1. Introduction
Due to the rapid development of Internet technology and the increasing popularity of personal digital camera devices, the amount of digital media (images, audio, and video) grows exponentially on the Internet [
1,
2,
3]. With the help of various image processing tools such as Photoshop, it is very easy for users to modify a copyrighted image (an original image) with a variety of manipulations such as rescaling, rotation, cropping, noise addition, and text addition to produce various kinds of copy versions of the image for illegal use.
Figure 1 shows the toy examples of an original image and its copies. In view of this, detecting image copies has become the first and key step for copyright protection.
Generally, two typical techniques are popularly applied to detect illegal copies: digital watermarking [
4] and content-based copy detection [
5,
6,
7,
8]. Digital watermarking embeds a watermark into the image file before its distribution. Consequently, all the copies of the marked image contain the watermark, which can be extracted and used as the proof of ownership. Instead of embedding additional information into the image, content-based copy detection directly relies on the image itself. Generally, a content-based copy detection system works as follows. It first collects numerous images downloaded from the networks to build a database, and extracts content-based features from the database images as their unique information. Then, for a given copyrighted image, the system compares its features to the features of the database images to determine whether there are copy versions of the copyrighted image in the database. Compared to the watermarking, the content-based copy detection does not need to embed the extra information but the image itself, and copy detection can be conducted after distribution [
5,
9]. Therefore, this paper focuses on content-based copy detection.
To resist various common copy attacks, the traditional content-based copy detection methods [
6,
7,
8,
9,
10,
11,
12,
13,
14] are usually based on local hand-crafted image features, such as scale-invariant feature transform (SIFT) [
15], principal component analysis on SIFT (PCA-SIFT) [
16], and speeded-up robust feature (SURF) [
17]. However, as hundreds to thousands of high-dimensional hand-crafted features are extracted from each image, directly matching these features between images for copy detection is very time-consuming. To reduce the time consumption of the matching process, a bag-of-visual-words (BOW) model [
18] is adopted to quantize these features to visual words to build an inverted index file for copy detection.
Recently, deep learning techniques, particularly convolutional neural networks [
19], have achieved great success in many applications of computer vision, such as image or scene classification [
20], human activity recognition [
21], and object defect detection [
22]. Since the CNN features have been proven to be superior to hand-crafted features for content-based retrieval tasks [
23], researchers prefer to employ CNN features for content-based retrieval. Some earlier works [
24,
25,
26,
27] feed an image into a pretrained CNN model and then use the output of the last fully-connected network layer as a global image representation. In some other works [
3,
23,
26], instead of focusing on the features extracted from fully-connected layers, the features extracted from the deep convolutional layers are explored for the tasks of content-based retrieval.
Generally, the convolutional feature maps (CFMs) are first extracted from the deep convolutional layers of CNNs with an input image, and a pooling strategy such as sum-pooling [
23] or max-pooling [
28] is usually adopted to aggregate the feature maps into a single image representation. In our previous work [
3], instead of only generating a single global representation from each image, we extract both the global and local CNN features from the CFMs and match these features between images with a coarse-to-fine matching strategy for near-duplicate image detection. In another work [
29], the spatial-temporal CNN features are generated and matched for video copy detection. However, since the global CNN features are sensitive to partial content-discarded attacks such as cropping and occlusion, it is hard for these methods to detect the image copies generated by these attacks. Consequently, the retrieval accuracy is compromised to some extent, and it is not a reasonable choice to directly apply these global CNN features for copy detection.
Therefore, we attempt to propose a novel image copy detection method based on local CNN features with contextual hash embedding. First, we extract the CFMs from the deep convolutional layers of a pre-trained CNN model with an input image. Then, a number of local CNN features are generated by sum-pooling the feature values within the image regions detected by the SURF region detector [
17]. Additionally, to improve the discriminability of the features, we extract a contextual hash sequence from a relatively large region surrounding each local feature. Next, these local CNN features are quantized to visual words by the BOW model to build an inverted index file, and the generated hash sequence is embedded into the index file. Finally, the local CNN features are matched efficiently between the images by looking up the inverted index file for copy detection. Our main contributions are summarized as follows.
(1) The extraction and indexing of local CNN features. The local CNN features are extracted by pooling the feature values of the convolutional feature maps (CFMs) within the regions detected by the SURF region detector. In the feature extraction, the regions detected by the SURF region detector change covariantly to the geometric transformations, including scaling and translation, and the feature values in CFMs are robust to a variety of content-preserved attacks due to the powerful training process. Therefore, the extracted local CNN features are not only robust to the partial content-discarded attacks, but also to the common geometric transformations and content-preserved attacks. Therefore, the extracted features have a high robustness, which will be beneficial to the accuracy of copy detection. Then, we index these local CNN features by the BOW model to form an inverted index file. By looking up the inverted index file, the feature matching process can be rapidly implemented for copy detection.
(2) The contextual hash embedding. To improve the discriminability of the quantized features, we also generate a contextual hash sequence for each feature and embed it into the inverted index file. Since the proposed contextual hash sequence is composed of a small number of hash values, it is quite compact and thus does not need too much additional storage space. Moreover, different from the CNN features that usually describe the complex patterns and semantic information of images, the hash sequence captures the correlations between blocks divided from relatively large regions surrounding the local CNN features, which can sufficiently characterize the contextual information of these features and thus improve the features’ discriminability significantly. That will lead to a higher detection accuracy.
The reminder of this paper is organized as follows. In
Section 2, we introduce the proposed copy detection method in detail. The experimental results and analysis are given in
Section 3.
Section 4 draws the conclusions.
2. The Proposed Copy Detection Method
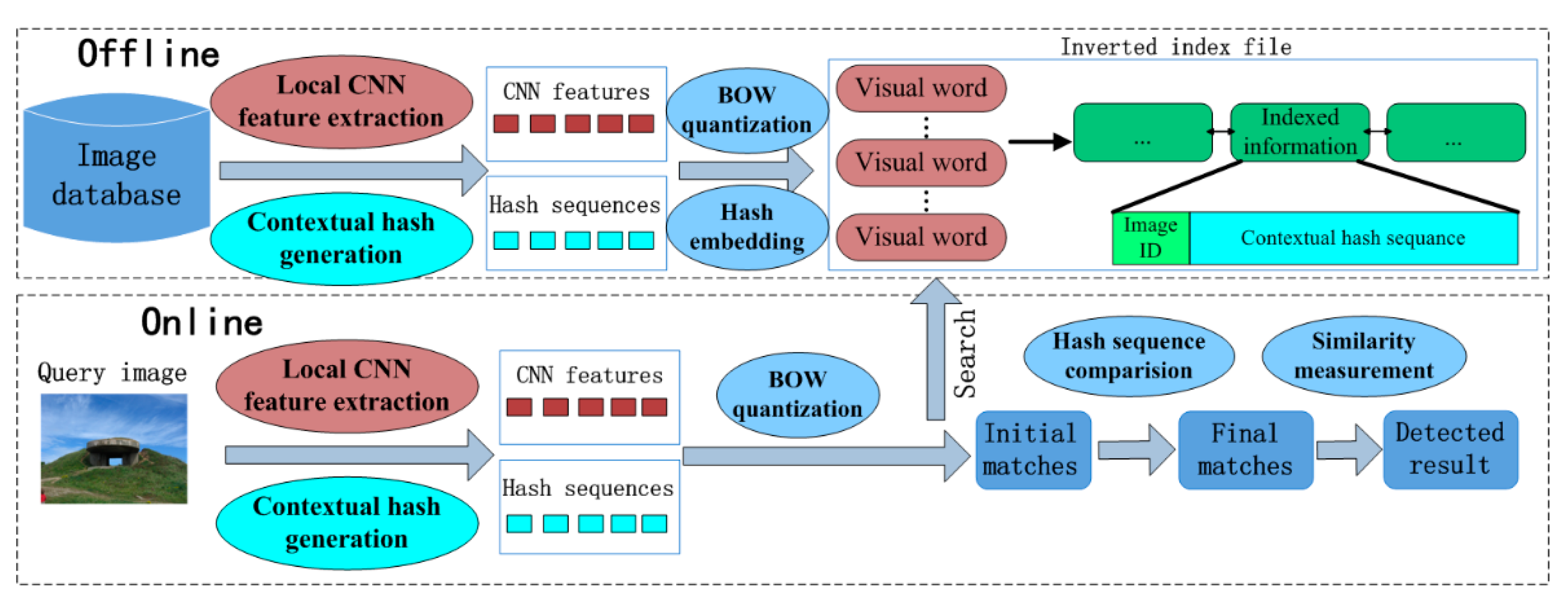
In this section, the proposed copy detection method will be introduced. The framework of the proposed copy detection method is illustrated by
Figure 2. In
Section 2.1, we introduce the generation of the CFMs for a given image. In
Section 2.2, we describe how to extract the local CNN features from the CFMs. In
Section 2.3, a contextual hash sequence is generated for each local CNN feature. In
Section 2.4, the extracted local CNN features are quantized by the BOW model to build an inverted index file, and the generated hash sequence is embedded into the index file. In
Section 2.5, by looking up the inverted index file, we match the features between images for copy detection.
2.1. CFM Generation
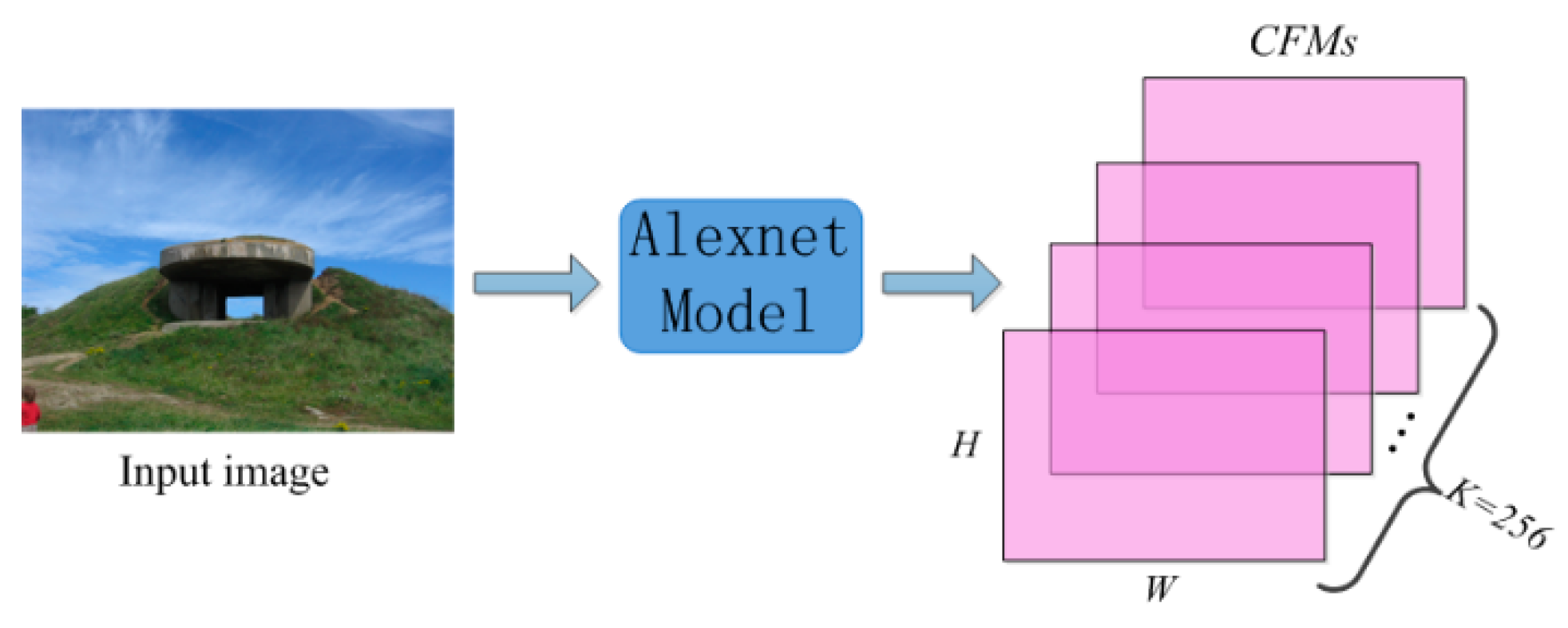
Generally, a typical CNN model is composed of a number of layers, including convolutional layers, pooling layers, and fully connected layers. As illustrated in [
23], the CNN features extracted from deep convolutional layers perform better than the features from other layers in many retrieval tasks. Thus, for a given image, it is fed into a pretrained CNN model and the output of the fifth convolutional layer—i.e., a set of CFMs—is used for the local CNN feature extraction. In our method, we adopt the famous CNN model—i.e.,
AlexNet [
19].
From [
19], by feeding an image into the AlexNet model, the output of the fifth convolutional layer is
feature maps with the size of
, where
and
and
are proportional to the width and height of the image, respectively. Denote the
feature maps as
. These CFMs will be further used for local CNN feature extraction.
Figure 3 illustrates the generation of CFMs.
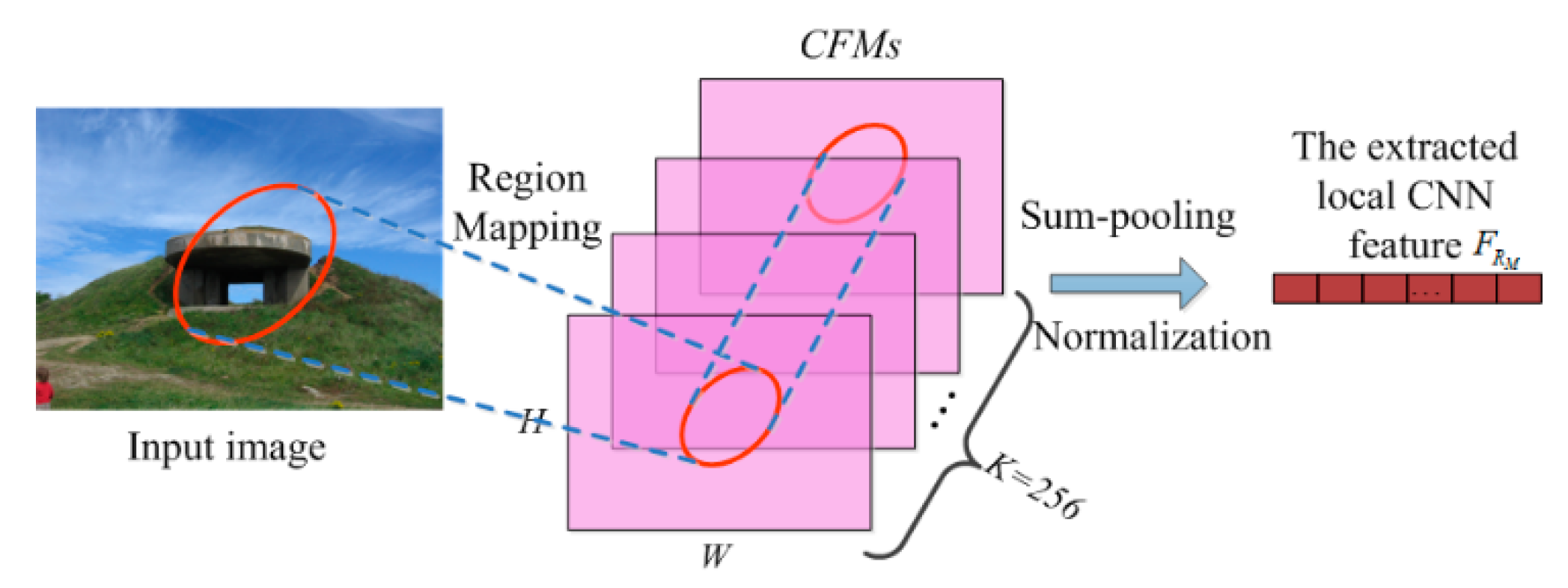
2.2. Local CNN Feature Extraction
To extract the local CNN features, we first detect a set of regions from the image and then extract the local CNN features by pooling the feature values within the detected regions. To achieve a high robustness of the common geometric transformations including rotation, rescaling, and translation, the regions detected for feature extraction should change covariantly to these transformations. To this end, the SURF region detector [
17] is adopted to detect the regions from images, since the SURF detector can efficiently detect the regions that change covariantly to the above transformations, as illustrated in [
17].
Since the sizes of CFMs are proportional to the size of the image, for a region detected on the image
, we can map the region to the CFMs to obtain its corresponding region
on CFMs, according to the ratio between the size of the image and its CFMs. Then, we adopt the sum-pooling strategy [
23] to aggregate the feature values of each CFM within the region
to extract the
dimensional local CNN feature
, by:
where,
represents a point located in the region
, and
means the feature value of
on the
-th feature map. Finally, we normalize the extracted feature by L2-normalization.
Figure 4 illustrates the local CNN feature extraction. As hundreds to thousands of SURF regions are detected from each image, the same number of local CNN features can be extracted by the above step.
2.3. Contextual Hash Generation
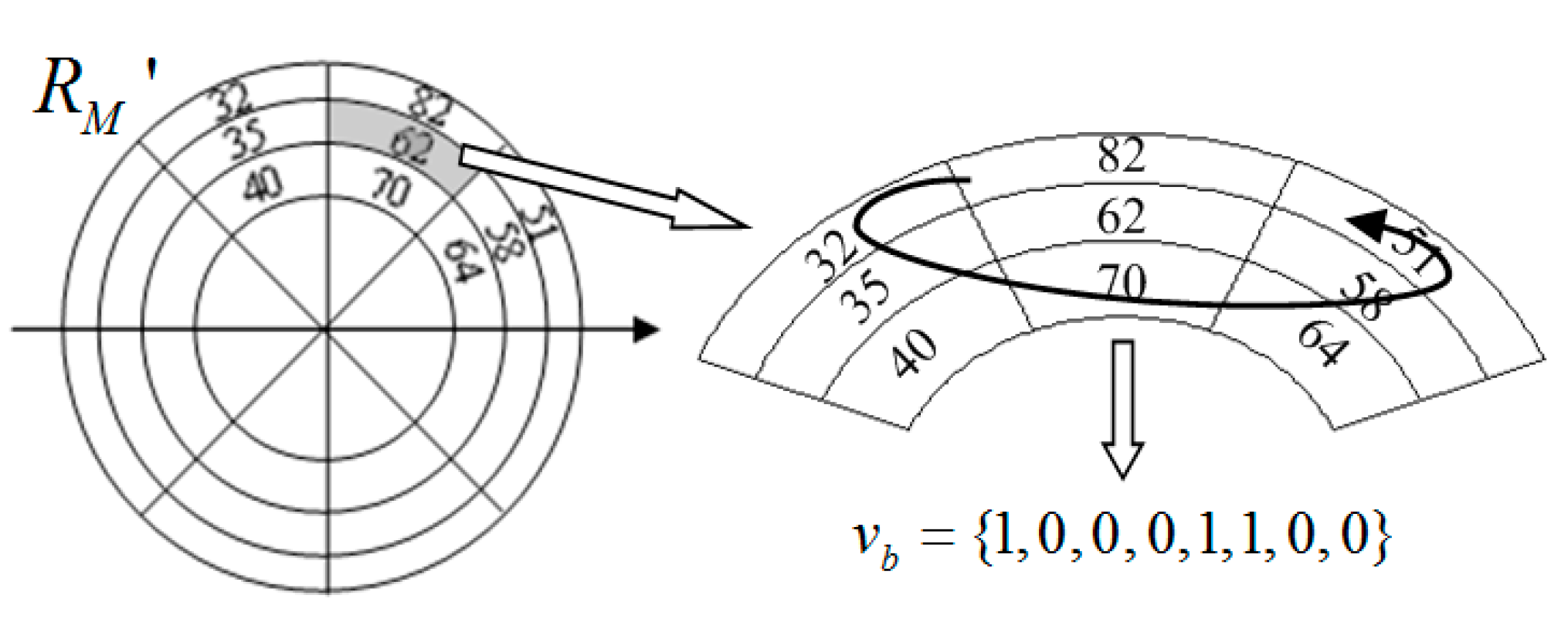
In our method, the extracted CNN features will be quantized to visual words to construct an inverted index file for rapid image matching. However, the BOW quantization process will decrease the discriminability of the features to some extent. To improve the features’ discriminability, we generate a contextual hash sequence of each local CNN feature and then embed it into the index file. In our method, we use the correlations between blocks divided from the relatively large region surrounding each local CNN feature to generate the contextual hash sequence. The algorithm of the contextual hash generation is described as follows.
Suppose the radius of a detection SURF region is
. To capture the contextual information, we expand the region proportionately, and the radius of the extended region
is denoted as:
where
is set as 3.2 by experiments.
For a given expended region
, we first divide it into
blocks with equal size in the log-polar space and then compute the average gray intensities of these blocks. We denote the average gray intensity of block
in the expended region as
, and those of the eight adjacent blocks of block
as
, where
. Note that some adjacent blocks of an edge block do not exist, and thus their average gray intensities are set as 0. Then, the hash values of block
denoted by
can be generated by Equation (3).
Figure 5 shows an example of the extraction of feature values from a block.
In the above manner, the hash values of all the blocks in the region are computed. Then, we concatenate the hash values of all the blocks to generate the contextual hash sequence of the local CNN feature, denoted as , which will be further embedded into the index file. Since the correlations of adjacent blocks that describe the comparative intensity relationships of adjacent blocks are less likely to be changed by various transformations, the generated hash sequence has a high robustness. Moreover, each hash sequence is composed of a small number of hash values, and thus we do not need too much additional memory space for storing it. In addition, the contextual hash sequence sufficiently captures the contextual information of the local CNN feature, which can significantly improve the feature’s discriminability for copy detection.
2.4. Index File Construction
As hundreds to thousands of local CNN features are detected from each image, it is very time-consuming to directly match these features between images for copy detection. Thus, in this section, we quantize these features to visual words based on the BOW model and then build the inverted index file for efficient copy detection.
Specifically, in the BOW model, numerous sample features are clustered to generate a set of clusters by a clustering algorithm—i.e., K-means—and each cluster center is viewed as a visual word to form a visual vocabulary. Then, we extract the local CNN features from all the database images, and then quantize them to the corresponding nearest visual words of the vocabulary to build the inverted index file.
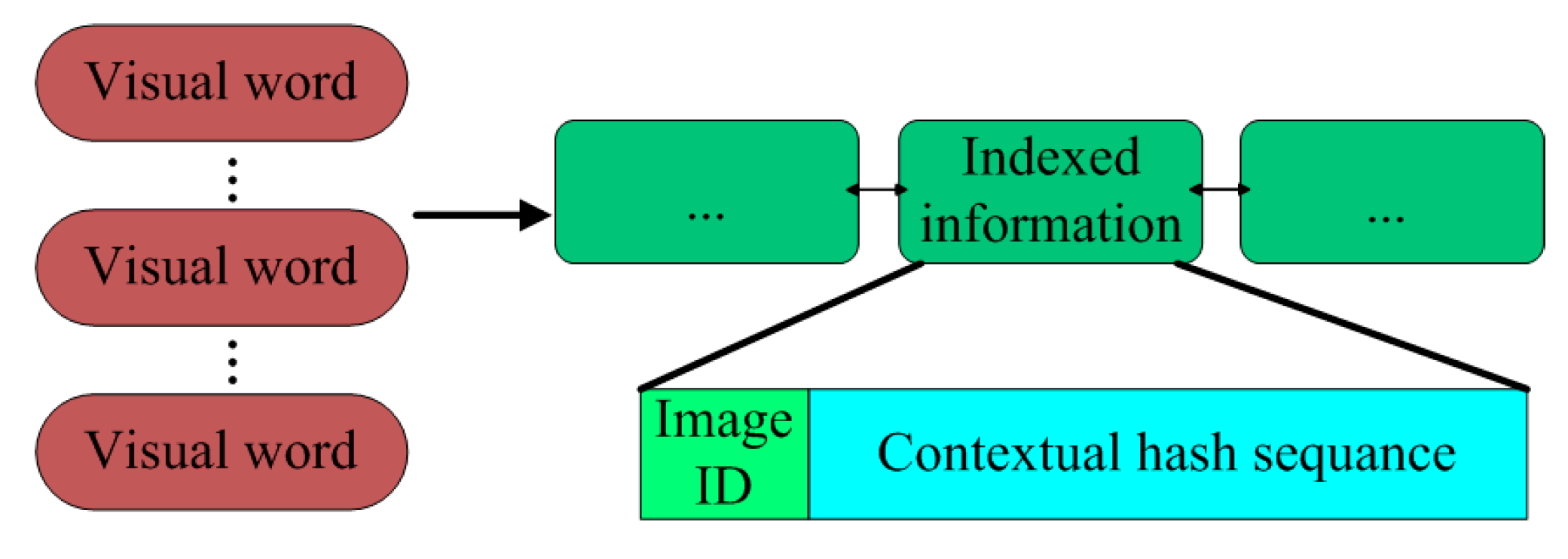
The structure of the inverted index file of our method is illustrated by
Figure 6. Each visual word is followed by the indexed information, each of which stores the ID of the image where the visual word occurs and the contextual hash sequence. Note that the generation of the contextual hash sequence for each local CNN feature is described in next subsection.
2.5. Copy Detection
By the above steps, we can obtain the inverted index file for the database images. Next, we will introduce the implementation of copy detection in detail.
For a query image, we also extract its local CNN features and the corresponding hash sequences by the algorithms described in
Section 2.3 and
Section 2.4, respectively. Then, by looking up the index file, any two local CNN features from different images quantized to the same visual word are treated as a candidate local match between the images.
Next, we compute the distance between the corresponding contextual hash sequences of initially matched local CNN features, denoted as
and
, to confirm whether they are a true match. The distance is computed by:
where
and
are the
-th elements in
and
, respectively. If the distance is smaller than a preset threshold
, we determine that the match is a true one. Then, like the tradition BOW-based retrieval methods [
7,
30], each matched feature casts the corresponding database image a vote weighted by the inverted document frequency (IDF) [
30]. The similarity of the query image to a database image is measured by adding up all the weighted votes. Finally, we compare the similarity with a pre-set threshold to determine whether a database image is a copy version of the query.
3. Experiments
In this part, the dataset and evaluation criteria used in our experiments are described first. Second, the optimal parameter setting is determined by experiments. Third, the performance of the proposed method is evaluated and compared to those of the state-of-the-art methods.
3.1. Datasets and Evaluation Criteria
In the experiments, two datasets are adopted, which are detailed as follows.
(1)
Copydays dataset [31]. This dataset is composed of 3212 images. There are 157 original ones and 3055 copies that are generated by different kinds of image attacks, such as JPEG compression, cropping, and “strong” attacks. The “strong” attacks mean the different combinations of a variety of manipulations such as scaling, blurring, and rotation. For each original image, it has nine copy versions that are generated by JPEG compression with different quality factors, nine copy versions that are generated by cropping the image from 10% to 80%, and 2 to 6 copy versions that are generated by “strong” attacks. The 175 original images are used as query images for copy detection.
(2)
DupImage dataset [
32]. This dataset contains 1104 images. In this dataset, there are 33 image groups. In each group, the first image is an original image, and the other images are the copy regions, which are cropped from the original image with a variety of copy attacks such as rescaling, noise addition, and compression. We use the 33 first images of these groups as query images for copy detection.
In the experiments, we adopt Mean Average Precision (MAP) to test the performances of the different methods. When detecting the copies of a given query in the database, by setting the image similarity threshold to different values we can obtain a set of pairs of precision and recall rates. Thus, we can compute the average precision across all the different recall levels. MAP is obtained by computing the mean value of the average precisions of all queries.
Note that the experiments are implemented on a personal computer (3.2 GHz Core-i5 and 8 GB RAM) with Windows 7 × 64 operation system.
3.2. Parameter Determination
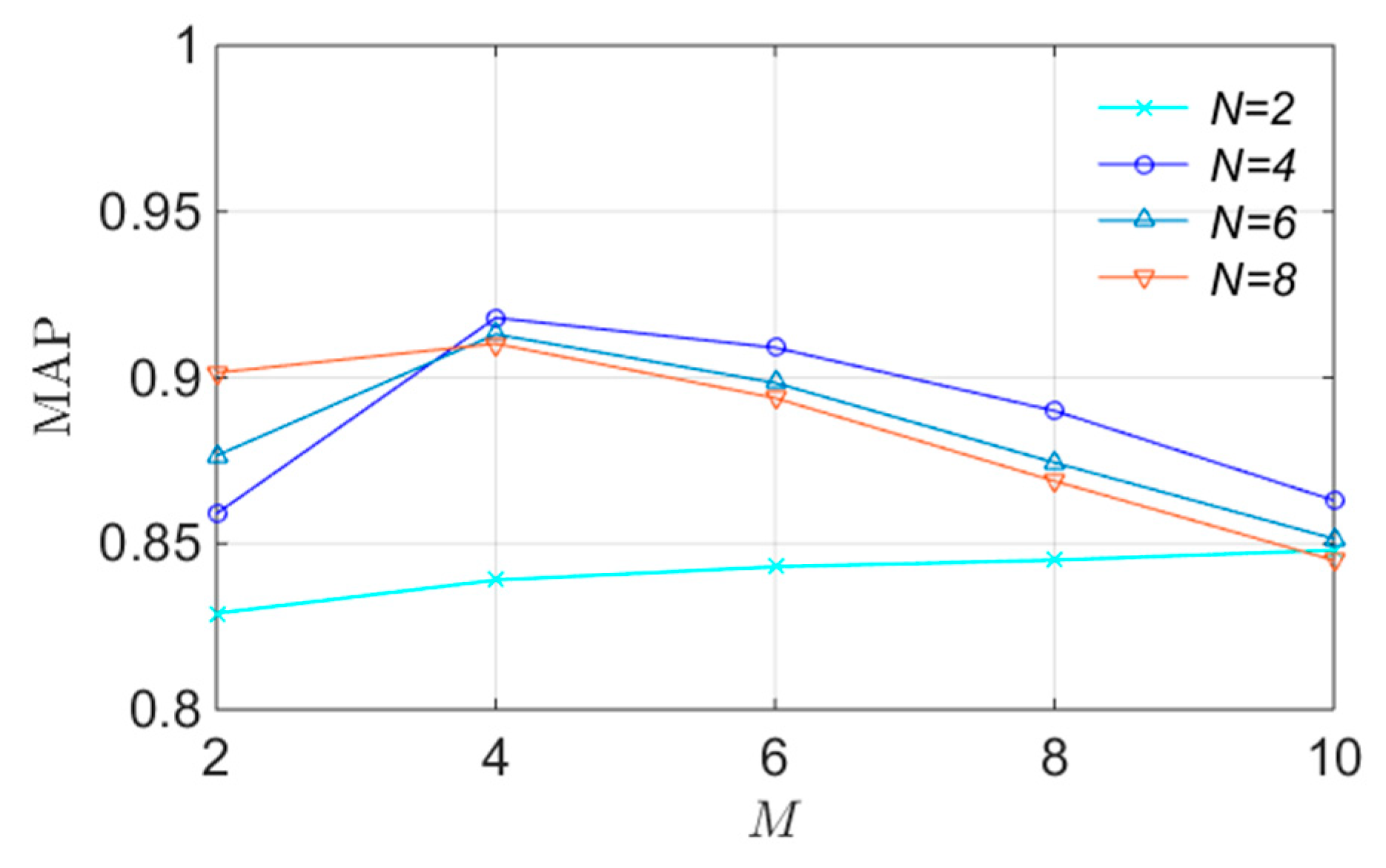
In this part, the impacts of three key parameters are tested: the parameters used for block generation—i.e., and —and the threshold used for feature matching—i.e., . The size of the visual vocabulary used for the index file construction is set as 20K.
First, the threshold
is fixed to a default value—i.e., 0.3—to observe the impacts of the parameters
and
on the MAP values. From
Figure 7, we can clearly observe that too large or too small
and
lead to an inferior detection performance for the following reasons. A larger
and
lead to more blocks divided from each region and a smaller number of pixels in each block, which will make the generated contextual hash sequence more sensitive to many copy attacks, such as nosing addition and blurring. A smaller
and
cause fewer blocks from each region, which will decrease the dimensionality of the generated contextual hash sequence. Thus, the accuracy of feature matching will be affected to some extent. According to
Figure 7,
and
provide the highest detection accuracy, and thus we use the above settings in the following experiments.
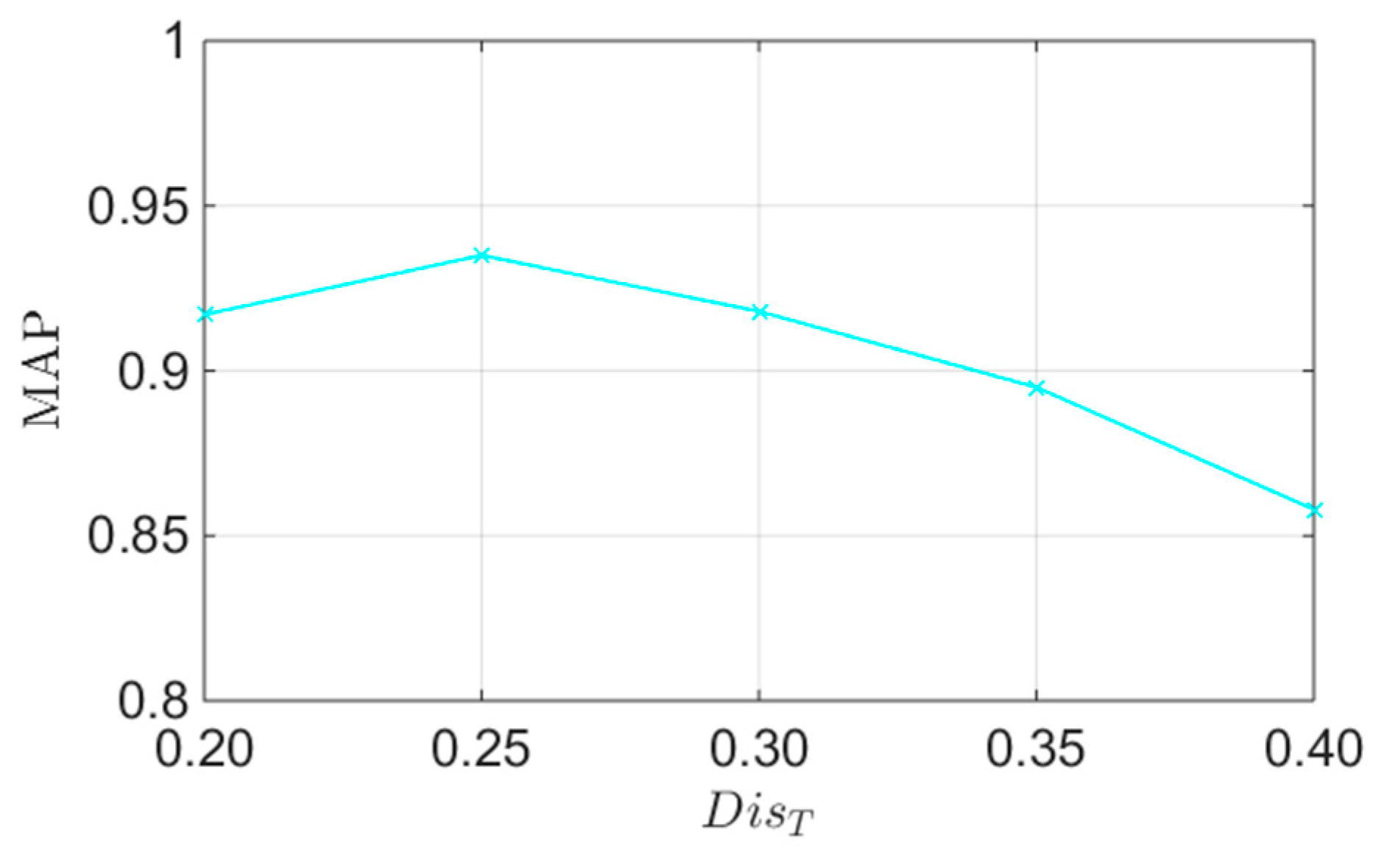
Then, we test the impact of the threshold
.
Figure 8 shows the effects of
on the MAP. From this figure, it can be clearly observed that the detection performance degrades when
is too small or too large. The reason is that if
is too small, a considerable number of true feature matches will be detected as false ones, and if
is too large, many false matches will be determined as true ones. According to this figure, when
, we can achieve the highest detection accuracy. Thus, we set
in the following experiments.
3.3. Performance Evaluation
In this part, we will compare the performance of the proposed method to those of five other methods, which are listed as follows.
(1)
SIFT + BOW [
33]: This is the method based on the hand-crafted local features—i.e., SIFT features [
15] and the BOW model [
18]. First, a set of SIFT features are extracted from each image, and then they are quantized by the BOW model to build an inverted index file for image copy detection.
(2)
SIFT + BOW + GC [
8]: This method is very similar to the previous one, but it has an additional step—i.e., feature match verification by geometric coding (GC). Specifically, after obtaining feature matches between images by inverted index file, a geometric coding algorithm is adopted for feature match verification to filter false matches. The remaining feature matches are used to evaluate the image similarity for copy detection.
(3)
Global CNN + Local CNN + CF [
3]: This method extracts both the global and local CNN features from the CFMs generated by a pre-trained CNN model—i.e., Alexnet [
19]—and match these features between images with a coarse-to-fine (CF) strategy for copy detection.
(4)
Global CNN + VDSH [
27]: In this method, we extract the global CNN features from the last fully connected layer of the same pre-trained CNN model—i.e., Alexnet [
19]—and index these global features by the BOW model. Then, the VDSH algorithm [
34] is employed to calculate the hash codes of images to improve the discriminability of the global features for copy detection.
(5)
Local CNN + BOW: Different from SIFT + BOW, this method uses the local CNN features extracted by the algorithm in
Section 2.2 instead of the SIFT features.
(6) Local CNN + BOW + CHE: This method is the proposed method, which extracts the local CNN features and then quantizes them to visual words by the BOW model to build the inverted index file, and the contextual hash sequences are generated and embedded into the index file.
We set the size of visual vocabulary as 20K to test the detection performances of those methods on the two datasets. The comparison results are shown in
Table 1 and
Table 2, where the average time cost per query is adopted to evaluate the time efficiency, while the memory consumption per indexed feature is used to measure the space efficiency of those methods. From
Table 1, it can be clearly observed that our method—i.e.,
Local CNN + BOW + CHE—achieves the highest accuracy among all of these methods on the Copydays dataset. Our method achieves a higher accuracy than the
SIFT + BOW and
SIFT + BOW + GC, mainly because our method uses the local CNN features, which have a higher discriminability than the local hand-crafted features. The accuracy of our method is higher than those of
Global CNN + Local CNN + CF and
Global CNN + VDSH. That is because the proposed local CNN features are more robust than the global CNN features to the partial content-discarded attacks, such as cropping and occlusion. Additionally, our method outperforms
Local CNN + BOW, since the contextual hash sequence embedded into the index file can significantly improve the discriminability of the local CNN features.
From
Table 2, our method still achieves the highest accuracy on the Dupimage dataset. All of the above methods, especially
Global CNN + Local CNN + CF and
Global CNN + VDSH, achieve worse performances on the Dupimage dataset than on the Copydays dataset. That is because the Dupimage dataset contains a lot of image copies generated by the partial content-discarded attacks such as cropping and occlusion, and the global CNN features are much more sensitive to these attacks than the proposed local features.
From
Table 1 and
Table 2, we can also observe that the time efficiency of our method is higher than that of
SIFT + BOW + GC and
Global CNN + Local CNN + CF, and is slightly lower than that of
Global CNN + VDSH and
Local CNN + BOW, since our method needs the additional verification step to confirm the local CNN feature matches by computing the distances between the contextual hash sequences. Our method requires comparable memory space to
SIFT + BOW + GC and
Global CNN + VDSH, and a higher memory space than
SIFT + BOW and
Local CNN + BOW. That is because the additional contextual hash sequence needs to be embedded into the inverted index file in our method.
In conclusion, our method provides a higher accuracy than the five other methods, while maintaining a desirable performance in the aspects of both space and time efficiency. Some examples of copy detection results of our method are shown in
Figure 9.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}