The main innovations of our work are to introduce a new attention mechanism into the field of compressed sensing imaging and propose a new interpretable loss function. In this section, we will describe the proposed method in detail, including model formula and the proof of loss function principle.
3.1. Overall Network Framework
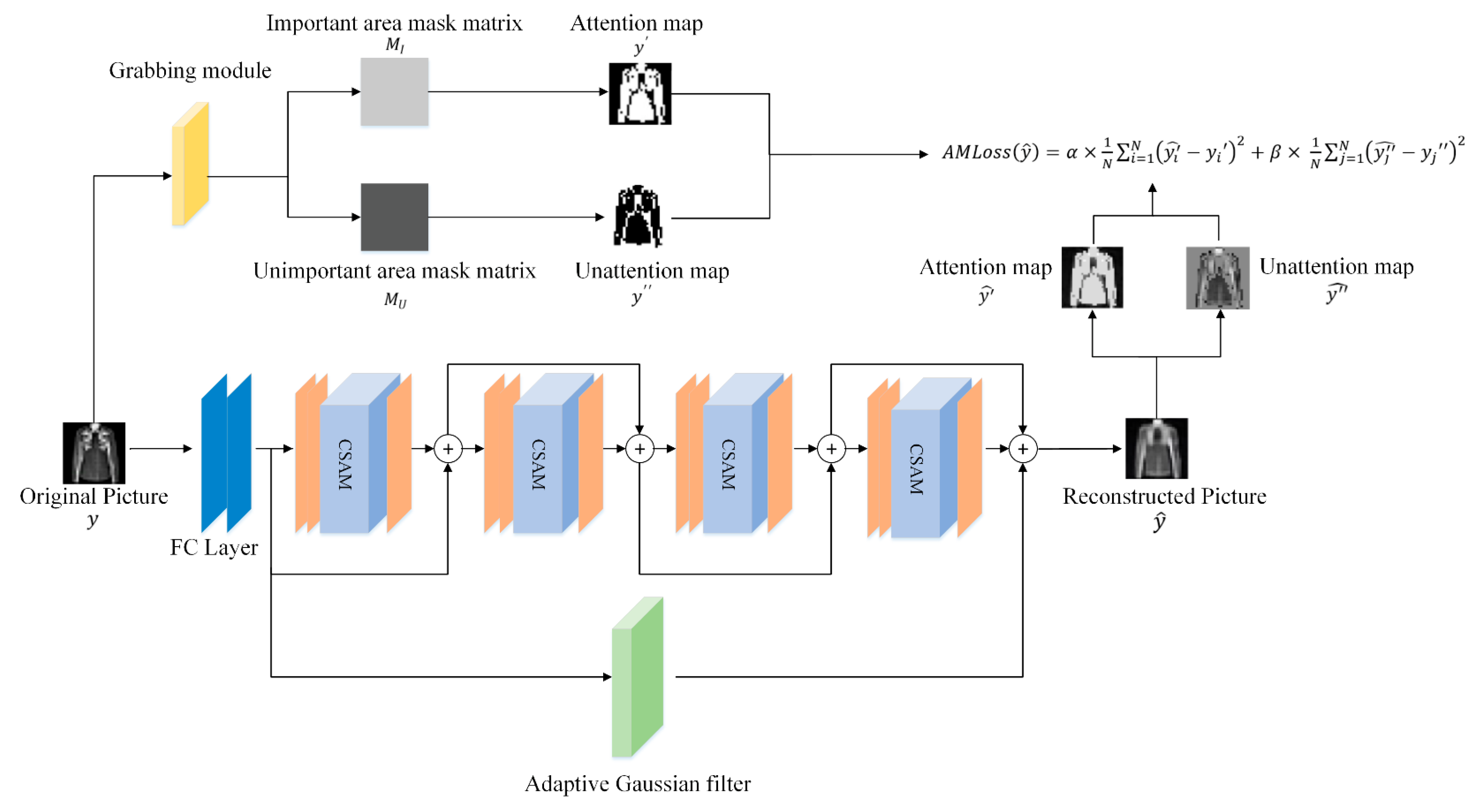
This part mainly introduces the structure of ACRM as shown in
Figure 1. The network consists of two fully connected layers, four ACR submodules, and an adaptive Gaussian filter. The first fully connected layer is a sampling network used to down sample the original image to generate CS measurements [
36]. The second fully connected layer is used for the preliminary reconstruction of the CS measurements [
36]. Related studies have shown that using fully connected layers as linear mapping networks can reconstruct high-quality primary images [
17] so that the subsequent deep convolution can proceed smoothly. The ACR submodule includes three convolutional layers and the CSAM. The convolution kernel sizes and channels of the three convolutional layers from left to right are 11 × 11 × 64, 7 × 7 × 32, and 3 × 3 × 1, respectively. After each convolutional layer, the
function is used to improve the ability of convolutional nonlinear feature extraction. Each ACR submodule uses a residual structure to cope with vanishing and exploding gradients. Next, we focus on the CSAM, the adaptive Gaussian filtering sub-network and the loss function used for network training.
3.2. Coordinated Self-Attention Module
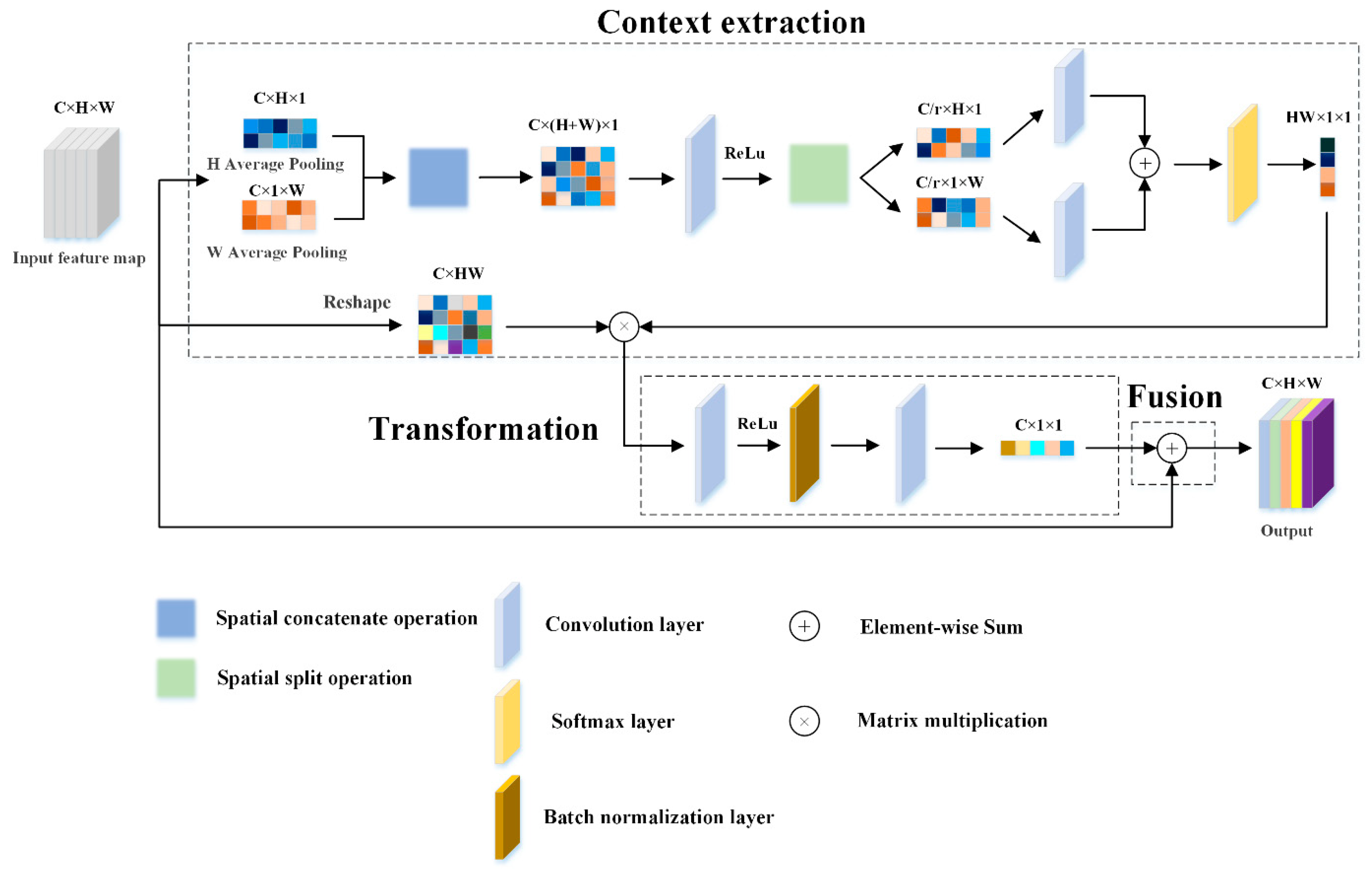
Ma et al. studied the classical attention module and established the framework of the attention module in a broad sense, thinking that the attention block is composed of three parts: context extraction, transformation, and fusion [
37]. The structure of our designed attention block also conforms to this framework, as shown in
Figure 2.
Context extraction is used to collect relevant feature information from the feature map of the internal relationship of the image. We assume that the feature map obtained by the previous convolution block is
. We perform one-dimensional average pooling in two directions, so the outputs of the
-th channel at height
and width
are expressed as [
34]
where
C is the number of channels of the feature map, and
H and
W are the height and width of the feature map, respectively.
The above results in two independent orientation-aware feature maps, which not only capture the long-distance dependencies in their respective orientations well but also preserve spatial location information from each other.
Then
and
are used with convolution
to generate the aggregated feature map [
34]:
where
is a convolutional layer with a convolution kernel size of ,
represents the connection operation along one dimension,
and are the input feature maps,
is the nonlinear activation function ,
is the output feature map,
is a reduction ratio to reduce the amount of computation.
Then we cut it into separate tensors along the two spatial dimensions
and
. Then we use two convolutions
and
to restore the tensors as dimension
consistent with the input dimension. Finally, the two tensors are connected along the two spatial dimensions to form an attention map with long-distance dependencies initially:
where
and
are convolutional layers with a convolution kernel size of
, respectively,
indicates that the two matrices are added along different dimensions,
and
are the cut feature vectors, and
is the generated attention map.
Unlike the coordinated attention module, the interaction between the attention map and the original image are used to calculate the position in the graph to capture long-range correlations after initially generating an attention map. Therefore, based on having a certain amount of attention, we further improve the context modeling ability, and aggregate the features of all positions to obtain global context features.
Inspired by [
31], all pixels in the image share an attention map. The relationship between positions
and
can be expressed as
where
(
equals
times
) represents the total number of pixels in the image.
Transformation aims to capture the channel and space dependencies and transform the extracted features on the nonlinear attention space to obtain the attention map
. The output
can be expressed as [
31]
where
and
are convolutional layers with a convolution kernel size of
, respectively, and
represents the nonlinear activation function
.
represents batch normalization processing.
Fusion aims to combine the obtained attention map with the feature map of the original convolutional block. According to (2) to (7), the process of aggregating global context features into features of each location can be expressed as
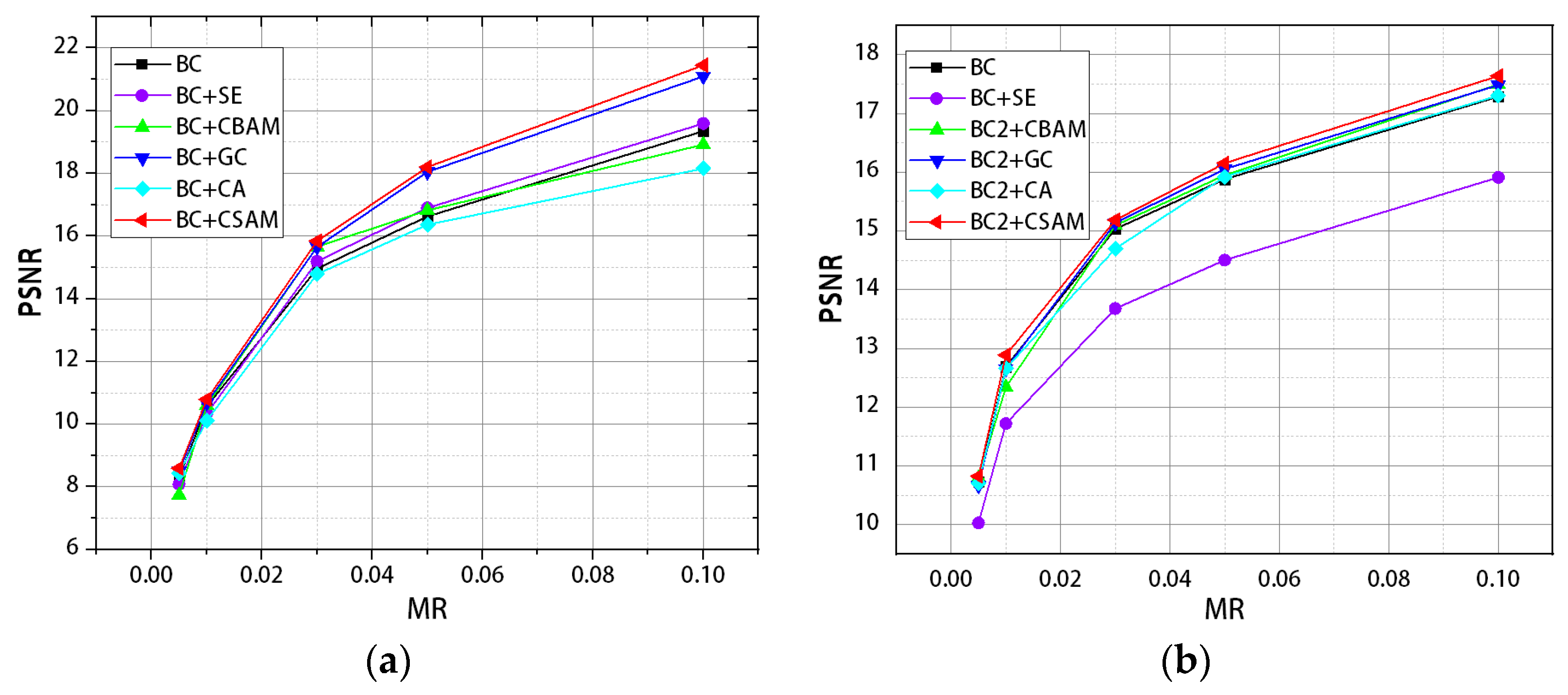
The attention module we designed not only acquires channel-level global features in the channel domain, but it also has a stronger ability to capture global information in the spatial domain. As mentioned above, we use the attention map in two directions to reflect whether there is a place to pay attention between the corresponding rows and columns, and then we encode the established attention map with itself. Then the global information is exploited to locate the areas that need attention accurately in the image. This enhances the power of context extraction and transformation nicely compared to general self-attention networks. Moreover, we also analyze the insufficiency of the global average pooling method in CSAM and propose an adaptive Gaussian filter to optimize this attention module (this is described in detail in the next section). Finally, the overall reconstruction ability of the network is improved. We showed this in experiments.
3.3. Adaptive Gaussian Filter Sub-Networks
Although the method of decomposing the 2D global average pooling into two parallel 1D feature encodings improves the ability of the network to utilize spatial information effectively in CSAM, Qin et al. pointed out that this method cannot capture rich input representation [
38]. It was demonstrated that the global average pooling method is the lowest frequency component of the discrete cosine transform. In other words, in the frequency domain, only a single component is used, and other useful components are ignored. Usually, the low-frequency part of the image mainly contains general image information, while the high-frequency part mainly contains the detailed information of the image. These details are very important for the reconstruction of the image. So, an adaptive Gaussian filtering sub-network is proposed to solve this problem.
The specific implementation of two-dimensional Gaussian filtering assigns different Gaussian weight values to the surrounding pixel values within a certain range. It obtains the result of the current point after the weighted average. The two-dimensional Gaussian function is
where
is the amplitude,
and
are the center point coordinates, and
and
are the standard variances.
The amplitude of the two-dimensional Gaussian function is inversely proportional to the standard variances . The larger the , the wider the frequency band of the Gaussian filter and the better the smoothness. However, the two-dimensional Gaussian filter is mainly used as a controllable filter, so the amplitude is fixed to one.
Usually, the low-frequency part of the image mainly contains general image information, while the high-frequency part mainly contains detailed information of the image. When the measurement rate is lower, the compressed sampled image contains more low-frequency information, so the bandwidth of the filter can be set smaller when the measurement rate is higher. Therefore, the standard variances
of the Gaussian filter sub-network we designed can vary with the measurement rate of the sampling network. In this way, the Gaussian filtering sub-network can supplement more frequency domain component information to the main network under different measurement rate conditions, which increases the expressive ability in the frequency domain. This method makes up for the deficiency of the global average pooling method and adopts the skip connection method as shown in
Figure 1 to reduce the computational complexity.
3.4. AMLoss (Attention MSE Loss)
The MSE (mean square error) loss function has the advantages easily using the gradient descent algorithm and is conducive to the convergence of the function. However, the MSE loss function has the characteristics of giving a larger penalty to the larger error and a smaller penalty to the smaller error. If there are outliers in the sample, the MSE loss function will give higher weights to the outliers, thereby ignoring the influence of the image content itself, which will reduce the overall performance of the model ultimately. Although there are some works on the combination of attention and loss function [
39,
40,
41], unfortunately, the combination of attention and MSE loss function is still very rare. Therefore, we propose an improved loss function based on the traditional MSE loss, which is called AMLoss (attention MSE loss). Its expression is
where
is the number of pixels in the image,
and
are the set hyperparameters, respectively, and
and
are the pixel values of the important area and the non-important area of the predicted value output
by the network, respectively,
and
are the pixel values of the important area and the non-important area of the real value input
by the network, respectively.
In the training process, as shown in
Figure 1, the designed adaptive grabbing module is used to extract its important area part before the input image enters the network. After that, it generates the corresponding important area mask matrix
and unimportant area mask matrix
. Finally, we multiply the predicted value
and the real value
with the masks
and
to obtain the respective important and non-important regions. Take MNIST dataset as an example. The characteristic of this dataset is that the main part of the image is in the center of the image, and the value of pixels is very large. According to this feature, we design the capture module as follows: First, we normalize the image. Then we calculate the average pixel value of all pixels in the picture and compare the value of all pixels in the picture with the average pixel value. If the value of the pixel point is greater than the average pixel value, the position of the matrix corresponding to the point is assigned as 1. On the contrary, the position of the matrix corresponding to the point is assigned as 0. Finally, the important area matrix is generated. We believe that the important part of the image is determined according to the work task. If the important part of the picture is artificially defined, the method of extraction is not unitary. Different datasets also have different methods.
In this way, the MSE-loss function will increase the penalty for important areas of the image and reduce the penalty for non-important areas of the image. This will not only alleviate the defects of the above MSE-loss function but also make the loss function have “attention”, paying more attention to the important parts of the image. The error of the important part has a greater impact on the update of parameters such as weights and biases of the network after the back-propagation algorithm. The proof process is as follows:
The last activation function used by the last convolution of this network is
:
This function solves ’s neuron death problem with a small positive slope in negative regions, so it can backpropagate even for negative input values. We assume an input vector , which is transformed by the function to obtain a vector , and propagates forward to obtain an error value . We only solve the gradient of to and do not solve the update of specific parameters in the network after backpropagation.
According to (11) and (13), we obtain:
According to (13), the gradient of
to
is:
According to (10) and (14), the gradient of
to
is:
According to the chain rule, we obtain:
According to (16) and (18), the gradient of
to
is:
where
represents the multiplication of parity elements.
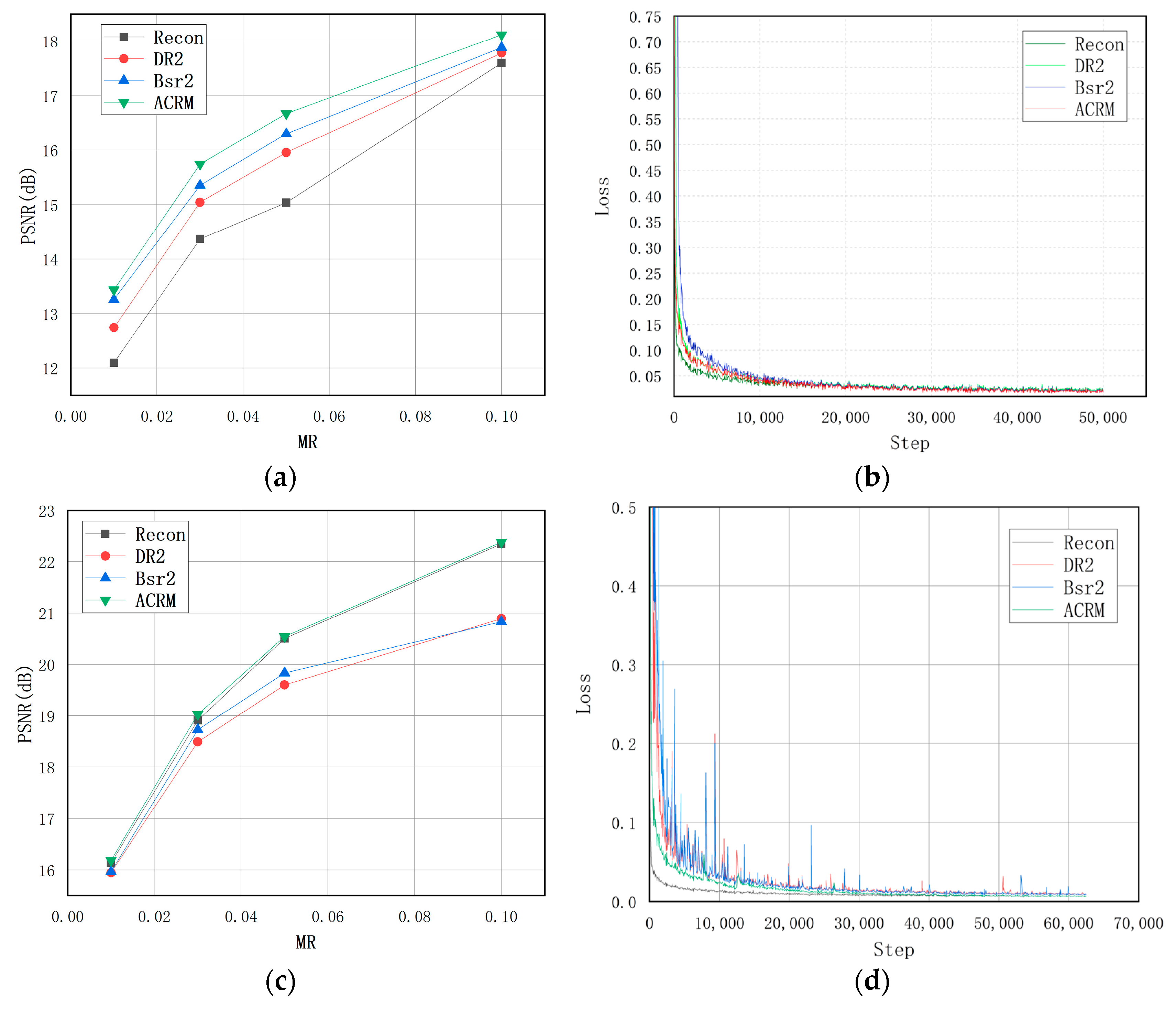
It can be seen from (19) that when , the weight of errors in important areas will be increased, and the weight of errors in non-important areas will remain the same or decrease. It is worth mentioning that the AMLoss is suitable for networks with an attention mechanism, because networks with an attention mechanism filter out important parts of the image. The AMLoss is more inclined to reduce the loss value for important parts of the image when it is minimized by backpropagation.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}