
Novel Triplet Loss-Based Domain Generalization Network for Bearing Fault Diagnosis with Unseen Load Condition

Abstract
:1. Introduction
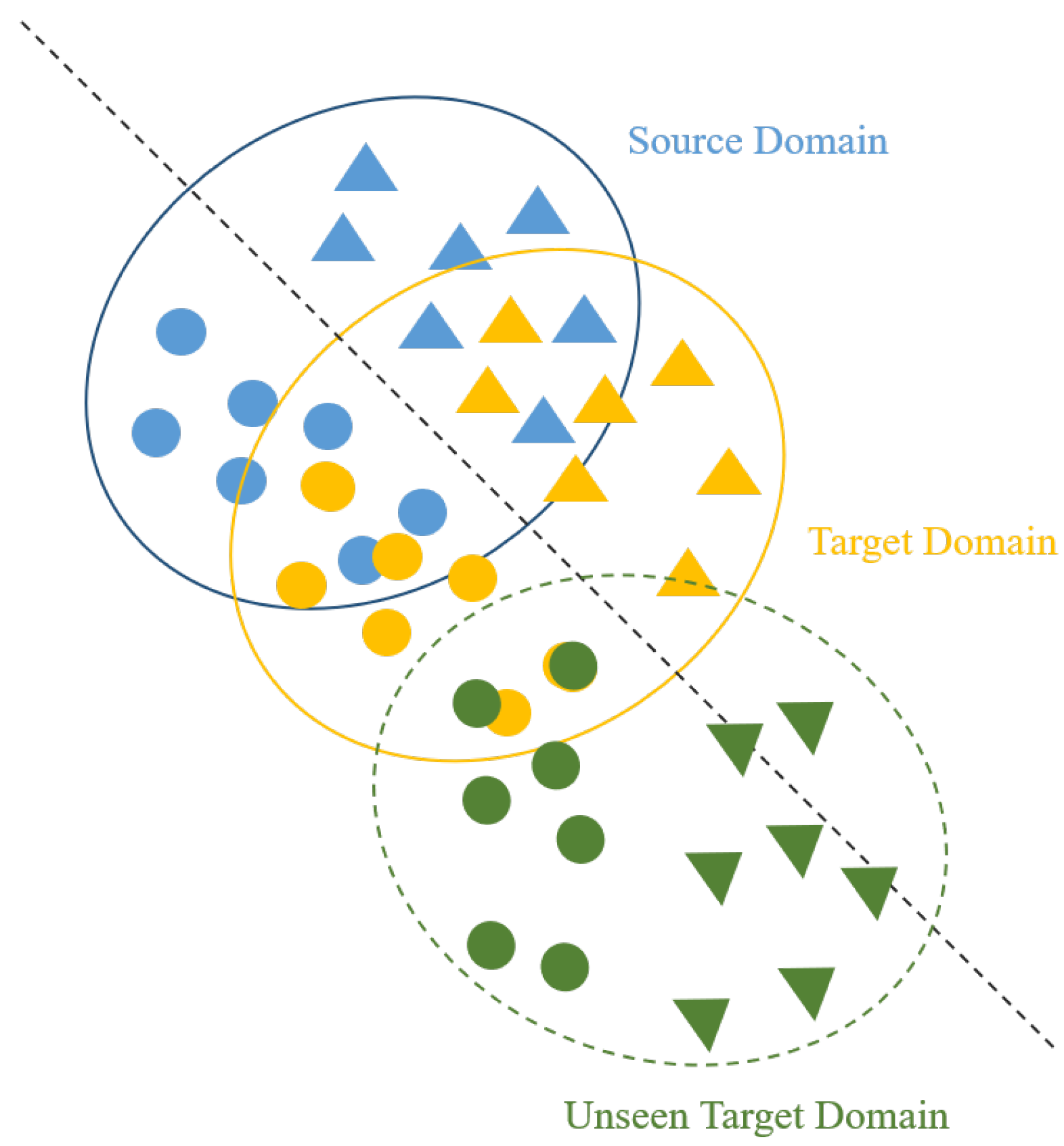
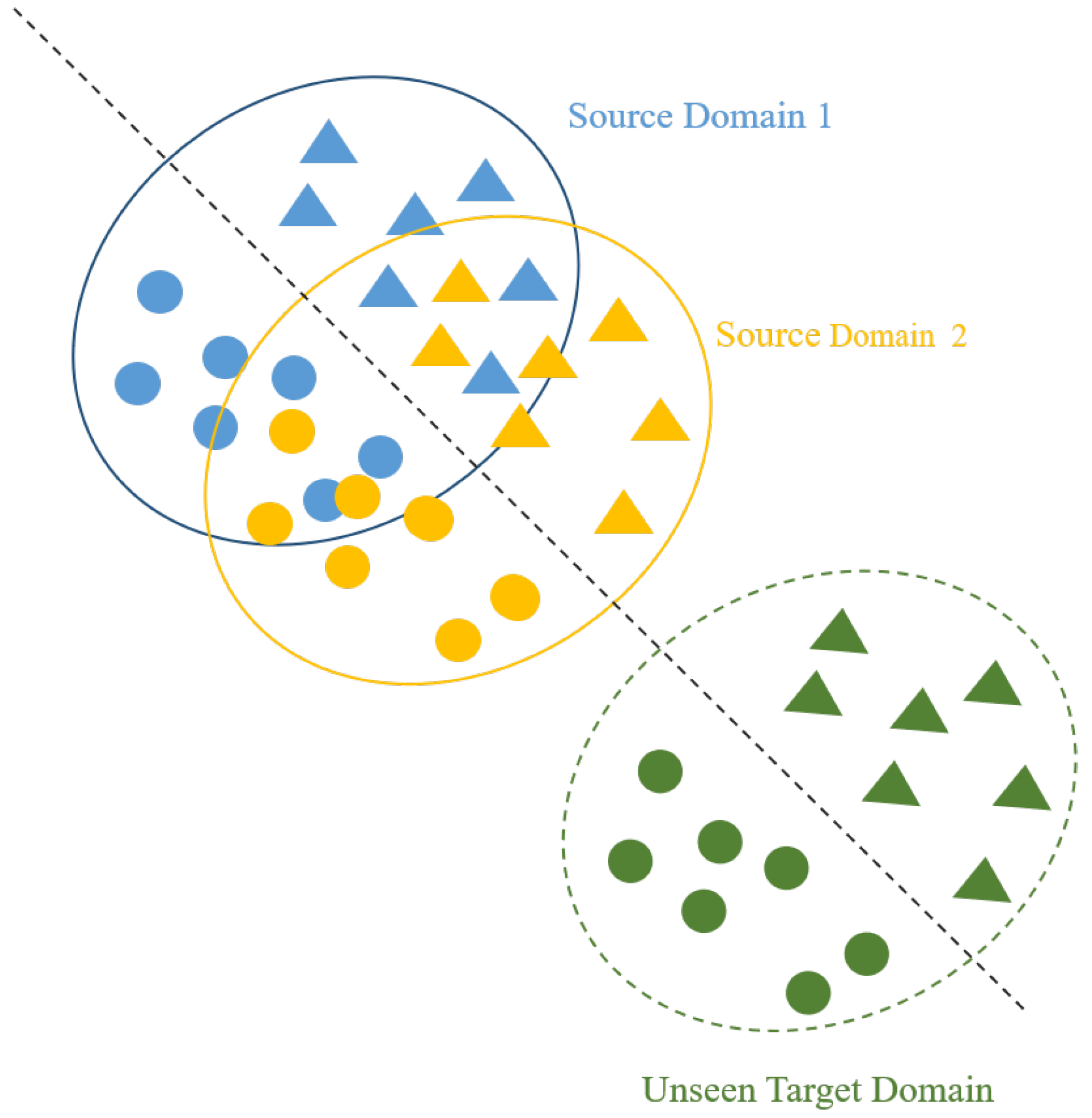
2. Brief Introduction of Domain Generalization
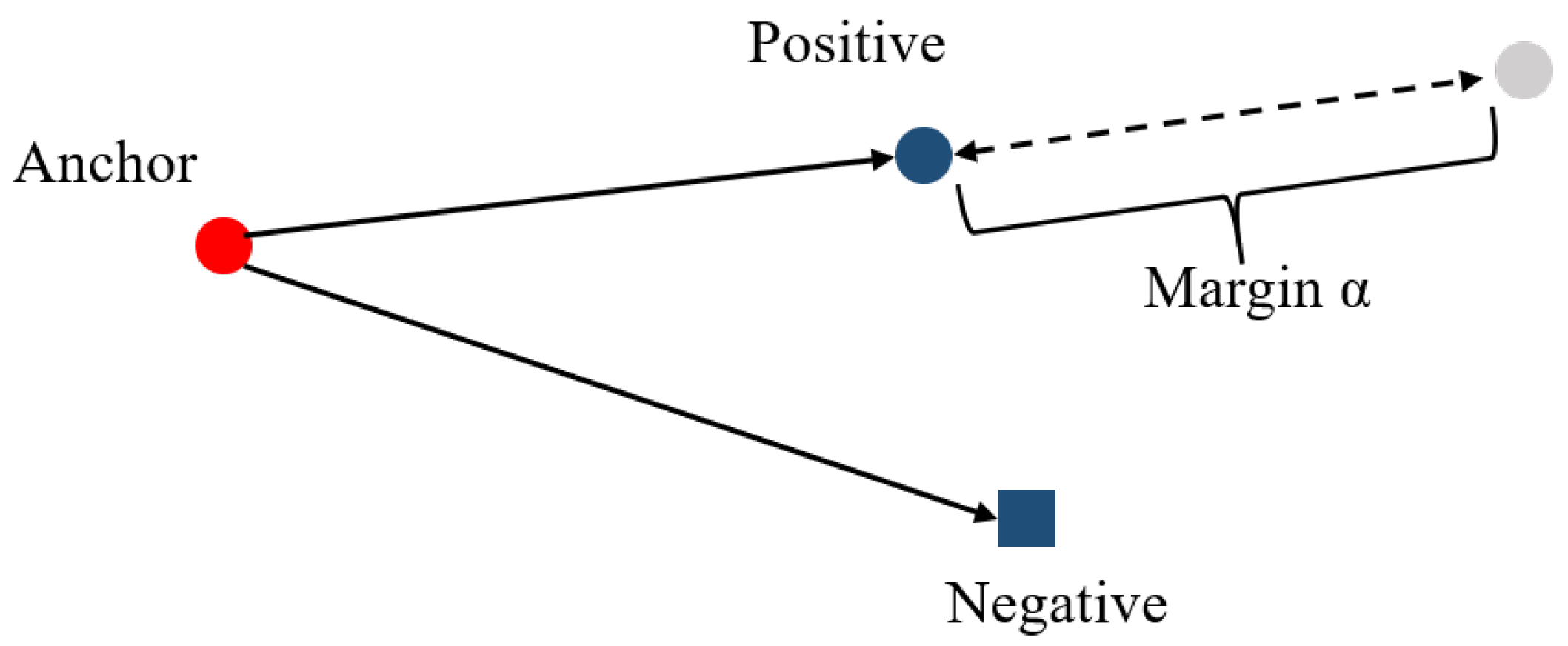
3. The Triplet Loss for Domain Generalization
- (1)
- are not equal, meaning all three samples are different.
- (2)
- The anchor sample and the positive sample belong to the same category, while the anchor sample and the negative sample belong to different categories.
- (1)
- When is smaller, the loss tends to approach 0 more easily. In this case, the anchor sample does not need to be pulled too close to the positive sample, and the anchor sample does not need to be pulled too far from the negative sample to quickly approach a loss of 0. However, the result obtained from such training may not effectively distinguish samples with different labels.
- (2)
- When is larger, the network parameters need to work harder to reduce the distance between the anchor sample and the positive sample while increasing the distance between the anchor sample and the negative sample. Setting the margin value too large may result in the loss, maintaining a relatively large value, making it difficult to approach 0.
4. The Proposed TL-DGN Method for Unseen Domain Fault Diagnosis
- (1)
- Discrimination: Firstly, the TL-DGN method can discriminate between fault features of different categories. Moreover, based on cross-entropy loss, the model can achieve low classification errors on fault data.
- (2)
- Feature clustering: In addition to classifying features, the introduced triplet loss allows features of similar fault data to cluster together, while features of dissimilar fault data are dispersed. This leads to a more discriminative classification boundary.
- (3)
- Generalization: Due to the discrimination and feature clustering characteristics of the proposed model, it can classify faults of different categories and aggregate features of the same category. This enhances the model’s generalization capability, making it relatively insensitive to changes in the load conditions.
- (1)
- Collect vibration signals of bearing fault states under multiple loads as fault datasets from multi-source domains.
- (2)
- Establish the TL-DGN model based on Equation (6). In this model, the feature extractor is CNN, the activation function is ReLU, and the optimizer is Adam.
- (3)
- Divide the source domain datasets into equal-length segments. Input the vibration data from multi-source domains into the model for training while keeping the model parameters fixed.
- (4)
- Collect vibration signals from the target domain (signals from the target domain were not involved in the training phase). Input these signals into the trained model to obtain the diagnosis results for rolling bearing faults in the target domain.
5. Case Study
5.1. German Paderborn Bearing Data Set
5.2. HUSTgearbox Data Set
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Edwards, S.; Lees, A.W.; Friswell, M.I. Fault diagnosis of rotating machinery. Shock Vib. Dig. 1998, 30, 4–13. [Google Scholar] [CrossRef]
- Liu, R.; Yang, B.; Zio, E.; Chen, X. Artificial intelligence for fault diagnosis of rotating machinery: A review. Mech. Syst. Signal Process. 2018, 108, 33–47. [Google Scholar] [CrossRef]
- Wang, T.; Han, Q.; Chu, F.; Feng, Z. Vibration based condition monitoring and fault diagnosis of wind turbine planetary gearbox: A review. Mech. Syst. Signal Process. 2019, 126, 662–685. [Google Scholar] [CrossRef]
- Lei, Y.; Lin, J.; He, Z.; Zuo, M.J. A review on empirical mode decomposition in fault diagnosis of rotating machinery. Mech. Syst. Signal Process. 2013, 35, 108–126. [Google Scholar] [CrossRef]
- Tao, H.; Wang, P.; Chen, Y.; Stojanovic, V.; Yang, H. An unsupervised fault diagnosis method for rolling bearing using STFT and generative neural networks. J. Frankl. Inst. 2020, 357, 7286–7307. [Google Scholar] [CrossRef]
- Peng, Z.K.; Chu, F. Application of the wavelet transform in machine condition monitoring and fault diagnostics: A review with bibliography. Mech. Syst. Signal Process. 2004, 18, 199–221. [Google Scholar] [CrossRef]
- Zheng, H.; Li, Z.; Chen, X. Gear fault diagnosis based on continuous wavelet transform. Mech. Syst. Signal Process. 2002, 16, 447–457. [Google Scholar] [CrossRef]
- Yu, Y.; Junsheng, C. A roller bearing fault diagnosis method based on EMD energy entropy and ANN. J. Sound Vib. 2006, 294, 269–277. [Google Scholar] [CrossRef]
- Chen, X.S.; Zeng, H.B.; Li, Z.X. A multi-fault diagnosis method of rolling bearing based on wavelet-PCA and fuzzy K-nearest neighbor. Appl. Mech. Mater. 2010, 29, 1602–1607. [Google Scholar] [CrossRef]
- Wang, Z.; Zhang, Q.; Xiong, J.; Xiao, M.; Sun, G.; He, J. Fault diagnosis of a rolling bearing using wavelet packet denoising and random forests. IEEE Sens. J. 2017, 17, 5581–5588. [Google Scholar] [CrossRef]
- Li, X.; Zhang, W.; Ding, Q.; Li, X. Diagnosing rotating machines with weakly supervised data using deep transfer learning. IEEE Trans. Ind. Inform. 2019, 16, 1688–1697. [Google Scholar] [CrossRef]
- Wang, X.; Qin, Y.; Wang, Y.; Xiang, S.; Chen, H. ReLTanh: An activation function with vanishing gradient resistance for SAE-based DNNs and its application to rotating machinery fault diagnosis. Neurocomputing 2019, 363, 88–98. [Google Scholar] [CrossRef]
- Pan, H.; He, X.; Tang, S.; Meng, F. An improved bearing fault diagnosis method using one-dimensional CNN and LSTM. J. Mech. Eng. Vestn. 2018, 64, 443–452. [Google Scholar]
- Hoang, D.T.; Kang, H.J. A survey on deep learning based bearing fault diagnosis. Neurocomputing 2019, 335, 327–335. [Google Scholar] [CrossRef]
- Wang, D.; Guo, Q.; Song, Y.; Gao, S.; Li, Y. Application of multiscale learning neural network based on CNN in bearing fault diagnosis. J. Signal Process. Syst. 2019, 91, 1205–1217. [Google Scholar] [CrossRef]
- Niu, G.; Wang, X.; Golda, M.; Mastro, S.; Zhang, B. An optimized adaptive PReLU-DBN for rolling element bearing fault diagnosis. Neurocomputing 2021, 445, 26–34. [Google Scholar] [CrossRef]
- Cui, M.; Wang, Y.; Lin, X.; Zhong, M. Fault diagnosis of rolling bearings based on an improved stack autoencoder and support vector machine. IEEE Sens. J. 2020, 21, 4927–4937. [Google Scholar] [CrossRef]
- Nie, X.; Xie, G. A novel normalized recurrent neural network for fault diagnosis with noisy labels. J. Intell. Manuf. 2021, 32, 1271–1288. [Google Scholar] [CrossRef]
- Wang, Y.R.; Sun, G.D.; Jin, Q. Imbalanced sample fault diagnosis of rotating machinery using conditional variational auto-encoder generative adversarial network. Appl. Soft Comput. 2020, 92, 106333. [Google Scholar] [CrossRef]
- Ghifary, M.; Kleijn, W.B.; Zhang, M.; Balduzzi, D. Domain generalization for object recognition with multi-task autoencoders. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2551–2559. [Google Scholar]
- Wang, J.; Lan, C.; Liu, C.; Ouyang, Y.; Qin, T.; Lu, W.; Chen, Y.; Zeng, W.; Philip, S.Y. Generalizing to unseen domains: A survey on domain generalization. IEEE Trans. Knowl. Data Eng. 2022, 35, 8052–8072. [Google Scholar] [CrossRef]
- Zhou, K.; Liu, Z.; Qiao, Y.; Xiang, T.; Loy, C.C. Domain generalization: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 4396–4415. [Google Scholar] [CrossRef]
- Chen, L.; Li, Q.; Shen, C.; Zhu, J.; Wang, D.; Xia, M. Adversarial domain-invariant generalization: A generic domain-regressive framework for bearing fault diagnosis under unseen conditions. IEEE Trans. Ind. Inform. 2021, 18, 1790–1800. [Google Scholar] [CrossRef]
- Shi, Y.; Deng, A.; Deng, M.; Li, J.; Xu, M.; Zhang, S.; Ding, X.; Xu, S. Domain transferability-based deep domain generalization method towards actual fault diagnosis scenarios. IEEE Trans. Ind. Inform. 2022, 19, 7355–7366. [Google Scholar] [CrossRef]
- Zhao, C.; Shen, W. Federated domain generalization: A secure and robust framework for intelligent fault diagnosis. IEEE Trans. Ind. Inform. 2023, 20, 2662–2670. [Google Scholar] [CrossRef]
- Fan, Z.; Xu, Q.; Jiang, C.; Ding, S.X. Deep mixed domain generalization network for intelligent fault diagnosis under unseen conditions. IEEE Trans. Ind. Electron. 2023, 71, 965–974. [Google Scholar] [CrossRef]
- Wang, X.; Liu, F. Triplet loss guided adversarial domain adaptation for bearing fault diagnosis. Sensors 2020, 20, 320. [Google Scholar] [CrossRef]
- Lessmeier, C.; Kimotho, J.K.; Zimmer, D.; Sextro, W. Condition monitoring of bearing damage in electromechanical drive systems by using motor current signals of electric motors: A benchmark data set for data-driven classification. In Proceedings of the PHM Society European Conference, Bilbao, Spain, 5–8 July 2016; Volume 3. [Google Scholar]
- Zhao, C.; Zio, E.; Shen, W. Domain Generalization for Cross-Domain Fault Diagnosis: An Application-oriented Perspective and a Benchmark Study. Reliab. Eng. Syst. Saf. 2024, 245, 109964. [Google Scholar] [CrossRef]
- Sanchez, R.V.; Lucero, P.; Vasquez, R.E.; Cerrada, M.; Macancela, J.C.; Cabrera, D. Feature ranking for multi-fault diagnosis of rotating machinery by using random forest and KNN. J. Intell. Fuzzy Syst. 2018, 34, 3463–3473. [Google Scholar] [CrossRef]
- Jing, C.; Hou, J. SVM and PCA based fault classification approaches for complicated industrial process. Neurocomputing 2015, 167, 636–642. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Date Set | Rotational Speed (rpm) | Load Torque (Nm) | Radial Force (N) | Name |
|---|---|---|---|---|
| A | 1500 | 0.7 | 400 | N15_M07_F04 |
| B | 1500 | 0.1 | 1000 | N15_M01_F10 |
| C | 900 | 0.7 | 1000 | N09_M07_F10 |
| D | 1500 | 0.7 | 1000 | N15_M07_F10 |
| Bearing Code | Module | Damage Degree | Damage Mode |
|---|---|---|---|
| KI01 | IR | 1 | Electro discharge machining |
| KA01 | OR | 1 | Electro discharge machining |
| KA07 | OR | 1 | Drilling |
| KI03 | IR | 1 | Electric engraving |
| Fault Category | Label | Number of Sample | Dimension of Sample |
|---|---|---|---|
| KI01 | 0 | 1000 | 1 × 1024 |
| KA01 | 1 | 1000 | 1 × 1024 |
| KA07 | 2 | 1000 | 1 × 1024 |
| KI03 | 3 | 1000 | 1 × 1024 |
| Layer | Parameter | ||
|---|---|---|---|
| Input | / | / | |
| Conv1D_1 | kernel_size = 11, filters = 32 | ReLU | |
| MaxP_2 | pool_size = 11 | / | |
| Feature | Conv1D_3 | kernel_size = 5, filters = 32 | ReLU |
| Extractor | MaxP_4 | pool_size = 5 | / |
| Conv1D_5 | kernel_size = 3, filters = 16 | ReLU | |
| AverP_6 | pool_size = 3 | / | |
| Dropout | 0.5 | / | |
| Label | FC1 | 50 | ReLU |
| Classifier | FC2 | 4 | Softmax |
| Source Domain | Target Domain | With Triplet Loss | Without Triplet Loss |
|---|---|---|---|
| A,B | C | 70.02 | 69.15 |
| A,B | D | 99.97 | 99.97 |
| A,C | B | 98.67 | 97.77 |
| C,D | A | 96.52 | 94.02 |
| C,D | B | 99.45 | 97.50 |
| A,C | D | 99.22 | 99.02 |
| Average | 93.98 | 92.91 | |
| KNN | SVM | Without Triplet Loss | ||||
|---|---|---|---|---|---|---|
| Accuracy | 0.3783 | 0.5050 | 0.6540 | 0.7556 | 0.7254 | 0.7238 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shen, B.; Zhang, M.; Yao, L.; Song, Z. Novel Triplet Loss-Based Domain Generalization Network for Bearing Fault Diagnosis with Unseen Load Condition. Processes 2024, 12, 882. https://doi.org/10.3390/pr12050882
Shen B, Zhang M, Yao L, Song Z. Novel Triplet Loss-Based Domain Generalization Network for Bearing Fault Diagnosis with Unseen Load Condition. Processes. 2024; 12(5):882. https://doi.org/10.3390/pr12050882
Chicago/Turabian StyleShen, Bingbing, Min Zhang, Le Yao, and Zhihuan Song. 2024. "Novel Triplet Loss-Based Domain Generalization Network for Bearing Fault Diagnosis with Unseen Load Condition" Processes 12, no. 5: 882. https://doi.org/10.3390/pr12050882