed]
- Lee, H.; Lee, T. Demand modelling for emergency medical service system with multiple casualties cases: K-inflated mixture regression model. Flex. Serv. Manuf. J. 2021, 33, 1090–1115. [Google Scholar] [CrossRef]
- Korolev, V.; Gorshenin, A. Probability models and statistical tests for extreme precipitation based on generalized negative binomial distributions. Mathematics 2020, 8, 604. [Google Scholar] [CrossRef]
- Furman, E. On the convolution of the negative binomial random variables. Stat. Probab. Lett. 2007, 77, 169–172. [Google Scholar] [CrossRef]
- Johnson, N.; Kotz, S.; Kemp, A. Univariate Discrete Distributions, 2nd ed.; Wiley: New York, NY, USA, 1992. [Google Scholar]
- Vellaisamy, P.; Upadhye, N.S. On the sums of compound negative binomial and gamma random variables. J. Appl. Probab. 2009, 46, 272–283. [Google Scholar] [CrossRef]
- Baena-Mirabete, S.; Puig, P. Computing probabilities of integer-valued random variables by recurrence relations. Stat. Probab. Lett. 2020, 161, 108719. [Google Scholar] [CrossRef]
- Laplace, P.-S. Mémoire sur les approximations des formules qui sont fonctions de très grands nombres, et sur leur application aux probabilités. Mémoires Cl. Sci. Mathématiques Phys. L’institut Fr. 1809, 1809, 353–415. [Google Scholar]
- Daniels, H.E. Saddlepoint approximations in statistics. Ann. Math. Stat. 1954, 25, 631–650. [Google Scholar] [CrossRef]
- Brent, R. Algorithms for Minimization without Derivatives; Prentice-Hall: Englewood Cliffs, NJ, USA, 1973. [Google Scholar]
- Lugannani, R.; Rice, S. Saddle point approximation for the distribution of the sum of independent random variables. Adv. Appl. Probab. 2016, 12, 475–490. [Google Scholar] [CrossRef]
- Girondot, M. HelpersMG: Tools for Environmental Analyses, Ecotoxicology and Various R Functions; The Comprehensive R Archive Network: Indianapolis, IN, USA, 2023. [Google Scholar]



{kind=link}
{kind=link}
| A: Vellaisamy and Upadhye [11]: Exact Probabilities | No Parallel | Parallel 8-Core | |||||
| x = 3 | x = 5 | x = 8 | x = 10 | x = 15 | Time (s) | Time (s) | |
| n = 2 | 0.02320400 | 0.03403236 | 0.04283461 | 0.04425234 | 0.03856123 | 0.001 | 0.011 |
| 16 | 36 | 81 | 121 | 256 | |||
| n = 3 | 0.00273650 | 0.00730772 | 0.01724312 | 0.02421915 | 0.03607386 | 0.003 | 0.011 |
| 40 | 126 | 405 | 726 | 2176 | |||
| n = 4 | 0.00020980 | 0.00094784 | 0.00408465 | 0.00785680 | 0.02099302 | 0.014 | 0.012 |
| 80 | 336 | 1485 | 3146 | 13,056 | |||
| n = 5 | 0.00001503 | 0.00010490 | 0.00076597 | 0.00196540 | 0.00920145 | 0.062 | 0.015 |
| 140 | 756 | 4455 | 11,011 | 62,016 | |||
| n = 6 | 0.00000131 | 0.00001291 | 0.00014555 | 0.00047692 | 0.00365038 | 0.249 | 0.023 |
| 224 | 1512 | 11,583 | 33,033 | 248,064 | |||
| n = 7 | 0.00000017 | 0.00000218 | 0.00003427 | 0.00013604 | 0.00154413 | 0.906 | 0.049 |
| 336 | 2772 | 27,027 | 88,088 | 868,224 | |||
| B: Furman [9]: Convolution | |||||||
| x = 3 | x = 5 | x = 8 | x = 10 | x = 15 | Time (s) | ||
| n = 2 | 13 | 14 | 15 | 16 | 18 | 0.007 | |
| n = 3 | 19 | 20 | 23 | 24 | 27 | 0.008 | |
| n = 4 | 27 | 29 | 32 | 34 | 38 | 0.009 | |
| n = 5 | 39 | 42 | 45 | 48 | 54 | 0.009 | |
| n = 6 | 58 | 62 | 67 | 70 | 79 | 0.009 | |
| n = 7 | 92 | 97 | 104 | 109 | 122 | 0.011 | |
| C: Normalized Saddlepoint Approximation | |||||||
| x = 3 | x = 5 | x = 8 | x = 10 | x = 15 | Time (s) | ||
| n = 2 | 0.02372254 | 0.03448835 | 0.04314218 | 0.04442429 | 0.03841261 | 0.007 | |
| n = 3 | 0.00283042 | 0.00748306 | 0.01754862 | 0.02458058 | 0.03637448 | 0.007 | |
| n = 4 | 0.00021836 | 0.00097613 | 0.00418037 | 0.00802118 | 0.02132508 | 0.008 | |
| n = 5 | 0.00001571 | 0.00010840 | 0.00078653 | 0.00201341 | 0.00938611 | 0.008 | |
| n = 6 | 0.00000137 | 0.00001337 | 0.00014977 | 0.00048960 | 0.00373283 | 0.008 | |
| n = 7 | 0.00000018 | 0.00000226 | 0.00003531 | 0.00013984 | 0.00158133 | 0.018 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Girondot, M.; Barry, J. Computation of the Distribution of the Sum of Independent Negative Binomial Random Variables. Math. Comput. Appl. 2023, 28, 63. https://doi.org/10.3390/mca28030063
Girondot M, Barry J. Computation of the Distribution of the Sum of Independent Negative Binomial Random Variables. Mathematical and Computational Applications. 2023; 28(3):63. https://doi.org/10.3390/mca28030063
Chicago/Turabian StyleGirondot, Marc, and Jon Barry. 2023. "Computation of the Distribution of the Sum of Independent Negative Binomial Random Variables" Mathematical and Computational Applications 28, no. 3: 63. https://doi.org/10.3390/mca28030063