The key to sparse representation is to find an overcomplete dictionary that best matches the original signal [
31]. Different signals have different vibration waveforms. In order to match the waveforms of each part of the signal, it is necessary to construct a suitable dictionary according to the characteristics of the signal. Over-complete dictionary
is the key factor to make the original signal more concise and accurate. In order to better decompose the original signal, the choice of dictionary is particularly important [
32]. If a signal can be linearly represented by a small number of atoms in an overcomplete dictionary, then the energy of the signal is concentrated on a small number of atoms. Therefore, it is particularly important to construct an overcomplete dictionary that can sparsely represent the original signal. Usually, two dictionaries are used for analysis: pre-constructed dictionary and learning dictionary. For complex signals, learning dictionary has a stronger processing ability [
33]. Learning dictionary is constructed by training observation examples of nonparametric signals, in which atoms are not generated by explicit mathematical expressions, but by training real signals. Therefore, learning dictionary can get rid of the shackles of pre-constructed dictionaries and express the characteristic structure of complex signals more accurately. Therefore, this paper chooses OMP algorithm and K-SVD algorithm to solve sparse representation and build the learning dictionary and make different improvements to get a better performance. Simultaneously, the EEMD method is merged, and the fault signal can be diagnosed fast and precisely thanks to the combination of enhanced algorithms.
2.1. Improved Sparse Representation Algorithm
- (1)
The adaptive orthogonal matching pursuit (adapOMP) algorithm
The collected signal consists of transient impact component
, harmonic component
and noise
, which can be expressed as:
In view of the consistency of the Fourier dictionary with the actual signal, we use the Fourier dictionary to construct an overcomplete dictionary. Set Fourier dictionary as
, and its sparse matrix is
. By introducing overcomplete dictionary, the original vibration signal can be expressed as:
OMP algorithm has been proved to have good effect in signal processing, but it is difficult to be widely used due to the problem of processing speed. In this study, the harmonic signals are first extracted to improve the efficiency of the OMP algorithm. Harmonic components in vibration signals can be expressed by the result of multiplication of and . Set the columns in as , where is the number of columns in the dictionary. For the sparse coefficient matrix , is the row, and , where is the number of rows in the coefficient matrix.
The error value of the product of current dictionary atoms and sparse coefficient and the original signal could be obtained during the orthogonal matching pursuit traversal process as follows:
If the matrix composed of the columns in dictionary
that make up the support set
is denoted as
, then:
The inner product of any two atoms in the Fourier dictionary is zero since they are sine wave unit functions of particular frequency and orthogonal to each other. From an energy standpoint, interpreting the vibration signal is as follows:
To separate harmonic components, an adaptive orthogonal matching pursuit method (adapOMP) is utilized. Because harmonic and modulation components are scattered on sine waves of specified frequencies, we may compute using the sparse coefficients of these atoms, as shown in Formula (5). Assuming that the maximum value of sparse coefficients obtained after k iterations is and the minimum value is , when , iteration stops outputting sparse coefficients. In order to better recover signals, can be set through experiments. The final residual signal is the composite signal of impact component and noise.
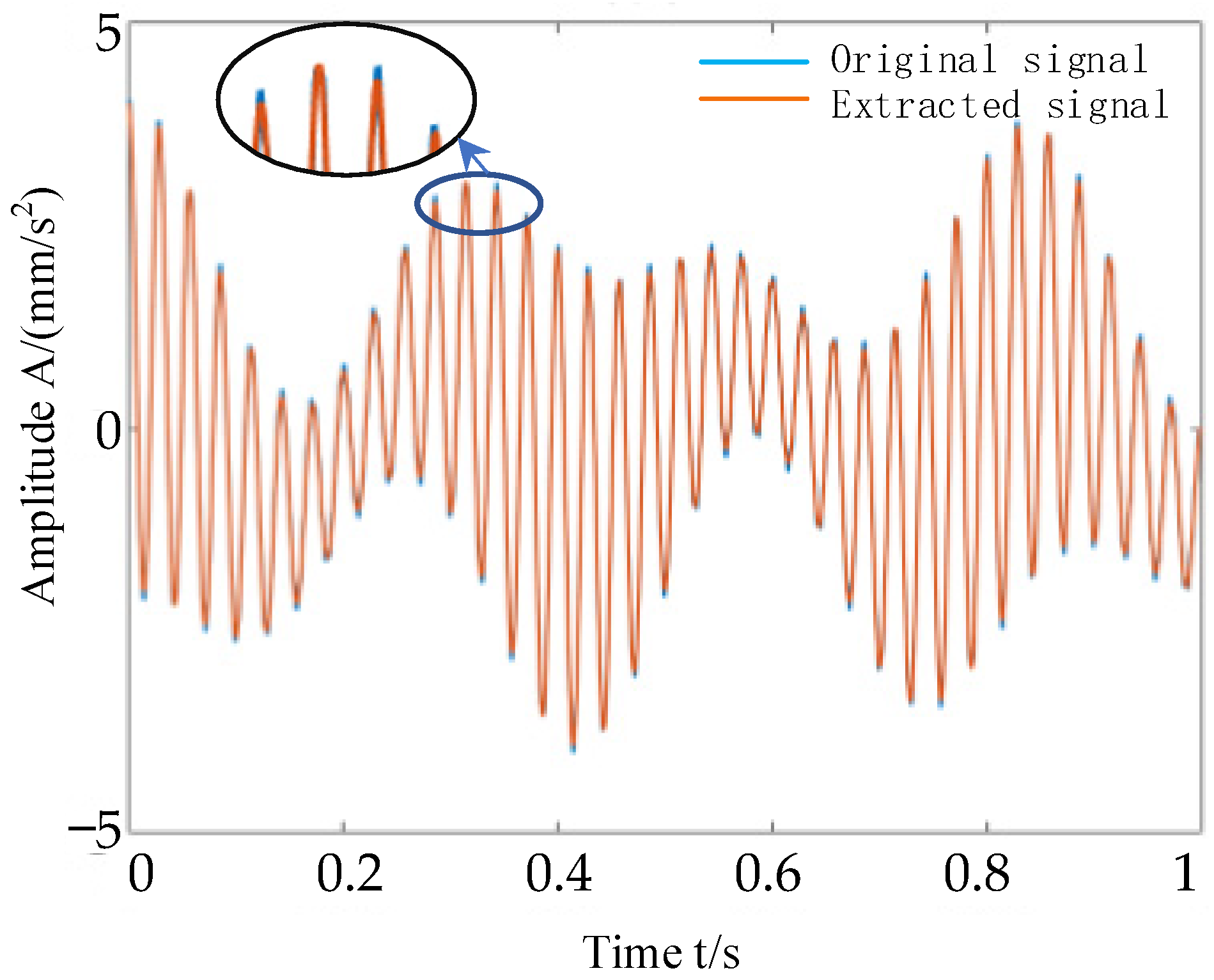
The harmonic signal can be separated quickly and efficiently by using adaptive orthogonal matching pursuit algorithm. We performed a comparative analysis of different algorithms on signals with specific harmonics and noise added and evaluated the results as
Table 1 [
34].
The adapOMP has the strongest harmonic extraction ability and less time when it is used alone.
- (2)
The improved K-SVD algorithm
A feature extraction approach of learning vocabulary is presented to address the issue that the pre-built lexicon has low flexibility when faced with various forms of failure signals. Dictionary learning may improve the feature information extraction for various fault signal kinds, reducing the interference of extraneous information and enabling the identification of the fault types. The sparse representation solution and dictionary learning are the two crucial elements in the sparse feature extraction approach [
35]. To better detect the defect information, we enhance the K-SVD algorithm to optimize the halting criterion of the dictionary learning feature extraction approach.
In order to lessen the sparsity of the sparse coefficient matrix corresponding to the dictionary, the over-complete dictionary learning method K-SVD is suggested. The atoms learnt by K-SVD may then be utilized to reflect the original signal more accurately. The issue can be summarized as follow:
In the formula, represents the original signal, represents the dictionary matrix containing K atoms , and represents the sparse coefficient matrix, where represents the number of samples and represents the properties of samples.
The sparse coding and dictionary learning phases of the K-SVD technique are separated. The orthogonal matching pursuit method with enhanced error threshold (OMPerr) is employed in place of the orthogonal matching pursuit algorithm in the sparse representation solution step, and the objective function and constraint conditions of Equation (6) are modified:
The biggest benefit of changing the constraint condition is that the program no longer needs to be stopped by setting the sparsity. It also avoids issues where the original signal cannot be accurately restored due to the sparsity of the sparse coefficient matrix not meeting the precision requirement due to insufficient iterations, as well as issues where the calculation takes too long due to excessive iterations. When the error of the original signal and sparse approximation is less than a predetermined amount, the iteration is halted thanks to the objective function’s error Goal setting, allowing for the accurate form of the signal to be retrieved and a more accurate reconstruction to be produced.
The meaning of each symbol in Formula (8) is the same as that of the symbol in the Formula (6), where
is the set of solution vectors of
. By resolving the optimization issue in Formula (7) using sparse representation, you may obtain the sparse coefficient vector that corresponds to the initialization dictionary. The dictionary is then updated column by column during the dictionary learning stage using the sparse vectors produced from the sparse coding method. Consider updating the
atom of the dictionary (designated as
) and the
coefficient of the sparse coefficient matrix (designated as
).
where
represents the calculation of residual error. In this case, the optimization problem is transformed into:
To obtain the least amount of error, the best solution must be found. This is a least squares issue that can be resolved using the singular value decomposition or the least squares approach (SVD). The SVD approach is employed in this study to find the best possible combination of two variables. Further reducing the computation dimension, the elements in and that correspond to zero elements are removed to create a new residual matrix .
Using mathematical expressions to describe this step is the sparse coefficient vector is not zero position in 1, the location of the zero element as 0, that is to set up a set of
to represent the index value when
. Define a N×
matrix,
. The element at position (
) is 1, and elements at other positions are 0, that is:
At this point, the target equation can be described as:
Therefore, to find the best
, we need to perform singular value decomposition of
.
The first column of the left singular matrix U is taken as , that is, . Take the product of the first row of the right singular matrix and the first singular value as , that is, .
Using this technique, one may create a new learning dictionary by replacing each of the columns in the original dictionary. Through this repeated process, the dictionary matrix and coefficient matrix corresponding to the original signal can be found again and again. The iteration ends if .
By improving sparse representation method, harmonic components and part of noise can be well removed, which plays an active role in bearing fault extraction.
2.2. Fault Feature Extraction Based on EEMD
Empirical mode decomposition (EMD) is an adaptive time–frequency localization method, which can be used to analyze and process nonlinear and non-stationary signals [
36]. However, EMD also has some shortcomings in the decomposition process. For example, the eigenmode function is easy to produce mode mixing phenomena in the decomposition process, and the signal end effect will also affect the decomposition effect of EMD [
37]. EEMD is proposed to improve EMD decomposition, which mainly uses the feature that the mean value of white noise is zero, adding evenly distributed white noise for many times in the decomposition process, covering up the noise of the signal itself by artificially adding white noise, filling up the missing frequency space in the original signal completely, making it continuous in the time-domain, changing the size of extreme points, obtaining a more accurate upper envelope and lower envelope, thus affecting the effect of signal decomposition and further reducing the occurrence of modal aliasing. After many times of average calculation, the influence of noise on the signal is minimized. The more times of calculation, the smaller the influence of noise on the signal.
- (1)
EEMD decomposition method
EEMD decomposition is performed on the signal
, and
groups of different white noises
are added to the original signal for decomposition. The decomposition process is shown in
Table 2:
EEMD decomposes into multiple IMF components, and we need to determine which IMF components are the true components of the signal and which IMF components are the false and meaningless components of the signal. We need to choose the real IMF component to reconstruct the signal, and the remaining IMF components are discarded as meaningless components in the process of reconstructing the signal. However, in order to avoid wrong selection or omission of some real IMF components, we use the correlation coefficient between the original signal and IMF components and the kurtosis value of IMF components as indicators to select real IMF components for signal reconstruction.
The cross-correlation coefficient
between the real signal
and the IMF component
is defined as:
where,
is the correlation coefficient between the real signal and the IMF component,
represents the
th IMF component,
is the data point,
is the signal length,
is the covariance between the real signal and IMF component, and
are the standard deviations between the real signal and the IMF component.
In order to select IMF components that are closely related to the original signal for signal reconstruction, a threshold is introduced to limit the selection of IMF components, namely:
where:
is the number of layers of the original signal decomposed by the EEMD method. In this way, the whole formula becomes the standard deviation of the correlation coefficient between the total IMF component and the original signal. The IMF component larger than
can be regarded as a real component, otherwise it is regarded as a false component. The real IMF components are selected to extract the transient impact components of each IMF component. After the selected IMF components that are correlated with the original signal, it is also necessary to determine whether the modified components contain obvious impact components. At this time, it is determined whether the component contains an impact component by using the kurtosis value of the calculated signal.
Kurtosis is a dimensionless parameter describing the
distribution characteristics of a signal, which is particularly sensitive to the impact components, and its expression is as follows:
where
is the number of data points of the signal,
is the average of IMF components, and
is the standard deviation of the signal.
Generally, it is considered that when the kurtosis value is greater than 3, the shock characteristics of the signal are more obvious. When the kurtosis value is less than 3, the shock characteristic of the signal is not obvious [
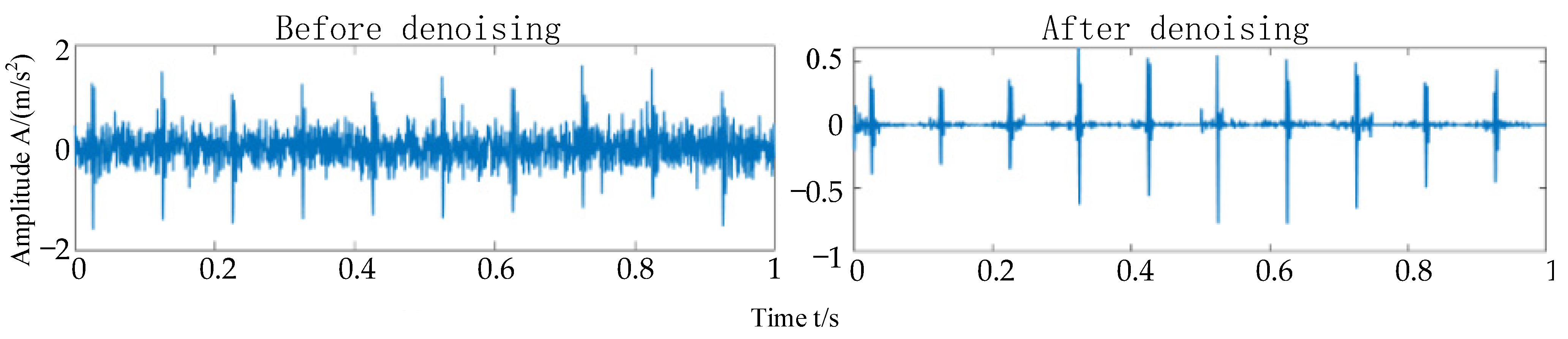
38]. In order to extract the transient impulse components from IMF components and reconstruct the signals, the IMF components whose cross-correlation coefficient is greater than 0.3 and the kurtosis value is greater than 3, which are correlated with the original signals, are selected for subsequent sparse representation. After sparse denoising, the IMF components are reconstructed to obtain reconstructed signals with rich transient impulse components, and it is easier to judge the fault frequency and fault types of rolling bearings.
- (2)
One-dimensional signal folding and hard threshold reconstruction
Through the cross-correlation coefficient and kurtosis value, the IMF component, which contains the impact component and has great correlation with the original signal, is selected for further sparse denoising. Then, the processed IMF components are reconstructed, and then the fault frequency is calculated by the envelope spectrum to judge the fault type.
We need to combine the EEMD algorithm with the K-SVD algorithm to extract fault features. The requirement of K-SVD calculation is that the number of columns of the matrix must be greater than the number of rows of the matrix, that is, the dictionary needs to be an over-complete dictionary. When K-SVD is used to process one-dimensional signals, the signals to be processed can be converted into the Hankel matrix for calculation [
39]. The Hankel matrix is a matrix with equal elements on every diagonal line, but the number of columns of the matrix is larger than the number of rows in K-SVD processing, so the Hankel matrix is deformed, that is, the number of elements in each row is larger than that in each column, forming a flat matrix. The IMF component
is arranged in the Hankel matrix. Namely:
Dictionary learning requires K to be much greater than d. Sparse representation is carried out with the Hankel matrix containing K signals and each signal dimension of d as input. Each signal contains the information in the original signal, and the latter signal is obtained by the shift of the previous signal, so K signals contain all the information in the original signal. In addition, in the calculation process, each signal needs to be calculated by K-SVD to obtain the learning dictionary and sparse coefficient matrix. The learning dictionary and sparse matrix are multiplied to restore to the form of the Hankel matrix, and the inverse Hankel function is used to restore to the form of one-dimensional signal.
A learning dictionary and the related sparse representation coefficient matrix are generated for each segment of the original signal throughout the signal reconstruction process. The reconstruction signal is then created by multiplying the learning dictionary by the sparse coefficient vector. However, a tiny amount of noise will still perturb the atoms in the learning dictionary. To partially filter out the low-frequency harmonics and noise components, a hard threshold can be implemented. The following optimization issues can be resolved with hard thresholds:
where
,
.
is the zero norm of vector
, and the terms of vector in Equation (18) can be disassembled as:
where
, each term in Equation (19) can be written as:
when
, the minimum value of function
is obtained at
, and the minimum value is
; when
, the value of function
is
. In order to get the minimum value, it is necessary to compare the sizes of
and
. If
, the minimum value of the function is obtained at
; If
the minimum value of the function is obtained at
. That is:
is regarded as a variable, is regarded as a threshold, and Formula (21) is a hard threshold. The optimization problem of Formula (18) can be written as follows:
Use all the elements in vector
, compare with the threshold, discard the elements less than the threshold, and keep the elements greater than the threshold. When
is a matrix, this formula can still be used, and each element in the formula is compared with the threshold to make a choice. A more intuitive function image is used to represent the hard threshold function. Let the function
and the threshold value be 1. The image is shown in
Figure 1. All the function values whose absolute value is less than the threshold value are discarded, and the function values whose absolute value is greater than the threshold value are retained.
After the original signal is divided and converted into the Hankel matrix, the learning dictionary matrix and sparse coefficient vector are obtained by K-SVD calculation. However, due to the influence of noise, the atoms of learning dictionary will still be affected by some noise. Using the hard threshold denoising method to remove smaller elements in dictionary atoms and further eliminate noise interference, the learning dictionary optimization model can be obtained as follow:
By setting a hard threshold to further eliminate noise interference, the optimized dictionary
is obtained. Usually, there are two ways to set the threshold. One is to debug through conventional artificial experiments, check the output results, and select the optimal threshold value. The second is to look for an index of the signal to choose, such as the signal-to-noise ratio of the noise-reduced signal as an index, and then set the corresponding threshold to the optimal value when the signal-to-noise ratio is the maximum. Through a series of tests, the threshold is set to 0.2 in this paper to further optimize the learning dictionary. Use the optimized dictionary to reconstruct the signal, that is:
The reconstructed Hankel matrix is transformed into a one-dimensional signal, and several pieces of signals are merged together to restore the original signal. At this time, the signal with K-SVD denoising is obtained. The envelope spectrum analysis is carried out to determine the fault frequency of rolling bearing and judge the fault type of rolling bearing.
Combined with the hard threshold denoising EEMD and sparse representation method, the capability of fault feature extraction is further improved.

 ,
, 






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}