Towards an Uncertainty-Aware Visualization in the Digital Humanities †

 ,
,  , and
, and
Abstract
:1. Introduction
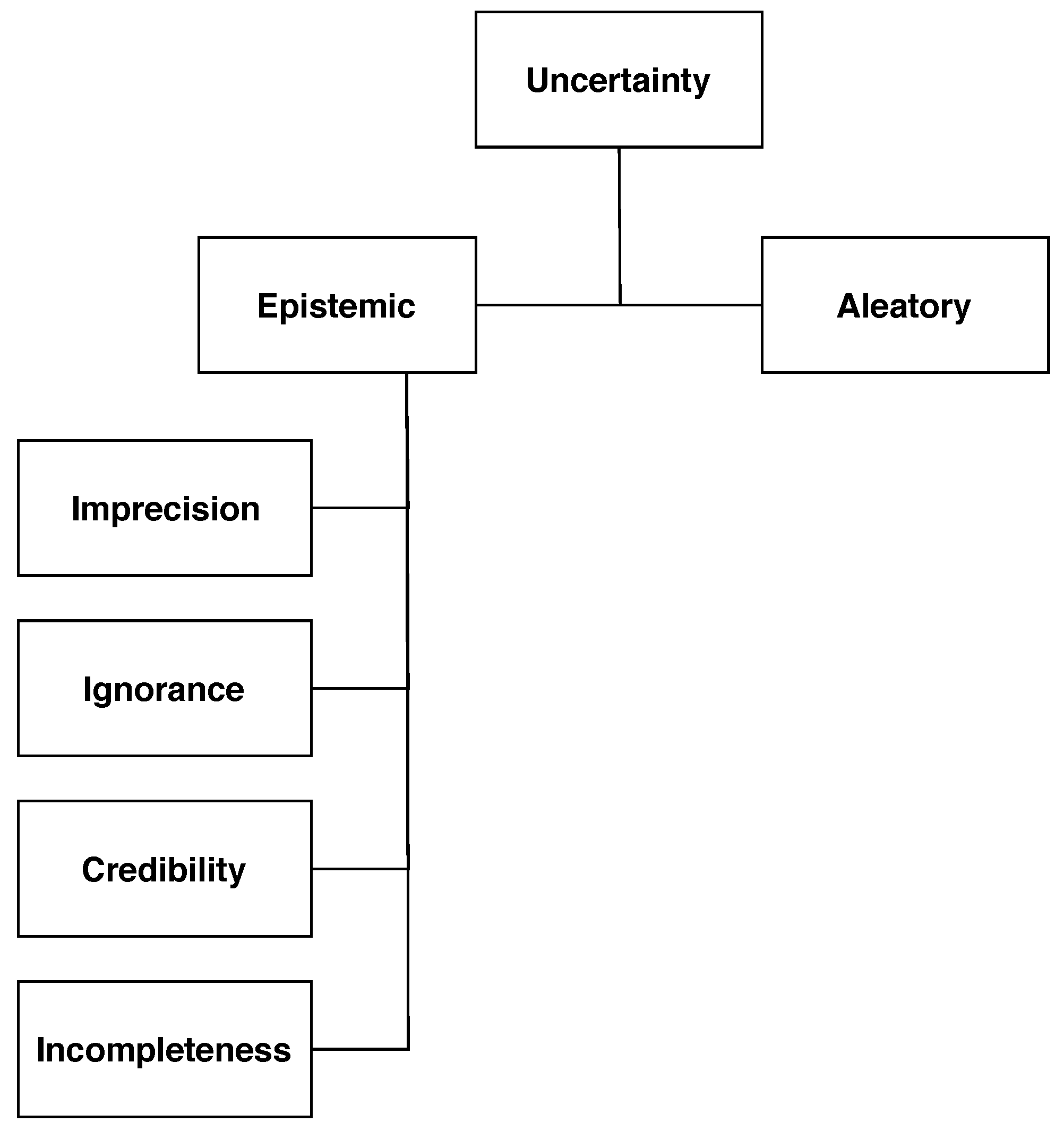
2. Uncertainty Taxonomies
2.1. Uncertainty in GIScience
2.1.1. Aleatoric Uncertainty
2.1.2. Epistemic Uncertainty
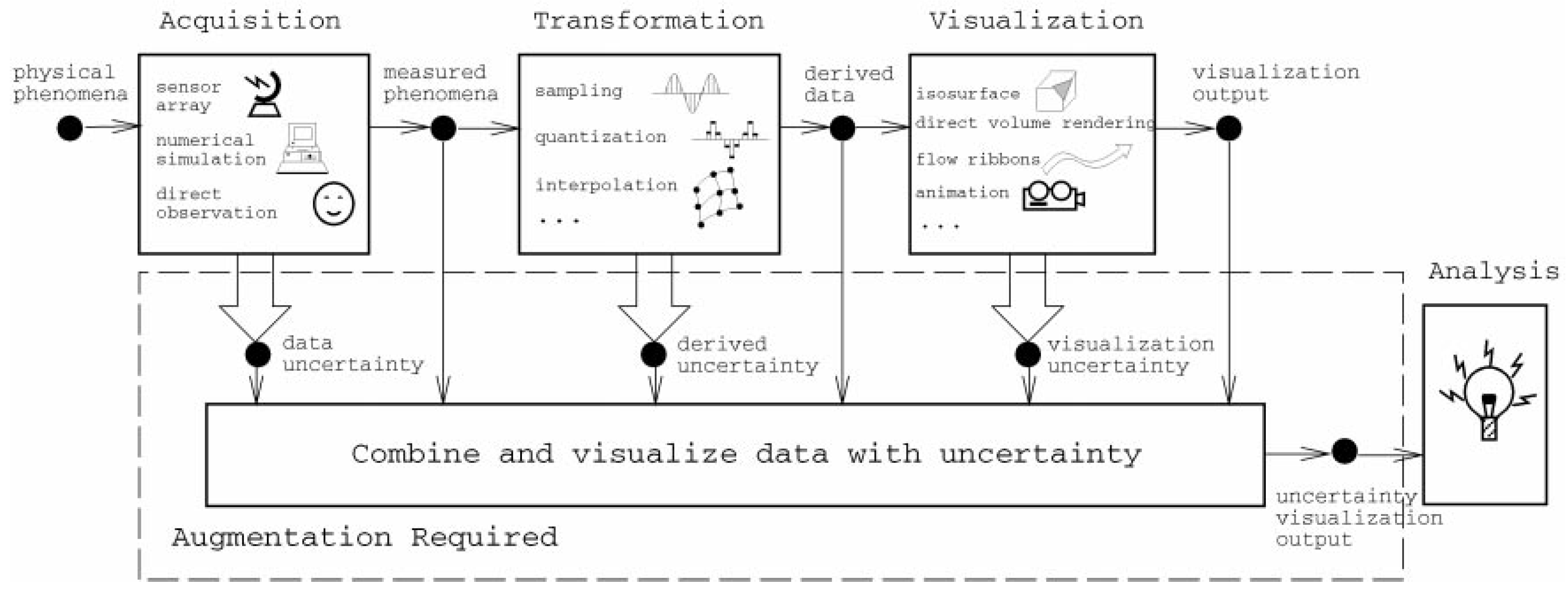
2.2. Sources of Uncertainty in Data Analysis
- Uncertainty in acquisition: All data sets are, by definition, uncertain due to their bounded variability. The source of this variability can be introduced by the lack of precision of the electronic devices capturing the information (e.g., a telescope), emerge from a numerical calculation performed according to a model (e.g., the limited precision of computers in representing very large numbers), or induced by human factors; for example, due to differences in perception of the individuals reporting the information through direct observation.
- Uncertainty in transformation: Appears due to the conversions applied to the data in order to produce meaningful knowledge. This could be related to the imprecise calculation of new attributes when applying clustering, quantization, or resampling techniques.
- Uncertainty in visualization: The process of presenting the information to the final user is also subject to introducing uncertainty. The rendering, rasterization, and interpolation algorithms at play that produce the graphical displays of information are also prone to errors. Furthermore, there is usually a performance/accuracy trade-off present at this stage: The more reliable and accurate a visualization is, the more computational resources it will employ and, almost always, the performance times will decay substantially. As has been noted by some authors, this has a negative effect on the way humans grasp the information contained in the data and can even invalidate the whole approach to data analysis [28,29,30].
2.3. Implications for Decision-Making in the Digital Humanities
3. Modeling Uncertainty in the Digital Humanities
3.1. Aleatoric Uncertainty
3.2. Epistemic Uncertainty
3.2.1. Imprecision
3.2.2. Ignorance
3.2.3. Credibility/Discord
3.2.4. Incompleteness
4. Data and Uncertainty in Digital Humanities
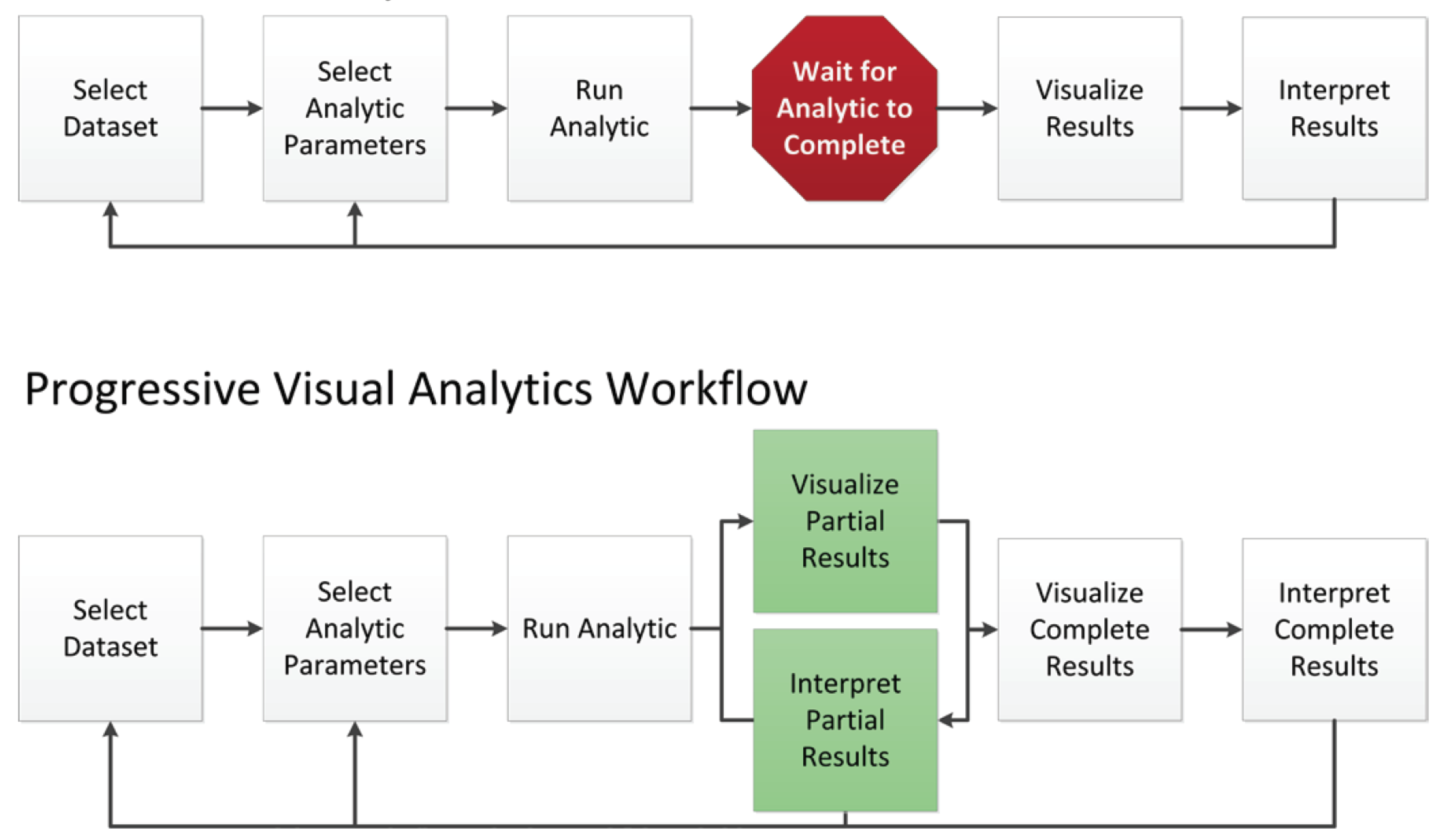
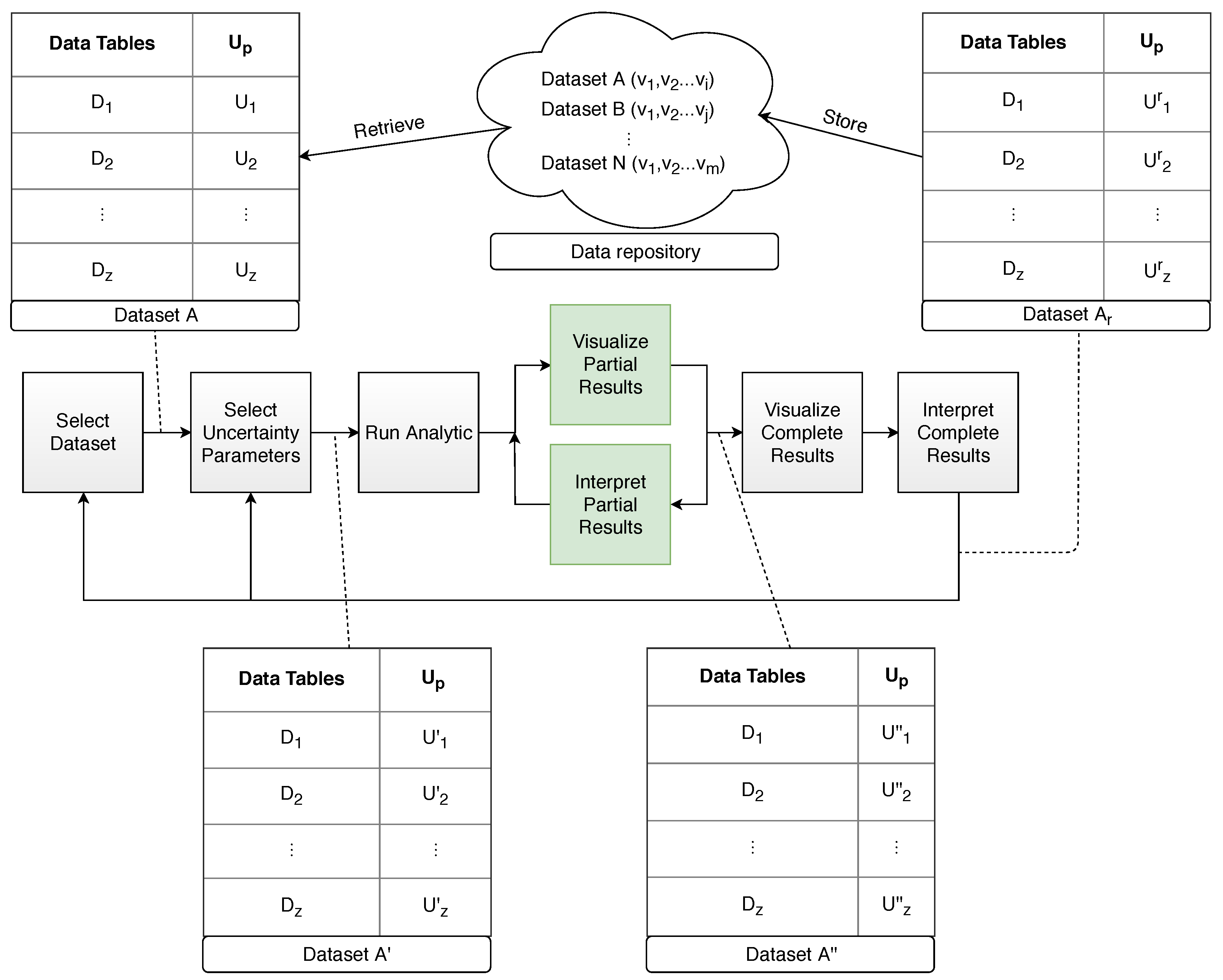
5. Managing Uncertainty Through Progressive Visual Analytics
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| DH | Digital Humanities |
| PVA | Progressive Visual Analytics |
| CS | Computer Science |
References
- Warwick, C.; Terras, M.; Nyhan, J. Digital Humanities in Practice; Facet Publishing: London, UK, 2012. [Google Scholar]
- Anne, K.; Carlisle, T.; Dombrowski, Q.; Glass, E.; Gniady, T.; Jones, J.; Lippincott, J.; MacDermott, J.; Meredith-Lobay, M.; Rockenbach, B.; et al. Building Capacity for Digital Humanities: A Framework for Institutional Planning; ECAR Working Group Paper; ECAR: Louisville, CO, USA, 2017. [Google Scholar]
- Hoffman, F.O.; Hammonds, J.S. Propagation of uncertainty in risk assessments: The need to distinguish between uncertainty due to lack of knowledge and uncertainty due to variability. Risk Anal. 1994, 14, 707–712. [Google Scholar] [CrossRef] [PubMed]
- Ferson, S.; Ginzburg, L.R. Different methods are needed to propagate ignorance and variability. Reliab. Eng. Syst. Saf. 1996, 54, 133–144. [Google Scholar] [CrossRef]
- Helton, J.C. Uncertainty and sensitivity analysis in the presence of stochastic and subjective uncertainty. J. Stat. Comput. Simul. 1997, 57, 3–76. [Google Scholar] [CrossRef]
- Riesch, H. Levels of uncertainty. In Essentials of Risk Theory; Springer: Dordrecht, The Netherlands, 2013; pp. 29–56. [Google Scholar]
- Lovell, B. A Taxonomy of Types of Uncertainty. Ph.D. Thesis, Portland State University, Portland, OR, USA, 1995. [Google Scholar]
- Zimmermann, H.J. An application-oriented view of modeling uncertainty. Eur. J. Oper. Res. 2000, 122, 190–198. [Google Scholar] [CrossRef]
- Ramirez, A.J.; Jensen, A.C.; Cheng, B.H. A taxonomy of uncertainty for dynamically adaptive systems. In Proceedings of the 7th International Symposium on Software Engineering for Adaptive and Self-Managing Systems, Zurich, Switzerland, 4–5 June 2012; pp. 99–108. [Google Scholar]
- Priem, R.L.; Love, L.G.; Shaffer, M.A. Executives’ perceptions of uncertainty sources: A numerical taxonomy and underlying dimensions. J. Manag. 2002, 28, 725–746. [Google Scholar] [CrossRef]
- Regan, H.M.; Colyvan, M.; Burgman, M.A. A taxonomy and treatment of uncertainty for ecology and conservation biology. Ecol. Appl. 2002, 12, 618–628. [Google Scholar] [CrossRef]
- Refsgaard, J.C.; van der Sluijs, J.P.; Højberg, A.L.; Vanrolleghem, P.A. Uncertainty in the environmental modelling process—A framework and guidance. Environ. Model. Softw. 2007, 22, 1543–1556. [Google Scholar] [CrossRef]
- Han, P.K.; Klein, W.M.; Arora, N.K. Varieties of uncertainty in health care: A conceptual taxonomy. Med. Decis. Mak. 2011, 31, 828–838. [Google Scholar] [CrossRef]
- Howell, W.C.; Burnett, S.A. Uncertainty measurement: A cognitive taxonomy. Organ. Behav. Hum. Perform. 1978, 22, 45–68. [Google Scholar] [CrossRef]
- Potter, K.; Rosen, P.; Johnson, C.R. From Quantification to Visualization: A Taxonomy of Uncertainty Visualization Approaches. In Uncertainty Quantification in Scientific Computing; Dienstfrey, A.M., Boisvert, R.F., Eds.; IFIP Advances in Information and Communication Technology; Springer: Berlin/Heidelberg, Germany, 2012; pp. 226–249. [Google Scholar]
- MacEachren, A.M. Visualizing Uncertain Information. Cartogr. Perspect. 1992, 13, 10–19. [Google Scholar] [CrossRef]
- Fisher, P.F. Models of uncertainty in spatial data. Geogr. Inf. Syst. 1999, 1, 191–205. [Google Scholar]
- Cooley, M. Human-Centered Design. In Information Design; MIT Press: Cambridge, MA, USA, 2000; pp. 59–81. [Google Scholar]
- Nusrat, E. A Framework of Descriptive Decision-Making under Uncertainty Using Depster-Shafer Theory and Prospect Theory. Ph.D. Thesis, Nagaoka University of Technology, Niigata, Japan, 2013. [Google Scholar]
- Dubois, D. Representation, propagation, and decision issues in risk analysis under incomplete probabilistic information. Risk Anal. 2010, 30, 361–368. [Google Scholar] [CrossRef] [PubMed]
- Der Kiureghian, A.; Ditlevsen, O. Aleatory or epistemic? Does it matter? Struct. Saf. 2009, 31, 105–112. [Google Scholar] [CrossRef]
- Simon, C. Data Uncertainty and Important Measures; ISTE Ltd/John Wiley and Sons Inc: Hoboken, NJ, USA, 2017. [Google Scholar]
- Matthies, H.G. Quantifying uncertainty: Modern computational representation of probability and applications. In Extreme Man-Made and Natural Hazards in Dynamics of Structures; Springer: Dordrecht, The Netherlands, 2007; pp. 105–135. [Google Scholar]
- Bae, H.R.; Grandhi, R.V.; Canfield, R.A. An approximation approach for uncertainty quantification using evidence theory. Reliab. Eng. Syst. Saf. 2004, 86, 215–225. [Google Scholar] [CrossRef]
- Dempster, A.P. Upper and lower probabilities induced by a multivalued mapping. Ann. Math. Stat. 1967, 38, 325–339. [Google Scholar] [CrossRef]
- Gonzalez-Perez, C. (Ed.) Vagueness. In Information Modelling for Archaeology and Anthropology: Software Engineering Principles for Cultural Heritage; Springer International Publishing: Cham, Switzerland, 2018; pp. 129–141. [Google Scholar]
- Pang, A.T.; Wittenbrink, C.M.; Lodha, S.K. Approaches to Uncertainty Visualization. Vis. Comput. 1997, 13, 370–390. [Google Scholar] [CrossRef]
- Miller, R.B. Response Time in Man-Computer Conversational Transactions. In Proceedings of the December 9-11, 1968, Fall Joint Computer Conference, Part I; AFIPS ’68 (Fall, Part I); ACM: New York, NY, USA, 1968; pp. 267–277. [Google Scholar] [CrossRef]
- Nielsen, J. Response Time Limits. 2010. Available online: http://www.nngroup.com/articles/response-times-3-important-limits (accessed on 3 June 2019).
- Shneiderman, B. Response Time and Display Rate in Human Performance with Computers. ACM Comput. Surv. 1984, 16, 265–285. [Google Scholar] [CrossRef]
- Mühlbacher, T.; Piringer, H.; Gratzl, S.; Sedlmair, M.; Streit, M. Opening the black box: Strategies for increased user involvement in existing algorithm implementations. IEEE Trans. Vis. Comput. Graph. 2014, 20, 1643–1652. [Google Scholar] [CrossRef] [PubMed]
- Thomson, J.; Hetzler, E.; MacEachren, A.; Gahegan, M.; Pavel, M. A Typology for Visualizing Uncertainty. Proc. SPIE 2005, 5669, 146–158. [Google Scholar] [CrossRef]
- Kahneman, D.; Tversky, A. Prospect Theory: An Analysis of Decision under Risk. Econometrica 1979, 47, 263–291. [Google Scholar] [CrossRef]
- Tversky, A.; Kahneman, D. Judgment under uncertainty: Heuristics and biases. Science 1974, 185, 1124–1131. [Google Scholar] [CrossRef] [PubMed]
- Küster, M.W.; Ludwig, C.; Al-Hajj, Y.; Selig, T. TextGrid provenance tools for digital humanities ecosystems. In Proceedings of the 5th IEEE International Conference on Digital Ecosystems and Technologies (DEST 2011), Daejeon, Korea, 31 May–3 June 2011; pp. 317–323. [Google Scholar]
- Burgess, L.C. Provenance in Digital Libraries: Source, Context, Value and Trust. In Building Trust in Information; Springer: Cham, Switzerland, 2016; pp. 81–91. [Google Scholar]
- Walkowski, N.O. Evaluating Research Practices in the Digital Humanities by Means of User Activity Analysis. In Proceedings of the Digital Humanities, DH2017, Montreal, QC, Canada, 8–11 August 2017; pp. 1–3. [Google Scholar]
- Sanchez, L.M.; Bertolotto, M. Uncertainty in Historical GIS. In Proceedings of the 1st International Conference on GeoComputation, Leeds, UK, 4–7 September 2017. [Google Scholar]
- Jänicke, S.; Wrisley, D.J. Visualizing uncertainty: How to use the fuzzy data of 550 medieval texts. In Proceedings of the Digital Humanities, Lincoln, NE, USA, 16–19 July 2013. [Google Scholar]
- Binder, F.; Entrup, B.; Schiller, I.; Lobin, H. Uncertain about Uncertainty: Different ways of processing fuzziness in digital humanities data. In Proceedings of the Digital Humanities, Lausanne, Switzerland, 7–12 July 2014. [Google Scholar]
- Seipp, K.; Ochoa, X.; Gutiérrez, F.; Verbert, K. A research agenda for managing uncertainty in visual analytics. In Proceedings of the Mensch und Computer 2016—Workshopband, Aachen, Germany, 4–7 September 2016. [Google Scholar]
- Meeks, E.; Weingart, S.B. The Digital Humanities Contribution to Topic Modeling. J. Digit. Humanit. 2012, 2, 1–6. [Google Scholar]
- McNutt, M. Reproducibility; American Association for the Advancement of Science: Washington, DC, USA, 2014. [Google Scholar]
- Stodden, V.; McNutt, M.; Bailey, D.H.; Deelman, E.; Gil, Y.; Hanson, B.; Heroux, M.A.; Ioannidis, J.P.; Taufer, M. Enhancing reproducibility for computational methods. Science 2016, 354, 1240–1241. [Google Scholar] [CrossRef] [PubMed]
- Edmond, J.; Folan, G.N. Data, Metadata, Narrative. Barriers to the Reuse of Cultural Sources. In Research Conference on Metadata and Semantics Research; Springer: Cham, Switzerland, 2017; pp. 253–260. [Google Scholar]
- Wyatt, S.; Millen, D. Meaning and Perspective in the Digital Humanities; A White Paper for the establishment of a Center for Humanities and Technology (CHAT); Royal Netherlands Academy of Arts & Sciences (KNAW): Amsterdam, The Netherlands, 2014. [Google Scholar]
- Drucker, J. Humanities Approaches to Graphical Display. Digit. Humanit. Q. 2011, 5, 1–21. [Google Scholar]
- Ghani, J.A.; Deshpande, S.P. Task Characteristics and the Experience of Optimal Flow in Human—Computer Interaction. J. Psychol. 1994, 128, 381–391. [Google Scholar] [CrossRef]
- Stolper, C.D.; Perer, A.; Gotz, D. Progressive Visual Analytics: User-Driven Visual Exploration of In-Progress Analytics. IEEE Trans. Vis. Comput. Graph. 2014, 20, 1653–1662. [Google Scholar] [CrossRef] [PubMed]
- Shneiderman, B. Direct manipulation: A step beyond programming languages. Computer 1983, 16, 57–69. [Google Scholar] [CrossRef]
- Bostock, M. Visualizing Algorithms. 2014. Available online: http://bost.ocks.org/mike/algorithms (accessed on 3 June 2019).
- Bostock, M.; Ogievetsky, V.; Heer, J. D3 Data-Driven Documents. IEEE Trans. Vis. Comput. Graph. 2011, 17, 2301–2309. [Google Scholar] [CrossRef] [PubMed]
- Pezzotti, N.; Lelieveldt, B.P.F.; van der Maaten, L.; Höllt, T.; Eisemann, E.; Vilanova, A. Approximated and User Steerable tSNE for Progressive Visual Analytics. IEEE Trans. Vis. Comput. Graph. 2017, 23, 1739–1752. [Google Scholar] [CrossRef]
- Fekete, J.D.; Primet, R. Progressive Analytics: A Computation Paradigm for Exploratory Data Analysis. arXiv, 2016; arXiv:1607.05162. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Therón Sánchez, R.; Benito Santos, A.; Santamaría Vicente, R.; Losada Gómez, A. Towards an Uncertainty-Aware Visualization in the Digital Humanities. Informatics 2019, 6, 31. https://doi.org/10.3390/informatics6030031
Therón Sánchez R, Benito Santos A, Santamaría Vicente R, Losada Gómez A. Towards an Uncertainty-Aware Visualization in the Digital Humanities. Informatics. 2019; 6(3):31. https://doi.org/10.3390/informatics6030031
Chicago/Turabian StyleTherón Sánchez, Roberto, Alejandro Benito Santos, Rodrigo Santamaría Vicente, and Antonio Losada Gómez. 2019. "Towards an Uncertainty-Aware Visualization in the Digital Humanities" Informatics 6, no. 3: 31. https://doi.org/10.3390/informatics6030031