1. Introduction
Voltage stability [
1] is the main limiting factor for the safe and reliable operation of power systems. With continued load growth and the penetration of new energy sources, modern power systems have been pushed to operate closer to their voltage stability limits. Over the past few decades, great efforts have been devoted to investigating the mechanisms of voltage instability and developing effective voltage stability assessment (VSA) methods [
2].
Generally, voltage profiles show no anomalies before undergoing a voltage collapse due to load changes. Voltage stability margin (VSM) is a static voltage stability index that quantifies how “close” a particular operating point is to the point of voltage collapse [
3]. Therefore, the VSM can be used to estimate the steady-state voltage stability limit of a power system. Knowing voltage stability margins is critical for utilities to operate their systems safely and with reliability. The system operator must provide an accurate and fast method to predict the voltage stability margin to initiate the necessary control actions [
4].
That proposed a static voltage stability prediction method based on gradient boosting, which has better prediction accuracy [
5]. However, its training set data are obtained through the calculation of the cumulative probability function (CPF), which is only applicable to a fixed load power factor case. Ghiocel et al. [
6] proposed a new method to directly eliminate the singularity by reformulating the power flow problem. The central idea is to introduce an AQ bus in which the bus angle and the reactive power consumption of a load bus are specified. However, the computation burden is still heavy, and the solution speed cannot meet the requirement of real-time assessment.
With the boom of wide-area measurement systems in smart grids [
7,
8,
9], the availability of large amounts of data acquired by phasor measurement units (PMUs) presents a huge opportunity for data-driven stability assessments. Great efforts have been made to perform such tasks through machine learning techniques.
In [
10], a static stability assessment method for a power system based on a decision tree algorithm is proposed, which improves the assessment speed. However, there is no countermeasure for the decision tree over-fitting problem. Lai et al. [
11] proposed a transient voltage stability assessment model based on convolutional neural networks, which improves the assessment speed by using statistical analysis for data dimensionality reduction. However, relying only on statistical analysis for data dimensionality reduction, it is easy to ignore individual features. Liang et al. proposed a random forest model for static voltage stability assessment, which makes up for the assessment defects of a single decision tree [
12]. However, the selection of features is based on subjective judgment. The voltage stability assessment problem is treated as a classification problem of machine learning, making it difficult to accurately know the degree of voltage stability.
A common feature of these machine learning-based efforts is that they assume that the learning dataset can be generated by system simulations in the desired quantity [
13]. Since accurate simulation and modeling, especially load modeling, are considered a great challenge in power systems, errors are inevitably introduced into the learning dataset. Preferably, the learning dataset can be obtained from PMU records, which will significantly improve the quality and reliability of the knowledge base. However, learning machines are likely to suffer from severe class imbalance problems. The system remains stable after most disturbances and becomes unstable only in a few cases. If not handled properly, this imbalance can greatly deteriorate the performance of the learning machine, and the minority class will be ignored and thus leading to misjudging. The class imbalance problem exists not only in the field of power systems, but also widely in other academic and industrial contexts, such as credit fraud detection, biomedical diagnosis, equipment fault diagnosis, and Internet intrusion [
14].
Faced with class imbalance problems [
15], considerable efforts have been made by machine learning researchers to deal with them [
16,
17]. Synthetic sampling is the most commonly used method for rebalancing class distributions. However, it cannot be directly applied to voltage stability assessment. Because datasets created by naive replication or linear interpolation may not exist in practice. Besides sampling-related techniques, some cost-sensitive tricks are proposed to build cost-sensitive classifiers. By attaching costs to different classes, these techniques manage to enhance minority learning by drawing more attention to minority classes [
18].
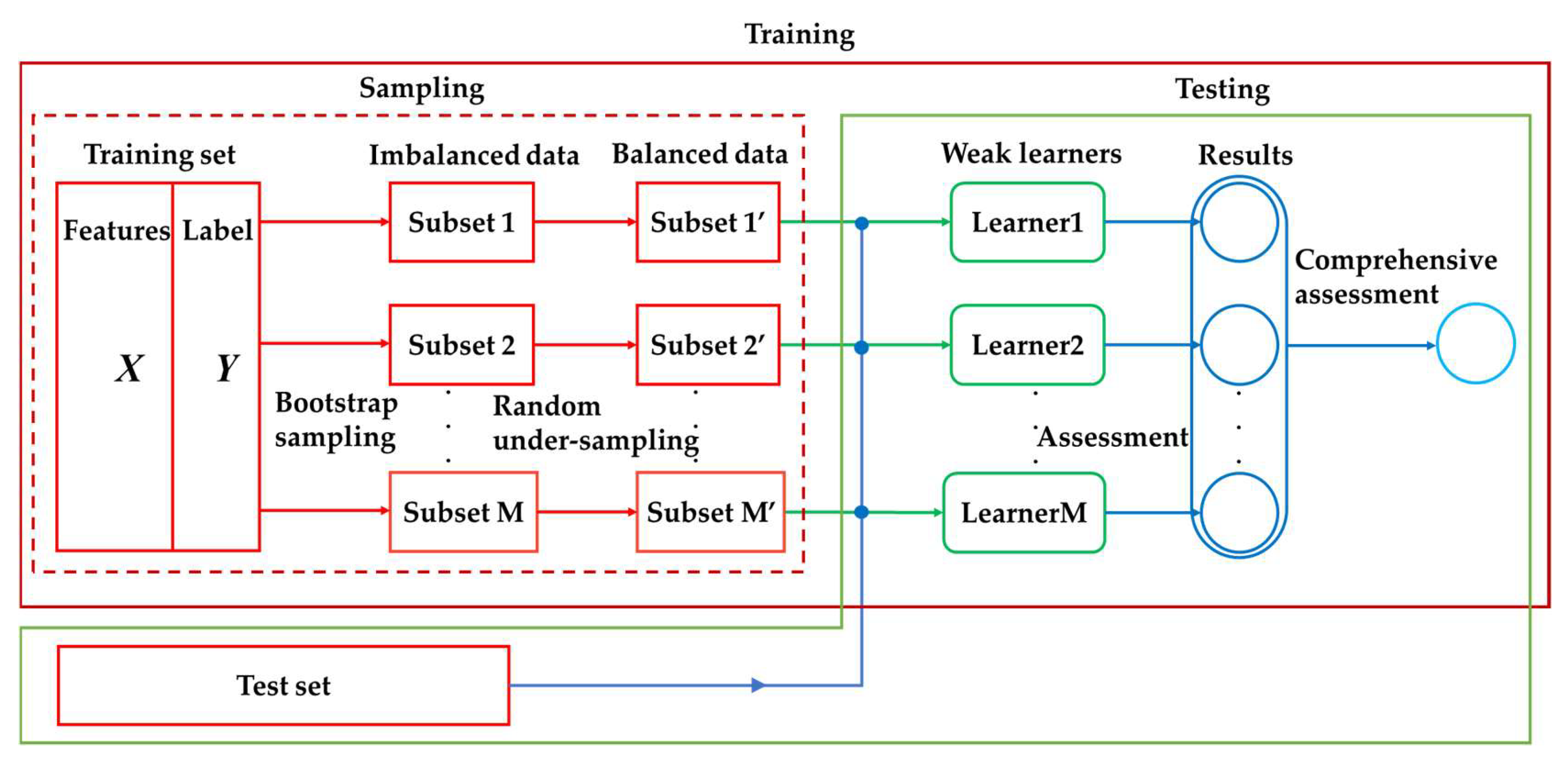
To meet the requirements of voltage stability assessment and solve the problem of class imbalance and poor model generalization in machine learning, an online assessment method of static voltage stability using the RUSBagging method is proposed. The method differs from other methods in that:
The problem of VSA is defined as a machine learning regression problem, which is helpful for grid operators to observe the voltage stability state of the power system.
The bagging method of the ensemble framework is used to build the model to improve the generalization ability of the model.
The random under-sampling method is added to bagging, which solves the class imbalance problem to a certain extent and improves the assessment accuracy on minority class samples.
2. Local Voltage Stability Index
Commonly used static voltage stability indexes are [
19,
20]: the Jacobi singular value index, voltage sensitivity index, load margin index, VCPI index, and local voltage stability index. Compared to other voltage stability indices, the local voltage stability index (L index), which can give normalized index values for different systems, and which is not limited by the randomness of the direction of load growth, are highly applicable and highly accurate.
By the KCL law (Kirchhoff’s current law) there is
, where
Y stands for node admittance,
V stands for node voltage, and
I stands for node current. In addition, according to the value of the node injection current, the network nodes are divided into generator nodes, load nodes, and contact nodes, and the equations of the node network after the division are as follows.
where
and
are the voltage and current vectors at the generator node,
and
are the voltage and current vectors at the load node, and
is the voltage vector at the contact node.
By eliminating the contact nodes, the remaining nodes in the network are divided into the set of generator nodes (
) and the set of load nodes (
), and Equation (1) can be transformed as:
where
,
,
,
.
Substituting
into Equation (2) converts to:
Reference [
15] gives the local voltage stability index
for load node
j:
where
,
are the voltage phases of nodes
i,
j respectively.
is the equivalent load of node
i.
is the mutual impedance conjugate between loads
j,
i of the equivalent load impedance matrix
.
is the self-conductance of the
jth node of the equivalent load conductance matrix
.
The local voltage stability index for all load nodes in the network forms the overall system stability index vector
,
and the maximum index value for the load is selected to define the voltage stability index for the system.
The relationship between local voltage stability index and system voltage stability is [
21]:
L < 1, system voltage stability.
L = 1, system voltage critical stability.
L > 1, system voltage instability.
4. Modeling of Static Voltage Stability Assessment Based on Machine Learning
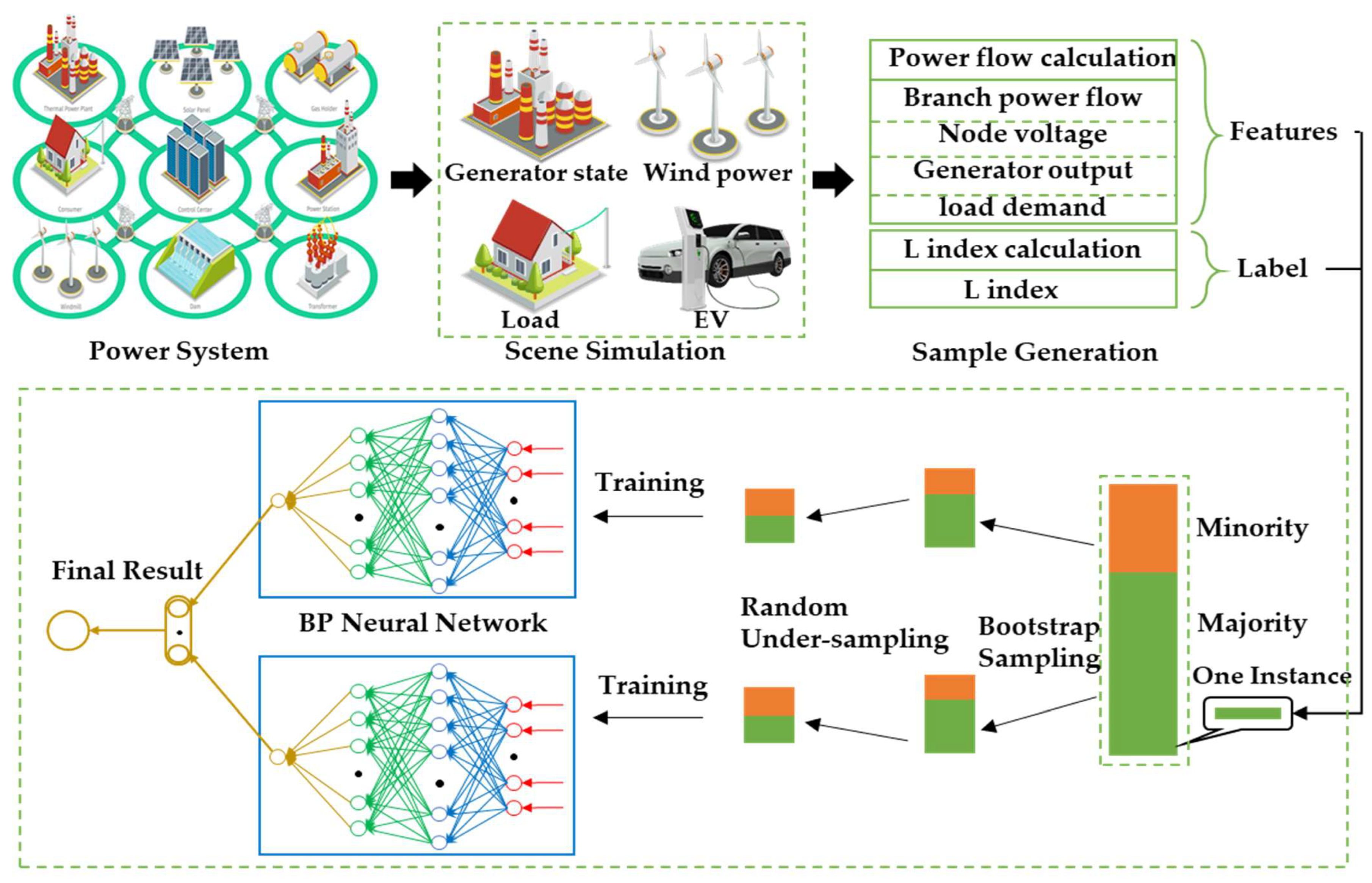
Based on power flow calculation and local voltage stability index calculation, the static voltage stability assessment problem of the power system is treated as a supervised machine learning problem. With the help of the machine learning method, the mapping relationship between the operating state and voltage stability is mined. The idea frame diagram is shown in
Figure 4.
In the framework shown in
Figure 4, there are mainly four parts: scene generation, sample generation, model building, and model training. The scene simulation is carried out considering the characteristics of the actual operation scene. In addition, the power flow calculation is performed on the simulated scene. The power flow calculation result is a feature variable of the sample corresponding to the scene. Based on the power flow calculation result, the local voltage stability index is calculated too. The index value is the corresponding label value (true value) of the sample in the scene.
The scenario simulation mainly considers the following factors: load demand, generator status, and new energy output power. Specifically, for the load demand, there are heavy load demand and light load demand. For the generator status, the generator does not reach the limit of reactive power and the reactive power of some units reaches the limit. There are two reasons for considering this factor: First, when the generator node transforms into a PQ node, the voltage stability state of the system will change abruptly. Second, the calculation of the L index needs to determine the type of system nodes in advance. When the type of node changes, the L index calculation model needs to be updated. For the output of new energy, the node where the unit is located is regarded as the PQ node. The load side also considers the batch connection to the grid and withdraws from the grid of electric vehicles.
The above factors only consider typical scenarios, so the number of scenarios is limited. Therefore, in the simulation, a mixed simulation of various factors is adopted to expand the number of scenarios. After the scenario simulation is completed, the power flow calculation is carried out for each scenario to obtain the voltage amplitude and phase angle of each node, the active and reactive power output of the generator, and the line power flow. These power flow calculation results and the load demand together constitute the features of samples. The L index corresponds to the features of samples packaged into complete training data. Since the L index can be directly calculated based on the power flow state, it does not require continuous power flow calculation like PV analysis, so the sample collection speed is very fast. The training set, validation set, and test set are randomly selected according to the ratio of 90%, 5%, and 5%.
BP network belongs to supervised learning [
27]. In the process of neural network modeling, the selection of activation function, loss function, and the optimization algorithm is required. In the design of hyperparameters, such as the number of hidden layers, the number of neurons in the hidden layer, the number of parallel BP networks, etc., it needs to be set according to specific problems, and these hyperparameters rely more on empirical values.
- (1)
Activation function
The activation function is the key to the nonlinear mapping function of the neural network. Common activation functions include Sigmoid, ReLU classes (ReLU, LReLU, RReLU), Tanh and Softmax. Through the nonlinearization of the input data by the above activation function, combined with the deep superposition of the neural network, the fitting of the nonlinear function is realized. In this paper, the LReLU activation function is selected as the activation function of the BP network, because the dead zone of LReLU has a small range. At the same time, LReLU can effectively avoid the problem of gradient disappearance, and also alleviate the problem of neuron death of ReLU, which is beneficial to the neural network. The curve of LReLU is shown in
Figure 5. The expression of the LReLU activation function is:
The domain of the LReLU function is negative infinity to positive infinity. LReLU alleviates the problem of ReLU neuron death and solves the problem that some neurons cannot be activated.
- (2)
Loss function
The loss function is used to measure the difference between the output value of the model and the true value of the sample. Through the back-propagation process, the loss function is minimized, the weight of the network is corrected, and the gap between the output value of the model and the true value of the sample is continuously narrowed to achieve network convergence.
For different learning models, such as regression models and classification models, the type of loss function needs to be selected. For the classification model, the cross-entropy loss function is generally used. For the regression model, the mean square error loss function is generally used. In this paper, the problem of voltage stability assessment is defined as a regression problem, so the mean square error function is chosen as the loss function.
where
represents the output value of the loss function,
N represents the number of samples used in a parameter update process, and
and
represent the true value and predicted value of the
ith sample label, respectively.
- (3)
Optimization algorithm
After completing the construction of the loss function, it is necessary to implement parameter correction through the optimization algorithm. The deep learning optimization algorithm mainly includes the basic optimization algorithm and the adaptive parameter optimization algorithm. The representative algorithm of the basic optimization algorithm is the stochastic gradient descent method, which keeps the learning rate unchanged during the training process. It cannot dynamically adapt to the training requirements. In addition, it is easy to fall into the local optimum point. The representative algorithm of the adaptive parameter optimization algorithm is Adam. The learning rate is gradually attenuated to better adapt to the training requirements as the learning progresses, shorten the training time, and improve the training effect. In this paper, the Adam algorithm [
28] is used as the optimization algorithm for network training.
In the formula, represents the gradient, represents the first-order moment estimation of the gradient, represents the second-order moment estimation of the gradient, and represent the corrected values of and , respectively. and represent the first-order momentum and the second-order momentum, respectively. Momentum coefficient, means avoiding smoothing terms with 0 denominators, means learning rate. The standard settings for and are 0.9 and 0.999, respectively, and the default value for is 0.001. A satisfactory training effect can be obtained by applying this set of hyperparameters during the training process, and no special adjustment is generally required.
5. Results
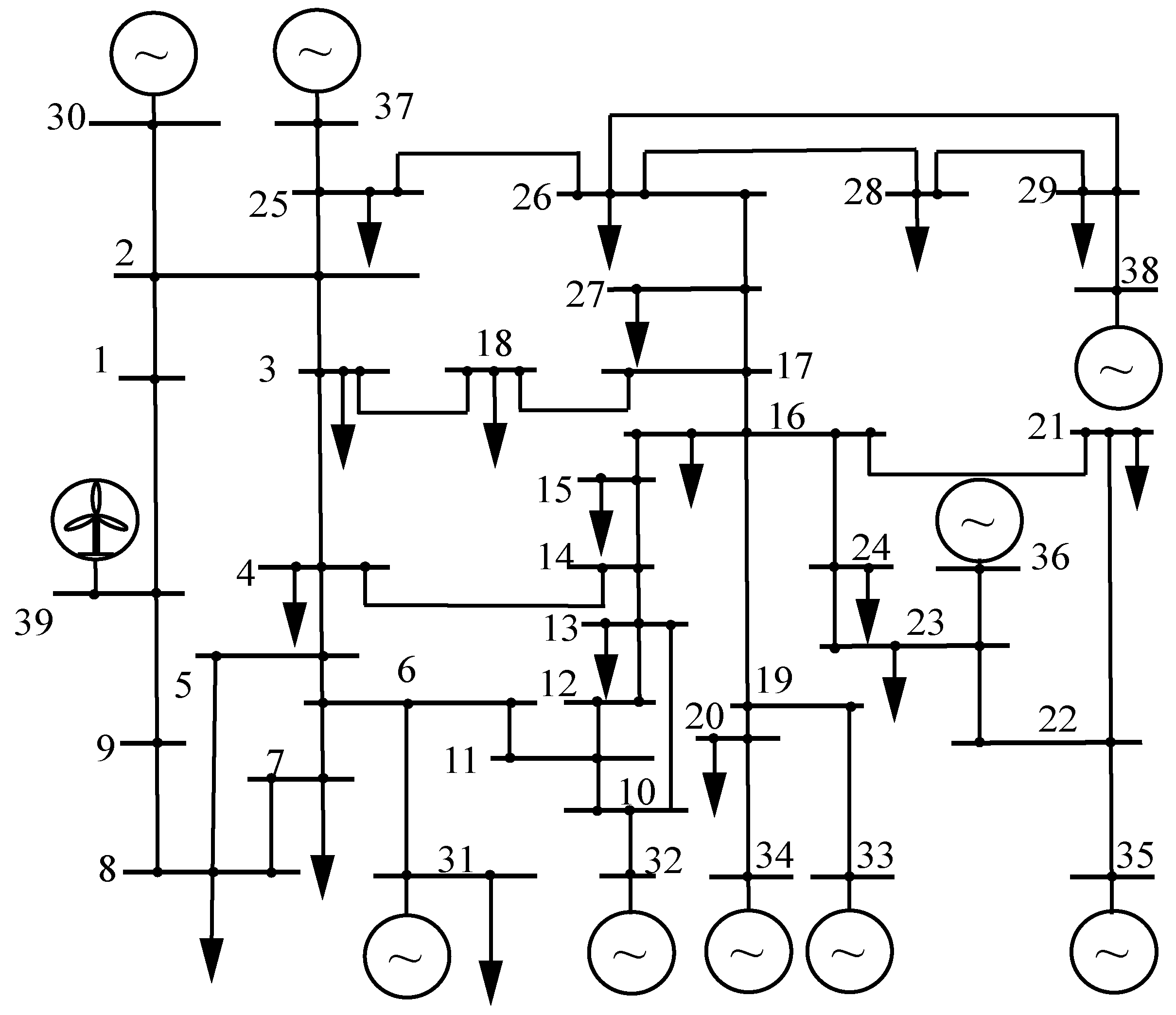
To verify the effectiveness of the proposed model, the modified IEEE39 system case is taken as an example, as shown in
Figure 6. The IEEE39 system [
29] has 39 nodes, 19 load nodes, 10 thermal power units, and 46 branches (including transformers) with the following modifications: replacing the thermal power generator on bus-39 with wind turbines with a capacity of 650 MVA and removing the load of bus-39.
The neural network model is built based on the Pytorch framework, and the power system simulation is performed based on the PSSE simulation platform. An analysis is developed from the perspectives of model training time, mean square error (MSE), and mean absolute percentage error (MAPE).
In machine learning, MSE is generally used as the error of model training, and it is used as the objective function to update the parameters. The expression of MSE is shown in Formula (17):
where
is the predicted value of the
ith sample, and
is the true value of the
ith sample. The advantage of MSE is to amplify extreme errors and avoid huge deviations in the model. The disadvantage is that it is not intuitive and it is difficult to explain its meaning after squaring.
In order to intuitively reflect the difference between the actual value and the predicted value, there is MAPE, which is expressed as Formula (18):
The value of MAPE is intuitive and has a clear meaning, but when the actual value is very small, it is easy to produce misleading information. Therefore, MAPE is generally not used for the loss function of regression problems with small real values, but it can be used as a more intuitive method to measure the model error.
In summary, MSE is used to evaluate the overall performance of the model, and MAPE is used to evaluate the performance of the model on batch instances.
The training time of different methods and the MSE and MAPE error of each method on the test set are shown in
Table 2.
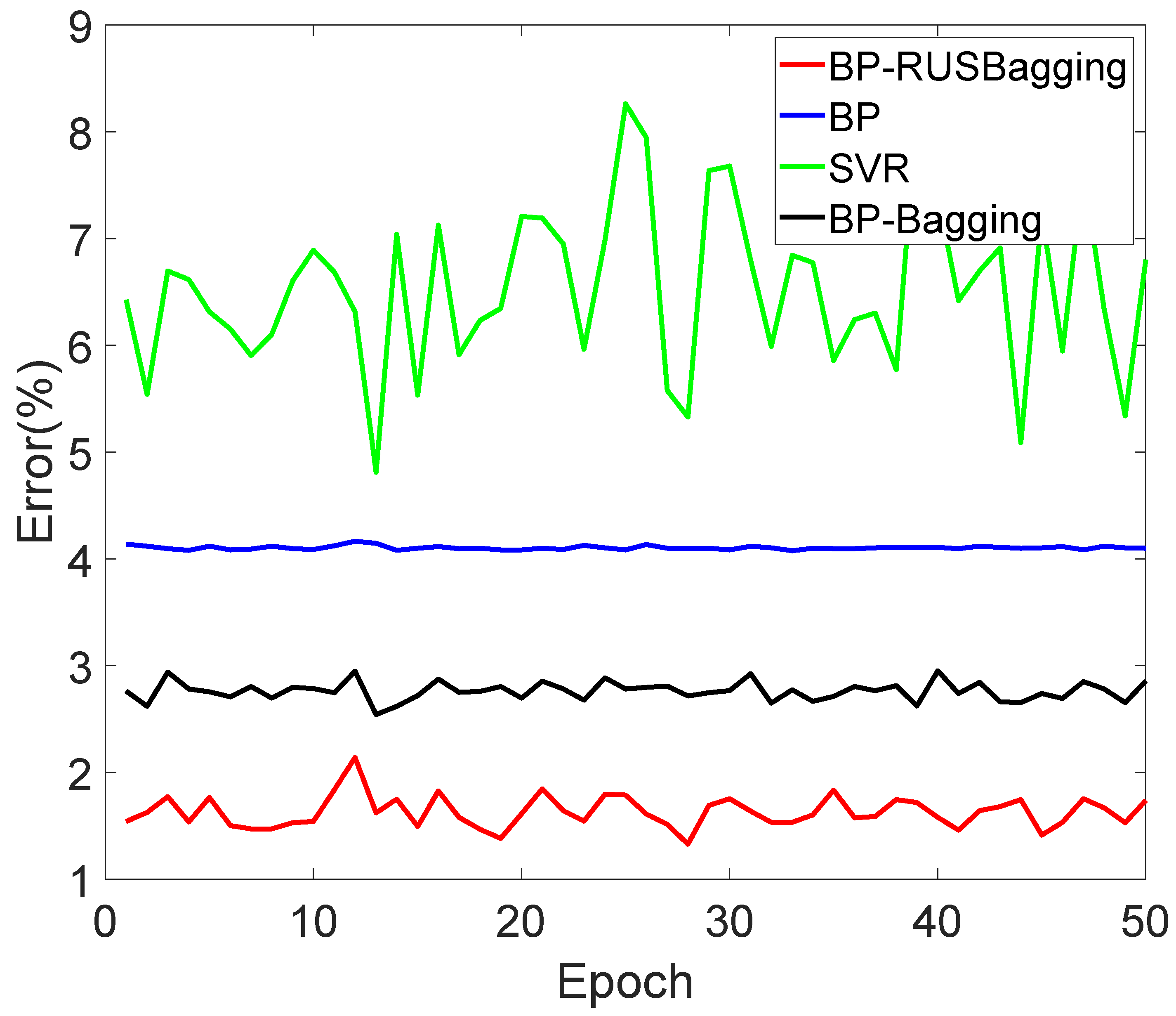
SVR stands for support vector regression. The test set is divided into multiple batches of data, and each batch of data is calculated to obtain the batch MAPE index and plot the results, as shown in
Figure 7.
As shown in
Figure 7, the errors of the four methods on the test set are all small, and the advantage of method 1 is not obvious. This is because the test set is also a class-imbalanced data set, so the advantage of the under-sampling method is not prominent on the whole test set.
To further illustrate the applicability of the proposed method to the class imbalance problem, the minority class samples in the test set are screened out, and then four methods are used for comparison based on the minority test set. The results are shown in
Table 3.
As shown in
Figure 8, on the screened test set, the proposed method has obvious advantages over other methods. It has a lower error on minority class samples. Compared with methods 3 and 4, method 2 also shows the adaptability to the class imbalance problem to a certain extent. This should be credited to the bagging framework.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}