1. Introduction
The share of coal energy in China’s primary energy will continue to exceed 50% until 2025 [
1]. However, mined gangue accounts for 15–20% of the raw coal production during coal production [
2]. It not only raises the transportation cost of the industry but also reduces the combustion efficiency of raw coal and aggravates ecological pollution [
3,
4]. Therefore, accurately sorting coal and gangue is essential for efficiently utilizing coal energy. The traditional methods of sorting coal and gangue are mainly manual gangue sorting, heavy media gangue sorting [
5], dynamic sieve skip sorting [
6], dual-energy gamma-ray detection [
7], X-ray detection [
8], and laser detection [
9]. However, the above methods have disadvantages such as high cost, low precision, low environmental protection, and harm to human health, which are not conducive to the long-term development of coal mining [
10]. The development of computer technology and machine vision has effectively solved these problems.
With the development of technologies for sorting robots to identify coal and gangue, automatic sorting of coal and gangue is becoming an increasingly popular area of research [
11]. Machine vision-based methods for coal and gangue localization and recognition are divided into machine learning and deep learning [
12]. Machine learning mainly relies on the design of manual image features, while deep learning enables the model to learn image features automatically. Li et al. used the standard features of grayscale skewness and texture contrast of coal gangue as the input vector of the least squares supports vector machine (LS-SVM) to achieve coal gangue recognition [
13]. Dou et al. used a topographic support vector machine (Relief-SVM) for color, texture, and other features of coal gangue pictures and constructed the optimal coal gangue classifier [
14]. Wang et al. constructed SVM classification models to identify coal and gangue by extracting their dielectric and geometric features [
15]. However, machine learning still faces some challenges, such as occlusion, intraclass, and background [
16]. Moreover, deep learning-based target detection algorithms can better handle these challenges through effective feature representation and the use of powerful model optimization techniques.
Two mainstream detection algorithms have been developed for deep learning-based target detection. One is the two-stage target detection algorithm represented by Faster R-CNN [
17]. The other is the single-stage target detection algorithm represented by the Yolo series [
18]. Although the accuracy of the two-stage-based target detection algorithm is generally higher than that of the single-stage, the single-stage detection algorithm is high in real-time and fast. It has been validated in some studies of coal and gangue detection based on the Yolo algorithms. Li et al. build a deformed convolutional Yolov3 network model based on the detection algorithm Yolov3 utilizing deformed convolution, multiple k-means clustering, and data augmentation [
19]. Pan et al. improved the Yolov3 network using a spatial pyramid pooling (SPP) network, a squeeze excitation (SE) module, and null convolution to speed up recognition while ensuring the model accuracy requirements [
20]. Liu et al. optimized the image quality and model anchor frame by adding deeper feature pyramids to the Yolov4 network [
4]. Zhang et al. combined mosaic data enhancement, learning rate cosine annealing decay strategy, and label smoothing optimization methods with Yolov4 networks to achieve a mAP value of 0.975 [
21]. Li et al. combined the Yolov4 target detection algorithm and hybrid domain attention mechanism to construct a coal gangue detection model. Both coal and gangue achieved high recognition accuracy [
22]. Yan et al. added spatial and channel compression excitation (scSE) to the Yolov5 network structure module, and the average accuracy of the model was as high as 0.983 [
23]. Therefore, end-to-end detection algorithms are chosen for coal and gangue detection in this paper. However, due to the limited storage space and processor performance of mobile or embedded devices, the substantial computational consumption makes it difficult for these devices to use these complex networks further.
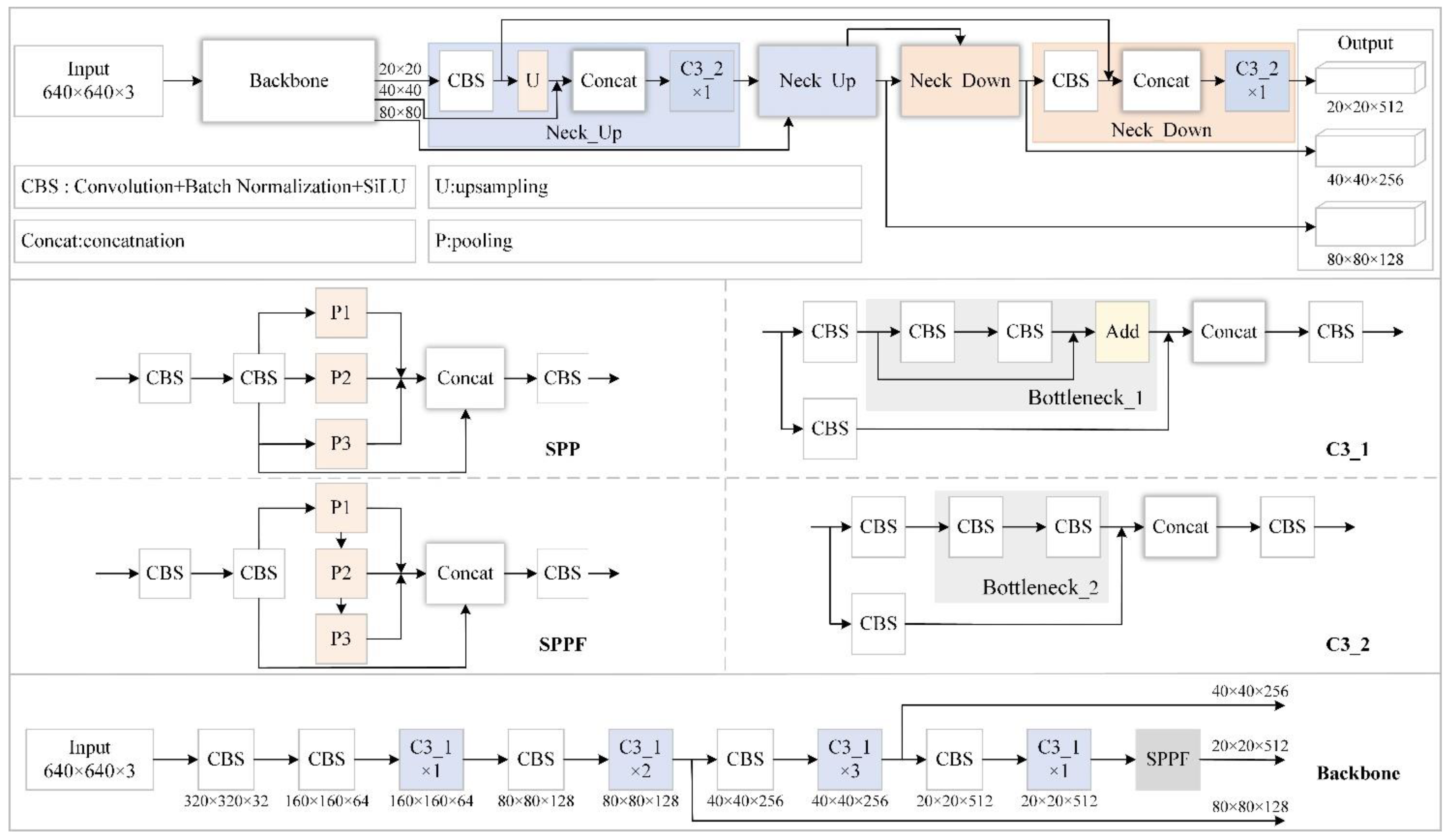
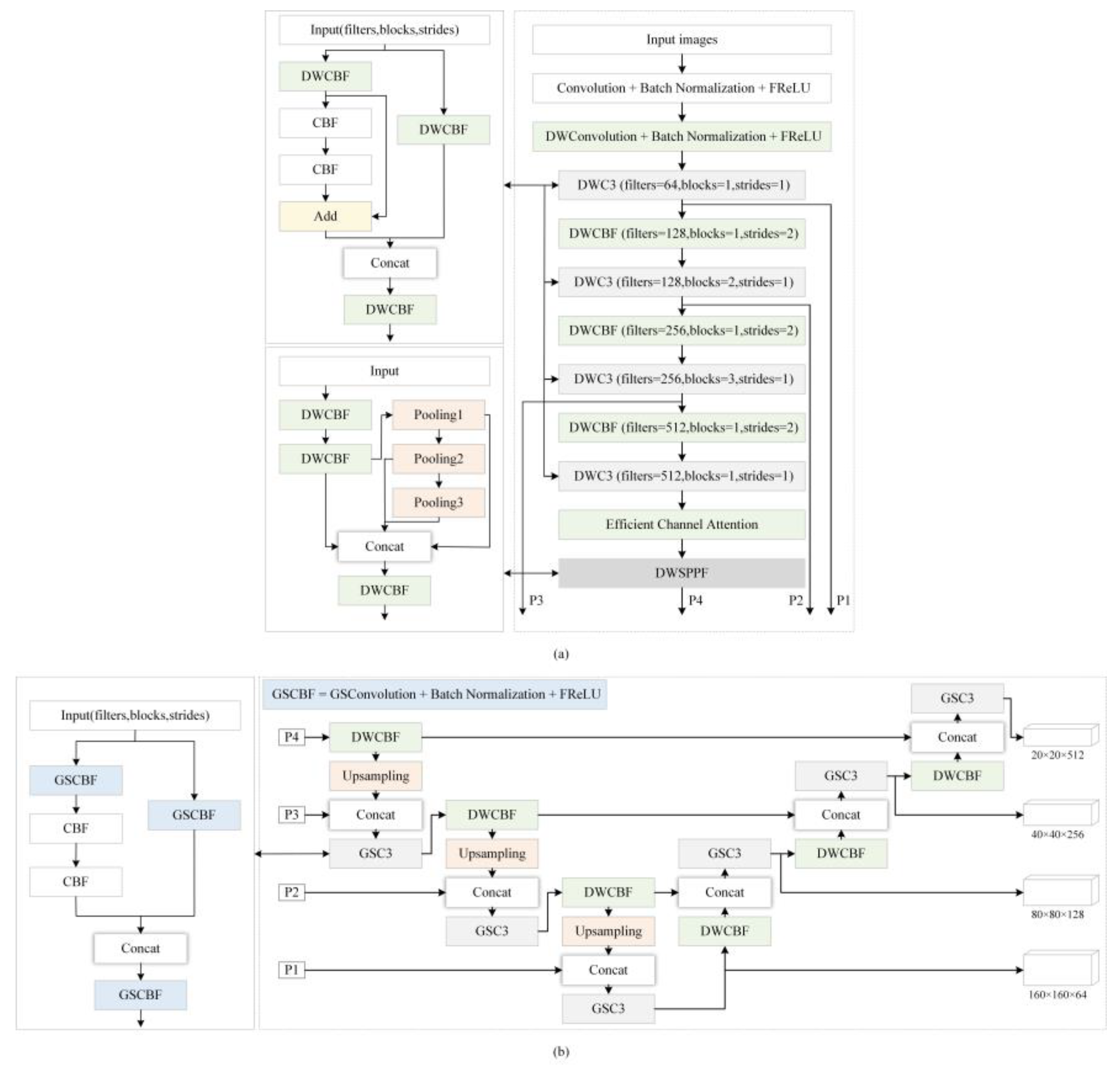
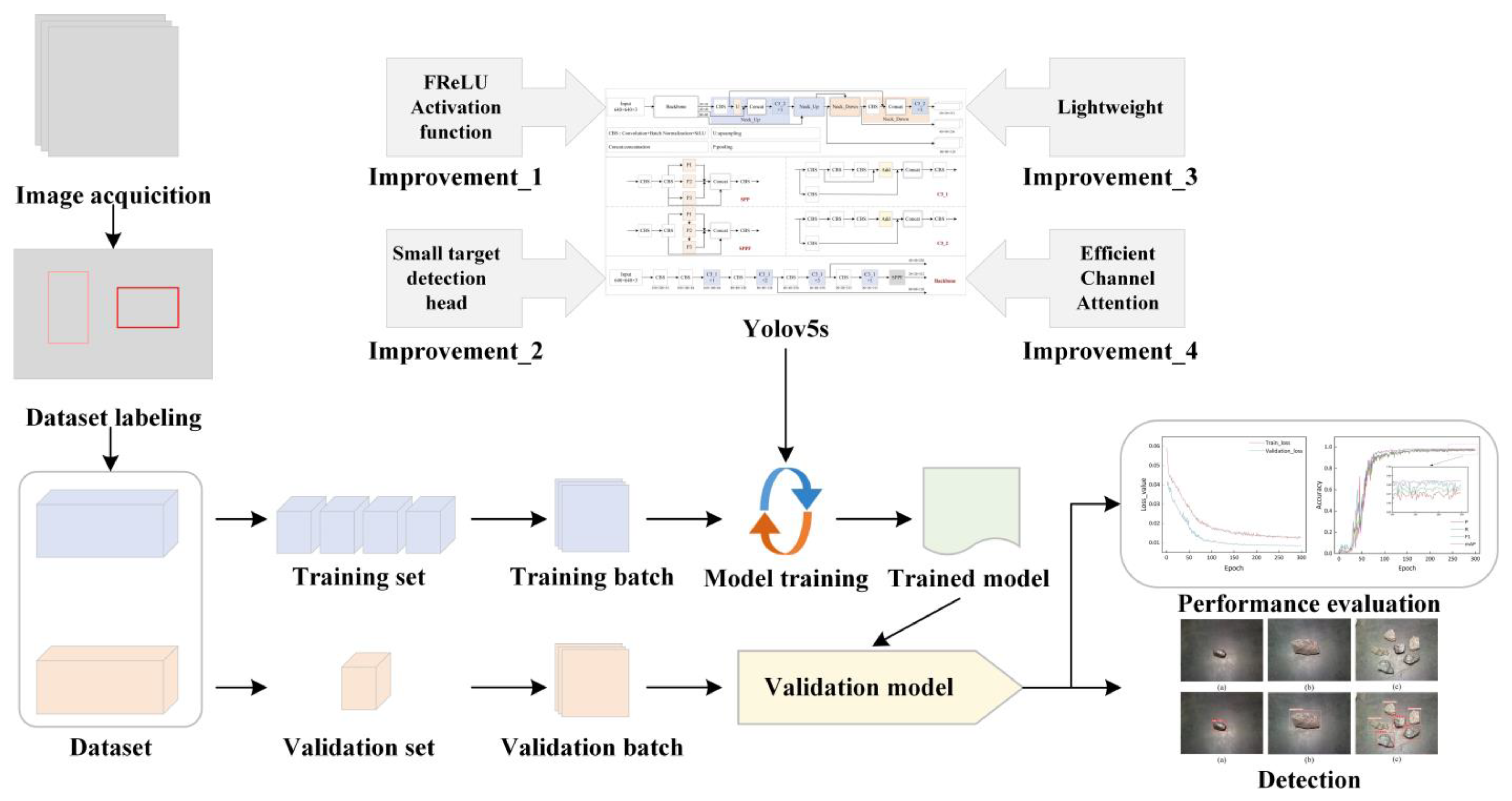
This paper proposes a lightweight target detection model based on improved Yolov5s for locating and identifying coal and gangue in images. The algorithm aims to reduce the model complexity with guaranteed accuracy and prepare for engineering deployment. Firstly, based on the Yolov5s network, the image context information is extracted adaptively by the visual activation function FReLU. Next, we redesign the neck structure of the network and adapt it to a multiscale target detection layer to improve the detection capability for small samples. After this the DWC and GSC modules replace some convolutional blocks in the original network to construct a lightweight feature extraction network, respectively. Finally, the ECA module is embedded in the backbone part further to improve the feature extraction capability of the model. As a result, our proposed improved Yolov5s model can achieve better detection performance with limited computational resources. The effectiveness of each improvement is verified through a series of experiments, and the improved algorithm is compared with commonly used lightweight target detection algorithms.
The rest of the paper is organized as follows.
Section 2 describes the experimental material used in the paper. The structure of the Yolov5s model is outlined, and an improved approach is proposed. In
Section 3, we show the experimental results of the improved model on actual data and analyze the results of the ablation and comparison experiments. Finally, in
Section 4, we summarize the conclusions obtained in this paper.
3. Experiments and Analysis
3.1. Design of Experiments
3.1.1. Conditions of Experiments
The experiments were conducted using Windows 11 64-bit operating system, computer configuration with Intel(R) Core (TM) i7-12700F CPU @ 2.10 GHz and NVIDIA GeForce RTX 3060 12 G graphics card; the deep learning framework Pytorch1.12.1 was used for training and validation of the model. These experiments rely on independently collected coal and gangue datasets for training. In order to improve the robustness and generalization of the model while increasing the amount of training data and thus reducing the risk of overfitting, mosaic enhancement is set during the model training [
36]. The main idea is to randomly scale, crop, flip and add noise to 8 images, and then stitch them onto one image as training data. The learning rate is set based on Warmup [
37], using the Stochastic gradient descent with momentum (SGDM) optimizer. The specific parameter settings are shown in
Table 2.
The downsampling of Yolov5s is generally 32 times, so the height and width of the internal feature map must be divided by 32. Since multi-scale training will generally choose 32 times, the experiments will choose a 640 × 640 pixel resolution for detection. In addition, the adaptive anchor frame in Yolov5s can effectively reduce the grey fill generated by the input 2048 × 1536 pixel image scaling, thus reducing the information redundancy.
3.1.2. Experiment Process
The goal of this paper is to improve the accuracy of coal and gangue in small target detection tasks by improving the original Yolov5s network while reducing the complexity of the model. Therefore, it can be considered as a kind of learning environment [
16].
Firstly, the coal and gangue in each image are annotated manually to obtain training label images. Subsequently, the image dataset and labels of coal and gangue are divided into training and validation sets in the ratio of 4:1. Next, the training set is input to the improved YOLOv5s network for training. During the training process, the stochastic gradient descent algorithm is used to optimize the network model, and the model weights with the highest mAP obtained on the validation set are saved as the experimental results. Finally, the trained optimal weights are loaded into the model, and the performance of the network model is tested using the images in the validation set. The specific experimental flow is shown in
Figure 6.
3.2. Model Evaluation Indicators
In this paper, both performance and complexity metrics are used to evaluate the proposed model respectively. The indicators of model performance include precision (P), recall (R), F1-Score and mAP. Precision and recall provide a visual representation of the accuracy of the target prediction. F1-Score is the weighted average of precision and recall. The AP value for each category is the region consisting of the label P-R curve for that category. The mAP is the average of the average precision (AP) values for each category of labels. Therefore, these indicators can represent the overall detection performance of the model. The specific formulas for each indicator are defined as follows.
where
represents the number of samples with correctly detected coal,
represents the number of samples with incorrectly detected coal, and
represents the number of samples with missed gangue.
is the number of detection categories.
The indicators for the complexity of the model include the number of parameters and the number of floating-point calculations (FLOPs) [
27]. The formulas are as follows.
where
is the step size.
3.3. Analysis of Model Training and Validation Results
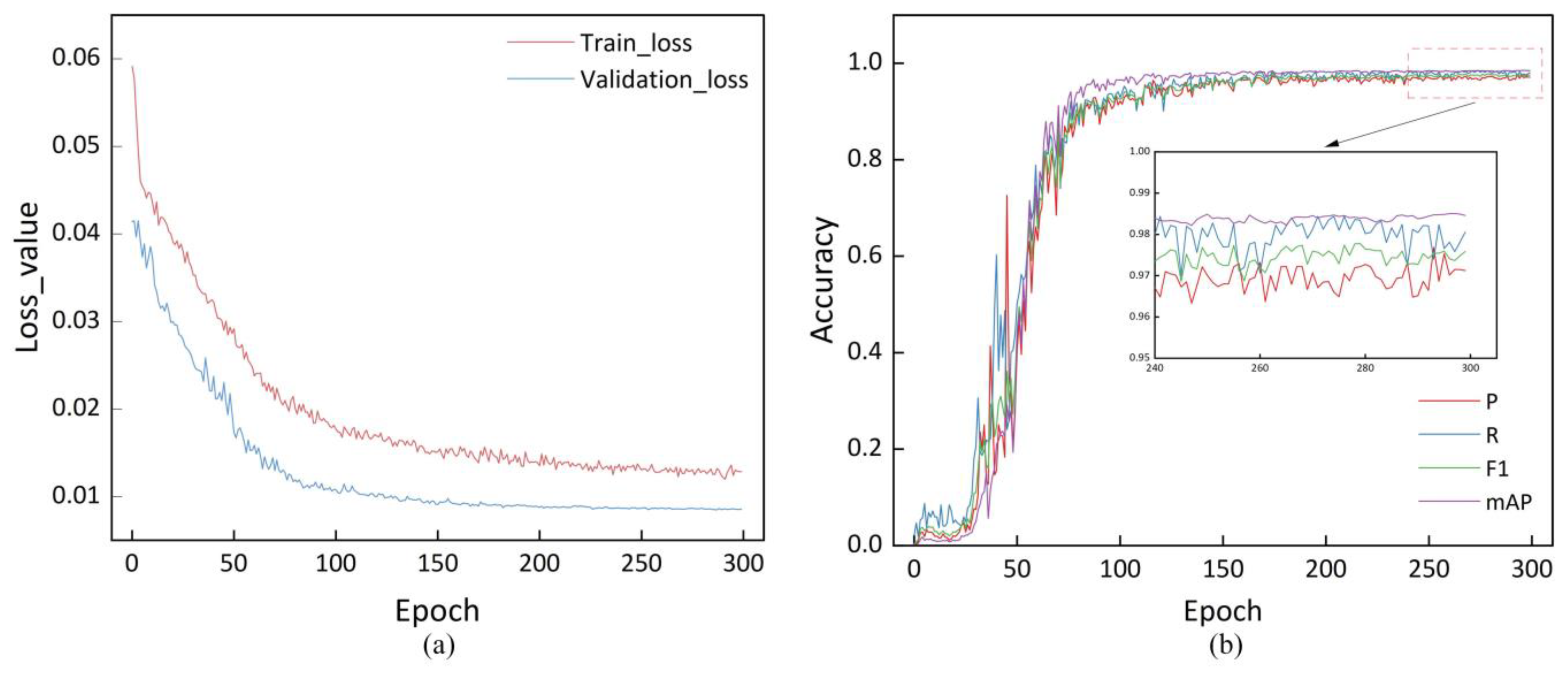
According to the data set type, the prediction model’s loss function can be divided into training loss and validation loss. The curves are shown in
Figure 7a. The figure shows that during the model training, the training loss and validation loss decrease rapidly when the number of iterations is between 0 and 50. When the number of iterations reaches 200 or more, the loss value of the prediction model starts to stabilize gradually. From the curves of precision, recall, F1-Score, and mAP in
Figure 7b, it can be seen that the trained prediction model does not show any overfitting phenomenon. In addition, each accuracy index of the model ends up at 0.96 or above.
It can be seen that the improved Yolov5s network has high detection accuracy for coal and gangue. The following figure shows some of the detection results of the improved Yolov5s model on the validation set. In this case, the predicted borders with low confidence have been filtered. It can be found that when single coal or gangue of different sizes are in one image, or even when coal and gangue are mixed, the improved Yolov5s can still identify and locate them accurately, which further indicates the effectiveness of the proposed model in coal and gangue detection.
The coordinate and scores of the bounding box of coal and gangue in
Figure 8 are shown in
Table 3. Where (
) is the upper left coordinate of the bounding box and (
) is the lower right coordinate of the bounding box. The labels are divided into coal and gangue. The coordinates of the bounding box can be obtained to get the positions of coal and gangue, and the relative sizes of coal and gangue can be obtained from the bounding box coordinates. It shows that the improved Yolov5s can identify the coal and gangue accurately and obtain the position and pair size of coal and gangue, which helps the sorting operation of coal and gangue.
3.4. Optimization of Lightweight Scheme and Attention Mechanism
The results of comparing the lightweight schemes of the 15 models proposed in
Section 2.3.2 are shown in
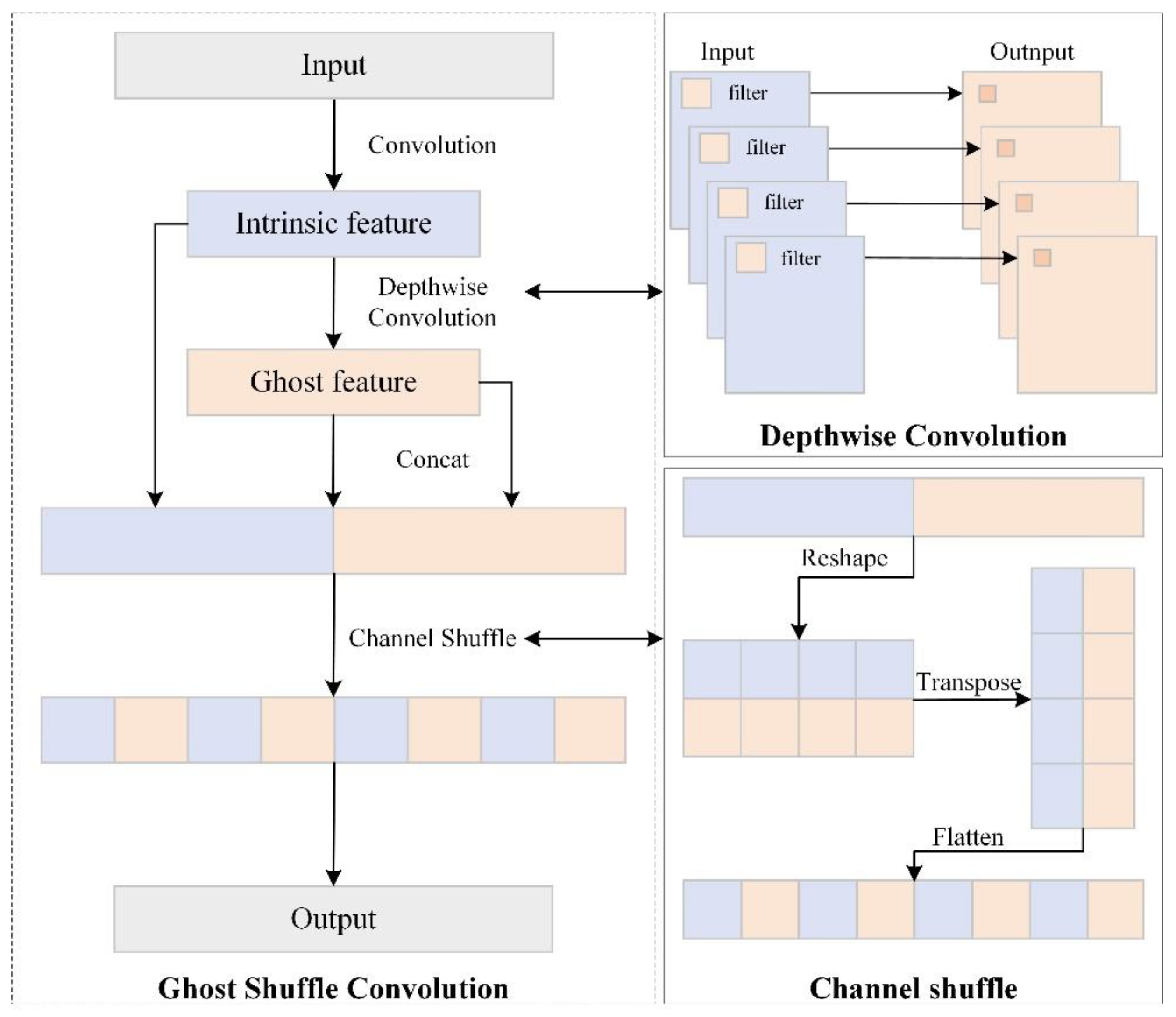
Table 4, where “√” indicates that the corresponding strategy is used and “×” indicates that the corresponding strategy is not used. Schemes 1–3 are experiments of replacing the DWC module alone. Schemes 4–6 are experiments of replacing the GSC module alone. Schemes 7–9 are DWC modules that only introduce backbone network experiments. Schemes 10–12 are experiments of introducing the DWC module into the neck network only. Schemes 13–15 are the experiments introducing the DWC module to the whole network. By comparing Schemes 1–3 and 4–6, it can be seen that the DWC module and the GSC module differ in the degree of lightweight of the network. Although the DWC module shows some advantages in reducing the model complexity and size, the accompanying price is that the detection accuracy of the model is also lost to some extent. The comparison results of Schemes 7–15 show that the computational cost of the model and the detection accuracy can be effectively balanced by analyzing the pairing of DWC and GSC modules in different positions in the network.
Throughout the experiment, the mAP of Scheme 5, Scheme 6, Scheme 7, Scheme 9, Scheme 11, and Scheme 14 remained above 0.98. However, scheme 14 maintained a higher mAP while the model size was reduced to its lowest. Therefore, considering the detection accuracy and complexity of the model, we finally chose scheme 14 as the basis for the next step of improving the model. This Scheme is as follows: in the backbone network, all the standard convolutions are replaced with deep ones except for the first layer and the bottleneck block. In the neck network, the normal convolution used for downsampling is replaced with a deep convolution. Except for the bottleneck block, the ordinary convolution in the C3 structure is replaced with the GSC module.
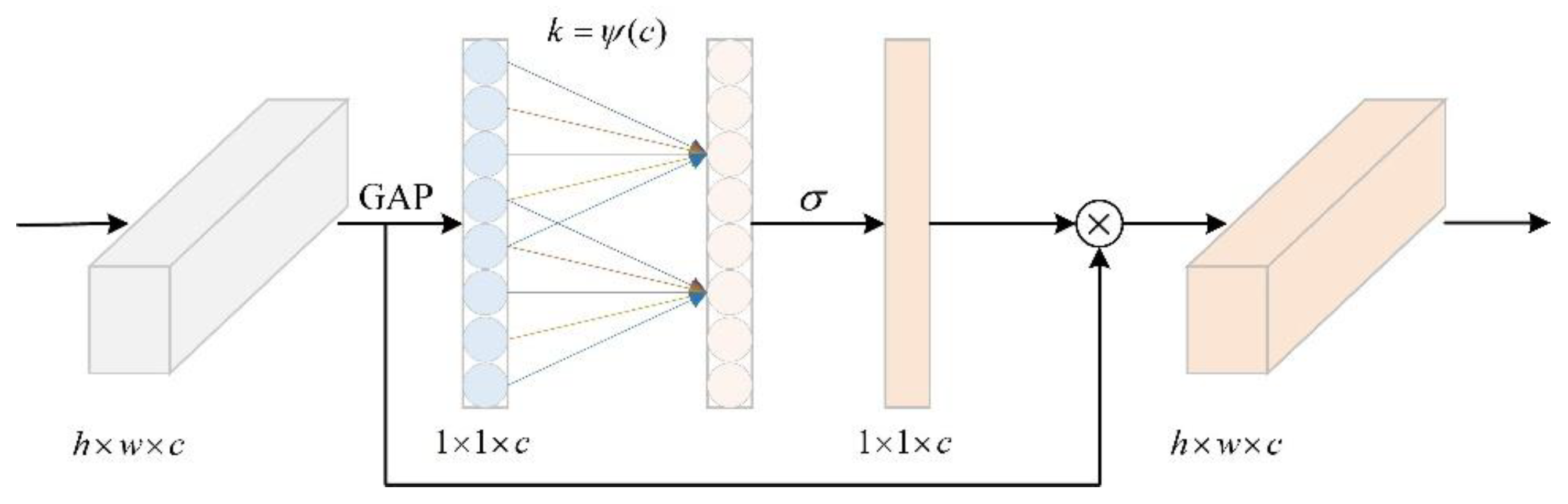
From the above experimental results, we find that although the lightweight operation can reduce the computational cost of the model, the performance of the model is also affected to some extent. Therefore, we compensate for the accuracy degradation caused by the lightweight operation by adding an attention mechanism to the model in the previous step. However, different attention mechanisms bring different effects to the model. On this basis, we introduced the ECA, Coordinate Attention (CA) [
38], Convolutional Block Attention Module (CBAM) [
39], and Global Attention Mechanism (GAM) [
40]. Among them, the ECA module focuses on increasing attention to the channel dimension, and the remaining three modules combine attention to the channel and to spatial dimensions. The comparison results are shown in
Table 5. The ECA module improves the model’s performance in this paper the most compared with other attention modules. The addition of the ECA module improves the network accuracy to a certain extent while not burdening the complexity of the model. However, after the introduction of CA, CBAM, and GAM modules, the complexity of the model increased, and the accuracy decreased. The results indicate that the lightweight model is more sensitive to the information interaction between feature map channels.
To observe more intuitively the effect of adding different attention mechanisms to the model, we used Grad-CAM as a visualization tool [
41]. It can be seen from
Figure 9 that the ECA module helps the model locate the object of interest more precisely than the other modules while achieving the highest detection accuracy.
3.5. Ablation Experiments
In order to verify the improvement of the model’s performance in this paper, one of the improvement points is compared and analyzed in this paper. The ablation study is performed on the homemade coal and gangue datasets with the same validation set and image input size. The results of the ablation experiments are summarized in
Table 6.
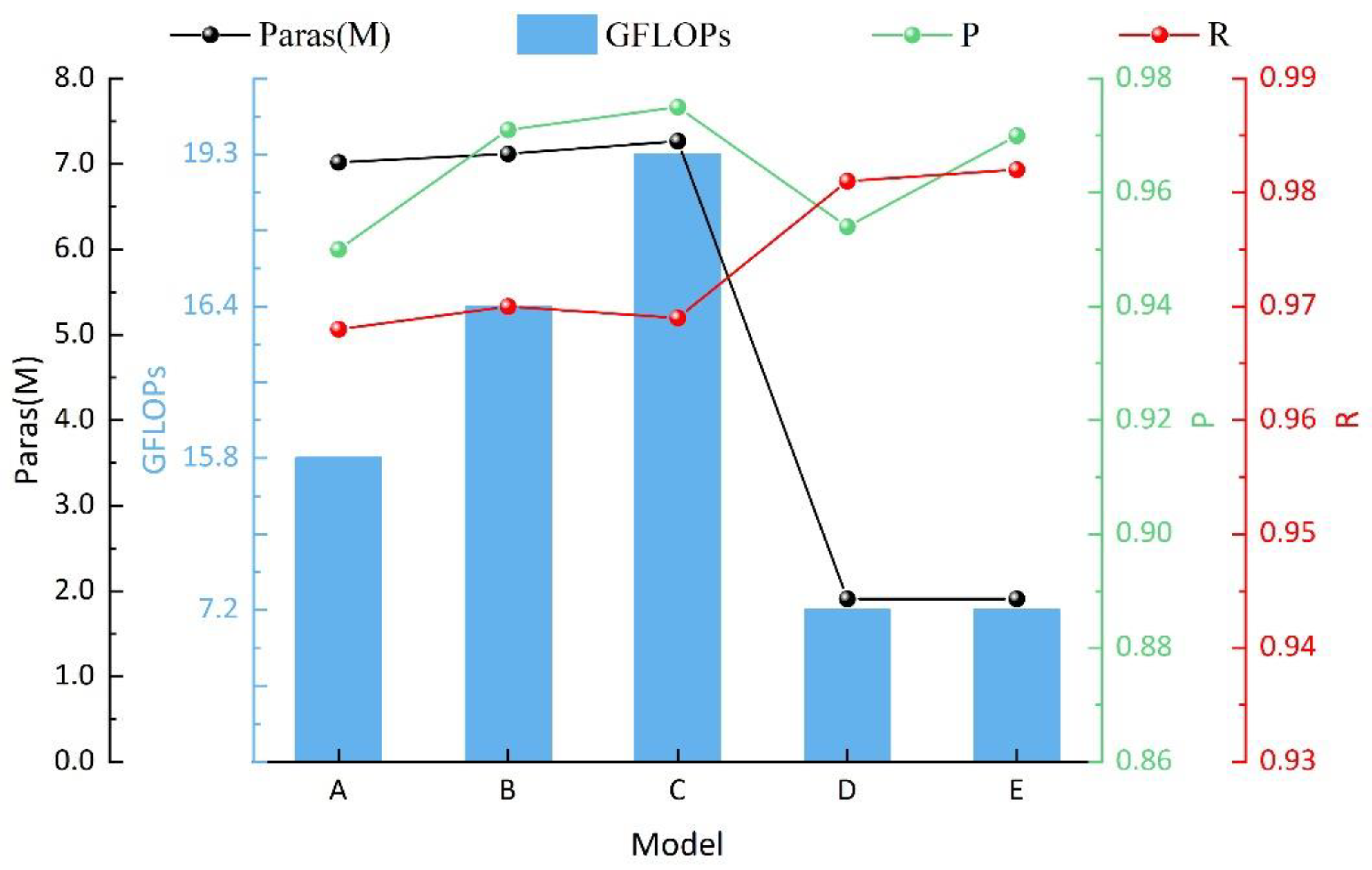
In
Table 6, Model A is the original Yolov5s; Model B replaces the activation function in Yolov5s with FReLU; Model C adds a small target detection head based on model B to achieve a four-scale detection output; Model D is a lightweight operation based on C; and Model E introduces the ECA module based on D. The details are as follows.
FReLU: The original nonlinear activation function SiLU in the network is replaced with FReLU to make the model adaptive and acquire the local image context for coal and gangue. The APs of coal and gangue reach 0.988 and 0.976, respectively. mAP and F1-Score are as high as 0.982 and 0.971, respectively, which are 0.3% and 1.2% better than the original Yolov5s network. The results show that the detection rate of the correct target frame for most of the coal and gangue has been improved, proving the effectiveness of the FReLU activation function for network optimization.
Small target detection head: By adding the small target detection head to the original network, the F1-Score and mAP improved by 0.1% and 0.3%, respectively. It indicates that the added detection branch anchor frames are set to the size of small targets, which can significantly reduce missed and false detections due to oversized anchor frame settings. However, the model size increases due to the added feature layer.
Lightweight: The model is lightened by pairing DWC and GSC modules on the network of multilayer detection heads. The results show that although the mAP and F1-Score are reduced to 0.981 and 0.968, respectively, the model’s size is reduced by 67.97% compared to model C.
ECA module: By integrating the ECA attention mechanism into the backbone network of model D, the F1-Score and mAP is improved by 0.8% and 0.4%, respectively, with no change in the size of the model. The results show that this module helps improve the model performance while avoiding increasing the model complexity.
In addition, the performance of the above five models in terms of precision, recall, the number of parameters and FLOPs of the model are shown in
Figure 10. The improved Yolov5s have improved the precision and recall of the model while significantly reducing the complexity of the model compared to the original network.
3.6. Comparison Experiments with Related Methods
To further validate the performance of the proposed model, we compare it with Yolov3-tiny [
42], Yolov4-tiny [
36], Yolox-tiny [
43], Yolov6-tiny [
44], Yolov7-tiny [
45] and some lightweight variants of Yolov5-based networks. For example, GhostNet [
46], ShuffleNetv2 [
47], and MobileNetv3 [
48] are used instead of Yolov5 backbone networks. However, previous studies differed regarding computer hardware, parameter settings, and data sets used in training and validation, which prevented scientific comparisons. To avoid the impact of these differences, the target detection algorithm described above was retrained in this study. The results are shown in
Table 7.
Our proposed model is optimal in terms of recall, F1-Score, number of model parameters, and model size compared to other networks. The highest recall and F1-Score improved by 2.9% and 3.3%, respectively, while the highest number of model parameters and size decreased by 81.95% and 78.7%, respectively. Compared with the previous Yolo series lightweight networks, the mAPs of each network are similar in terms of accuracy. Although the precision of the proposed model is second only to Yolov7-tiny, our proposed model has a clear advantage in characterizing the model size. For example, the number of parameters, FLOPs and size of the proposed model is reduced by 68.39%, 45.45% and 60.16%, respectively, compared to Yolov7-tiny. Compared with the lightweight variant of the Yolov5 network, although Yolov5 (MobileNetv3) and Yolov5 (ShuffleNetv2) slightly outperform the model in this paper in terms of FLOPs and mAP, respectively, the rest of the evaluation metrics are not outstanding. In summary, the overall performance of the proposed model is better than that of the compared models.
In addition, some detection results of coal and gangue mixtures are selected to visualize the difference in the detection performance of the above algorithms. The results are shown in
Figure 11. In addition to the inspection boxes set in the algorithm, the green elliptical boxes represent the cases of missed and false detection by the models. The figure shows that Yolov5s, Yolo series lightweight models and variants of the Yolov5 network have different degrees of false detection and missed detection for different sizes of coal and gangue. However, the model proposed in this paper is free of false and missed detections under the same detection conditions. In addition, compared with the original Yolov5s network, the prediction values of this model for small-scale coal and gangue are mostly higher than those of the original network model. Thus, it is proved that the proposed model is adequate for coal and gangue target detection.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}