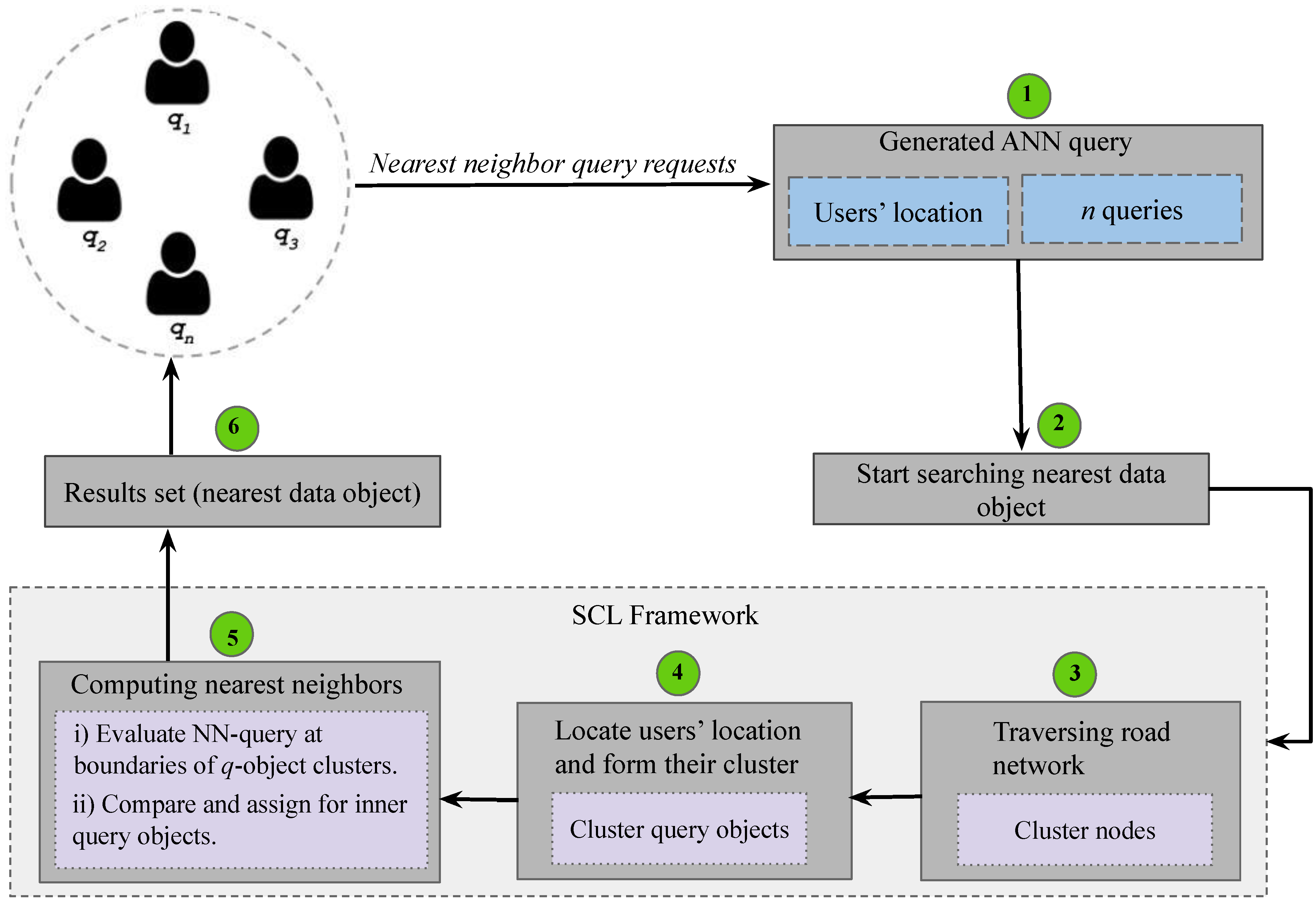
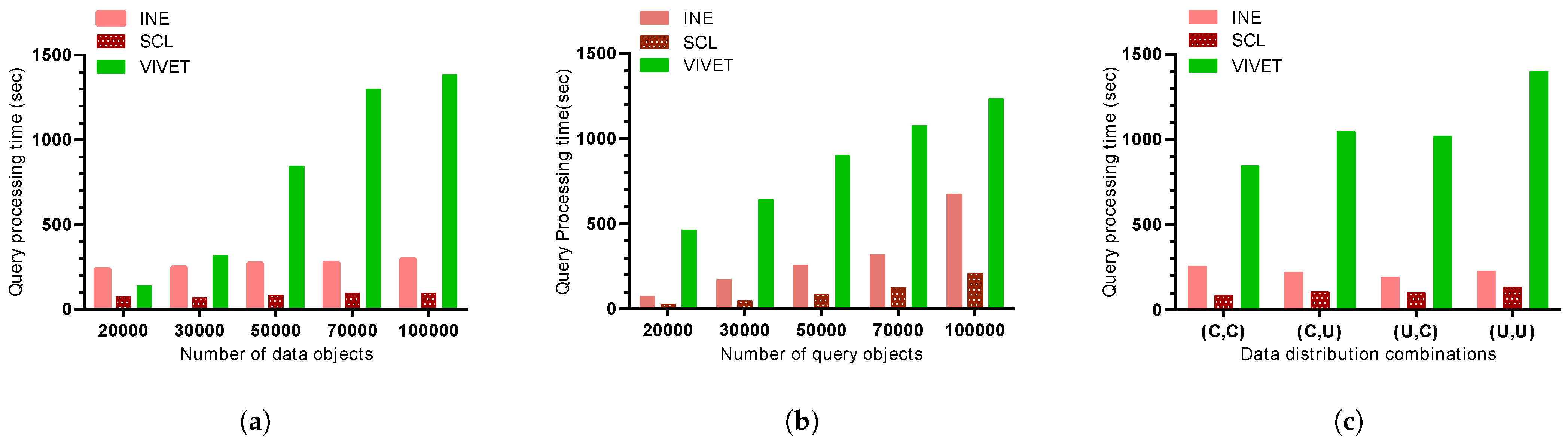
5.1. Overview of SCL
Cho [
34] suggests that evaluating NN queries at the two ends of the query object cluster is adequate to retrieve the nearest data object for every query object. According to Lemma 1, after evaluating at most two NN queries for
and
, located at the boundaries of the query object cluster
, evaluating the NN for other query objects located inside
is irrelevant. It is because the data objects can be retrieved just by comparing the distance from inner query objects
to the
and
and assigning answer data object of the closest boundary query object. This process eliminates the necessity to perform traversal for inner query objects.
Lemma 1. For every query object , there exists , which is a subset of , where refers to the set of data objects nearest to the query objects , and refers to the set of data objects lying in the query object cluster .
Proof of Lemma 1. The correctness of Lemma 1 is proved by contradiction. Let us assume that is false and rather it holds , such that there is a data object and . It is noticeable that , hence d is farther from than its nearest data object , i.e., . On the other hand, , hence d is farther from than its nearest data object , i.e., . Nevertheless, d does not belong to , i.e., . Hence, the shortest path connecting q to d must travel through either or . The distance between q to d is calculated by . Based on the aforementioned cases: , which contradicts the assumption that there is a data object d that belongs to , i.e., such that . □
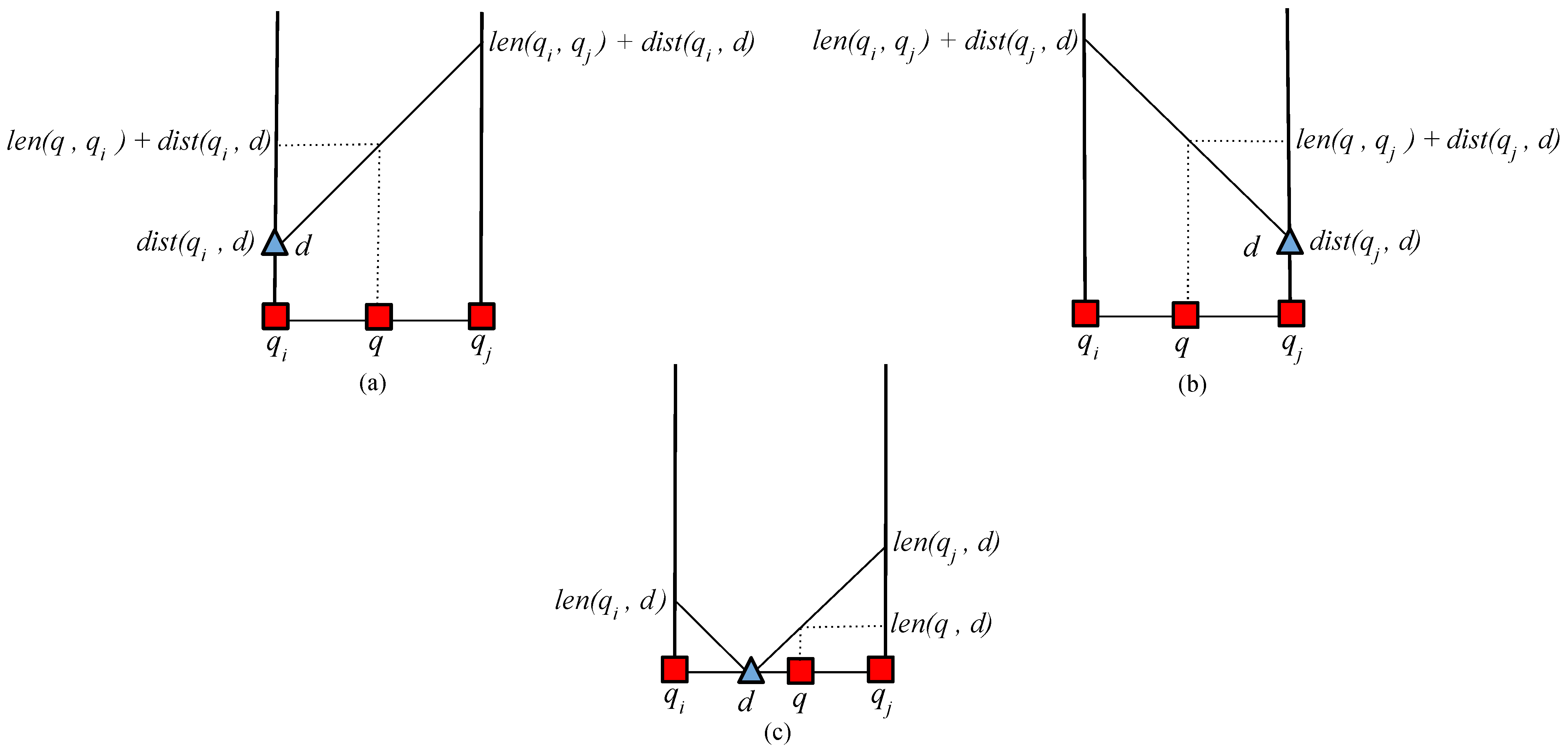
It is required to find the distance from the query object
to the nearest data object
d. In
Figure 4,
coordinates represent the distance and length from the query points to the data objects.
X coordinate refers to the
, whereas the
Y coordinate refers to the distance from query point to data object
. When there exists a path from
, then,
is used to compute the distance. Likewise, if there exists a path from
, then
is used. Lastly, if the data object
d exists inside of the
then
is evaluated as
. Finally, from the array holding the computed distance, only the minimum distance is extracted as given below. Here,
and
represent length and distance, respectively.
Table 2 shows the conditions to compute the distance from the
q to
d. A data object can belong either to
,
, or
. Retrieving the closest data object from
is more significant than retrieving the set of data objects from
. The process of identifying the nearest-neighbor pairs is described in Algorithm 2. The shared execution process can be implemented to improve the execution time. Firstly,
, i.e., the set of object pairs, is initially assigned to be null. The algorithm comprises two steps. In the first step, the adjacent query objects are clustered together and query object clusters are formed and
Q is transformed to
. The latter step involves the evaluation of the nearest neighbor query at the query object cluster
to retrieve the nearest data object
d.
| Algorithm 2: SCL_Algorithm |
![Mathematics 09 01137 i002]() |
The algorithm involves three different cases considering the number of query objects located in query object clusters. Case-I: ; Case-II: ; and Case-III: . In Case-I, the NN query is evaluated at , as in this case, the query object cluster consists solely of . Following this, the NN query result is added to the partial join result in 8–12. If it is Case-II, and are evaluated at and , respectively. Then, the partial join result and are obtained, and the union is performed for the obtained partial sets, i.e., in 13–19.
Finally, for Case-III, two NN queries are evaluated, and the search for the nearest data objects is performed at and . For each query object , the set of nearest neighbors of q is extracted in 12–24. According to Lemma 1, a partial join result can be extracted from by applying the shared execution method. Finally, the join result set is obtained and the union of partial join results is returned in 25–29 after processing the entire query object cluster.
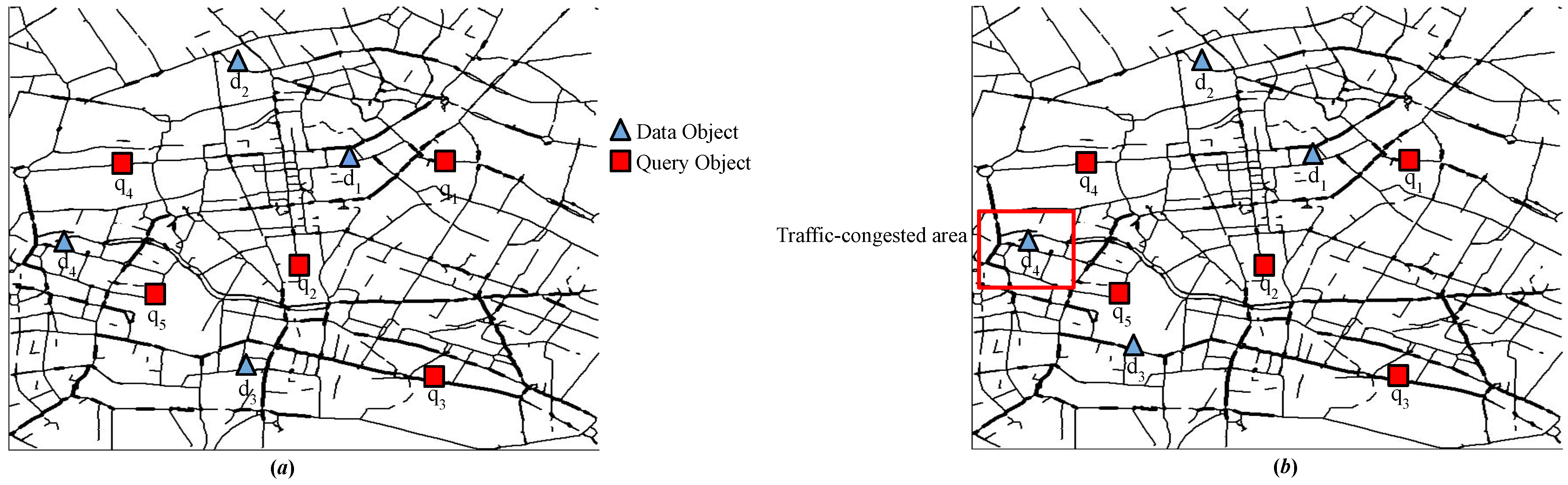
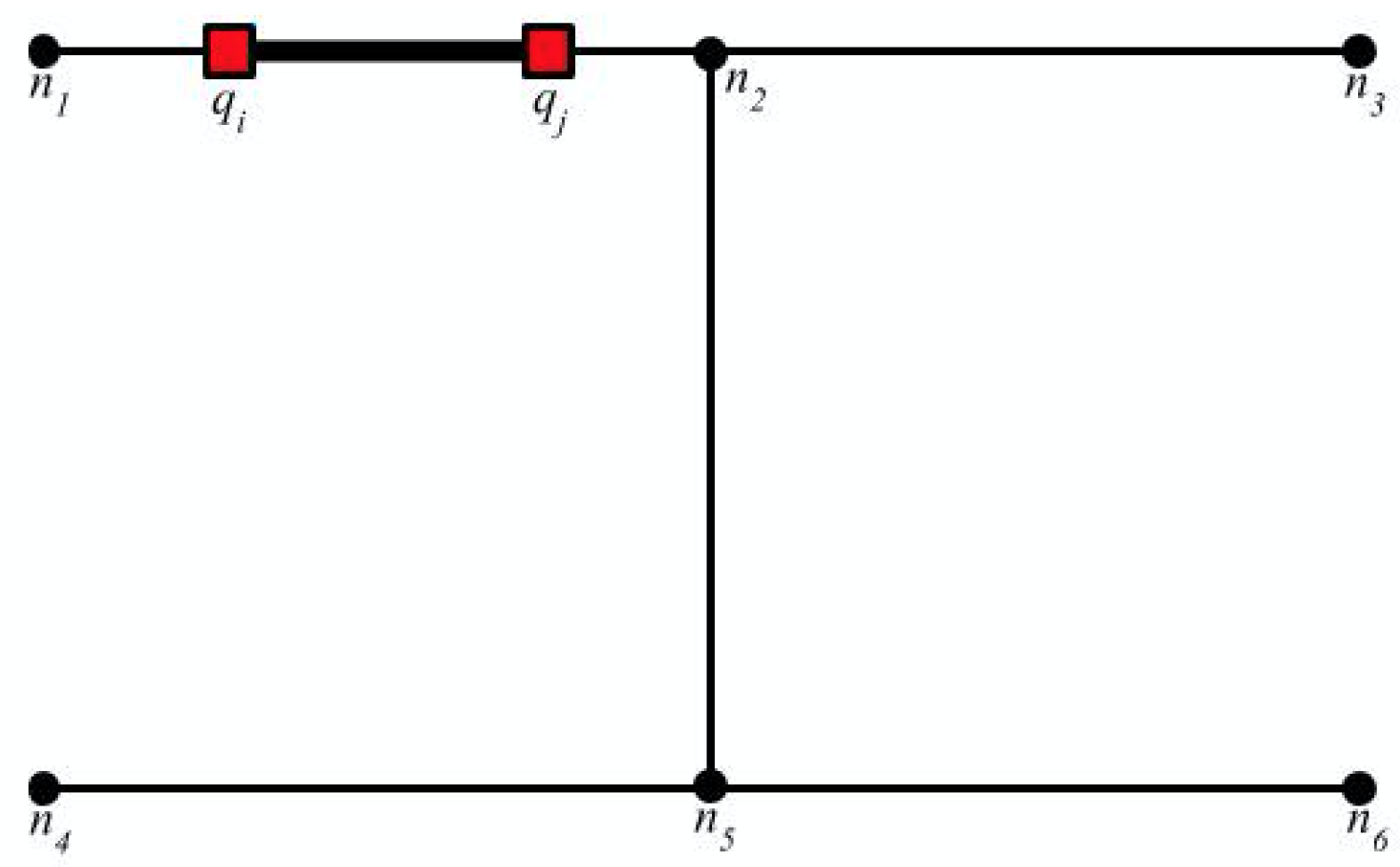
To bypass evaluating the redundant NN queries, a simple heuristic has been adopted, where no NN query is computed at query points close to the terminal nodes. For instance, as depicted in
Figure 5, the graph consists of an intersection node
with a query cluster
adjacent to it that ends with a terminal node
. In this example, the NN query at
is unnecessary because it holds that
, and it is sufficient to evaluate NN query at
.
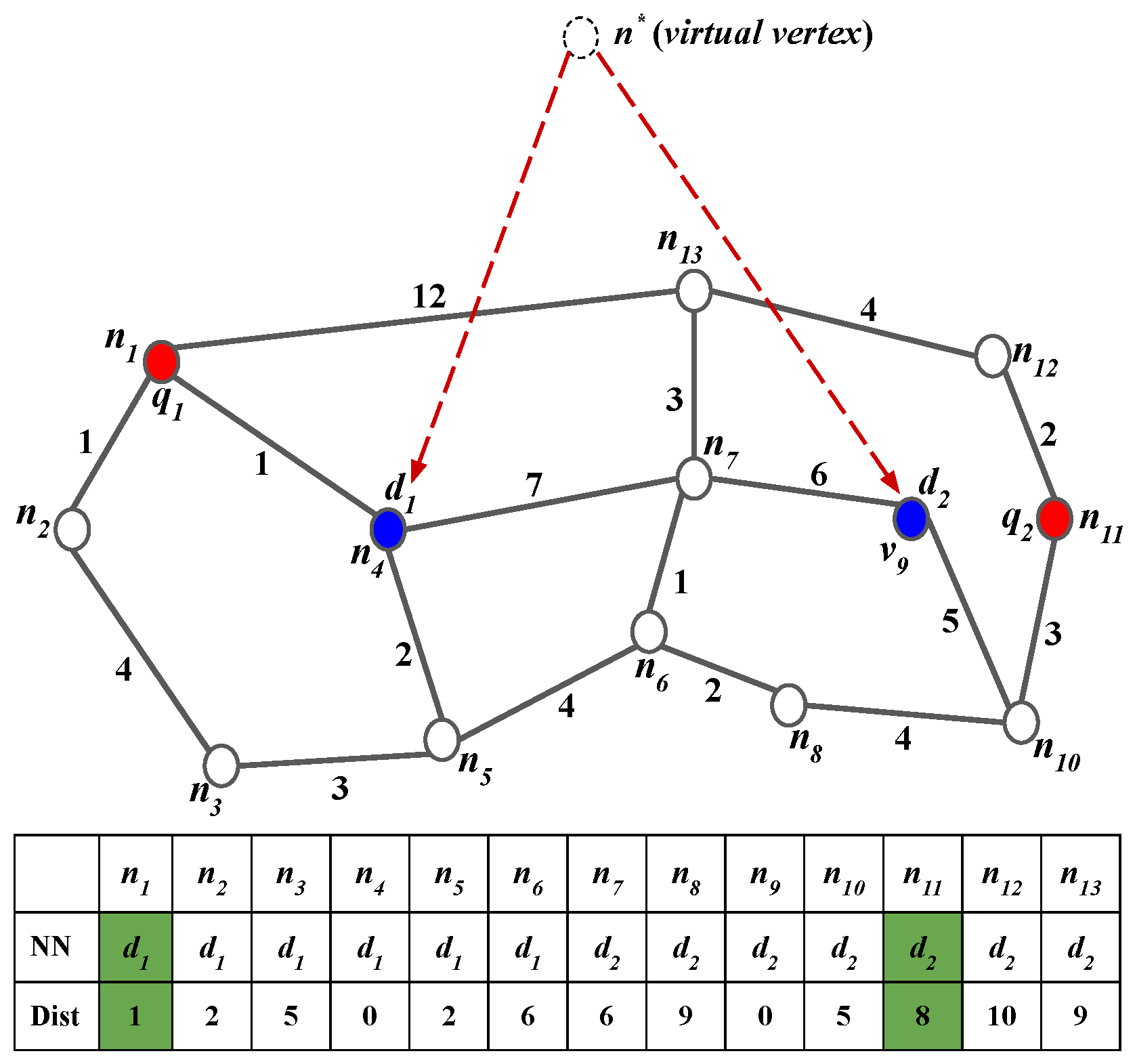
5.2. Evaluation of SCL
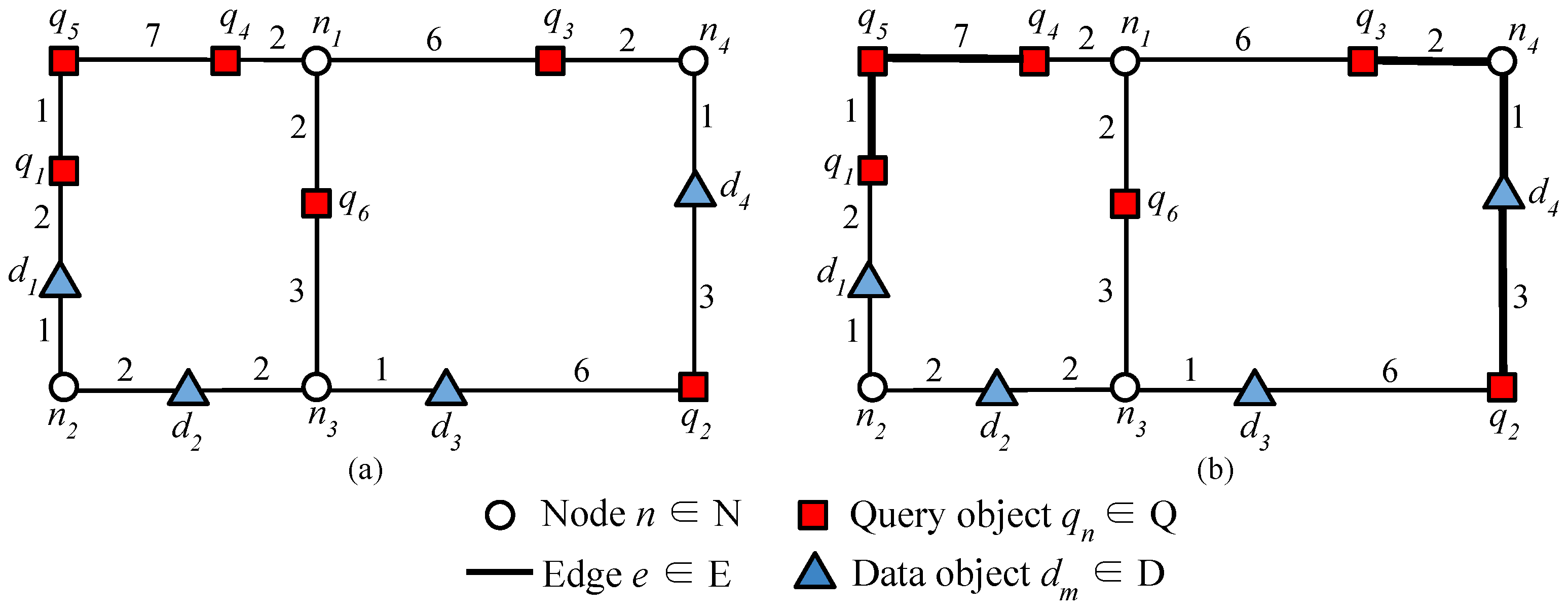
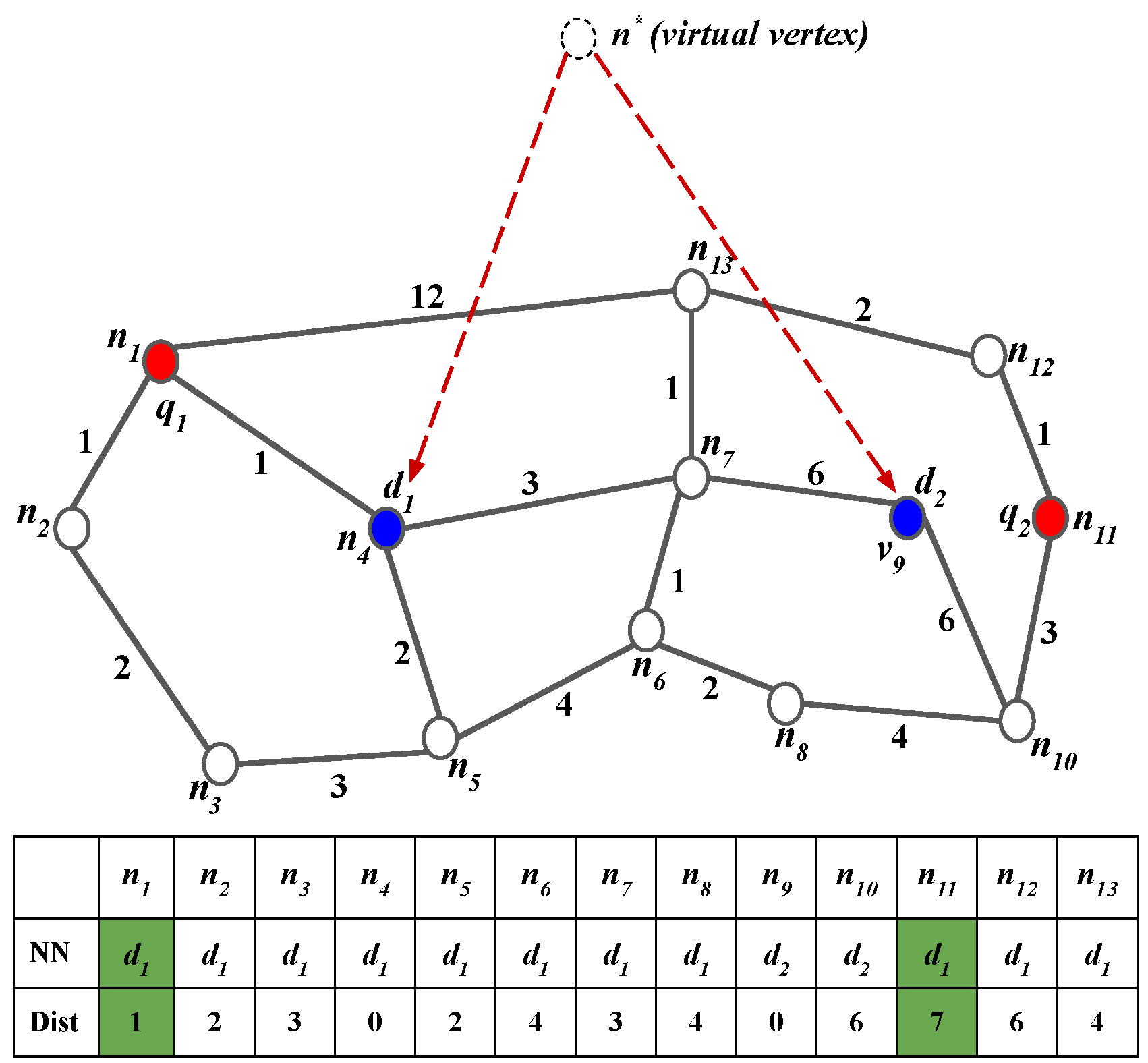
In this section, a brief discussion about the SCL algorithm has been carried out using
Figure 3. Considering that,
and
are the given sets of query and data objects, respectively. Query objects from
Q have been clustered into query object clusters
,
, and
, all of which belong to
, as depicted in
Figure 3b.
While processing
containing
,
, and
, the two NN queries are evaluated at
and
and the corresponding nearest data objects are retrieved. After evaluating the NN queries at two ends of the query object cluster,
=
,
=
, and
=
⌀ are obtained. The simple partial join result sets can be generated based on this information as
=
and
=
. Instead of evaluating the NN query corresponding to
, as it is an inner query object in the query object cluster
. Rather, simply applying Lemma 1 is enough to retrieve the NN for
based on the relation
=
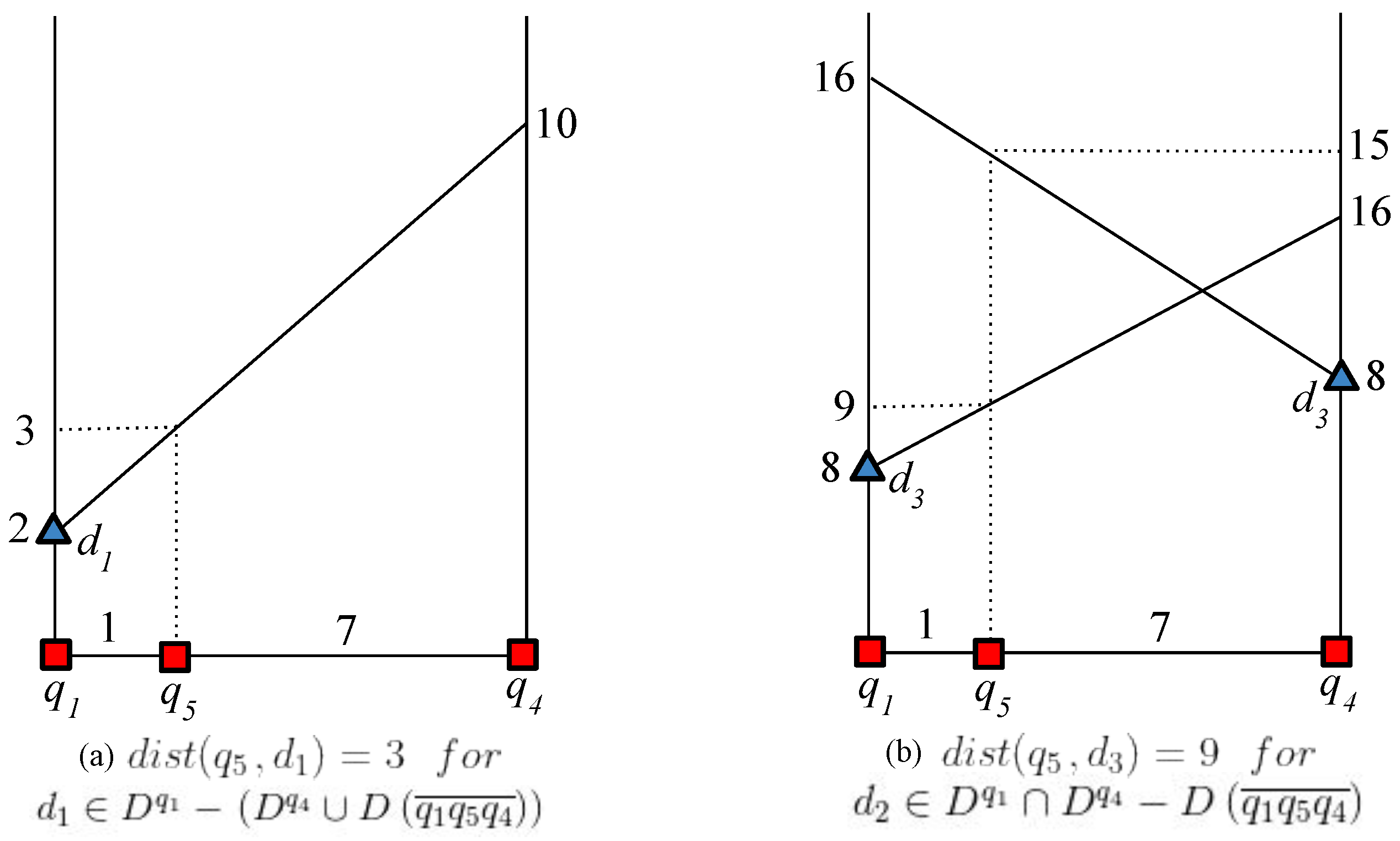
. For this purpose, it is necessary to compute the distance between
and the candidate data object
. It is evident that
and so, based on
Table 3, the distance between
and
is given by
=
= 3, as depicted in
Figure 6a. Similarly,
and so, based on
Table 3, the distance from
to
is
, as shown in
Figure 6b.
Next, the evaluation of the NN queries at query object cluster
is performed. As the query object cluster consists of only two query objects, the NN queries corresponding to both query objects need to be evaluated. On retrieving the set of the nearest data objects, the respective partial join result set is generated for each query object. From
Table 3, it is observed that
=
and
=
, then the partial join result set for
and
will be
=
and
=
, respectively.
On successful processing, the NN queries from , which leads to the final query point . In this case, a single NN query is generated at and the partial join set for is performed as = . Finally, the union of all query object clusters is computed to be = where = , and = , respectively.
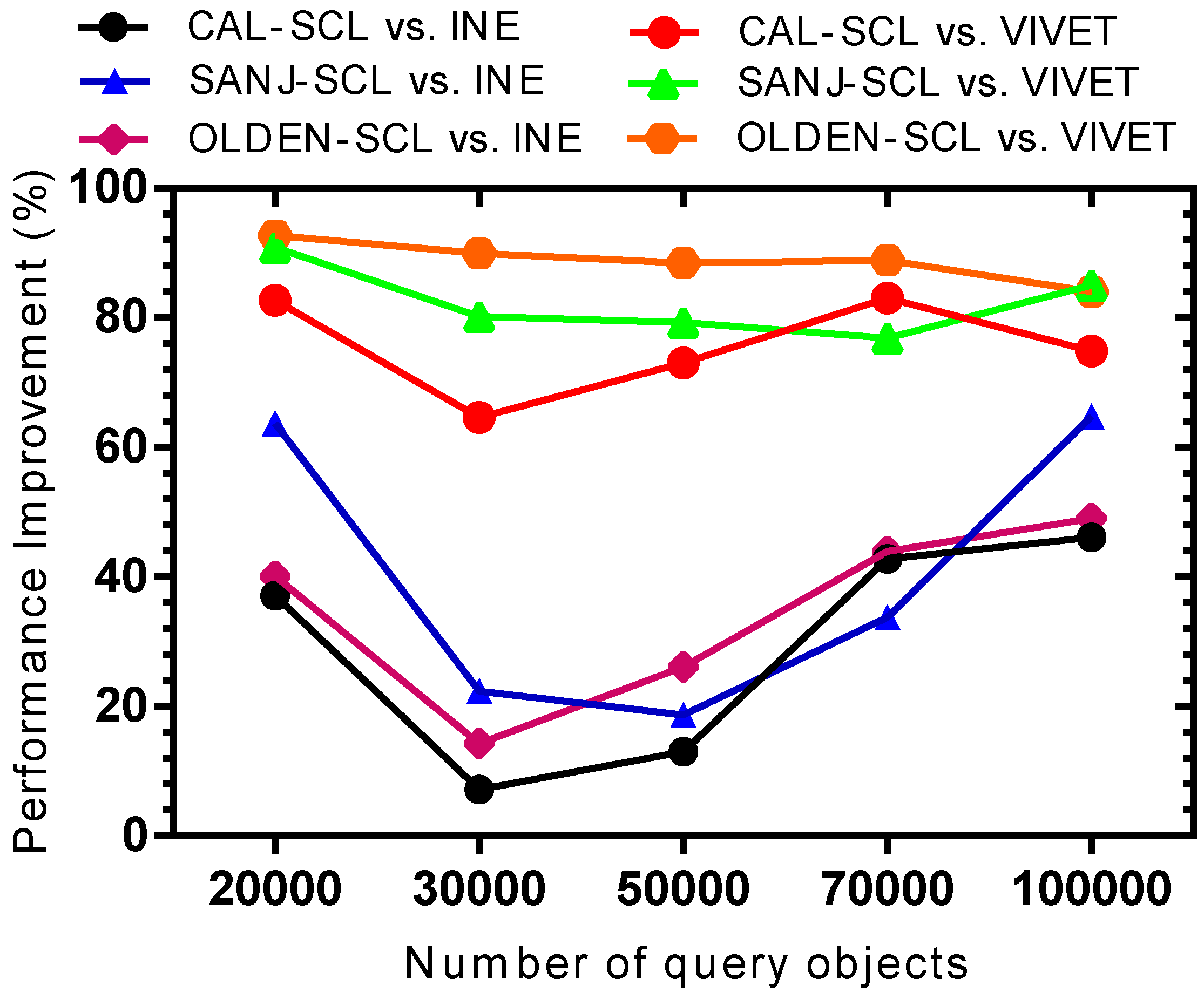
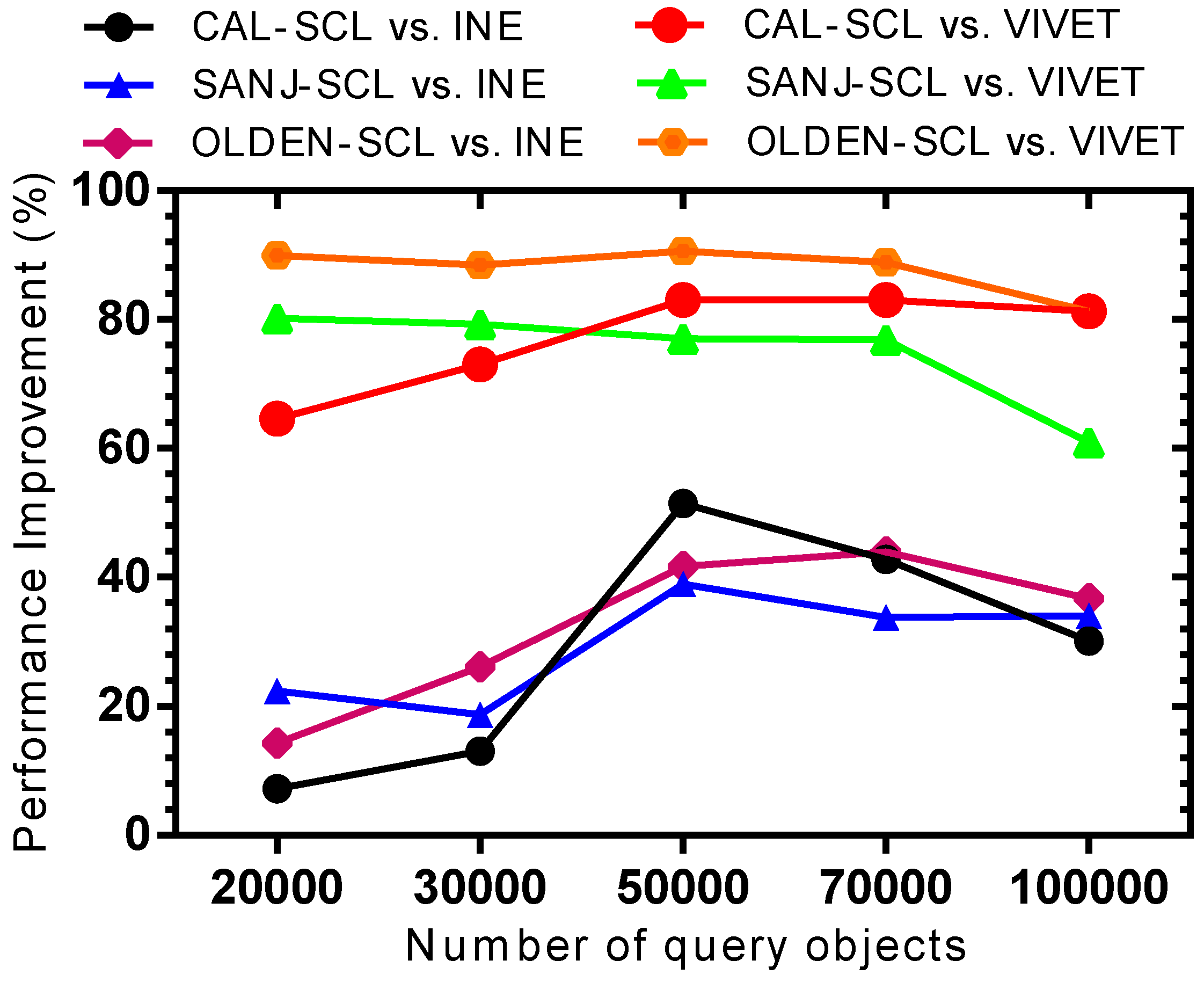
5.3. Complexity Analysis
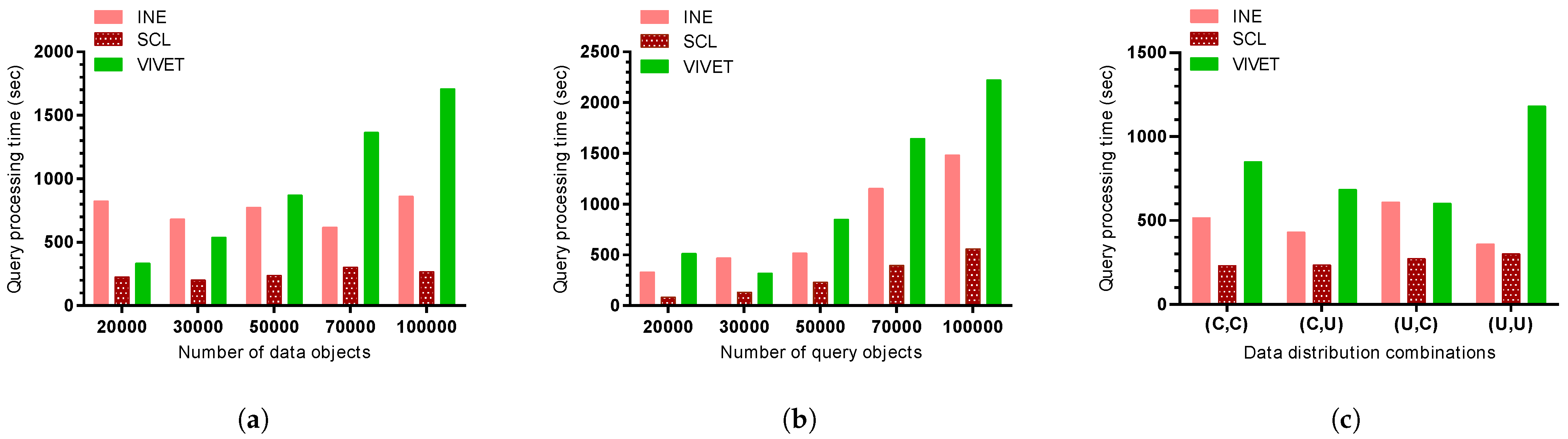
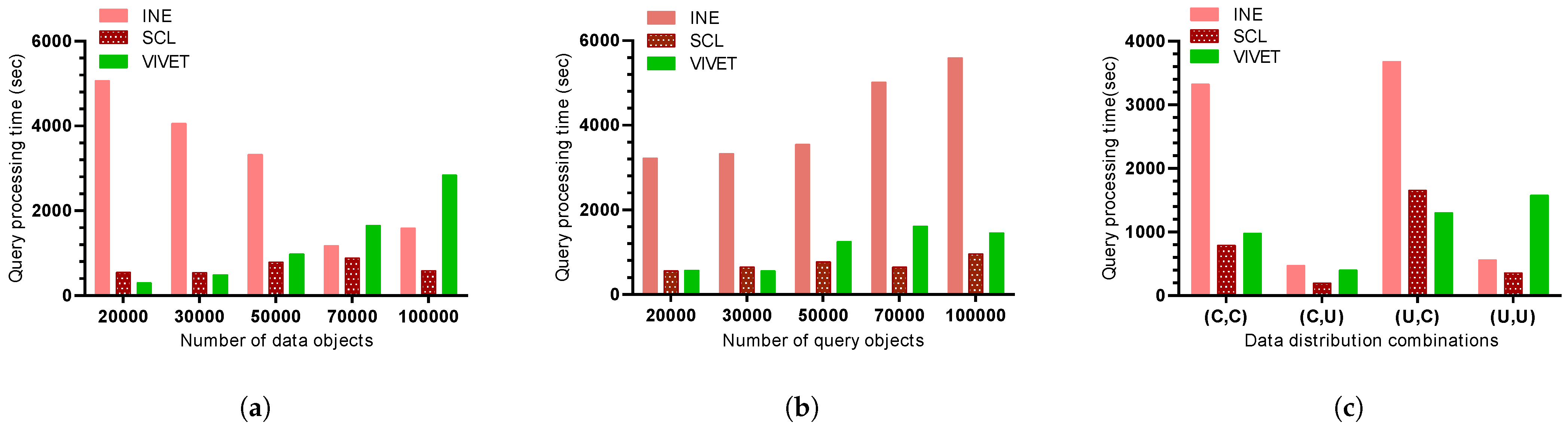
The complexity of finding the ANN queries using the proposed SCL method is covered as follows. The number of data objects are denoted as , the number of query objects as , and the node cluster as . The number of nodes and edges are denoted as and , respectively.
The clustering process takes . Initially, the road network is traversed from the terminal or intersection node until it reaches another intersection node. For the road network traversal, the SCL algorithm adopts a breadth-first search traversal with the worst-case time complexity of . Once the node clustering is completed, the algorithm linearly scans through the node clusters to find query objects located in those node clusters. The scanning takes the linear search of time.
The query time complexity of the SCL algorithm depends upon the number of query object clusters, i.e., . At most, two NN queries are applied for each query object cluster that makes . To find the shortest path from the end of each query object cluster to the nearest data object, Dijkstra’s algorithm was implemented, which has a worst-case time complexity of . Therefore, the time complexity of the SCL algorithm is expressed as: .




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}