
Machine Learning Model Based on Lipidomic Profile Information to Predict Sudden Infant Death Syndrome

 ,
,  , , , , and
, , , , and
Abstract
:1. Introduction
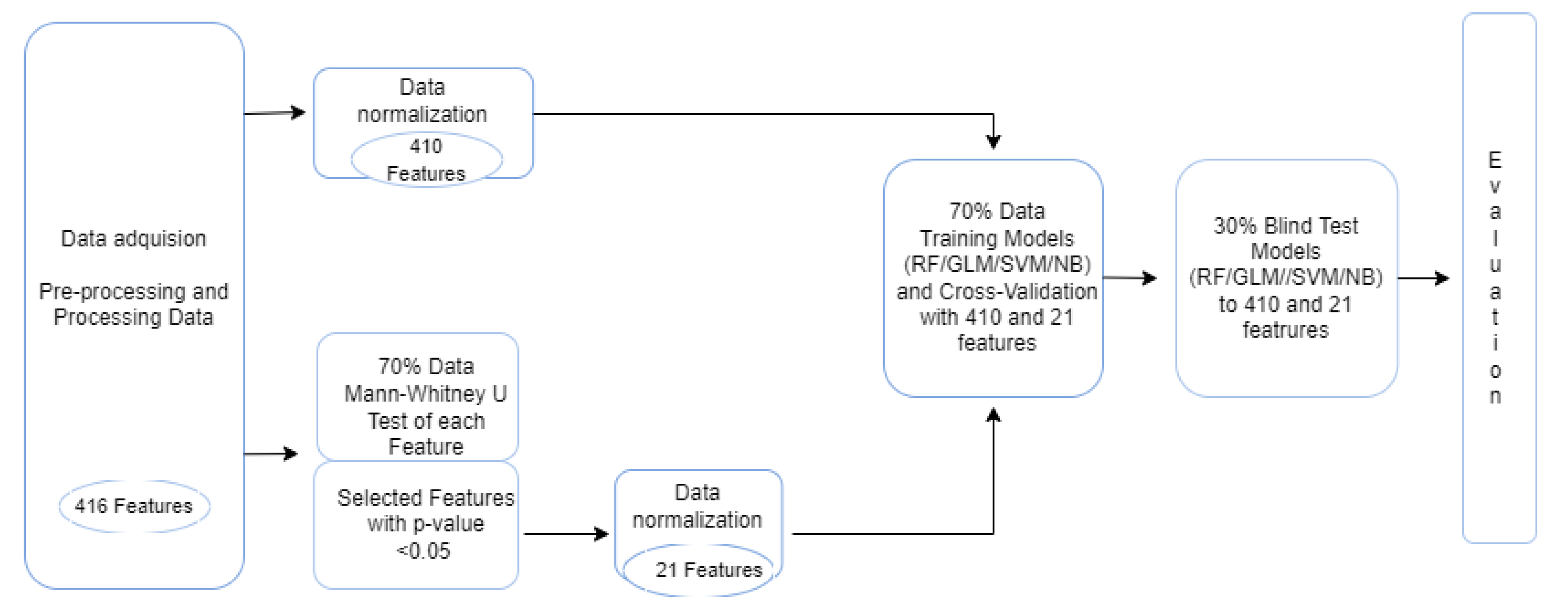
2. Materials and Methods
2.1. Data Description
2.2. Data Preprocessing
2.3. Data Normalization
2.4. Classification Methods
2.5. Feature Selection
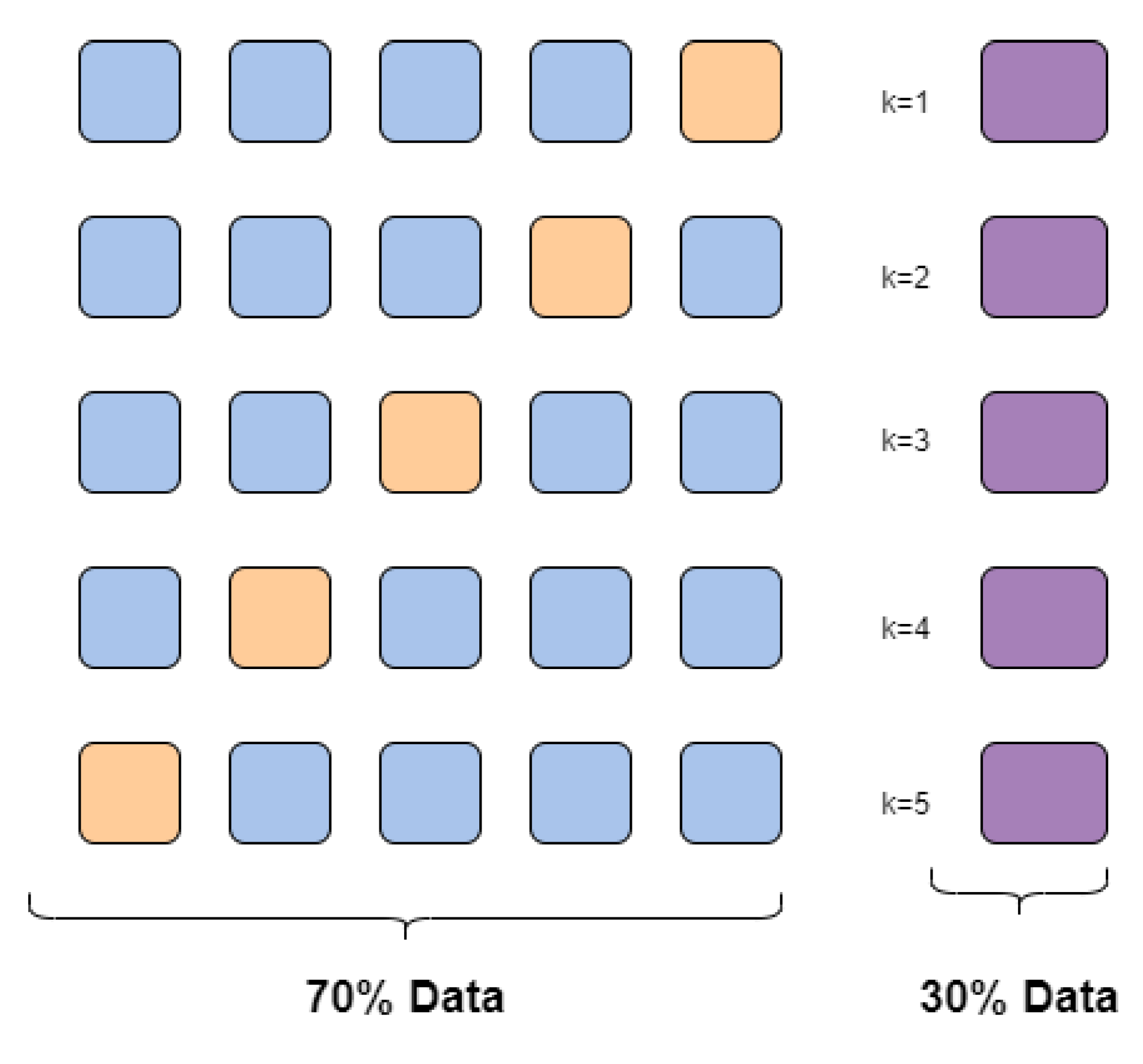
2.6. Cross-Validation
2.7. Metrics of Evaluation
3. Results and Experimentation
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Horne, R.S. Sudden infant death syndrome: Current perspectives. Intern. Med. J. 2019, 49, 433–438. [Google Scholar] [CrossRef] [PubMed]
- Bajanowski, T.; Vege, Å.; Byard, R.W.; Krous, H.F.; Arnestad, M.; Bachs, L.; Banner, J.; Blair, P.S.; Borthne, A.; Dettmeyer, R.; et al. Sudden infant death syndrome (SIDS)—Standardised investigations and classification: Recommendations. Forensic Sci. Int. 2007, 165, 129–143. [Google Scholar] [CrossRef]
- Baruteau, A.E.; Tester, D.J.; Kapplinger, J.D.; Ackerman, M.J.; Behr, E.R. Sudden infant death syndrome and inherited cardiac conditions. Nat. Rev. Cardiol. 2017, 14, 715–726. [Google Scholar] [CrossRef] [PubMed]
- Tester, D.J.; Wong, L.C.; Chanana, P.; Jaye, A.; Evans, J.M.; FitzPatrick, D.R.; Evans, M.J.; Fleming, P.; Jeffrey, I.; Cohen, M.C.; et al. Cardiac genetic predisposition in sudden infant death syndrome. J. Am. Coll. Cardiol. 2018, 71, 1217–1227. [Google Scholar] [CrossRef] [PubMed]
- Izquierdo, I.; Zorio, E.; Molina, P.; Marín, P. Principales hipótesis y teorías patogénicas del síndrome de la muerte súbita del lactante. In Libro Blanco de la Muerte Súbita Infantil; Asociación Española de Pediatría: Barcelona, Spain, 2013; pp. 47–60. [Google Scholar]
- Giambelluca, S.; Verlato, G.; Simonato, M.; Vedovelli, L.; Bonadies, L.; Najdekr, L.; Dunn, W.B.; Carnielli, V.P.; Cogo, P. Chorioamnionitis alters lung surfactant lipidome in newborns with respiratory distress syndrome. Pediatr. Res. 2021, 90, 1039–1043. [Google Scholar] [CrossRef]
- Alpay Savasan, Z.; Yilmaz, A.; Ugur, Z.; Aydas, B.; Bahado-Singh, R.O.; Graham, S.F. Metabolomic profiling of cerebral palsy brain tissue reveals novel central biomarkers and biochemical pathways associated with the disease: A pilot study. Metabolites 2019, 9, 27. [Google Scholar] [CrossRef] [Green Version]
- Segers, K.; Declerck, S.; Mangelings, D.; Heyden, Y.V.; Eeckhaut, A.V. Analytical techniques for metabolomic studies: A review. Bioanalysis 2019, 11, 2297–2318. [Google Scholar] [CrossRef]
- Holčapek, M.; Gerhard, L.; Ekroos, K. Lipidomic analysis. Anal. Chem. 2018, 90, 4249–4257. [Google Scholar] [CrossRef] [Green Version]
- Ochoa, B. La lipidómica, una nueva herramienta al servicio de la salud. Gaceta Méd. Bilbao 2006, 103, 101–102. [Google Scholar] [CrossRef]
- Villa, C.; Yoon, J.H. Multi-Omics for the Understanding of Brain Diseases. Life 2021, 11, 1202. [Google Scholar] [CrossRef]
- Graham, S.; Chevallier, O.; Kumar, P.; Türkoǧlu, O.; Bahado-Singh, R. Metabolomic profiling of brain from infants who died from Sudden Infant Death Syndrome reveals novel predictive biomarkers. J. Perinatol. 2017, 37, 91–97. [Google Scholar] [CrossRef] [PubMed]
- Graham, S.F.; Turkoglu, O.; Kumar, P.; Yilmaz, A.; Bjorndahl, T.C.; Han, B.; Mandal, R.; Wishart, D.S.; Bahado-Singh, R.O. Targeted metabolic profiling of post-mortem brain from infants who died from sudden infant death syndrome. J. Proteome Res. 2017, 16, 2587–2596. [Google Scholar] [CrossRef] [PubMed]
- Perrone, S.; Lembo, C.; Moretti, S.; Prezioso, G.; Buonocore, G.; Toscani, G.; Marinelli, F.; Nonnis-Marzano, F.; Esposito, S. Sudden Infant Death Syndrome: Beyond Risk Factors. Life 2021, 11, 184. [Google Scholar] [CrossRef] [PubMed]
- Tabl, A.A.; Alkhateeb, A.; ElMaraghy, W.; Rueda, L.; Ngom, A. A machine learning approach for identifying gene biomarkers guiding the treatment of breast cancer. Front. Genet. 2019, 10, 256. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, J.; Yan, D.; Zhao, A.; Hou, X.; Zheng, X.; Chen, P.; Bao, Y.; Jia, W.; Hu, C.; Zhang, Z.L. Discovery of potential biomarkers for osteoporosis using LC-MS/MS metabolomic methods. Osteoporos. Int. 2019, 30, 1491–1499. [Google Scholar] [CrossRef]
- Yilmaz, A.; Ustun, I.; Ugur, Z.; Akyol, S.; Hu, W.T.; Fiandaca, M.S.; Mapstone, M.; Federoff, H.; Maddens, M.; Graham, S.F. A Community-Based Study Identifying Metabolic Biomarkers of Mild Cognitive Impairment and Alzheimer’s Disease Using Artificial Intelligence and Machine Learning. J. Alzheimer’s Dis. 2020, 78, 1381–1392. [Google Scholar] [CrossRef]
- Zheng, L.; Lin, F.; Zhu, C.; Liu, G.; Wu, X.; Wu, Z.; Zheng, J.; Xia, H.; Cai, Y.; Liang, H. Machine Learning Algorithms Identify Pathogen-Specific Biomarkers of Clinical and Metabolomic Characteristics in Septic Patients with Bacterial Infections. BioMed Res. Int. 2020, 2020, 6950576. [Google Scholar] [CrossRef]
- Bhavsar, K.A.; Singla, J.; Al-Otaibi, Y.D.; Song, O.Y.; Zikria, Y.B.; Bashir, A.K. Medical diagnosis using machine learning: A statistical review. Comput. Mater. Contin. 2021, 67, 107–125. [Google Scholar] [CrossRef]
- Zoabi, Y.; Deri-Rozov, S.; Shomron, N. Machine learning-based prediction of COVID-19 diagnosis based on symptoms. NPJ Digit. Med. 2021, 4, 3. [Google Scholar] [CrossRef]
- Yadav, S.S.; Jadhav, S.M. Detection of common risk factors for diagnosis of cardiac arrhythmia using machine learning algorithm. Expert Syst. Appl. 2021, 163, 113807. [Google Scholar] [CrossRef]
- Iqbal, M.J.; Javed, Z.; Sadia, H.; Qureshi, I.A.; Irshad, A.; Ahmed, R.; Malik, K.; Raza, S.; Abbas, A.; Pezzani, R.; et al. Clinical applications of artificial intelligence and machine learning in cancer diagnosis: Looking into the future. Cancer Cell Int. 2021, 21, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Blackburn, J.; Chapur, V.F.; Stephens, J.A.; Zhao, J.; Shepler, A.; Pierson, C.R.; Otero, J.J. Revisiting the neuropathology of sudden infant death syndrome (SIDS). Front. Neurol. 2020, 11, 594550. [Google Scholar] [CrossRef] [PubMed]
- Galván-Tejada, C.E.; Villagrana-Bañuelos, K.E.; Zanella-Calzada, L.A.; Moreno-Báez, A.; Luna-García, H.; Celaya-Padilla, J.M.; Galván-Tejada, J.I.; Gamboa-Rosales, H. Univariate Analysis of Short-Chain Fatty Acids Related to Sudden Infant Death Syndrome. Diagnostics 2020, 10, 896. [Google Scholar] [CrossRef] [PubMed]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2020. [Google Scholar]
- NIH Common Fund’s National Metabolomics Data Repository (NMDR) Website, t.M.W. Lipidomics in (SIDS) Sudden Infant Death Syndrome, Project ID PR000475. 2017. Available online: https://www.metabolomicsworkbench.org/data/DRCCMetadata.php?Mode=Project&ProjectID=PR000475 (accessed on 22 February 2021).
- Curtis, A.E.; Smith, T.A.; Ziganshin, B.A.; Elefteriades, J.A. The mystery of the Z-score. Aorta 2016, 4, 124–130. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Lantz, B. Machine Learning with R: Expert Techniques for Predictive Modeling; Packt Publishing Ltd.: Birmingham, UK, 2019. [Google Scholar]
- RColorBrewer, S.; Liaw, M.A. Package ‘Randomforest’; University of California, Berkeley: Berkeley, CA, USA, 2018. [Google Scholar]
- Cox, D.R. The regression analysis of binary sequences. J. R. Stat. Soc. Ser. (Methodol.) 1958, 20, 215–232. [Google Scholar] [CrossRef]
- Sperandei, S. Understanding logistic regression analysis. Biochem. Med. 2014, 24, 12–18. [Google Scholar] [CrossRef]
- R Core Team. Package “Stats”. The R Stats Package 2018. Available online: https://stat.ethz.ch/R-manual/R-devel/library/stats/html/00Index.html (accessed on 22 February 2021).
- Noble, W.S. What is a support vector machine? Nat. Biotechnol. 2006, 24, 1565–1567. [Google Scholar] [CrossRef]
- Patle, A.; Chouhan, D.S. SVM kernel functions for classification. In Proceedings of the 2013 International Conference on Advances in Technology and Engineering (ICATE), Mumbai, India, 23–25 January 2013; pp. 1–9. [Google Scholar]
- Meyer, D.; Dimitriadou, E.; Hornik, K.; Weingessel, A.; Leisch, F.; Chang, C.C.; Lin, C. Misc Functions of the Department of Statistics, Probability Theory Group (Formerly: E1071), T.W. [R package e1071 version 1.6-7]. Comprehensive R Archive Network (CRAN), 2014. Available online: http://www2.uaem.mx/r-mirror/web/packages/e1071/ (accessed on 22 February 2021).
- Bayes, T.L., III. An essay towards solving a problem in the doctrine of chances. By the late Rev. Mr. Bayes, FRS communicated by Mr. Price, in a letter to John Canton, AMFR S. Philos. Trans. R. Soc. Lond. 1763, 53, 370–418. [Google Scholar]
- Mann, H.B.; Whitney, D.R. On a test of whether one of two random variables is stochastically larger than the other. Ann. Math. Stat. 1947, 18, 50–60. [Google Scholar] [CrossRef]
- MacFarland, T.W.; Yates, J.M. Chapter 4. Mann–Whitney U Test. In Introduction to Nonparametric Statistics for the Biological Sciences Using R; Springer International Publishing: Cham, Switzerland, 2016. [Google Scholar] [CrossRef]
- R Core Team. Wilcoxon Rank Sum and Signed Rank Tests. 2011. Available online: https://stat.ethz.ch/R-manual/R-devel/library/stats/html/wilcox.test.html (accessed on 22 February 2021).
- Refaeilzadeh, P.; Tang, L.; Liu, H. Cross-Validation. In Encyclopedia of Database Systems; Liu, L., Özsu, M.T., Eds.; Springer: Boston, MA, USA, 2009. [Google Scholar] [CrossRef]
- Kuhn, M. Building predictive models in R using the caret package. J. Stat. Softw. 2008, 28, 1–26. [Google Scholar] [CrossRef] [Green Version]
- Hoo, Z.H.; Candlish, J.; Teare, D. What is an ROC curve? Emerg. Med. J. 2017, 34, 357–359. [Google Scholar] [CrossRef] [PubMed]
- Domínguez, E.; González, R. Análisis de las curvas receiver-operating characteristic: Un método útil para evaluar procederes diagnósticos. Rev. Cuba. Endocrinol. 2002, 13, 169–176. [Google Scholar]
- Zhu, W.; Zeng, N.; Wang, N. Sensitivity, specificity, accuracy, associated confidence interval and ROC analysis with practical SAS implementations. NESUG Proc. Health Care Life Sci. 2010, 19, 67. [Google Scholar]
- Narkhede, S. Understanding auc-roc curve. Towards Data Sci. 2018, 26, 220–227. [Google Scholar]
- Baratloo, A.; Hosseini, M.; Negida, A.; El Ashal, G. Part 1: Simple definition and calculation of accuracy, sensitivity and specificity. Arch. Emerg. Med. 2015, 3, 48–49. [Google Scholar]
- Kuhn, M. Caret: Classification and regression training. Astrophys. Source Code Libr. 2015, ascl1505. [Google Scholar]
- Robin, X.; Turck, N.; Hainard, A.; Tiberti, N.; Lisacek, F.; Sanchez, J.C.; Müller, M. pROC: An open-source package for R and S+ to analyze and compare ROC curves. BMC Bioinform. 2011, 12, 77. [Google Scholar] [CrossRef]
- Yu, L.; Liu, H. Feature selection for high-dimensional data: A fast correlation-based filter solution. In Proceedings of the 20th International Conference on Machine Learning (ICML-03), Washington, DC, USA, 21–24 August 2003; pp. 856–863. [Google Scholar]
- Bommert, A.; Sun, X.; Bischl, B.; Rahnenführer, J.; Lang, M. Benchmark for filter methods for feature selection in high-dimensional classification data. Comput. Stat. Data Anal. 2020, 143, 106839. [Google Scholar] [CrossRef]
- Hishikawa, D.; Hashidate, T.; Shimizu, T.; Shindou, H. Diversity and function of membrane glycerophospholipids generated by the remodeling pathway in mammalian cells. J. Lipid Res. 2014, 55, 799–807. [Google Scholar] [CrossRef] [Green Version]
- Farooqui, A.A.; Horrocks, L.A.; Farooqui, T. Glycerophospholipids in brain: Their metabolism, incorporation into membranes, functions, and involvement in neurological disorders. Chem. Phys. Lipids 2000, 106, 1–29. [Google Scholar] [CrossRef]
- Castro-Gómez, P.; Garcia-Serrano, A.; Visioli, F.; Fontecha, J. Relevance of dietary glycerophospholipids and sphingolipids to human health. Prostaglandins Leukot. Essent. Fat. Acids 2015, 101, 41–51. [Google Scholar] [CrossRef] [PubMed]
- Farooqui, A.A.; Horrocks, L.A. Glycerophospholipids in the Brain: Phospholipases A2 in Neurological Disorders; Springer Science & Business Media: New York, NY, USA, 2006. [Google Scholar]
- Califf, R.M. Biomarker definitions and their applications. Exp. Biol. Med. 2018, 243, 213–221. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
| Group | Number of Features |
|---|---|
| Cardiolipins | 6 |
| Sphingolipids | 1 |
| Acids | 16 |
| Glycerophosphate | 1 |
| Phosphatylcholine | 24 |
| Phosphatylethalonamine | 24 |
| Phosphatidylglycerols | 15 |
| Phosphatidylinositols | 12 |
| Glycerophosphoserines | 9 |
| Lysophosphatidylethanolamine | 8 |
| Ether Phosphatidylethanolamines | 16 |
| Group | Number of Features |
|---|---|
| Cholesterol esters | 12 |
| Diacylglycerols | 37 |
| Monoradylglycerols | 2 |
| Phosphatylcholine | 37 |
| Phosphatylethalonamine | 11 |
| Sphingomyelins | 43 |
| Triacylglycerols | 98 |
| Lysophosphatidylcholines | 25 |
| Ether Phosphatidylethanolamines | 4 |
| Ether Phosphatidylcholines | 9 |
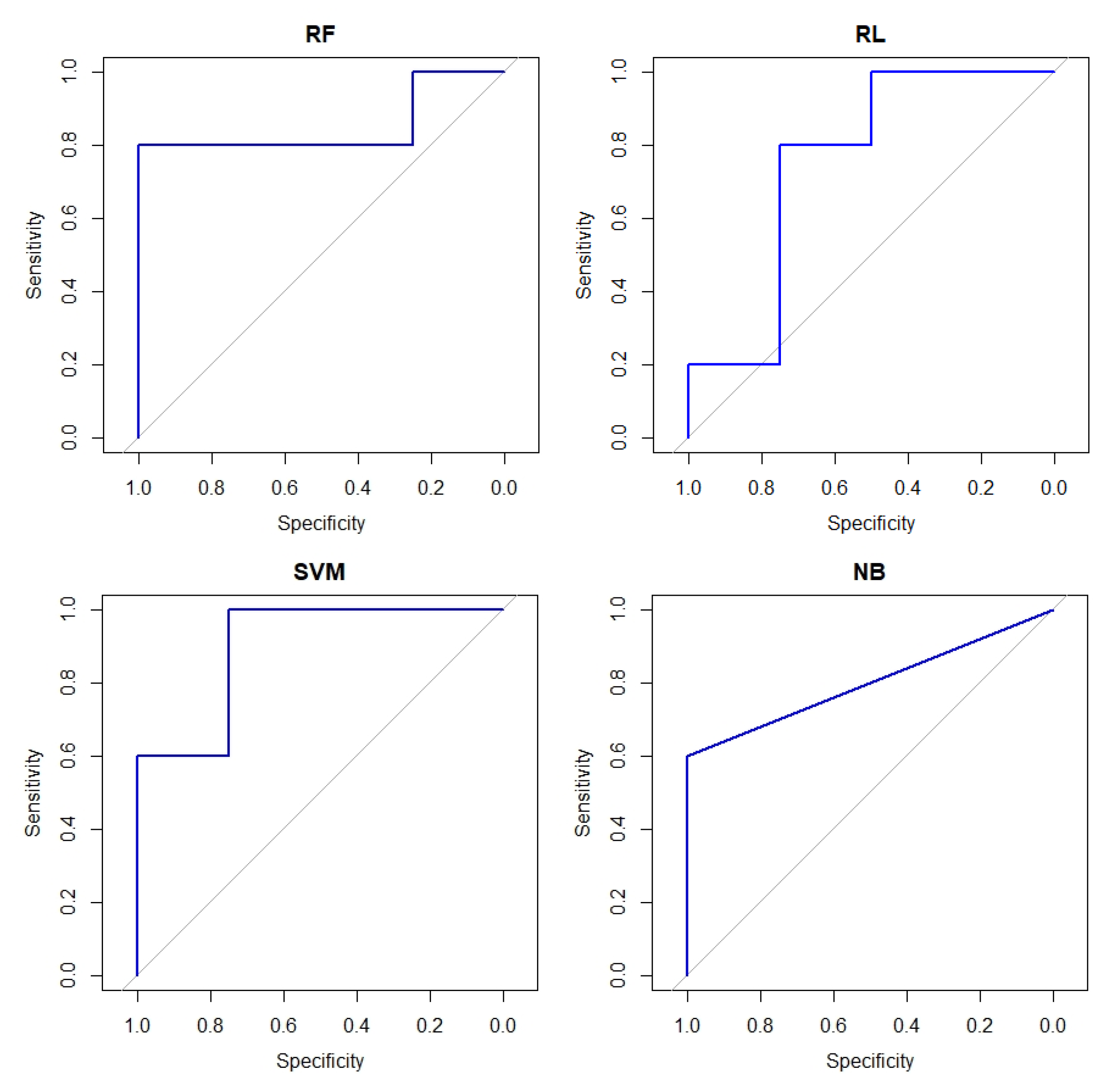
| Classification Method | Features | AUC | Accuracy | Sensitivity | Specificity |
|---|---|---|---|---|---|
| RF | 410 | 0.2857 | 0.4444 | 0.5714 | 0 |
| RF | 21 | 0.9000 | 0.8889 | 0.8000 | 1 |
| LR | 410 | 0.4500 | 0.5555 | 0.4000 | 0.7500 |
| LR | 21 | 0.7500 | 0.7777 | 0.8000 | 0.7500 |
| SVM | 410 | 0.7000 | 0.7777 | 0.8000 | 0.7500 |
| SVM | 21 | 0.9000 | 0.8888 | 1 | 0.7500 |
| NB | 410 | 0.6750 | 0.6666 | 0.6000 | 0.7500 |
| NB | 21 | 0.8000 | 0.7777 | 0.6000 | 1 |
| Features | Super Class | Main Class | Sub Class 1 | Formula | p-Value |
|---|---|---|---|---|---|
| PC 40:7 | Glycerophospholipids | Glycerophosphocholines | PC | CHNOP | 0.00420 |
| PI 36:2 | Glycerophospholipids | Glycerophosphocholines | PC | CHNOP | 0.00420 |
| PE 35:0 | Glycerophospholipids | Glycerophosphoethanolamines | PE | CHNOP | 0.01060 |
| DG 34:1 | Glycerolipids | Diradylglycerols | DAG | CHO | 0.01308 |
| PC.38.7 | Glycerophospholipids | Glycerophosphocholines | PC | CHNOP | 0.01602 |
| PE 34:3 | Glycerophospholipids | Glycerophosphoethanolamines | PE | CHNOP | 0.02355 |
| TG 57:8 | Glycerolipids | Triradylglycerols | TAG | CHO | 0.02355 |
| CL 70:5 | Glycerophospholipids | Cardiolipins | CL | CHOP | 0.02355 |
| SM 40:1 | Sphingolipids | Sphingomyelins | SM | CHNOP | 0.02826 |
| PC 30:2 | Glycerophospholipids | Glycerophosphocholines | PC | CHNOP | 0.02826 |
| PC 32:3 | Glycerophospholipids | Phosphatidylcholines | PC | CHNOP | 0.03372 |
| SM 36:2 | Sphingolipids | Sphingomyelins | SM | CHNOP | 0.03372 |
| PC 33:1 | Glycerophospholipids | Glycerophosphocholines | PC | CHNOP | 0.03372 |
| CE 18:2. | Sterol Lipids | Sterol esters | Chol | CHO | 0.03372 |
| DG 36:2 | Glycerolipids | Diradylglycerols | DAG | CHO | 0.03372 |
| PC 32:1 | Glycerophospholipids | Glycerophosphocholines | PC | CHOP | 0.03999 |
| PG 36:3 | Glycerophospholipids | Glycerophosphoglycerols | PG | CHOP | 0.04717 |
| CE 22:6 | Sterol Lipids | Sterol esters | Chol | CHO | 0.04717 |
| PC 40:10 | Glycerophospholipids | Glycerophosphocholines | PC | CHNOP | 0.04717 |
| PC 42:7 | Glycerophospholipids | Glycerophosphocholines | PC | CHNOP | 0.04717 |
| SM.30.1 | Sphingolipids | Sphingomyelins | SM | CHNOP | 0.04717 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Villagrana-Bañuelos, K.E.; Galván-Tejada, C.E.; Galván-Tejada, J.I.; Gamboa-Rosales, H.; Celaya-Padilla, J.M.; Soto-Murillo, M.A.; Solís-Robles, R. Machine Learning Model Based on Lipidomic Profile Information to Predict Sudden Infant Death Syndrome. Healthcare 2022, 10, 1303. https://doi.org/10.3390/healthcare10071303
Villagrana-Bañuelos KE, Galván-Tejada CE, Galván-Tejada JI, Gamboa-Rosales H, Celaya-Padilla JM, Soto-Murillo MA, Solís-Robles R. Machine Learning Model Based on Lipidomic Profile Information to Predict Sudden Infant Death Syndrome. Healthcare. 2022; 10(7):1303. https://doi.org/10.3390/healthcare10071303
Chicago/Turabian StyleVillagrana-Bañuelos, Karen E., Carlos E. Galván-Tejada, Jorge I. Galván-Tejada, Hamurabi Gamboa-Rosales, José M. Celaya-Padilla, Manuel A. Soto-Murillo, and Roberto Solís-Robles. 2022. "Machine Learning Model Based on Lipidomic Profile Information to Predict Sudden Infant Death Syndrome" Healthcare 10, no. 7: 1303. https://doi.org/10.3390/healthcare10071303