

Is It Possible to Predict COVID-19? Stochastic System Dynamic Model of Infection Spread in Kazakhstan
 , , ,
, , ,
Abstract
:1. Introduction
2. Materials and Methods
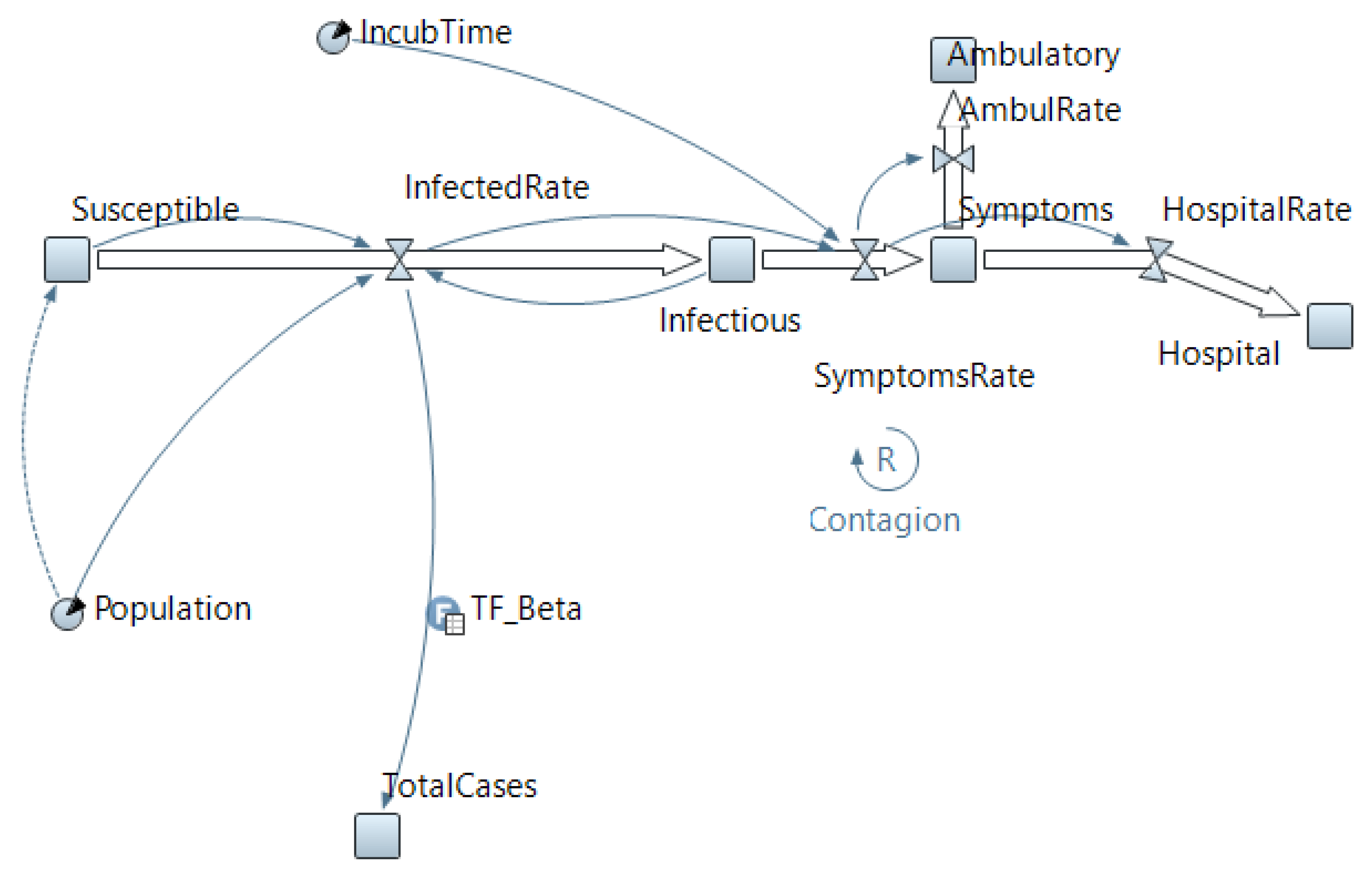
2.1. Developing a System Dynamic Model
- –
- The recovered population do not become susceptible again.
- –
- The symptomatic are immediately isolated and cannot infect the susceptible.
- –
- Population is not affected by birth and death rates.
- –
- The incubation period for all infected individuals is 6 days.
2.2. Data Collection
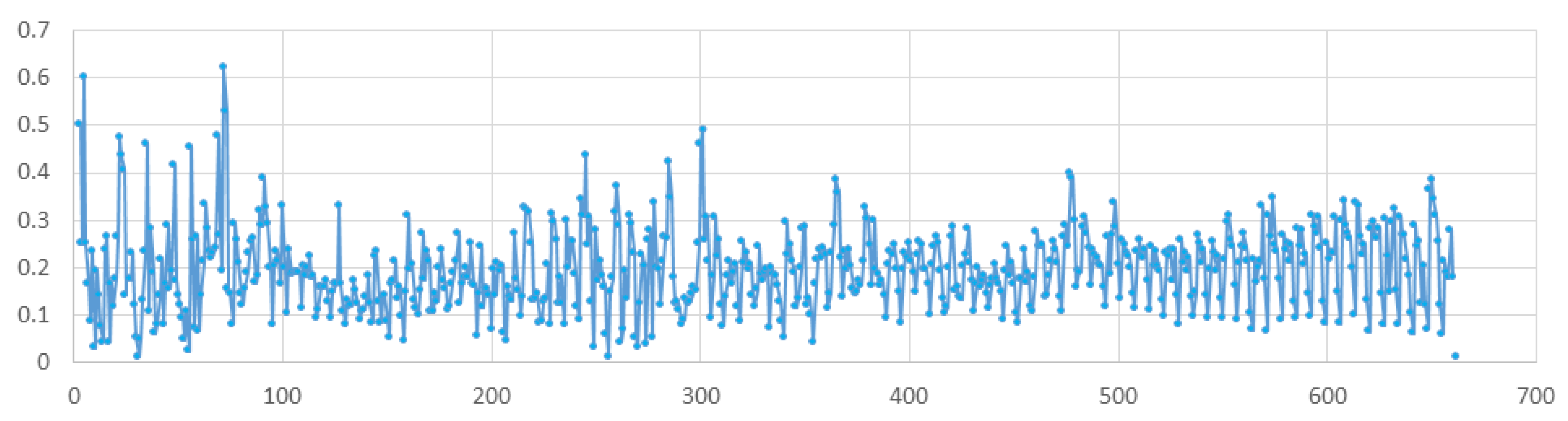
2.3. The Estimation and Prediction Scheme
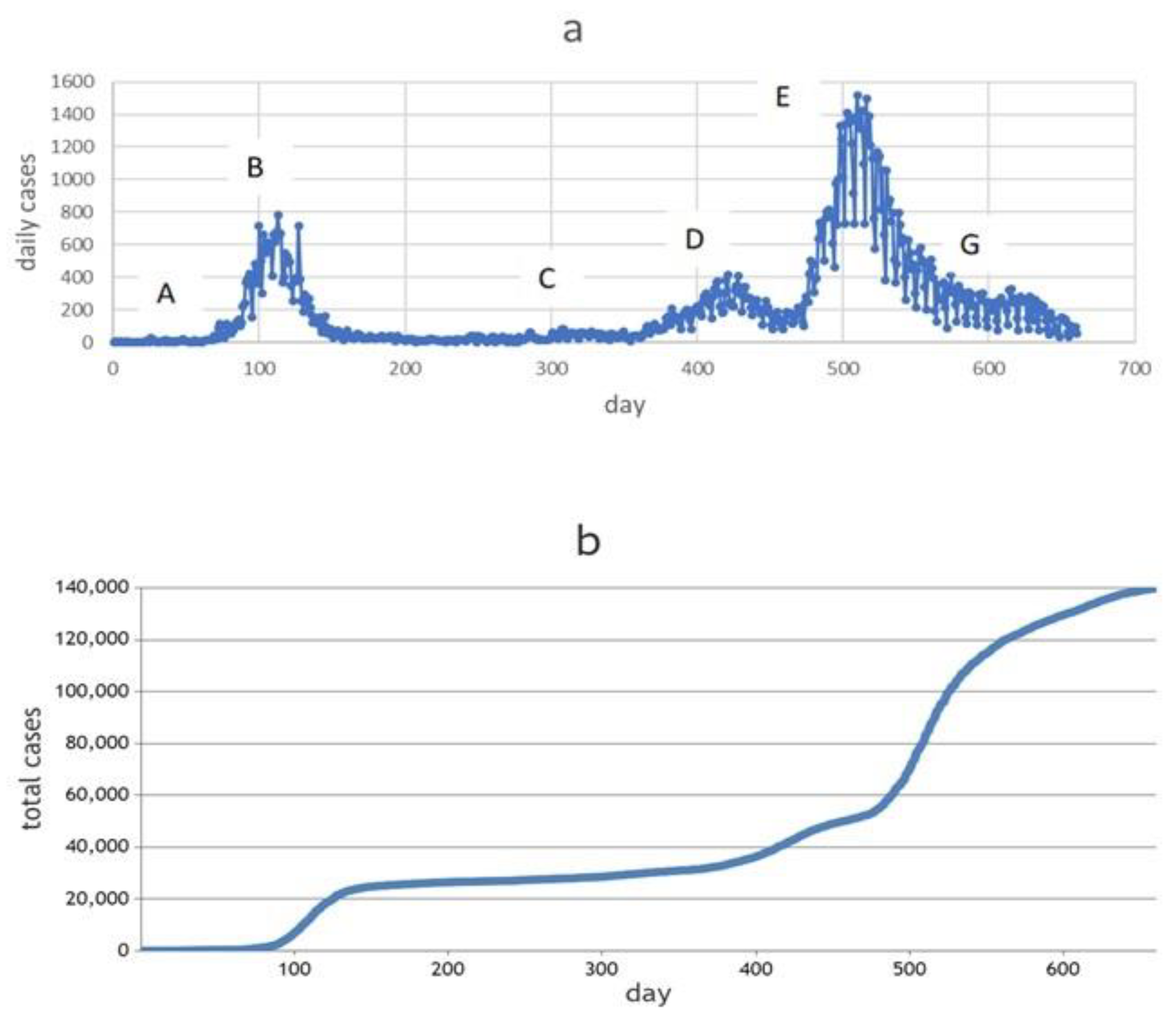
- –
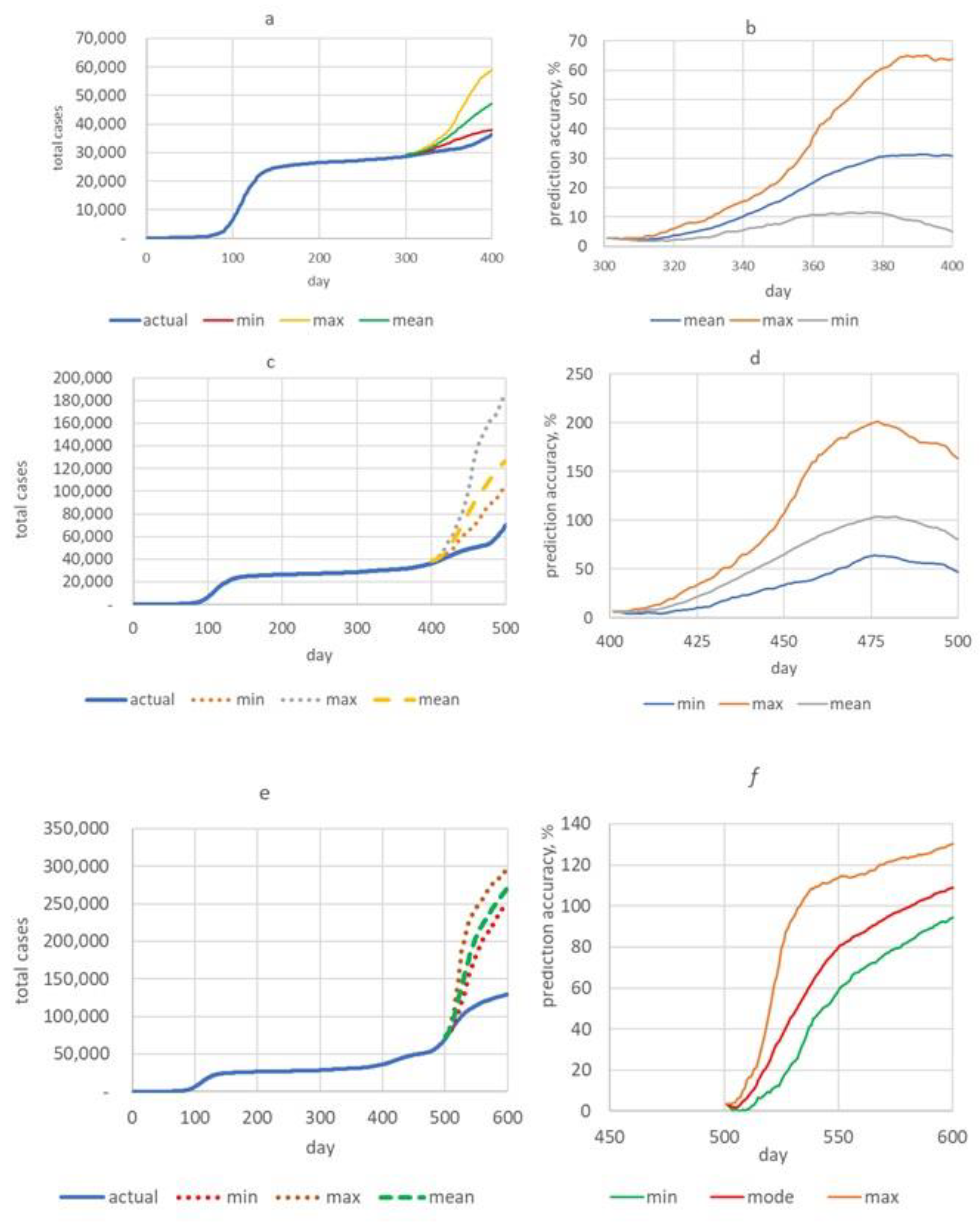
- The first training time frame (AC) included periods of relative stability in daily new cases, as well as periods of rise and fall in incidence. This corresponds to the first 300 days of the pandemic development in Karaganda from 10 March 2020 to 5 January 2021.
- –
- The next training time frame (AD) was 400 days from the first recorded COVID-19 incident in the city (from 10 March 2020 to 15 April 2021, see Figure 2a). This period includes the first wave and the beginning of the second wave from about 361 days.
- –
- The third training time frame (AF) was 500 days, from 10 March 2020 to 24 July 2021. In this period, there were two waves of morbidity and the rise of the third—the most “powerful” wave.
3. Results
4. Discussion
4.1. The Findings and Their Implications
- –
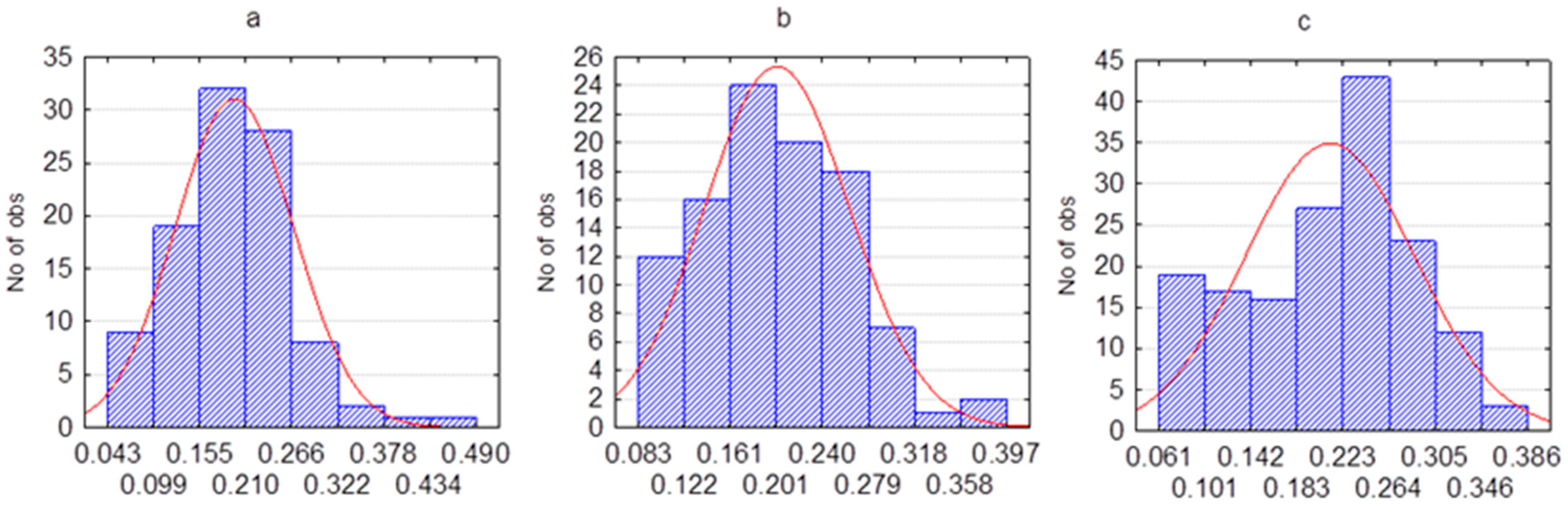
- Estimation of model parameters improved due to the increase in sample size.
- –
- Three scenarios of the development of the situation were proposed—optimistic, pessimistic and most probable—which is especially important for regulators when developing various response measures.
- –
- The duration of forecasting with acceptable accuracy was 100 days, which significantly exceeds some of the literature data [61]. When compared with the information from Table 3, it is obvious that the results obtained by us in terms of the duration and accuracy of the forecast surpass those of the indicated models. The already-mentioned review [9] demonstrates the high prediction accuracy of machine-learning models. However, the duration of forecasting in these works was no more than 14 days. Under the optimistic scenario, the quality of long-term forecasting of our model can be assessed as high and good.
4.2. Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Rahimi, I.; Chen, F.; Gandomi, A.H. A review on COVID-19 forecasting models. Neural Comput. Appl. 2021, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Shakeel, S.M.; Kumar, N.S.; Madalli, P.P.; Srinivasaiah, R.; Swamy, D.R. COVID-19 prediction models: A systematic literature review. Osong Public Health Res. Perspect. 2021, 12, 215–229. [Google Scholar] [CrossRef] [PubMed]
- Gnanvi, J.E.; Salako, K.V.; Kotanmi, G.B.; Glèlè Kakaï, R. On the reliability of predictions on Covid-19 dynamics: A systematic and critical review of modelling techniques. Infect. Dis. Model. 2021, 6, 258–272. [Google Scholar] [CrossRef]
- Vytla, V.; Ramakuri, S.K.; Peddi, A.; Kalyan Srinivas, K.; Nithish Ragav, N. Mathematical models for predicting covid-19 pandemic: A review. J. Phys. Conf. Ser. 2021, 1797, 012009. [Google Scholar] [CrossRef]
- Adiga, A.; Dubhashi, D.; Lewis, B.; Marathe, M.; Venkatramanan, S.; Vullikanti, A. Mathematical models for covid-19 pandemic: A comparative analysis. J. Indian Inst. Sci. 2020, 100, 793–807. [Google Scholar] [CrossRef]
- Gola, A.; Arya, R.K.; Animesh Dugh, R. Review of Forecasting Models for Coronavirus (COVID-19) Pandemic in India during Country-Wise Lockdowns. Epidemiology 2020. [Google Scholar] [CrossRef]
- Shinde, G.R.; Kalamkar, A.B.; Mahalle, P.N.; Dey, N.; Chaki, J.; Hassanien, A.E. Forecasting Models for Coronavirus Disease (COVID-19): A Survey of the State-of-the-Art. SN Comput. Sci. 2020, 1, 197. [Google Scholar] [CrossRef]
- Akdi, Y.; Karamanoğlu, Y.E.; Ünlü, K.D. Identifying the cycles in COVID-19 infection: The case of Turkey. J. Appl. Stat. 2022, 1–13. [Google Scholar] [CrossRef]
- Muhammad, L.J.; Algehyne, E.A.; Usman SSAhmad, A.; Chakraborty, C.; Mohammed, I.A. Supervised Machine Learning Models for Prediction of COVID-19 Infection using Epidemiology Dataset. Comput. Sci. 2021, 2, 11. [Google Scholar] [CrossRef]
- Chumachenko, D.; Meniailov, I.; Bazilevych, K.; Chumachenko, T.; Yakovlev, S. Investigation of Statistical Machine Learning Models for COVID-19 Epidemic Process Simulation: Random Forest, K-Nearest Neighbors, Gradient Boosting. Computation 2022, 10, 86. [Google Scholar] [CrossRef]
- Kaliappan, J.; Srinivasan, K.; Mian Qaisar, S.; Sundararajan, K.; Chang, C.Y. Performance Evaluation of Regression Models for the Prediction of the COVID-19 Reproduction Rate. Front. Public Health. 2021, 9, 729795. [Google Scholar] [CrossRef] [PubMed]
- Yan, L.; Zhang, H.T.; Goncalves, J.; Xiao, Y.; Wang, M.; Guo, Y.; Sun, C.; Tang, X.; Jing, L.; Zhang, M.; et al. An interpretable mortality prediction model for COVID-19 patients. Nat. Mach. Intell. 2020, 2, 283–288. [Google Scholar] [CrossRef]
- Fang, Z.G.; Yang, S.Q.; Lv, C.X.; An, S.Y.; Wu, W. Application of a data-driven XGBoost model for the prediction of COVID-19 in the USA: A time-series study. BMJ Open 2022, 12, e056685. [Google Scholar] [CrossRef] [PubMed]
- Gupta, V. Prediction of COVID-19 Confirmed, Death, and Cured Cases in India Using Random Forest Model. Big Data Min. Anal. 2021, 4, 116–123. [Google Scholar] [CrossRef]
- Galasso, J.; Cao, D.M.; Hochberg, R. A random forest model for forecasting regional COVID-19 cases utilizing reproduction number estimates and demographic data. Chaos Solitons Fractals. 2022, 156, 111779. [Google Scholar] [CrossRef] [PubMed]
- Chharia, A.; Jeevan, G.; Jha, R.A.; Liu, M.; Berman, J.M.; Glorioso, C. Accuracy of Us Cdc Covid-19 Forecasting Models. medRxiv 2022. [Google Scholar] [CrossRef]
- Gerlee, P.; Jöud, A.; Spreco, A.; Timpka, T. Computational models predicting the early development of the COVID-19 pandemic in Sweden: Systematic review, data synthesis, and secondary validation of accuracy. Sci. Rep. 2022, 12, 13256. [Google Scholar] [CrossRef]
- Moein, S.; Nickaeen, N.; Roointan, A.; Borhani, N.; Heidary, Z.; Javanmard, S.H.; Ghaisari, J.; Gheisari, Y. Inefficiency of SIR models in forecasting COVID-19 epidemic: A case study of Isfahan. Sci. Rep. 2021, 11, 4725. [Google Scholar] [CrossRef]
- Eker, S. Validity and usefulness of COVID-19 models. Humanit. Soc. Sci. Commun. 2020, 7, 54. [Google Scholar] [CrossRef]
- Ahmetolan, S.; Bilge, A.H.; Demirci, A.; Peker-Dobie, A.; Ergonul, O. What can we estimate from fatality and infectious case data using the susceptible-infected-removed (Sir) model? A case study of covid-19 pandemic. Front. Med. 2020, 7, 556366. [Google Scholar] [CrossRef]
- Bastos, S.B.; Cajueiro, D.O. Modeling and Forecasting the Early Evolution of the Covid-19 Pandemic in Brazil. Available online: http://arxiv.org/abs/2003.14288 (accessed on 16 January 2023).
- Guirao, A. The Covid-19 outbreak in Spain. A simple dynamics model, some lessons, and a theoretical framework for control response. Infect. Dis. Model. 2020, 5, 652–669. [Google Scholar] [CrossRef]
- Yang, Z.; Zeng, Z.; Wang, K.; Wong, S.S.; Liang, W.; Zanin, M.; Liu, P.; Cao, X.; Gao, Z.; Mai, Z.; et al. Modified SEIR and AI prediction of the epidemics trend of COVID-19 in China under public health interventions. J. Thorac. Dis. 2020, 12, 165–174. [Google Scholar] [CrossRef]
- Salgotra, R.; Gandomi, M.; Gandomi, A.H. Evolutionary modelling of the COVID-19 pandemic in fifteen most affected countries. Chaos Solitons Fractals 2020, 140, 110118. [Google Scholar] [CrossRef]
- Santosh, K.C. Covid-19 prediction models and unexploited data. J. Med. Syst. 2020, 44, 170. [Google Scholar] [CrossRef]
- Parbat, D.; Chakraborty, M. A Python based support vector regression model for prediction of COVID19 cases in India. Chaos Solitons Fractals 2020, 138, 109942. [Google Scholar] [CrossRef]
- Hasan, A.; Putri, E.R.M.; Susanto, H.; Nuraini, N. Data-driven modeling and forecasting of COVID-19 outbreak for public policy making. ISA Trans. 2022, 124, 135–143. [Google Scholar] [CrossRef]
- Chen, L.P. Analysis and prediction of covid-19 data in Taiwan. SSRN J. 2020. [Google Scholar] [CrossRef]
- Zhussupov, B.; Saliev, T.; Sarybayeva, G.; Altynbekov, K.; Tanabayeva, S.; Altynbekov, S.; Tuleshova, G.; Pavalkis, D.; Fakhradiyev, I. Analysis of COVID-19 pandemics in Kazakhstan. J. Res. Health Sci. 2021, 21, e00512. [Google Scholar] [CrossRef] [PubMed]
- Nabirova, D.; Taubayeva, R.; Maratova, A.; Henderson, A.; Nassyrova, S.; Kalkanbayeva, M.; Alaverdyan, S.; Smagul, M.; Levy, S.; Yesmagambetova, A.; et al. Factors associated with an outbreak of COVID-19 in oilfield workers, kazakhstan, 2020. Int. J. Environ. Res. Public Health 2022, 19, 3291. [Google Scholar] [CrossRef] [PubMed]
- Semenova, Y.; Pivina, L.; Khismetova, Z.; Auyezova, A.; Nurbakyt, A.; Kauysheva, A.; Ospanova, D.; Kuziyeva, G.; Kushkarova, A.; Ivankov, A.; et al. Anticipating the need for healthcare resources following the escalation of the covid-19 outbreak in the republic of Kazakhstan. J. Prev. Med. Public Health 2020, 53, 387–396. [Google Scholar] [CrossRef]
- Bektemessov, J. Mathematical model for medium-term Covid-19 forecasts in Kazakhstan. JMMCS 2021, 111, 95–106. [Google Scholar] [CrossRef]
- Rogers, L.C.G.; Williams, D. Diffusions, Markov Processes and Martingales: Volume 1, Foundations, 2nd ed.; John Wiley and Sons Ltd.: Chichester, UK, 1994. [Google Scholar]
- Zhang, Z.; Karniadakis, G. Numerical Methods for Stochastic Partial Differential Equations with White Noise; Springer: Cham, Switzerland, 2017. [Google Scholar]
- Bernal, F.; Acebrón, J.A. A comparison of higher-order weak numerical schemes for stopped stochastic differential equations. Commun. Comput. Phys. 2016, 20, 703–732. [Google Scholar] [CrossRef] [Green Version]
- Biagini, F.; Øksendal, B.; Sulem, A.; Wallner, N. An introduction to white noise theory and Malliavin calculus for fractional Brownian motion. Proc. R. Soc. Lond. Ser. A Math. Phys. Eng. Sci. 2004, 460, 347–372. [Google Scholar] [CrossRef]
- Burdzy, K. Brownian Motion. In Brownian Motion and Its Applications to Mathematical Analysis. Lecture Notes in Mathematics; Springer: Cham, Switzerland, 2014; Volume 2106. [Google Scholar] [CrossRef]
- Hussain, S.; Madi, E.N.; Khan, H.; Etemad, S.; Rezapour, S.; Sitthiwirattham, T.; Patanarapeelert, N. Investigation of the stochastic modeling of covid-19 with environmental noise from the analytical and numerical point of view. Mathematics 2021, 9, 3122. [Google Scholar] [CrossRef]
- Hoertel, N.; Blachier, M.; Blanco, C.; Olfson, M.; Massetti, M.; Limosin, F.; Leleu, H. Facing the COVID-19 Epidemic in NYC: A Stochastic Agent-Based Model of Various Intervention Strategies. medRxiv 2020. [Google Scholar] [CrossRef]
- Porgo, T.V.; Norris, S.L.; Salanti, G.; Johnson, L.F.; Simpson, J.A.; Low, N.; Egger, M.; Althaus, C.L. The use of mathematical modeling studies for evidence synthesis and guideline development: A glossary. Res. Syn. Meth. 2019, 10, 125–133. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Zeb, A.; Hussain, S.; Alzahrani, E. Dynamics of COVID-19 mathematical model with stochastic perturbation. Adv. Differ. Equ. 2020, 2020, 451. [Google Scholar] [CrossRef]
- Niño-Torres, D.; Ríos-Gutiérrez, A.; Arunachalam, V.; Ohajunwa, C.; Seshaiyer, P. Stochastic modeling, analysis, and simulation of the COVID-19 pandemic with explicit behavioral changes in Bogotá: A case study. Infect. Dis. Model. 2022, 7, 199–211. [Google Scholar] [CrossRef]
- Tesfaye, A.W.; Satana, T.S. Stochastic model of the transmission dynamics of COVID-19 pandemic. Adv. Differ. Equ. 2021, 2021, 457. [Google Scholar] [CrossRef]
- Zevika, M.; Triska, A.; Nuraini, N.; Lahodny, G., Jr. On the study of covid-19 transmission using deterministic and stochastic models with vaccination treatment and quarantine. CBMS 2022, 5, 1–19. [Google Scholar] [CrossRef]
- Mohamed, C.; Modeste, N. A stochastic model with jumps for the covid-19 epidemic in the greater abidjan region during public health measures. J. Infect. Dis. Epidemiol. 2021, 7, 196. [Google Scholar] [CrossRef]
- Balsa, C.; Lopes, I.; Guarda, T.; Rufino, J. Computational simulation of the COVID-19 epidemic with the SEIR stochastic model. Comput. Math Organ Theory 2021, 1–19. [Google Scholar] [CrossRef] [PubMed]
- Mishra, B.K. Stochastic models on the transmission of novel COVID-19. Int. J. Syst. Assur. Eng. Manag. 2022, 13, 599–603. [Google Scholar] [CrossRef]
- Ando, S.; Matsuzawa, Y.; Tsurui, H.; Mizutani, T.; Hall, D.; Kuroda, Y. Stochastic modelling of the effects of human-mobility restriction and viral infection characteristics on the spread of COVID-19. Sci. Rep. 2021, 11, 6856. [Google Scholar] [CrossRef] [PubMed]
- Solari, H.G.; Natiello, M.A. Stochastic model for COVID-19 in slums: Interaction between biology and public policies. Epidemiol. Infect. 2021, 149, e206. [Google Scholar] [CrossRef]
- Alenezi, M.N.; Al-Anzi, F.S.; Alabdulrazzaq, H.; Alhusaini, A.; Al-Anzi, A.F. A study on the efficiency of the estimation models of COVID-19. Results Phys. 2021, 26, 104370. [Google Scholar] [CrossRef]
- Gunti Reema, B.; Babu, V.; Praveen, T.; Praveen, S.P. COVID-19 EDA analysis and prediction using SIR and SEIR models. Int. J. Healthc. Manag. 2022, 1–16. [Google Scholar] [CrossRef]
- Roda, W.C.; Varughese, M.B.; Han, D.; Li, M.Y. Why is it difficult to accurately predict the COVID-19 epidemic? Infect. Dis. Model. 2020, 5, 271–281. [Google Scholar] [CrossRef]
- Kermack, W.O.; McKendrick, A.G. A contribution to the mathematical theory of epidemics. Proc. Soc. Lond. A. 1927, 115, 700–721. [Google Scholar] [CrossRef] [Green Version]
- Biggerstaff, M.; Cowling, B.J.; Cucunubá, Z.M.; Dinh, L.; Ferguson, N.M.; Gao, H.; Hill, V.; Imai, N.; Johansson, M.A.; Kada, S.; et al. Early Insights from Statistical and Mathematical Modeling of Key Epidemiologic Parameters of COVID-19. Emerg. Infect. Dis. 2020, 26, e1–e14. [Google Scholar] [CrossRef]
- Gallo, L.G.; Oliveira, A.F.d.M.; Abrahao, A.A.; Sandoval, L.A.M.; Martins, Y.R.A.; Almirón, M.; dos Santos, F.S.G.; Araújo, W.N.; de Oliveira, M.R.F.; Peixoto, H.M. Ten Epidemiological Parameters of COVID-19: Use of Rapid Literature Review to Inform Predictive Models During the Pandemic. Front. Public Health 2020, 8, 598547. [Google Scholar] [CrossRef]
- McAloon, C.; Collins, Á.; Hunt, K.; Barber, A.; Byrne, A.W.; Butler, F.; Casey, M.; Griffin, J.; Lane, E.; McEvoy, D. Incubation period of COVID-19: A rapid systematic review and meta-analysis of observational research. BMJ Open 2020, 10, e039652. [Google Scholar] [CrossRef]
- Cheng, C.; Zhang, D.; Dang, D.; Geng, J.; Zhu, P.; Yuan, M.; Liang, R.; Yang, H.; Jin, Y.; Xie, J.; et al. The incubation period of COVID-19: A global meta-analysis of 53 studies and a Chinese observation study of 11,545 patients. Infect. Dis. Poverty 2021, 10, 119. [Google Scholar] [CrossRef] [PubMed]
- Wu, Y.; Kang, L.; Guo, Z.; Liu, J.; Liu, M.; Liang, W. Incubation Period of COVID-19 Caused by Unique SARS-CoV-2 Strains: A Systematic Review and Meta-analysis. JAMA Netw. Open 2022, 5, e2228008. [Google Scholar] [CrossRef]
- Cortés Martínez, J.; Pak, D.; Abelenda-Alonso, G.; Langohr, K.; Ning, J.; Rombauts, A.; Colom, M.; Shen, Y.; Gómez Melis, G. SARS-CoV-2 incubation period according to vaccination status during the fifth COVID-19 wave in a tertiary-care center in Spain: A cohort study. BMC Infect. Dis. 2022, 22, 828. [Google Scholar] [CrossRef]
- Lewis, C.D. Industrial and Business Forecasting Methods: A Practical Guide to Exponential Smoothing and Curve Fitting; Butterworth-Heinemann: Oxford, UK, 1982. [Google Scholar]
- Wang, Y.; Yan, Z.; Wang, D.; Yang, M.; Li, Z.; Gong, X.; Wu, D.; Zhai, L.; Zhang, W.; Wang, Y. Prediction and analysis of COVID-19 daily new cases and cumulative cases: Times series forecasting and machine learning models. BMC Infect. Dis. 2022, 22, 495. [Google Scholar] [CrossRef] [PubMed]
- Gupta, R.; Pandey, G.; Chaudhary, P.; Pal, S.K. Machine Learning Models for Government to Predict COVID-19 Outbreak. Digit. Gov.: Res. Pract. 2020, 1, 1–6. [Google Scholar] [CrossRef]
- Khan, F.M.; Gupta, R. ARIMA and NAR Based Prediction Model for Time Series Analysis of COVID-19 Cases in India. J. Saf. Sci. Resil. 2020, 1, 12–18. [Google Scholar] [CrossRef]
- Sujath, R.; Chatterjee, J.M.; Hassanien, A.E. A Machine Learning Forecasting Model for COVID-19 Pandemic in India. Stoch Env. Res Risk Assess 2020, 34, 959–972. [Google Scholar] [CrossRef]
- Tiwari, S.; Kumar, S.; Guleria, K. Outbreak Trends of Coronavirus Disease–2019 in India: A Prediction. Disaster Med. Public Health Prep. 2020, 14, e33–e38. [Google Scholar] [CrossRef] [Green Version]
- Tomar, A.; Gupta, N. Prediction for the Spread of COVID-19 in India and Effectiveness of Preventive Measures. Sci. Total Environ. 2020, 728, 138762. [Google Scholar] [CrossRef] [PubMed]
- Salgotra, R.; Gandomi, M.; Gandomi, A.H. Time Series Analysis and Forecast of the COVID-19 Pandemic in India Using Genetic Programming. Chaos Solitons Fractals 2020, 138, 109945. [Google Scholar] [CrossRef]
- Sunori, S.K.; Juneja, P.; Negi, P.B.; Maurya, S.; Raj, P.; Nainwal, D. AI and Machine Learning Based Classification of Air Quality Index Using COVID-19 Lockdown Period Data. In Proceedings of the 2021 2nd International Conference on Smart Electronics and Communication (ICOSEC), Trichy, India, 7–9 October 2021; IEEE: Trichy, India, 2021; pp. 896–904. [Google Scholar]
- Ghosh, M.S. An Overview: Situation Assessment and Prediction of Corona Virus in India. Mukt Shabd J. 2020, IX, 2347–3150. [Google Scholar]
- Mamis, K.; Farazmand, M. Supplementary material from Stochastic compartmental models of COVID-19 pandemic must have temporally correlated uncertainties. Proc. R. Soc. A 2023, 479, 20220568. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
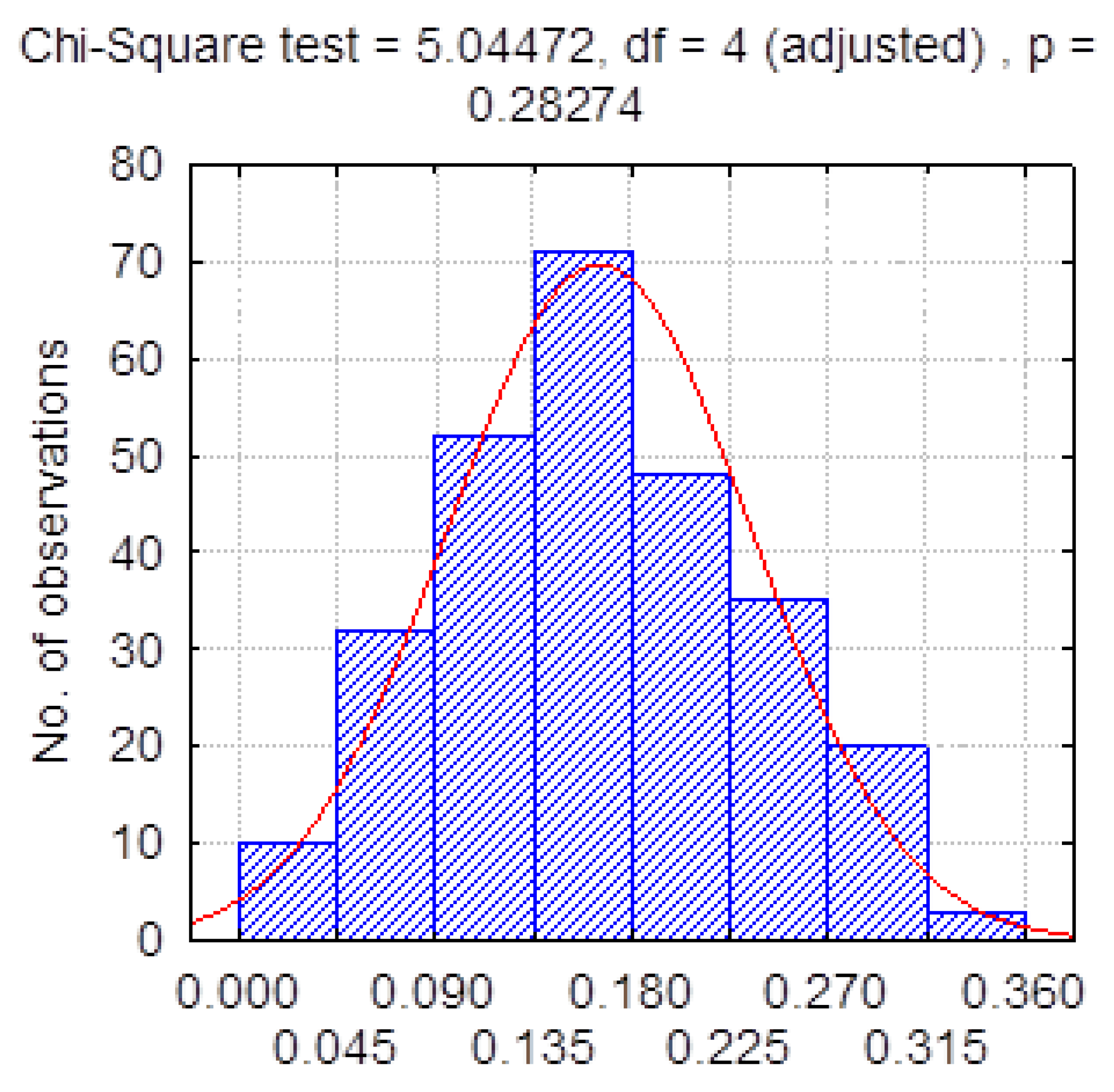
| Training Time Frame, Day | 1–300 | 1–400 | 1–500 |
|---|---|---|---|
| β (mean, SD) | 0.17 (0.075) | 0.177 (0.074) | 0.182 (0.073) |
| MAPE (%) | ||||
|---|---|---|---|---|
| Duration of Forecasting | 25 Days | 50 Days | 75 Days | 100 Days |
| (a) First testing time frame | ||||
| Optimistic scenario | 2.235 | 3.712 | 5.986 | 6.697 |
| Pessimistic scenario | 4.481 | 9.400 | 19.781 | 30.569 |
| Most likely scenario | 3.004 | 6.320 | 11.897 | 16.629 |
| (b) Second testing time frame | ||||
| Optimistic scenario | 6.209 | 14.119 | 25.059 | 33.154 |
| Pessimistic scenario | 16.532 | 40.448 | 83.038 | 108.475 |
| Most likely scenario | 10.405 | 26.836 | 46.881 | 59.193 |
| (c) Third testing time frame | ||||
| Optimistic scenario | 5.648 | 22.237 | 38.360 | 50.641 |
| Pessimistic scenario | 29.947 | 65.941 | 83.094 | 93.817 |
| Most likely scenario | 14.143 | 37.537 | 54.659 | 66.829 |
| S. No. | References | Forecasting Techniques | Duration of Forecasting | MAPE Score |
|---|---|---|---|---|
| 1 | Gupta, R.; et al., 2020 [62] | SEIR and regression models | 20 days | SEIR: 25.533, Regression: 21.889 |
| 2 | Khan, F.M.; Gupta, R., 2020 [63] | ARIMA and NAR | 50 days | ARIMA: 362.1761 |
| 3 | Sujath, R.; et al., 2020 [64] | LR, MLP and VAR | 69 days | LR: 1745454.432, MLP: 80.057, VAR: 43289.290 |
| 4 | Tiwari, S.; et al., 2020 [65] | Time series forecasting using Weka | 24 days | 55.489 |
| 5 | Tomar, A.; Gupta, N., 2020 [66] | LSTM | 25 days | 63.357 |
| 6 | Salgotra, R.; et al., 2020 [67] | Genetic programming-based model (GP) (GEP model) | 10 days | 7.827 |
| 7 | Sunori, S.K.; et al., 2021 [68] | Exponential growth model and ML-based LR model | 33 days | LR: 662.441, Exponential: 2096.000 |
| 8 | Mr. Sudip Ghosh, 2020 [69] | Least square fit- ted model | 35 days | 39.816 |
| Time Frame, Day | 300–400 | 400–500 | 500–600 | |
|---|---|---|---|---|
| Actual data | β (mean, SD) | 0.195 (0.071) | 0.200 (0.061) | 0.204 (0.065) |
| Model data | β (mean, SD) | 0.17 (0.075) | 0.177 (0.074) | 0.182 (0.073) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Koichubekov, B.; Takuadina, A.; Korshukov, I.; Turmukhambetova, A.; Sorokina, M. Is It Possible to Predict COVID-19? Stochastic System Dynamic Model of Infection Spread in Kazakhstan. Healthcare 2023, 11, 752. https://doi.org/10.3390/healthcare11050752
Koichubekov B, Takuadina A, Korshukov I, Turmukhambetova A, Sorokina M. Is It Possible to Predict COVID-19? Stochastic System Dynamic Model of Infection Spread in Kazakhstan. Healthcare. 2023; 11(5):752. https://doi.org/10.3390/healthcare11050752
Chicago/Turabian StyleKoichubekov, Berik, Aliya Takuadina, Ilya Korshukov, Anar Turmukhambetova, and Marina Sorokina. 2023. "Is It Possible to Predict COVID-19? Stochastic System Dynamic Model of Infection Spread in Kazakhstan" Healthcare 11, no. 5: 752. https://doi.org/10.3390/healthcare11050752