
LCA-GAN: Low-Complexity Attention-Generative Adversarial Network for Age Estimation with Mask-Occluded Facial Images

Abstract
:1. Introduction
- This is the first study of its kind on age estimation that considers the de-occlusion of facial images where the nose and mouth are completely occluded by a mask;
- We propose a novel LCA-GAN for mask de-occlusion. LCA-GAN contains low-complexity attention blocks (LCABs) that reduce computation and complexity by combining down and upsampling with the attention module. LCAB comprises low-complexity channel attention (LCCA) and low-complexity spatial attention (LCSA), and it uses attention to assign weights based on the importance of features in channel and spatial dimensions;
- To reconstruct the facial feature information lost by mask occlusion as much as possible in de-occlusion, edge loss and content loss in LCA-GAN were used;
- The trained LCA-GAN and CNN for age estimation and experimental mask generated facial images were published [12], enabling a fair comparison with the performance of other researchers.
2. Related Works
3. Proposed Methods
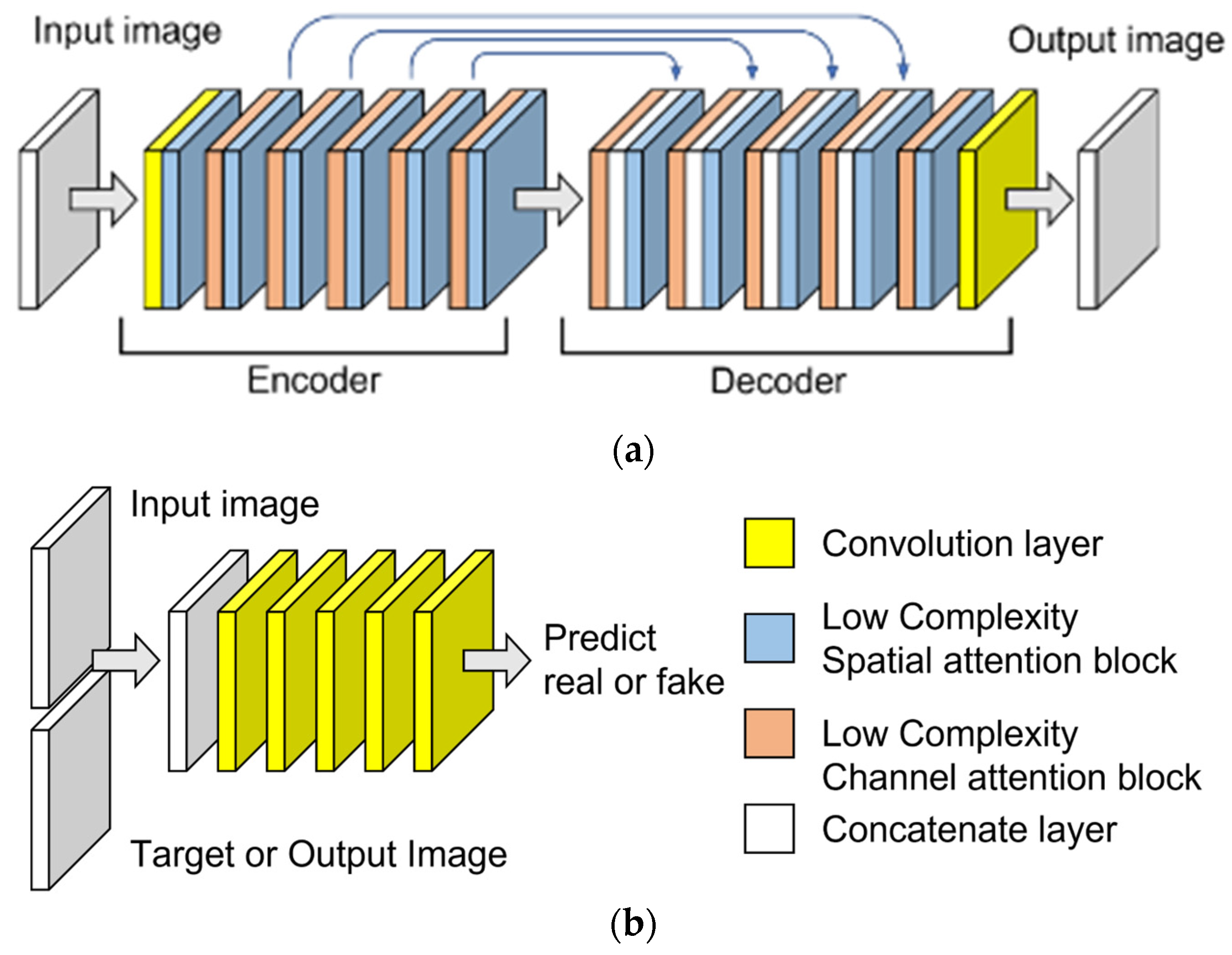
3.1. Overview of Suggested Method
3.2. Pre-Processing
3.3. De-Occlusion of Masked Facial Image by LCA-GAN
3.3.1. Generator
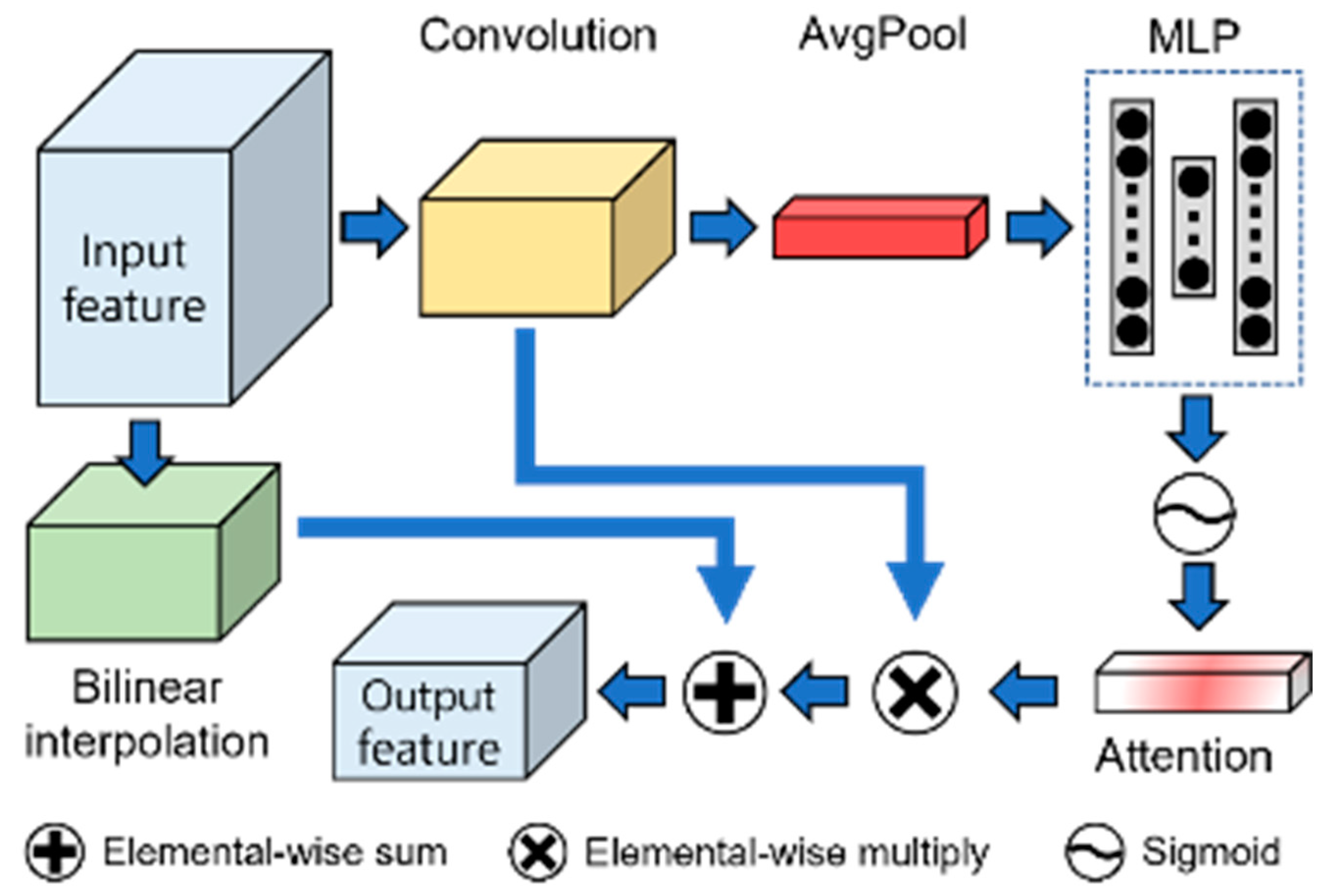
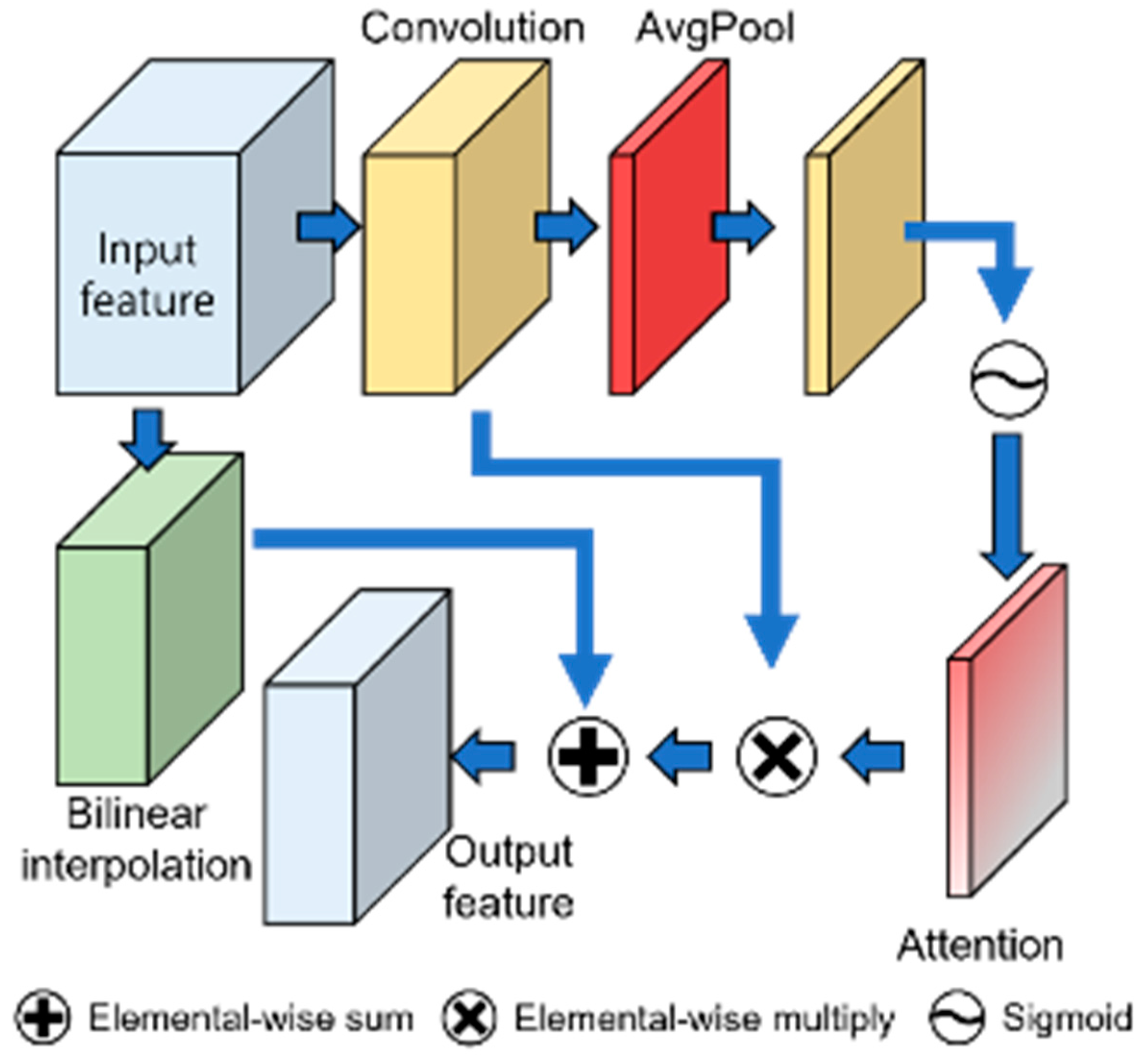
3.3.2. The Structure of LCAB
3.3.3. Discriminator
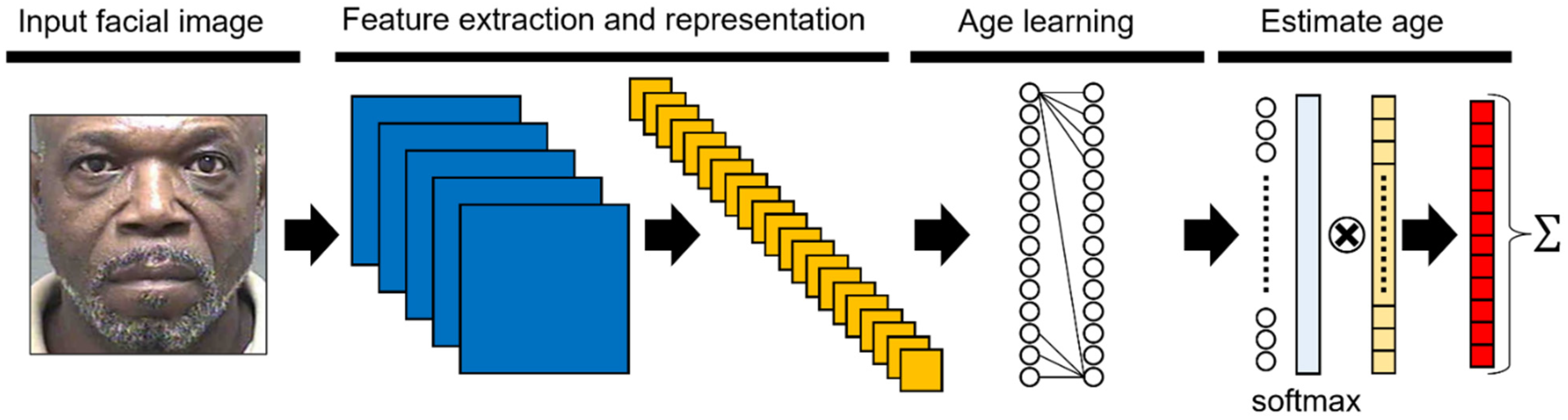
3.4. Age Estimator
4. Experimental Results
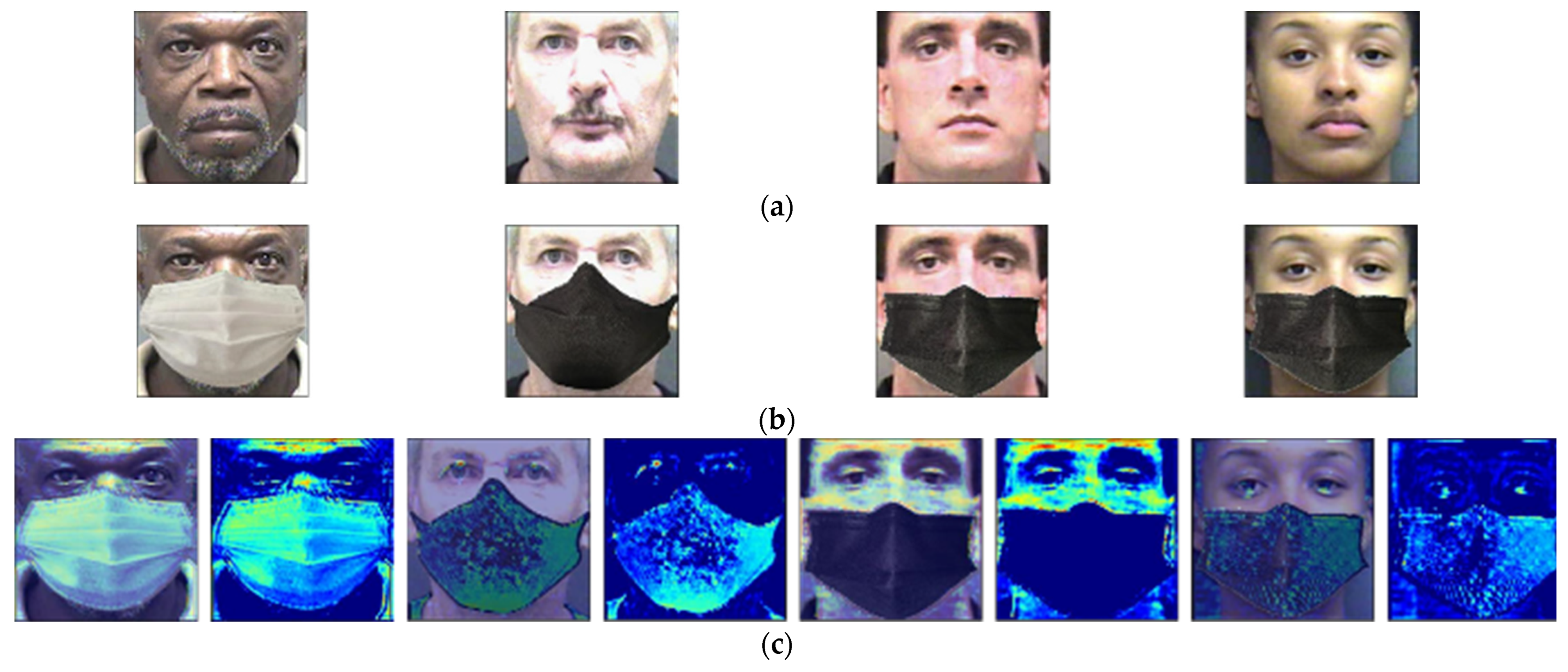
4.1. Data and Environment for Experiments
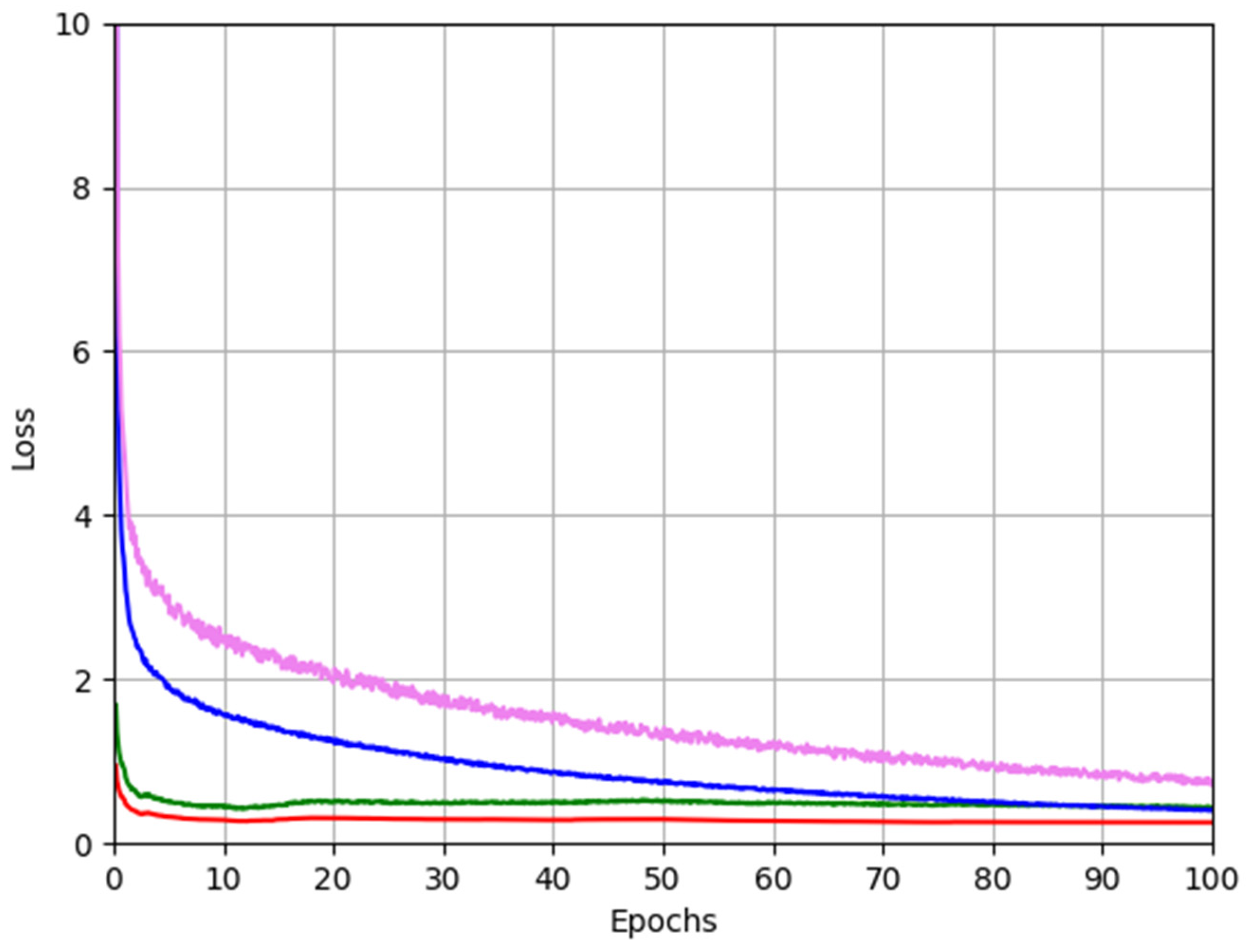
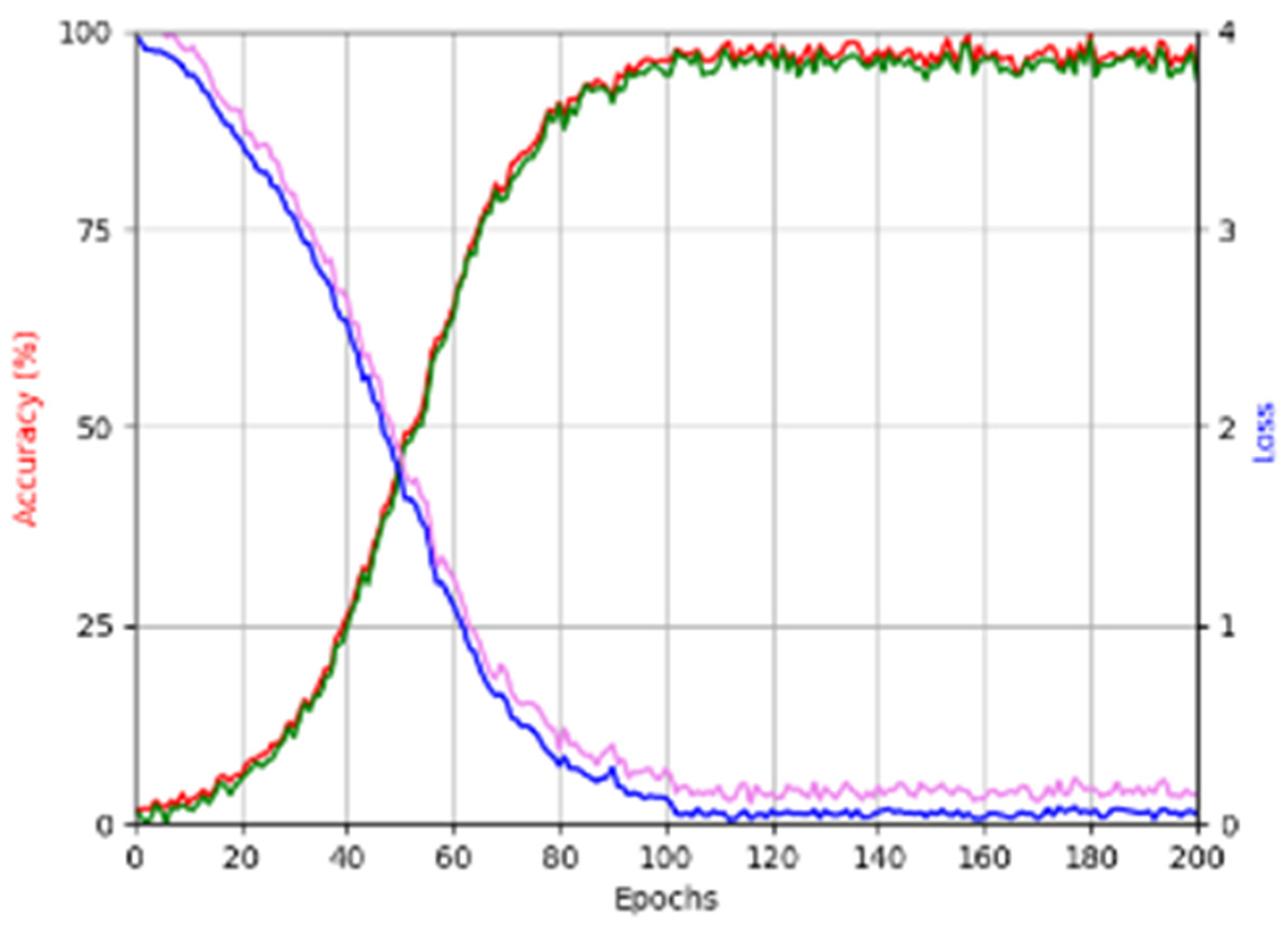
4.2. Training of LCA-GAN for Masked Image De-Occlusion and CNN for Age Estimation
4.3. Testing with MORPH Database
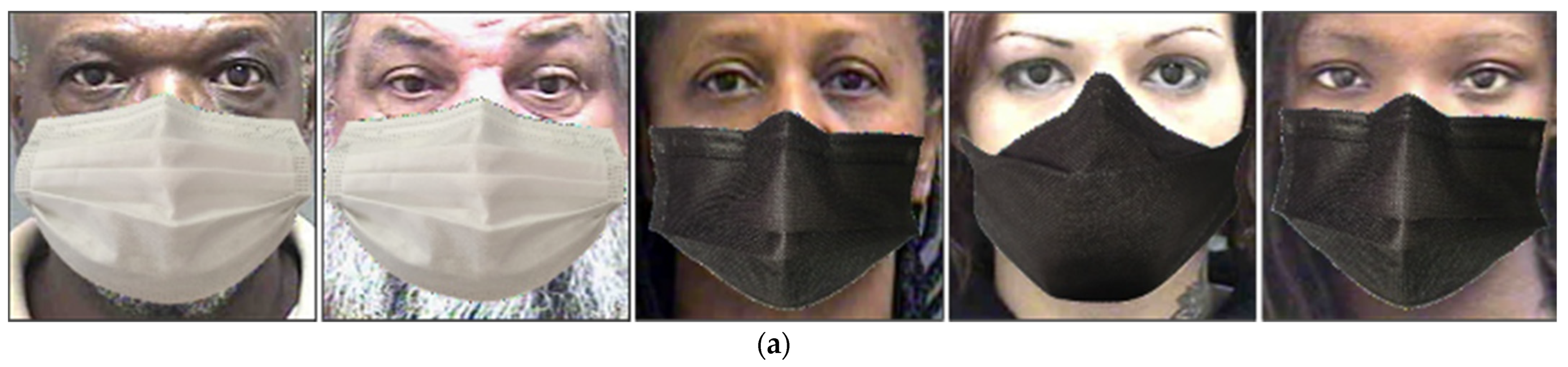
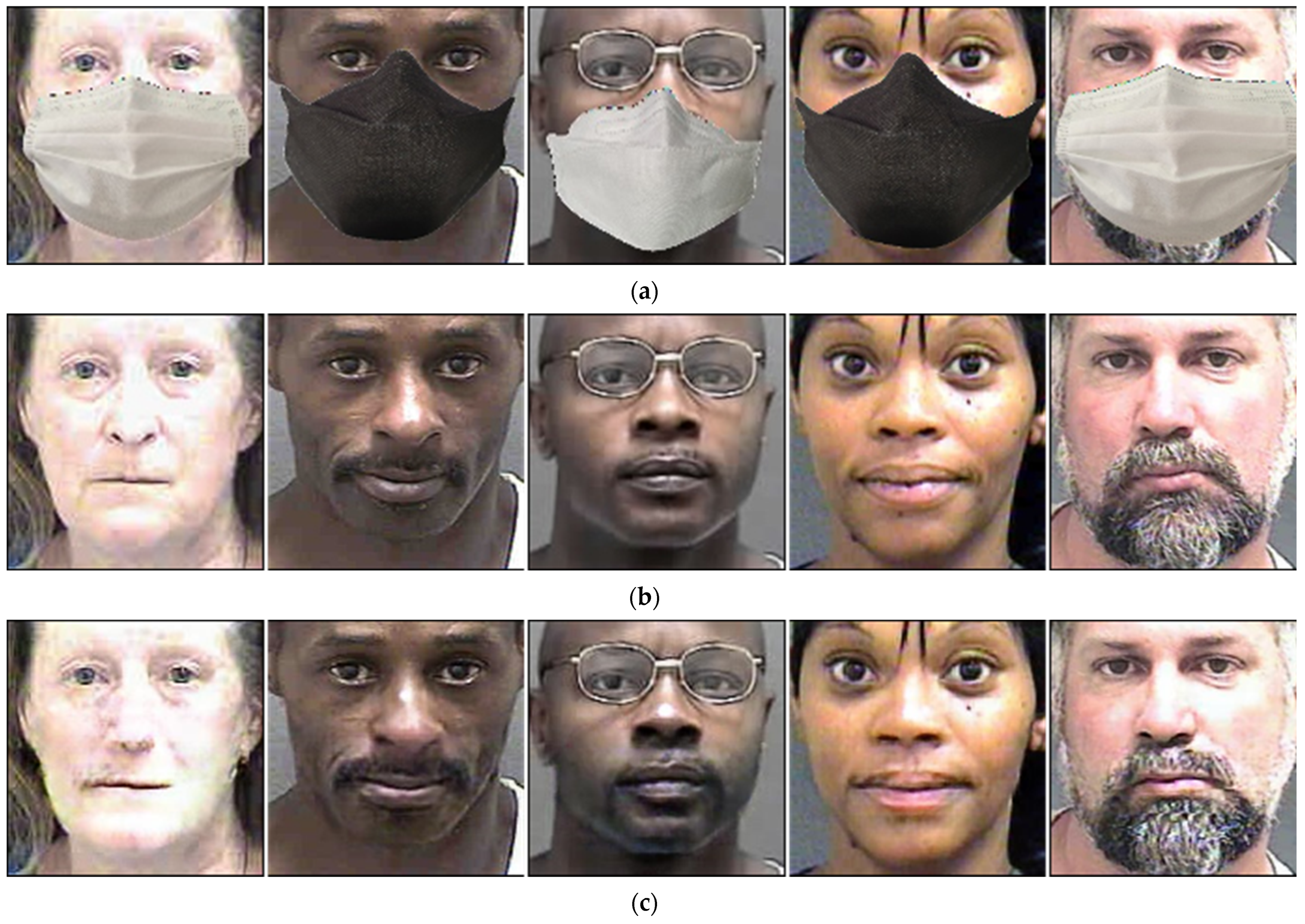
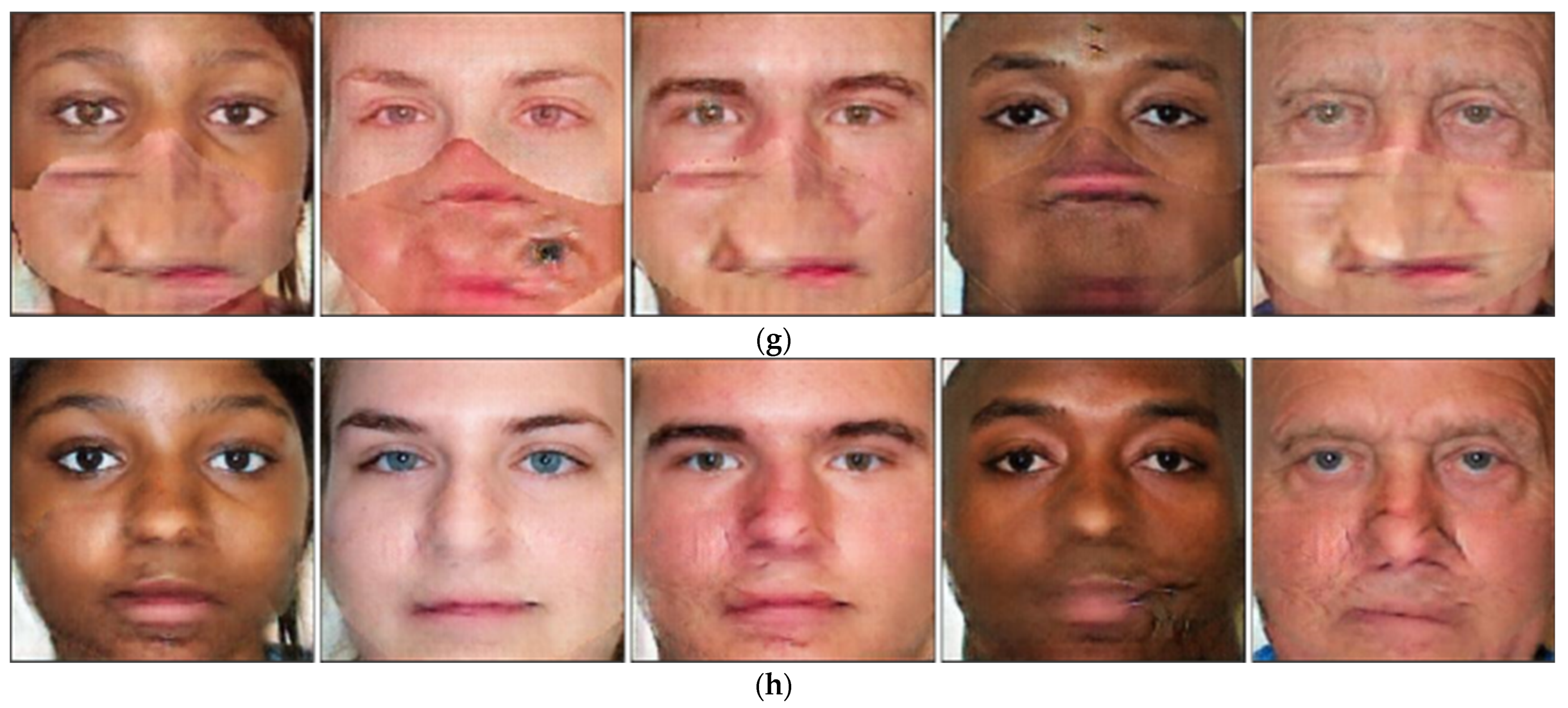
4.3.1. Comparisons of the Quality of Images Generated by Proposed Method and State-of-the-Art Methods
4.3.2. Comparisons of Age Estimation Accuracy
Ablation Studies
Comparisons of our LCA-GAN with Existing Methods
4.4. Testing with PAL Database
4.4.1. Comparisons of the Quality of Images Generated by Proposed Method and the State-of-the-Art Methods
4.4.2. Comparisons of Age Estimation Accuracy by Our LCA-GAN and the Existing Methods
4.5. Processing Speed
4.6. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gallagher, A.C.; Chen, T. Estimating age, gender, and identity using first name priors. In Proceedings of the 26th IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Angulu, R.; Tapamo, J.R.; Adewumi, A.O. Age estimation via face images: A survey. EURASIP J. Image Video Process. 2018, 2018, 42. [Google Scholar] [CrossRef]
- Wang, X.; Guo, R.; Kambhamettu, C. Deeply-learned feature for age estimation. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 5–9 January 2015; pp. 534–541. [Google Scholar]
- Farkas, J.P.; Pessa, J.E.; Hubbard, B.; Rohrich, R.J. The Science and Theory behind Facial Aging. Plast. Reconstr. Surg. Glob. Open 2013, 1, e8–e15. [Google Scholar] [CrossRef]
- Albert, A.M.; Ricanek, K., Jr.; Patterson, E. A review of the literature on the aging adult skull and face: Implications for forensic science research and applications. Forensic Sci. Int. 2007, 172, 1–9. [Google Scholar] [CrossRef]
- Olatunbosun, A.-A.; Serestina, V. Deep learning approach for facial age classification: A survey of the state-of-the-art. Artif. Intell. Rev. 2020, 54, 179–213. [Google Scholar]
- Antipov, G.; Baccouche, M.; Berrani, S.-A.; Dugelay, J.-L. Apparent age estimation from face images combining general and children-specialized deep learning models. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 801–809. [Google Scholar]
- Rothe, R.; Timofte, R.; Van Gool, L. Deep Expectation of Real and Apparent Age from a Single Image Without Facial Landmarks. Int. J. Comput. Vis. 2018, 126, 144–157. [Google Scholar] [CrossRef]
- Agbo-Ajala, O.; Viriri, S. Face-based age and gender classification using deep learning model. In Proceedings of the 2019 International Workshops, Sydney, NSW, Australia, 18–22 November 2019; pp. 125–137. [Google Scholar]
- Duan, M.; Li, K.; Li, K. An ensemble CNN2ELM for age estimation. IEEE Trans. Inf. Forensic Secur. 2018, 13, 758–772. [Google Scholar] [CrossRef]
- Liao, H.; Yan, Y.; Dai, W.; Fan, P. Age Estimation of Face Images Based on CNN and Divide-and-Rule Strategy. Math. Probl. Eng. 2018, 2018, 1712686. [Google Scholar] [CrossRef]
- LCA-GAN with Algorithm. (Model and Algorithm to Be Uploaded on Github). Available online: https://github.com/nsh6473/LCA-GAN/ (accessed on 1 February 2023).
- Buolamwini, J.; Gebru, T. Gender shades: Intersectional accuracy disparities in commercial gender classification. In Proceedings of the 1st Conference on Fairness, Accountability and Transparency, New York, NY, USA, 23–24 February 2018; pp. 77–91. [Google Scholar]
- Hiba, S.; Keller, Y. Hierarchical attention-based age estimation and Bias estimation. arXiv 2021, arXiv:2103.09882. [Google Scholar]
- Nimhed, C. Estimation of Height, Weight, Sex and Age from Magnetic Resonance Images Using 3D Convolutional Neural Networks. Master’s Thesis, Linköping University, Linköping, Sweden, 2022; pp. 1–60. [Google Scholar]
- Yaman, D.; Eyiokur, F.I.; Ekenel, H.K. Multimodal soft biometrics: Combining ear and face biometrics for age and gender classification. Multimedia Tools Appl. 2021, 81, 22695–22713. [Google Scholar] [CrossRef]
- Onifade, O.F.W.; Akinyemi, J.D. A GW ranking approach for facial age estimation. Egypt. Comput. Sci. J. 2014, 38, 63–74. [Google Scholar]
- Levi, G.; Hassner, T. Age and gender classification using convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 11–12 June 2015; pp. 34–42. [Google Scholar]
- Chen, J.-C.; Kumar, A.; Ranjan, R.; Patel, V.M.; Alavi, A.; Chellappa, R. A cascaded convolutional neural network for age estimation of unconstrained faces. In Proceedings of the IEEE 8th International Conference on Biometrics Theory, Applications and Systems, Niagara Falls, NY, USA, 6–9 September 2016; pp. 1–8. [Google Scholar]
- Zhu, Y.; Li, Y.; Mu, G.; Guo, G. A study on apparent age estimation. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Santiago, Chile, 11–12 December 2015; pp. 267–273. [Google Scholar]
- Rothe, R.; Timofte, R.; Gool, L.V. Dex: Deep expectation of apparent age from a single image. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Santiago, Chile, 11–12 December 2015; pp. 252–257. [Google Scholar]
- Agustsson, E.; Timofte, R.; Escalera, S.; Baro, X.; Guyon, I.; Rothe, R. Apparent and real age estimation in still images with deep residual regressors on appa-real database. In Proceedings of the 12th IEEE International Conference on Automatic Face and Gesture Recognition, Washington, DC, USA, 30 May–3 June 2017; pp. 87–94. [Google Scholar]
- Anand, A.; Labati, R.D.; Genovese, A.; Munoz, E.; Piuri, V.; Scotti, F. Age estimation based on face images and pre-trained convolutional neural networks. In Proceedings of the 2017 IEEE Symposium Series on Computational Intelligence, Honolulu, HI, USA, 27 November–1 December 2017; pp. 1–7. [Google Scholar]
- Aydogdu, M.F.; Demirci, M.F. Age classification using an optimized CNN architecture. In Proceedings of the International Conference on Compute and Data Analysis, Lakeland, FL, USA, 19–23 May 2017; pp. 233–239. [Google Scholar]
- Zhang, K.; Gao, C.; Guo, L.; Sun, M.; Yuan, X.; Han, T.X.; Zhao, Z.; Li, B. Age Group and Gender Estimation in the Wild With Deep RoR Architecture. IEEE Access 2017, 5, 22492–22503. [Google Scholar] [CrossRef]
- Ranjan, R.; Zhou, S.; Chen, J.C.; Kumar, A.; Alavi, A.; Patel, V.M.; Chellappa, R. Unconstrained age estimation with deep convolutional neural networks. In Proceedings of the 2015 IEEE International Conference on Computer Vision Workshop, Santiago, Chile, 7–13 December 2015; pp. 351–359. [Google Scholar]
- Niu, Z.; Zhou, M.; Wang, L.; Gao, X.; Hua, G. Ordinal regression with multiple output CNN for age estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4920–4928. [Google Scholar]
- Li, W.; Lu, J.; Feng, J.; Xu, C.; Zhou, J.; Tian, Q. Bridgenet: A continuity-aware probabilistic network for age estimation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1145–1154. [Google Scholar]
- Gao, B.B.; Zhou, H.Y.; Wu, J.; Geng, X. Age estimation using expectation of label distribution learning. In Proceedings of the International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 712–718. [Google Scholar]
- Zhang, K.; Liu, N.; Yuan, X.; Guo, X.; Gao, C.; Zhao, Z.; Ma, Z. Fine-Grained Age Estimation in the Wild With Attention LSTM Networks. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 3140–3152. [Google Scholar] [CrossRef]
- Chen, S.; Zhang, C.; Dong, M.; Le, J.; Rao, M. Using ranking-CNN for age estimation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 742–751. [Google Scholar]
- Liu, W.; Chen, L.; Chen, Y. Age Classification Using Convolutional Neural Networks with the Multi-class Focal Loss. IOP Conf. Series: Mater. Sci. Eng. 2018, 428, 012043. [Google Scholar] [CrossRef]
- Liu, H.; Lu, J.; Feng, J.; Zhou, J. Ordinal Deep Learning for Facial Age Estimation. IEEE Trans. Circuits Syst. Video Technol. 2017, 29, 486–501. [Google Scholar] [CrossRef]
- Gurpinar, F.; Kaya, H.; Dibeklioglu, H.; Salah, A.A. Kernel ELM and CNN based facial age estimation. In Proceedings of the 2016 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 785–791. [Google Scholar]
- Liu, K.-H.; Yan, S.; Kuo, C.-C.J. Age Estimation via Grouping and Decision Fusion. IEEE Trans. Inf. Forensics Secur. 2015, 10, 2408–2423. [Google Scholar] [CrossRef]
- Liu, W.; Wang, Z.; Liu, X.; Zeng, N.; Liu, Y.; Alsaadi, F.E. A survey of deep neural network architectures and their applications. Neurocomputing 2017, 234, 11–26. [Google Scholar] [CrossRef]
- Duan, M.; Li, K.; Yang, C.; Li, K. A hybrid deep learning CNNELM for age and gender classification. Neurocomputing 2018, 275, 448–461. [Google Scholar] [CrossRef]
- Liu, X.; Zou, Y.; Kuang, H.; Ma, X. Face Image Age Estimation Based on Data Augmentation and Lightweight Convolutional Neural Network. Symmetry 2020, 12, 146. [Google Scholar] [CrossRef]
- MORPH Database. Available online: https://ebill.uncw.edu/C20231_ustores/web/store_main.jsp?STOREID=4 (accessed on 17 May 2022).
- FGNET Database. Available online: https://yanweifu.github.io/FG_NET_data/index.html (accessed on 17 May 2022).
- IMDB Database. Available online: https://www.imdb.com/interfaces/ (accessed on 17 May 2022).
- Adience Database. Available online: https://talhassner.github.io/home/projects/Adience/Adience-data.html/ (accessed on 17 May 2022).
- LAP 2015 Database. Available online: https://chalearnlap.cvc.uab.cat/dataset/18/description/ (accessed on 17 May 2022).
- LAP 2016 Database. Available online: https://chalearnlap.cvc.uab.cat/dataset/19/description/ (accessed on 17 May 2022).
- CACD Database. Available online: https://bcsiriuschen.github.io/CARC/ (accessed on 17 May 2022).
- Guo, G.; Mu, G. Human age estimation: What is the influence across race and gender. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, San Francisco, CA, USA, 13–18 June 2010; pp. 71–78. [Google Scholar]
- Chen, K.; Gong, S.; Xiang, T.; Change Loy, C. Cumulative attribute space for age and crowd density estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2467–2474. [Google Scholar]
- Szegedy, C.; Loffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. arXiv 2016, arXiv:1602.07261v2. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Ma, N.; Zhang, X.; Zheng, H.-T.; Sun, J. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar] [CrossRef]
- Looking at People CVPR Challenge—Track1: Age Estimation. Available online: https://chalearnlap.cvc.uab.cat/challenge/13/description/ (accessed on 17 May 2022).
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Dong, J.; Zhang, L.; Zhang, H.; Liu, W. Occlusion-aware GAN for face de-occlusion in the wild. In Proceedings of the IEEE International Conference on Multimedia and Expo, London, UK, 6–10 July 2020; pp. 1–6. [Google Scholar]
- Jabbar, A.; Li, X.; Assam, M.; Khan, J.A.; Obayya, M.; Alkhonaini, M.A.; Al-Wesabi, F.N.; Assad, M. AFD-StackGAN: Automatic nask generation network for face de-occlusion using StackGAN. Sensors 2022, 22, 1747. [Google Scholar] [CrossRef]
- Ju, Y.-J.; Lee, G.-H.; Hong, J.-H.; Lee, S.-W. Complete Face Recovery GAN: Unsupervised joint face rotation and de-occlusion from a single-view image. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 3711–3721. [Google Scholar]
- Zhao, F.; Feng, J.; Zhao, J.; Yang, W.; Yan, S. Robust LSTM-Autoencoders for Face De-Occlusion in the Wild. IEEE Trans. Image Process. 2017, 27, 778–790. [Google Scholar] [CrossRef] [PubMed]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar]
- Iliadis, M.; Wang, H.; Molina, R.; Katsaggelos, A.K. Robust and Low-Rank Representation for Fast Face Identification With Occlusions. IEEE Trans. Image Process. 2017, 26, 2203–2218. [Google Scholar] [CrossRef] [PubMed]
- Din, N.U.; Javed, K.; Bae, S.; Yi, J. A Novel GAN-Based Network for Unmasking of Masked Face. IEEE Access 2020, 8, 44276–44287. [Google Scholar] [CrossRef]
- Khan, M.K.J.; Din, N.U.; Bae, S.; Yi, J. Interactive Removal of Microphone Object in Facial Images. Electronics 2019, 8, 1115. [Google Scholar] [CrossRef]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Dlib C++ Library. Available online: http://dlib.net/ (accessed on 17 May 2022).
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Jiang, J.; Wang, C.; Liu, X.; Ma, J. Deep Learning-based Face Super-resolution: A Survey. ACM Comput. Surv. 2021, 55, 1–36. [Google Scholar] [CrossRef]
- Looking at People ICCV Challenge—Track1: Age Estimation. Available online: https://chalearnlap.cvc.uab.cat/challenge/12/description/ (accessed on 17 May 2022).
- Nam, S.H.; Kim, Y.H.; Choi, J.; Hong, S.B.; Owais, M.; Park, K.R. LAE-GAN-Based Face Image Restoration for Low-Light Age Estimation. Mathematics 2021, 9, 2329. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- PAL database. Available online: http://agingmind.utdallas.edu/download-stimuli/face-database/ (accessed on 17 May 2022).
- Python. Available online: https://www.python.org/ (accessed on 1 October 2019).
- OpenCV. Available online: http://opencv.org (accessed on 1 October 2022).
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M. Tensorflow: Large-scale machine learning on heterogeneous distributed systems. arXiv 2016, arXiv:1603.04467v2. [Google Scholar]
- NVIDIA GeForce GTX 1070. Available online: https://www.nvidia.com/en-in/geforce/products/10series/geforce-gtx-1070/ (accessed on 21 April 2022).
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations, Sandiego, CA, USA, 7–9 May 2015; pp. 1–15. [Google Scholar]
- Goodfellow, I. NIPS 2016 Tutorial: Generative adversarial networks. arXiv 2017, arXiv:1701.00160v4. [Google Scholar]
- Salimans., T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X.; Chen, X. Improved techniques for training GANs. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 2234–2242. [Google Scholar]
- Arjovsky, M.; Bottou, L. Towards principled methods for training generative adversarial networks. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017; pp. 1–17. [Google Scholar]
- Loshchilov, I.; Hutter, F. Fixing weight decay regularization in ADAM. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018; pp. 1–4. [Google Scholar]
- Smith, S.L.; Kindermans, P.-J.; Ying, C.; Le, Q.V. Don’t decay the learning rate increase the batch size. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018; pp. 1–11. [Google Scholar]
- Reddi, S.J.; Kale, S.; Kumar, S. On the convergence of Adam and beyond. arXiv 2019, arXiv:1904.09237v1. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image Quality Assessment: From Error Visibility to Structural Similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Antkowiak, J.; Baina, T.J. Final Report from the Video Quality Experts Group on the Validation of Objective Models of Video Quality Assessment. ITU-T Standards Contribution COM, 2000. Available online: https://www.vqeg.org/publications-and-software/ (accessed on 17 May 2022).
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.-H.; Shao, L. Multi-stage progressive image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14821–14831. [Google Scholar]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Sharma, N.; Sharma, R.; Jindal, N. Face-Based Age and Gender Estimation Using Improved Convolutional Neural Network Approach. Wirel. Pers. Commun. 2022, 124, 3035–3054. [Google Scholar] [CrossRef]
- Zhang, B.; Bao, Y. Age Estimation of Faces in Videos Using Head Pose Estimation and Convolutional Neural Networks. Sensors 2022, 22, 4171. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Liu, X.; Li, S.; Kan, M.; Zhang, J.; Wu, S.; Liu, W.; Han, H.; Shan, S.; Chen, X. Agenet: Deeply learned regressor and classifier for robust apparent age estimation. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Santiago, Chile, 7–13 December 2015; pp. 16–24. [Google Scholar]
- Jetson TX2 Module. Available online: https://www.nvidia.com/en-us/autonomous-machines/embedded-systems-dev-kits-modules/ (accessed on 15 September 2022).
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar] [CrossRef]























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Categories | Method | Database | MAE | Exact | 1-Off | ϵ-Error |
|---|---|---|---|---|---|---|
| Classification of multi-class ages | DEX [21] | IMDB-WIKI + LAP2015 | 3.22 | N.A. | N.A. | 0.26 |
| Residual DEX [22] | LAP2015 | 4.45 | N.A. | |||
| Dimensionality reduction + FFNNs [23] | WIKI + AmI-Face + Adience | 3.30 | ||||
| 4C2FC [24] | MORPH | N.A. | 46.39 | |||
| RoR [25] | IMDB-WIKI + Adience | 67.3 | 97.51 | |||
| DEX [8] | MORPH | 2.68 | N.A. | N.A. | ||
| FG-NET | 3.09 | |||||
| CACD | 6.52 | |||||
| IMDB-WIKI + LAP2015 | N.A. | 64.0 | ||||
| Adience | N.A. | 96.6 | 0.26 | |||
| 4C2FC + dropout [9] | Adience | N.A. | 84.8 | 89.7 | N.A. | |
| Regression based on metrics | 3NNR [26] | Adience + MORPH + LAP2015 | N.A. | N.A. | N.A. | 0.37 |
| OR-CNN [27] | AFAD MORPH | 3.34 3.27 | N.A. | |||
| VGG + BridgeNet [28] | MORPH FG-NET LAP2015 | 2.38 2.56 2.98 | ||||
| 0.26 | ||||||
| Learning by the distribution of deep label | DLDL-v2 [29] | LAP2015 LAP2016 MORPH | 3.14 3.45 1.97 | 0.272 | ||
| 0.267 | ||||||
| N.A. | ||||||
| Inception v4 [30] | MORPH FG-NET | 1.32 2.19 | ||||
| Ranking | Ranking-CNN [31] | MORPH | 2.96 | |||
| ODFL + OHRank [32] | MORPH FG-NET LAP2016 Adience | 3.12 3.89 4.12 N.A. | ||||
| N.A. | ||||||
| 0.34 | ||||||
| 54.0 | 88.2 | N.A. | ||||
| ODL [33] | MORPH FG-NET LAP2016 | 2.92 3.71 3.95 | N.A. | N.A. | N.A. | |
| 0.312 | ||||||
| Hybrid methods | Kernel ELM + CNN [34] | LAP2016 | N.A. | 0.37 | ||
| MRCNN [35] | MORPH | 3.48 | N.A. | |||
| GA-DFL [36] | MORPH FG-NET LAP2015 | 3.25 3.93 4.21 | N.A. N.A. 0.37 | |||
| CNN + ELM [37] | MORPH Adience | 3.44 N.A. | N.A. 52.3 | N.A. | ||
| RAGN [10] | IMDB-WIKI + MORPH IMDB-WIKI + Adience IMDB-WIKI + LAP2016 | 2.61 N.A. N.A. | N.A. 66.5 N.A. | N.A. | ||
| 0.37 | ||||||
| AgeNet + divide and rule [11] | FG-NET MORPH IMDB-WIKI | 4.02 3.48 3.29 | N.A. | N.A. | ||
| MA-ShuffleNet v2 [38] | MORPH FG-NET | 2.68 3.81 |
| Categories | Age Learning Technique | Method | Strength | Weakness |
|---|---|---|---|---|
| Age estimation without considering face occlusion | Handcrafted feature-based | Guo et al. [46] | Age estimation robust to restricted environment | They did not consider face-occluded images for age estimation |
| Chen et al. [47] | ||||
| Deep feature-based | Inception v4 [30] | |||
| MA-ShuffleNet v2 [38] | ||||
| Age estimation with considering face occlusion | DEX [8] | Age estimation robust to occluded facial images | They trained simultaneously with occlusion and non-occlusion images, which made network convergence difficult | |
| AgeNet + divide and rule [11] | ||||
| RAGN [10] | ||||
| 4C2FC + dropout [9] | ||||
| Proposed method | Additional procedures are required to train LCA-GAN |
| Layer | Size of Feature | Concatenation | ||
|---|---|---|---|---|
| Input image | 256 × 256 × 3 | - | ||
| Encoder | Convolution layer 1 | 256 × 256 × 64 | - | |
| Spatial attention | 256 × 256 × 64 | - | ||
| LCAB 1 | LCCA LCSA | 128 × 128 × 64 128 × 128 × 128 | - | |
| LCAB 2 | LCCA LCSA | 64 × 64 × 128 64 × 64 × 256 | - | |
| LCAB 3 | LCCA LCSA | 32 × 32 × 256 32 × 32 × 512 | - | |
| LCAB 4 | LCCA LCSA | 16 × 16 × 512 16 × 16 × 512 | - | |
| LCAB 5 | LCCA LCSA | 8 × 8 × 512 8 × 8 × 512 | - | |
| Decoder | LCAB 6 | LCCA Concatenation LCSA | 16 × 16 × 512 16 × 16 × 1024 16 × 16 × 512 | LCAB4 |
| LCAB 7 | LCCA Concatenation LCSA | 32 × 32 × 512 32 × 32 × 1024 32 × 32 × 512 | LCAB3 | |
| LCAB 8 | LCCA Concatenation LCSA | 64 × 64 × 512 64 × 64 × 768 64 × 64 × 256 | LCAB2 | |
| LCAB 9 | LCCA Concatenation LCSA | 128 × 128 × 256 128 × 128 × 384 128 × 128 × 128 | LCAB1 | |
| LCAB 10 | LCCA LCSA | 256 × 256 × 128 256 × 256 × 64 | - | |
| Convolution layer 2 Tanh activation layer | 256 × 256 × 3 | - | ||
| Generated image | 256 × 256 × 3 | |||
| Layer | Size of Feature | |
|---|---|---|
| Input image | 256 × 256 × 3 | |
| Target or de-occluded image | 256 × 256 × 3 | |
| Concatenate | 256 × 256 × 6 | |
| CL 1 | Convolution BN ReLU | 128 × 128 × 64 |
| CL 2 | Convolution BN ReLU | 64 × 64 × 128 |
| CL 3 | Convolution BN ReLU | 32 × 32 × 256 |
| CL 4 | Zero padding Convolution BN Leaky ReLU | 34 × 34 × 256 31 × 31 × 512 |
| CL 5 | Zero padding Convolution Sigmoid Average pooling | 33 × 33 × 512 30 × 30 × 1 1 × 1 × 1 |
| Output | Real or fake | |
| Gender | Age | White | Black | Hispanic | Asian | Other | Total | |
|---|---|---|---|---|---|---|---|---|
| Training | Male | 16~25 | 952 | 5834 | 401 | 44 | 4 | 7235 |
| 26~35 | 864 | 4184 | 231 | 13 | 5 | 5296 | ||
| 36~45 | 1090 | 4300 | 92 | 3 | 4 | 5490 | ||
| 46~55 | 579 | 1973 | 24 | 4 | 7 | 2588 | ||
| 56~65 | 90 | 268 | 2 | 0 | 0 | 360 | ||
| 66~77 | 7 | 16 | 0 | 0 | 0 | 23 | ||
| Total | 3582 | 16,574 | 750 | 63 | 20 | 20,990 | ||
| Female | 16~25 | 283 | 710 | 20 | 5 | 0 | 1017 | |
| 26~35 | 367 | 761 | 19 | 0 | 2 | 1149 | ||
| 36~45 | 395 | 818 | 6 | 0 | 5 | 1224 | ||
| 46~55 | 106 | 275 | 0 | 0 | 1 | 383 | ||
| 56~65 | 18 | 25 | 0 | 0 | 1 | 45 | ||
| 66~77 | 1 | 1 | 0 | 0 | 0 | 2 | ||
| Total | 1169 | 2591 | 46 | 6 | 9 | 3820 | ||
| Validation | Male | 16~25 | 212 | 1296 | 89 | 10 | 1 | 1608 |
| 26~35 | 192 | 930 | 51 | 3 | 1 | 1177 | ||
| 36~45 | 242 | 956 | 20 | 1 | 1 | 1220 | ||
| 46~55 | 129 | 439 | 5 | 1 | 2 | 575 | ||
| 56~65 | 20 | 60 | 0 | 0 | 0 | 80 | ||
| 66~77 | 2 | 4 | 0 | 0 | 0 | 5 | ||
| Total | 796 | 3683 | 167 | 14 | 4 | 4665 | ||
| Female | 16~25 | 63 | 158 | 4 | 1 | 0 | 226 | |
| 26~35 | 82 | 169 | 4 | 0 | 1 | 255 | ||
| 36~45 | 88 | 182 | 1 | 0 | 1 | 272 | ||
| 46~55 | 24 | 61 | 0 | 0 | 0 | 85 | ||
| 56~65 | 4 | 6 | 0 | 0 | 0 | 10 | ||
| 66~77 | 0 | 0 | 0 | 0 | 0 | 1 | ||
| Total | 260 | 576 | 10 | 1 | 2 | 849 | ||
| Total | Male | 7961 | 36,832 | 1667 | 141 | 44 | 46,645 | |
| Female | 2598 | 5757 | 102 | 13 | 19 | 8489 |
| LCA-GAN | AFD-StackGAN [54] | CFR-GAN [55] | MPRNet [83] | CycleGAN [84] | Pix2pix [57] | |
|---|---|---|---|---|---|---|
| SSIM | 0.6962 | 0.6769 | 0.7107 | 0.7031 | 0.5630 | 0.7225 |
| PSNR (unit: dB) | 19.0302 | 16.3121 | 18.3067 | 19.6427 | 19.3321 | 18.8731 |
| LCSA | LCCA | Edge Loss + Content Loss | MAE |
|---|---|---|---|
| × | × | × | 7.72 |
| ◯ | × | × | 7.11 |
| × | ◯ | × | 7.09 |
| × | × | ◯ | 7.83 |
| ◯ | ◯ | × | 6.82 |
| ◯ | ◯ | ◯ | 6.64 |
| Method | MAE |
|---|---|
| Baseline 1 | 5.80 |
| Baseline 2 | 10.45 |
| U-net | 7.70 |
| Pix2pix (LCA-GAN) | 6.64 |
| CycleGAN | 7.15 |
| Pix2pix* | 6.91 |
| LCA-GAN | AFD-StackGAN [54] | CFR-GAN [55] | MPRNet [83] | MPRNet* [83] | Pix2pix [57] | CycleGAN [84] | |
|---|---|---|---|---|---|---|---|
| MAE | 6.64 | 6.92 | 7.13 | 6.95 | 7.83 | 7.72 | 8.18 |
| LCA-GAN | AFD-StackGAN [54] | CFR-GAN [55] | MPRNet [83] | Pix2pix [57] | CycleGAN [84] | |
|---|---|---|---|---|---|---|
| SSIM | 0.7042 | 0.6983 | 0.7207 | 0.7002 | 0.7134 | 0.6892 |
| PSNR | 18.3302 | 19.4423 | 18.3043 | 18.9742 | 19.4211 | 17.9443 |
| LCA-GAN | AFD-StackGAN [54] | CFR-GAN [55] | MPRNet [83] | MPRNet* [83] | Pix2pix [57] | CycleGAN [84] | |
|---|---|---|---|---|---|---|---|
| MAE | 6.12 | 6.94 | 6.52 | 8.21 | 8.70 | 7.12 | 9.02 |
| VGG-16 [68] | ResNet-50 [87] | ResNet-152 [87] | DEX [8] | AgeNet [11,88] | Inception with Random Forest [20] | |
|---|---|---|---|---|---|---|
| MAE | 6.20 | 7.22 | 6.32 | 6.12 | 6.19 | 6.42 |
| Desktop Computer | Jetson TX2 Board | |
|---|---|---|
| LCA-GAN | 11.94 | 177.52 |
| AFD-Stack GAN [54] | 23.03 | 342.8 |
| CFR-GAN [55] | 35.6 | 541.5 |
| MPRNet [83] | 21.12 | 318.02 |
| MPRNet* [83] | 14.04 | 212.24 |
| Pix2pix [57] | 11.2 | 171.5 |
| Cycle GAN [84] | 23.2 | 353.1 |
| Number of Parameters | GFLOPs | Memory Usage (GB) | |
|---|---|---|---|
| LCA-GAN | 57,118,684 | 1.4668 | 0.5913 |
| AFD-Stack GAN [54] | 102,325,149 | 2.6764 | 0.5961 |
| CFR-GAN [55] | 171,588,876 | 2.8730 | 1.0925 |
| MPRNet [83] | 102,725,856 | 9.1092 | 4.5598 |
| MPRNet* [83] | 68,114,344 | 6.0728 | 3.0399 |
| Pix2pix [57] | 57,196,292 | 0.972 | 0.2062 |
| Cycle GAN [84] | 114,392,584 | 1.944 | 0.4124 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nam, S.H.; Kim, Y.H.; Choi, J.; Park, C.; Park, K.R. LCA-GAN: Low-Complexity Attention-Generative Adversarial Network for Age Estimation with Mask-Occluded Facial Images. Mathematics 2023, 11, 1926. https://doi.org/10.3390/math11081926
Nam SH, Kim YH, Choi J, Park C, Park KR. LCA-GAN: Low-Complexity Attention-Generative Adversarial Network for Age Estimation with Mask-Occluded Facial Images. Mathematics. 2023; 11(8):1926. https://doi.org/10.3390/math11081926
Chicago/Turabian StyleNam, Se Hyun, Yu Hwan Kim, Jiho Choi, Chanhum Park, and Kang Ryoung Park. 2023. "LCA-GAN: Low-Complexity Attention-Generative Adversarial Network for Age Estimation with Mask-Occluded Facial Images" Mathematics 11, no. 8: 1926. https://doi.org/10.3390/math11081926