1. Introduction
With the increasing scale of modern industry and economy, it is unavoidable to deal with multi-player and multi-objective optimal control problems [
1]. There will inevitably be cooperation or competition between different players. As an important tool to solve this problem, game theory has been widely studied by scholars [
2,
3,
4,
5]. Game theory includes the noncooperative game and the cooperative game. In a noncooperative game, one player makes independent decisions without considering the benefits of the other players. On the contrary, the cooperative game reasonably coordinates the interests of each player within a specific rule. As the concept of win-win cooperation gains popularity, the cooperative game has also become a popular topic.
As an important type of cooperative games, Pareto game has firstly been used in economic theories [
6,
7], and now it is also used in the engineering field, such as path planning [
8], crude oil scheduling [
9] and mobile edge computing [
10]. Hence, Pareto game has been widely investigated by many researchers. Engwerda [
11] gave a characterization of all Pareto solutions when the weighting matrices of the cost function are positive definite and then generalized this result for indefinite criteria [
12]. Further, Reddy [
13] studied the conditions for the existence of Pareto optimal strategy in infinite horizon, and systematically analyzed the relationship between Pareto optimality and weight sum minimization. Along with maturing of Pareto optimal control theory for deterministic systems, scholars have done some work on Pareto optimal control of stochastic systems. Lin et al. [
14] derived the necessary and sufficient conditions for Pareto optimal strategy of stochastic system. For discrete-time stochastic systems, Zhu et al. [
15] gave sufficient conditions for the existence of the strategy sets with finite horizon, and Peng et al. [
16,
17] studied the Pareto optimality of linear and nonlinear systems with infinite horizon, respectively. Ahmed et al. [
18] studied the Pareto optimal control with external disturbances, and gave the form of Pareto optimal control under
constraint for continuous-time stochastic systems by means of linear matrix inequalities. Jiang et al. [
19] introduced the generalized differential Riccati equations to obtain Pareto solutions under
constraint for continuous-time stochastic systems. It should be noted that the above two articles are about continuous-time rather than discrete-time.
The development of Pareto optimal control theory is inseparable from the progress of linear quadratic (LQ) dynamic game theory. The stochastic LQ optimal control problem was proposed initially by Wonham [
20] and attracted great attention of many scholars [
21,
22,
23]. Chen et al. [
24] found that a stochastic LQ problem with indefinite cost weighting matrices can still be well-posed. The reference [
25] investigated discrete-time indefinite stochastic LQ problem and proposed a generalized difference Riccati equation (GDRE). To design optimal robust controllers with external disturbances, in [
26], the authors proposed the mixed
control, while [
27] generalized
control theory of deterministic systems to stochastic systems. However, different from the Pareto optimal control studied in this paper,
control can only give the optimal control of single-player, and can not deal with the optimization problem of multi-player and multi-objective.
Compared with the
control, there are few studies on the Pareto efficiency with
constraint for discrete-time stochastic systems. However, practical systems are often affected by both white noises and exogenous disturbances, and compared with the generalized differential Riccati equations, it is easier to solve the GDREs associated with discrete-time stochastic systems. In recent years, the characteristics of discrete stochastic systems have become a very attractive research field [
28,
29]. Motivated by the above discussions, we study the Pareto optimum for stochastic discrete-time systems with external disturbances. The main contributions of this work are as follows:
Using the weighted sum method of Pareto optimization and combined with the control theory, the GDREs are obtained. Based on obtained GDREs, we get the Pareto efficient strategies under constraint, which can not only achieve Pareto optimization, but also reduce the influence of external disturbances.
Based on the solvability of the GDREs, we derive the necessary and the sufficient conditions for the existence of constraint Pareto optimal control for discrete-time stochastic systems. Then we derive all Pareto solutions for all Pareto efficient strategies.
We investigate the indefinite linear-quadratic difference game with external disturbance and stochastic bounded real lemma (SBRL) with a nonzero initial value. The weighting matrices of the cost functional are allowed to be indefinite in this paper.
The rest of this paper is organized as follows:
Section 2 presents the system description and makes some useful preliminaries. In
Section 3, Pareto optimality under
constraint is investigated.
Section 4 presents an example of space heating to illustrate the obtained results. The conclusion of this paper is given in
Section 5.
Notations: : the transpose of the matrix or vector ; : the Moore-Penrose pseudoinverse of ; : is the positive definite (positive semi-definite) symmetric matrix; : the mathematical expectation operator; : the set of n-dimensional real vectors; : the set of real matrices; : the identity matrix; : the set of all real symmetric matrices; ;
2. System Descriptions and Preliminaries
Consider stochastic finite horizon discrete-time linear system with multi-player as follows:
where
represents the system state,
is the
ith control input at time
k,
is the disturbance signal,
is the controlled output. Denote the joint action of each controllers by
.
,
,
,
,
,
,
and
with
are matrix-valued continuous functions with appropriate dimensions.
is an independent one-dimensional real random variable sequence defined in a given complete filtered probability space
with
and
, where
is a Kronecker function. Denote
the
-algebra generated by
Let
consists of all finite sequences
, such that
is
measurable for
, where
, i.e.,
is constant. The
-norm of
is defined as
Before giving the definition of Pareto optimal strategy with
constraint, we need to analyze the Pareto optimality and
performance of discrete-time systems, respectively. We will first introduce some definitions and lemmas of Pareto optimal strategy. In this part, the disturbance is not considered. Let
, system (
1) can be reduced to
For system (
2), the cost functionals that the player or controller
wants to minimize are
where
,
and
exists.
Definition 1 ([
19]).
Denote and joint control , where is the set of all admissible controls. The is called Pareto efficient for system (2), if the set of the inequalities , do not hold for any solution , where at least one of the inequalities is strict. The corresponding to Pareto efficiency is a Pareto solution, and all Pareto solutions form the Pareto frontier. If is Pareto efficient, it means that we cannot find other admissible u to make one or more get better while no gets worse at the same time. To solve pareto efficiency, we need to introduce the following two lemmas.
Lemma 1 ([
30]).
Let , whereThen is Pareto efficient.
Lemma 2 ([
12]).
Assume that the control strategy set is a convex set and the cost functionals , are convex w.r.t. u. If admissible is Pareto efficient, then there exists an such that holds. Remark 1. Lemma 1 is only a sufficient condition to obtain Pareto efficient strategies, and it cannot guarantee that all Pareto efficient strategies can be obtained by (4). If and ,through triangle inequality [11], we can infer that the corresponding cost functionals are convex. According to Lemma 2, if the control strategy set and the cost functionals are convex, the Pareto efficient strategy can be obtained by the weighted sum method. In this paper, we consider the case that and may be indefinite matrices, which requires us first to ensure that is convex. Lemma 3 ([
14]).
Consider the system (2). The cost functionals shown in Equation (3) is convex w.r.t.
, where is a convex set, iff Under the assumption that is convex and , the convexity of the cost function is guaranteed, which further ensures that all Pareto efficient strategies with indefinite matrices and can be obtained by minimizing the weighted cost functional.
For the weighted sum cost functional
if
are all convex w.r.t.
u, then the corresponding
is also convex for any
,
,
,
.
Next, let control input
consider the following discrete-time stochastic perturbed system for
analysis.
The perturbed operator of system (
6) is defined by
with
,
Define the norm of the perturbed operator of system (
6) as
In (
7) the initial weighting matrix
is introduced to measure the uncertainty of initial state
. It can be seen that
represents the effect of the initial value and external disturbance on the system output. When we require
, the following robust cost functional is obtained, which establishes a relationship between the disturbance attenuation problem and the solvability of GDRE.
For notational convenience, simplify discrete-time system (
1) as
where
,
,
Based on the above analysis, we define the Pareto optimal strategy for discrete-time system (
9) with
constraint.
Definition 2. Consider the controlled stochastic system (9). For a given disturbance attenuation level , find a state feedback joint control with , such that (1) For the closed-loop system the norm of the perturbed operator of (10) satisfies (2) If the worst-case disturbance is imposed on system (9), satisfies where the cost performances are defined aswhen such exists, we say that the Pareto optimal strategy for discrete-time system (9) with constraint is solvable. 3. Main Results
In this section, we will first study control and Pareto optimal control separately. Then by solving the coupled GDREs equation, the Pareto optimal control under the worst-case disturbance can be obtained.
In order to obtain the worst-case disturbance, we need to introduce the stochastic bounded real lemma (SBRL), which plays a crucial role in analysis. Below, we give some lemmas that are essential for our main results.
Lemma 4 ([
27]).
Suppose , are arbitrary real symmetric matrices, then for any in system (6), we havewhere . Lemma 5 ([
27]).
Suppose , are arbitrary real symmetric matrices. It can be further derived that, for any in system (6):whereThen can be simplified as
Lemma 6 ([
27]).
For , and exists, we have Lemma 5 rewrites the cost functional
so that Lemma 6 can be applied. Finally, the cost functional
is transformed into the following Equations (
16). Accordingly, the minimum value of
and the corresponding worst-case disturbance are apparent.
Lemma 7. (SBRL) Consider the discrete-time stochastic system (6) and perturbed operator (7), we have for some disturbance attenuation and initial weighting matrix , if and only ifhas a unique solution on with . Proof of Lemma 7. Sufficiency part: Based on Lemmas 5 and 6, we can rewrite
as follows:
where
. Because Equation (
15) holds, we can finally get
Since
, when
we can easily know
, that is
. When
, according to Appendix C of reference [
31], we can also have
.
Necessity part: The literature [
31] has proved that for arbitrary
, if
, then (
15) admits a solution
on
. Next, we will prove
by contradiction.
Suppose there exists a nonzero vector , that makes . We already know . Let and we can get , which contradicts the assumption that . Therefore, for any nonzero vector , which means . Lemma 7 is proved. □
Remark 2. In this paper, the Pareto solution we studied is valid for any initial value . In order to maintain consistency, we extend the SBRL in [31] to the case where the initial value can be arbitrary. According to Lemmas 1 and 2, Pareto optimal strategy can be obtained by minimizing weighted sum objective functional , which is a single-objective optimization problem. Because and are allowed to be indefinite, if is taken as the cost functional of LQ problem, Pareto optimal control can be regarded as the solution of stochastic discrete-time system indefinite LQ problem.
Consider discrete-time stochastic system without disturbance
And the corresponding cost functional is given as
The LQ problem aims to find a control strategy that minimizes weighted sum cost functional (
18). We should note that the LQ problem may be ill-posed under the constraint (
17) since
and
may be indefinite. Therefore, the following two definitions are given.
Definition 3 ([
25]).
The LQ problem (17) and (18) is called well-posed if , for any . Definition 4 ([
25]).
The LQ problem (17) and (18) is called attainable if there exists such that . It can be seen that if the LQ problem is attainable, it means that there must exist a corresponding optimal control .
The property of the pseudo matrix inverse will be used in order to solve the indefinite LQ problem.
Lemma 8 ([
32]).
Given a matrix , there exists a unique matrix satisfying In Lemma 8, is called the Moore-Penrose pseudoinverse of .
Lemma 9 ([
25]).
For the system (17) and indefinite weighted sum cost functional (18), the following are equivalent:(1) The following GDRE is solved by a symmetric matrix sequence . (2) The LQ problem is well-posed.
(3) The LQ problem is attainable.
If any of the above three conditions can be satisfied, the LQ problem is attainable by where are solutions of GDRE (19). Based on the above analysis of the indefinite LQ problem and the SBRL with nonzero initial value, we study the Pareto optimal control with constraint.
Theorem 1. Consider the discrete-time stochastic system (9) with multiple control inputs , and the external disturbance Set , the weighting factor and . If the following GDREs (20)–(23) have a solution with and , , then the discrete-time finite horizon Pareto optimal control with constraint is solvable. Pareto efficiency strategy under the worst-case disturbance is Conversely, if and Pareto optimal problem with constrain is solved by , then GDREs (20)–(23) have a solution with , . where Proof of Theorem 1. Sufficiency part: Applying
into system (
9), where
is defined in (
23), we have
Because system (
24) and system (
6) have the same structure, the related lemmas of system (
6) are also applicable to system (
24). Similar to the proof of Lemma 7, we denote
Applying Lemma 5 and completing squares method to system (
24) and considering the corresponding cost functional
, we have
where
Since Equation (
20) holds, combined with (
25), we can obtain
. So when
,
is the worst-case disturbance. Because
, we know
, that means inequality (
11) holds, i.e.,
, and
is under
constraint.
Similarly, let
we get:
Accordingly, the weighted sum cost functional is
Replacing
with
using completing squares method and considering Equation (
22), it follows that:
where
So
, that is,
minimizes the weighted sum cost functional
under the worst-case disturbance
. According to Lemmas 1 and 9, when the worst-case disturbance
is imposed on system (
9) the Pareto efficiency can be given as
.
Necessity part: Assume the Pareto optimal strategy for discrete-time system (
9) with worst-case disturbance
is
It means that when
is applied to system (
22), we have
. According to Lemma 7, we can conclude that Equation (
20) has a unique solution
on
with
. Substituting the worst-case disturbance
to system (
9), we get system (
26). Since
, i.e.,
is convex w.r.t
and
is Pareto optimal control subject to system (
26), according to Lemma 2, there exists an
such that
It means that the LQ problem corresponding to system (
26) and cost functional (
18) is not only well-posed but also attainable. According to Lemma 9, Equation (
22) has a real symmetric solution
. The proof is completed. □
Remark 3. It can be seen from Theorem 1 that the Pareto optimal control under the worst-case disturbance can be obtained by solving the coupled GDREs (20)–(23). Different from the reference [16], the results in Theorem 1 take into account both Pareto optimality and performance, and are about finite horizon. The weighted sum method only provides a sufficient condition for solving Pareto optimal control. Therefore, we can obtain a necessary condition only when the cost function is guaranteed to be convex. In [15], the authors only analyzed the sufficiency of Pareto efficiency strategy. Our conclusion further gives the necessary condition, and more importantly, considers the influence of the disturbance. Theorem 2. The Pareto solutions of system (1) with Pareto efficient strategy and the worst-case disturbance obtained from Theorem 1 can be described aswhere satisfy:where represents the jth row of Proof of Theorem 2. Since we have known
and
,
can be rewritten as
and the system (
1) can be rewritten as
Adding Equation (
33) to Equation (
32), it yields
Replacing
with
and combining with (
31), we have
. The proof is completed. □
Remark 4. Theorem 2 shows how to obtain the value of for any controllers . According to the definition of Pareto solutions, is not uniquely determined. When changes, will also change, and the set of all Pareto solutions constitutes the Pareto frontier.
Remark 5. Because of the existence of , , and in Equations (21) and (23), and are coupled. To avoid overly complex solutions, the system (1) is reduced to a system with only state-dependent noise: Equations (21) and (23) can be rewritten as the follwing two coupled equations: Substituting into the Equation (35), after calculations, is as follows: 










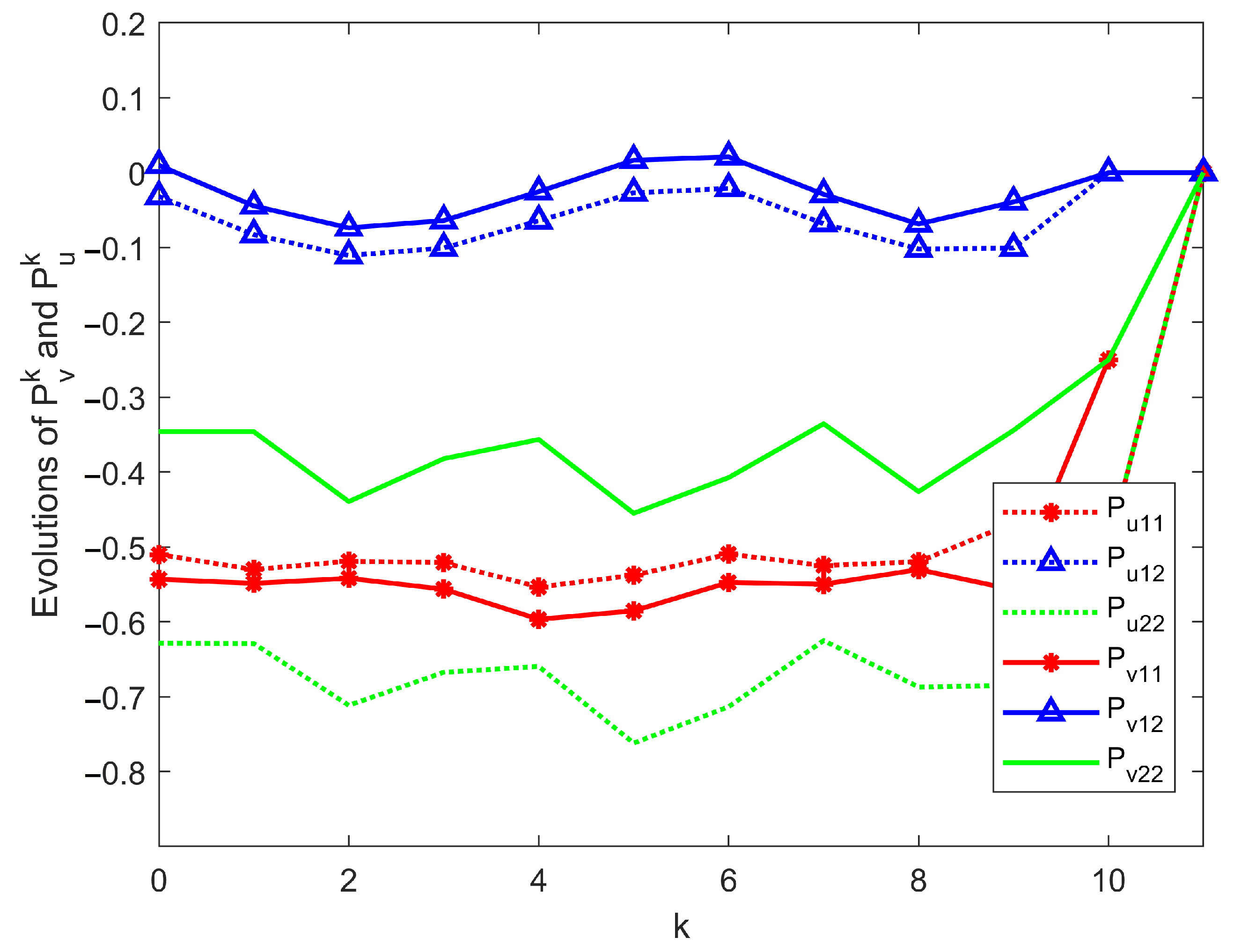{kind=link}
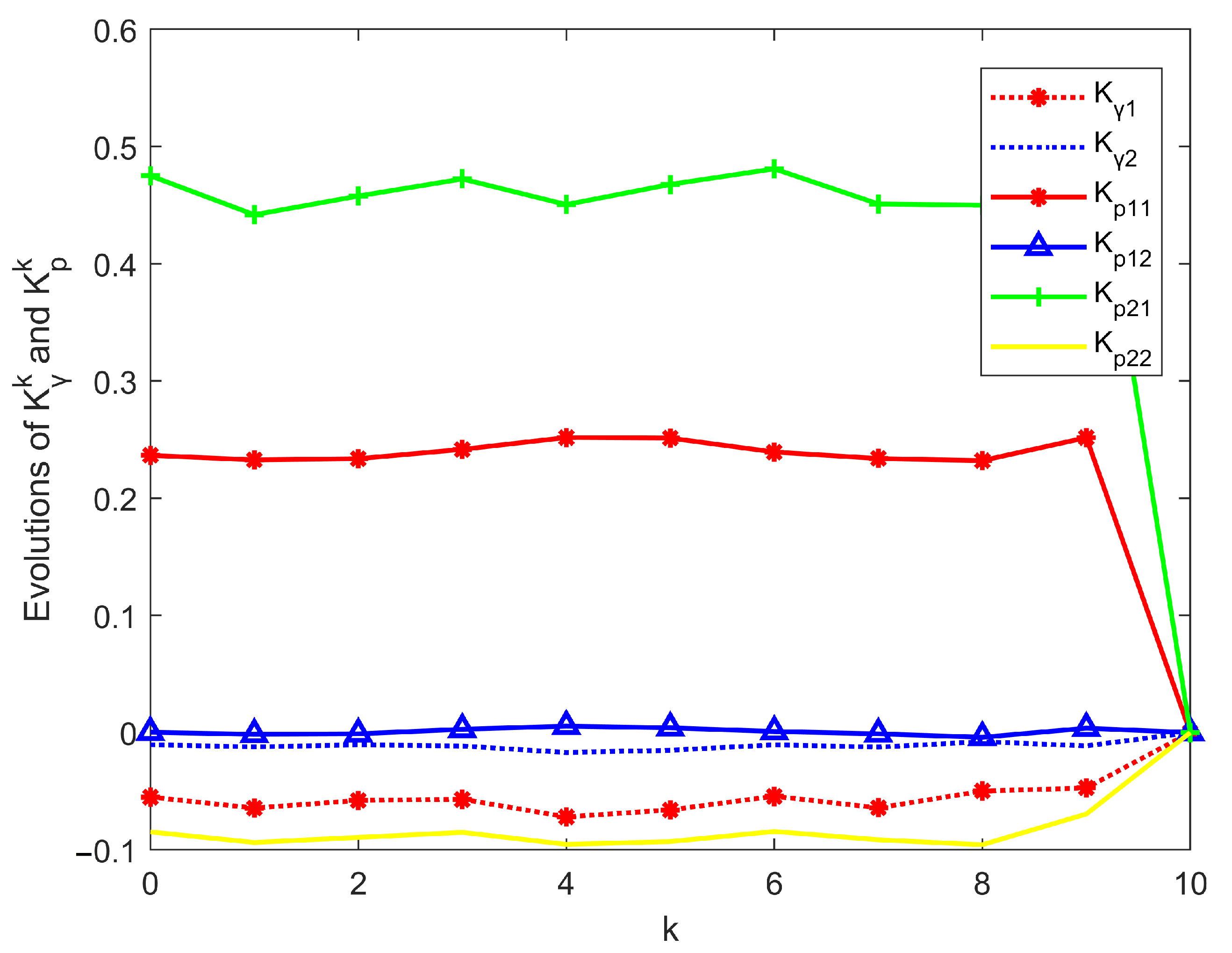{kind=link}
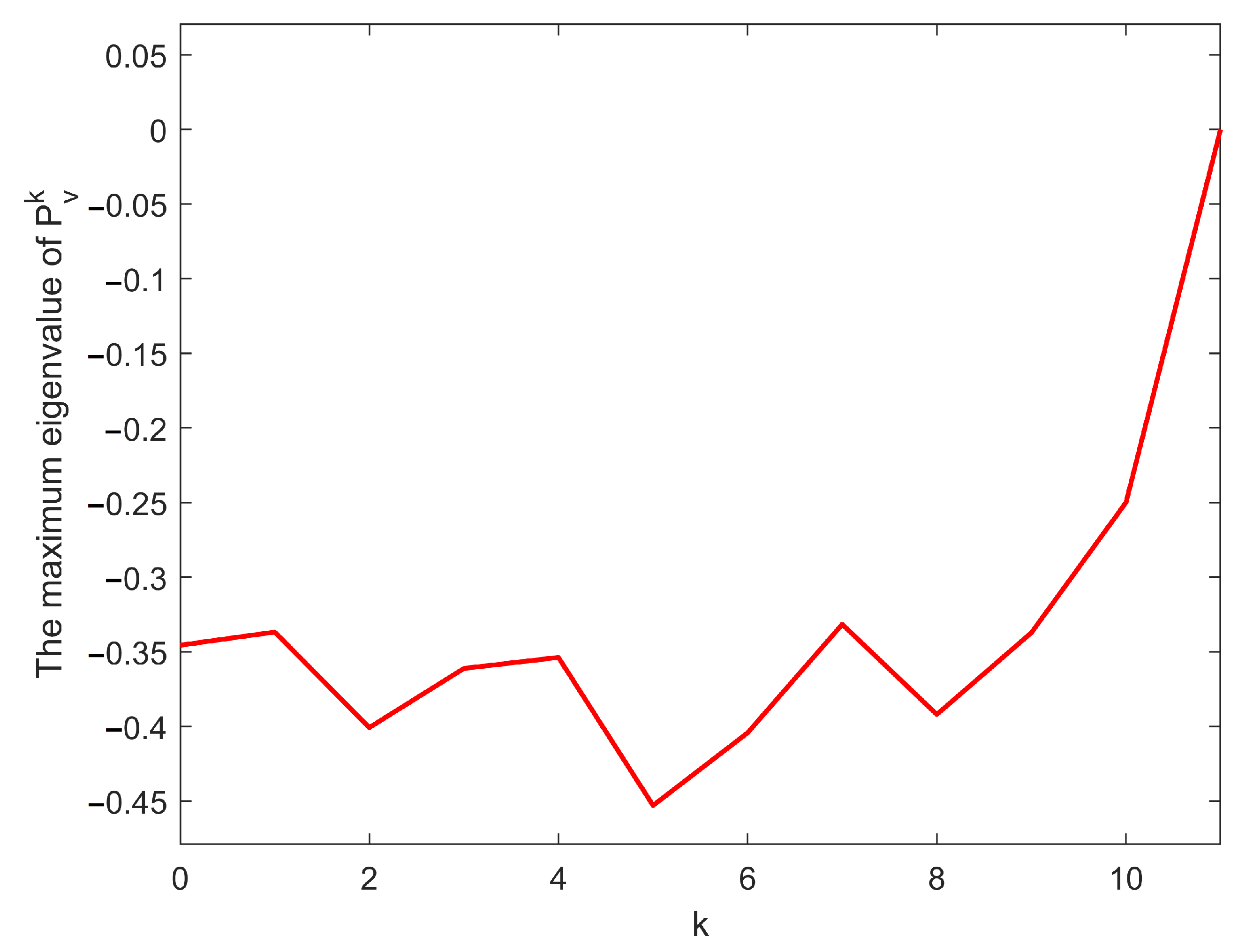{kind=link}
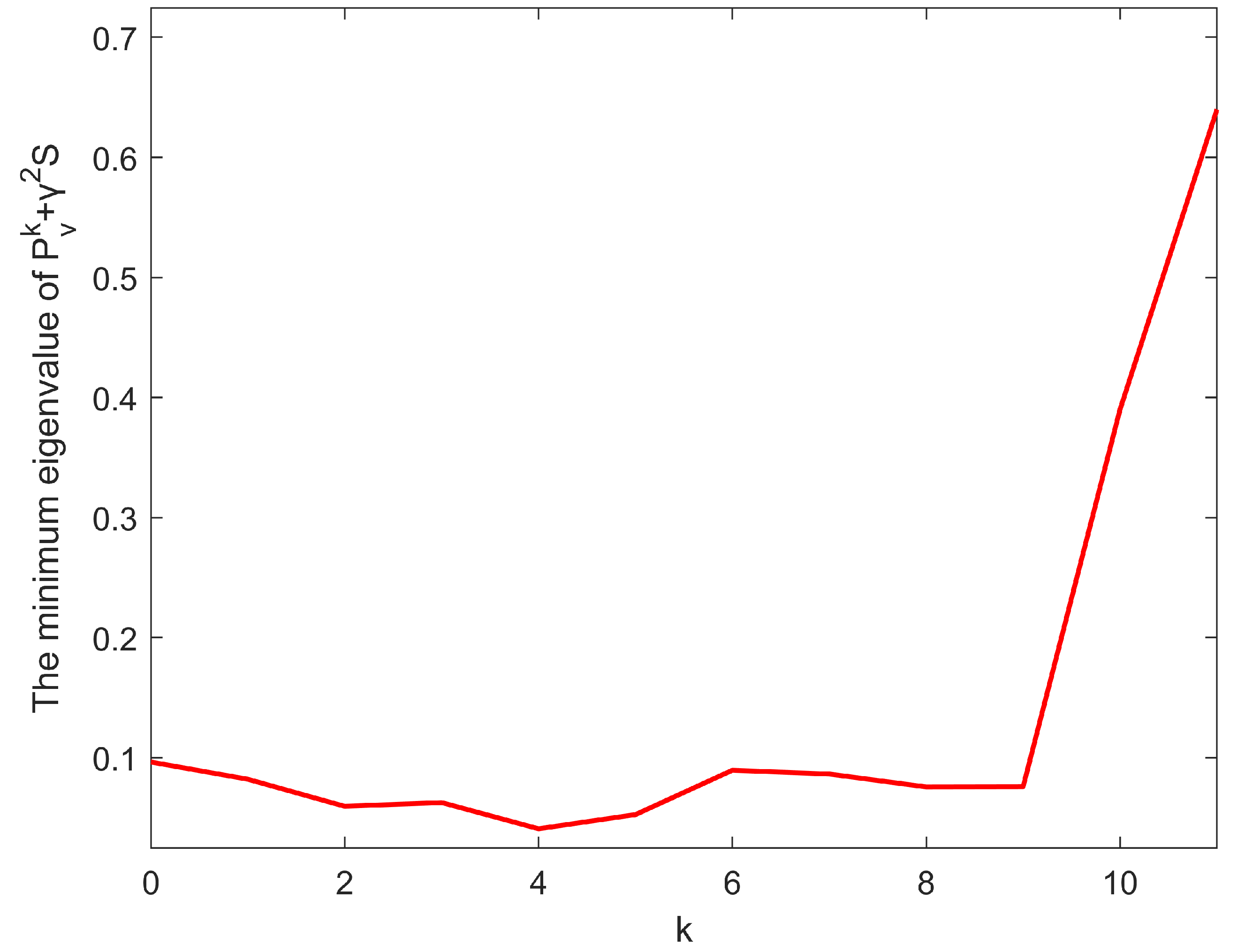{kind=link}
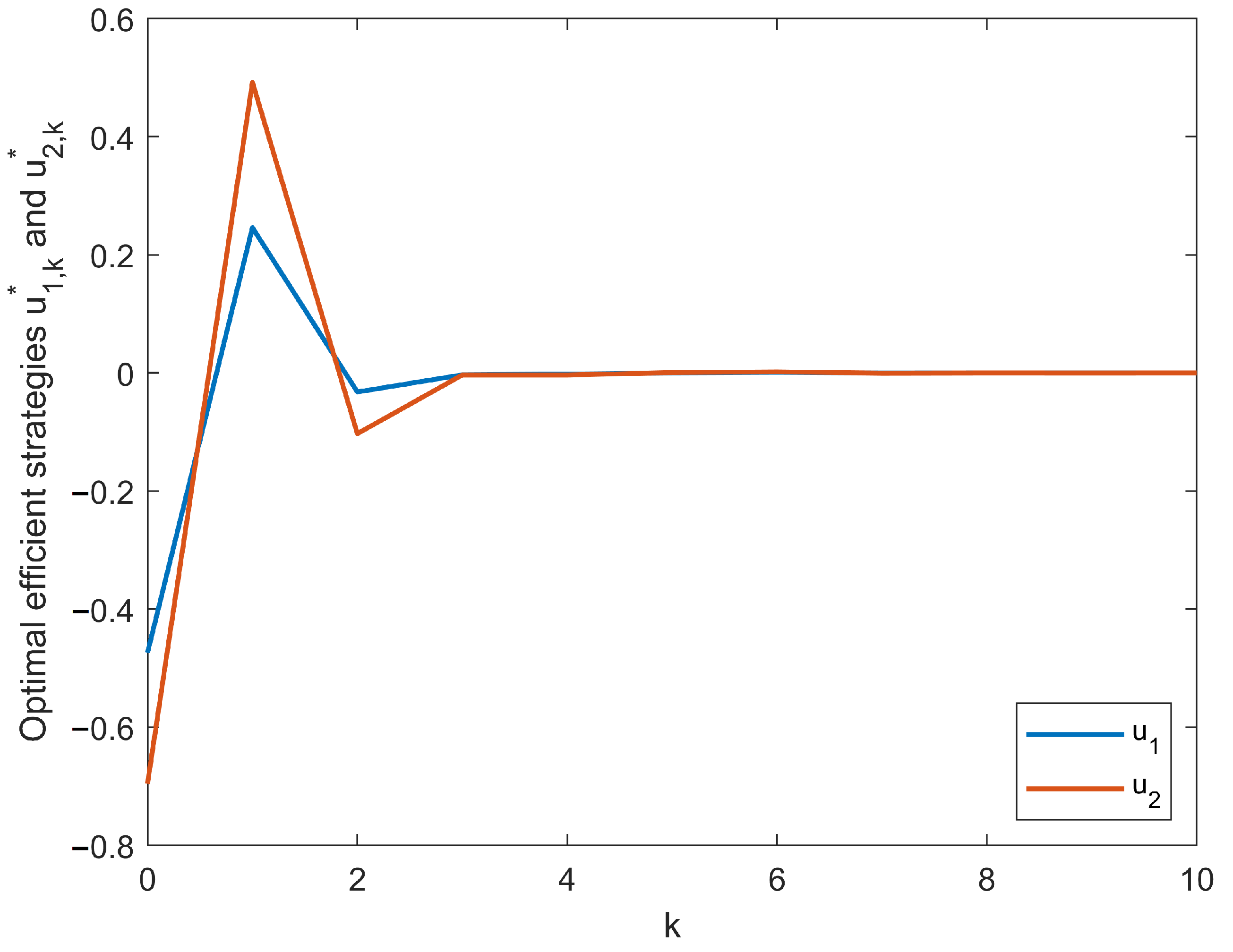{kind=link}
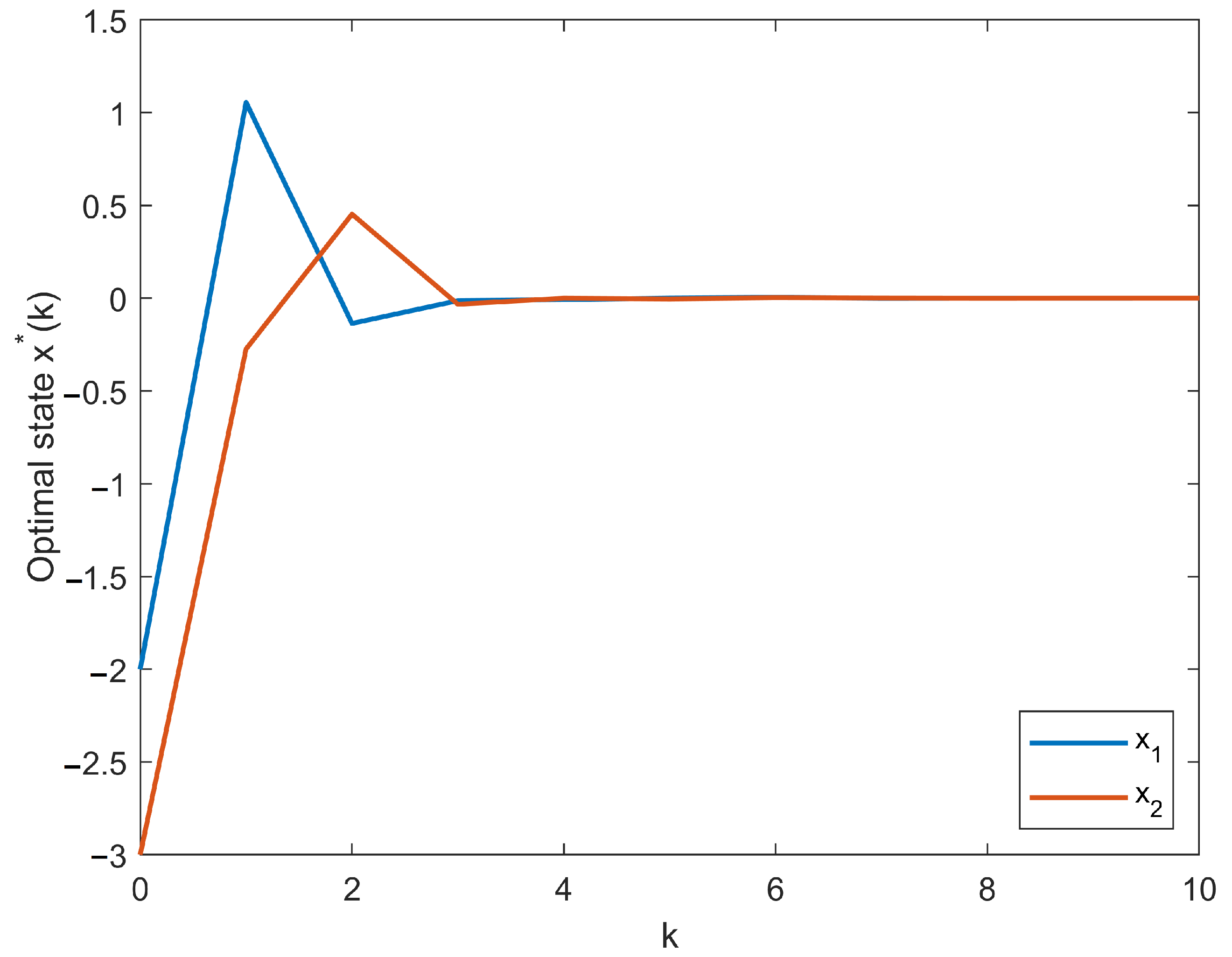{kind=link}
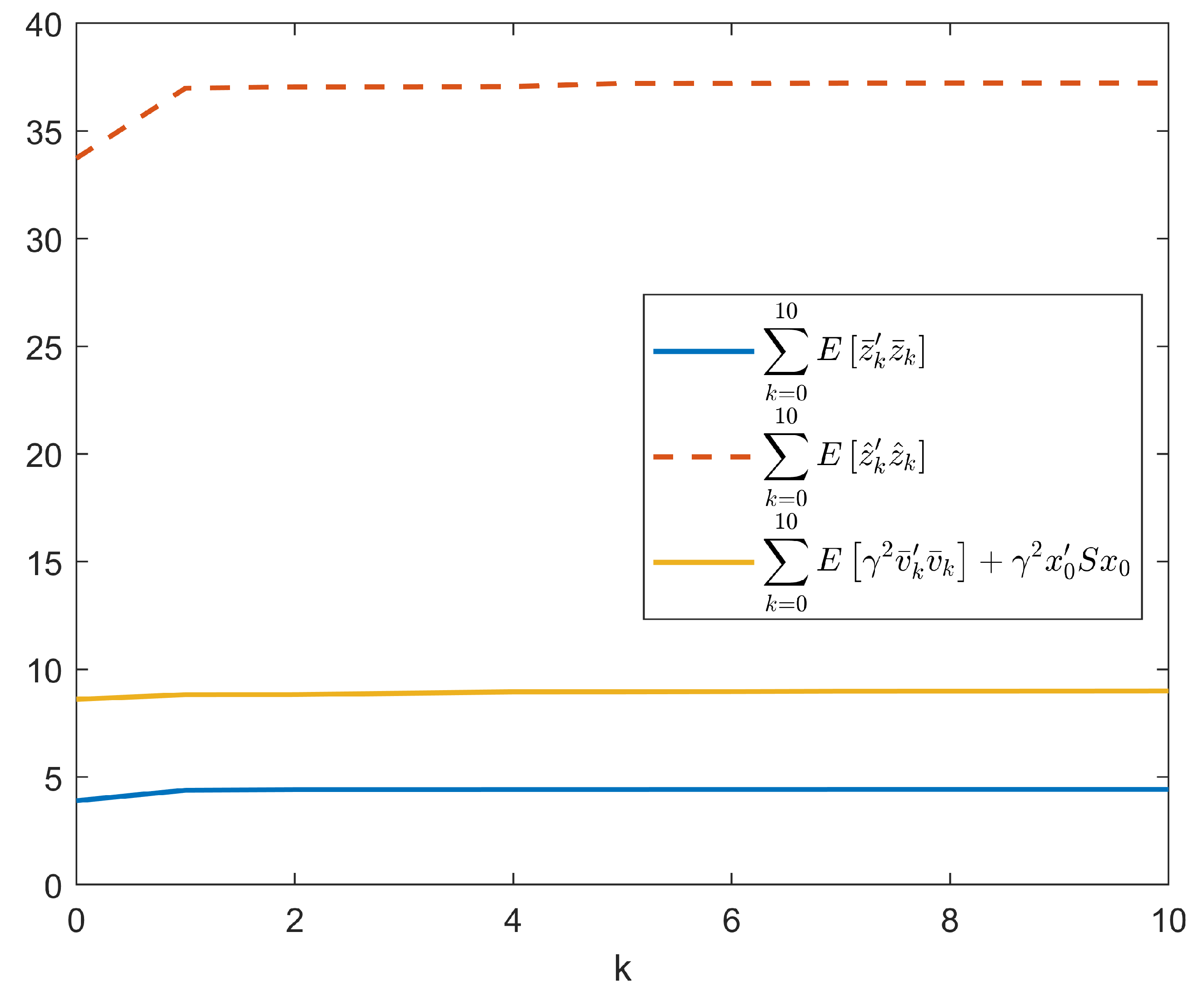{kind=link}
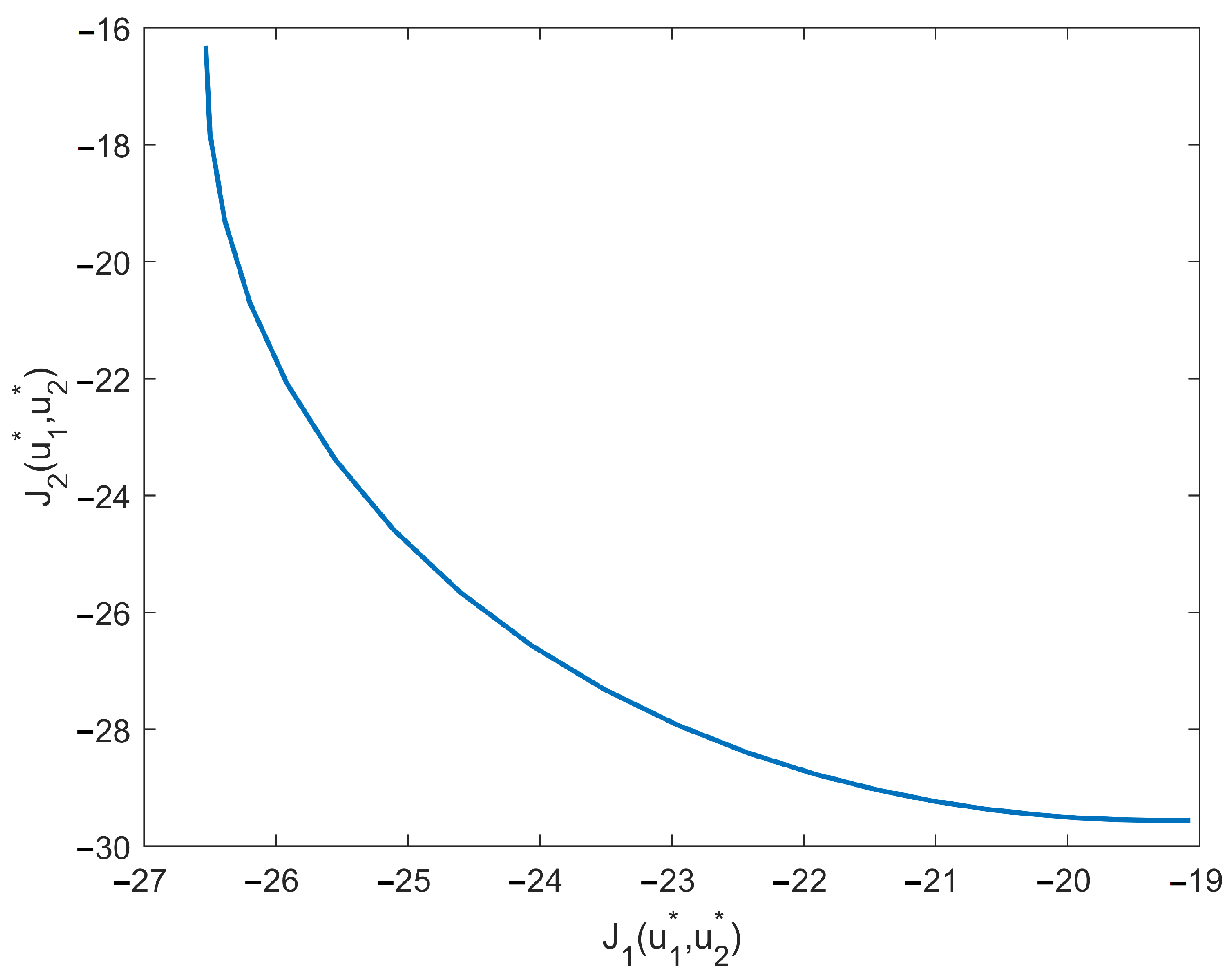{kind=link}