1. Introduction
With the advent of the fifth generation mobile network (5G) era, the high bandwidth of 5G provides the basis for serving massive users, thus opening a new era of multi-scenario the Internet of Everything in the orthogonal frequency division multiple access (OFDMA) system. There are three major application scenarios of the 5G: (1) massive machine type communications (mMTC) [
1]; (2) enhanced mobile broadband (eMBB) [
2]; (3) ultra-reliable and low-latency communication (URLLC) [
3]. The overall architecture of the 5G has undergone big and small changes. For example, the 5G base station integrates the original remote radio unit (RRU) and antenna into the active antenna unit (AAU) to replace the RRU of the 4G base station in the wireless access network, which reduces the loss of the feed line from antennas to the RRU in the previous architecture. In the 5G bearer network, the building baseband unit (BBU) can separate optionally into a centralized unit (CU) and a distributed unit (DU), and some non-real-time functions of the BBU are integrated into DU and then sink to the AAU. The remaining real-time functions are integrated into CU. Therefore, they can be selectively separated into different application scenarios [
4]. This structure application with the following network function virtualization (NFV) application will be more extensive. In the core network, different from the serving gateway and the packet data network gateway [
5] of the 4G network, the 5G completely separates the control plane (CP) from the user plane (UP). Its advantages are flexible service changes, convenient network expansion and upgrades, and the user plane can be removed from the “centralized” position. It can be deployed in the core network or sunk into the access network, meeting the requirements of low latency 5G networks and providing great convenience for the maintenance and expansion of the 5G core network. This flexible networking mode brings great new challenges to the resource allocation of wireless networks and makes it possible to further improve resource utilization.
From the perspective of users, 5G users are more diverse than 4G users. The 5G users have stronger diversity, with different scenarios, different fields, diverse forms, and different problem-solving, so they have different demands for networks and other resources. Thus, the resource allocation models and algorithms of 4G are no longer enough to meet the requirements of 5G network resource allocation. Network slicing is an effective means to deal with the requirements of multiple scenarios. The 5G network slicing technology has been extensively studied. Network slicing is a logical concept that reorganizes resources [
6]. Reorganizations select virtual machines [
7] and physical resources for specific communication service types, based on service level agreements [
8]. It is defined as a form of the on-demand network. It can make operators in unity on the infrastructure of isolated multiple virtual end-to-end networks. Each network slice from the wireless access network to the bearing network to core online logical isolation to fit a variety of types of applications. NFV is the core of network-slicing technology [
9]. NFV separates the hardware and software parts from the traditional network. The hardware is deployed by a unified server, and the software is undertaken by different network functions, in order to meet the requirements of flexible service assembly. So, it can remodel the network structure to virtualize the functionality in CU and DU.
These architectural changes are also more applicable to the multi-slice and multi-scenario. These changes make the 5G operators’ charge mode of innovation [
10,
11]. The application of the network section has brought a new operation model, a new business model, and a new service model. It allows 5G operators to charge for slices. In this new business model, the base station allocates resources to the slices and charges the slices, which then allocates the resources to the users. These changes bring about changes in the issue of sub-channel and power resources allocation. The resource allocation process has a clear hierarchical structure. The 5G operators may pay more attention to profit, and the slices may pay more attention to serving their users. The existing resource allocation models and algorithms rarely consider this hierarchical coupling relationship. It generally formulates the resource allocation problem as a single-objective optimization problem or multi-objective optimization problem [
12]. The single-objective optimization model generally aggregates the factors influencing the allocation of resources through weighted methods [
13], but it does not work well for the hierarchical resource allocation problem. The multi-objective optimization simultaneously optimizes several conflicting objectives, but it still does not well-address the hierarchical resource allocation problem. Therefore, a bi-level model is considered in this paper, which can place the base station’s resource allocation to the slice by the upper-level optimization task, and the slices allocate the resource to their users by the lower-level optimization task.
The above-mentioned bi-level resource allocation model is a complex bi-level optimization problem. In recent years, bi-level optimization has been widely concerned by scholars [
14]. In the past few years, some scholars used the knowledge of Lagrange duality theory, based on convex optimization, to transform a bi-level optimization problem into a single-level optimization problem and solve it. This method assumes that the objectives and constraints are differentiable and the objectives are convex [
15]. However, this method based on convex optimization is not suitable for the bi-level model with mixed variables. In addition, some researchers use an evolutionary algorithm to search for a feasible solution [
16]. Generally speaking, evolutionary algorithms can provide an acceptable solution. However, evolutionary algorithms require the consumption of a large number of real-time computing resources and take a long time to provide a solution. It requires the optimization algorithm to quickly give a good allocation scheme in the case of massive 5G connections. This leads to these methods encountering great challenges in solving the complex and changeable resource allocation model of the 5G communication system. Recently, with the rise of deep learning, reinforcement learning has also been greatly developed [
17]. Reinforcement learning has the characteristic of reusability, so it has a good application prospect in resource allocation. At the expense of certain accuracy, the trained neural network can quickly and stably give a better feasible solution.
Consequently, we propose a bi-level resource allocation model in the 5G OFDMA system. It fully considers the profit of the 5G operator and the fairness of slice in allocating resources to its users. The resource contains sub-channels and power resources in the OFDMA system. The upper-level objective is about the 5G operator taking different prices for different slices because the slices are serving different scenarios. The base station allocates sub-channels and power resources to slices based on the upper-level objectives. After the base station allocates resources to the slices, the slices allocate sub-channel and power resources to their users according to the lower-level objective. The lower-level objective is that the slices fairly allocate the resource to their users. The lower-level objective is dominated by the upper-level objective, that is, the upper-level optimization task gives the resource scheme for slices, and the lower-level optimization gives the lower-level optimal solution based on the allocation scheme given by the upper level and then returns the optimal solution of the lower-level optimization problem to the upper-level optimization problem. The proposed bi-level model fully considers the situation where the upper and lower objectives are different. The bi-level resource allocation model is a complex constrained mixed-variable optimization problem, in which the sub-channel resource allocation is a discrete variable and the power allocation is a continuous variable.
Reinforcement learning is used to solve the bi-level resource allocation model. Reinforcement learning can give a better solution while saving certain real-time computing resources. The architecture and the components of reinforcement learning play an important role in solving practical problems. Consequently, this paper employs the multi-agent twin delayed deep deterministic policy gradient (MATD3) for the upper-level resources allocation and the discrete and continuous twin delayed deep deterministic policy gradient (DCTD3) for the lower-level resources allocation, according to the characteristics of the bi-level resource optimization problem. Simulation experiments fully verify the effectiveness of the proposed resource allocation model and its corresponding solving algorithm. The major contributions in this paper are concluded as follows:
We propose a bi-level resource allocation model. The base stations allocate the resources to the slices to optimize the operator’s benefits. Additionally, these slices allocate the resource to their users to improve the service equity of all users.
We select an effective reinforcement learning network architecture according to the characteristics of the resource allocation optimization problem. MATD3 is employed for the upper-level resources allocation and DCTD3 for the lower-level resources allocation.
We provide an effective definition of the environment, state, action, and reward of MATD3 and DCTD3 for solving the bi-level resource allocation problem.
We conduct some simulation experiments to investigate the effectiveness of the proposed model and algorithm. The simulation results show that the proposed algorithm can quickly provide a better resource allocation scheme.
The rest of this paper is organized as follows.
Section 2 makes a review of the related works.
Section 3 describes the proposed bi-level resource allocation model in detail.
Section 4 presents the bi-level resource allocation strategy based on reinforcement learning.
Section 5 provides the simulation results and gives a discussion of the results. Finally,
Section 6 draws a conclusion.
3. The Proposed Bi-Level Resource Allocation Model
3.1. Hierarchical Architecture of Resource Allocation in 5G Communication System
Network function virtualization and slice technique are the core technologies for the 5G communication system. The CU-DU separation architecture based on these technologies makes it possible to flexibly network for different scenarios.
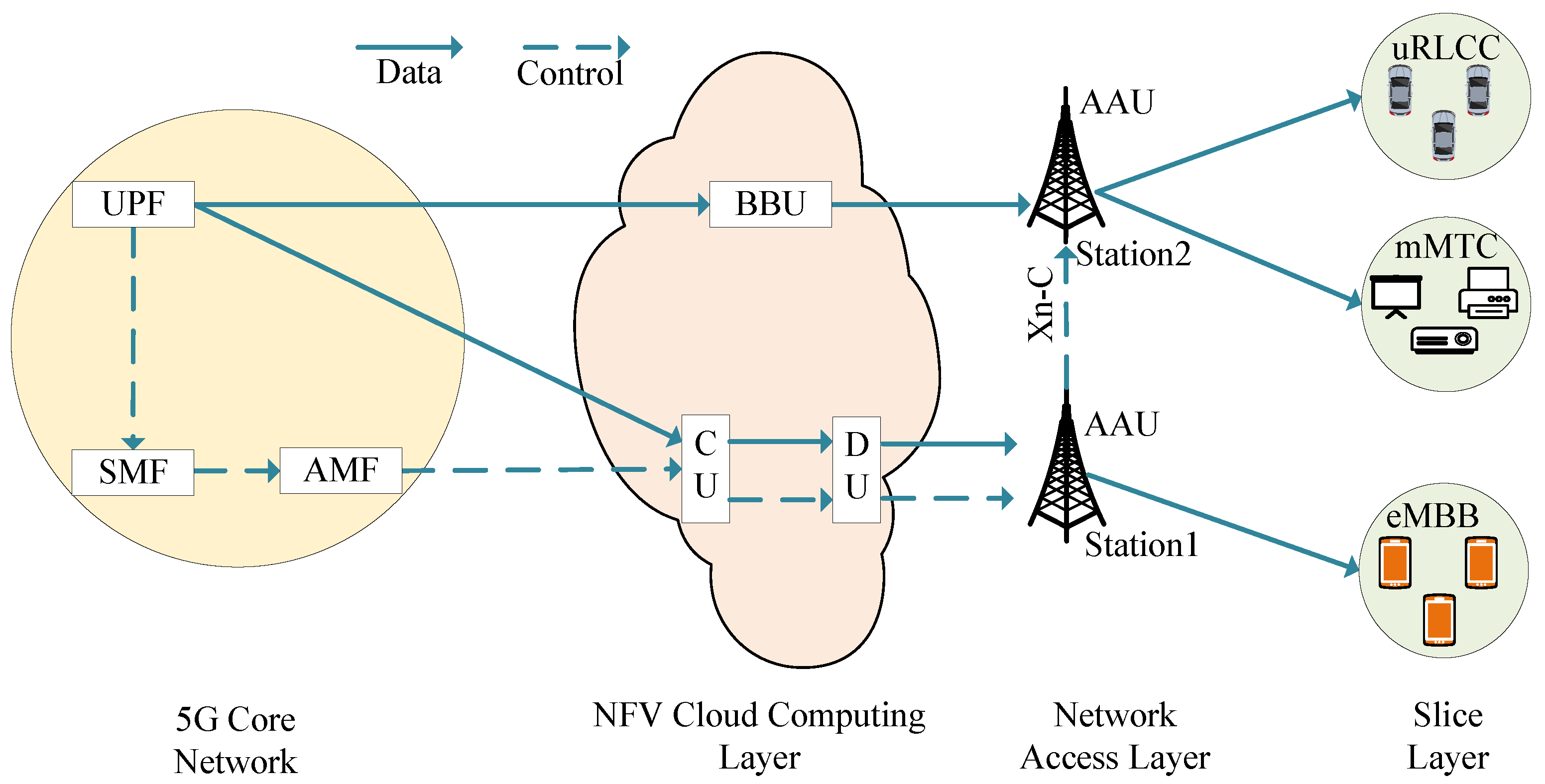
Figure 1 plots a 5G network architecture. Station 1 connects to the DU, DU then connects to CU, and CU connects to the 5G core network. Station 2 connects to the BBU indirectly, and the BBU connects to the 5G core network. Because of the dividing of the user plane and the control plane in 5G, the data stream is divided into the actual data stream and the control signaling stream. The solid line refers to the actual stream from the user plane function (UPF) to the CU of station 1 and the BBU of station 2. Then, the dotted line refers to the control signaling from the UPF to the session management function (SMF), then from the SMF to the access and mobility management function (AMF), and then from the AMF to the CU of station 1.
Three scenarios, i.e., eMBB, mMTC, and uRLLC, are considered in this paper, and one slice serves one application scenario. Thus, three slices corresponding to these three 5G scenarios are considered in this paper. The mMTC scenario focuses on the number of connections, and it does not require low latency strictly, such as the Internet of Things users. It can apply the CU and DU separation scheme, so the user in this slice is appropriately connected to the base station 1, as shown in
Figure 1. The eMBB scenario focuses on the peaking rate, capacity, and spectrum efficiency and requires low latency, such as for mobile users. It is more appropriate for taking the CU and DU setting together scheme, so the user in this slice is connected to base station 2. The uRLLC focuses on ultra-reliability and low-latency communication, such as the vehicle network. It is most suitable for adopting the CU and DU setting together, so the user in this slice is connected to base station 2.
This means that different slices and different users have different demands for communication resources. Moreover, resource allocation has a clear hierarchical relationship. The base stations allocate resources to the slices, and then the slices allocate resources to the users contained in this slice. This hierarchy brings great challenges to resource allocation. An efficient resource allocation strategy is crucial for improving resource utilization and, thus, improving the economic benefits of operators. Therefore, we proposed a bi-level resource allocation model in which the NFV clouding computing makes the 5G base station allocate the sub-channels and power sources to the three slices, and the slices allocate the sub-channels and power resources obtained from the base station to their users.
Specifically, let denote the users in the nth slice, where and are the number of users. We assume that there are K sub-channels and denote the set of sub-channels as . In the upper-level resources allocation of the base station to the slices, the upper-level optimization variables include power allocation and sub-channel allocation . is the power allocated to the nth slice, and denotes that the kth sub-channel is allocated to the nth slice, otherwise . When the base station’s allocation of resources () to the slices has been given, we can obtain the number of sub-channel resource allocated by the base station to the nth slice. In the lower-level resource allocation of the slices to their users, the lower-level optimization variables contain the power allocation , with , sub-channel allocation for users , with , . refers to the power allocated to the kth sub-channel, and refers to the sub-channel allocation. denotes that the kth sub-channel is allocated to the uth user in the nth slice, otherwise, .
3.2. Upper-Level Optimization: 5G Base Stations Allocate Resources to the Slices
The upper-level optimization problem of the bi-level model refers to the base stations allocating the sub-channels and power resources to the slices. The slices apply these resources to customize the service. The 5G operator benefits from the tenants which maintain the slice. The upper-level optimization aims to optimize the benefit of the operator and improve resource utilization and cover more users. Thus, it can be given as:
where
(
) is the unit prices of the
nth slice, and
is the total power resource that the NFV cloud computing layer can be allocated.
is the rate in the
nth slices on the
kth sub-channel.
is the rate of user
u in the
nth slices obtained on the
kth sub-channel, which is given by the resource allocation scheme in the lower-level optimization task. The first term of the objective is the total revenue, and the second term is the total number of covered users.
is a parameter that is used to balance the revenue and the number of covered users.
The first constraint means that the allocating power cannot exceed the total power, and the second constraint means that each sub-channel only can be allocated to one slice at most. Additionally,
denotes the connection identifier that is given by the lower-level optimization task. It is given a detailed description in
Section 3.3. The sub-channel allocation
is discrete, but the power allocation
is continuous. Therefore, the upper-level optimization problem is a complex constrained mixed variable optimization problem.
3.3. Lower-Level Optimization: Slices Allocate Resources to Their Users
The lower-level optimization of the proposed bi-level resource allocation model is that the slices further allocate the sub-channel and power resources obtained from the based stations to their users. Since different slices correspond to different scenarios, the resource allocation of each slice is relatively independent, we allocate the resources of each slice, respectively. The sub-channel and power resources are allocated according to the channel gain and desired rate of the users. The lower-level optimization task aims to optimize the service equity of all users in each slice. Thus, the lower-level optimization problem can be given as:
where
is the rate of user
u in the
nth slice obtained on the
kth sub-channel. It is calculated by
where
w is the bandwidth of the sub-channel and
is the noise power,
is the channel gain matrix, and
is the channel gain on the sub-channel
k between the user
u in the
nth slice and the 5G base station, which is calculated as
, where
is the path loss function with a shadow fading that follows a normal distribution, according to the actual scene, and
is the distance between the user and the base station.
is the desired rate of the users in the
nth slice.
The first constraint of problem (
2) makes that the power allocated to each sub-channel must be in the range
and
. The second constraint of problem (
2) states that the power allocated to the users in the
nth slice cannot exceed the power allocated to the
nth slice. The third constraint means that each sub-channel only can be allocated to one user at most. The connection identifier
is calculated as follows.
represents that the
uth user is connecting and its communication rate meets the minimum communication requirement of the
nth slice, otherwise,
. That is
where
is the minimum rate promised by joining the
nth slice.
The lower-level optimization variable is continuous, and is 0–1 discrete optimization variables. The lower-level optimization problem is also a constrained mixed variable optimization problem. Therefore, the proposed bi-level resource allocation model is a nonlinear constraint mixed-discrete variable optimization problem. Additionally, in the actual 5G application scenarios, the services that the slices request change rapidly, which puts forward higher requirements and challenges for the speed of the algorithm. Thus, we need to present a fast resource allocation algorithm. We use a reinforcement learning method to solve the proposed bi-level resource allocation model in this paper.
In summary, the bi-level resource allocation model can be formulated as the following mathematical model.
4. Resource Allocating Based on Reinforcement Learning
4.1. The Flow of the Proposed Resource Allocation Algorithm
Reinforcement learning can give a better resource allocation scheme with a certain real-time computing resource, which has been widely used in practice. However, the selection of the architecture and the components of reinforcement learning has a great impact on the performance of the algorithm. It is necessary to choose the appropriate reinforcement learning architecture for different problems. We employ MATD3 for the upper-level resources allocation and DCTD3 for the lower-level resources allocation, according to the challenges of the proposed resource allocation model. In the actual scenario, we must ensure mutual isolation and security between slices, so we do not use multiple agents in the process of slice resource allocation to users, but train one agent for each slice for resource allocation.
Figure 2 plots the flow of the proposed resource allocation process. The MATD3 reinforcement learning algorithm contains two agents. One agent is for the base station allocating the discrete sub-channel resources (
) to the slice, and the other agent is for the base station allocating continuous power resources (
) to the slice. DCTD3 is employed for the lower-level optimization task, which enables each slice to simultaneously allocate the discrete sub-channel resources (
) and continuous power resources (
) obtained from the base station to its users. The agent in the lower level is trained according to the reward of the lower-level objective. After the resources are allocated to users by the lower-level slices, the agents in the upper level will get a reward by calculating the upper-level objective according to the results of the lower-level resource allocation.
4.2. The Upper-Level Resource Allocation by Using MATD3
How to effectively and accurately define the components, i.e., state, environment, action, and reward, of reinforcement learning is the key to applying reinforcement learning to solve practical problems. We will give a detailed description of the components of reinforcement learning. In the upper-level optimization, the power allocation is a continuous variable and the sub-channel allocation is a 0-1 discrete variable. In addition, there are more and more slices in the actual scenario under CD-DU separation. The increase in dimension brings challenges to the convergence of reinforcement learning. Therefore, MATD3 with two agents is employed for the upper-level resource allocation. Algorithm 1 provides the pseudo-code flow of the algorithm. The first agent is used to allocate sub-channels resources, and the second agent is to allocate power resources. Additionally, the two agents cooperate for the same upper-level objective.
| Algorithm 1 MATD3 for the upper-level optimization. |
- 1:
for agent m = 1 to 2 do - 2:
Randomly initialize two current critic networks , and one current actor network with weights , and . - 3:
Initialize target critic networks , and target actor with weights , , . - 4:
end for - 5:
for episode = 1 to do - 6:
Initialize the state of the agents . - 7:
for t = 1 to do - 8:
Select the action by the current actor network, . - 9:
The first agent executes action to allocate sub-channels to slices. - 10:
The second agent executes action to allocate power resource to slices. - 11:
Observe reward and observe new state . - 12:
Store transition in D. - 13:
Sample a random minibatch of S transition from D. - 14:
Set . - 15:
for agent m = 1 to 2 do - 16:
Calculate the value of of mth agent according to Equation ( 13). - 17:
Update the current critic networks by minimizing the loss according to Equation ( 14). - 18:
Update the current actor network according to Equation ( 15) or Equation ( 16). - 19:
Update the target critic networks according to Equation ( 17). - 20:
Update the target actor network according to Equation ( 18). - 21:
end for - 22:
end for - 23:
end for
|
4.2.1. State
At each time-step, the state of the mth agent of MATD3 consists of the following four aspects in this paper.
The average channel gain : with is the average channel gain of users is the nth slice on the kth sub-channel, .
The percentage of the request rate : , with being the percentage of the request rate of the nth slice. .
The sub-channels assignment at time t.
The power resource allocation at time t.
We denote as the state of the mth agent and as the state of the two agents at time t.
4.2.2. Multi-Agent Actor and Critic Networks
The action of the first agent is the action regarding the sub-channels allocation for three slices at time t. For each k sub-channel, we assign it to the slice with the maximum value, that is, —the value of is set to 1, and the value of for the other slice is set to 0 at time . Therefore, the action impacts the sub-channel allocation of the state of the two agents.
The action
of the second agent regards the power allocation for the three slices at time
t. At each time-step, the action of power increases or decreases
at time
t, where
is the power action bound at time
t in the upper-level optimization. The power allocation
is computed with the action of the second agent by Equation (
6):
Therefore, the actions will impact the state of the agents and the entire environment.
Two current critic networks
and
with weights
,
are randomly initialized, which are used to approximate the Q-function for the
mth agent in MATD3. Moreover, we initialize one current actor network
with weights
for each
mth agent as shown in line 2 of Algorithm 1, where
. The current actor network chooses a deterministic action based on the state
at time
t by using the deterministic policy gradient. Then, the action
of the
mth agent at time
t can be given as:
where
is a normal random noise. It is used to explore more movements. The variance of this noise decreases with the number of training epochs, that is,
, where
is a constant less than one. The action is compressed to
by the Tanh activation function in the actor network.
Moreover, we initialize two critic target networks,
and
, and one target actor network,
, where
. The parameters
,
and
are initialized with that of the corresponding current actor networks. The action
is given as:
4.2.3. Reward
After the two agents execute theirs action
, the environment state is changed from
to
. The
mth agent gets a reward
from the environment,
. In upper-level optimization, two agents are assigned to allocate sub-channels and power resources for the same upper-level optimization objective. Therefore, we set the same reward function for these two agents at time
t, that is,
, according to the objective function and the constraint violation of the upper-level optimization (
1).
where the
is the degree of constraint violation and
is the penalty coefficient. Therefore, the total reward
of the
mth agent can be given as
where
is a discount factor. The Q-value function based on the Belman function can evaluate the expected total return per action. It can be denoted as follows
We select actions
of agents according to Equation (
7) for a given state
. Then, we execute action
to get the rewards of agents
and the new states of the two agents
. Transition
is stored in the memory replay
D, as shown in line 13 of Algorithm 1.
4.2.4. Training Process of MATD3
We extract samples
from
D, with a batch size
N for training the networks at each time-step.
Figure 3 plots the training process of agent 1 of MATD3. Global information is required to be adopted for training the networks in multiple agents-based reinforcement learning. Therefore, we need to input the actions of all agents into the current critic networks. The parameters of the current critic networks are updated to minimize the loss. The loss function of the
jth current critic network of the
mth agent is given as
where
is an approximation of policy. The values of
are the minimum Q-values of the target critic networks
and
. That is,
where
contains actions of the target actor network of the two agents. Then, the parameters
of the
jth current critic network of the
mth agent is updated to minimize the loss function. That is,
The parameters of the current actor network of the agents are updated by using a deterministic policy gradient strategy. We can get to the Q-value through any one of the current critic networks, We choose the Q-value from the first current critic network in this paper. Accordingly, we can derive the gradient of the ensemble objective concerning the first agent, i.e.,
as follows:
In this paper, we use the Adam optimizer [
49] with a learning rate of
and
,
to update the parameters of the current actor networks. The learning rate
is allowed to adjust during the training phase.
After an epoch of training, we update the parameters of the target critic networks of the
mth agent as follows:
The parameters of the target actor network of the
mth agent are updated as:
where
is a smaller constant to update target networks. The calculation of reward in upper-level optimization depends on the lower-level optimization scheme given by the actor network of the lower-level optimization.
4.3. The Lower-Level Resource Allocation by Using DCTD3
Because slices are securely isolated from each other and there is an interaction between agents in multi-agent reinforcement learning, we use only one agent to complete discrete sub-channel resource allocation and continuous power resource allocation from slices to users. Therefore, we employ DCTD3 for this resource allocation model to solve the problem of simultaneously allocating discrete resources and continuous resources. Each slice corresponds to an agent.
To deal with the resource allocation of the nth slice, we denote the state of the agent in the nth slice as , where is the channel gain vector about the users on these sub-channels, is the channel gain on the sub-channel k between the user u in the nth slice and the 5G base station, and is the desired rate of the users in the nth slice. and are the sub-channel allocation and power allocation in the nth slice at time t, respectively.
The action of the
nth agent consists of two parts:
. It is compressed to
by using the Tanh function. It also adds a noise, as used in MATD3 for exploration. The action
is about sub-channels allocation for users in the
n slice. For each sub-channel
k, we assign it to the
user with the maximal value, that is,
, and the
is set to 1 at time
. The action
is about power allocation for
sub-channels. At each time-step, the action of power increases or decreases
at time
t, where
is the power action bound at time
t in the lower-level optimization.
Therefore, the discrete subchannels resource and continuous power resources can be allocated together by using only one agent.
The state of the environment changes according to these processed actions, that is,
becomes
. First of all, we need to generate training samples, that is, to extract a certain batch of training samples of reinforcement learning and store it in experience replay. The states of the input neural network are composed of the channel gain, desired rate, and allocated power. After taking enough samples, we start to train the critic and actor networks. The reward is defined according to the objective and constraint violation of the lower-level optimization (
2) at time
t:
where the
is the degree of constraint violation and
is the penalty coefficient.
The training process is similar to MATD3 in the upper-level optimization on the whole, except that, in the critic network, we only need the actions of the current agent, but not the actions of other agents. Therefore, we extract samples with a batch size
N, and the update formula through gradient ascent of the actor network of each agent with parameter
in the
nth slice is as follows
Then, the loss that we want to reduce of the agent’s current critic networks with parameter
in the
nth slice can be calculated as
Additionally, the target networks are updated by Equations (
17) and (
18), the same as MATD3 for the upper-level optimization. In case of similar problems, we can input its state into the actor network to a good solution for lower optimization by iterating a certain time. We then give the lower allocation scheme to the upper optimization.
6. Conclusions
In this paper, we established a bi-level resource allocation model for the 5G wireless communication system under the CU-DU separation architecture. The upper-level optimization is about the base stations allocating the resources to the slices to optimize the operator’s benefits, and the lower-level optimization is about the slices allocating the resource to their users to improve the service equity of all users. In the actual application of this scenario, because the situation in the slice changed rapidly, it required an algorithm that can quickly give a better allocation scheme. Thus, this paper employed MATD3 for the upper-level resource allocation and DCTD3 for the lower-level resource allocation. Finally, we conducted a lot of simulation experiments. The results demonstrated the efficiency and feasibility of the proposed algorithm.
In the future, we will try to study how to allocate different amounts of resource blocks with fixed input action dimensions to realize the training of only one agent for each slice in a real sense. However, due to this kind of reinforcement learning based on neural networks, a different allocation of resource blocks have different dimensions during training, which brings many restrictions in the actual landing. We will make some improvements in this area to make the algorithm generalize better.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}