Coverless Image Steganography Based on Generative Adversarial Network


Abstract
:1. Introduction
- (1)
- We propose a method of using GAN to complete steganography tasks, whose relative payload is 2.36 bits per pixel.
- (2)
- We propose a measurement method to evaluate the image quality of the steganography algorithm based on deep learning, which can be compared with traditional methods.
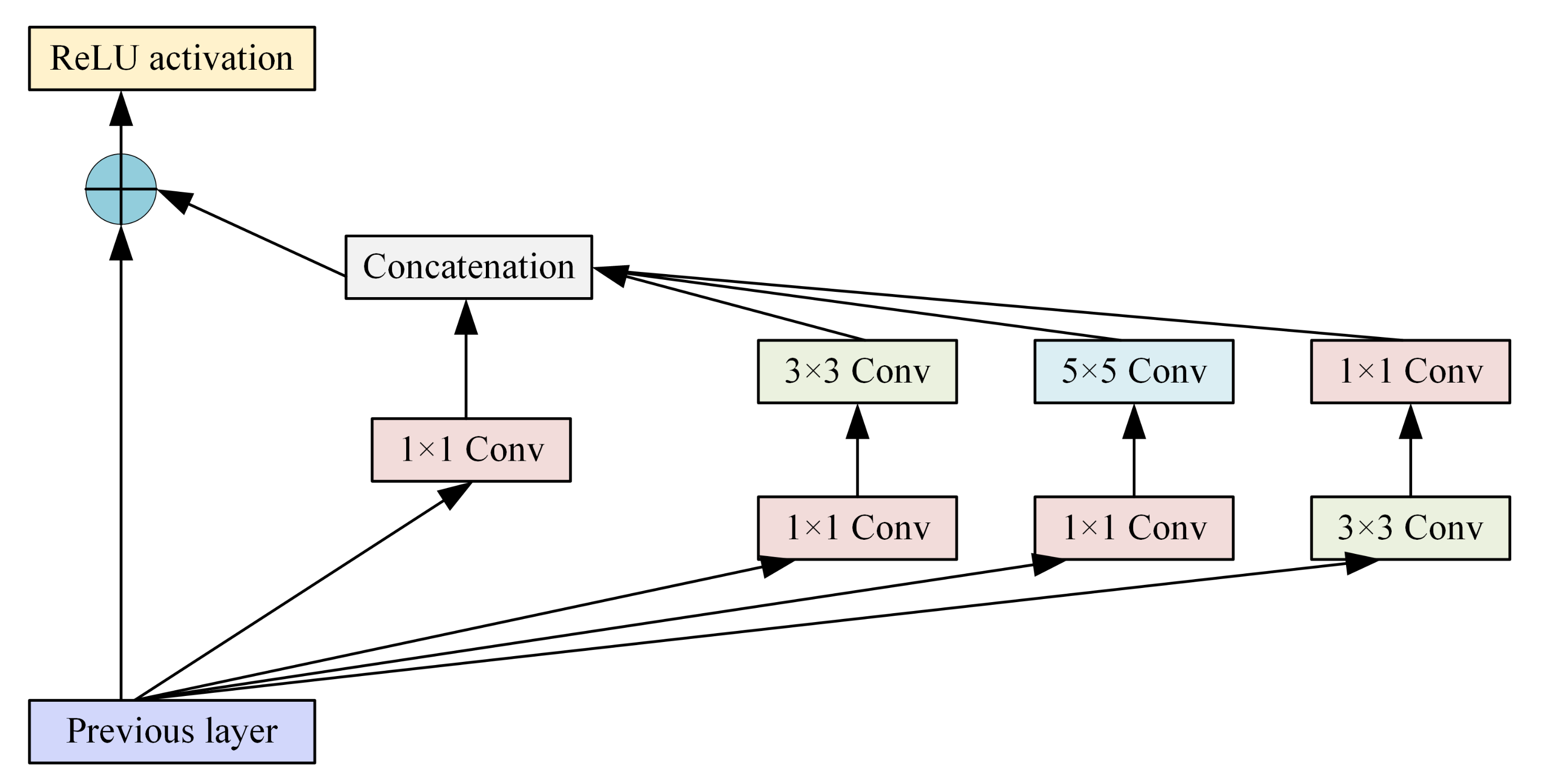
2. Image Steganography Based on GAN
3. Method
- (1)
- An Encoder network , which receives a coverless image and a string of binary secret message, generates a steganographic image;
- (2)
- A Decoder network G, which obtains a steganographic image, attempts to recover a secret message;
- (3)
- A Discriminator network D is used to evaluate the quality of vectors and steganographic images S.
3.1. Encoder Network
- (1)
- Use convolutional block to process the cover image C to get the tensor a with the size of .
- (2)
- Concatenate the message M with a and then process the tensor b with a convolutional block . The size of b is :
- (i)
- Basic model: We apply two convolution blocks to tensor b successively to generate steganographic images S. Formally:
- (ii)
3.2. Decoder Network
3.3. Discriminator Network
3.4. The Objective Fuction
3.4.1. Encoder-Decoder Loss
- (1)
- The cross entropy loss function is used to evaluate the decoding accuracy of decoder network, that is
- (2)
- The mean square error is used to analyze the similarity between the steganographic image and the cover image, where W is the width and H is the length of image, that is
- (3)
- And the realness of the steganographic image using the discriminator, that is
| Algorithm 1 Steganographic training algorithm based on GAN |
| Input: Encoder Decoder Discriminator threshold threshold . |
| Output: valCrossEntropy of G. |
| 1. While valthreshold do |
| 2. Update and G using . |
| 3. for training epochs do |
| 4. if valthreshold then |
| 5. Update using using |
| 6. else if threshold then |
| 7. else |
| 8. Update using using |
| 9. Get CrossEntropy of G |
| 10. Get valCross validation accuracy of D |
| 11. end if |
| 12. end for |
| 13. done |
| 14. return |
3.4.2. Structural Similarity Index
4. Experimental Results and Analysis
4.1. Evaluation Metrics
4.1.1. Reed Solomon Bits Per Pixel
4.1.2. Peak Signal-to-Noise Ratio
4.2. Training
4.3. Experimental Results
5. Discussion and Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Pouli, V.; Kafetzoglou, S.; Tsiropoulou, E. Personalized multimedia content retrieval through relevance feedback techniques for enhanced user experience. In Proceedings of the 13th International Conference on Telecommunications, Graz, Austria, 13–15 July 2015; pp. 1–8. [Google Scholar]
- Tan, Y.; Qin, J.H.; Xiang, X.Y.; Neal, N. A Robust Watermarking Scheme in YCbCr Color Space Based on Channel Coding. IEEE Access 2019, 7, 25026–25036. [Google Scholar] [CrossRef]
- Qin, J.H.; Li, H.; Xiang, X.Y.; Tan, Y.; Neal, N.X. An Encrypted Image Retrieval Method Based on Harris Corner Optimization and LSH in Cloud Computing. IEEE Access 2019, 7, 24626–24633. [Google Scholar] [CrossRef]
- Chen, K.; Liu, Y.J. Real-time adaptive visual secret sharing with reversibility and high capacity. J. Real-Time Image Process. 2019, 16, 871–881. [Google Scholar]
- Bao, Z. Research on the Key Problems of Steganography in JPEG Images. Strategic Support Force Information Engineering University. 2018. Available online: https://cdmd.cnki.com.cn/Article/CDMD-91037-1018841713.htm (accessed on 20 August 2020).
- Zhang, Y.; Luo, X.Y. Enhancing reliability and efficiency for real-time robust adaptive steganography using cyclic redundancy check codes. J. Real-Time Image Process. 2020, 115–123. [Google Scholar] [CrossRef]
- Lee, C.; Shen, J. Overlapping pixel value ordering predictor for high-capacity reversible data hiding. J. Real-Time Image Process. 2019, 16, 835–855. [Google Scholar] [CrossRef]
- Luo, Y.J.; Qin, J.H.; Xiang, X.Y.; Tan, Y.; Liu, Q. Coverless real-time image information hiding based on image block matching and Dense Convolutional Network. J. Real-Time Image Process. 2020, 17, 125–135. [Google Scholar] [CrossRef]
- Liu, Q.; Xiang, X.Y.; Qin, J.H.; Tan, Y.; Tan, J.S. Coverless steganography based on image retrieval of DenseNet features and DWT sequence mapping. Knowl.-Based Syst. 2020, 192, 105375–105389. [Google Scholar] [CrossRef]
- Xiang, L.Y.; Guo, G.Q.; Yu, J.M. A convolutional neural network-based linguistic steganalysis for synonym substitution steganography. Math. Biosci. Eng. 2020, 192, 11041–11058. [Google Scholar] [CrossRef]
- Zhou, Z.L.; Sun, H.Y. Coverless Image Steganography Without Embedding. In Proceedings of the International Conference on Cloud Computing and Security, Nanjing, China, 13–15 August 2015; pp. 123–132. [Google Scholar]
- Zheng, S.L. Coverless Information Hiding Based on Robust Image Hashing; Springer: Cham, Switzerland, 2017; pp. 536–547. [Google Scholar]
- Zhou, Z.L.; Cao, Y.; Sun, X.M. Coverless Information Hiding Based on Bag-of-Words Model of Image. J. Appl. Sci. 2016, 34, 527–536. [Google Scholar]
- Otori, H. Texture Synthesis for Mobile Data Communications. IEEE Comput. Soc. 2009, 29, 74–81. [Google Scholar] [CrossRef]
- Otori, H. Data-Embeddable Texture Synthesis; Springer: Berlin/Heidelberg, Germany, 2007; pp. 146–157. [Google Scholar]
- Wu, K. Steganography Using Reversible Texture Synthesis. IEEE Trans. Image Process. 2015, 24, 130–139. [Google Scholar] [PubMed]
- Xu, J. Hidden message in a deformation-based texture. Vis. Comput. 2015, 31, 1653–1669. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z. Densely Connected Convolutional Networks. arXiv 2017, arXiv:1608.06993v5. [Google Scholar]
- Wang, J.; Qin, J.H. CAPTCHA recognition based on deep convolutional neural network. Math. Biosci. Eng. 2019, 16, 5851–5861. [Google Scholar] [CrossRef] [PubMed]
- Qin, J.H.; Pan, W.Y.; Xiang, X.Y. A biological image classification method based on improved CNN. Ecol. Inform. 2020, 58, 1–8. [Google Scholar] [CrossRef]
- Hayes, J. Generating Steganographic Images via Adversarial Training. arXiv 2017, arXiv:1703.00371v3. [Google Scholar]
- Baluja, S. Hiding Images in Plain Sight: Deep Steganography. In Proceedings of the 31st Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 2069–2079. [Google Scholar]
- Zhu, J.; Kaplan, R. HiDDeN: Hiding Data With Deep Networks. arXiv 2018, arXiv:1807.09937v1. [Google Scholar]
- Wu, P.; Yang, Y. StegNet: Mega Image Steganography Capacity with Deep Convolutional Network. Future Internet 2018, 10, 54. [Google Scholar] [CrossRef] [Green Version]
- Ian, G.; Jean, P. Generative Adeversarial Nets. NIPS 2014, 2672–2680. [Google Scholar]
- Volkhonskiy, D.; Nazarov, I. Steganographic generative adversarial networks. arXiv 2017, arXiv:1703.05502. [Google Scholar]
- Radford, A. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Shi, H.; Dong, J. SSGAN: Secure steganography based on generative adversarial networks. In Proceedings of the Pacific Rim Conference on Multimedia, Harbin, China, 28–29 September 2017; pp. 534–544. [Google Scholar]
- Arjovsky, M.; Chintala, S. Wasserstein GAN. arXiv 2017, arXiv:1701.07875. [Google Scholar]
- Tang, W.; Tan, S.; Li, B. Automatic Steganographic Distortion Learning Using a Generative Adversarial Network. IEEE Signal Process. Lett. 2017, 24, 1547–1551. [Google Scholar] [CrossRef]
- Vojtech, H.; Jessica, F.; Tomas, D. Universal distortion function for steganography in an arbitrary domain. J. Inf. Secur. 2014, 1, 1–13. [Google Scholar]
- Rahim, R.; Nadeem, M.S. End-to-end trained CNN encode-decoder networks for image steganography. arXiv 2017, arXiv:1711.07201. [Google Scholar]
- Zhang, K.; Xu, L. SteganoGAN: High Capacity Image Steganography with GANs. arXiv 2019, arXiv:1901.03892v2. [Google Scholar]
- He, K.; Zhang, X.Y.; Ren, S.Q. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 1904–1916. [Google Scholar] [CrossRef] [Green Version]
- Cachin, C. An information theoretic model for steganography. Inf. Comput. 2004, 192, 41–56. [Google Scholar] [CrossRef] [Green Version]
- Zhang, R.; Dong, S.; Liu, J. Invisible steganography via generative adversarial networks. Multimed. Tools Appl. 2019, 78, 8559–8575. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Bovik, C.A. Image Quality Assessment: From Error Visibility to Structural Similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [Green Version]




{kind=link}
{kind=link}
{kind=link}
| Layers | Name | Output Size |
|---|---|---|
| Input | / | |
| Layer1 | ConvBlock1 | |
| Layer2 | ConvBlock1 | |
| Layer3 | ConvBlock2 | |
| Layer4 | ConvBlock2 | |
| Layer5 | ConvBlock3 | |
| Layer6 | SPPBlock | |
| Layer7 | FC | |
| Layer8 | FC |
| Dataset | Depth | Ours | Zhang’s | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Basic Model | Dense Model | Basic Model | Dense Model | ||||||
| PSNR | MS-SSIM | PSNR | MS-SSIM | PSNR | MS-SSIM | PSNR | MS-SSIM | ||
| Div2k | 1 | 39.80 | 0.91 | 37.27 | 0.90 | 34.71 | 0.86 | 34.33 | 0.85 |
| 2 | 36.03 | 0.87 | 36.09 | 0.88 | 34.21 | 0.84 | 34.32 | 0.85 | |
| 3 | 34.74 | 0.84 | 34.65 | 0.84 | 33.14 | 0.80 | 33.00 | 0.80 | |
| 4 | 35.59 | 0.86 | 35.35 | 0.85 | 33.73 | 0.83 | 33.99 | 0.83 | |
| 5 | 35.88 | 0.87 | 36.47 | 0.88 | 34.17 | 0.84 | 34.36 | 0.84 | |
| 6 | 36.61 | 0.88 | 36.78 | 0.89 | 34.97 | 0.86 | 34.71 | 0.85 | |
| Dataset | Depth | Ours | Zhang’s | ||
|---|---|---|---|---|---|
| Basic Model | Dense Model | Basic Model | Dense Model | ||
| RS-BPP | |||||
| Div2k | 1 | 0.96 | 0.96 | 0.93 | 0.93 |
| 2 | 1.82 | 1.83 | 1.76 | 0.93 | |
| 3 | 2.36 | 2.36 | 2.18 | 2.22 | |
| 4 | 2.30 | 2.30 | 2.20 | 2.23 | |
| 5 | 2.28 | 2.31 | 2.15 | 2.19 | |
| 6 | 2.24 | 2.27 | 2.17 | 2.18 | |
| Dataset | Depth | Ours | Zhang’s | ||
|---|---|---|---|---|---|
| Basic Model | Dense Model | Basic Model | Dense Model | ||
| Accuracy of Recovery | |||||
| Div2k | 1 | 0.98 | 0.98 | 0.97 | 0.96 |
| 2 | 0.96 | 0.96 | 0.94 | 0.96 | |
| 3 | 0.89 | 0.89 | 0.86 | 0.87 | |
| 4 | 0.79 | 0.79 | 0.77 | 0.78 | |
| 5 | 0.73 | 0.73 | 0.72 | 0.72 | |
| 6 | 0.67 | 0.69 | 0.68 | 0.68 | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qin, J.; Wang, J.; Tan, Y.; Huang, H.; Xiang, X.; He, Z. Coverless Image Steganography Based on Generative Adversarial Network. Mathematics 2020, 8, 1394. https://doi.org/10.3390/math8091394
Qin J, Wang J, Tan Y, Huang H, Xiang X, He Z. Coverless Image Steganography Based on Generative Adversarial Network. Mathematics. 2020; 8(9):1394. https://doi.org/10.3390/math8091394
Chicago/Turabian StyleQin, Jiaohua, Jing Wang, Yun Tan, Huajun Huang, Xuyu Xiang, and Zhibin He. 2020. "Coverless Image Steganography Based on Generative Adversarial Network" Mathematics 8, no. 9: 1394. https://doi.org/10.3390/math8091394