1. Introduction
The data of complex industrial processes mainly appear in the form of time series, which contain rich process information [
1,
2]. In continuous processes, people often grasp the inherent laws through modeling [
3,
4,
5,
6], which can be classified as either mechanistic or data models. The data model, which is built by directly using data acquired from sensors or supervisory control and data acquisition (SCADA), shows great potential in many fields of process monitoring, fault detection and diagnosis, energy systems, and so on [
7,
8,
9,
10], because these data can precisely represent the process states in current environments.
The data model can be used in two directions for multivariate time series in complex industrial processes. One approach of prioritizing the temporal feature is to establish various mathematical forms along the timeline direction, which includes numerous empirical formulas, an autoregressive model (AR), a moving average model (MA), an auto-regressive moving average model (ARMA), narrow and deep neural networks (NN), and so on. Reference [
11] demonstrated lemmas and theorems about the least squares and multi-innovation least squares parameter estimation algorithms after reviewing and surveying some important contributions and extended the results of the least squares and multi-innovation least squares algorithms for linear regressive systems with white noise to other systems with colored noise. Reference [
12] proposed a filtering-based extended stochastic gradient (ESG) algorithm. The filtering-based multi-innovation ESG algorithm was then proposed for improving the parameter estimation accuracy of a multivariable system with moving average noise. In [
13], an auto-regressive integrated moving average (ARIMA) model was used to estimate the values of the predictor variables. An algorithm combined the time-series analysis methods with machine learning techniques for predicting the remaining useful life (RUL) of aircraft engines. Reference [
14] proposed a deep neural network with contrastive divergence for short-term natural gas load forecasting. The proposed deep network outperformed traditional artificial neural networks by a 9.83% weighted mean absolute percent error in 62 operating areas. In [
15], a deep residual shrinkage network was developed to improve the feature learning ability from highly noised vibration signals, achieving a high fault-diagnosing accuracy. Reference [
16] provided a state-of-the-art review of deep learning and different methods that made the successful training of deep learning models possible at a very high scale in various modem practices. This kind of approach, where the mathematical equivalent model, whether explicit or implicit, is based on historical data, is suitable for invariant steady operation during the process. When the actual situation differs from the historical situation it forms a significant error. Some scholars have proposed online parameter adjustments, adaptive training, and other measures to improve this. In [
17], a novel identification technique with a high-gain observer-based identification approach was proposed for systems with bounded process and measurement noises, which resulted in the identified parameters and the response curves being applied to a gas turbine engine using the recorded input data from the engine testbed. In [
18], a hybrid novel approach was presented that integrated a data-driven method with a coarse model to improve operational conversion efficiency in air-conditioning refrigeration. In [
19], a separation method was used to transform the original optimization problem into quadratic and nonlinear optimization problems in order to overcome the estimation difficulty due to the highly nonlinear relations between the parameters and the output of the radial basis function-based state-dependent autoregressive model. However, online monitoring in a time-varying complex system still presents challenges using this method.
The other approach to prioritizing states of spatial relations is to directly construct a data matrix by selecting a specific observation window length, whereby the time axis is scanned by sliding the windows. This kind of model brings the spatial relationships of variables into data matrices within a finite time, which are then analyzed by a matrix theory or multidimensional statistical theory. The typical model includes principal component analysis (PCA), independent component analysis (ICA) and so on. Reference [
20] considers critically how principal component analysis (PCA) is employed with spatial data and provides a brief guide that includes robust and compositional PCA variants, links to factor analysis, latent variable modeling, and multilevel PCA. Reference [
21] gives an overview of the analysis of spatial and of functional data observed over complicated two-dimensional domains. Reference [
22] presents different data-driven dimension reduction techniques for dynamical systems that are based on transfer operator theory as well as methods to approximate transfer operators and their eigenvalues, Eigen functions, and Eigen modes. Recently, deep neural networks have also been considered for use in spatial relationships. Reference [
23] provided an overview of traditional statistical and machine learning perspectives for modeling spatial and spatiotemporal data, and then focused on a variety of hybrid models that have recently been developed for latent process, data, and parameter specifications. Reference [
24] provided a comprehensive overview of methods to analyze deep neural networks and an insight as to how those interpretable and explainable methods help us to understand time-series data. This kind of approach has an inherent advantage for real-time monitoring because it directly uses the real-time data to construct data matrices.
A standard procedure for data modeling is to first determine the length of a sliding window based on experiences, then preprocess the data (e.g., filtered, normalized, etc.) and finally build the data matrix for analysis. To construct a data matrix, an equal length of data for the sliding window must be used. However, the data series describing a complex industrial object is essentially a reflection of the characteristics of the variables. Different physical variables have different time-scale characteristics; for example, temperature usually has strong inertia, and an excessive sampling frequency will obtain a large number of similar data, which have a negative impact on the analysis of the matrix model. The flow rate is affected by fluid flow, so an excessive sampling frequency conversely brings noise to disturb the measurement of the actual state of the fluid, resulting in control difficulties. Because vibration signals reflect rapid changes in the equipment state in real time, low sampling frequencies may miss some characteristics. Therefore, data alignment is a prerequisite for constructing a window matrix. There are two types of modes, expansion and compression, for solving the alignment problem of data of different lengths. The expansion mode aligns data with a shorter length to data with a longer length with data-filling or embedding technology. Conversely, the compression mode aligns data with a longer length to data with a shorter length using data division or segmenting. Reference [
25] introduced a generative adversarial network (GAN) framework to generate synthetic data pertaining to data imputation. In [
26], a multivariate time-series generative adversarial network was proposed for multivariate time-series distribution modeling by introducing multi-channel convolution into GANs; this is a mathematical approach that does not consider the properties and effects of underlying physical quantities, which can lead to differences between the data matrix and the actual system. In fact, these kinds of physical variables have relatively stable effects on the system within a limited time window but are susceptible to changes due to the influence of the data matrix.
The aim of this paper is to solve three problems faced by data modelling: (1) different time scales; (2) different roles of variables; and (3) the difficulty in determining the length of the window. This paper proposes a modeling method to make up the gap between modeling and analysis by constructing a data matrix. The effectiveness of the proposed approach was validated by the Tennessee Eastman (TE) model. The advantages of this method are as follows.
- (1)
This approach makes a surrogate of the original sequence through the reconstructed data sequence, which owns the main frequency information of the original sequence. The frequency information of the surrogate is applied to determine the minimum length of the sliding window. This overcomes the difficulty in determining the length of the sliding window through empirical methods;
- (2)
A sequence-to-sequence method is used to map the data sequence from different time scales to a time window of the same length, which preserves the information of the original time series as completely as possible due to keeping the relationship of the original time series. This achieves data alignment at different time scales;
- (3)
The variables’ relationship with the previous sliding window is utilized to adjust the current data matrix by introducing the attention mechanism with a consideration of the contribution rates of different variables to the system, thereby enhancing the robustness of the data matrix.
The rest of this paper is organized as follows. In
Section 2, the primaries of the data matrix of the time series, sequence-to-sequence model and dynamic time warping algorithm are given.
Section 3 describes the proposed approach, including the integral structure, determination of window length, S2S transformation, matrix modification and the workflow. The verification is provided in
Section 4, followed by the conclusion in
Section 5.
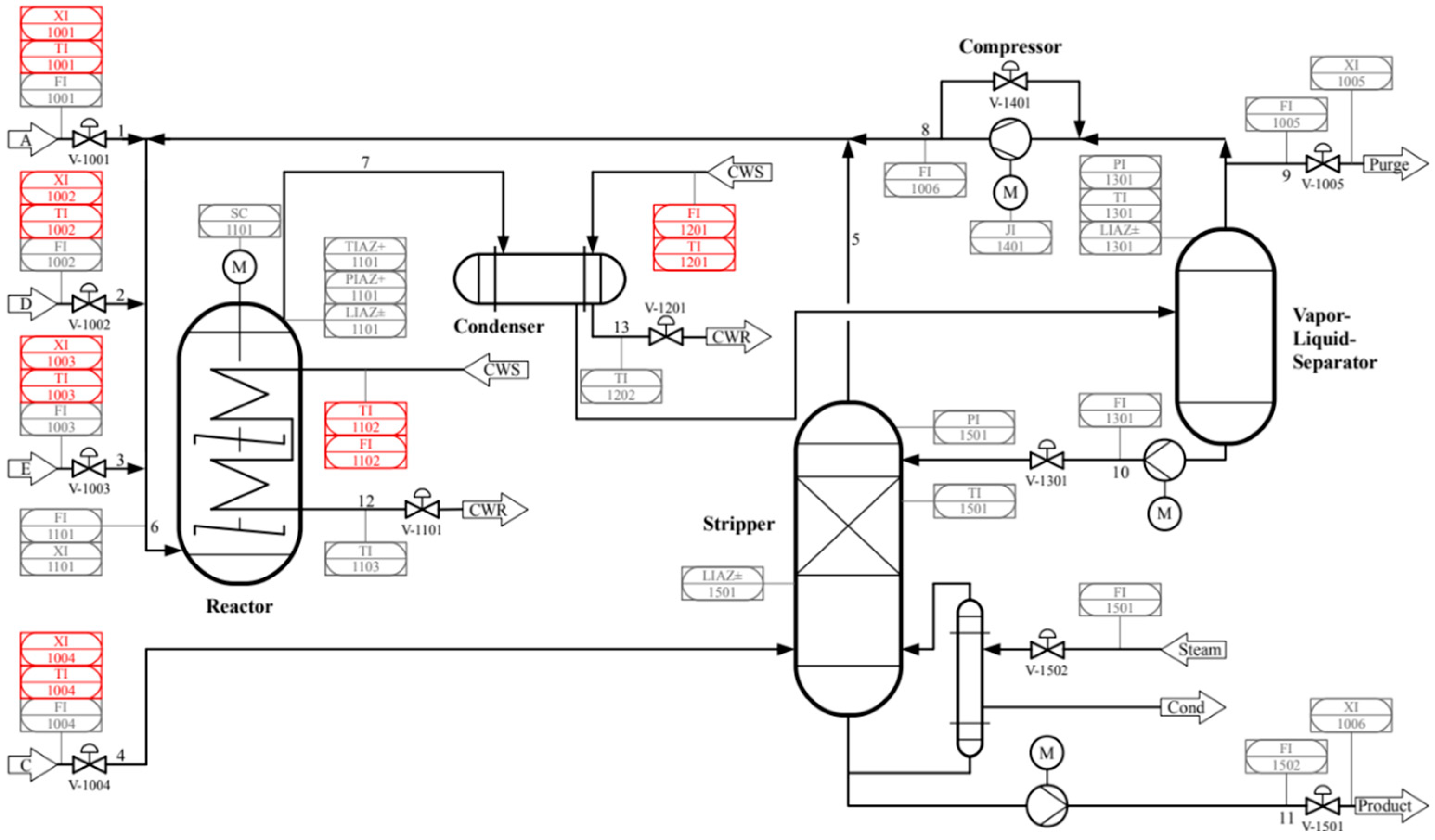
3. The Proposed Method
3.1. The Integral Structure
The integral structure of the proposed approach is shown in
Figure 1.
The structure consists of three parts: the window length module, the S2S transformation module, and the matrix modification module.
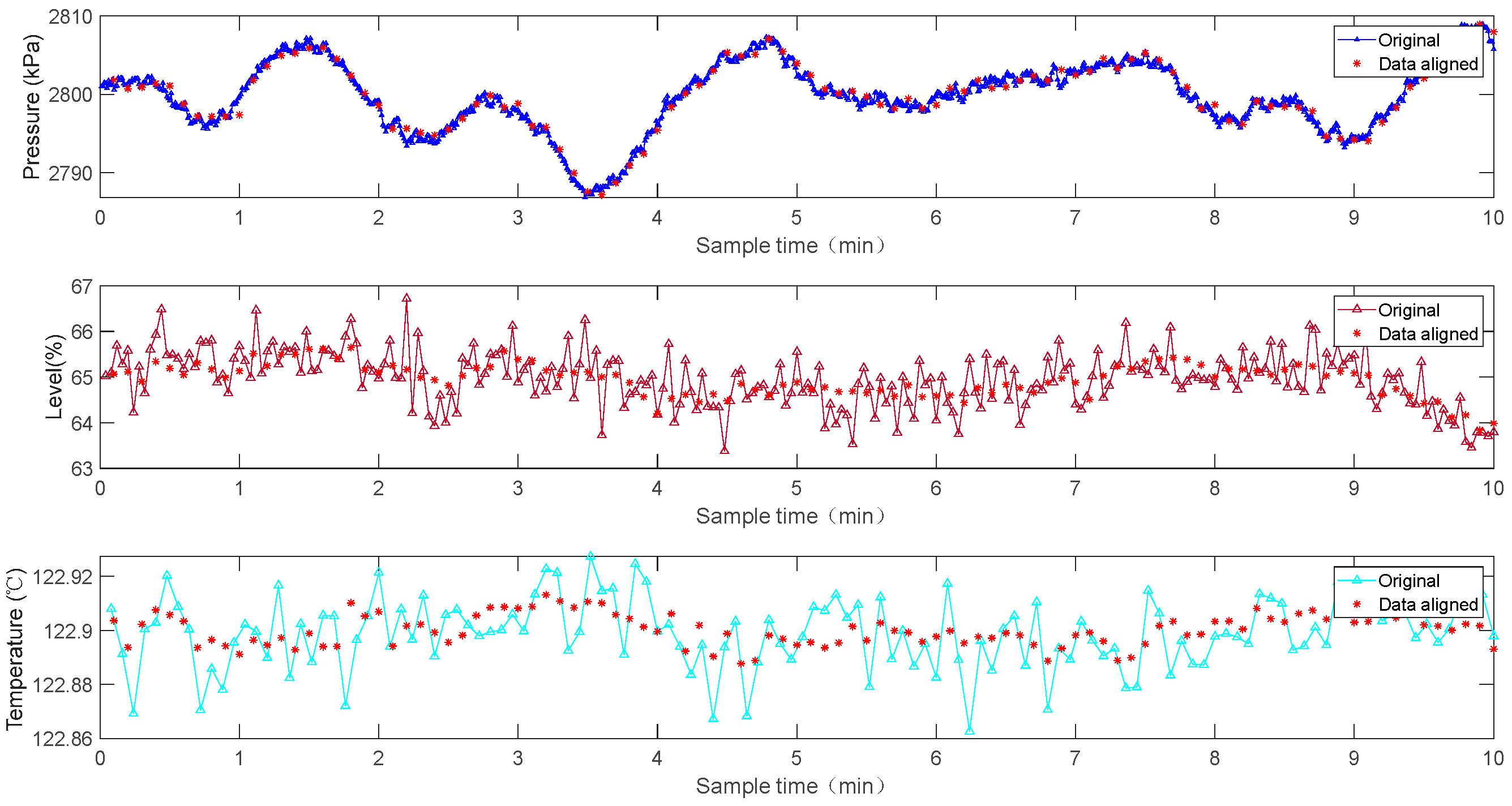
The window length is used to determine the length of the observation window. For a data model of the time series, the characteristics of an industrial process are only obtained through observation windows. The longer the length of observation window, the richer the information process. However, this will affect the real-time analysis of the time series because too many sampling points require a longer amount of time. In practice, the window length can only be set based on experiences because the relation between the physical characteristics of the object and the length of the observation window are unknown. Considering that secondary information and noises make few contributions in process monitoring, the time series can be reconstructed with a certain allowable accuracy. Therefore, this reconstructed time series has complete sequence information after the construction process. The length of the observation window can be easily determined according to this information.
The S2S transformation implements the function of transforming different window lengths to a uniform length. The number of samples in the observation window whose length is determined by the window length module is not the same because the physical variables behind the time series have different time scales. This creates the dilemma of not establishing a window data matrix due to the different lengths of data. The S2S module forms a uniform sequence of equal lengths to meet the spatial alignment requirements by transforming different lengths to the same length for observation window sequences without losing time-series information.
The matrix modification module corrects the deviation between matrix and process characteristics caused by the different impacts of variables behind the window data on the process. With help from the window length module and the S2S transformation module, a data matrix for the observation window is established under a standard length. However, this establishment process is based on the independent modeling of each channel for different variables, which implies that each variable has an equal effect on the process. In fact, the contribution of different variables is not equal to the process, especially for varying processes. Taking into account the different effects of the variables on the process, the attention mechanism is applied to redistribute the occupied weights of each variable, thus forming a final model based on the window data.
3.2. Window Length Module
The method of determining the sliding window length is based on frequency analysis in our previous work. The idea behind this method is to replace the original time series with a clearly defined signal and use this clear information to construct the observation window. Specifically, frequency domain decomposition of the time series is performed and the time series is reconstructed within the allowable range of accuracy by using frequency signals that have a significant impact on the original signal. The frequency values of the constructed components are obtained during the reconstruction process. The minimum common multiple of these periods corresponding to the frequencies are used to form a new cycle. The window corresponding to this cycle is regarded as the sliding window length because this cycle contains all the information of the structural components. The main steps of this method include frequency decomposition, frequency reconstruction, information loss assessment, effective frequencies determination, and obtaining the window length. More details are provided in reference [
29].
3.3. S2S Transformation Module
S2S Transformation module includes a sequence-to-sequence construction and DTW-based training.
- (1)
Sequence-to-sequence construction
In the classical sequence-to-sequence model, the encoder and decoder both use RNN, because the semantic coding contains the information of the whole input sequence. The encoder is responsible for compressing the input sequence into a vector of specified length, which can be regarded as the semantics of that sequence. The decoder takes the output of the previous moment as the input of the next moment, and at the same time, decoding is performed according to the semantic vector output by the encoder as the input of the decoder at each step. Here, the long short-term memory (LSTM) neural network is selected as the carrier of the sequence-to-sequence transformation. The construction is based on the recurrent neural network (RNN) model by adding thresholds to solve the short-term memory problem of the RNN so that the LSTM neural network can effectively use long-term temporal information. The structure is shown in
Figure 2 where A is a repetitive structural unit and C is the semantic vector.
The LSTM adds three logical control units, the input threshold, output threshold, and forgetting threshold, to the basic structure of the RNN, and each of these is combined with a multiplication original by setting the weights at the connecting edges of the memory cells and other parts of the neural network, so that the input and output of the information flow and the state of the cell unit are controlled.
The input threshold is a value that determines whether new information can be written to the LSTM cell. If the signal input to the LSTM cell is below the input threshold, the signal will not be written to the cell. This prevents the cell from being affected by noise or meaningless information. The input threshold can be thought of as a switch that controls the inflow of information.
The output threshold determines the information that can be read from or output to the LSTM cell. If the internal state of the cell, also known as the cell state, falls below the output threshold, it will not be output. This prevents the cell from outputting irrelevant or confusing information. The output threshold can be considered a filter that regulates the flow of information.
The forget threshold is a value that determines which old information can be erased or forgotten from the LSTM cell. If the internal state of the cell falls below the forget threshold, a portion of that state will be forgotten or erased. This enables the LSTM cell to adapt to new information without being influenced by old, irrelevant information. The forget threshold can be thought of as a ‘scavenger’ that controls the forgetting and updating of information.
These weights are set and updated by other parts of the neural network, in addition to the logical control unit described earlier. The storage unit of the LSTM contains specific weights for input gates, forget gates, output gates, and candidate cell states. The weights’ initial values are typically sampled from a random distribution and then updated during training using optimization algorithms such as back propagation and gradient descent. By continuously adjusting these weights, the LSTM can better process sequential data and achieve long-term dependent memory capabilities.
The formula for the LSTM is defined as Equations (8)–(13):
where
represents the recursive connection weights of their corresponding thresholds, respectively. The
and the
are two types of activation functions,
is the input gate,
is the forget gate,
is the output gate,
is the memory cell,
is the hidden state, and
is the candidate memory cell.
- (2)
DTW-based training
In the training of a sequence-to-sequence model, the data features at the time t are first inputted to the input layer and the results are outputted after the excitation function, and then the output results, the output of the hidden layer at the time and the information stored in the cell at the time are inputted to the nodes of the LSTM, and then the data are outputted to the next hidden layer or the output layer after the input gate, the output gate, the forget gate and the cell, and the results of the LSTM nodes are outputted to the neurons of the output layer. The back propagation errors of Euclidean distance are calculated, and the individual weights are updated.
However, the Euclidean distance is not effective in calculating the distance between the two time series because the time-series length between the source and the target is inconsistent. To find a parsimonious representation of a short sequence of a long time series, in order to make the short sequence as similar as possible to the original sequence, the dynamic time warping (DTW) algorithm is introduced to measure the degree of similarity between the two sequences of different lengths. The optimal warping path is defined as an error loss function and the boundary conditions are adopted as
and
, indicating that the start point is at the lower-left corner of the grid and the end point is at the upper-right corner of the grid, the kth element of the warping path is denoted as
. Under the above conditions, the optimization problem shown in Equation (14) is solved using the dynamic programming algorithm.
where
denotes the sum of cumulative distances to the point
.
3.4. Matrix Modification Module
For the multivariate model, the influence of different variables on the final matrix is further investigated. Considering the positive effect of SENet [
30] on the role of the channel, the attention mechanism is adopted to adjust the weights of the roles of each variable. SENet introduces a squeeze module and an excitation module, wherein in the squeeze operation the feature maps of each channel are globally averaged and compressed into a single feature vector, and in the excitation operation, a fully connected layer, and a non-linear activation function (e.g., sigmoid or ReLU) are used to learn the weights of each channel to capture the relationship between the channels. Finally, these weights are applied to the original feature maps via a dot-multiplication operation to produce a weighted matrix model, allowing the model to update the feature maps adaptively. The entire procedure is represented by Equation (15):
where
is the input feature map,
is the final output feature map,
is the global average pooling operation,
is the activation function,
, and
is the activation function
,
and
are parameters of the fully connected layer, in which
is a smaller dimension.
Using samples collected by previous time series to construct the data matrix
of an observation window with the standard length, L. Then, a singular value decomposition is applied for data matrices according to Equation (16):
Take the diagonal elements of s to form a vector
and obtain the target vector
after normalization
where
is the diagonal element of S,
is a sum symbol,
is the number of elements, and
is a transpose symbol.
By changing the initial sampling time, many data matrices, with their corresponding target vectors, are obtained as the training database. A SENet is constructed to implement the attention mechanism by dispersing the output value to various components. Thus, the final data matrix is obtained by performing the product operation with the aligned window matrix.
The process of the proposed approach is as follows:
Step 1: determine the length of the sliding time window according to
Section 3.2;
Step 2: construct the S2S transformation with the long short-term memory (LSTM) neural network, the inputs of which are sampling values from different observation windows, and the outputs are the standard observation window data;
Step 3: train taking DTW as the loss function;
Step 4: build the data matrix with the length of the standard window and construct the attention mechanism to train;
Step 5: modify the data matrix according to
Section 3.4.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}