1. Introduction
Many people want to remain at home as they get older, especially those with disabilities. However, home healthcare services are becoming increasingly sophisticated and intensive. People with disabilities, chronic diseases, and functional impairments need additional services and support to maintain their independence. When it comes to fulfilling the needs and demands of these populations, home health organizations and other service providers are investigating new models of treatment and payment, as well as the optimum use of their workforce. It is important to consider where home healthcare fits into the wider healthcare system in light of these issues and possibilities. Individuals appreciate the benefits of receiving healthcare at home, and well-managed home healthcare can encourage healthy living and well-being [
1].
Home healthcare agencies (HHCAs) are a network of treatment delivered to individuals in their residences by professional staff under the supervision of medical physicians. The Medicare rules are perceived as the standard treatment for all interactions between HHCAs, even if an individual is not insured by Medicare [
2]. The star ratings in Medicare are utilized to measure the quality of the service HHCAs provide. According to the Centers for Medicare and Medicaid Services (CMS), over 5.26 million aged and impaired persons were cared for by 10,519 HHCAs throughout the USA in 2019 [
3]. HHCAs are the most rapidly rising expenditure in the Medicaid beneficiaries due to the elderly population, a higher number of chronic illnesses, and increased hospital fees [
4].
The high quality of services provided by HHCAs is an essential component for patients in order to improve the provided services. In Medicare, star ratings are of significance and are valuable to analyze the performance of quality services regarding the HHCA. It was proposed in July 2015 by CMS and named Quality of Patient Care star ratings (QoPCsr) with a range of 1–5; “1” means an awful experience about service, and “5” means the consumer is delighted about the system [
5]. They implemented star ratings as a significant criterion for customers to consider when choosing a home care professional.
The world of HHCAs varies from clinics and other agencies, whereby nurses are employed. For this instance, home healthcare workers operate independently in the field with support services provided by a head office. The nurse–practitioner working partnership has considerably less physician communication, and the surgeon relies on the nurse to render decisions and communicate observations to a larger extent [
6]. This high degree of patient control in the home environment and the minimal supervision of informal careers by skilled physicians motivated us to conduct research in HHCAs and uncover the influential features using the star ratings.
Another characteristic of HHCAs is that physicians deliver services in a special environment for everyone. There could be situational factors that pose costs for patients that the health professional cannot remove [
7]. Hospitals should have offices for environmental protection to control air pollution, and engineers should guarantee that the staircase height is secure. Home care professionals are unlikely to be trained or have the means to identify and improve patient welfare threats at home. It is essential to determine all the factors for HHCAs with the star ratings to enhance their quality service and increase their revenue as well. Moreover, the influential factors are also helpful in satisfying the customer by providing better services in the Medicare environment.
Influential features are one the best ways to obtain favorable results from unstructured data. The identification of novel features concisely improves the measuring evaluators in the quantitative study. The study of HHCAs enables us to establish an effective framework by utilizing data mining techniques for exploring the best house healthcare facilities, as there is a need to declare an ML model that provides promising outcomes.
Numerous healthcare professionals at home wondered why they have poor star ratings considering comparable facilities and services. The poor satisfaction rate suggests that patients are reduced to home health services, significantly affecting the healthcare provider’s income over time. Home practitioners’ reputation could also be involved in the poor star ratings. Combined with this, it is challenging to continuously examine enormous amounts of data while discovering complex and dynamic characteristics that are likely to occur, but are obscure to humans [
8]. The rising digitization of healthcare and the advancement in ubiquitous computing technology has hastened the development of prediction models for deriving knowledge from patient feedback for home care services. The retrieved knowledge could potentially be valuable to various user groups within the healthcare industry, ranging from patients to their respective healthcare practitioners [
9].
Therefore, examining Medicare’s star ratings of HHCAs’ data is a need, and the use of artificial intelligence (AI) in gaining insights from these data will help in establishing an effective framework for evaluating the finest home healthcare facilities. Artificial intelligence, known as machine learning, or ML, can be defined as the application of a number of different statistical methods that can be used to produce predictions and decisions based on similarities between what is currently being examined and what is being identified in the past. To fill this gap, we propose an automated ML-based method for gaining insights from the OASIS and Medicaid claim datasets. The utilized approach will yield the influential factors that are highly dependent on the star ratings. A publicly available home healthcare agencies (HHCAs) dataset [
10] is utilized to conduct the experimental phase using the different machine learning (ML) techniques. The research aims to gain valuable insights from an unstructured form of HHCAs’ data. The unstructured data are firstly converged into a meaningful form so that machines can easily interpret the data. Then, various statistical techniques are brought into action to find the influential characteristics of the data. In this study, we employ binary and multi-class classification on four renowned machine learning algorithms. In addition, diving deeply into the study, the variable significance for each factor is computed to evaluate each feature’s participation in the HHCAs’ predictive model building. Healthcare-related data are frequently vast and challenging for individuals to swiftly evaluate and interpret. In order to identify and predict different ailments effectively, ML-based models have demonstrated promising outcomes in all medical domains [
11]. Analyzing the HHCAs’ data using data mining techniques along with ML approaches can assist in the creation of a framework for accurately identifying the best home healthcare facilities. A blend of statistical along with ML techniques is used to construct an automated predictive framework for extracting knowledge from patient input.
To emphasize the significance of our work, the following are the contributions that this study makes:
Binary class and multi-class classification are applied by using four renowned ML models built to justify the robust model for HHCAs’ data.
Computing variable significance score for each attribute to analyze the contribution of each indicator in predictive analysis.
For experimentation, unstructured data are considered, and statistical techniques are applied to uncover the outperforming indicators.
Twelve effective attributes are proposed in this research, which can help in finding the best HHCA. We are the first to explore these features from HHCAs’ data.
The rest of the study is structured as follows:
Section 2 covers the literature review, where studies are considered regarding the role of ML in Medicare and the implication of Deep Learning in Medicare. In
Section 3, the proposed methodology is discussed along with the proposed framework and a brief description of the data. In
Section 4, experiments are performed, and the findings are analyzed in the Results Section. Finally,
Section 5 and
Section 6 illustrate the conclusion and future work of the study, respectively.
2. Related Work
The way doctors and health givers think about disease and treatment has significantly evolved to reflect the changes that have taken place in our patients, our healthcare system, and medical science. The complexity level now present in medicine is beyond the capabilities of the human mind [
12]. As a result, the healthcare industry has made substantial use of computer algorithms, which can learn from human decisions [
13]. Health information technologies (HITs) have been widely regarded as critical for enhancing the quality of healthcare organizations [
14,
15,
16]. Driven by the significant gains of these technological innovations, whether in clinical or IT fields, the governmental agencies in Europe and America have committed large financial resources to advance HITs’ adoption in the healthcare sector [
17,
18].
Data analysis tools evaluate various data types and run relevant analyses to gain insights from data records. This is essential when it comes to translating raw patient data into useful information, which can be used to support the decision-making in healthcare organizations [
19,
20]. Delen [
21] proposed a simple classification of analytics that distinguishes three types of analytics: descriptive, predictive, and prescriptive, each defined by the data type and the objective of the study. In the context of predictive analytics, it is possible to predict a particular variable’s future by utilizing probabilistic modeling [
22]. With predictive analytics, developers can access flexible and active predictive models for predictions for the future that identify causalities, trends, and hidden correlations between the input and target output. It is not hard to see how predictive analytics can be used in the healthcare industry to help healthcare providers understand the complexities of clinical cost, find the most effective treatment options, and anticipate future healthcare trend lines relying on the habits, lifestyles, and diseases of their patients [
23]. Natural language processing (NLP) and Data Mining are mostly applied in predictive-analytics-based approaches [
24,
25].
Various researchers have studied the impact of important factors using ML techniques in prior studies. Most of the studies provide the solution for binary classification and regression analysis in the medical domain. Some important research to find the influential parameters using the ML methods are discussed here.
The start was to develop and verify a patient registration system for health promotion that allows patients to be classified according to their skilled nursing needs [
26]. Nursing theory and experience were combined to create the Community Health Intensity Rating Scale (CHIRS). Groups of public health nursing experts created model definitions for fifteen public health criteria, and they used both patient attributes and essential measures of treatment as descriptive words of nursing care standards. The method was then put through its paces with the help of three home health agency support nurses. A cumulative rating of 560 graphs by two home health organizations was used to validate the system.
Prediction analytics and AI in healthcare face a number of obstacles, including data access, standardization, engagement, computing resource requirements, and the implementation of predictive models [
27]. In addition, big data analysis has its own set of issues to deal with [
17,
28]. It has become increasingly important to explore the use of high-speed cloud computing for both data storage and maintenance, as well as for business intelligence, due to the recent growth of big data in medicine and the advancement of cloud computing [
29]. Nevertheless, the analogies between cloud and non-cloud storage and maintenance of massive data are complex. Big data analysis, on the other hand, necessitates high-performance parallel distributed computing algorithms. Data science, bioinformatics, statistical genomics, and other fields have all attempted to address this issue. In addition to the aforementioned medical images and genomic data, these apps also allow for the study of organized data [
29,
30].
Moreover, rating quality was examined and how confidential rates react to the introduction of a five star rating system for nursing homes [
31]. According to their findings, the difference in price among top and bottom facilities grows because of star ratings. The highest-level facility’s prices rose by 4.7 to 6.1% higher than the lowest-level premises’ prices in total. They see more fantastic pricing effects in less mature industries, where buyers can choose from a broader range of nursing homes. The findings show that customers are more receptive to quality reporting where the interface is streamlined and the audiences are less fragmented.
During the literature review, it was noted that there was no similar research on the star rating of reviews using Medicare data with the exception of one paper [
32], where the research was conducted on review ratings, but in the context of patient outcomes and not on the influential factors. Therefore, the research being conducted in this paper is entirely novel in that sense. Many research papers identified the influential factors in other areas apart from the review ratings. Conceptually similar papers were selected for the literature review, and the findings are presented in this paper. The association between the Centres for Medicare and Medicaid Services Hospital Star Rating and Patient Outcomes was researched, which is somewhat related to the current study in terms of star ratings and Medicare providers [
32]; however, this research is novel in the sense that it focuses just on the home healthcare rating and influential factors driving the rating.
5. Discussion and Conclusions
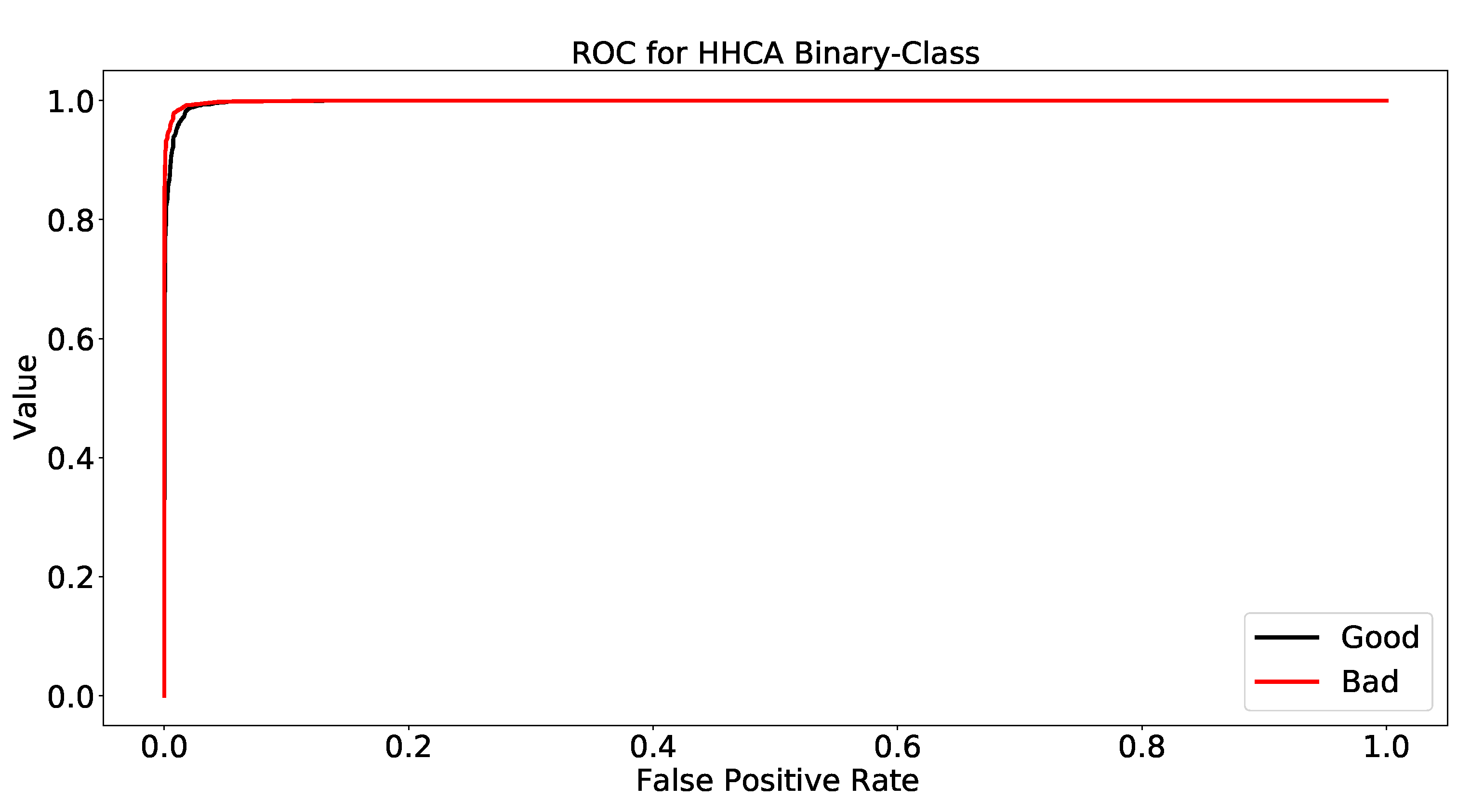
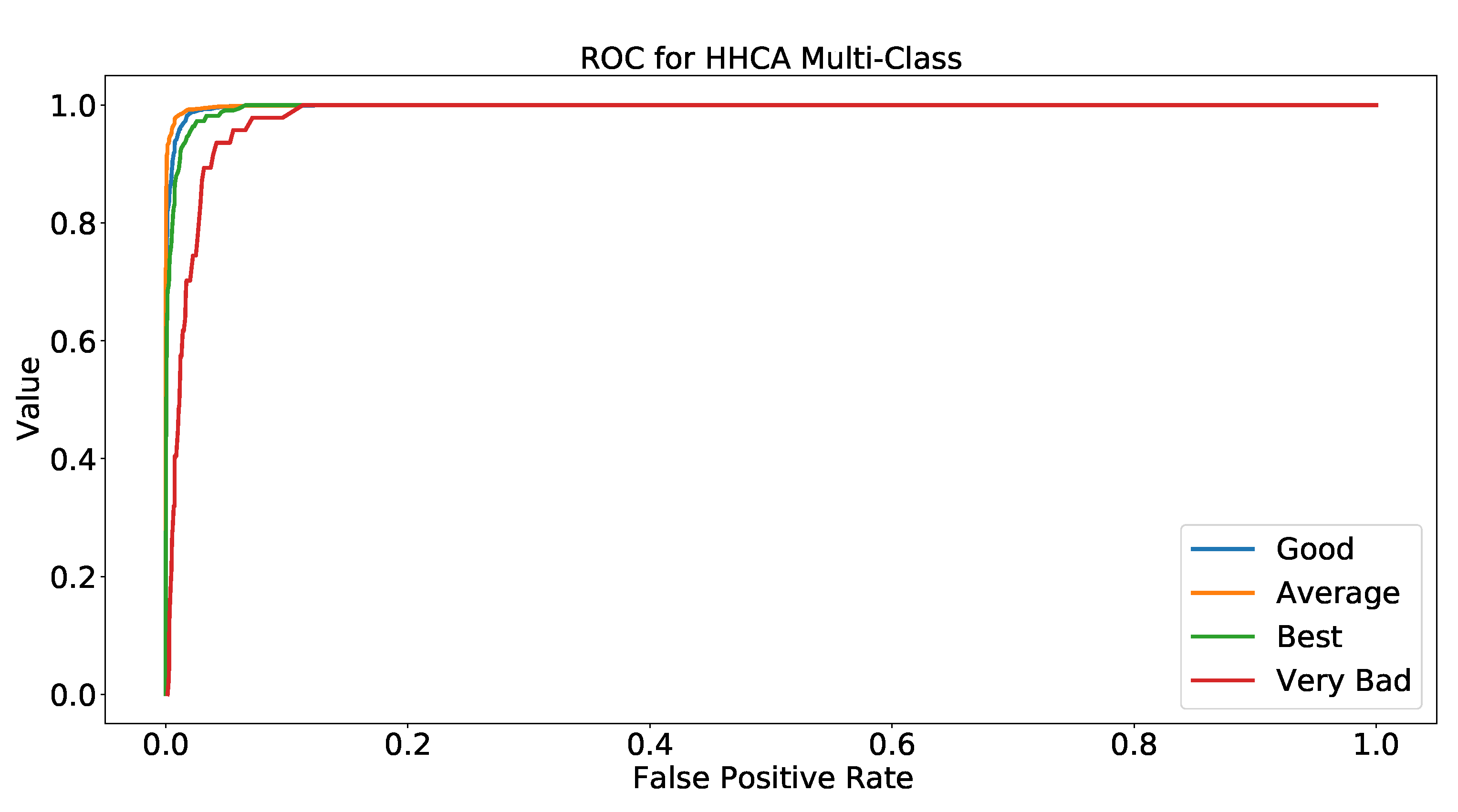
This research proposed a solution for the Medicare industry to uncover the most influential attributes using the star ratings. Two types of ML techniques were implemented, which included binary and multi-class classification. The HHCA dataset was utilized here, which contains 70 features along with the target variable (star rating). The data pre-processing was performed along with handling missing values, removal of inconsistencies, and elimination of outliers from the dataset. Afterward, feature engineering was conducted using Weka, and four different attribute selection filters (CAE, RA, PCA, CSE) were applied to locate the most impactful attributes for binary and multi-class classification problems. The RF model was chosen for these “4” filters to find the best feature selection technique, and the findings depicted that the CSE filter had the best performance for both techniques (binary, multi-class) using the “12” features. The name of the important factors are O_H_H_A_Ser, h_t_p_c_t_m, r_c_f_s, f_c_t_p_f_c, b_m_a, h_g_o_b, g_ b_a_b, p_b_i, i_h_a_o, a_d_c_b_m, t_b_a_t_h, and P_iS_a. After selecting the best from the 70 available attributes, four renowned machine learning models (DT, SVM, DNN, RF) were utilized for binary and multi-class classification using the “12” features. The ML model’s performance was analyzed based on four evaluation metrics: accuracy, precision, recall, F-1 score. For better results, the hyperparameters’ tunings were also considered, and we tested the models with the best hyperparameters. The findings showed that the DNN and RF models outperformed and achieved the highest score among all other models for binary and multi-class classification, respectively. The ROC was also a significant evaluation metric for finding the significance of the model. We computed the ROC results for each class in both binary and multi-class classification. The findings of this research are helpful in the healthcare domain to improve the customer experience using the influential features for better results.
The twelve significant extracted features affecting Medicare’s star rating had the following features: Offers Home Health Aide Services, how often the home health team began their patients’ care in a timely manner, how often the home health team determined whether patients received a flu shot for the current flu season, How frequently did the home health care staff follow the doctor’s recommendations, provide foot care, and provide education to people with diabetes, Frequency with which patients improved in their capacity to walk and move, Rate with which patients improved their ability to get out and back into bed, How frequently patients improved their ability to shower, Note on the frequency with which patients’ breath improves, Rate at which surgical incisions healed or improved, Rates at which patients improved their oral medication adherence, Frequency with which home health care recipients were hospital admission, PPR Risk-Standardized Rate (Upper Limit).
Initiation of Care at the Appropriate Time was one of the important features, h_t_p_c_t_m, that was yielded in this study, and it affects the Medicare star rating. It shows the percentage of home health quality occurrences when treatment began or resumed. Timely Initiation of Care [
45] came first and the feature “Offers Home Health Aide Services”, O_H_H_A_Ser. This is a vital feature especially for those with disabilities. However, further analysis is needed to improve this service as Medicare does not cover home health personal care aides as a stand-alone service. It only pays for a home health personal care aide when an individual also receives skilled nursing care or rehabilitation services through home health.
Appropriate timing is one of the important aspects preventing costly rehospitalizations and improving patient outcomes. When home healthcare was delayed after hospital discharge, the patients were more likely to experience a 30-day rehospitalization, and the association between it and the rehospitalization of diabetes patients was investigated in [
46], while influenza immunization received for the current flu season is another important feature, r_c_f_s, considering that influenza has been linked to 12,000 to 56,000 deaths in the United States alone each year and that geriatric adults, those ≥65 years old, are the most vulnerable to severe infection and account for up to 85% of these deaths [
47].
Improvement in bathing, g_b_a_b, was another feature that was yielded in this investigation that affects the star rating. The percentage of home health quality episodes in which the patient improved his/her ability to bathe himself/herself on his/her own is reported by the “Improvement in Bathing [
45]” feature. In [
48], the effect of this feature was investigated to understand how alterations in the physical capacity of an older adult affect his/her preferences in bathing, as well as how the care environment incorporates these alterations.
Another aspect of this study’s findings that impacts the star rating was the “Improvement in the status of surgical wounds”, i_h_a_o. Home care wound management was tested in [
49] to see if oral antibiotics and the wound and patient variables affected the efficacy and surgical site infection rate compared to hospital-based wound management.


 ,
, 




{kind=link}
{kind=link}
{kind=link}