
Discrete Time Hybrid Semi-Markov Models in Manpower Planning


Abstract
:1. Introduction
2. Markov and Semi-Markov Manpower Planning Models
2.1. Markov Model
2.2. Semi-Markov Model
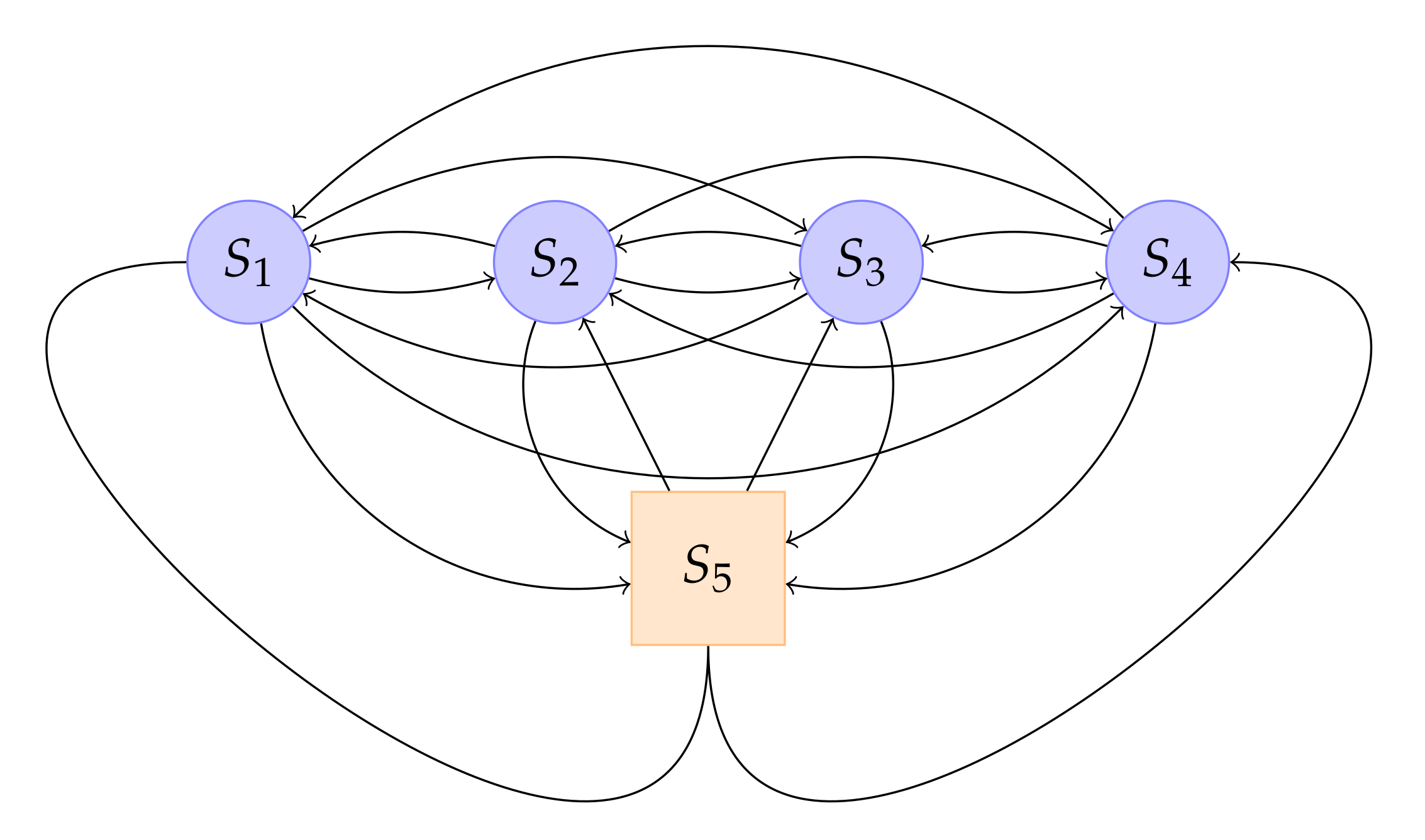
3. Hybrid Semi-Markov Model
4. Application
4.1. Data Handling
4.2. Parameter Estimation and Modeling
- M, a classical Markov model as in Section 2.1;
- SMW, a semi-Markov model as in Section 2.2, where all s are Weibull distributions;
- HSM, the hybrid semi-Markov model as in Section 3 with the s as described above.
4.3. Comparison of the Different Models
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jones, E. An actuarial problem concerning the Royal Marines. J. Staple Inn. Actuar. Soc. 1946, 6, 38–42. [Google Scholar] [CrossRef]
- Vajda, S. The Stratified Semi-Stationary Population. Biometrika 1947, 34, 243–254. [Google Scholar] [CrossRef]
- Vajda, S. Mathematics of Manpower Planning; Wiley: Chichester, UK, 1978. [Google Scholar]
- Bartholomew, D.J. The Statistical Approach to Manpower Planning. Statistician 1971, 20, 3–26. [Google Scholar] [CrossRef]
- Bartholomew, D.J. A Multi-Stage Renewal Process. J. R. Stat. Soc. Ser. B (Methodol.) 1963, 25, 150–168. [Google Scholar] [CrossRef]
- Young, A.; Almond, G. Predicting Distributions of Staff. Comput. J. 1961, 3, 246–250. [Google Scholar] [CrossRef] [Green Version]
- Vassiliou, P.C.G. Asymptotic behavior of Markov systems. J. Appl. Probab. 1982, 19, 851–857. [Google Scholar] [CrossRef]
- Vassiliou, P.C.G.; Papadopoulou, A.A. Non-homogeneous semi-Markov systems and maintainability of the state sizes. J. Appl. Probab. 1992, 29, 519–534. [Google Scholar] [CrossRef]
- Papadopoulou, A.A. Economic Rewards in Non-homogeneous Semi-Markov Systems. Commun. Stat. Theory Methods 2004, 33, 681–696. [Google Scholar] [CrossRef]
- Dimitriou, V.; Georgiou, A.; Tsantas, N. The multivariate non-homogeneous Markov manpower system in a departmental mobility framework. Eur. J. Oper. Res. 2013, 228, 112–121. [Google Scholar] [CrossRef]
- McClean, S.; Montgomery, E.; Ugwuowo, F. Non-homogeneous continuous-time Markov and semi-Markov manpower models. Appl. Stoch. Model. Data Anal. 1997, 13, 191–198. [Google Scholar] [CrossRef]
- McClean, S. Continuous-Time Stochastic Models of a Multigrade Population. J. Appl. Probab. 1978, 15, 26–37. [Google Scholar] [CrossRef]
- Papadopoulou, A.; Vassiliou, P.C. Continuous time non homogeneous semi-Markov systems. In Semi-Markov Models and Applications; Janssen, J., Limnios, N., Eds.; Springer: Boston, MA, USA, 1999; pp. 241–251. [Google Scholar] [CrossRef]
- Mehlmann, A. Semi-Markovian Manpower Models in Continuous Time. Appl. Probab. Probab. 1979, 16, 416–422. [Google Scholar] [CrossRef]
- Esquível, M.L.; Krasii, N.P.; Guerreiro, G.R. Open Markov Type Population Models: From Discrete to Continuous Time. Mathematics 2021, 9, 1496. [Google Scholar] [CrossRef]
- Moore, A.D. The semi-Markov process: A useful tool in the analysis of vegetation dynamics for management. J. Environ. Manag. 1990, 30, 111–130. [Google Scholar] [CrossRef]
- Cohen, J.E. Markov population processes as models of primate social and population dynamics. Theor. Popul. Biol. 1972, 3, 119–134. [Google Scholar] [CrossRef]
- Guerreiro, G.R.; Mexia, J.T.; Miguens, M.F. A Model for Open Populations Subject to Periodical Re-Classifications. J. Stat. Theory Pract. 2010, 4, 303–321. [Google Scholar] [CrossRef]
- Barbu, V.S.; Limnios, N. Semi-Markov chains and hidden semi-Markov models toward applications: Their use in reliability and DNA analysis. In Lecture Notes in Statistics; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2009; Volume 191. [Google Scholar]
- Papadopoulou, A.A. Some Results on Modeling Biological Sequences and Web Navigation with a Semi Markov Chain. Commun. Stat. Theory Methods 2013, 42, 2853–2871. [Google Scholar] [CrossRef]
- Kolias, P.; Papadopoulou, A. Investigating some attributes of periodicity in DNA sequences via semi-Markov modelling. arXiv 2019, arXiv:stat.AP/1907.03119. [Google Scholar]
- Stenberg, F.; Silvestrov, D.; Manca, R. Semi-Markov reward models for disability insurance. Theory Stoch. Process. 2006, 12, 239–254. [Google Scholar]
- Vasileiou, A.; Vassiliou, P.C. An inhomogeneous semi-Markov model for the term structure of credit risk spreads. Adv. Appl. Probab. 2006, 38, 171–198. [Google Scholar] [CrossRef]
- Vassiliou, P.C.; Vasileiou, A. Asymptotic behaviour of the survival probabilities in an inhomogeneous semi-Markov model for the migration process in credit risk. Linear Algebra Its Appl. 2013, 438, 2880–2903. [Google Scholar] [CrossRef]
- D’Amico, G.; Janssen, J.; Manca, R. Valuing credit default swap in a non-homogeneous semi-Markovian rating based model. Comput. Econ. 2007, 29, 119–138. [Google Scholar] [CrossRef]
- D’Amico, G.; Janssen, J.; Manca, R. Initial and final backward and forward discrete time non-homogeneous semi-Markov credit risk models. Methodol. Comput. Appl. Probab. 2010, 12, 215–225. [Google Scholar] [CrossRef]
- D’Amico, G.; Manca, R.; Corini, C.; Petroni, F.; Prattico, F. Tornadoes and related damage costs: Statistical modelling with a semi-Markov approach. Geomat. Nat. Hazards Risk 2016, 7, 1600–1609. [Google Scholar] [CrossRef] [Green Version]
- D’Amico, G.; Petroni, F.; Prattico, F. Wind speed modeled as an indexed semi-{M}arkov process. Environmetrics 2013, 24, 367–376. [Google Scholar] [CrossRef] [Green Version]
- Wu, B.; Maya, B.I.G.; Limnios, N. Using Semi-Markov Chains to Solve Semi-Markov Processes. Methodol. Comput. Appl. Probab. 2020, 1–13. [Google Scholar] [CrossRef]
- Guédon, Y. Hidden hybrid Markov/semi-Markov chains. Comput. Stat. Data Anal. 2005, 49, 663–688. [Google Scholar] [CrossRef] [Green Version]
- McClean, S.I.; Gribbin, J.O. Estimation for incomplete manpower data. Appl. Stoch. Model. Data Anal. 1987, 3, 13–25. [Google Scholar] [CrossRef]
- Kalbfleisch, J.D.; Prentice, R.L. The Statistical Analysis of Failure Time Data; John Wiley & Sons: Hoboken, NJ, USA, 2011; Volume 360. [Google Scholar] [CrossRef]
- McClean, S.; Gribbin, O. A non-parametric competing risks model for manpower planning. Appl. Stoch. Model. Data Anal. 1991, 7, 327–341. [Google Scholar] [CrossRef]
- Howard, R.A. Dynamic Probabilistic Systems: Markov Models; Courier Corporation: North Chelmsford, UK, 2012; Volume 1. [Google Scholar]
- Bickenbach, F.; Bode, E. Markov or Not Markov-This Should Be a Question; Technical Report; Kiel Working Paper; Kiel Institute for the World Economy (IfW): Kiel, Germany, 2001. [Google Scholar]
- Anderson, T.W.; Goodman, L.A. Statistical Inference about Markov Chains. Ann. Math. Stat. 1957, 28, 89–110. [Google Scholar] [CrossRef]
- Vassiliou, P.C. Non-Homogeneous Semi-Markov and Markov Renewal Processes and Change of Measure in Credit Risk. Mathematics 2021, 9, 55. [Google Scholar] [CrossRef]
- Valliant, R.; Milkovich, G. Comparison of Semi-Markov and Markov Models in a Personnel Forecasting Application. Decis. Sci. 1977, 8, 465–477. [Google Scholar] [CrossRef]
- D’Amico, G.; Petroni, F.; Prattico, F. Semi-Markov Models in High Frequency Finance: A Review. arXiv 2013, arXiv:q-fin.ST/1312.3894. [Google Scholar]
- Nakagawa, T.; Yoda, H. Relationships Among Distributions. IEEE Trans. Reliab. 1977, 26, 352–353. [Google Scholar] [CrossRef]
- Barbu, V.; Bérard, C.; Cellier, D.; Sautreuil, M.; Vergne, N. SMM: An R Package for Estimation and Simulation of Discrete-time semi-Markov Models. R J. 2018, 10, 226. [Google Scholar] [CrossRef] [Green Version]
- Papadopoulou, A.; Vassiliou, P.C.G. On the Variances and Convariances of the Duration State Sizes of Semi-Markov Systems. Commun. Stat. Theory Methods 2014, 43, 1470–1483. [Google Scholar] [CrossRef]
- Udom, A.U.; Ebedoro, U.G. On multinomial hidden Markov model for hierarchical manpower systems. Commun. Stat. Theory Methods 2021, 50, 1370–1386. [Google Scholar] [CrossRef]
- Koch, K. Parameter Estimation and Hypothesis Testing in Linear Models, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 1999. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| State | ||
|---|---|---|
| Doctor-assistent | (lecturer with a PhD) | |
| Docent | (assistent professor) | |
| Hoofddocent | (associate professor) | |
| Hoogleraar | (full professor) |
| / | 0.12 | −0.00 | 0 | −3.76 | |
| 0.49 | / | 0.83 | 0 | −1.22 | |
| 0.17 | 0.09 | / | −1.87 | −1.68 | |
| 0 | 0 | 0 | / | −1.10 | |
| 2.05 | 1.12 | 0.08 | 0 | / |
| Model Predictions | |||||||
|---|---|---|---|---|---|---|---|
| M | SMW | HSM | Actual Stocks in 2013 | ||||
| ( | () | () | 229 | ||||
| () | () | 304 | |||||
| () | () | 96 | |||||
| () | () | 64 | |||||
| Selection Criteria | ||
|---|---|---|
| AIC | BIC | |
| M | 7487 | 7624 |
| SMW | 7906 | 8179 |
| HSM | 7409 | 7559 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Verbeken, B.; Guerry, M.-A. Discrete Time Hybrid Semi-Markov Models in Manpower Planning. Mathematics 2021, 9, 1681. https://doi.org/10.3390/math9141681
Verbeken B, Guerry M-A. Discrete Time Hybrid Semi-Markov Models in Manpower Planning. Mathematics. 2021; 9(14):1681. https://doi.org/10.3390/math9141681
Chicago/Turabian StyleVerbeken, Brecht, and Marie-Anne Guerry. 2021. "Discrete Time Hybrid Semi-Markov Models in Manpower Planning" Mathematics 9, no. 14: 1681. https://doi.org/10.3390/math9141681