An Estimation of Sensitive Attribute Applying Geometric Distribution under Probability Proportional to Size Sampling

Abstract
:1. Introduction
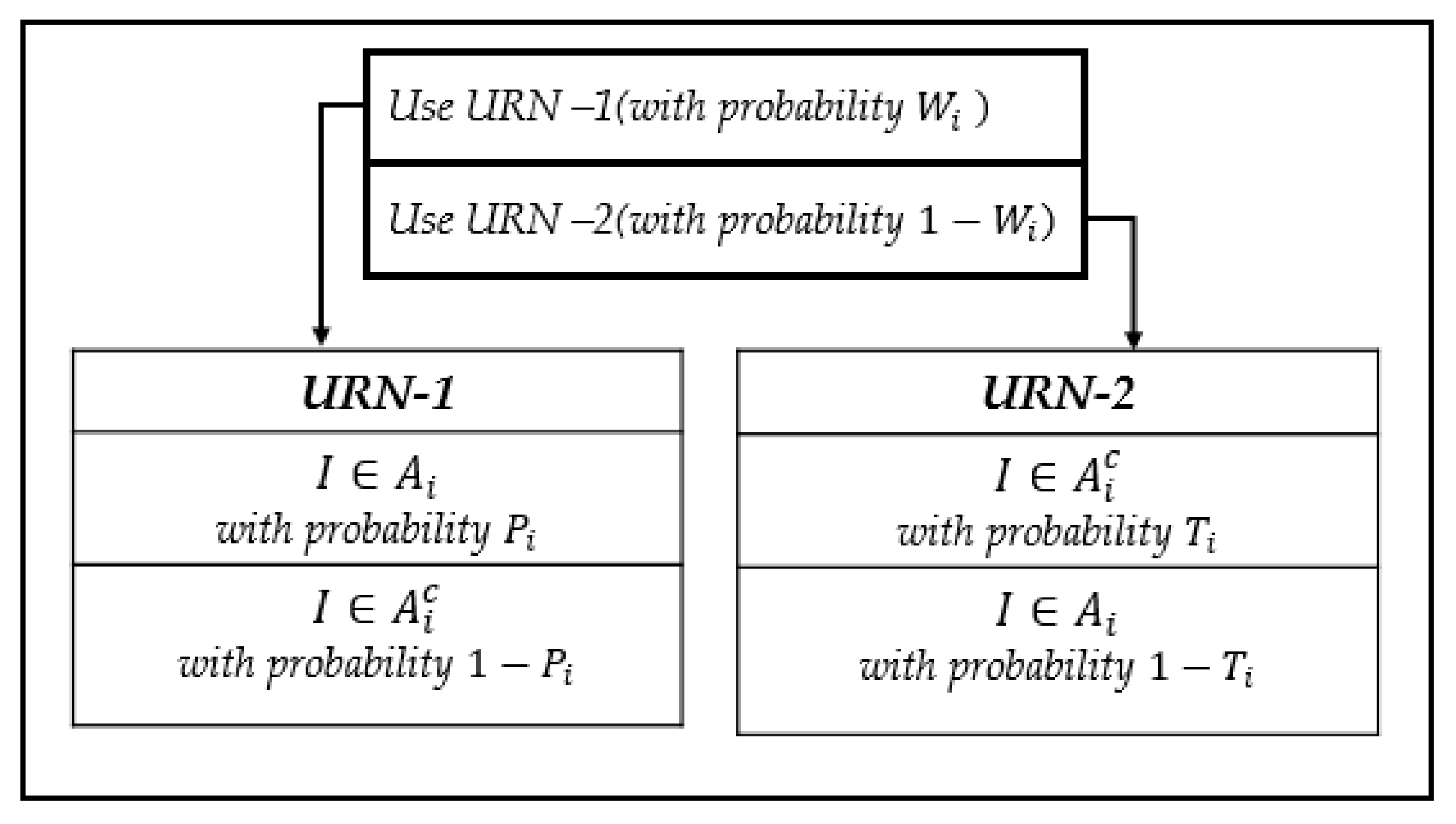
2. An Estimation of Sensitive Attributes with Probability Proportional to Size Sampling under Yennum et al.’s Model
2.1. PPS Sampling with Replacement
2.2. The PPS without Replacement
2.3. Two-Stage Equal Probability Sampling
3. An Estimation of Sensitive Attributes with Probability Proportional to Size Sampling Under Yennum et al.’s Generalized Model
3.1. PPS Sampling with Replacement
3.2. PPS Sampling Without Replacement
3.3. Two-Stage Equal Probability Sampling
4. Efficiency Comparisons
4.1. PPSWR Sampling versus Equal Probability Two-Stage Sampling in Yennum et al.’s Model
4.2. PPSWR Sampling versus Equal Probability Two-Stage Sampling in Yennum et al.’s Generalized Model
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Warner, S.L. Randomized response: A survey technique for eliminating evasive answer bias. J. Am. Stat. Assoc. 1965, 60, 63–69. [Google Scholar] [CrossRef] [PubMed]
- Cochran, W.G. Sampling Techniques, 3rd ed.; John Wiley and Sons: New York, NY, USA, 1977. [Google Scholar]
- Fox, J.A.; Tracy, P.E. Randomized Response: A Method for Sensitive Survey; Sage Publications: Newbury Park, CA, USA, 1986. [Google Scholar]
- Kuk, A.Y.C. Asking sensitive questions indirectly. Biometrika 1990, 77, 436–438. [Google Scholar] [CrossRef]
- Chaudhuri, A.; Mukerjee, R. Randomized Response: Theory and Techniques; Marcel Dekker Inc.: New York, NY, USA, 1988. [Google Scholar]
- Ryu, J.B.; Hong, K.H.; Lee, G.S. Randomized Response Model; Freedom Academy: Seoul, Korean, 1993. [Google Scholar]
- Lee, G.S.; Hong, K.H. Randomized response model by two-stage cluster sampling. Korean Commun. Stat. 1998, 5, 99–105. [Google Scholar]
- Lee, G.S. A Study on the Randomized Response Technique by PPS Sampling. Korean J. Appl. Stat. 2006, 19, 69–80. [Google Scholar]
- Yennum, N.Y.; Sedory, S.A.; Singh, S. Improved strategy to collect sensitive data by using geometric distribution as a randomization device. Commun. Stat. Theory Methods 2019, 48, 5777–5795. [Google Scholar] [CrossRef]
- Hussain, Z.; Shabbir, J.; Pervez, Z.; Shah, S.F.; Khan, M. Generalized geometric distribution of order k: A flexible choice to randomize the response. Commun. Stat. Simul. Comput. 2017, 46, 4708–4721. [Google Scholar] [CrossRef]


{kind=link}
| W | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T | 0.1 | 0.3 | 0.5 | 0.7 | 0.9 | |||||||||||
| P | 0.6 | 0.7 | 0.8 | 0.6 | 0.7 | 0.8 | 0.6 | 0.7 | 0.8 | 0.6 | 0.7 | 0.8 | 0.6 | 0.7 | 0.8 | |
| 0.1 | 0.65 | 56.59 | 95.07 | 123.5 | 48.08 | 61.06 | 91.71 | 52.73 | 46.18 | 55.97 | 63.18 | 52.59 | 39.63 | 75.51 | 71.08 | 61.88 |
| 0.7 | 54.42 | 89.17 | 120 | 50 | 54.61 | 81.69 | 58.65 | 48.28 | 48.17 | 71.01 | 60.85 | 45.08 | 83.88 | 80.2 | 72.61 | |
| 0.75 | 52.93 | 81.67 | 114.8 | 53.61 | 51.26 | 70.48 | 64.76 | 53.56 | 45.34 | 77.67 | 69.08 | 54.13 | 90.33 | 87.46 | 81.68 | |
| 0.8 | 52.61 | 72.72 | 106.4 | 58.15 | 51.63 | 59.9 | 70.32 | 60.37 | 48.28 | 83.01 | 76.38 | 64.29 | 95.2 | 93.08 | 88.97 | |
| 0.85 | 53.84 | 63.67 | 93.17 | 62.84 | 55.3 | 53.48 | 75.02 | 67.37 | 55.79 | 87.17 | 82.48 | 73.91 | 98.87 | 97.41 | 94.69 | |
| 0.9 | 56.57 | 57.65 | 74.27 | 67.15 | 61.05 | 54.47 | 78.79 | 73.8 | 65.52 | 90.32 | 87.41 | 82.23 | 101.6 | 100.7 | 99.15 | |
| 0.2 | 0.65 | 82.74 | 134.4 | 153.1 | 50.22 | 92.87 | 130.8 | 60.29 | 48.44 | 86.05 | 90.64 | 61.69 | 34.18 | 117.4 | 108.9 | 89.02 |
| 0.7 | 75.82 | 129.7 | 151.4 | 51.78 | 76.68 | 121.8 | 77.73 | 48.28 | 65.5 | 108.7 | 84.97 | 43.35 | 130.7 | 125.1 | 111.8 | |
| 0.75 | 68.56 | 122.7 | 148.7 | 60.97 | 61.93 | 108.4 | 94.15 | 62.33 | 48.62 | 121.2 | 104.6 | 67.95 | 139 | 135.4 | 127 | |
| 0.8 | 62.59 | 111.6 | 144.1 | 74.34 | 56.05 | 88.85 | 107.2 | 82.13 | 48.28 | 129.7 | 118.9 | 94 | 144.4 | 142.1 | 137 | |
| 0.85 | 61.04 | 94.57 | 135 | 87.93 | 64.32 | 66.55 | 116.7 | 100.4 | 68.61 | 135.4 | 128.9 | 114.4 | 148 | 146.5 | 143.6 | |
| 0.9 | 66.6 | 74.23 | 114.3 | 99.4 | 82.02 | 61.52 | 123.5 | 114.4 | 95.72 | 139.3 | 135.8 | 128.5 | 150.4 | 149.6 | 148.1 | |
| 0.3 | 0.65 | 106.8 | 152.4 | 164.9 | 54.34 | 117.7 | 149.2 | 70.41 | 53.88 | 109.9 | 119 | 74.13 | 31.19 | 148.1 | 139.5 | 115.9 |
| 0.7 | 98.24 | 149.4 | 163.9 | 53.64 | 99.37 | 142.7 | 100.6 | 48.28 | 85.26 | 139.9 | 111.1 | 42.92 | 159 | 154.4 | 141.5 | |
| 0.75 | 87.63 | 144.7 | 162.4 | 70.27 | 76.57 | 132.3 | 124 | 73.92 | 55.9 | 151.7 | 135.4 | 85.58 | 164.8 | 162.2 | 155.2 | |
| 0.8 | 76.17 | 136.6 | 159.9 | 94.79 | 61.53 | 114 | 139.2 | 107.4 | 48.28 | 158.6 | 149.6 | 122.7 | 168.2 | 166.6 | 162.8 | |
| 0.85 | 69.9 | 121.6 | 154.7 | 116.5 | 75.47 | 83.46 | 148.7 | 131.9 | 85.14 | 162.8 | 158 | 145.2 | 170.2 | 169.4 | 167.4 | |
| 0.9 | 78.83 | 94.88 | 140.8 | 131.9 | 107.7 | 69.61 | 154.7 | 146.9 | 126.4 | 165.4 | 163.1 | 157.6 | 171.6 | 171.1 | 170.2 | |
| 0.4 | 0.65 | 124.6 | 162.1 | 171.2 | 59.97 | 134.4 | 159.3 | 82.29 | 61.29 | 126.3 | 141.7 | 88.14 | 30.06 | 166.3 | 159.3 | 136.7 |
| 0.7 | 116.5 | 160 | 170.5 | 55.58 | 117.6 | 154.6 | 122.6 | 48.28 | 102.2 | 160.3 | 133.3 | 43.6 | 173.7 | 170.4 | 159.7 | |
| 0.75 | 105.4 | 156.9 | 169.6 | 81.25 | 91.92 | 146.7 | 147.4 | 87.35 | 65.18 | 169.2 | 156.3 | 103.3 | 177.3 | 175.5 | 170.3 | |
| 0.8 | 91.07 | 151.5 | 168 | 116.6 | 67.99 | 131.8 | 160.8 | 130.8 | 48.28 | 173.8 | 167.6 | 144.2 | 179.1 | 178.2 | 175.5 | |
| 0.85 | 80.35 | 140.6 | 164.9 | 142.3 | 88.79 | 100.6 | 168.2 | 155.2 | 103.2 | 176.4 | 173.5 | 164 | 180.2 | 179.7 | 178.4 | |
| 0.9 | 93.87 | 116 | 156.4 | 157 | 133.7 | 78.99 | 172.3 | 167.2 | 150.6 | 178 | 176.6 | 173.2 | 180.9 | 180.6 | 180.1 | |
| W | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T | 0.1 | 0.3 | 0.5 | 0.7 | 0.9 | |||||||||||
| P | 0.6 | 0.7 | 0.8 | 0.6 | 0.7 | 0.8 | 0.6 | 0.7 | 0.8 | 0.6 | 0.7 | 0.8 | 0.6 | 0.7 | 0.8 | |
| 0.1 | 0.65 | 171.5 | 172.8 | 172.8 | 163 | 166.9 | 167.9 | 145.4 | 155.4 | 159.1 | 104.1 | 126.5 | 138.8 | 48.17 | 52.15 | 68.27 |
| 0.7 | 167.5 | 169.7 | 170.1 | 152.7 | 160.2 | 163.1 | 119.1 | 139.1 | 148.9 | 57.85 | 83.09 | 111 | 78.98 | 76.63 | 58.68 | |
| 0.75 | 162.2 | 165.9 | 167 | 135.6 | 150.2 | 156.7 | 79 | 111 | 133.1 | 54.18 | 48.22 | 69.55 | 116.3 | 124.4 | 117.6 | |
| 0.8 | 154.2 | 160.9 | 163.3 | 106.2 | 133.1 | 147.2 | 48.74 | 68.09 | 105.6 | 88.1 | 76.9 | 50.14 | 136.5 | 148.1 | 152.8 | |
| 0.85 | 139.8 | 153.1 | 158.5 | 64.63 | 99.62 | 130.1 | 64.15 | 50.65 | 60.85 | 116.4 | 120.1 | 102.3 | 147 | 159.4 | 168.3 | |
| 0.9 | 108.4 | 136 | 150.3 | 49.94 | 51.5 | 89.01 | 96.84 | 95.38 | 69.51 | 133 | 144.7 | 150.1 | 152.7 | 165.1 | 175.3 | |
| 0.2 | 0.65 | 180.9 | 181.1 | 181 | 177 | 178.1 | 178.3 | 168.4 | 172 | 173.1 | 140.7 | 154.2 | 160 | 48.39 | 59.25 | 87.17 |
| 0.7 | 178.9 | 179.5 | 179.5 | 172.1 | 174.6 | 175.5 | 152.4 | 162.4 | 166.8 | 75.03 | 112.8 | 137.8 | 120.5 | 111 | 71.17 | |
| 0.75 | 176.4 | 177.5 | 177.8 | 163.1 | 169.2 | 171.8 | 113.3 | 142.1 | 156.1 | 67.28 | 48.47 | 88.43 | 159.6 | 161.5 | 149 | |
| 0.8 | 172.6 | 174.9 | 175.8 | 143.4 | 159.1 | 166.1 | 50.3 | 91.74 | 133.4 | 132.9 | 110.7 | 52.83 | 171.6 | 175.4 | 173.9 | |
| 0.85 | 165.8 | 171 | 173.1 | 91.83 | 133.9 | 154.7 | 94.45 | 55.74 | 74.87 | 160 | 159 | 135.4 | 176.4 | 180.4 | 182.1 | |
| 0.9 | 147.3 | 162.3 | 168.5 | 55.09 | 58.5 | 118.4 | 145.2 | 139.7 | 94.09 | 170.3 | 174.6 | 173.7 | 178.6 | 182.6 | 185.2 | |
| 0.3 | 0.65 | 184 | 184 | 183.9 | 181.6 | 182 | 182 | 176.2 | 178 | 178.5 | 157.3 | 165.5 | 168.9 | 48.68 | 66.76 | 101.4 |
| 0.7 | 182.8 | 183 | 182.9 | 178.5 | 179.7 | 180.2 | 165.6 | 171.4 | 174 | 91.45 | 130.8 | 151.3 | 145.6 | 132.9 | 81.96 | |
| 0.75 | 181.2 | 181.7 | 181.8 | 172.9 | 176.1 | 177.6 | 134.5 | 156.5 | 166.1 | 81.89 | 48.76 | 102.6 | 174.4 | 173.9 | 161.9 | |
| 0.8 | 178.9 | 180 | 180.4 | 159.7 | 169.3 | 173.6 | 52.38 | 109.5 | 147.9 | 155.9 | 132.1 | 55.54 | 181.2 | 182.4 | 180.1 | |
| 0.85 | 174.8 | 177.5 | 178.6 | 114.3 | 150.9 | 165.5 | 120.4 | 61.6 | 86.84 | 174.9 | 172.4 | 151.2 | 183.6 | 185.3 | 185.4 | |
| 0.9 | 163.6 | 172.1 | 175.6 | 62.66 | 66.66 | 135.6 | 166.4 | 160.1 | 112.1 | 180.7 | 182.3 | 180.3 | 184.7 | 186.4 | 187.3 | |
| 0.4 | 0.65 | 185.5 | 185.5 | 185.4 | 183.9 | 184.1 | 184 | 180 | 181 | 181.3 | 166.1 | 171.6 | 173.8 | 49.04 | 74.03 | 112.4 |
| 0.7 | 184.7 | 184.8 | 184.7 | 181.7 | 182.4 | 182.6 | 172.3 | 176.1 | 177.9 | 105.3 | 142.5 | 159.4 | 159.6 | 146.4 | 91.15 | |
| 0.75 | 183.5 | 183.8 | 183.9 | 177.7 | 179.7 | 180.7 | 147.7 | 164.5 | 171.7 | 95.48 | 49.07 | 113.7 | 180.5 | 179.2 | 168.8 | |
| 0.8 | 181.9 | 182.6 | 182.9 | 168.2 | 174.7 | 177.7 | 54.79 | 122.6 | 156.8 | 167.6 | 145.4 | 58.24 | 184.8 | 185.2 | 182.8 | |
| 0.85 | 179.2 | 180.8 | 181.6 | 130.6 | 160.5 | 171.4 | 138.7 | 67.61 | 97.01 | 181 | 178.3 | 160.1 | 186.3 | 187 | 186.7 | |
| 0.9 | 171.7 | 177.1 | 179.3 | 71.76 | 75 | 146.8 | 176 | 170.1 | 125 | 184.7 | 185.3 | 183.2 | 186.9 | 187.8 | 188.1 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, G.-S.; Hong, K.-H.; Son, C.-K. An Estimation of Sensitive Attribute Applying Geometric Distribution under Probability Proportional to Size Sampling. Mathematics 2019, 7, 1102. https://doi.org/10.3390/math7111102
Lee G-S, Hong K-H, Son C-K. An Estimation of Sensitive Attribute Applying Geometric Distribution under Probability Proportional to Size Sampling. Mathematics. 2019; 7(11):1102. https://doi.org/10.3390/math7111102
Chicago/Turabian StyleLee, Gi-Sung, Ki-Hak Hong, and Chang-Kyoon Son. 2019. "An Estimation of Sensitive Attribute Applying Geometric Distribution under Probability Proportional to Size Sampling" Mathematics 7, no. 11: 1102. https://doi.org/10.3390/math7111102