
A Cluster Analysis of the Acceptance of a Contact Tracing App—The Identification of Profiles for the Italian Immuni Contact Tracing App

 , , ,
, , ,  , and
, and
Abstract
:1. Introduction
2. Theoretical Background
2.1. Technology Acceptance Model and Health Belief Model
2.2. Computer Self Efficacy
2.3. Moral Disengagement
2.4. Institutional Trust, Political Orientation, Core Political Values, and Prosocial Responsibility
2.5. Privacy
2.6. Perceived Locus of Causality
3. Materials and Methods
3.1. Study Design and Data Collection
3.2. Ethical Considerations
3.3. Survey Questionnaire
3.4. Database Preparation
3.5. Tools
3.6. Sociodemographic Data
3.7. Measures
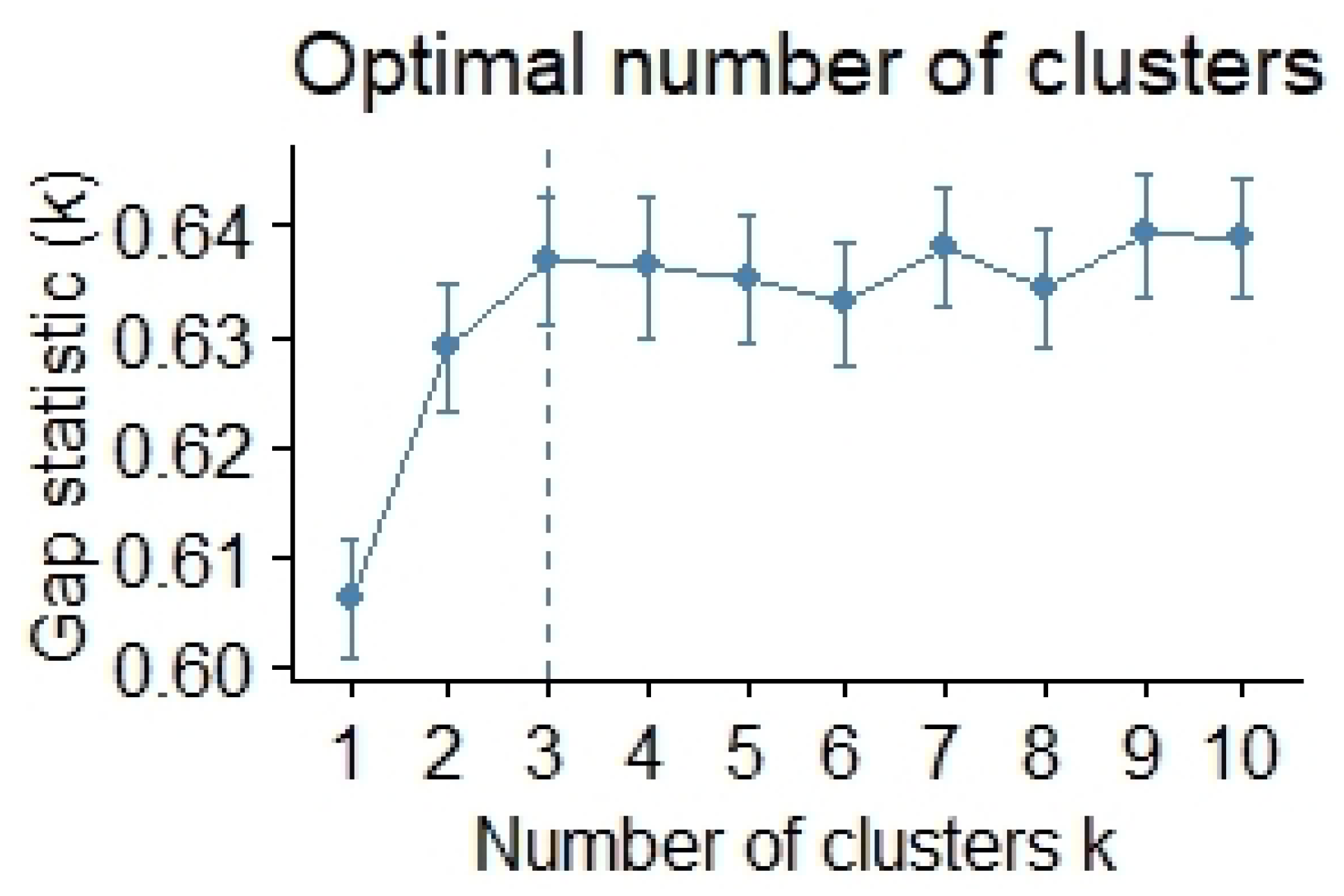
3.8. Cluster Analysis
4. Results
4.1. Descriptive Statistics
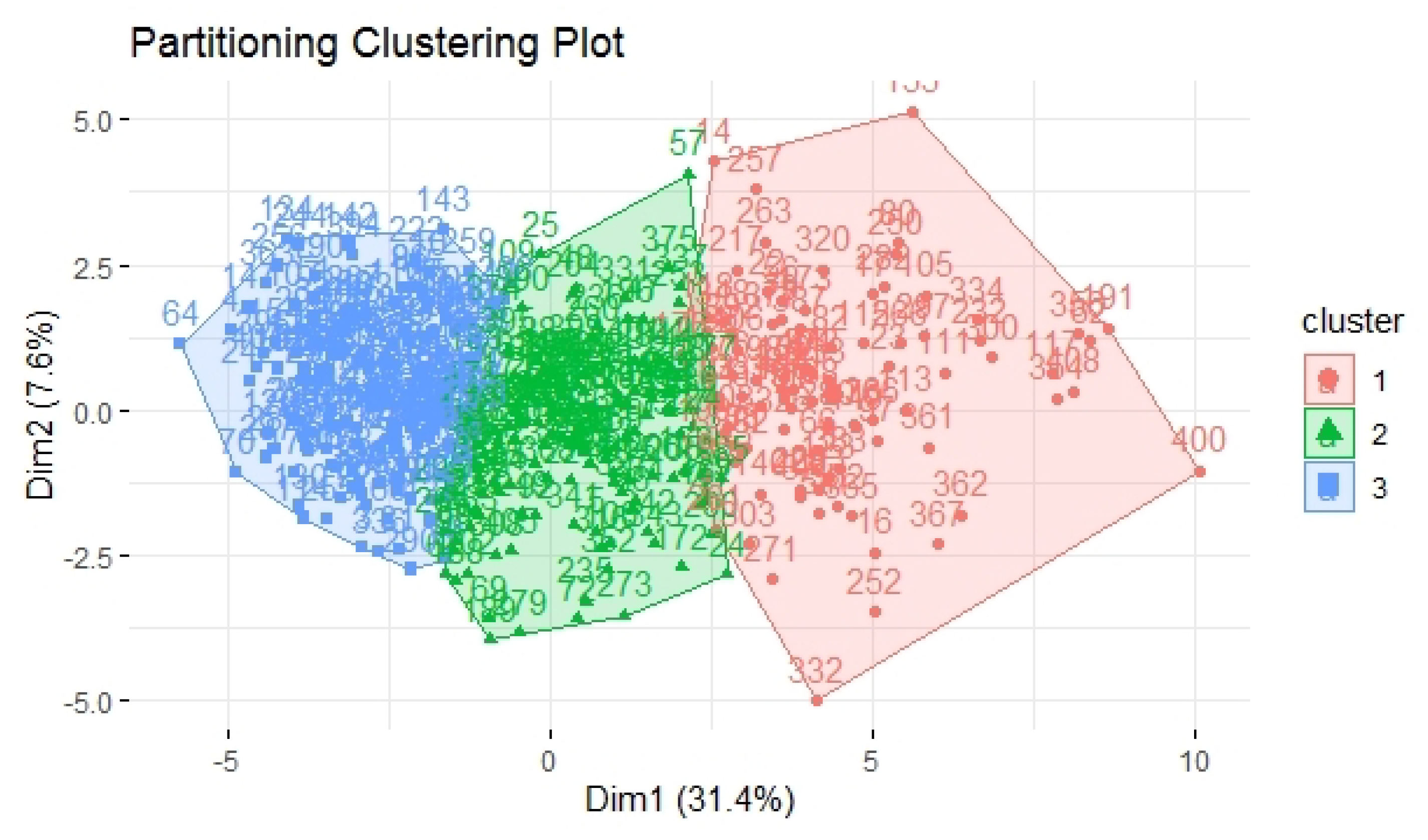
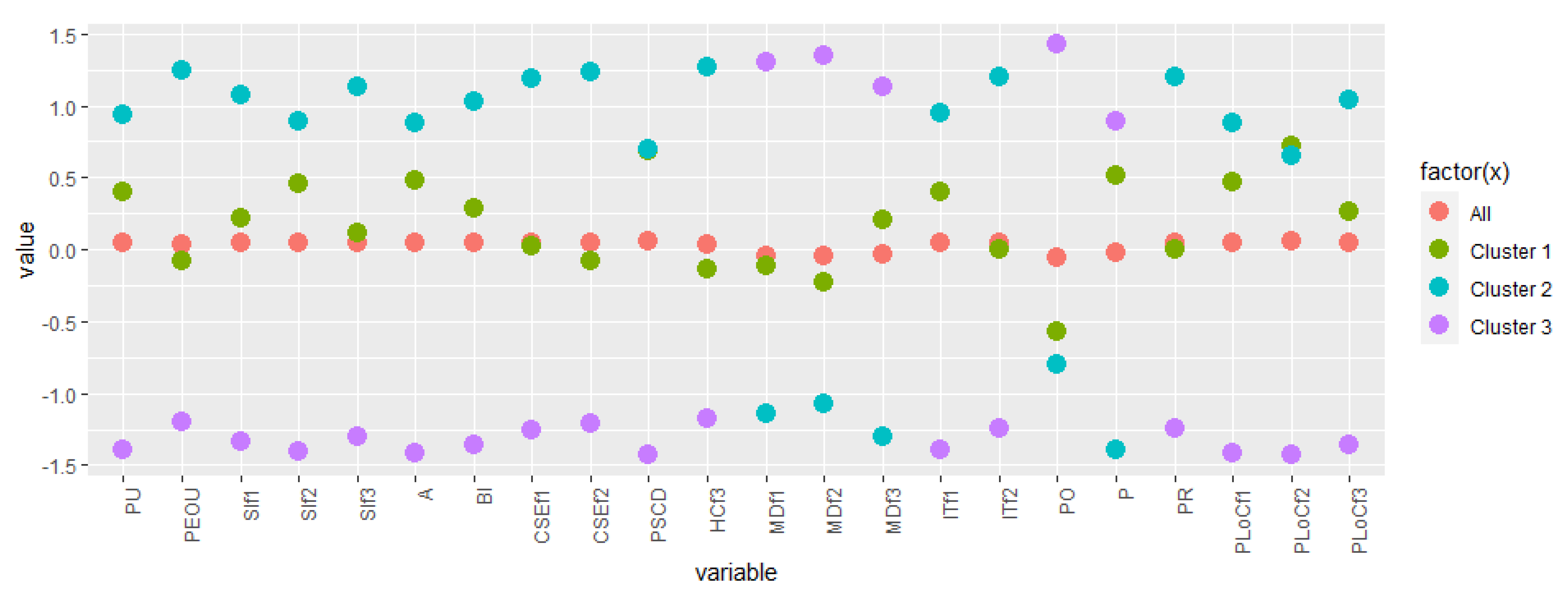
4.2. Building Respondents’ Profiles from Cluster Data
4.3. Integrating Profiles with Sociodemographic Data
5. Discussion
Predicting Profile Membership
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Cascella, M.; Rajnik, M.; Aleem, A.; Dulebohn, S.C.; Di Napoli, R. Features, Evaluation, and Treatment of Coronavirus (COVID-19); Statpearls: Treasure Island, FL, USA, 2022. [Google Scholar]
- WHO. T3: Test, Treat, Track—Report; Technical Report; World Health Organization: Geneva, Switzerland, 2012. [Google Scholar]
- Immuni Official Documentation. Technical Report. 2021. Available online: https://github.com/immuni-app/immuni-documentation (accessed on 27 July 2021).
- Fraser, C.; Abeler-Dorner, L.; Ferretti, L.; Parker, M.; Kendall, M.; Bonsall, D. Digital Contact Tracing: Comparing the Capabilities of Centralized and Decentralized Data Architecture to Effectively Suppress the COVID-19 Epidemic Whilst Maximizing Freedom of Movement and Maintaining Privacy. Technical Report. 2020. Available online: https://github.com/BDI-pathogens/covid-19_instant_tracing/blob/master/Centralised%20and%20decentralised%20systems%20for%20contact%20tracing.pdf (accessed on 20 October 2020).
- Zhang, B.; Kreps, S.; McMurry, N.; McCain, R.M. Americans’ perceptions of privacy and surveillance in the COVID-19 pandemic. PLoS ONE 2020, 15, e0242652. [Google Scholar] [CrossRef] [PubMed]
- Patil, P. What is Exploratory Data Analysis? Technical Report, Towards Data Science. 2018. Available online: https://towardsdatascience.com/exploratory-data-analysis-8fc1cb20fd15 (accessed on 4 January 2022).
- Tukey, J.W. Exploratory Data Analysis; Addison-Wesley: Boston, MA, USA, 1977. [Google Scholar]
- von Luxburg, U.; Williamson, R.C.; Guyon, I. Clustering: Science or Art? In Proceedings of ICML Workshop on Unsupervised and Transfer Learning; Guyon, I., Dror, G., Lemaire, V., Taylor, G., Silver, D., Eds.; PMLR: Bellevue, WA, USA, 2012; Volume 27, pp. 65–79. [Google Scholar]
- Walrave, M.; Waeterloos, C.; Ponnet, K. Adoption of a Contact Tracing App for Containing COVID-19: A Health Belief Model Approach. JMIR Public Health Surveill. 2020, 6, e20572. [Google Scholar] [CrossRef] [PubMed]
- Walrave, M.; Waeterloos, C.; Ponnet, K. Ready or Not for Contact Tracing? Investigating the Adoption Intention of COVID-19 Contact-Tracing Technology Using an Extended Unified Theory of Acceptance and Use of Technology Model. Cyberpsychology, Behav. Soc. Netw. 2021, 24, 377–383. [Google Scholar] [CrossRef] [PubMed]
- Ahadzadeh, A.S.; Pahlevan Sharif, S.; Ong, F.S.; Khong, K.W. Integrating Health Belief Model and Technology Acceptance Model: An Investigation of Health-Related Internet Use. J. Med. Internet. Res. 2015, 17, e45. [Google Scholar] [CrossRef]
- Wnuk, A.; Oleksy, T.; Maison, D. The acceptance of COVID-19 tracking technologies: The role of perceived threat, lack of control, and ideological beliefs. PLoS ONE 2020, 15, 1–16. [Google Scholar] [CrossRef]
- Davis, F.D. Perceived Usefulness, Perceived Ease of Use, and User Acceptance of Information Technology. MIS Q. 1989, 13, 319–340. [Google Scholar] [CrossRef] [Green Version]
- Fishbein, M. Attitude and the Prediction of Behaviour; Wiley: New York, NY, USA, 1967. [Google Scholar]
- Fishbein, M.; Ajzen, I. Belief, Attitude, Intention, and Behaviour. An Introduction to Theory and Research; Addison Wesley: Boston, MA, USA, 1975. [Google Scholar]
- Davis, F.D.; Bagozzi, R.P.; Warshaw, P.R. User Acceptance of Computer Technology: A Comparison of Two Theoretical Models. Manag. Sci. 1989, 35, 982–1003. [Google Scholar] [CrossRef] [Green Version]
- Venkatesh, V. Determinants of Perceived Ease of Use: Integrating Control, Intrinsic Motivation, and Emotion into the Technology Acceptance Model. Inf. Syst. Res. 2000, 11, 342–365. [Google Scholar] [CrossRef] [Green Version]
- Park, K.; Park, N.; Heo, W. Factors Influencing Intranet Acceptance in Restaurant Industry: Use of Technology Acceptance Model. Int. Bus. Res. 2018, 11, 1. [Google Scholar] [CrossRef]
- Alsharida, R.A.; Hammood, M.M.; Al-Emran, M. Mobile Learning Adoption: A Systematic Review of the Technology Acceptance Model from 2017 to 2020. Int. J. Emerg. Technol. Learn. (iJET) 2021, 16, 147–162. [Google Scholar] [CrossRef]
- Melzner, J.; Heinze, J.; Fritsch, T. Mobile Health Applications in Workplace Health Promotion: An Integrated Conceptual Adoption Framework. Procedia Technol. 2014, 16, 1374–1382. [Google Scholar] [CrossRef] [Green Version]
- Rosenstock, I.M. Historical Origins of the Health Belief Model. Health Educ. Monogr. 1974, 2, 328–335. [Google Scholar] [CrossRef]
- Janz, N.K.; Becker, M.H. The Health Belief Model: A decade later. Health Educ. Q. 1984, 11, 1–47. [Google Scholar] [CrossRef] [Green Version]
- Jayanti, R.K.; Burns, A.C. The Antecedents of Preventive Health Care behaviour: An Empirical Study. J. Acad. Mark. Sci. 1998, 26, 6–15. [Google Scholar] [CrossRef]
- Ariff, M.S.; Yeow, S.; Zakuan, N.; Jusoh, A.; Bahari, A.Z. The Effects of Computer Self-Efficacy and Technology Acceptance Model on behavioural Intention in Internet Banking Systems. Procedia Soc. Behav. Sci. 2012, 57, 448–452. [Google Scholar] [CrossRef] [Green Version]
- Park, N.; Rhoads, M.; Hou, J.; Lee, K. Understanding the acceptance of teleconferencing systems among employees: An extension of the technology acceptance model. Comput. Hum. Behav. 2014, 39, 118–127. [Google Scholar] [CrossRef]
- Revythi, A.; Tselios, N.K. Extension of Technology Acceptance Model by using System Usability Scale to assess behavioural intention to use e-learning. Educ. Inf. Technol. 2017, 24, 2341–2355. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Han, X.; Dang, Y.; Meng, F.; Guo, X.; Lin, J. User acceptance of mobile health services from users’ perspectives: The role of self-efficacy and response-efficacy in technology acceptance. Informatics Health Soc. Care 2017, 42, 194–206. [Google Scholar] [CrossRef]
- Hong, W.; Thong, J.Y.; Wong, W.M.; Tam, K.Y. Determinants of User Acceptance of Digital Libraries: An Empirical Examination of Individual Differences and System Characteristics. J. Manag. Inf. Syst. 2002, 18, 97–124. [Google Scholar] [CrossRef]
- Davis, F.; Venkatesh, V. A Critical Assessment of Potential Measurement Biases in the Technology Acceptance Model: Three Experiments. Int. J. Hum. Comput. Stud. 1996, 45, 19–45. [Google Scholar] [CrossRef] [Green Version]
- Bandura, A.; Barbaranelli, C.; Caprara, G.V.; Pastorelli, C. Mechanisms of moral disengagement in the exercise of moral agency. J. Personal. Soc. Psychol. 1996, 71, 364. [Google Scholar] [CrossRef]
- Bandura, A. Moral Disengagement in the Perpetration of Inhumanities. Personal. Soc. Psychol. Rev. 1999, 3, 193–209. [Google Scholar] [CrossRef] [PubMed]
- Olivero, N.; Greco, A.; Annoni, A.M.; Steca, P.; Lowry, P.B. Does opportunity make the thief? Abilities and moral disengagement in illegal downloading. Behav. Inf. Technol. 2019, 38, 1273–1289. [Google Scholar] [CrossRef]
- Erikson, R.; Tedin, K. American Public Opinion: Its Origins, Content and Impact; Taylor & Francis: Oxfordshire, UK, 2015. [Google Scholar]
- Feldman, S. Values, ideology, and the structure of political attitudes. In Oxford Handbook of Political Psychology; Sears, D.O., Huddy, L., Jervis, R., Eds.; Oxford University Press: Oxford, UK, 2003. [Google Scholar]
- Mari, S.; Volpato, C.; Papastamou, S.; Chryssochoou, X.; Prodromitis, G.; Pavlopoulos, V. How Political Orientation and Vulnerability Shape Representations of the Economic Crisis in Greece and Italy. Int. Rev. Soc. Psychol. 2017, 30, 52–67. [Google Scholar] [CrossRef] [Green Version]
- McLamore, Q.; Syropoulos, S.; Leidner, B.; Hirschberger, G.; Young, K.; Zein, R.A.; Baumert, A.; Bilewicz, M.; Bilgen, A.; van Bezouw, M.J.; et al. Trust in scientific information mediates associations between conservatism and coronavirus responses in the U.S., but few other nations. Sci. Rep. 2022, 12, 3724. [Google Scholar] [CrossRef]
- Schwartz, S.H.; Caprara, G.V.; Vecchione, M. Basic Personal Values, Core Political Values, and Voting: A Longitudinal Analysis. Political Psychol. 2010, 31, 421–452. [Google Scholar] [CrossRef]
- McCann, J.A. Electoral Choices and Core Value Change: The 1992 Presidential Campaign. Am. J. Political Sci. 1997, 41, 564–583. [Google Scholar] [CrossRef]
- Devos, T.; Spini, D.; Schwartz, S. Conflicts Among Human Values and Trust in Institutions. Br. J. Soc. Psychol. Br. Psychol. Soc. 2003, 41, 481–494. [Google Scholar] [CrossRef]
- Mari, S.; Gil de Zúñiga, H.; Suerdem, A.; Hanke, K.; Brown, G.; Vilar, R.; Boer, D.; Bilewicz, M. Conspiracy Theories and Institutional Trust: Examining the Role of Uncertainty Avoidance and Active Social Media Use. Political Psychol. 2021, 43, 277–296. [Google Scholar] [CrossRef]
- Devine, D.; Gaskell, J.; Jennings, W.; Stoker, G. Trust and the Coronavirus Pandemic: What are the Consequences of and for Trust? An Early Review of the Literature. Political Stud. Rev. 2021, 19, 274–285. [Google Scholar] [CrossRef]
- Advice for the Public: Coronavirus Disease (COVID-19); Technical Report; Word Health Organization: Geneva, Switzerland, 2021.
- Oosterhoff, B.; Palmer, C.A. Attitudes and Psychological Factors Associated With News Monitoring, Social Distancing, Disinfecting, and Hoarding behaviours Among US Adolescents During the Coronavirus Disease 2019 Pandemic. JAMA Pediatr. 2020, 174, 1184–1190. [Google Scholar] [CrossRef] [PubMed]
- Bobowik, M.; Rupar, M.; Sekerdej, M.; Pastor, E.S.; Arnoso, M.; Ghilani, D.; Ghorbani, F.; Mari, S.; Martinovic, B. Individual and Collective Responsibility within the Context of the COVID-19 Pandemic; Technical Report; laCaixa Foundation: Valencia, Spain, 2021. [Google Scholar]
- Kokkoris, M.D.; Kamleitner, B. Would You Sacrifice Your Privacy to Protect Public Health? Prosocial Responsibility in a Pandemic Paves the Way for Digital Surveillance. Front. Psychol. 2020, 11, 578618. [Google Scholar] [CrossRef] [PubMed]
- Stone, E.S.D. Privacy in organizations: Theoretical issues, research findings, and protection strategies. Res. Pers. Hum. Resour. Manag. 1990, 8, 411–549. [Google Scholar]
- Alge, B. Effects of Computer Surveillance on Perceptions of Privacy and Procedural Justice. J. Appl. Psychol. 2001, 86, 797–804. [Google Scholar] [CrossRef] [PubMed]
- Ryan, R.M.; Connell, J.P. Perceived locus of causality and internalization: Examining reasons for acting in two domains. J. Personal. Soc. Psychol. 1989, 57, 749–761. [Google Scholar] [CrossRef]
- Deci, E.L.; Ryan, R.M. The ”What” and ”Why” of Goal Pursuits: Human Needs and the Self-Determination of behaviour. Psychol. Inq. 2000, 11, 227–268. [Google Scholar] [CrossRef]
- Ng, J.Y.Y.; Ntoumanis, N.; Thøgersen-Ntoumani, C.; Deci, E.L.; Ryan, R.M.; Duda, J.L.; Williams, G.C. Self-Determination Theory Applied to Health Contexts: A Meta-Analysis. Perspect. Psychol. Sci. 2012, 7, 325–340. [Google Scholar] [CrossRef]
- Teixeira, P.; Marques, M.; Silva, M.; Brunet, J.; Duda, J.; Haerens, L.; La Guardia, J.; Lindwall, M.; Lonsdale, C.; Markland, D.; et al. A Classification of Motivation and behaviour Change Techniques Used in Self-Determination Theory-Based Interventions in Health Contexts. Motiv. Sci. 2020, 6, 438–455. [Google Scholar] [CrossRef]
- Chan, D.K.C.; Fung, Y.K.; Xing, S.; Hagger, M.S. Myopia prevention, near work, and visual acuity of college students: Integrating the theory of planned behaviour and self-determination theory. J. Behav. Med. 2014, 37, 369–380. [Google Scholar] [CrossRef]
- Brooks, J.M.; Huck, G.; Iwanaga, K.; Chan, F.; Wu, J.R.; Finnicum, C.A.; Brinck, E.A.; Estala-Gutierrez, V.Y. Towards an integration of the health promotion models of self-determination theory and theory of planned behaviour among people with chronic pain. Rehabil. Psychol. 2018, 63, 553–562. [Google Scholar] [CrossRef]
- Vansteenkiste, M.; Sierens, E.; Soenens, B.; Luyckx, K.; Lens, W. Motivational profiles from a self-determination perspective: The quality of motivation matters. J. Educ. Psychol. 2019, 101, 671–688. [Google Scholar] [CrossRef] [Green Version]
- Paganin, G.; Simbula, S. New Technologies in the Workplace: Can Personal and Organizational Variables Affect the Employees’ Intention to Use a Work-Stress Management App? Int. J. Environ. Res. Public Health 2021, 18, 9366. [Google Scholar] [CrossRef] [PubMed]
- Compeau, D.; Higgins, C.A. Computer Self-Efficacy: Development of a Measure and Initial Test. MIS Q. 1995, 19, 189–211. [Google Scholar] [CrossRef] [Green Version]
- Nimrod, G. Technostress: Measuring a new threat to well-being in later life. Aging Ment. Health 2018, 22, 1086–1093. [Google Scholar] [CrossRef]
- The Jamovi Project. Jamovi (Version 1.6). Technical Report. 2021. Available online: https://www.jamovi.org (accessed on 4 April 2021).
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning: With Applications in R; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Schmidt, P. Assumption Checking of LDA vs. QDA—R Tutorial (Pima Indians Data Set). Technical Report; Personal Blog. 2019. Available online: https://thatdatatho.com/assumption-checking-lda-vs-qda-r-tutorial-2/ (accessed on 22 April 2022).
- Harrell, F.E.J. Regression Modeling Strategies; Technical Report; Vanderbilt University School of Medicine: Nashville, TN, USA, 2022. [Google Scholar]
- Tripathi, A. What is StepAIC in R? Technical Report, Medium. 2019. Available online: https://ashutoshtripathi.com/2019/06/10/what-is-stepaic-in-r/ (accessed on 27 April 2022).
- Brownlee, J. Machine Learning Evaluation Metrics in R. Technical Report; Machine Learning Mastery. 2019. Available online: https://machinelearningmastery.com/machine-learning-evaluation-metrics-in-r/ (accessed on 27 April 2022).
- Dembla, G. Intuition Behind Log-Loss Score; Technical Report; Towards Data Science. 2020. Available online: https://towardsdatascience.com/intuition-behind-log-loss-score-4e0c9979680a (accessed on 27 April 2022).
- Denicolai, S. Immuni: E se Bastasse il 25 Percento di Adozione? Technical Report; Linkedin. 2020. Available online: https://it.linkedin.com/pulse/immuni-e-se-bastasse-il-25-di-adozione-stefano-denicolai (accessed on 20 July 2020). (In Italian).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metrics | Value |
|---|---|
| km.res$totss | 220,847.1 |
| km.res$withinss | [c1 = 20,097.21, c2 = 14,695.99, c3 = 18,055.22] |
| km.res$tot.withinss | 52,848.43 |
| km.res$betweenss | 167,998.6 |
| km.res$betweenss/km.res$tot.withinss | 3.178876 |
| km.res$size | [c1 = 145, c2 = 141, c3 = 122] |
| km.res$betweenss/km.res$totss | 0.7607012 |
| Accuracy | AIC | LogLoss | |
|---|---|---|---|
| Full model | 0.9012346 | 116 | 0.3119839 |
| Step-wise reduction model | 0.9382716 | 52.066 | 0.5360709 |
| Knowledge-based model | 0.9876543 | 48 | 0.6150691 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sarini, M.; Actis Grosso, R.; Magrin, M.E.; Mari, S.; Olivero, N.; Paganin, G.; Simbula, S. A Cluster Analysis of the Acceptance of a Contact Tracing App—The Identification of Profiles for the Italian Immuni Contact Tracing App. Healthcare 2022, 10, 888. https://doi.org/10.3390/healthcare10050888
Sarini M, Actis Grosso R, Magrin ME, Mari S, Olivero N, Paganin G, Simbula S. A Cluster Analysis of the Acceptance of a Contact Tracing App—The Identification of Profiles for the Italian Immuni Contact Tracing App. Healthcare. 2022; 10(5):888. https://doi.org/10.3390/healthcare10050888
Chicago/Turabian StyleSarini, Marcello, Rossana Actis Grosso, Maria Elena Magrin, Silvia Mari, Nadia Olivero, Giulia Paganin, and Silvia Simbula. 2022. "A Cluster Analysis of the Acceptance of a Contact Tracing App—The Identification of Profiles for the Italian Immuni Contact Tracing App" Healthcare 10, no. 5: 888. https://doi.org/10.3390/healthcare10050888