
Research on Industry Data Analytics on Processing Procedure of Named 3-4-8-2 Components Combination for the Application Identification in New Chain Convenience Store

 , ,
, ,
Abstract
:1. Introduction
2. Literature Review
2.1. Chain Convenience Store and Its Applications
2.2. Industry Data Mining
2.3. Attribute Selection Technique
2.4. Data Discretization Technique
2.5. Classification Algorithm
- (1)
- Bayes net: a Bayes net definition includes a directed acyclic graph (DAG) and a set of conditional probability tables. Explanation of DAG: DAG has no ring, no turning back, never turning back, and just moving forward. DAG can be redrawn, so that all edges extend in the same direction and all points have a sequence. Each node in DAG represents a random variable, which can directly observe the variable or hide the variable, while the directed edge represents the conditional dependence between the random variables. Each element in the conditional probability table corresponds to a unique vertex in the DAG and stores the joint conditional probability of this vertex for all its immediate predecessors. The training of Bayes net is divided into the following two steps: (1) to determine the topological relationship between random variables and form the DAG, which usually requires the domain experts to complete, and in order to establish a good topological structure, it usually requires repeated operations and improvements; (2) to train the Bayes net: this step is to complete the construction of the conditional probability table. If the value of each random variable can be directly observed, the training in this step is intuitive, similar to Naive Bayes classification. However, there are hidden variable vertexes in Bayes net, so the training methods are complicated, such as the gradient descent method. Research on Bayes net has been applied in various fields, such as intelligence quotient [24], learning style [25], patient discharge [26], and cervical cancer [27]. Bayes net can combine data with expert knowledge judgment and not only has the ability to predict but also can perform calculations for uncertain problems, showing the correlation between variables. For example, Bayes net is used in the prediction of consumer review analysis [28]. The Bayes net was chosen for this study experiment because it performed well in various domains when applied to classification tasks from past studies.
- (2)
- Logistic regression: logistic is similar to linear regression analysis, mainly discussing the relationship between dependent variables and independent variables. The dependent variable (Y) in linear regression is usually a continuous variable, but the dependent variable (Y) discussed in logistic regression is mainly a category variable, especially variables divided into two categories (e.g., yes or no, with or without, agreed or disagreed, etc.). Logic regression is a statistical method used to analyze data sets with binary dependent variables (binary system). It can be used to find a relationship between a dependent binary variable and one or more independent variables. Each independent variable is multiplied by the weight and summed. This result is added to the sigmoid function to find the result between 0 and 1. Values above 0.5 are treated as 1; values below 0.5 are treated as 0, and it is important to find out the best weight or regression coefficient. Therefore, optimization techniques are used to find the optimal regression coefficient and weight [29]. Logistic regression does not require much computing resources, so it is widely used. In particular, from the study of Demidenko [30], it is indicated that there is no consensus on the approach to calculate the computational power resource and data sample size with logistic regression. Thus, the problem of defining unknown data sample size with power is important in different industry fields, especially in cases of expensive measurements of industrial applications. In [30], a Wald-based power and data sample size formula had been derived for logistic regression and proposed to minimize the total data sample sizes within a case–control study in order to obtain a power given by optimizing the ratio of control cases; as a result, the optimal control cases are equal to the square root of the alternative odds ratio. Moreover, Motrenko et al. [31] treated the parameters of a regression model as a multivariate variable and used the distance of parameter distribution functions on cross-validation datasets to measure the data sample size, and they supported an applied mathematics contribution to data mining and statistical learning.Interestingly and importantly, it is also a key issue to address and describe the problem of related resource consumption in actual analysis when the data size is unknown. For example, the World Wide Web has grown and collected new data from being an active industry platform and has arrived at immense speed to a big data, and this situation has spawned a specialized computing basis in the data paradigm, where the massive amount of given data must be processed within a reasonable response time in order to handle its high velocity; thus, this spurred several ideas for processing fast data interests [32]. In [32], the authors proposed and optimized the prototype of their so-called Raincoat query, and they demonstrated the significant contribution in increasing the performance of a Raincoat query; concurrently, they used the random sampling method to estimate cardinality and to store less data compared to histograms, and this method is especially important since the total data size is not known like with data stream structure, which can take advantage of less time to compute the estimate data. Regarding data streams of a big data framework [33], many techniques such as different sampling algorithms have developed to overcome the dilemma between resource consumption and unknown data size and some have shown superior performance in recent years. In particular, from the research of Cardellini et al. [34], it is indicated that dealing with unbounded dataflows, data stream application is typically long running and thus likely experiences varying workloads and working conditions over time.Looking back to logistic regression, it is easy to interpret, requires no adjustment of input features and is easy to normalize, and its output is a well-corrected predicted probability. For example, the application in predicting waiting and treatment times in emergency departments [35] has a good performance. The reason for choosing the logistic regression method in this study is that it also has excellent performance in many application fields of research, so it is adopted and also used as one target of the supervised classification tools.
- (3)
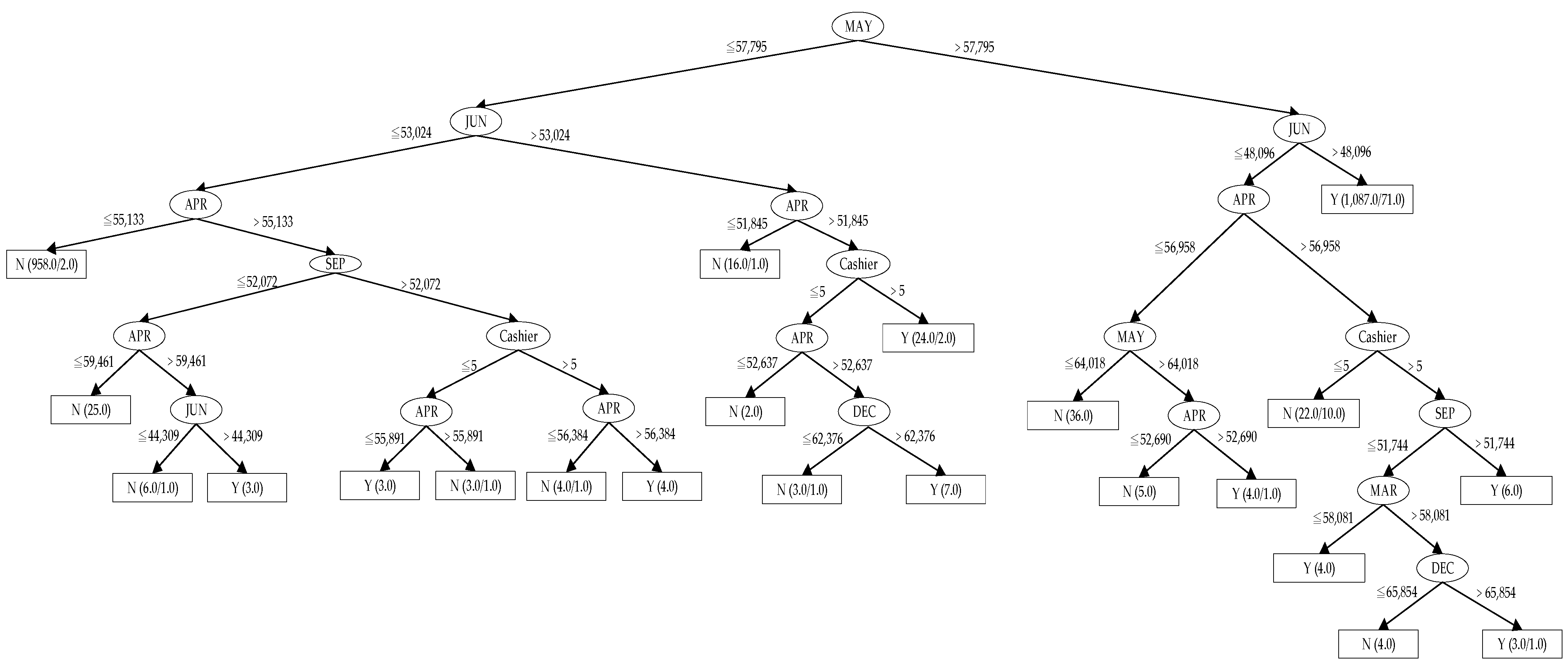
- Decision tree: decision tree is the main application tool in the field of data mining, and its method can be verified and segmented from root in order. Each branch tree represents a verification result, and the leaf node displays the distribution state of target variables, which is finally presented in the form of the tree. Each path from root to leaf node can extract a decision tree rule, and the data can be classified into a tree structure through the selection of different variables and the designation of targets, and a classification system or prediction model with hierarchical structure can be presented [36]. A variety of decision tree algorithms have been developed in modern times, mainly including Chi-squared Automatic Interaction Detection (CHAID) [37], Classification and Regression Tree (CART) [38], Interactive Dichotomiser 3 (ID3) [39], and C4.5 [40]. Advantages of decision tree classification: the classification rules are easy to understand, the data processing time is not too long, and it can also process the string data in category. Disadvantages: it is difficult to process the continuous string data type, and the data type of time series needs to be discretized first. When there are too many data types, the error rate increases rapidly. The decision tree is easy to understand and easy to extract the characteristics of the rules, which can make the research results easier to interpret through visual graphics, such as with the classification and prediction of student grades [41]. According to the performance of the decision tree, it is suitably used for comparison with other classification methods in this study.
3. Research Methods
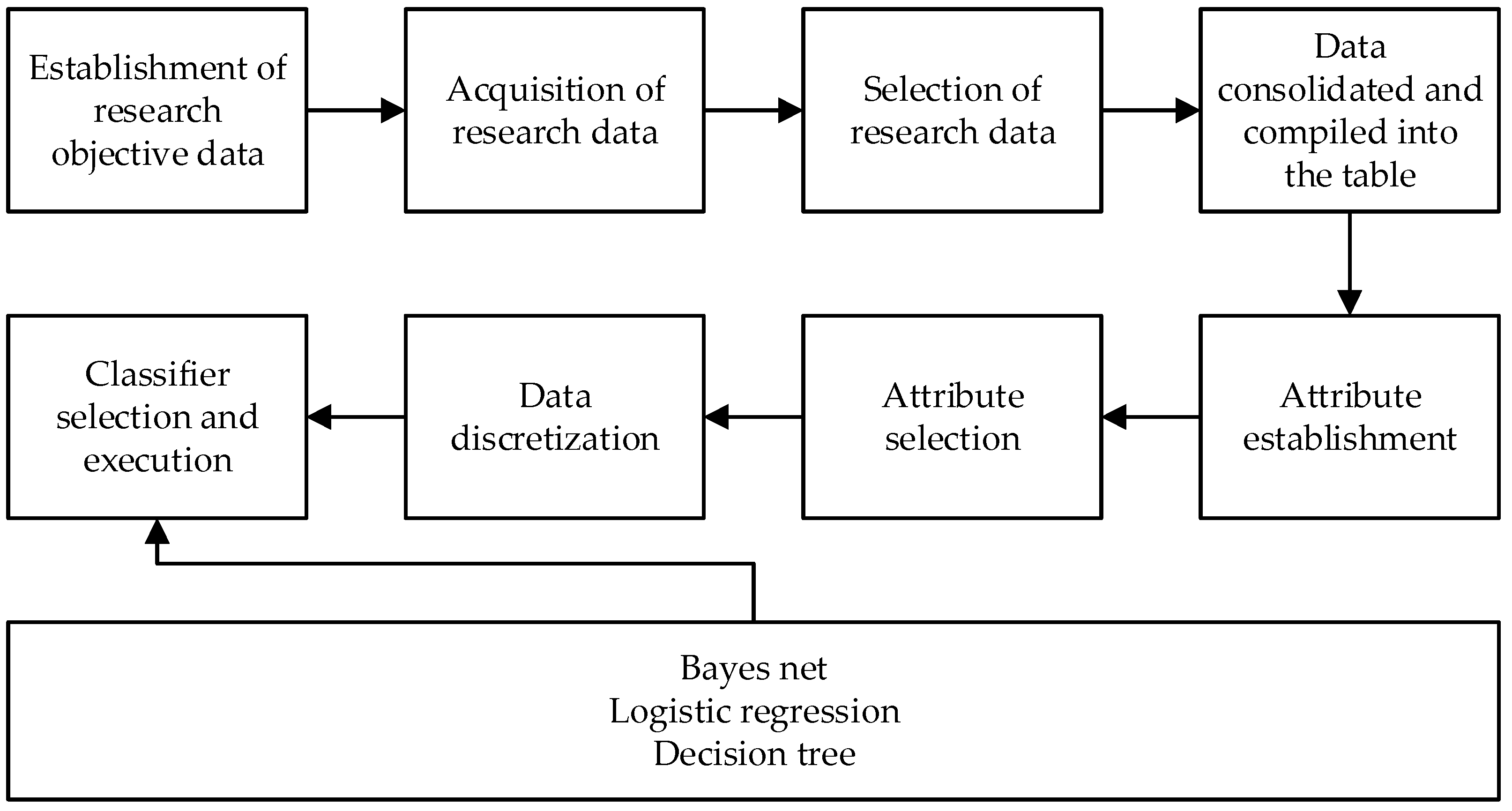
3.1. Research Framework for the Proposed Mixed Models
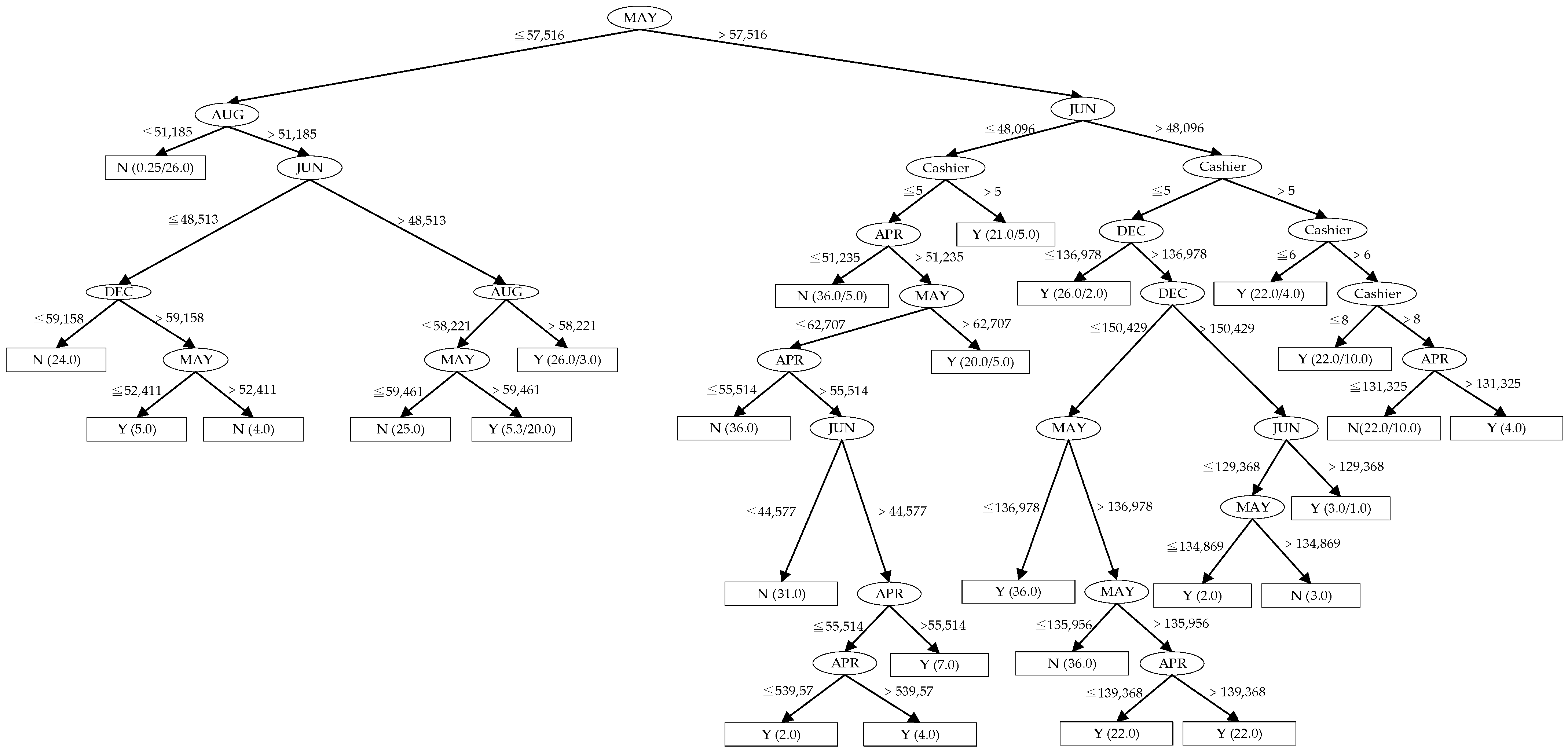
3.2. Mixed Classification Model Research Steps and Examples
4. Analysis of Empirical Results
4.1. Empirical Step Description
- (1)
- The data sets are divided into the training and testing data, and the optimal prediction model is found through machine learning techniques. The data mining tool randomly samples and trains 67% data and tests the remaining 33% data to verify the accuracy of the data analysis.
- (2)
- K times (folds) of cross-validation: the training set is divided into K subsamples and one single subsample is reserved as the data to verify the model, and the other K-1 samples are used for training. Cross-validation is repeated for K times, once for each subsample, averaging the results of K times or using other combinations, resulting in a single estimate. The advantage of this method lies in the repeated use of randomly generated subsamples for training and validation at the same time, with each result verified once. In this study, 10 times of mixed cross-validation are adopted and conducted.
4.2. Empirical Results
- (1)
- Experiment 1: net profit is the decision attribute, including the conditional attribute of daily average performance. 67% data are randomly sampled for training, and the remaining 33% data are for testing.
- (2)
- Experiment 2: profit is the decision attribute, including the conditional attribute of daily average performance, by cross-validation (10-fold mixed cross-validation). Model description:
- (3)
- Experiment 3: NSS is the decision attribute, including the conditional attribute of daily average performance. 67% data are randomly sampled for training, and the remaining 33% data are for testing.
- (4)
- Experiment 4: NSS is a decision attribute, including the conditional attribute of daily average performance, by cross-validation (10-fold mixed cross-validation).
4.3. Comparison of Experiment 1 to Experiment 8
- (1)
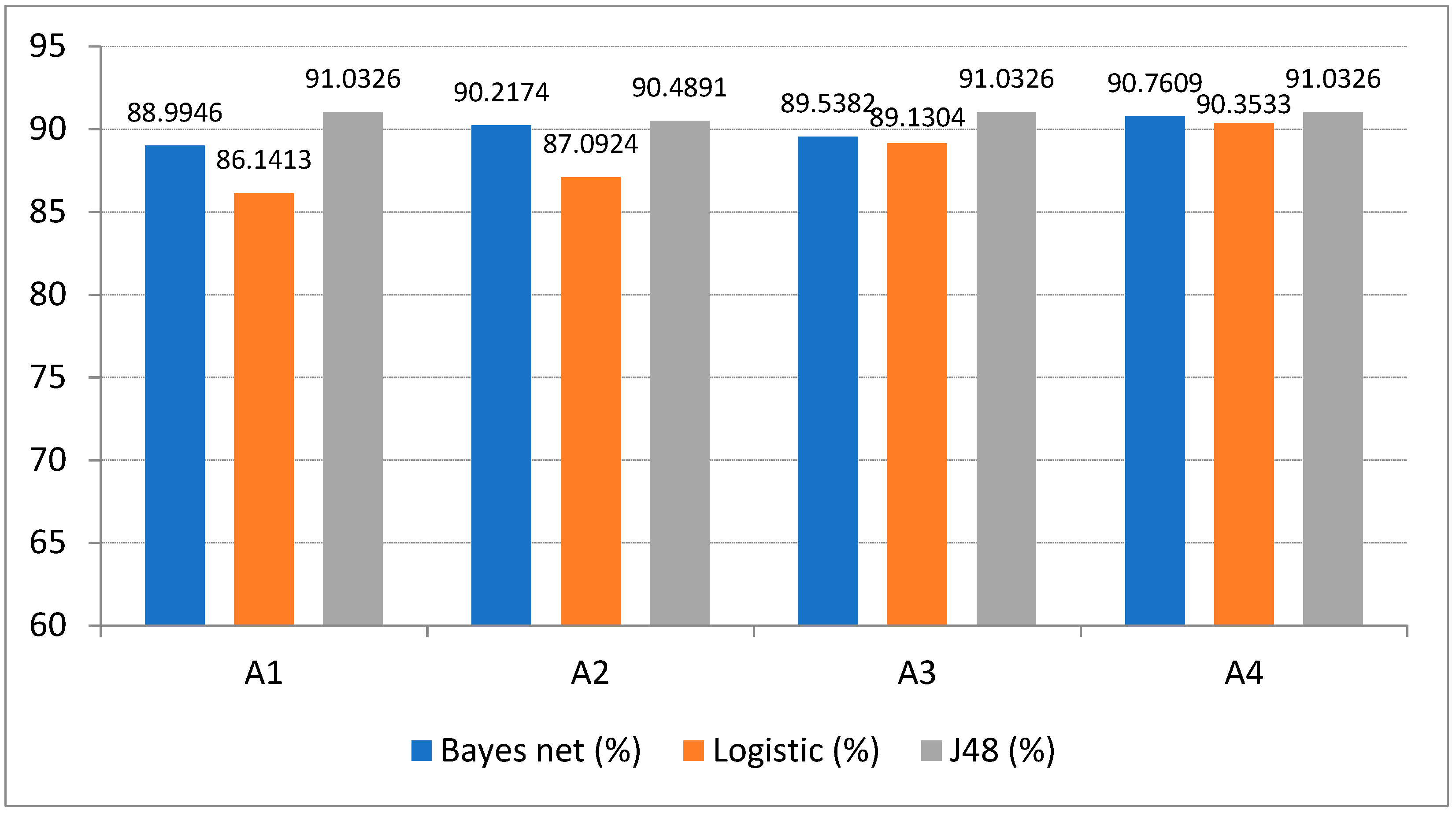
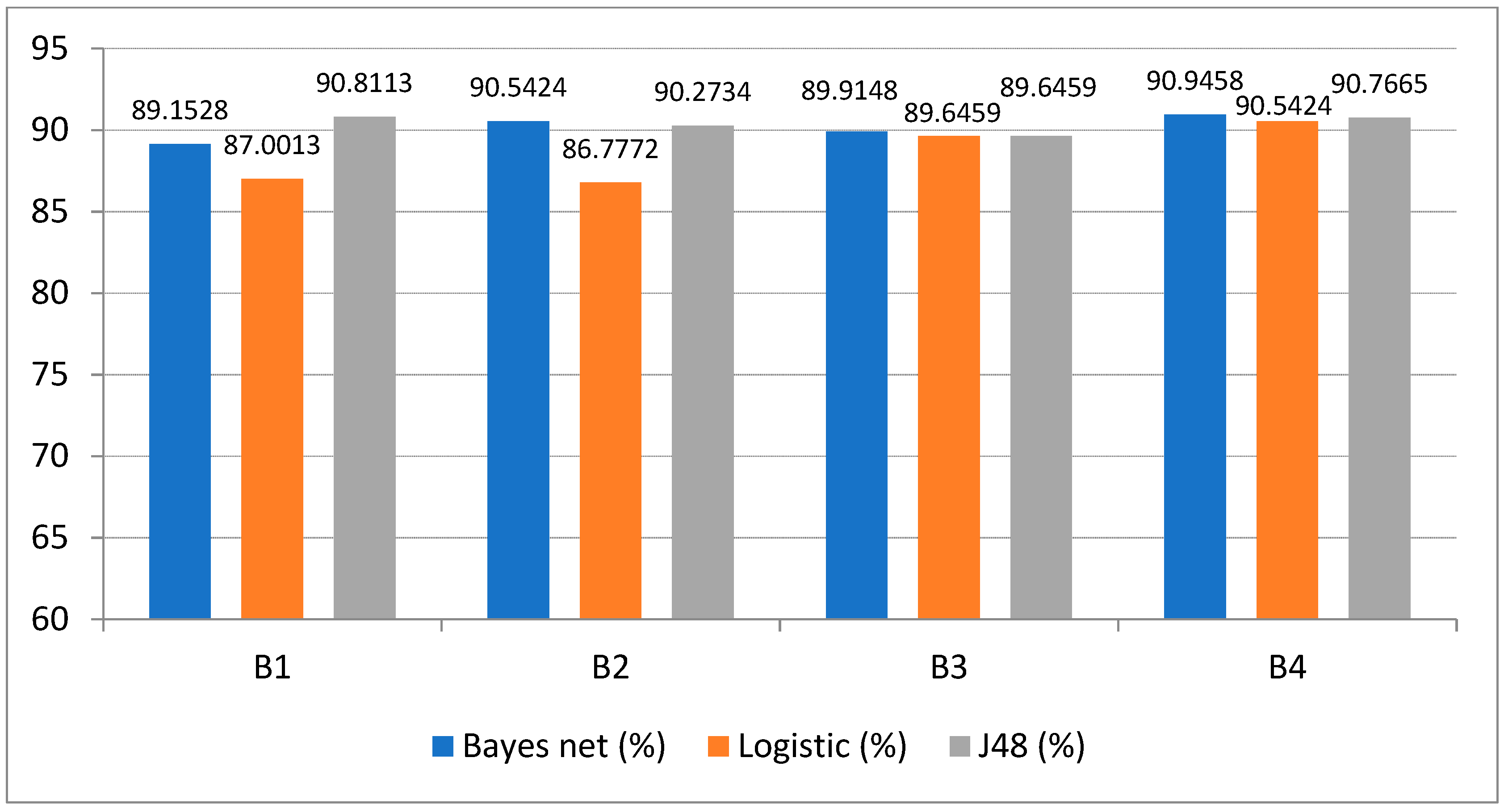
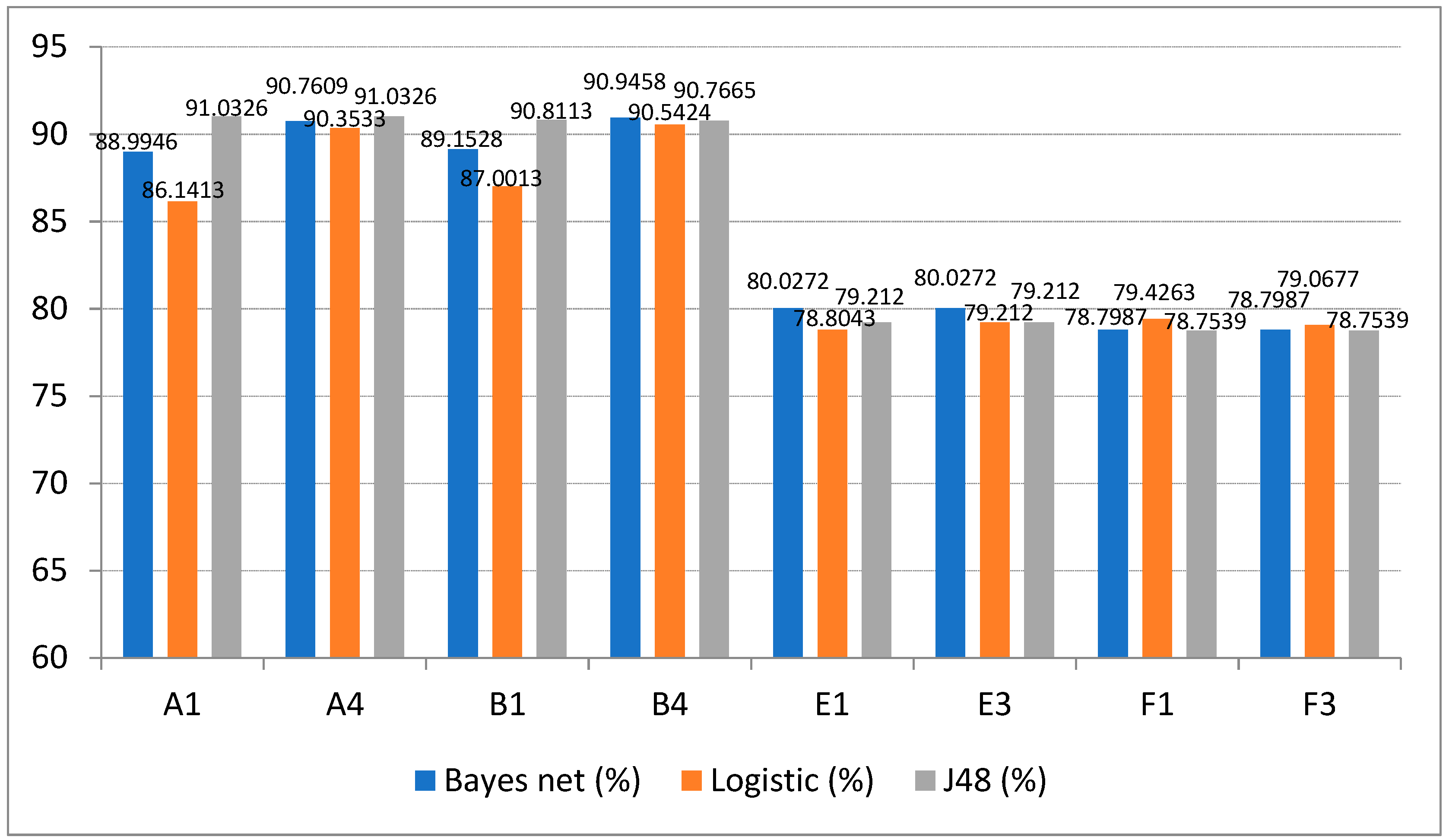
- When to predict whether the store will create a net profit, the mixed test method has a high accuracy, while whether the performance condition (PSD) is added has a great impact, with an accuracy difference of about 10%. The accuracy of the classifier based on J48 decision tree is relatively high and stable. In addition, those with data preprocessing such as attribute selection and data discretization will also have higher accuracy than those without data preprocessing.
- (2)
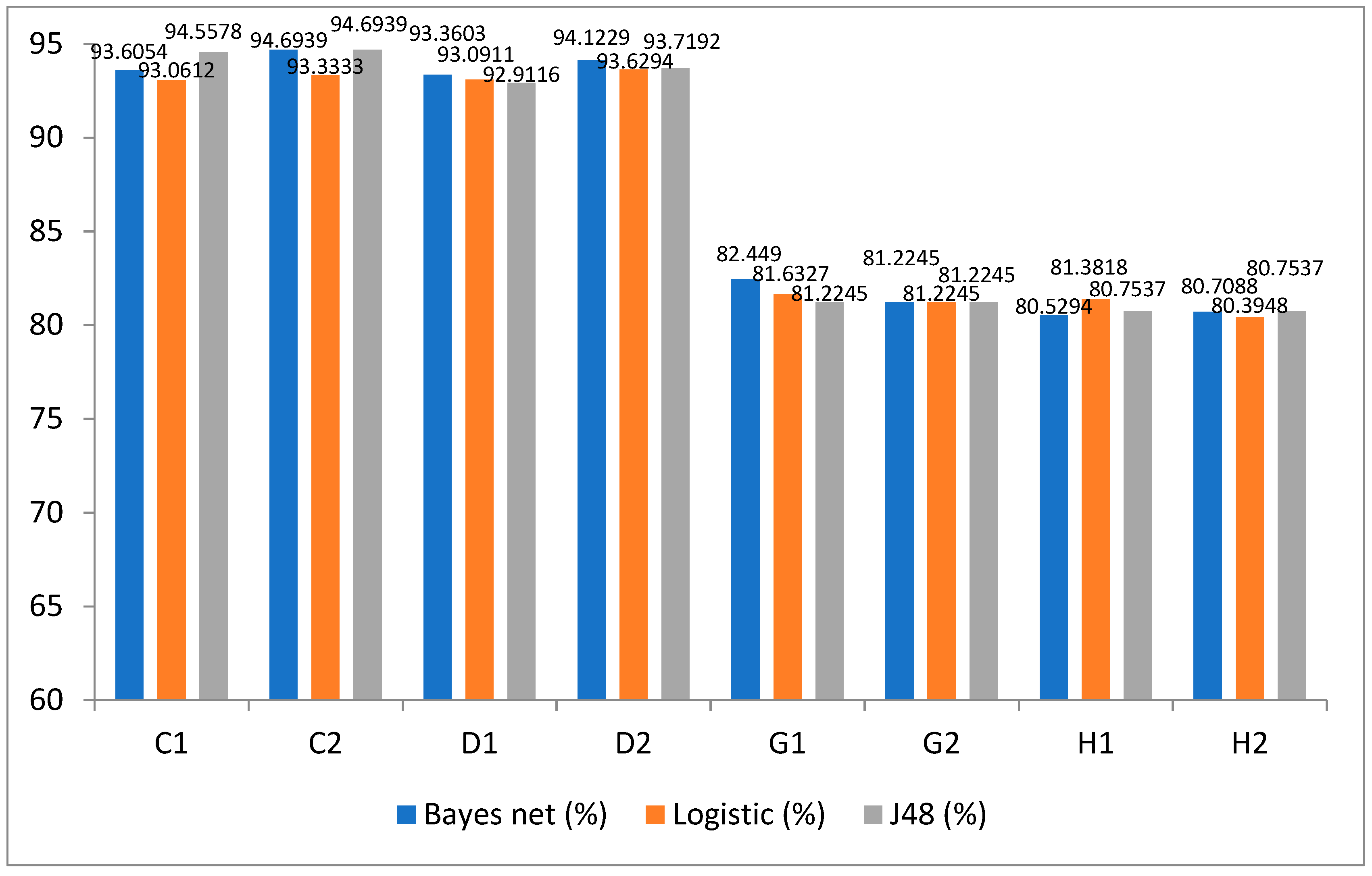
- When to predict whether this area (site) can be selected as a new store, the results are slightly different from whether the store will create a net profit. The accuracy of the test method is higher with the random sampling method, and whether the performance condition (PSD) is added has a great impact, with an accuracy difference of about 10%. The accuracy of classifiers selected in this experiment does not differ greatly. In addition, the accuracy with data preprocessing of attribute selection is higher than that without data preprocessing. The only considerable difference is that the data mining software can perform the attribute selection in the experiment but not the data discretization, resulting in poor reference for the prediction, which needs to be further studied by interested people in the future.
5. Conclusions
5.1. Discussion
- (1)
- Market selection: Considering an area or site with potential for a new store location is an important and interesting issue. It is also valuable that identifying business districts with specific functions or features can be measured based on stores, goods, service content, and demographics. Afterwards, the general selection conditions for the market of a new chain convenience store are convenient transportation, obvious landmarks, convenient parking, easy access for consumers, and targeting specific consumer groups as the primary goal. However, exploring and discussing the variables influencing market selection is a considerable task because there are too many other factors to be addressed, particularly for unpredictable events. For example, the COVID-19 epidemic is accompanied with social distancing regulations, which restrict consumers’ original shopping habits and challenge the supermarket connection with consumers. In order to minimize the contact between people, it is suggested that the location of supermarkets can be oriented towards community and delivery services. Supermarket exhibition stores are not limited to commercial areas, but they should be located in residential areas as much as possible. The purpose is to be close to consumers because the rental cost is relatively lower than that in commercial areas, and the number of stores can be more. The manpower and logistics of supermarkets may be affected by COVID-19. Automated robotics and Internet of Things (IoT) solutions can track goods and arrange shipments. Potential benefits of autonomous robots include increased efficiency, reduced errors, and improved safety. Facing the risk of uncertainty and the continuous change of online and offline consumption habits via Internet technology, it is expected that the operating mode of supermarkets can be changed more flexibly.
- (2)
- Regional analysis: It is a key concern to select the potential best area for the new store within the selected area, e.g., investigate whether there is sufficient population, whether there is a target audience, etc. If you can know who lives in the surrounding area or how many people work nearby before you create a new store, it is possible and necessary to predict the turnover.
- (3)
- On-site assessment: It is also a topic that can be discussed to take into account factors of on-site assessment, such as the number of competitors in the region, style, and popularity, etc. In this way, it is possible that the competition level of the region in the future can be estimated to adjust the brand product mix, product pricing, and service model.
- (4)
- Market positioning: The data mining techniques used for industry in this study are organized to predict whether a chain of identifying new convenience stores will be profitable, and whether an area (site) can be selected as a new store. Behind the data experiment processing, we can understand the potential demand and potential store capacity of the new store location. The scale of the new store can be huge, and the products can be various, but it is impossible to meet the needs of all consumers. Each store has a certain market scope and a specific consumer group. If the target market positioning is wrong, the store will not be able to have consumer groups and will be eliminated and excluded by the market. Thus, the market positioning is a vital part of marketing expansion. In particular, the new expansion of chain convenience stores is a long-term investment, and it is not as flexible as the marketing of manufacturing companies. Especially when the COVID-19 epidemic affects the global economy, the challenges of international convenience stores will be even more severe than that of past times.
- (5)
- Comparative studies of this paper and next-future paper: First, although the study has used past classification algorithms to construct the proposed mixed models, we still have a significantly scientific advantage and have comparative studies of “three well-known classification algorithms” (i.e., Bayes net, logistic regression, and J48 decision tree) in this paper when compared to actuarial literature. That is, we use a combination procedure of highlighting and processing a named 3-4-8-2 components experience (i.e., three above well-known classifiers with past good performance and four models (without preprocessing, with attribute selection, with data discretization, and with attribute selection and data discretization) are used for eight different experiments, through two data verification methods (percentage split and cross-validation)) to address the issue of a new chain convenience store. Furthermore, these classification algorithms used had a well-known and popular method with superior performance in a variety of application fields; thus, they are selected as the research focuses and research objects of the study. In the entire research plan, we have two phased objectives and interests: near-term (present paper) and later-term (next research). First, the present paper aims to use the past classifiers and compare them in the short term. Next, we will upgrade the subsequent research to capture and model some sophisticated new algorithms or state-of-the-art techniques to develop a robust model for further identifying applications of the new chain convenience store over the long term; at the same time, the performance of the proposed present and future new models can be compared and differentiated in order to study new issues related from the study concerns and future empirical results addressed.
- (1)
- About computer resources used for the data analysis: It is a valuable issue to discuss that the computer resources used for the data analysis interests have some key software/hardware elements, such as OS, CPU, RAM, HDD, GPU, and software for data analysis, etc. The quality of them will have positive influences on the data analysis processing and performance; thus, to explore the better combinations of these components is a priority concern and a valuable issue to explore in future research.
- (2)
- About the trade-off problem between data analysis speed and analysis accuracy: Four literature cases are addressed and studied in this problem: (a) According to the study of Fujiwara and Casanova on network simulation issues [42], they indicated and faced a trade-off problem that packet-level network simulators can enable higher accuracy for simulation, but they consume disappointingly long times; conversely, although some simulation networks are developed for a higher level to enable fast simulation, they lose accuracy performance. (b) In Guiard and Rioul [43], they focused on discovering and strengthening the roots of the problem for the speed/accuracy trade-off for the sharp concern of human-computer interaction (HCI) work, and they proposed a method, which may have the help of HCI practitioners in obtaining from their experienced data more trustworthy and more comprehensive information on the superlative achievements of design options to evaluate the related resource-allocation strategy. (c) Lu et al. [44] proposed a framework of feature fusion deep learning, a residual neural network (ResNet) combined with attention modules, with limited computing resources to balance the accuracy and speed trade-off problem with the empirical results of the high performance of a promising video-based urban traffic crash detection system. As a result, they achieved a higher detection accuracy of 87.78% as well as an acceptable detection speed (FPS > 30 with GTX 1060). (d) Norman and Bobrow [45] analyzed the performance effect for limited processing resources. Their key principles have a limited process in its performance effect, either limits in the available processing resources, such as memory or processing effort, or limits in the available data quality. From the experimental results, they showed competition among processes affects a resource-limited process, but not a data-limited one.Consequently, based on the above four examples, it is clear that data analysis speed and analysis accuracy are exactly a trade-off dilemma issue and worth discussing and examining; thus, it is also a key goal to design some related techniques or methods of interest in future work.
- (4)
- About the problem of too much low-value data and too little high-value data from Chandrashekar and Sahin [16]: Although the process of attribute selection and modeling tools or algorithms will actively select or discard attributes according to their practicability for data analysis, attribute selection will be dependent on different characteristics of the given data, and thus it cannot practically produce highly consistent standard values for addressing the low-value data and high-value data in this study.
5.2. Research Finding
- (1)
- In this study, three classifiers, Bayes net, logistic regression, and decision tree are used to predict whether the store will create a net profit and whether this area (site) can be selected as a new store. A set of rules are developed as reference elements according to the empirical results. This is an important purpose of this study, and this provides effective knowledge-based references to academicians and practitioners.
- (2)
- In this experiment, the store performance is considered for comparison, and it is also found that if PSD data are not included, the accuracy of prediction would decrease by about 10%. In addition, the store size, such as the number of cashiers and POS as well as population development index, would also affect the prediction of new store expansion or profit and loss. It is obvious that current store management can be a reference for the evaluation of future store expansion in this area.
- (3)
- In this experiment, we found that climate and population are not valuable for the analysis of data mining software when selecting the attributes. Empirically, we also found that if the data is not preprocessed, the accuracy will be about 10% lower than if the data is preprocessed. Moreover, it is expected that this research can reduce the time and cost of new store selection and opening in an enterprise’s operation, and then help the enterprise to obtain the maximum benefits and business opportunities.
5.3. Research Contribution
- (1)
- Academic contributions: In this study, four models, namely without preprocessing, with attribute selection, with data discretization, with attribute selection and data discretization, are discussed, respectively. The classifiers used are Bayes net, logistic regression, and decision tree for data analysis. Within the scope of this study, the data analysis shows that the performance of the decision tree classifier is stable, and the average accuracy is high. Moreover, to model such a hybrid approach by machine learning techniques for assessment and selection applications of new chain convenience stores is rarely seen from past studies; thus, this study owns significant research interest.
- (2)
- Enterprise contributions: Due to the different culture and climate factors, the new store expansion application is not necessarily universal. Country-A is in the role of a developing country in ASEAN member countries, so the successful experience of Country-A’s chain convenience store B is appropriate as the research object, hoping to help enterprises desiring to develop new chain convenience stores in Country-A.
- (3)
- Application contributions: Although modeling the mixed model from methodology views is not the key objective of this study, the core applications of the modeled methods are also key, intensified by the impressive results, to benefit the challenges of future application issues. This study provides a good bellwether in the field of data mining for new chain convenience store applications.
- (4)
- Management contributions: This study offers trees-based knowledgeable rules as practical managerial directions for different purposes of interested parties and also contributes helpful management references to discover the related chain convenience store information from the study experiences.
5.4. Research Limitation
5.5. Future Studies
- (1)
- As there are many factors that determine whether the store will create a net profit and this area (site) can be selected as a new store, such as store rent, personnel costs, water and electricity expenses, and taxes, which are not included in the scope of this study, the prediction reference may be inaccurate, and it is expected to be further explored in depth in the future.
- (2)
- This proposed mixed method can be applied to the data analysis of different industries. For example, the commodities of fresh food stores include fresh food, daily necessities, etc., which will be affected by external environment changes of geographical location, population structure, regional attributes, weather, and seasons.
- (3)
- The demand from different stores is different. Through data mining tools, it is possible to predict the demand of store merchandise and discuss the competition pattern among stores and the research on key factors of influencing demand.
- (4)
- We will further build state-of-the-art classification techniques to construct a robust model for further re-identifying applications of new chain convenience store issues in our next research.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Department of Economic and Social Affairs. Available online: https://www.un.org/development/desa/zh/about/desa-divisions/population.html (accessed on 20 January 2022).
- Statista. Available online: https://www.statista.com/ (accessed on 23 January 2022).
- Davies, R.L.; Rogers, D. Store Location and Store Assessment Research; John Wiley & Sons Inc.: Hoboken, NJ, USA, 1984. [Google Scholar]
- Jaravaza, D.C.; Chitando, P. The role of store location in influencing customers’ store choice. J. Emerg. Trends Econ. Manag. Sci. 2013, 4, 302–307. [Google Scholar]
- Reynolds, J. Retail location analysis: An annotated bibliography. J. Target. Meas. Anal. Mark. 2005, 13, 258–266. [Google Scholar] [CrossRef]
- Levy, M.; Weitz, B.A.; Beitelspacher, L.S. Retailing Management, 8th ed.; McGraw Hill: New York, NY, USA; Irwin: Huntersville, NC, USA, 2012. [Google Scholar]
- Wood, S.; Reynolds, J. Leveraging locational insights within retail store development? assessing the use of location planners’ knowledge in retail marketing. Geoforum 2012, 43, 1076–1087. [Google Scholar] [CrossRef]
- Church, R.L.; Murray, A.T. Business Site Selection, Location Analysis, and GIS; John Wiley & Sons: Hoboken, NJ, USA, 2009; pp. 209–233. [Google Scholar]
- Wieland, T. Market area analysis for retail and service locations with MCI. R. J. 2017, 9, 298–323. [Google Scholar] [CrossRef] [Green Version]
- Santos-Pereira, J.; Gruenwald, L.; Bernardino, J. Top data mining tools for the healthcare industry. J. King Saud Uni.-Comput. Inform. Sci. 2022, 34, 4968–4982. [Google Scholar] [CrossRef]
- Gandomi, A.; Haider, M. Beyond the hype: Big data concepts, methods, and analytics. Int. J. Inf. Manag. 2015, 35, 137–144. [Google Scholar] [CrossRef] [Green Version]
- Fayyad, U.M.; Piatetsky-Shapiro, G.; Smyth, P.; Uthurusamy, R. Advances in Knowledge Discovery and Data Mining; AAAI Press: Menlo Park, CA, USA, 1996; Volume 21. [Google Scholar]
- Greener, J.G.; Kandathil, S.M.; Moffat, L.; Jones, D.T. A guide to machine learning for biologists. Nat. Rev. Mol. Cell Biol. 2022, 23, 40–55. [Google Scholar] [CrossRef]
- Hamdi, A.; Shaban, K.; Erradi, A.; Mohamed, A.; Rumi, S.K.; Salim, F.D. Spatiotemporal data mining: A survey on challenges and open problems. Artif. Intell. Rev. 2022, 55, 1441–1488. [Google Scholar] [CrossRef]
- Armanfard, N.; Reilly, J.P.; Komeili, M. Local feature selection for data classification. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 1217–1227. [Google Scholar] [CrossRef]
- Chandrashekar, G.; Sahin, F. A survey on feature selection methods. Comput. Electr. Eng. 2014, 40, 16–28. [Google Scholar] [CrossRef]
- Cui, P.; Athey, S. Stable learning establishes some common ground between causal inference and machine learning. Nat. Mach. Intell. 2022, 4, 110–115. [Google Scholar] [CrossRef]
- Xu, Y.; Sun, Y.; Ma, Z.; Zhao, H.; Wang, Y.; Lu, N. Attribute selection based genetic network programming for intrusion detection system. J. Adv. Comput. Intell. Intell. Inform. 2022, 26, 671–683. [Google Scholar] [CrossRef]
- Noering, F.K.D.; Jonas, K.; Klawonn, F. Improving discretization based pattern discovery for multivariate time series by additional preprocessing. Intell. Data Anal. 2021, 25, 1051–1072. [Google Scholar] [CrossRef]
- Chen, Q.; Huang, M.; Wang, H.; Xu, G. A feature discretization method based on fuzzy rough sets for high-resolution remote sensing big data under linear spectral model. IEEE Trans. Fuzzy Syst. 2021, 30, 1328–1342. [Google Scholar] [CrossRef]
- Jane, V.A. Survey on IoT data preprocessing. TURCOMAT 2021, 12, 238–244. [Google Scholar]
- Safarkhani, F.; Moro, S. Improving the accuracy of predicting bank depositor’s behavior using a decision tree. Appl. Sci. 2021, 11, 1–13. [Google Scholar] [CrossRef]
- Awujoola, O.; Odion, P.O.; Irhebhude, M.E.; Aminu, H. Performance evaluation of machine learning predictive analytical model for determining the job applicants employment status. Malays. J. Sci. 2021, 6, 67–79. [Google Scholar] [CrossRef]
- Cooke, R.M.; Joe, H.; Chang, B. Vine regression with Bayes nets: A critical comparison with traditional approaches based on a case study on the effects of breastfeeding on IQ. Risk Anal. 2022, 42, 1294–1305. [Google Scholar] [CrossRef]
- Hidayat, N.; Afuan, L. Naïve Bayes for detecting student’s learning style using Felder-Silverman index. JUITA J. Inform. 2021, 9, 181–190. [Google Scholar] [CrossRef]
- Gramaje, A.; Thabtah, F.; Abdelhamid, N.; Ray, S.K. Patient discharge classification using machine learning techniques. Ann. Data Sci. 2021, 8, 755–767. [Google Scholar] [CrossRef]
- Suman, S.K.; Hooda, N. Predicting risk of Cervical Cancer: A case study of machine learning. Int. J. Stat. Manag. Syst. 2019, 22, 689–696. [Google Scholar] [CrossRef]
- Kannan, R.P. Prediction of consumer review analysis using Naive Bayes and Bayes Net algorithms. Turk. J. Com. Math. Edu. (TURCOMAT) 2021, 12, 1865–1874. [Google Scholar]
- Manogaran, G.; Lopez, D. Health data analytics using scalable logistic regression with stochastic gradient descent. Int. J. Adv. Intell. Paradig. 2018, 10, 118–132. [Google Scholar] [CrossRef]
- Demidenko, E. Sample size determination for logistic regression revisited. Stat. Med. 2007, 26, 3385–3397. [Google Scholar] [CrossRef] [PubMed]
- Motrenko, A.; Strijov, V.; Weber, G.W. Sample size determination for logistic regression. J. Comput. Appl. Math. 2014, 255, 743–752. [Google Scholar] [CrossRef]
- Stenersen, S.R.; Grønnbeck, K.O. Continuously adapting continuous Queries for Data Streams in Raincoat. Master’s Thesis, Institutt for Datateknikk og Informasjonsvitenskap, Trondheim, Norway, 2013. [Google Scholar]
- El Sibai, R.; Chabchoub, Y.; Demerjian, J.; Kazi-Aoul, Z.; Barbar, K. Sampling algorithms in data stream environments. In Proceedings of the 2016 International Conference on Digital Economy (ICDEc), Carthage, Tunisia, 28–30 April 2016; pp. 29–36. [Google Scholar]
- Cardellini, V.; Lo Presti, F.; Nardelli, M.; Russo, G.R. Runtime adaptation of data stream processing systems: The state of the art. ACM Comput. Surv. 2022, 54, 1–36. [Google Scholar] [CrossRef]
- Ataman, M.G.; Sarıyer, G. Predicting waiting and treatment times in emergency departments using ordinal logistic regression models. Am. J. Emerg. Med. 2021, 46, 45–50. [Google Scholar] [CrossRef]
- Lee, C.S.; Cheang, P.Y.S.; Moslehpour, M. Predictive analytics in business analytics: Decision tree. Adv. Decis. Sci. 2022, 26, 1–29. [Google Scholar]
- Kee, L.; Huynh, M.; Xanthos, P.; Davids, C.; James, L. The determinants of student attrition in an undergraduate sport and exercise science degree. J. Sport. Sci. Edu. 2022, 7, 7–16. [Google Scholar]
- Huang, K.L.; Chen, M.H.; Hsu, J.W.; Tsai, S.J.; Bai, Y.M. Using classification and regression tree modeling to investigate appetite hormones and proinflammatory cytokines as biomarkers to differentiate bipolar I depression from major depressive disorder. CNS Spectr. 2022, 27, 450–456. [Google Scholar] [CrossRef]
- Jeiad, H.A.; Ameen, Z.J.; Mahmood, A.A. Employee performance assessment using modified decision tree. J. Eng. Technol. 2018, 36, 806–811. [Google Scholar] [CrossRef]
- Riandari, F.; Sihotang, H.T.; Gautama, R.; Ramen, S. Student graduation value analysis based on external factors with C4.5 Algorithm. J. Mantik 2022, 6, 2228–2235. [Google Scholar]
- Al Karim, M.; Ara, M.Y.; Masnad, M.M.; Rasel, M.; Nandi, D. Student performance classification and prediction in fully online environment using Decision tree. AIUB J. Sci. Eng. 2021, 20, 70–76. [Google Scholar] [CrossRef]
- Fujiwara, K.; Casanova, H. Speed and accuracy of network simulation in the Simgrid framework. In Proceedings of the 1st International ICST Workshop on Network Simulation Tools, Nantes, France, 22 October 2007. [Google Scholar] [CrossRef] [Green Version]
- Guiard, Y.; Rioul, O. A mathematical description of the speed/accuracy trade-off of aimed movement. In Proceedings of the 2015 British HCI Conference, Lincoln, UK, 13–17 July 2015; pp. 91–100. [Google Scholar] [CrossRef]
- Lu, Z.; Zhou, W.; Zhang, S.; Wang, C. A new video-based crash detection method: Balancing speed and accuracy using a feature fusion deep learning framework. J. Adv. Transp. 2020, 2020, 8848874. [Google Scholar] [CrossRef]
- Norman, D.A.; Bobrow, D.G. On data-limited and resource-limited processes. Cogn. Psychol. 1975, 7, 44–64. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Item | Domain Name | Description | Attribute |
|---|---|---|---|
| 01 | Store Type | Store franchise type | Text |
| 02 | Zone | Large zone (divided by island) | Text |
| 03 | District_name | District name | Text |
| 04 | Cluster_name | Business circle | Text |
| 05 | HDI | Human development index | Number |
| 06 | Climate type | Climate coefficient | Number |
| 07 | Population | Population | Number |
| 08 | Population density | Population density coefficient | Number |
| 09 | POS | Cash register | Number |
| 10 | Cashier | Store staff | Number |
| 11 | PSD(JAN) | Average daily performance of January | Number |
| 12 | PSD(FEB) | Average daily performance of February | Number |
| 13 | PSD(MAR) | Average daily performance of March | Number |
| 14 | PSD(APR) | Average daily performance of April | Number |
| 15 | PSD(MAY) | Average daily performance of May | Number |
| 16 | PSD(JUN) | Average daily performance of June | Number |
| 17 | PSD(JUL) | Average daily performance of July | Number |
| 18 | PSD(AUG) | Average daily performance of August | Number |
| 19 | PSD(SEP) | Average daily performance of September | Number |
| 20 | PSD(OCT) | Average daily performance of October | Number |
| 21 | PSD(NOV) | Average daily performance of November | Number |
| 22 | PSD(DEC) | Average daily performance of December | Number |
| 23 | NSS | Evaluating the new store selection | Text |
| 24 | Profit | Evaluating the net profit (earning) | Text |
| Store Type | Zone | District_Name | Cluster_Name | HDI | … | PSD(OCT) | PSD(NOV) | PSD(DEC) | NSS | Profit |
|---|---|---|---|---|---|---|---|---|---|---|
| CO | South Luzon | SOUTH FIVE | Residential | 0.649 | … | 51,213 | 50,520 | 64,416 | N | N |
| FC2 | Central Luzon | CENTRAL TWO | School | 0.649 | … | 89,316 | 86,267 | 97,059 | Y | Y |
| FC3 | Central Luzon | CENTRAL THREE | School | 0.649 | … | 41,345 | 39,879 | 42,703 | N | N |
| CO | Central Luzon | CENTRAL THREE | School | 0.649 | … | 70,661 | 24,850 | 73,793 | N | N |
| SA | Central Luzon | CENTRAL THREE | Transit | 0.649 | … | 88,692 | 92,361 | 94,669 | Y | N |
| … | … | … | … | … | … | … | … | … | … | … |
| CO | Central Luzon | CENTRAL TWO | Residential | 0.649 | … | 80,697 | 82,987 | 88,594 | Y | Y |
| CO | Visayas | WESTHERN VISAYAS | Transit | 0.749 | … | 31,770 | 29,349 | 37,762 | N | N |
| FC1 | North Luzon | NORTH FOUR | Transit | 0.749 | … | 33,321 | 32,958 | 39,839 | N | N |
| CO | Visayas | WESTHERN VISAYAS | School | 0.749 | … | 30,278 | 26,797 | 28,565 | N | N |
| FC1 | South Luzon | SOUTH SIX | Commercial | 0.799 | … | 37,158 | 34,260 | 40,511 | N | N |
| Item | Domain Name | Description |
|---|---|---|
| 01 | Store type | Store franchise type |
| 02 | Zone | Divided by island |
| 03 | District_name | District name |
| 04 | Cluster_name | Business circle |
| 05 | HDI | Human development index |
| 06 | Climate type | Climate coefficient |
| 07 | Population | Population |
| 08 | Population Density | Population density coefficient |
| 09 | POS | Cash register |
| 10 | Cashier | Store staff |
| 11~22 | PSD (January–December) | Average daily performance of January to December |
| 23 | NSS | New store selection decision |
| 24 | Profit | Net profit (earning) decision |
| Climate Type | Grading Code |
|---|---|
| Two distinct seasons; dry from November to April and wet during the rest of the year. | I |
| There is no dry season; there is very significant rainfall from November to April and it gets wet for the rest of the year. | II |
| The seasons are not very obvious; relatively dry from November to April and wet during the rest of the year. | III |
| Rainfall is more or less evenly distributed throughout the year. | IV |
| Experiment Number | Model Number | Attribute Selection | Data Discretization | Classifiers | Percentage Split | Cross- Validation | Daily Average Performance | Protfit | NSS |
|---|---|---|---|---|---|---|---|---|---|
| 1 | A1 | V | V | V | V | ||||
| A2 | V | V | V | V | V | ||||
| A3 | V | V | V | V | V | ||||
| A4 | V | V | V | V | V | V | |||
| 2 | B1 | V | V | V | V | ||||
| B2 | V | V | V | V | V | ||||
| B3 | V | V | V | V | V | ||||
| B4 | V | V | V | V | V | V | |||
| 3 | C1 | V | V | V | V | ||||
| C2 | V | V | V | V | V | ||||
| C3 | V | V | V | V | V | ||||
| C4 | V | V | V | V | V | V | |||
| 4 | D1 | V | V | V | V | ||||
| D2 | V | V | V | V | V | ||||
| D3 | V | V | V | V | V | ||||
| D4 | V | V | V | V | V | V | |||
| 5 | E1 | V | V | V | |||||
| E2 | V | V | V | V | |||||
| E3 | V | V | V | V | |||||
| E4 | V | V | V | V | V | ||||
| 6 | F1 | V | V | V | |||||
| F2 | V | V | V | V | |||||
| F3 | V | V | V | V | |||||
| F4 | V | V | V | V | V | ||||
| 7 | G1 | V | V | V | |||||
| G2 | V | V | V | V | |||||
| G3 | V | V | V | V | |||||
| G4 | V | V | V | V | V | ||||
| 8 | H1 | V | V | V | |||||
| H2 | V | V | V | V | |||||
| H3 | V | V | V | V | |||||
| H4 | V | V | V | V | V |
| Model | Bayes Net (%) | Logistic Regression (%) | J48 (%) |
|---|---|---|---|
| A1 | 88.9946 | 86.1413 | 91.0326 |
| A2 | 90.2174 | 87.0924 | 90.4891 |
| A3 | 89.5382 | 89.1304 | 91.0326 |
| A4 | 90.7609 | 90.3533 | 91.0326 |
| Model | Bayes Net (%) | Logistic Regression (%) | J48 (%) |
|---|---|---|---|
| B1 | 89.1528 | 87.0013 | 90.8113 |
| B2 | 90.5424 | 86.7772 | 90.2734 |
| B3 | 89.9148 | 89.6459 | 89.6459 |
| B4 | 90.9458 | 90.5424 | 90.7665 |
| Model | Decision attribute | Performance Condition | Test Method | Bayes Net (%) | Logistic (%) | J48 (%) |
|---|---|---|---|---|---|---|
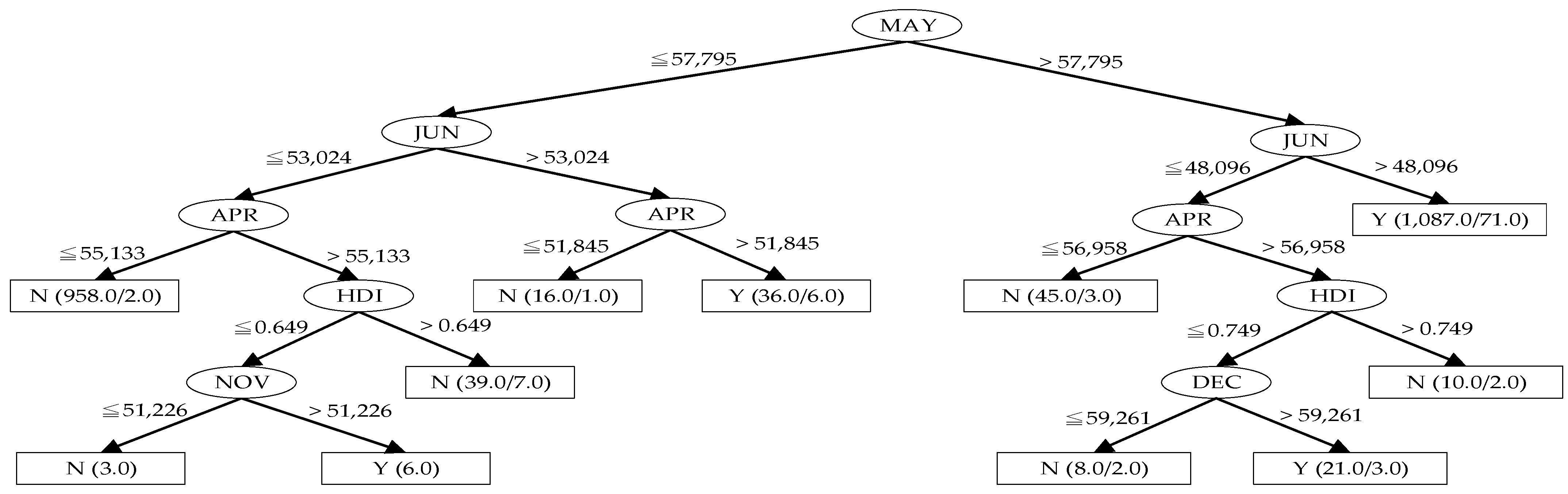
| A1 | Profit | Y | Random Sampling | 88.9946 | 86.1413 | 91.0326 |
| A4 | Profit | Y | Random Sampling | 90.7609 | 90.3533 | 91.0326 |
| B1 | Profit | Y | Mixed | 89.1528 | 87.0013 | 90.8113 |
| B4 | Profit | Y | Mixed | 90.9458 | 90.5424 | 90.7665 |
| E1 | Profit | N | Random Sampling | 80.0272 | 78.8043 | 79.2120 |
| E3 | Profit | N | Random Sampling | 80.0272 | 79.2120 | 79.2120 |
| F1 | Profit | N | Mixed | 78.7987 | 79.4263 | 78.7539 |
| F3 | Profit | N | Mixed | 78.7987 | 79.0677 | 78.7539 |
| Model | Decision Attribute | Performance Condition | Test Method | Bayes Net (%) | Logistic (%) | J48 (%) |
|---|---|---|---|---|---|---|
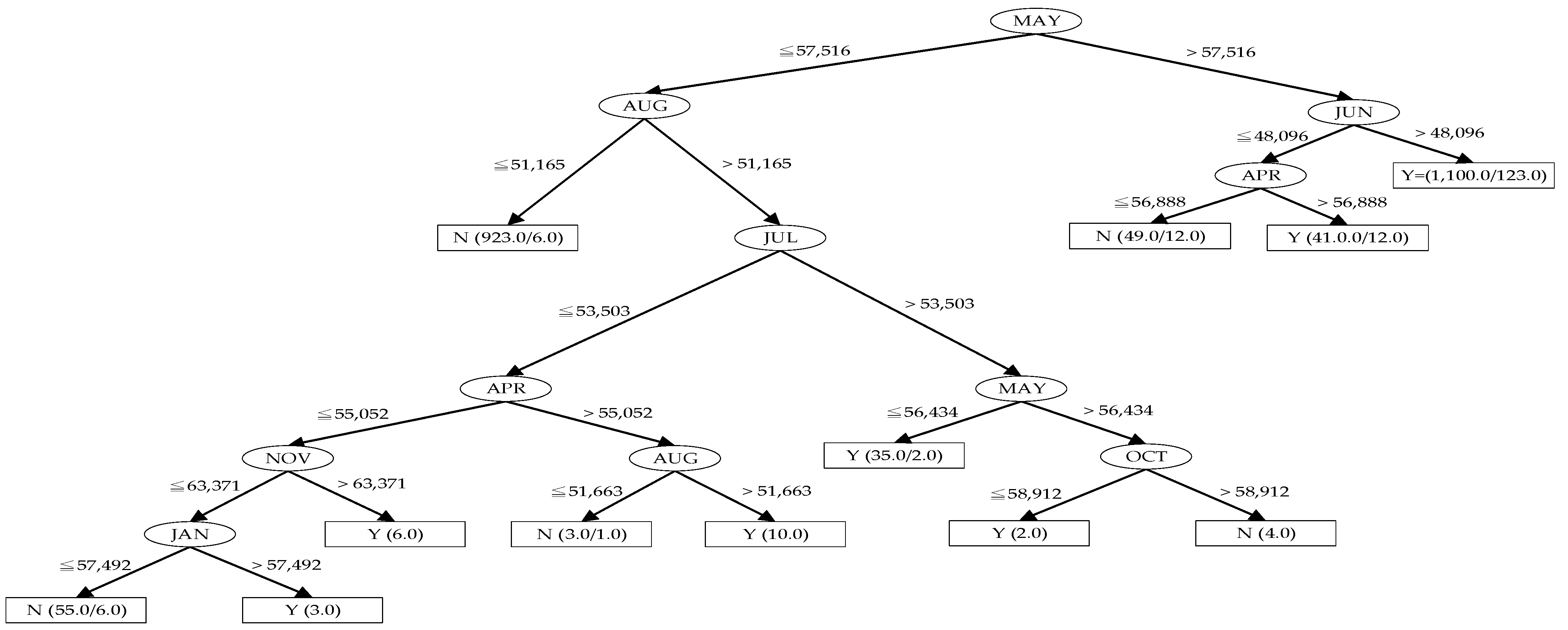
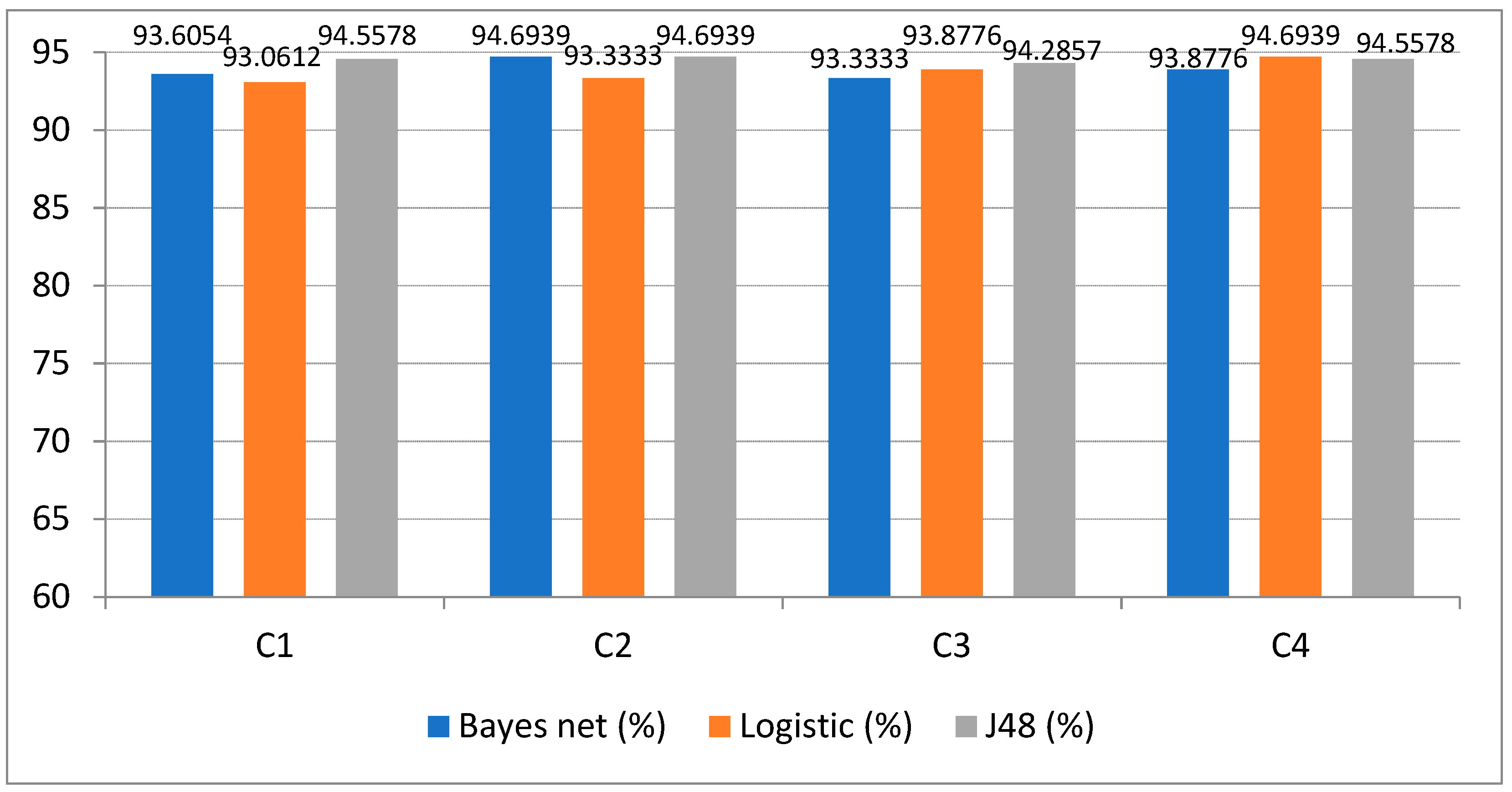
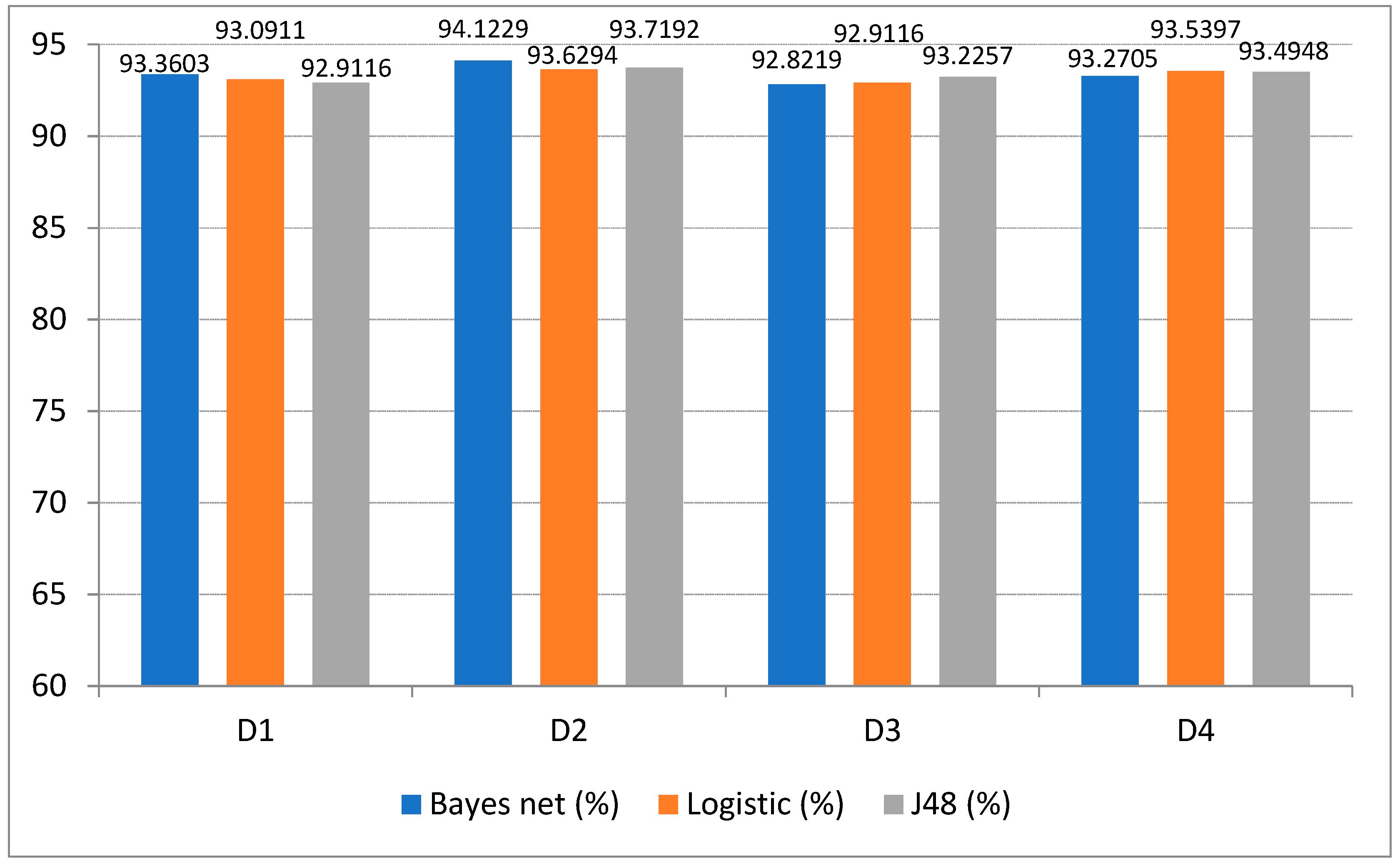
| C1 | NSS | Y | Random Sampling | 93.6054 | 93.0612 | 94.5578 |
| C2 | NSS | Y | Random Sampling | 94.6939 | 93.3333 | 94.6939 |
| D1 | NSS | Y | Mixed | 93.3603 | 93.0911 | 92.9116 |
| D2 | NSS | Y | Mixed | 94.1229 | 93.6294 | 93.7192 |
| G1 | NSS | N | Random Sampling | 82.4490 | 81.6327 | 81.2245 |
| G2 | NSS | N | Random Sampling | 81.2245 | 81.2245 | 81.2245 |
| H1 | NSS | N | Mixed | 80.5294 | 81.3818 | 80.7537 |
| H2 | NSS | N | Mixed | 80.7088 | 80.3948 | 80.7537 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.-S.; Lin, C.-K.; Chou, J.C.-L.; Hung, Y.-H.; Wang, S.-W. Research on Industry Data Analytics on Processing Procedure of Named 3-4-8-2 Components Combination for the Application Identification in New Chain Convenience Store. Processes 2023, 11, 180. https://doi.org/10.3390/pr11010180
Chen Y-S, Lin C-K, Chou JC-L, Hung Y-H, Wang S-W. Research on Industry Data Analytics on Processing Procedure of Named 3-4-8-2 Components Combination for the Application Identification in New Chain Convenience Store. Processes. 2023; 11(1):180. https://doi.org/10.3390/pr11010180
Chicago/Turabian StyleChen, You-Shyang, Chien-Ku Lin, Jerome Chih-Lung Chou, Ying-Hsun Hung, and Shang-Wen Wang. 2023. "Research on Industry Data Analytics on Processing Procedure of Named 3-4-8-2 Components Combination for the Application Identification in New Chain Convenience Store" Processes 11, no. 1: 180. https://doi.org/10.3390/pr11010180