

Informatics 2024, 11(2), 22; https://doi.org/10.3390/informatics11020022 - 19 Apr 2024
Abstract
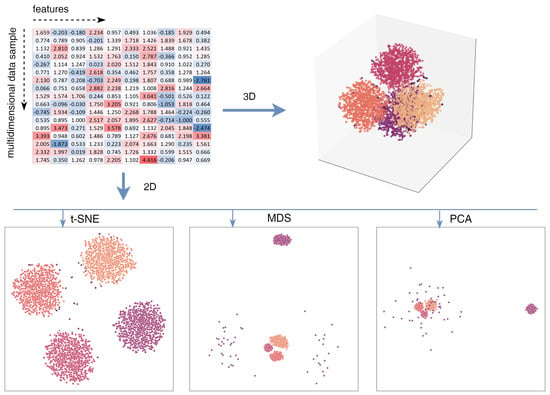
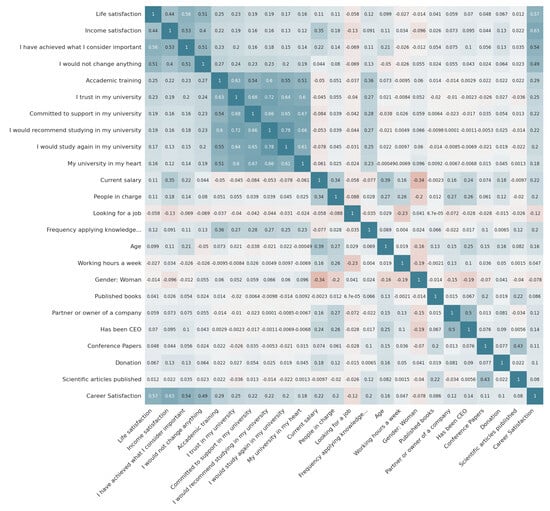
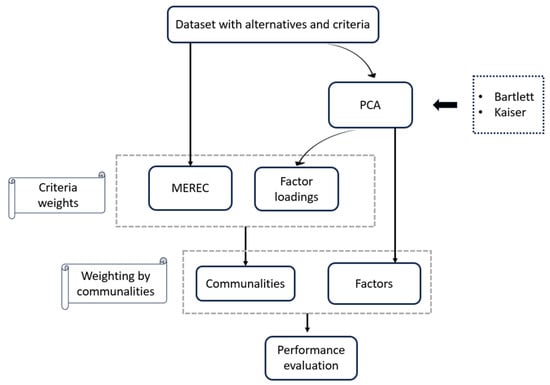
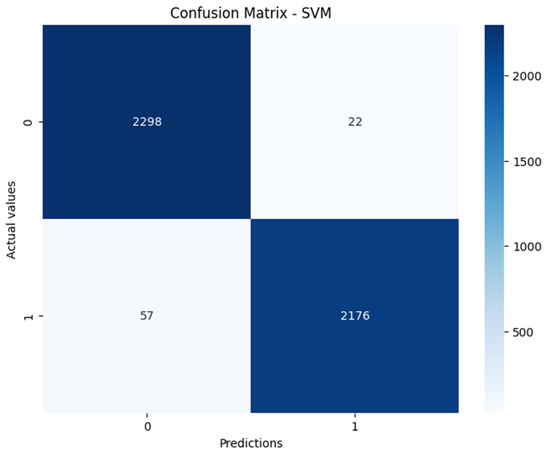
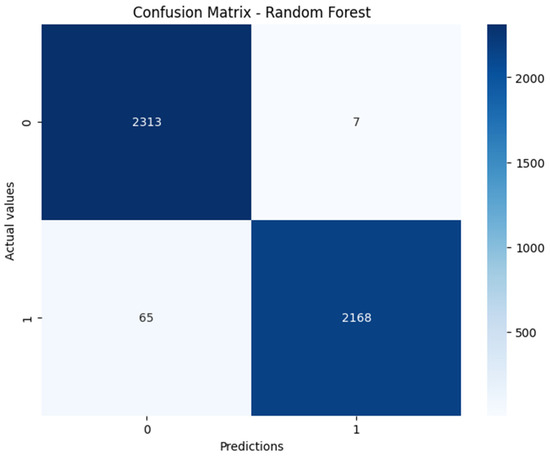
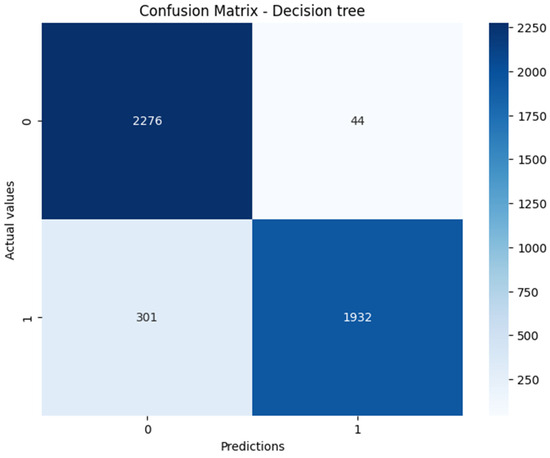
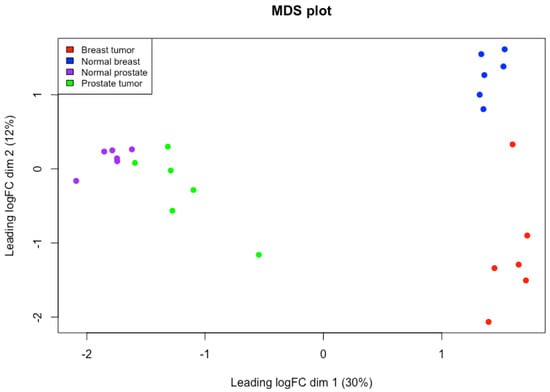
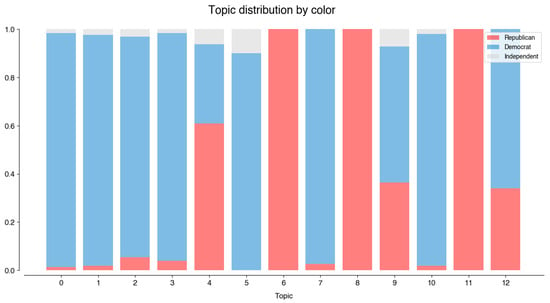
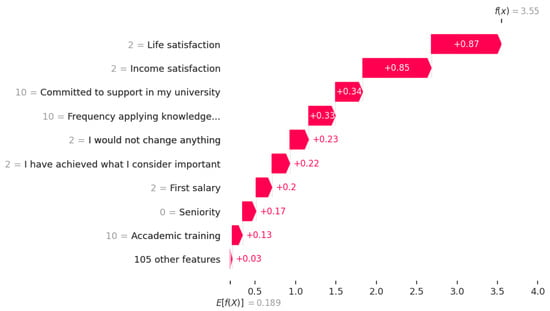
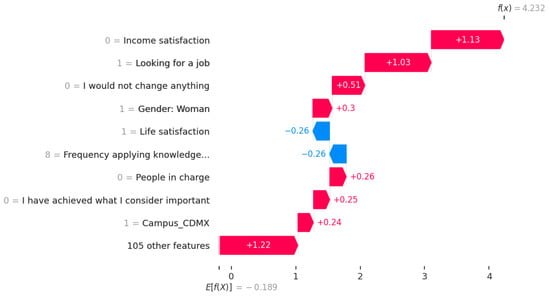
This study addresses Obstructive Sleep Apnea (OSA), which impacts around 936 million adults globally. The research introduces a novel decision support method named Communalities on Ranking and Objective Weights Method (CROWM), which employs principal component analysis (PCA), unsupervised Machine Learning techniques, and Multicriteria
[...] Read more.
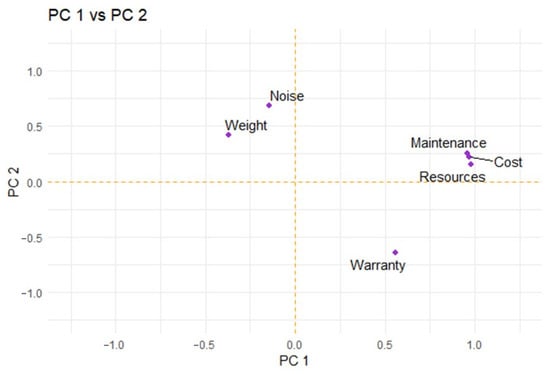
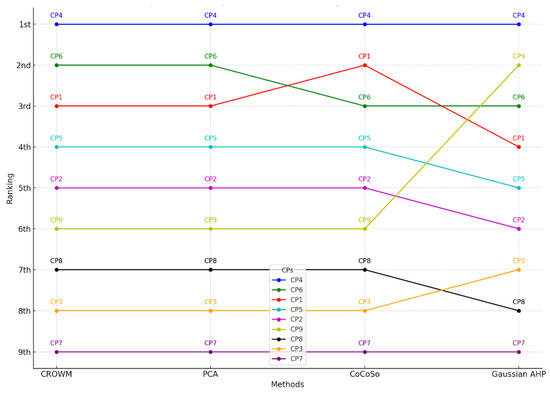
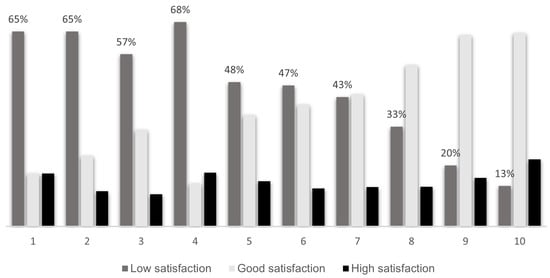
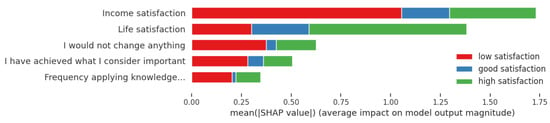
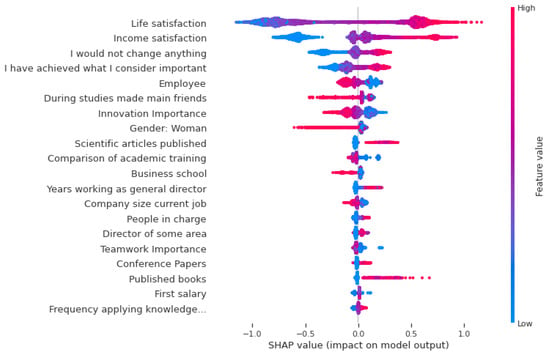
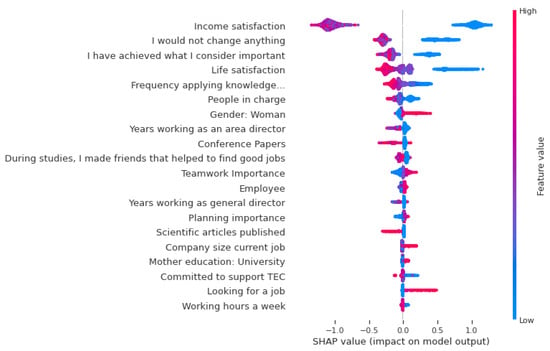
This study addresses Obstructive Sleep Apnea (OSA), which impacts around 936 million adults globally. The research introduces a novel decision support method named Communalities on Ranking and Objective Weights Method (CROWM), which employs principal component analysis (PCA), unsupervised Machine Learning techniques, and Multicriteria Decision Analysis (MCDA) to calculate performance criteria weights of Continuous Positive Airway Pressure (CPAP—key in managing OSA) and to evaluate these devices. Uniquely, the CROWM incorporates non-beneficial criteria in PCA and employs communalities to accurately represent the performance evaluation of alternatives within each resulting principal factor, allowing for a more accurate and robust analysis of alternatives and variables. This article aims to employ CROWM to evaluate CPAP for effectiveness in combating OSA, considering six performance criteria: resources, warranty, noise, weight, cost, and maintenance. Validated by established tests and sensitivity analysis against traditional methods, CROWM proves its consistency, efficiency, and superiority in decision-making support. This method is poised to influence assertive decision-making significantly, aiding healthcare professionals, researchers, and patients in selecting optimal CPAP solutions, thereby advancing patient care in an interdisciplinary research context.
Full article
(This article belongs to the Topic Decision Science Applications and Models (DSAM))
►
Show Figures
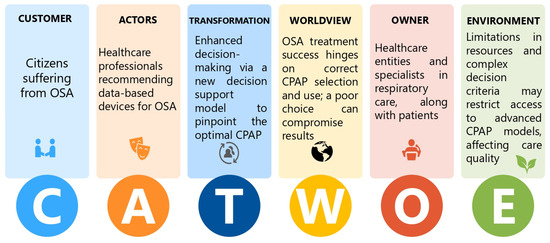
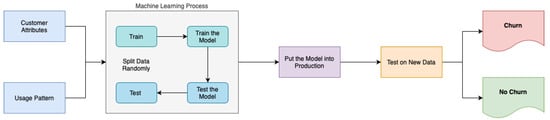
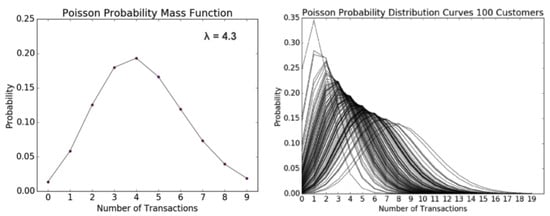
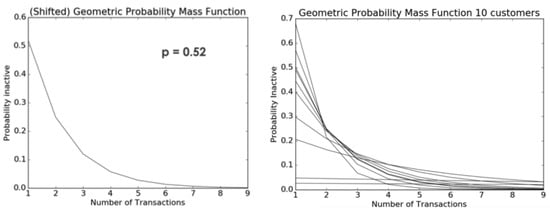
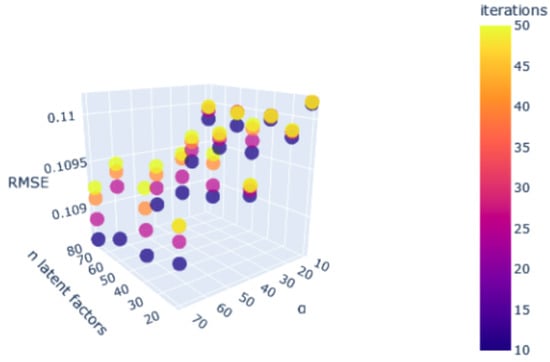
Figure 1




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
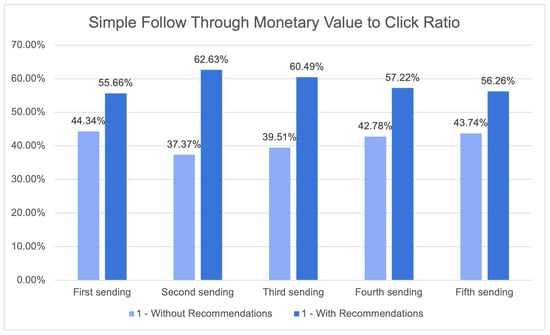{kind=link}
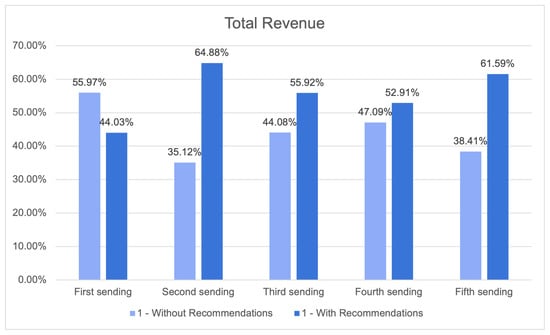{kind=link}
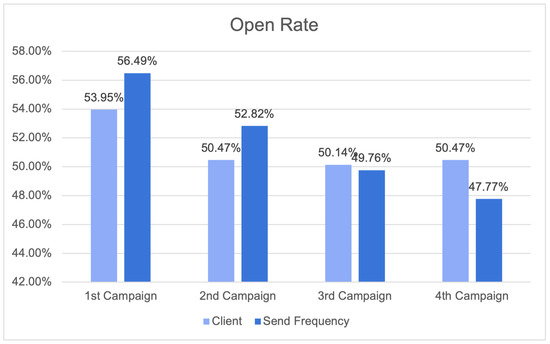{kind=link}
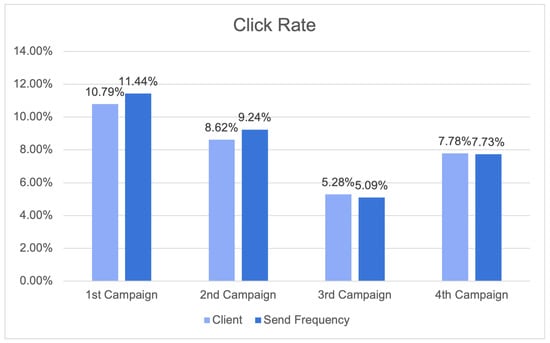{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
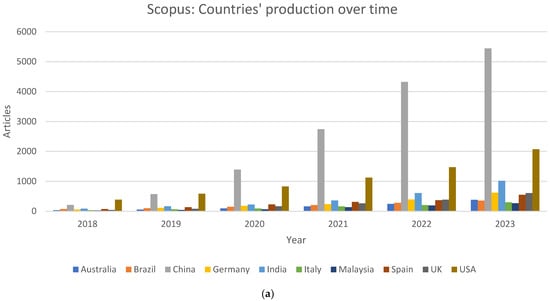{kind=link}
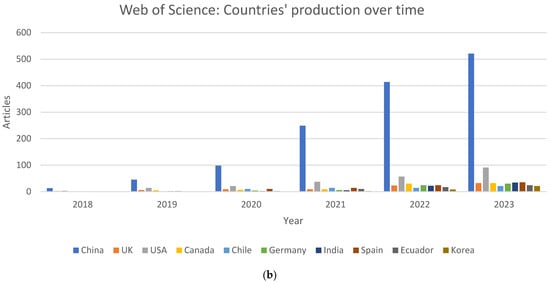{kind=link}
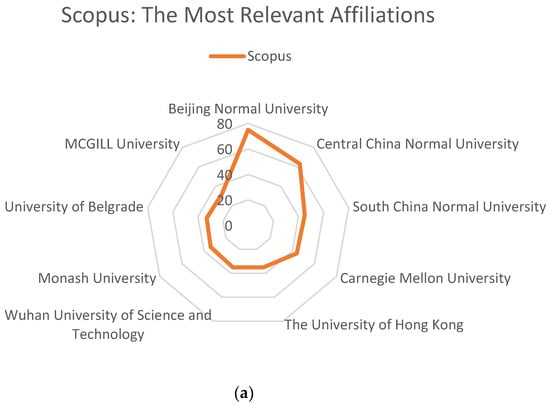{kind=link}
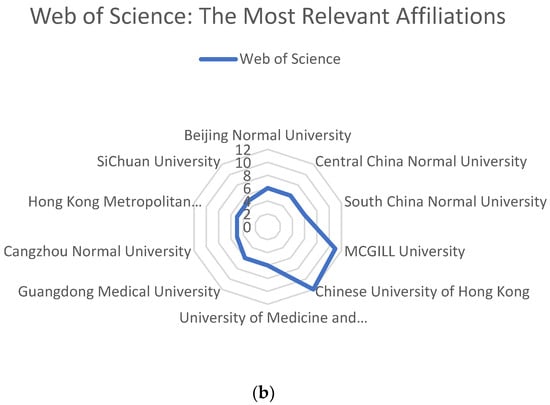{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}