
Self-Expressive Kernel Subspace Clustering Algorithm for Categorical Data with Embedded Feature Selection



Abstract
:1. Introduction
- We define the self-expressive kernel density estimation approach, in which the symbols can be expressed by probability that is proportional to the kernel bandwidth, and the cluster center is smoothed to the frequency estimator for the categories;
- We propose a non-linear feature-weighted similarity measurement method that gives consideration to the relationship between the attributes;
- We put forward a non-linear optimization method in kernel subspace. Furthermore, we present the SKSCC, an efficient self-expressive kernel subspace clustering algorithm for categorical data that uses feature selection to choose the important attributes;
- A series of experiments on several synthesis and real-world datasets were conducted to compare the performance of the proposed algorithm. The experimental results show that the proposed algorithm outperforms other algorithms in terms of non-linear relationship exploration among attributes and improves the performance and efficiency of clustering.
2. Related Work
3. KDE-Based Similarity for Categorical Data
3.1. Self-Expressive Kernel Density Estimation (SKDE)
3.2. Similarity Measurement Based on Kernel Subspace
- origin polynomial kernel function:
- weighted feature polynomial kernel function:
4. Proposed Clustering Algorithm
4.1. Non-Linear Optimization in Kernel Subspace
- (1)
- When , the inequality clearly holds;
- (2)
- We suppose that the inequality clearly holds when , then,When , let , then, we have:
4.2. SKSCC Clustering Algorithm
- (1)
- Weight ComputingWe define K independent suboptimal objective functions, as follows:Let , then:Let , then:
- (2)
- ClusteringCluster can be generated by dividing into the cluster with the most similarity. The algorithm can be expressed as follows:
| Algorithm 1 SKSCC clustering algorithm. |
| Input: |
| The categorical dataset , the number of clusters K, incentive intensity ; |
| Output: |
| Cluster and weight set W. |
| 1: Initialization: iterations’ times t, t = 0; Set all W to , that’s ; Calculate bandwidth ; Calculate global variance ; Randomly select k objects as the initial cluster center, generating initial datasets, denoted as ; |
| 2: repeat |
| 3: let , divide all the samples into clusters using Equation (25), and then get ; |
| 4: Update cluster center: ; |
| 5: Update W: set , update weight W using Equation (24), then get ; |
| 6: ; |
| 7: until The clustering set does not change, that is, . |
| 8: return and . |
4.3. Optimization of Kernel Bandwidths
- (1)
- The larger the number of samples N, the smaller the bandwidth.The coefficient of N is ; its values’ range is . The larger the number of samples N, the smaller the bandwidths. When , the bandwidth . This is consistent with the effect of bandwidth as the smoothing parameter of the kernel function.
- (2)
- The larger the data dispersion, the larger the bandwidth.Let us calculate the derivative of with respect to as follows:Because , then ; so, is the increasing function with respect to in the range [0,1). The larger the data dispersion , the larger the bandwidth , that is to say, the larger the discreteness of an attribute, the larger the kernel bandwidth corresponding to the attribute. In particular, when an attribute categorical data are uniformly distributed, the corresponding kernel bandwidth takes the maximum value.
5. Experimental Analysis
5.1. Experimental Setup
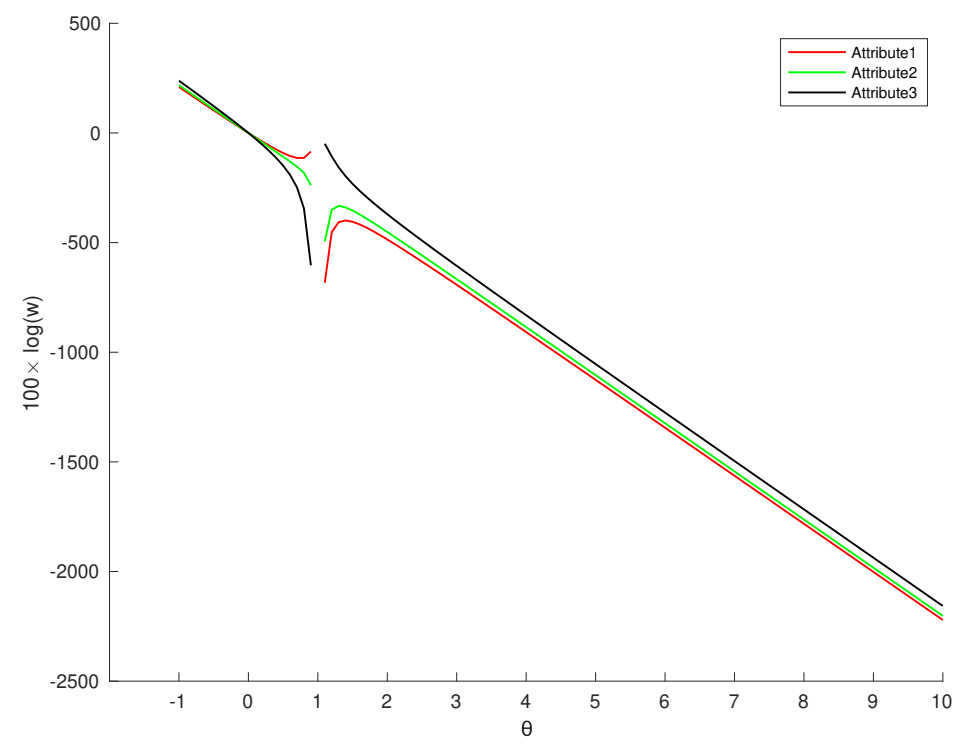
5.2. Discussion of Parameters
- (1)
- When , is the constant, that is, each attribute will be assigned an equal weight;
- (2)
- When , , but all of the weights must meet the restriction , so when , the attribute with the minimum deviation of the sample will be weighted, while the rest of the attributes will be given zero weight; when , the importance of all attributes tends to be the same;
- (3)
- When , the more discrete the attribute, the greater its weight;
- (4)
- When and , the attribute weight is inversely proportional to the dispersion of data distribution. Considering Theorem 1, we should set , but when is too larger, the difference between attribute weights is reduced.
5.3. Analysis of Synthetic Data and Results
- The covariance of attribute 1 and attribute 2 is set to −2 in DataSet1, which makes their attributes a negative correlation. The covariance of attribute 1 and attribute 4 is set to 2, which makes their attributes a positive correlation. The variances are set to be equal on each attribute;
- DataSet2 and DataSet1 are set to the same clusters, but the number of attributes differs. Ten attributes are extracted to set their covariance. The variances are set to be equal on each attribute;
- DataSet3 and DataSet2 are set to the same attributes, but the clusters are different. The variances are set to be equal in two clusters. Ten attributes are extracted to set their covariance;
- DataSet4 is set to the most number of attributes and the clusters. Twenty attributes are extracted to set their covariance in seven clusters. All attributes are set to covariance in one cluster. A half clusters set the same variances, as well as other half clusters.
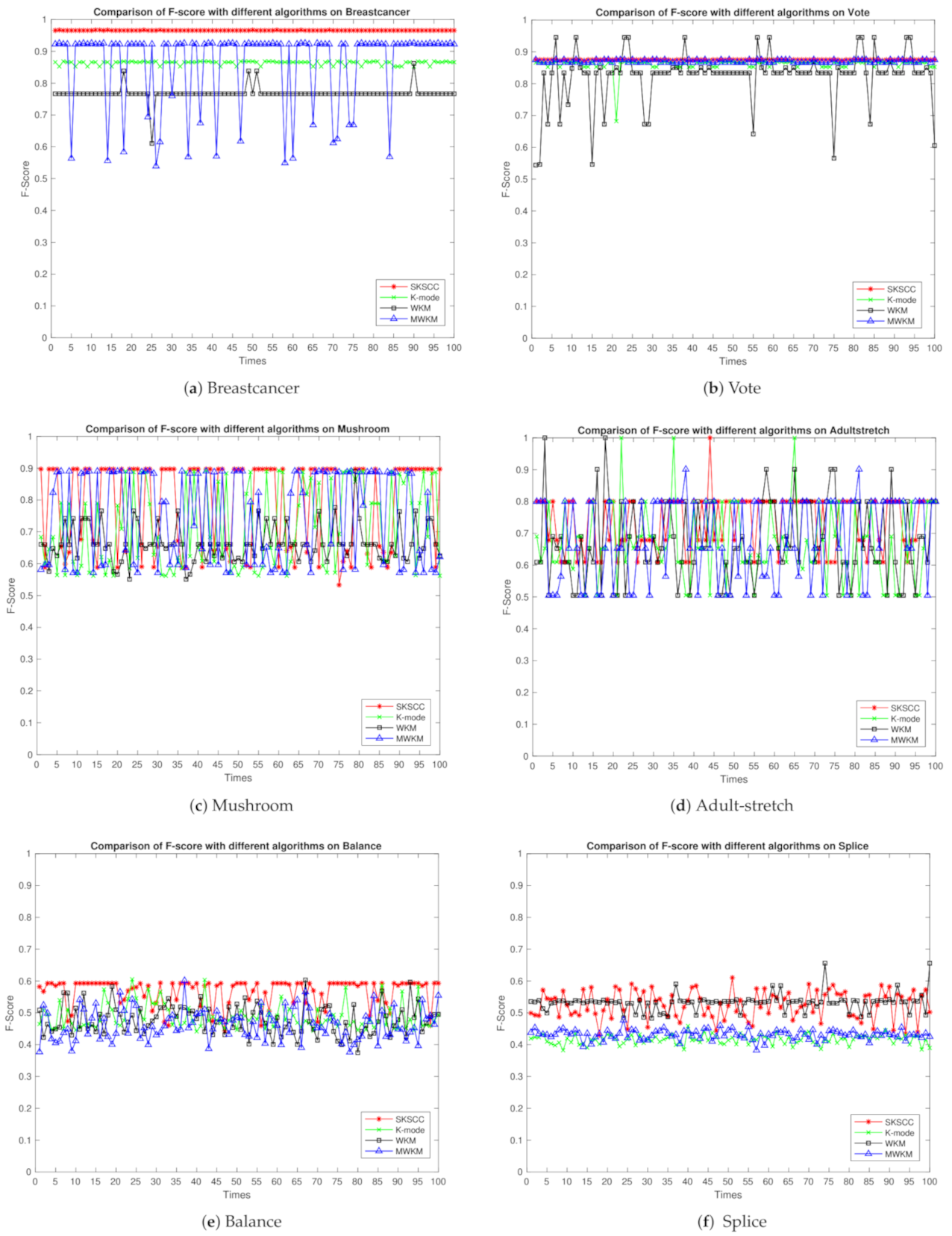
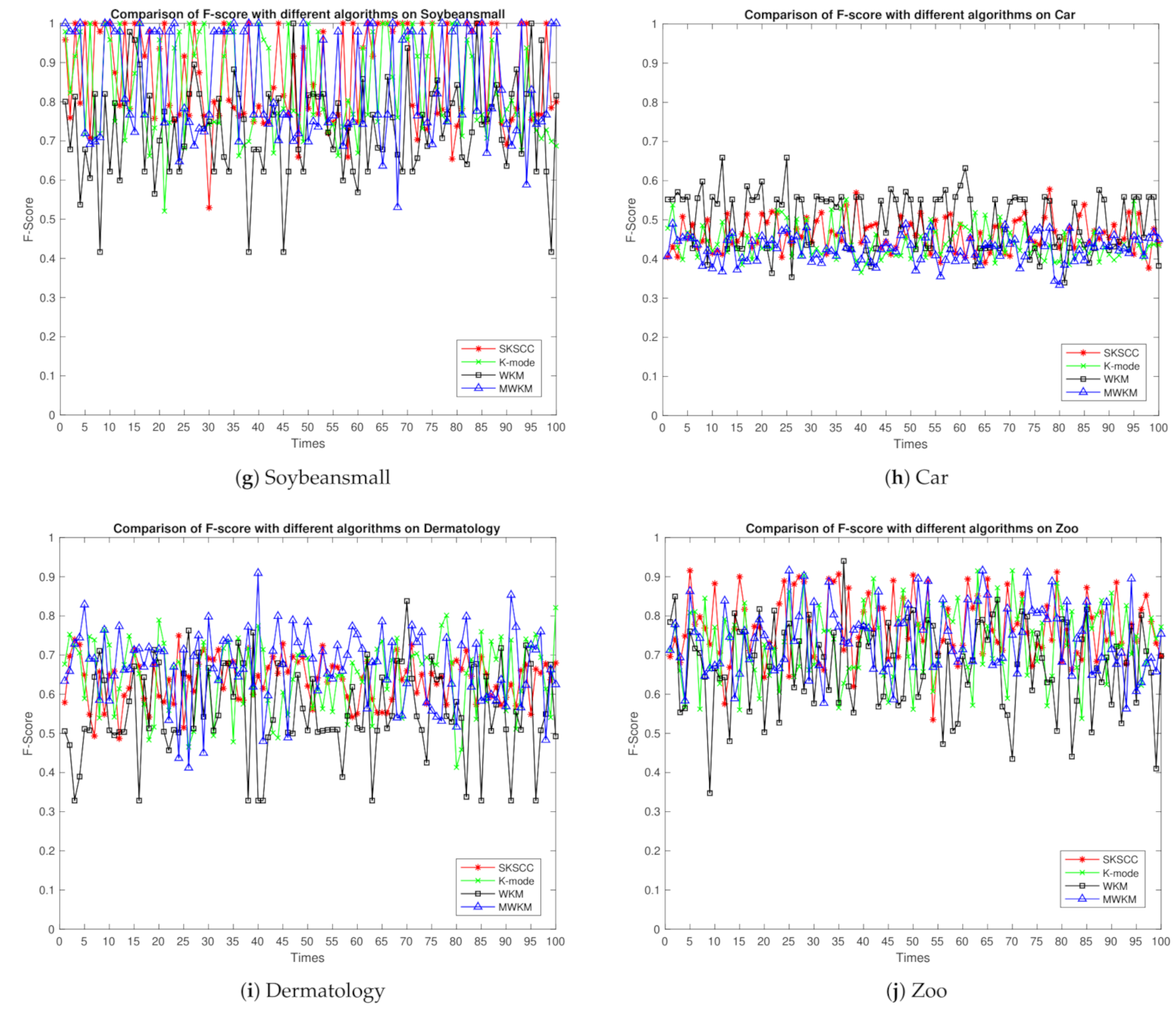
5.4. Analysis of Real-World Data and Results
5.4.1. Real-World Datasets
5.4.2. Comparison of Clustering Quality
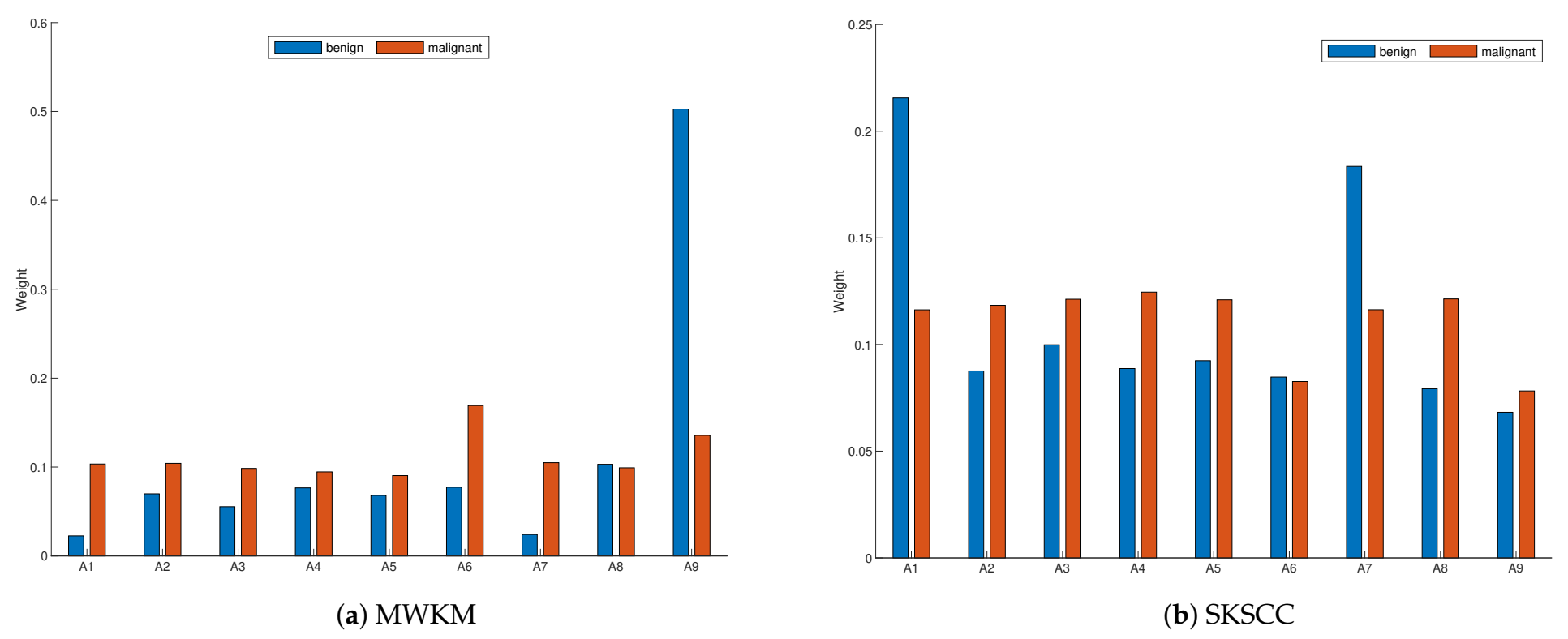
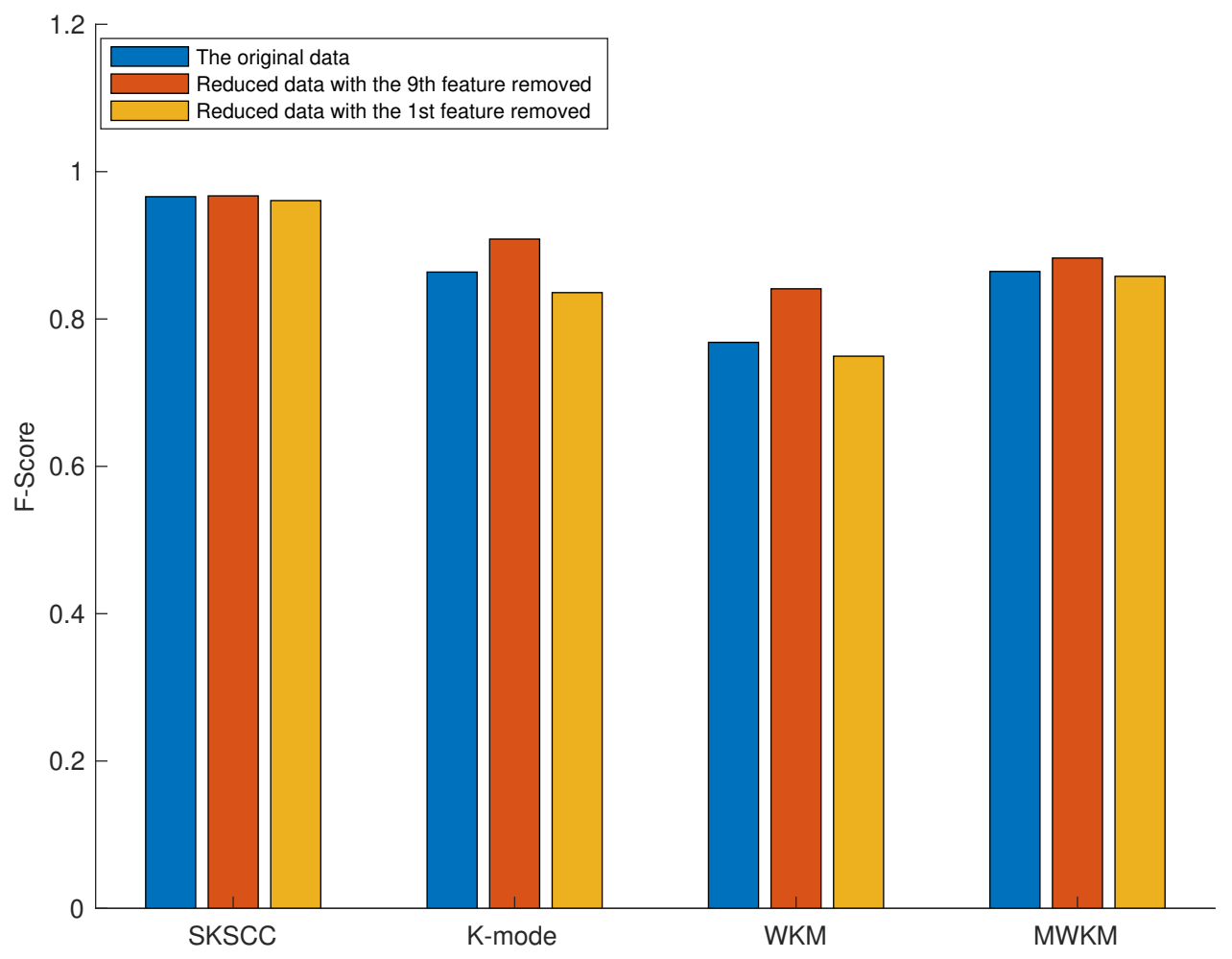
5.4.3. Feature Weighting Results
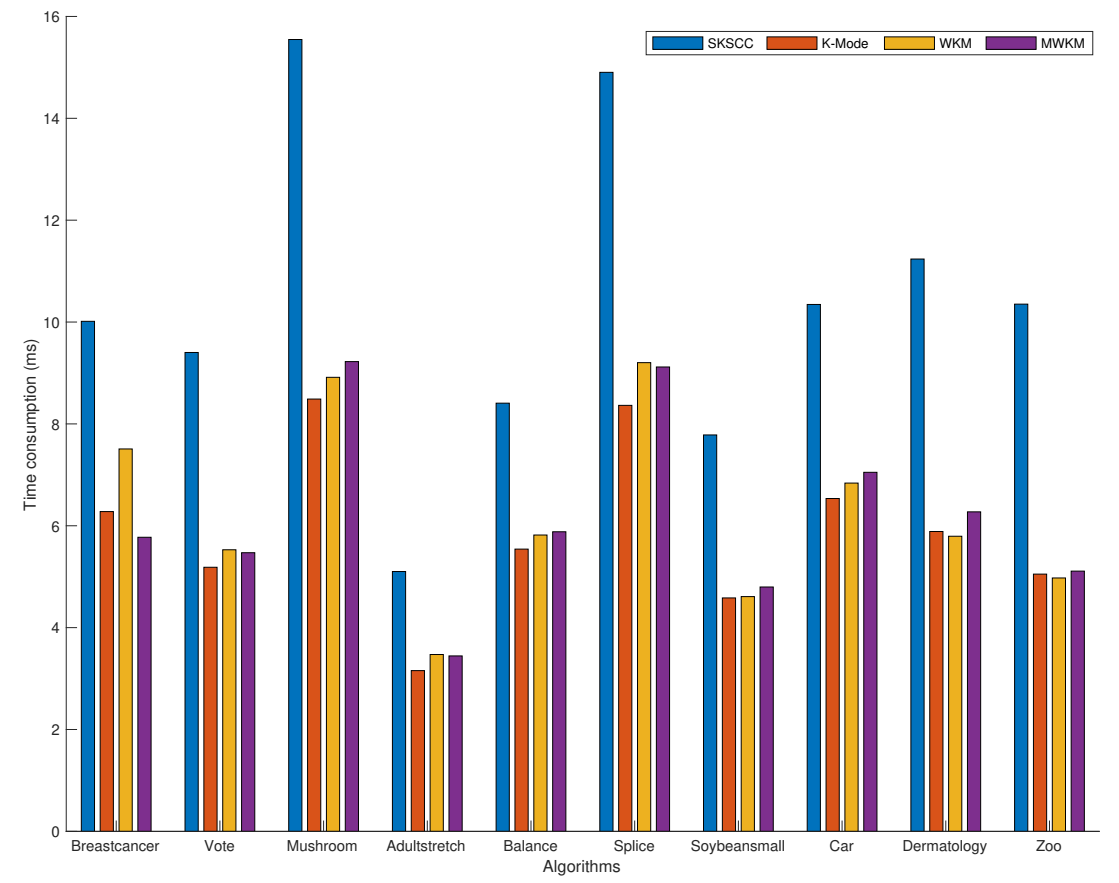
5.4.4. Time Consumption
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Tang, J.; Liu, H. An unsupervised feature selection framework for social media data. IEEE Trans. Knowl. Data Eng. 2014, 26, 2914–2927. [Google Scholar] [CrossRef] [Green Version]
- Alelyani, S.; Tang, J.; Liu, H. Feature selection for clustering: A review. Data Clust. Algorithms Appl. 2013, 29, 144. [Google Scholar]
- Han, J.; Kamber, M. Data Mining: Concepts and Techniques; Morgan Kaufmann: San Francisco, CA, USA, 2001. [Google Scholar]
- Bharti, K.K.; Singh, P.K. A survey on filter techniques for feature selection in text mining. In Proceedings of the Second International Conference on Soft Computing for Problem Solving (SocProS 2012), Jaipur, India, 28–30 December 2012; Springer: New Delhi, India, 2014; pp. 1545–1559. [Google Scholar]
- Yasmin, M.; Mohsin, S.; Sharif, M. Intelligent image retrieval techniques: A survey. J. Appl. Res. Technol. 2014, 12, 87–103. [Google Scholar] [CrossRef] [Green Version]
- Saeys, Y.; Inza, I.; Larranaga, P. A review of feature selection techniques in bioinformatics. Bioinformatics 2007, 23, 2507–2517. [Google Scholar] [CrossRef] [Green Version]
- Frank, A. UCI Machine Learning Repository. 2010. Available online: http://archive.ics.uci.edu/ml (accessed on 28 March 2021).
- Jain, A.K.; Murty, M.N.; Flynn, P.J. Data clustering: A review. ACM Comput. Surv. (CSUR) 1999, 31, 264–323. [Google Scholar] [CrossRef]
- Xu, R.; Wunsch, D. Survey of clustering algorithms. IEEE Trans. Neural Netw. 2005, 16, 645–678. [Google Scholar] [CrossRef] [Green Version]
- Jain, A.K. Data clustering: 50 years beyond k-mean. Pattern Recognit. Lett. 2010, 31, 651–666. [Google Scholar] [CrossRef]
- Wu, S.; Lin, J.; Zhang, Z.; Yang, Y. Hesitant fuzzy linguistic agglomerative hierarchical clustering algorithm and its application in judicial practice. Mathematics 2021, 9, 370. [Google Scholar] [CrossRef]
- Guha, S.; Rastogi, R.; Shim, K. ROCK: A robust clustering algorithm for categorical attributes. Inf. Syst. 2000, 25, 345–366. [Google Scholar] [CrossRef]
- Andritsos, P.; Tzerpos, V. Information-theoretic software clustering. IEEE Trans. Softw. Eng. 2005, 31, 150–165. [Google Scholar] [CrossRef]
- Andritsos, P.; Tsaparas, P.; Miller, R.J.; Sevcik, K.C. LIMBO: Scalable clustering of categorical data. In Proceedings of the International Conference on Extending Database Technology, Heraklion, Crete, Greece, 14–18 March 2004; Springer: Berlin/Heidelberg, Germany, 2004; pp. 123–146. [Google Scholar]
- Qin, H.; Ma, X.; Herawan, T.; Zain, J.M. MGR: An information theory based hierarchical divisive clustering algorithm for categorical data. Knowl.-Based Syst. 2014, 67, 401–411. [Google Scholar] [CrossRef] [Green Version]
- Xiong, T.; Wang, S.; Mayers, A.; Monga, E. DHCC: Divisive hierarchical clustering of categorical data. Data Min. Knowl. Discov. 2012, 24, 103–135. [Google Scholar] [CrossRef]
- Huang, Z. Extensions to the k-means algorithm for clustering large data sets with categorical values. Data Min. Knowl. Discov. 1998, 2, 283–304. [Google Scholar] [CrossRef]
- Huang, Z.; Ng, M.K. A fuzzy k-modes algorithm for clustering categorical data. IEEE Trans. Fuzzy Syst. 1999, 7, 446–452. [Google Scholar] [CrossRef] [Green Version]
- Ng, M.K.; Li, M.J.; Huang, J.Z.; He, Z. On the impact of dissimilarity measure in k-modes clustering algorithm. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 503–507. [Google Scholar] [CrossRef] [PubMed]
- Bai, L.; Liang, J.; Dang, C.; Cao, F. The impact of cluster representatives on the convergence of the k-modes type clustering. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 1509–1522. [Google Scholar] [CrossRef] [PubMed]
- Cao, F.; Liang, J.; Li, D.; Zhao, X. A weighting k-modes algorithm for subspace clustering of categorical data. Neurocomputing 2013, 108, 23–30. [Google Scholar] [CrossRef]
- Chan, E.Y.; Ching, W.K.; Ng, M.K.; Huang, J.Z. An optimization algorithm for clustering using weighted dissimilarity measures. Pattern Recognit. 2004, 37, 943–952. [Google Scholar] [CrossRef]
- Bai, L.; Liang, J.; Dang, C.; Cao, F. A novel attribute weighting algorithm for clustering high-dimensional categorical data. Pattern Recognit. 2011, 44, 2843–2861. [Google Scholar] [CrossRef]
- Chen, L.; Wang, S.; Wang, K.; Zhu, J. Soft subspace clustering of categorical data with probabilistic distance. Pattern Recognit. 2016, 51, 322–332. [Google Scholar] [CrossRef]
- Han, J.; Kamber, M.; Pei, J. Data mining concepts and techniques third edition. Morgan Kaufmann Ser. Data Manag. Syst. 2011, 5, 83–124. [Google Scholar]
- Guyon, I.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Breiman, L.; Friedman, J.; Stone, C.J.; Olshen, R.A. Classification and Regression Trees; CRC Press: Boca Raton, FL, USA, 1984. [Google Scholar]
- Kohavi, R.; John, G.H. Wrappers for feature subset selection. Artif. Intell. 1997, 97, 273–324. [Google Scholar] [CrossRef] [Green Version]
- Pashaei, E.; Aydin, N. Binary black hole algorithm for feature selection and classification on biological data. Appl. Soft Comput. 2017, 56, 94–106. [Google Scholar] [CrossRef]
- Rasool, A.; Tao, R.; Kamyab, M.; Hayat, S. Gawa—A feature selection method for hybrid sentiment classification. IEEE Access 2020, 8, 191850–191861. [Google Scholar] [CrossRef]
- Liu, H.; Setiono, R. Chi2: Feature selection and discretization of numeric attributes. In Proceedings of the 7th IEEE International Conference on Tools with Artificial Intelligence, Herndon, VA, USA, 5–8 November 1995; pp. 388–391. [Google Scholar]
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef] [Green Version]
- Quinlan, J.R. C4. 5: Programs for Machine Learning; Elsevier: Amsterdam, The Netherlands, 2014. [Google Scholar]
- Kandaswamy, K.K.; Pugalenthi, G.; Hazrati, M.K.; Kalies, K.U.; Martinetz, T. BLProt: Prediction of bioluminescent proteins based on support vector machine and relieff feature selection. BMC Bioinform. 2011, 12, 345. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shao, J.; Liu, X.; He, W. Kernel based data-adaptive support vector machines for multi-class classification. Mathematics 2021, 9, 936. [Google Scholar] [CrossRef]
- Robnik-Šikonja, M.; Kononenko, I. Theoretical and empirical analysis of ReliefF and RReliefF. Mach. Learn. 2003, 53, 23–69. [Google Scholar] [CrossRef] [Green Version]
- Le, T.T.; Urbanowicz, R.J.; Moore, J.H.; McKinney, B.A. Statistical inference Relief (STIR) feature selection. Bioinformatics 2019, 35, 1358–1365. [Google Scholar] [CrossRef]
- Huang, Z.; Yang, C.; Zhou, X.; Huang, T. A hybrid feature selection method based on binary state transition algorithm and ReliefF. IEEE J. Biomed. Health Inform. 2018, 23, 1888–1898. [Google Scholar] [CrossRef] [PubMed]
- Deng, Z.; Chung, F.L.; Wang, S. Robust relief-feature weighting, margin maximization, and fuzzy optimization. IEEE Trans. Fuzzy Syst. 2010, 18, 726–744. [Google Scholar] [CrossRef]
- Chen, L.F. A probabilistic framework for optimizing projected clusters with categorical attributes. Sci. China Inf. Sci. 2015, 58, 1–15. [Google Scholar] [CrossRef]
- Kong, R.; Zhang, G.; Shi, Z.; Guo, L. Kernel-based k-means clustering. Comput. Eng. 2004, 30, 12–14. [Google Scholar]
- Elhamifar, E.; Vidal, R. Sparse subspace clustering: Algorithm, theory, and applications. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2765–2781. [Google Scholar] [CrossRef] [Green Version]
- Ji, P.; Zhang, T.; Li, H.; Salzmann, M.; Reid, I. Deep subspace clustering networks. arXiv 2017, arXiv:1709.02508. [Google Scholar]
- You, C.; Li, C.G.; Robinson, D.P.; Vidal, R. Oracle based active set algorithm for scalable elastic net subspace clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 3928–3937. [Google Scholar]
- Chen, L.; Guo, G.; Wang, S.; Kong, X. Kernel learning method for distance-based classification of categorical data. In Proceedings of the 2014 14th UK Workshop on Computational Intelligence (UKCI), Bradford, UK, 8–10 September 2014; pp. 1–7. [Google Scholar]
- Ouyang, D.; Li, Q.; Racine, J. Cross-validation and the estimation of probability distributions with categorical data. J. Nonparametr. Stat. 2006, 18, 69–100. [Google Scholar] [CrossRef]
- Huang, Z. Clustering large data sets with mixed numeric and categorical values. In Proceedings of the 1st Pacific-Asia Conference on Knowledge Discovery and Data Mining (PAKDD), Singapore, 23–24 February 1997; pp. 21–34. [Google Scholar]
- Cheung, Y.M.; Jia, H. Categorical-and-numerical-attribute data clustering based on a unified similarity metric without knowing cluster number. Pattern Recognit. 2013, 46, 2228–2238. [Google Scholar] [CrossRef]
- Zhong, S.; Chen, D.; Xu, Q.; Chen, T. Optimizing the gaussian kernel function with the formulated kernel target alignment criterion for two-class pattern classification. Pattern Recognit. 2013, 46, 2045–2054. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attributes (D) | Clusters (K) | Samples (N) | |
|---|---|---|---|
| Datasets1 | 6 | 2 | 1000 |
| Datasets2 | 20 | 2 | 1000 |
| Datasets3 | 20 | 4 | 1000 |
| Datasets4 | 40 | 8 | 1000 |
| Index | Datasets | K-Mode [17] | WKM [22] | MWKM [23] | SKSCC |
|---|---|---|---|---|---|
| F-Score | Datasets1 | 0.9823 ± 0.0000 | 0.9489 ± 0.0079 | 0.9738 ± 0.0018 | |
| Datasets2 | 0.9762 ± 0.0015 | 0.9860 ± 0.0000 | 0.9860 ± 0.0000 | ||
| Datasets3 | 0.6346 ± 0.0011 | 0.5766 ± 0.0018 | 0.6311 ± 0.0009 | ||
| Datasets4 | 0.5268 ± 0.0008 | 0.3839 ± 0.0033 | 0.5367 ± 0.0010 | ||
| Accuracy | Datasets1 | 0.9823 ± 0.0000 | 0.9589 ± 0.0038 | 0.9746 ± 0.0012 | |
| Datasets2 | 0.9762 ± 0.0015 | 0.9860 ± 0.0000 | 0.9860 ± 0.0000 | ||
| Datasets3 | 0.6755 ±0.0016 | 0.6037 ± 0.0024 | 0.6644 ± 0.0009 | ||
| Datasets4 | 0.5863 ± 0.0013 | 0.5053 ± 0.0147 | 0.5848 ± 0.0014 |
| No. | UCI Datasets | Attributes (D) | Clusters (K) | Samples (N) |
|---|---|---|---|---|
| 1 | Breastcancer | 9 | 2 | 699 |
| 2 | Vote | 16 | 2 | 435 |
| 3 | Mushroom | 21 | 2 | 8124 |
| 4 | Adult+stretch | 4 | 2 | 20 |
| 5 | Balance | 4 | 3 | 625 |
| 6 | Splice | 60 | 3 | 3190 |
| 7 | Soybeansmall | 35 | 4 | 47 |
| 8 | Car | 6 | 4 | 1728 |
| 9 | Dermatology | 33 | 6 | 366 |
| 10 | Zoo | 15 | 7 | 101 |
| Index | Datasets | K-Mode [17] | WKM [22] | MWKM [23] | SKSCC |
|---|---|---|---|---|---|
| F-Score | Breastcancer | 0.8637 ± 0.0000 | 0.7683 ± 0.0005 | 0.8645 ± 0.0155 | |
| Vote | 0.8610 ± 0.0000 | 0.8238 ± 0.0073 | 0.8698 ± 0.0000 | ||
| Mushroom | 0.7159 ± 0.0171 | 0.6645 ± 0.0034 | 0.7480 ± 0.0202 | ||
| Adult + stretch | 0.6691 ± 0.0135 | 0.6722 ± 0.0159 | 0.6876 ± 0.0163 | ||
| Balance | 0.4882 ± 0.0016 | 0.4782 ± 0.0022 | 0.4630 ± 0.0024 | ||
| Splice | 0.4155 ± 0.0000 | 0.4313 ± 0.0000 | |||
| Soybeansmall | 0.8324 ± 0.0152 | 0.7336 ± 0.0157 | 0.8436 ± 0.0175 | ||
| Car | 0.4412 ± 0.0018 | 0.4268 ± 0.0012 | 0.4738 ± 0.0028 | ||
| Dermatology | 0.6476 ± 0.0083 | 0.5573 ± 0.0136 | 0.6357 ± 0.0034 | ||
| Zoo | 0.7273 ± 0.0090 | 0.6716 ± 0.0130 | 0.7417 ± 0.0074 | ||
| Accuracy | Breastcancer | 0.8621 ± 0.0000 | 0.8284 ± 0.0000 | 0.8659 ± 0.0156 | |
| Vote | 0.8625 ± 0.0000 | 0.8244 ± 0.0066 | 0.8681 ± 0.0000 | ||
| Mushroom | 0.7536 ± 0.0134 | 0.8481 ± 0.0157 | 0.7733 ± 0.0143 | 0.8194 ± 0.0131 | |
| Adult + stretch | 0.7150 ± 0.0160 | 0.7165 ± 0.0168 | 0.6910 ± 0.0159 | ||
| Balance | 0.5251 ± 0.0010 | 0.4629 ± 0.0033 | 0.4327 ± 0.0024 | ||
| Splice | 0.4237 ± 0.0000 | 0.4314 ± 0.0000 | |||
| Soybeansmall | 0.8740 ± 0.0110 | 0.8915 ± 0.0110 | 0.9085 ± 0.0083 | ||
| Car | 0.4023 ± 0.0013 | 0.3593 ± 0.0000 | 0.4251 ± 0.0038 | ||
| Dermatology | 0.7085 ± 0.0076 | 0.7367 ± 0.0063 | 0.6911 ± 0.0048 | ||
| Zoo | 0.7937 ± 0.0066 | 0.7895 ± 0.0073 | 0.8043 ± 0.0061 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, H.; Xu, K.; Chen, L.; Jiang, Q. Self-Expressive Kernel Subspace Clustering Algorithm for Categorical Data with Embedded Feature Selection. Mathematics 2021, 9, 1680. https://doi.org/10.3390/math9141680
Chen H, Xu K, Chen L, Jiang Q. Self-Expressive Kernel Subspace Clustering Algorithm for Categorical Data with Embedded Feature Selection. Mathematics. 2021; 9(14):1680. https://doi.org/10.3390/math9141680
Chicago/Turabian StyleChen, Hui, Kunpeng Xu, Lifei Chen, and Qingshan Jiang. 2021. "Self-Expressive Kernel Subspace Clustering Algorithm for Categorical Data with Embedded Feature Selection" Mathematics 9, no. 14: 1680. https://doi.org/10.3390/math9141680