
Survival Analysis of Oncological Patients Using Machine Learning Method

Abstract
:1. Introduction
1.1. Theoretical Analysis
1.2. Related Works
- “Deep learning-based breast cancer grading and survival analysis on whole-slide histopathology images”.
- 2.
- “Fast training of support vector machines for survival analysis”.
- 3.
- “Prediction of survival and metastasis in breast cancer patients using machine learning classifiers”.
- 4.
- “Convolutional Neural Networks and Support Vector Machines for Five-Year Survival Analysis of Metastatic Rectal Cancer”.
- 5.
- “Prognostic Nomograms for Predicting Overall Survival and Cancer-Specific Survival in Patients with Head and Neck Mucosal Melanoma”.
1.3. Important Notes on Previous Studies
- The previous studies focus on deep learning-based breast cancer grading and survival analysis by whole-slide histopathology pictures and focus on three different linear survival support vector machine training algorithms.
- The previous studies developed and verified a reliable predictive nomogram for HMM, built the model, and demonstrated the SVM performed better than other machine learning techniques in predicting the patient’s survival.
1.4. The Current Study Differs from Previous Studies
- The data come from medical records and hospital records.
- The data mining (DM) technique was used to predict trends or describe characteristics of the past. DM methods can include classification, generalisation, characterisation, clustering, association, evolution, pattern discovery, data visualisation, and rule-guided mining techniques.
- The database of patients treated by the Baghdad Teaching Hospital between 2018 and 2021 was examined using a classification of the most crucial variables for event prediction.
- The current study uses machine learning techniques for a global assessment of the data that is available and produces results that can be interpreted as significant information for epidemiological studies.
2. Materials and Methods
2.1. Data Analysis
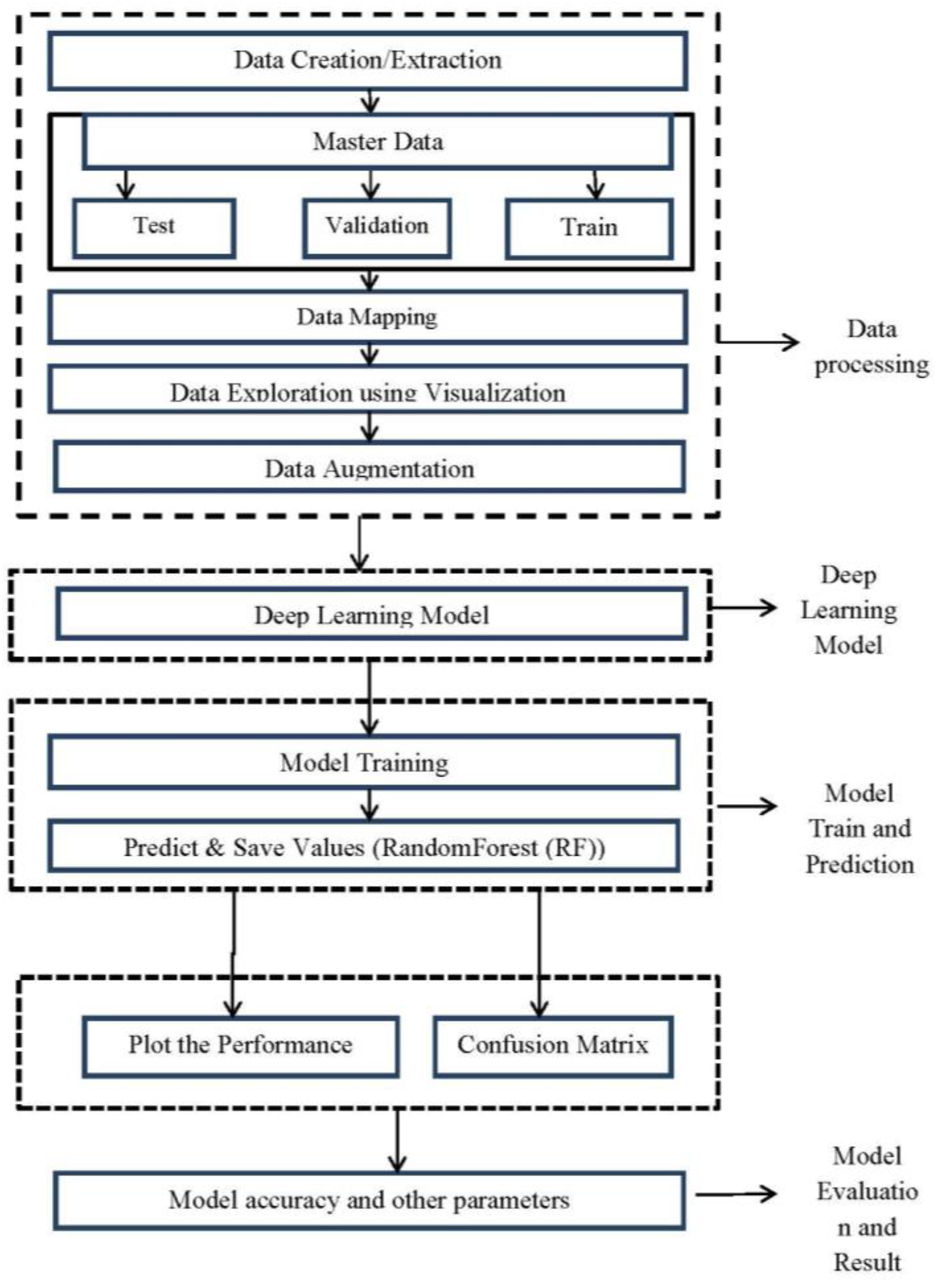
2.2. Survival Analysis Using Machine Learning Algorithms
2.3. Methodology
2.4. Ethical Aspects
3. Results and Discussion
3.1. Prediction Model Error Rate
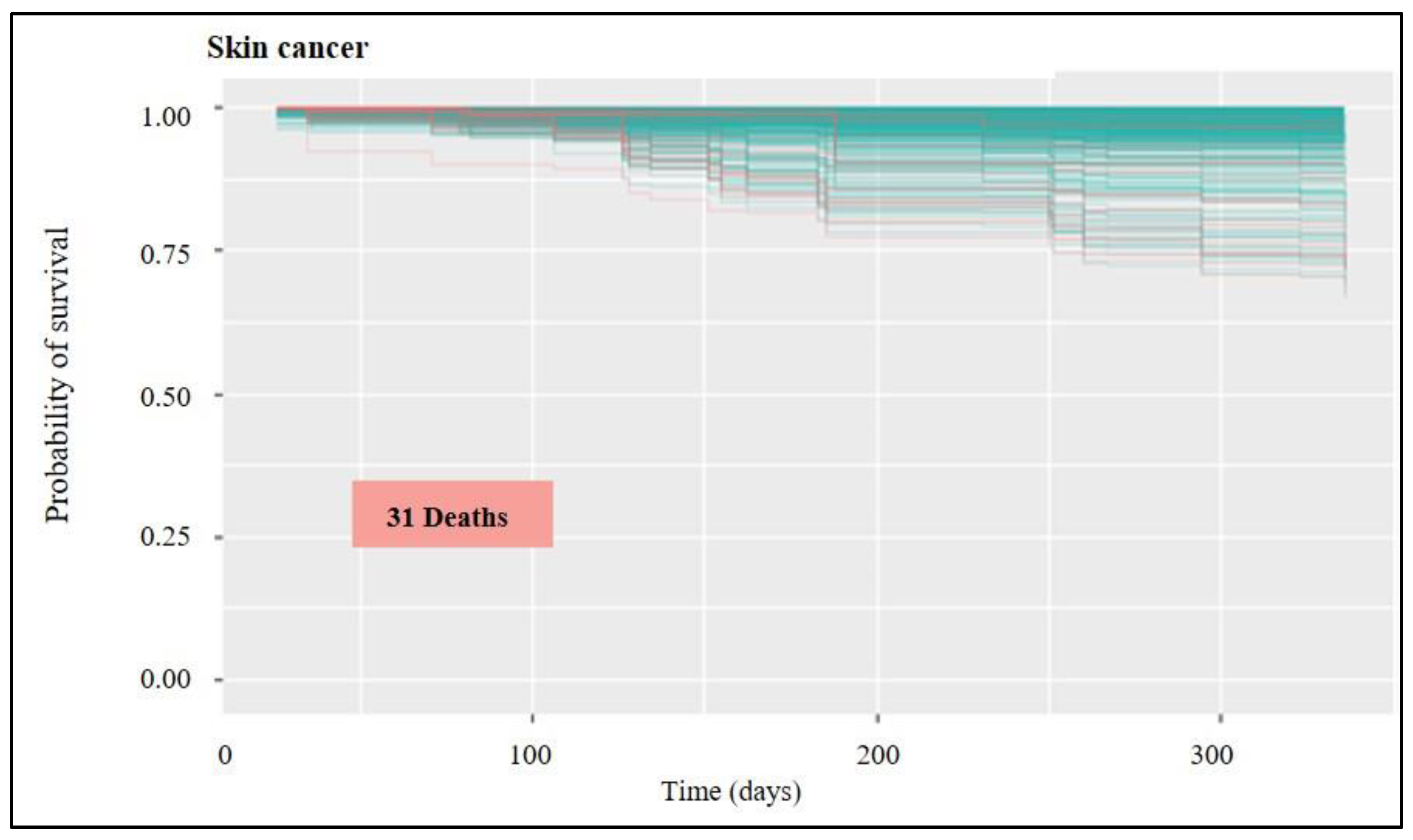
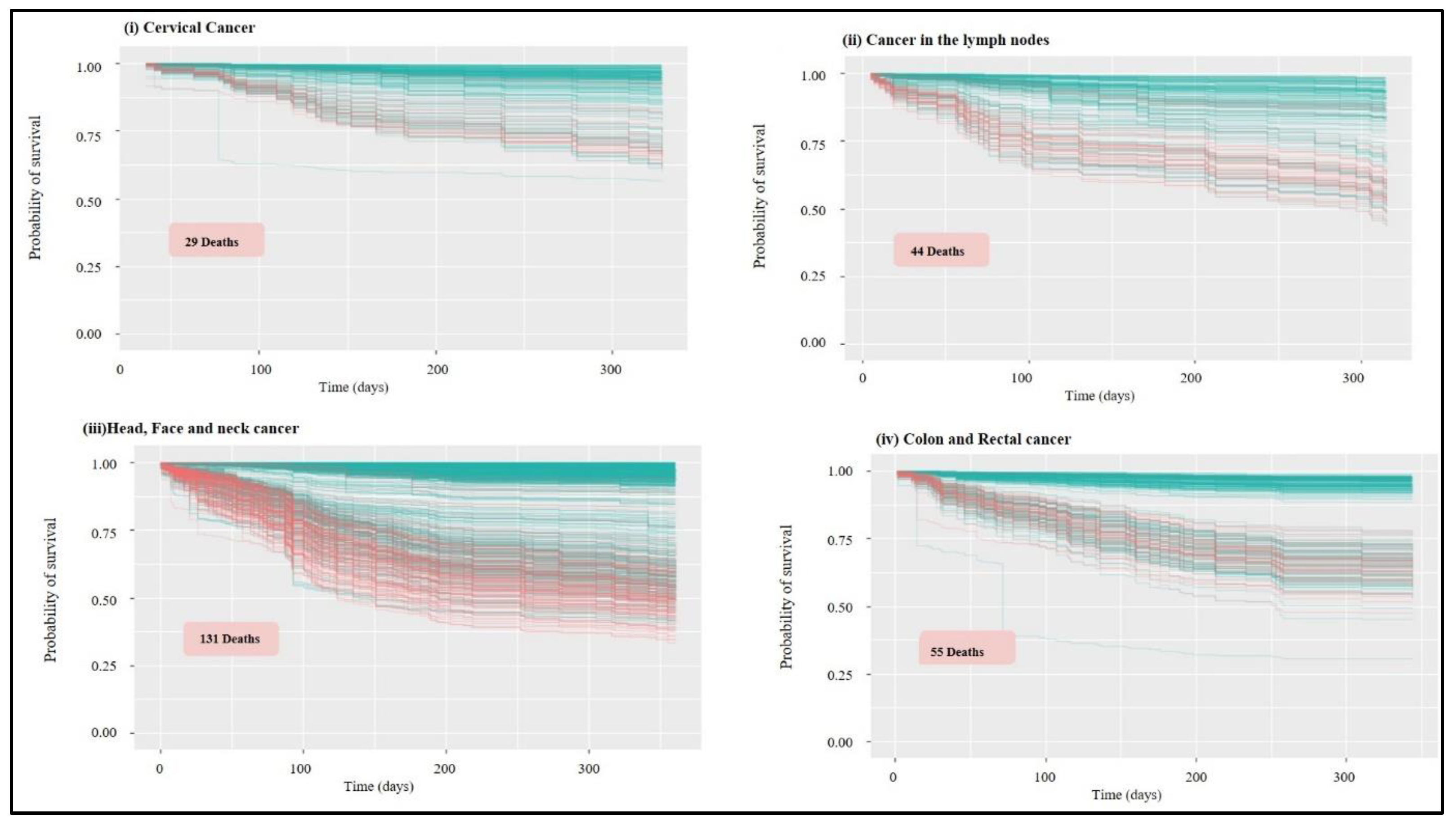
3.2. Analysis of Survival and Classification of Variables
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Baba, A.I.; Câtoi, C. Comparative Oncology; Publishing House of the Romanian Academy: Bucharest, Romania, 2007. [Google Scholar]
- Pavlopoulou, A.; Spandidos, D.A.; Michalopoulos, I. Human cancer databases (Review). Oncol. Rep. 2014, 33, 3–18. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Abdullah, O.S.; Amin, A.; Mohamed, Z.A.; Hasan, B.; Shekha, M.; Najmuldeen, H.H.; Rahman, F.M.; Housein, Z.; Salih, A.M.; Mohammed, A.S.; et al. Cancer Incidence in the Kurdistan Region of Iraq: Results of a Seven-Year Cancer Registration in Erbil and Duhok Governorates. Asian Pac. J. Cancer Prev. 2022, 23, 601–615. [Google Scholar] [CrossRef]
- Goel, M.K.; Khanna, P.; Kishore, J. Understanding survival analysis: Kaplan-Meier estimate. Int. J. Ayurveda Res. 2010, 1, 274–278. [Google Scholar] [CrossRef] [Green Version]
- Abood, R.A.; Abdahmed, K.A.; Mazyed, S.S. Epidemiology of different types of cancers reported in Basra, Iraq. Sultan Qaboos Univ. Med. J. 2020, 20, e295. [Google Scholar] [CrossRef] [PubMed]
- Ong, C.S. Knowledge discovery in databases: An information retrieval perspective. Malays. J. Comput. Sci. 2000, 13, 54–63. [Google Scholar]
- Fayyad, U.; Piatetsky-Shapiro, G.; Smyth, P. From data mining to knowledge discovery in databases. AI Mag. 1996, 17, 37. [Google Scholar]
- Tripathi, R.C. An analysis of data mining applications. Asian J. Multidimens. Res. 2021, 10, 297–303. [Google Scholar] [CrossRef]
- Islam, S.; Hasan, M.; Wang, X.; Germack, H.D.; Alam, N.E. A Systematic Review on Healthcare Analytics: Application and Theoretical Perspective of Data Mining. Healthcare 2018, 6, 54. [Google Scholar] [CrossRef] [Green Version]
- Jarada, T.N.; Rokne, J.G.; Alhajj, R. A review of computational drug repositioning: Strategies, approaches, opportunities, challenges, and directions. J. Cheminform. 2020, 12, 1–23. [Google Scholar] [CrossRef]
- Fawagreh, K.; Gaber, M.M.; Elyan, E. Random forests: From early developments to recent advancements. Syst. Sci. Control Eng. Open Access J. 2014, 2, 602–609. [Google Scholar] [CrossRef] [Green Version]
- Mogensen, U.B.; Ishwaran, H.; Gerds, T.A. Evaluating random forests for survival analysis using prediction error curves. J. Stat. Softw. 2012, 50, 1. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hamidi, O.; Poorolajal, J.; Farhadian, M.; Tapak, L. Identifying Important Risk Factors for Survival in Kidney Graft Failure Patients Using Random Survival Forests. Iran. J. Public Health 2016, 45, 27. [Google Scholar] [PubMed]
- Ishwaran, H.; Lauer, M.S.; Blackstone, E.H.; Lu, M.; Kogalur, U.B. Randomforestsrc: Random survival forests vignette. Random Forest SRC 2022, 15. [Google Scholar] [CrossRef]
- Schober, P.; Vetter, T.R. Survival analysis and interpretation of time-to-event data: The tortoise and the hare. Anesth. Analg. 2018, 127, 792. [Google Scholar] [CrossRef]
- Wetstein, S.C.; de Jong, V.M.T.; Stathonikos, N.; Opdam, M.; Dackus, G.M.; Pluim, J.P.; van Diest, P.J.; Veta, M. Deep learn-ing-based breast cancer grading and survival analysis on whole-slide histopathology images. Sci. Rep. 2022, 12, 15102. [Google Scholar] [CrossRef] [PubMed]
- Pölsterl, S.; Navab, N.; Katouzian, A. Fast training of support vector machines for survival analysis. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Porto, Portugal, 7–11 September 2015; Springer: Cham, Switzerland; pp. 243–259. [Google Scholar] [CrossRef]
- Tapak, L.; Shirmohammadi-Khorram, N.; Amini, P.; Alafchi, B.; Hamidi, O.; Poorolajal, J. Prediction of survival and metastasis in breast cancer patients using machine learning classifiers. Clin. Epidemiol. Glob. Health 2019, 7, 293–299. [Google Scholar] [CrossRef] [Green Version]
- Suliman, W.; Ravi, V.; Luo, B.; Sun, X.F.; Pham, T.D. Convolutional Neural Networks and Support Vector Machines for Five-Year Survival Analysis of Metastatic Rectal Cancer. In Proceedings of the 2022 International Joint Conference on Neural Networks (IJCNN), Padua, Italy, 18–23 July 2022; pp. 1–8. [Google Scholar] [CrossRef]
- Lu, Z.; Zhou, Y.; Nie, G.; Miao, B.; Lu, Y.; Chen, T. Prognostic Nomograms for Predicting Overall Survival and Cancer-Specific Survival in Patients with Head and Neck Mucosal Melanoma. Int. J. Gen. Med. 2022, 15, 2759. [Google Scholar] [CrossRef] [PubMed]
- DiSantostefano, J. International classification of diseases 10th revision (ICD-10). J. Nurse Pract. 2009, 5, 56–57. [Google Scholar] [CrossRef]
- Assel, M.; Sjoberg, D.D.; Vickers, A.J. The Brier score does not evaluate the clinical utility of diagnostic tests or prediction models. Diagn. Progn. Res. 2017, 1, 19. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Donald, A.R.; Daniel, A.B.; David, H.H. Assessing predictive accuracy: How to compare brier scores. J. Clin. Epidemiol. 1991, 44, 1141–1146. [Google Scholar] [CrossRef]
- Rustam, F.; Reshi, A.A.; Ashraf, I.; Mehmood, A.; Ullah, S.; Khan, D.M.; Choi, G.S. Sensor-based human activity recognition using deep stacked multilayered perceptron model. IEEE Access 2020, 8, 218898–218910. [Google Scholar] [CrossRef]
- Liono, J.; Abdallah, Z.S.; Qin, A.K.; Salim, F.D. Inferring transportation mode and human activity from mobile sensing in daily life. In Proceedings of the 15th EAI International Conference on Mobile and Ubiquitous Systems: Computing, Networking and Services, New York, NY, USA, 5–7 November 2018; pp. 342–351. [Google Scholar] [CrossRef] [Green Version]
- Steele, A.J.; Denaxas, S.C.; Shah, A.D.; Hemingway, H.; Luscombe, N.M. Machine learning models in electronic health records can outperform conventional survival models for predicting patient mortality in coronary artery disease. PLoS ONE 2018, 13, e0202344. [Google Scholar] [CrossRef] [Green Version]
- Zhao, J.; Henriksson, A.; Asker, L.; Boström, H. Predictive modeling of structured electronic health records for adverse drug event detection. BMC Med. Inform. Decis. Mak. 2015, 15, S1. [Google Scholar] [CrossRef] [Green Version]
- Akritas, M.G.; Lahiri, S.; Politis, D.N. Topics in Nonparametric Statistics; Springer: New York, NY, USA, 2016. [Google Scholar] [CrossRef] [Green Version]
- Hu, C.; Steingrimsson, J.A. Personalized risk prediction in clinical oncology research: Applications and practical issues using survival trees and random forests. J. Biopharm. Stat. 2018, 28, 333–349. [Google Scholar] [CrossRef] [PubMed]
- Van Abbema, D.; Vissers, P.; de Vos-Geelen, J.; Lemmens, V.; Janssen-Heijnen, M.; Tjan-Heijnen, V. Trends in overall survival and treatment patterns in two large population-based cohorts of patients with breast and colorectal cancer. Cancers 2019, 11, 1239. [Google Scholar] [CrossRef] [PubMed]
- Alwan, N. Iraqi initiative of a regional comparative breast cancer research project in the Middle East. J. Cancer Biol. Res. 2014, 2, 1016. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cancer Location | Dataset Type (Grade Based) | Error Rate | Brier Score | No of Samples (Human) |
|---|---|---|---|---|
| Head, face, and neck | Different dataset/simple dataset with class column | 0.1189 | 0.1 | 855 |
| colon and rectum | Different dataset | 0.1869 | 0.1 | 321 |
| Cervix | Classes are already define in dataset | 0.1531 | 0.09 | 233 |
| Stomach | Simple dataset | 0.2672 | 0.15 | 253 |
| Liver | Simple dataset | 0.65 | 0.26 | 59 |
| lymph nodes | Multi column simple dataset with classes defined | 0.1648 | 0.15 | 207 |
| mama | Same dataset | 0.1014 | 0.09 | 981 |
| pancreas | Different Dataset | 0.5986 | 0.25 | 53 |
| Skin | Complex Dataset | 0.0711 | 0.01 | 2038 |
| Prostate | Complex Dataset | 0.1084 | 0.05 | 629 |
| Lung | Simple Dataset | 0.3035 | 0.19 | 248 |
| Total = 5877 | ||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fryan, L.H.A.; Alazzam, M.B. Survival Analysis of Oncological Patients Using Machine Learning Method. Healthcare 2023, 11, 80. https://doi.org/10.3390/healthcare11010080
Fryan LHA, Alazzam MB. Survival Analysis of Oncological Patients Using Machine Learning Method. Healthcare. 2023; 11(1):80. https://doi.org/10.3390/healthcare11010080
Chicago/Turabian StyleFryan, Latefa Hamad Al, and Malik Bader Alazzam. 2023. "Survival Analysis of Oncological Patients Using Machine Learning Method" Healthcare 11, no. 1: 80. https://doi.org/10.3390/healthcare11010080