1. Introduction
In contrast to the mean-based regression that mainly gives an overall quantification for the central covariate effect, quantile regression can directly model a series of quantiles (from lower to higher) of the response variable to deliver a global evaluation of the covariate effect [
1,
2]. A major advantage of quantile regression is that no assumptions about the distribution of the response are required, which makes it practical, robust and amenable to skewed response distributions [
3]. Additionally, quantile regression methods can help to handle the cases of heteroscedasticity [
4]. Nowadays, quantile regressions have been widely used in many fields, established numerous methodologies covering linear, nonlinear and longitudinal quantile regressions [
5,
6], as well as applications in survival analysis [
7]. Application studies show that quantile regression allows adjustment for potential confounders and calculation of interaction terms and variable selection, while being more robust to statistical outliers and yielding much more information about the underlying associations [
1,
3]. However, the computation of quantile regressions is relatively complex and somewhat unique, especially compared with ordinary least squares for mean-based linear (or nonlinear) regressions. Take a 0.5 quantile estimation as an example: the quantile regression minimizes the sum of weighted absolute residuals instead of squared residuals [
8]. One drawback of quantile regressions is that the estimation efficiency fluctuates a lot at different quantiles and is relatively low at the tails [
9]. A traditional quantile regression is typically based on minimizing a check loss function [
1], but often the relative quantile loss could be more relevant than the check loss function and hence might be used to gain more efficiency for inference. So far, to the best of our knowledge, there have been no consistent studies on other type of loss functions, such as the relative error loss for quantile regression.
In many practical applications, the magnitude of the relative error, rather than the absolute error, is of the major concern. In general, the relative error is more relevant when the range of predicted values is large and that of predictors is small. Narula and Wellington (1977) proposed an estimation approach for linear models by minimizing the sum of relative errors [
10], without any theoretical results. Khoshgoftaar et al. (1992) studied the asymptotic properties of the estimators by minimizing both the squared relative loss and the absolute relative loss under nonlinear regression models [
11], and made a great comparative study on them. Later, Chen et al. (2010) applied the least absolute relative error loss [
12] for the linear regression model
and proposed to estimate the model parameters by minimizing the sum of the absolute relative error
where
and they assumed
has a mean of 1. Motivated by [
12], Yang and Ye (2013) established the connection between relative error estimators and the M-estimation under a linear model [
13]. However, their works only consider the absolute relative loss, not related to any quantile estimates of model distribution. None of these studies discussed the way to apply the relative error for a general quantile regression.
In this article, we propose a general class of relative loss functions via a Box–Cox transformation [
14,
15]. The proposed loss function includes the absolute loss and the relative loss as special cases. We also show that the proposed loss function is convex, scale-free and able to be elicited. We apply the proposed loss function for a linear quantile regression [
1] and prove that the estimates of the regression coefficients are consistent and asymptotically normal. Through numerical studies on two concrete examples that have well-derived theoretical solutions, we show that the proposed method is feasible and verify that the numerical results have the expected theoretical properties obtained from the theoretical study. We also apply the proposed method to a prostate cancer study, showing that our method provides more accurate statistical inferences on quantile estimates compared to the regular quantile regression, especially at the region of tail quantiles.
The rest of this article is organized as follows. In
Section 2, we introduce the model and propose the estimation procedure. In
Section 3, we establish the consistency and asymptotic normality for the parameter estimates under certain regularity conditions. In
Section 4, we examine the finite-sample properties using two simple simulations. An application example is given in
Section 5 with a prostate cancer study. We conclude with a brief summary and remarks in
Section 6.
2. Model and Methods
Let
be the response of interest and
be a
-dimensional covariate with the first element being 1. Consider a linear quantile regression model
where
is a
-dimensional coefficient for some
, and
is a random error with the
th quantile being equal to 0 conditional on
. In model (
1),
could also be replaced by any other reasonable monotone transformation, but considering that a linear relationship in the transformed model may not be linear in the original scale, one may need to transform the result back to the original measurement scale for the interpretation.
Through an exponential transformation, model (
1) can be rewritten as
where
,
. Denote
as a monotone function of real value, then according to the equivariance property of quantiles,
holds for any random error
. Here,
is the
th conditional quantile of
given
X. This characteristic enables us to consider quantile regressions under a proper transformation of the random error so as to enhance the estimation efficiency.
To this end, we propose to conduct the model regression using a general class of relative loss functions, which leads to the objective function in the form
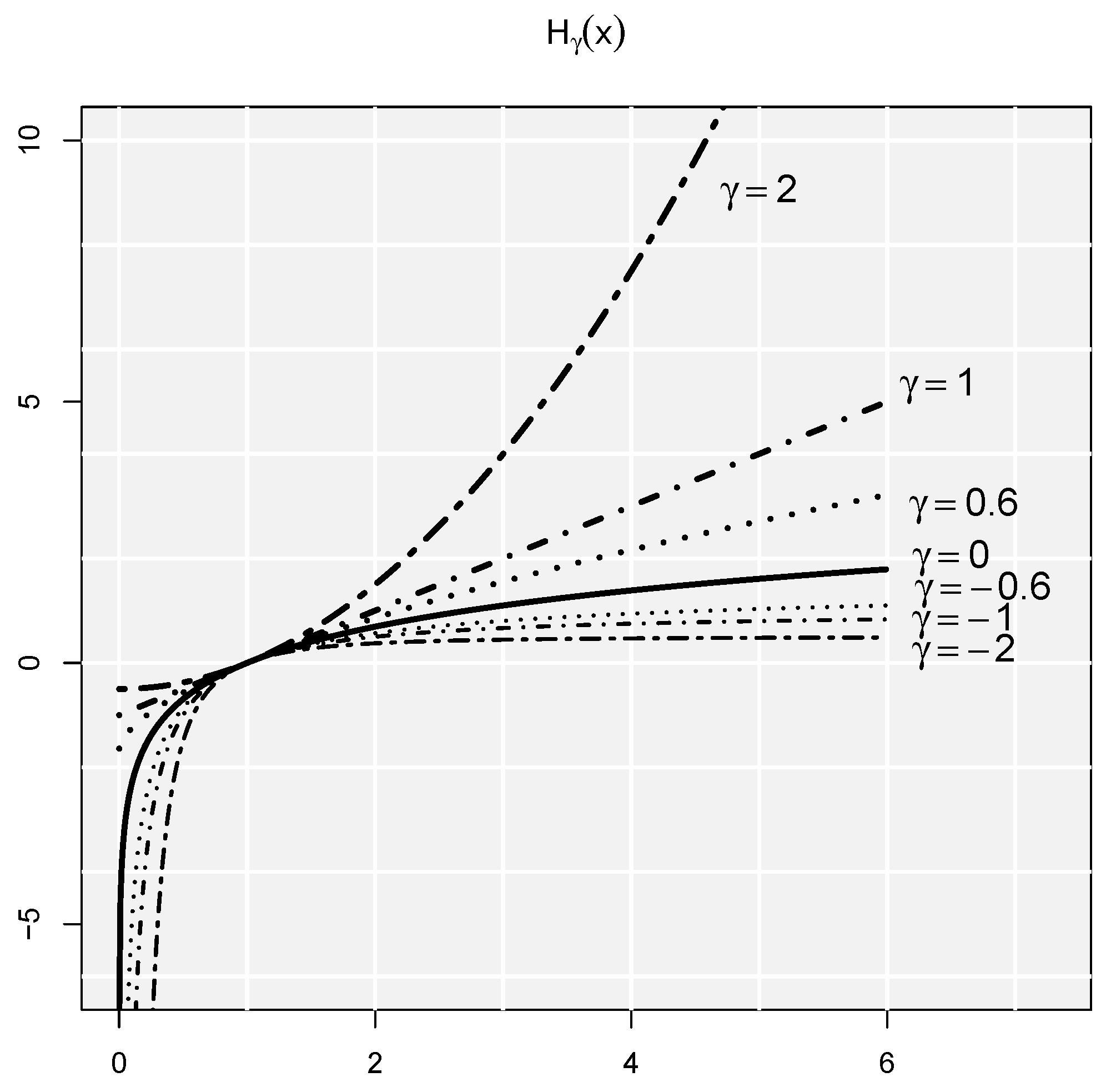
where
is the traditional quantile loss function and
takes the Box–Cox transformation with
for
and
for
(see
Figure 1).
The objective function, (
3), can be further simplified as
where
if
, otherwise
is a general relative loss function. In particular, if
, (
4) is reduced to the objective function of traditional quantile regression, and if
and
, (
4) is reduced to
which is exactly the objective function of the least absolute relative error in [
12].
The proposed framework is very flexible—it allows us to adapt the quantile regression to either the absolute or relative loss or somewhere in between by tuning the parameter
. Furthermore, the function
in (
4) can guarantee the proposed criterion function to be convex (see Lemma A1), scale-free, and able to be elicited (see Definition 2 in [
16]). Therefore, given
, the minimizer of
with respect to
, denoted as
, can be obtained conveniently using classical algorithms, such as the Nelder–Mead simplex method recommended by Yin and Cai [
17].
3. Asymptotic Properties
3.1. Conditions and Main Results
We assumed that , , are independent. Let and be the cumulative distribution functions of and , and be the conditional distribution function of given X. We considered a random design for X and used to denote the corresponding density function that is almost definitely continuous in the neighborhood of 1. To establish the asymptotic properties of the estimators under a certain metric, we imposed regularity conditions as follows:
- (C1)
Covariate X is bounded and does not concentrate on any hyperplane of p dimensions.
- (C2)
For any fixed , it holds that and .
- (C3)
If for any fixed , then .
- (C4)
is a positive definite.
Condition (C1) is regular, and condition (C2) ensures the consistency and asymptotic normality, which can be treated as a generalized version of the zero mean and zero median assumptions for the least square estimation and least absolute deviation regression methods, respectively. Condition (C3) guarantees the identifiability of the adaptive parameter and regression parameters. Condition (C4) is to ensure the asymptotic normality of the estimates of the regression coefficients, similar to the finite second moment condition for the least square estimator in linear regressions.
Theorem 1. Under conditions (C1)–(C4), for any and any finite , is a constantin probability as , where indicates the Euclidean norm. Proof of Theorem 1. By the results of Lemma A1 in
Appendix A, we know that
is a convex function with respect to
. According to the Convexity Lemma [
18], it holds that
with the probability as
and the function
is necessarily convex on
. Through an algebraic calculation, we obtain
According to the Knight’s identity [
19], it holds that
Then, by using the Knight’s identity we obtain
and similarly we obtain
The first term in the summand of right-hand side is equal to 0 by condition (C2). By condition (C2) and the fact that
which implies
. We know the second term in (
7) is non-negative. The third term in (
7) is equivalent to
As the upper limits of both
and
always have same signs, plus the fact that the integrated functions
and
are all monotone functions with respect to
s and the signs of the integrated functions are also consistent with those of the upper limits of the integrations, we know that (
9) is also non-negative. Thus,
ensures
As is the unique minimizer of , it follows from conditions (C1), (C3) and that is the unique minimizer of .
When
, then for every
,
, such that
for
. For any
and a constant
, suppose the minimizer of
, i.e.
, is achieved in
. Following (
5), we know that
in probability as
, and
. So
holds in probability for any constant
. This is contradictory to (
5). Hence, the minimum of
can only be achieved in
. By the randomness of
, we know
in probability as
. □
Theorem 2. Under conditions (C1)–(C4), for any and any finite ,where , and . In particular, if ε follows a symmetric distribution with the symmetrical axis , then . Proof of Theorem 2. To prove the asymptotic normality, we approximate
for every
in a neighborhood of
first. By the proof in Theorem 1, we know
where
and
The item
can be expanded near
as
Note that the item
equals
Thus,
where
and
.
Let
. Observe that
we next claim that
in probability as
. Let
, then the above equation is equivalent to
Similar to the proof of Lemma B.4 in [
20], using the arguments of VC-subgraph classes we can show
with probability as
. Then, according to (
10) and the Taylor expansion in the first term, (
11) holds.
Let
, then
is convex and thus has a unique minimizer
. By (
12), we know that
uniformly holds over
. Thus,
, that is,
Hence, , where and . □
3.2. Adaptive Criteria for Choosing
The loss function defined in (
4) provides a flexible framework that allows us to conduct a quantile regression adaptively to practical scenario. However, how to choose the tuning parameter
for the proposed loss function adaptively to real data is a challenging but important problem. Reasonable criteria for choosing the tuning parameter need to be explored, so with that we could select the optimal
based on the criterion using data-driven techniques.
In this article, we investigate two criteria as follows:
- (i)
Criterion (I) selects the that minimizes the objective function for at each given ;
- (ii)
Criterion (II) selects the that minimizes the variance of at each given .
According to Lemma A1, we conclude that
. That is, the proposed quantile regression approach is equivalent to the traditional quantile regression under criterion (I). Thus, the optimal
selected by criterion (I) provides the best model fitting at each quantile in the sense of regular quantile regression. Criterion (II) selects
, which reshapes the distribution of residuals for obtaining the best estimation efficiency. The optimal
selected by criterion (II) is denoted as
. According to the derived asymptotic covariance matrix in Theorem 2, we know that the value of
depends on
as well as the distribution of
. For a fixed
and a specified distribution of
, minimizing the variance of
is equivalent to maximizing
, and thus
In the sequel, we mainly discuss the performance of criterion (II).
Remark 1. To estimate the asymptotic variance for a given γ, we recommend to use the wild bootstrap technique. Definewhere is a sequence of i.i.d nonnegative random variables with both mean and variance equal to 1. Let , and then the distribution of can be approximated by the resampling distribution of , where is the minimizer of (4). The standard error of can be approximately estimated by the empirical standard error of . Remark 2. People can also define other criteria, such as selecting by minimizing the summation of the standardized and the standardized variance of , we denote this criterion as (III), then the selected shall be between 0 and . In practice, it is hard to assess whether a criterion is better than another one. The criterion that fits practical needs is the best.
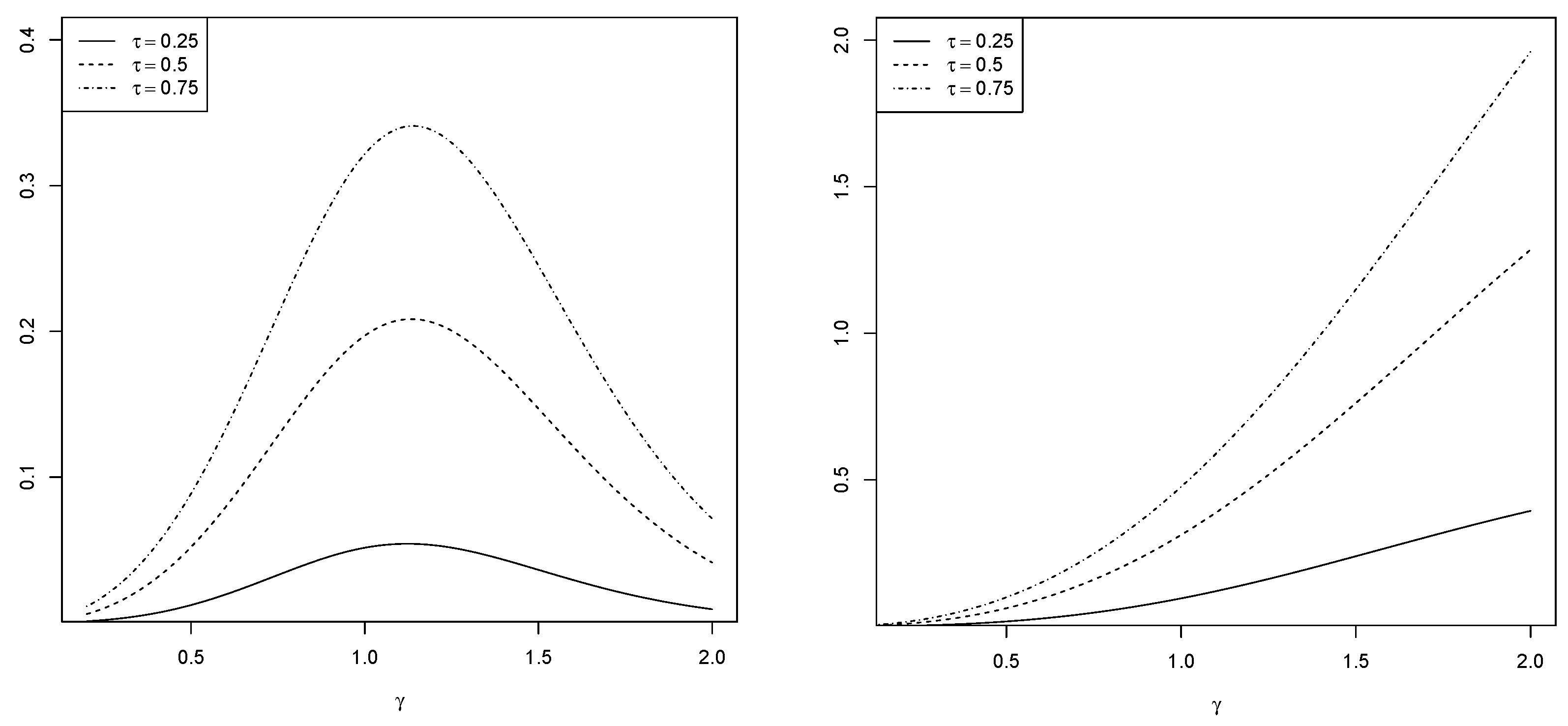
To illustrate the feasibility of criterion (II) and show the existence of optimal , we next give two concrete examples with specified quantiles and distributions of .
Example 1. Assume that follows the standard log-normal distribution and is independent of , i.e., , then for , respectively.
By the definition,hence, . We can derive There is no closed form solution for minimizing , but through a numerical procedure, we find that reaches the maximum at , , and , see Figure 2, for , respectively. □ Example 2. If , then for any . In particular, if we set .
First, by we know that . It further leads to As is shown in Figure 2, reaches the maximum at . □ 4. Simulation Study
For numerical implementation of the proposed method, we first obtained
by minimizing (
4) for each fixed
using the Nelder–Mead simplex algorithm, and then tuned and selected
based on a criterion. We finally obtained the adapted value
and the corresponding coefficient
. To verify the theoretical properties of the proposed method, we conducted simulation studies under two simple scenarios with finite samples to illustrate the proposed method.
Scenario 1. We considered a simple univariate, case,
where
,
,
follows the standard normal distribution, and
, with
following the standard normal distribution and
indicating the
-quantile of the standard normal distribution. We set the sample size
and the number of replications as 500.
For Scenario 1,
is of one dimension. So, we can plot the 3-dimensional surface of
, see
Figure 3, which shows that
is local convex with respect to both
and
. As illustrated previously in Example 1, if
follows the standard normal distribution, the true value of
in theory is around
by criterion (II).
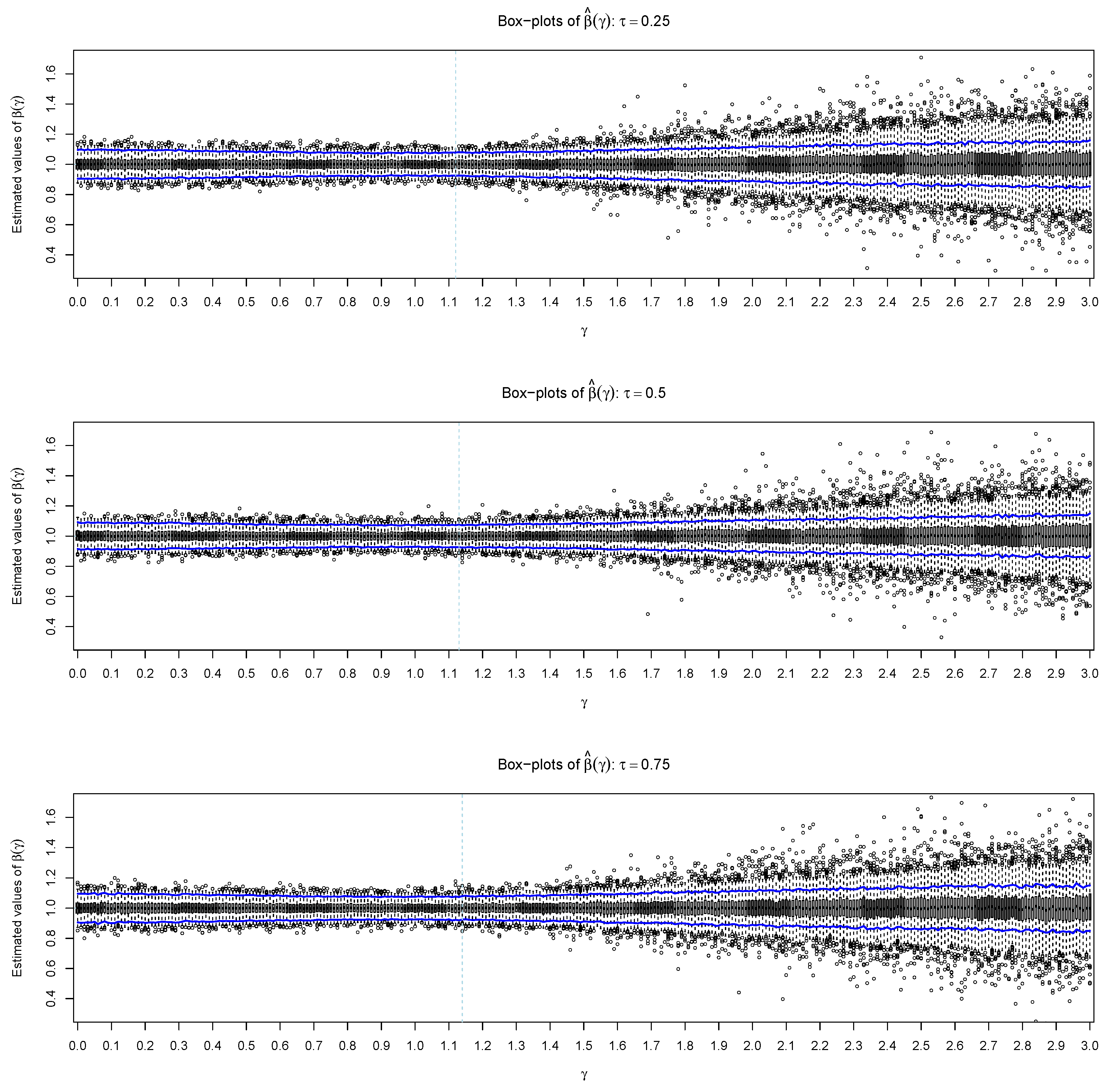
Table 1 summarizes the simulation results at different quantiles with various adaptive criteria. The results show that the estimated regression coefficients have small biases, and the biases demonstrate a clear trend of asymptotic consistency for all settings. According to the results in
Table 1 and the box-plots in
Figure 4 and
Figure 5, we also see that the adaptive parameter
selected by criteria (I) and (II) converge to 0.0, 1.13 and 0.8, respectively. The values of
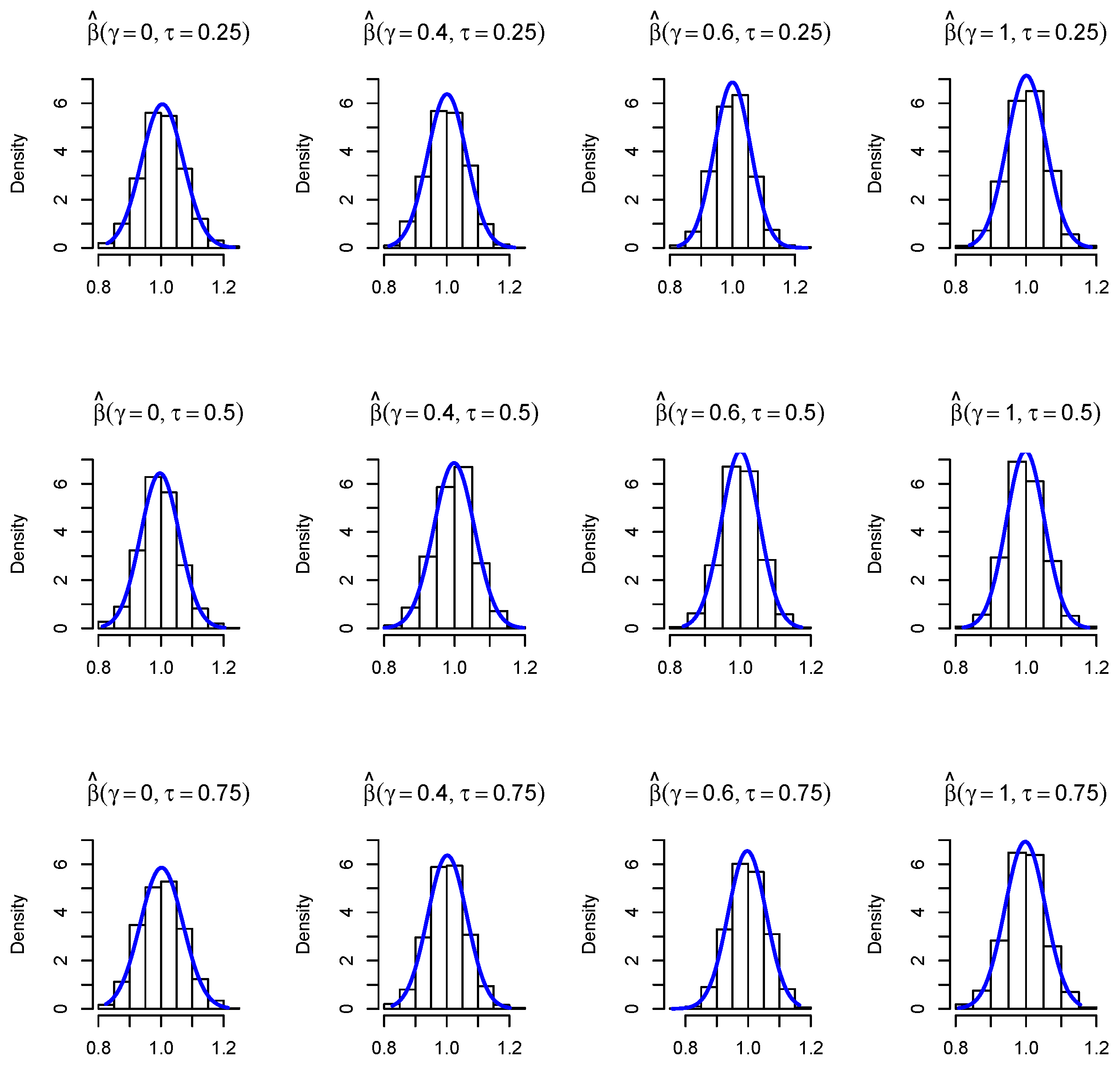
by criterion (I) are all equal to 0, indicating the estimates by criterion (I) are equivalent to that by the traditional quantile regression. Compared to the estimate by traditional quantile regression, the proposed estimate under the adaptive criterion (II) enhances the estimation efficiency of coefficients by 5∼20%. Additionally, from the histogram in
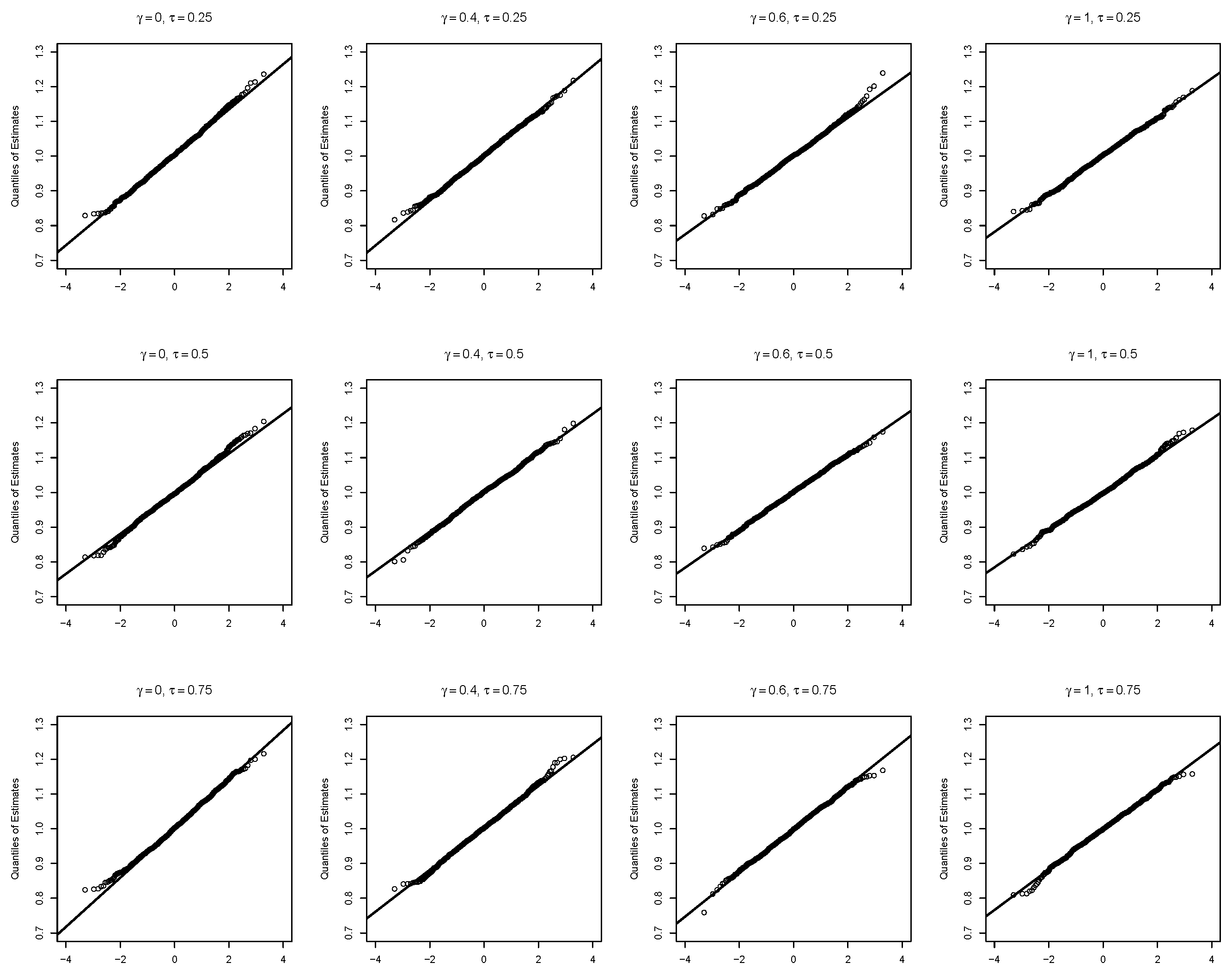
Figure 6 and the quantile–quantile (Q–Q) plot [
21,
22] in
Figure 7, we see that the empirical distribution of the estimators follows a clear normal distribution.
Scenario 2. We considered the same model and settings as in Scenario 1, except that the error follows a uniform distribution, and , where follows , and .
The simulation results are presented in
Table 2. It is shown that under criterion (I) that the estimated values of
are all equal to 0 as well, and the corresponding estimated coefficients at different quantiles have small biases and reasonable coverage probabilities. Under the adaptive criterion (II), the estimated values of
tend to converge to
. In addition, the regression coefficients are all estimated accurately. Overall, the simulation results in
Table 2 match well with the theoretical properties in Example 2 in
Section 4. Specifically, the estimation efficiency of coefficients using the proposed method with criterion (II) increases by 60∼100% over the traditional quantile regression.
5. Application
We applied the proposed method to a prostate cancer study [
23], where the prostate cancer data contain the medical records of 97 male patients who received a radical prostatectomy. The description of data is summarized in
Table 3.
The response variable of interest is the level of prostate antigen (PSA), and there are eight predictor variables, including the log of cancer volume, the log of prostate weight, age, the log of the amount of benign prostatic hyperplasia, seminal vesicle invasion, the log of capsular penetration, Gleason score and the percentage of Gleason scores of 4 or 5. The research goal is to study the covariate effects of the predictor variables at the level of prostate antigen.
We considered a linear quantile model for the association between prostate antigen and the predictor variables. For convenience, we first standardized the predictors as well as the dependent variables, and then included the intercept in the model. We took 200 bootstrap samples for the variance estimation of coefficients, and selected the adaptive parameter using criterion (II). We obtained the estimate
for all grid points
. Then, we further acquired the estimated regression coefficients with 95% Confidence Intervals (CIs) at the 0.25, 0.50 and 0.75 quantiles, which are summarized in
Table 4, where the results are also compared to those of the traditional quantile regression. As is shown in the table, there is not much difference between the estimated coefficients by the traditional quantile regression and the proposed method with criterion (II). However, referring to the values of the ‘CI ratio’ (‘CI Ratio’ is defined as the ratio of the length of 95% CI by traditional QR over that by the proposed method using criterion (II)), we can see overall that the lengths of 95% CIs by the proposed method are significantly smaller than that by a traditional quantile regression.
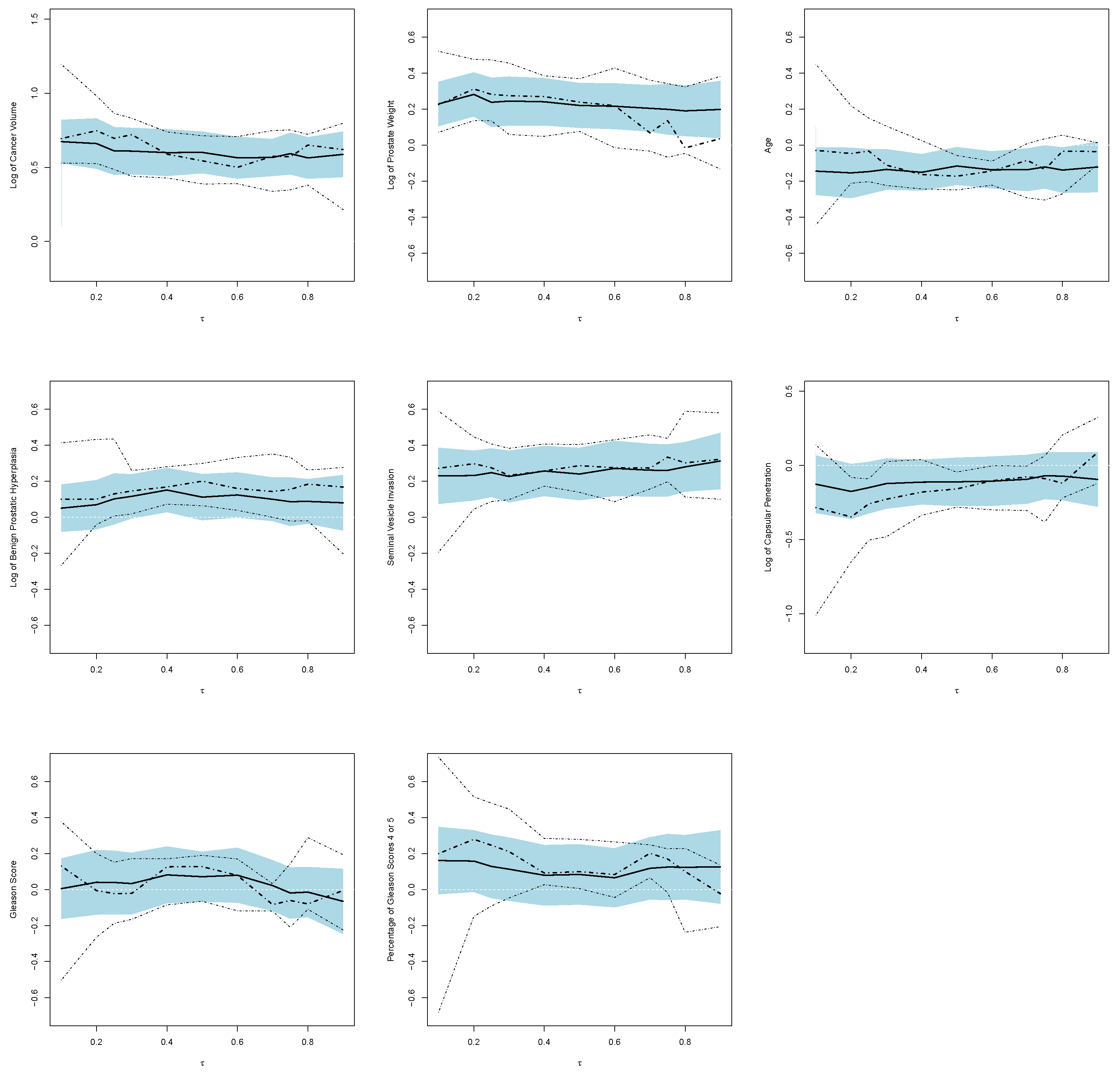
Figure 8 presents the estimated curves of coefficients with 95% confidence bands. The figure shows that the proposed method with criterion (II) provides smoother estimates and more stable and narrower confidence bands compared to those by a regular quantile regression, especially at the region of tail quantiles. From the results in both
Table 4 and
Figure 8, we concluded that the cancer volume, the prostate weight, and the seminal vesicle invasion are significantly associated with the level of prostate antigen, which is as expected since a high level of prostate antigen is generally regarded as strong evidence of prostate cancer. While the effects of the amount of benign prostatic hyperplasia, capsular penetration, Gleason score and the percentage of Gleason scores of 4 or 5 at the level of prostate antigen are statistically insignificant.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}