
Design of Confidence-Integrated Denoising Auto-Encoder for Personalized Top-N Recommender Systems


 and
and
Abstract
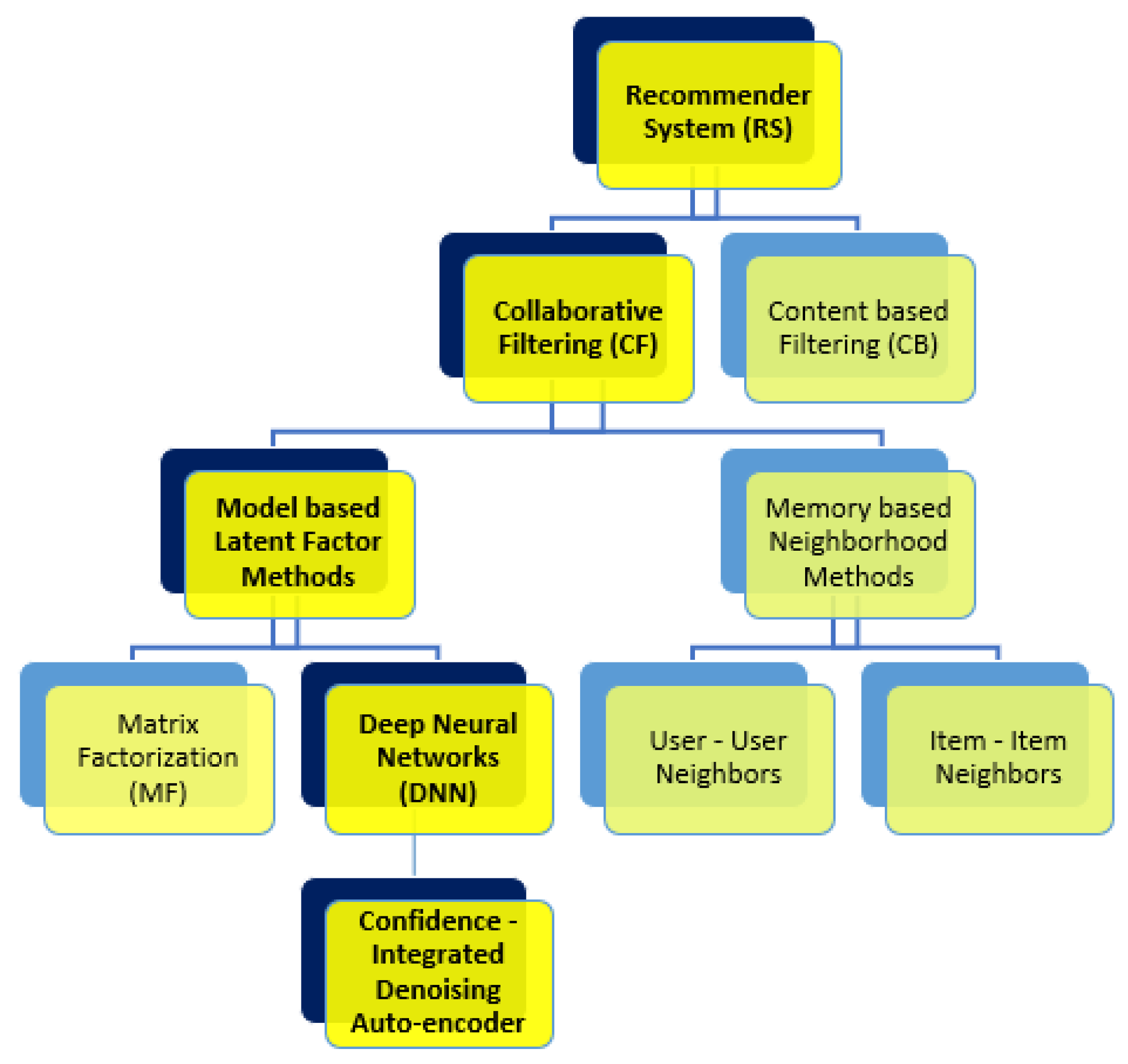
:1. Introduction
1.1. Related Work
1.2. Research Objectives
- To design an intelligent, deep neural network (DNN)-based collaborative filtering model (auto-encoder-based denoising model) with the ability to provide the most suitable, top-N recommendation of items to the users quickly and correctly;
- To extract the significant features encapsulated in the users’ feedback for different products by using a confidence-aware DAE;
- To validate the robustness of the proposed model for different noise variations;
- To authenticate the intended efficacy of the suggested model for predicting top-N recommendations through benchmark data sets (ML100K and ML1M).
1.3. Research Contributions
- To characterize the observed ratings with respect to the confidence of a user in a specific product, a confidence-integrated denoising model is proposed (CIDAE) to exploit the actual ratings set completely for accurate and useful top-N recommendations;
- The proposed denoising model (CIDAE) succeeds in extracting the prominent latent features for different noise levels, which confirms the robustness of the proposed model for providing accurate top-N recommendations;
- The correctness of the proposed CIDAE regarding ranking predictions for top-N recommendations is verified through two benchmark datasets: ML-1M and ML-100k;
- The proposed CIDAE exhibits an improved performance via ranking-based evaluation metrics (precision, recall and normalized discounted gain) in a smaller number of epochs when compared to state-of-the-art denoising models (DAE and CDAE).
1.4. Paper Organization
2. Mathematical Model of Auto-Encoders for Recommender Systems
3. Auto-Encoder Variants for Recommender Systems
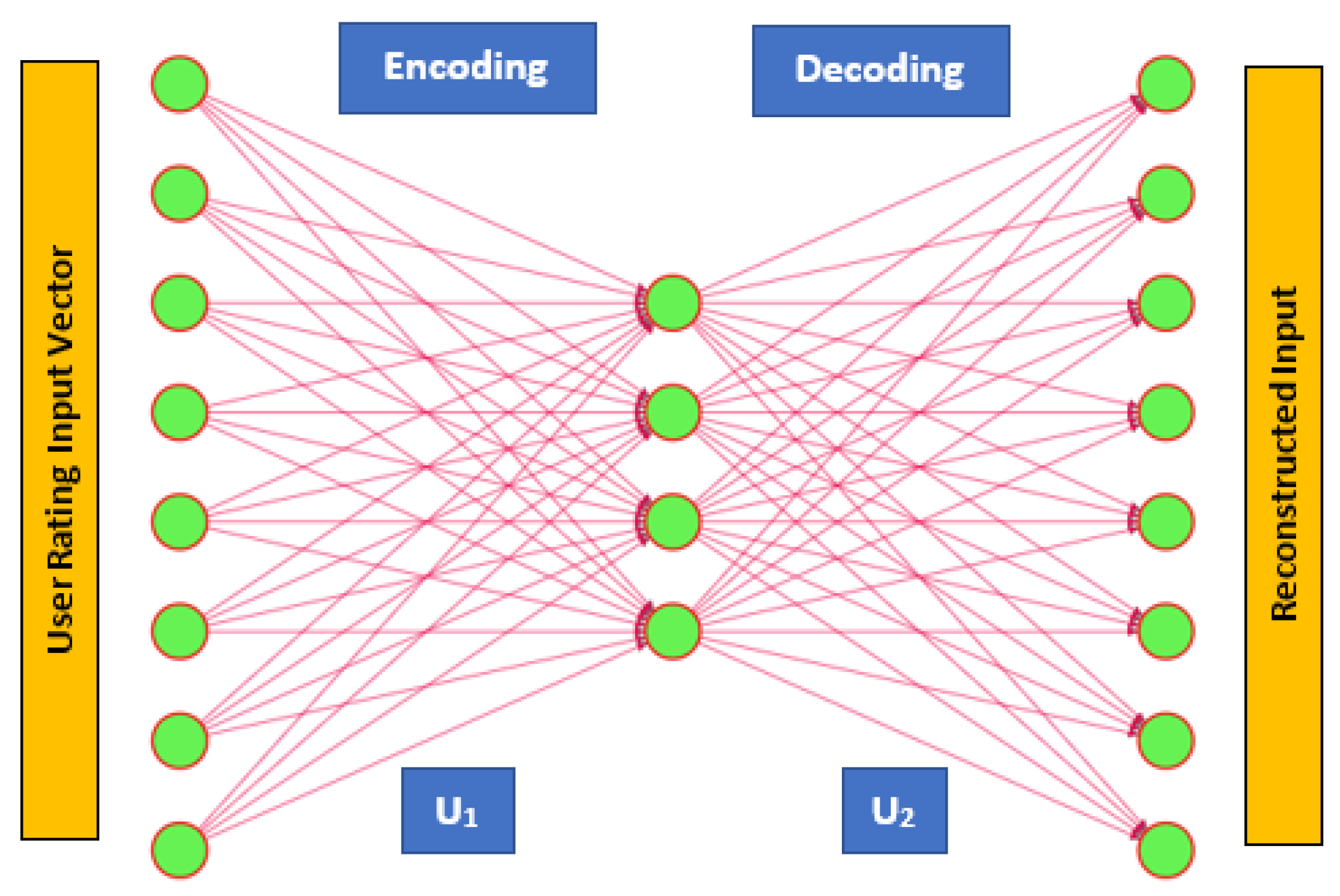
3.1. Auto-Encoder (AE)
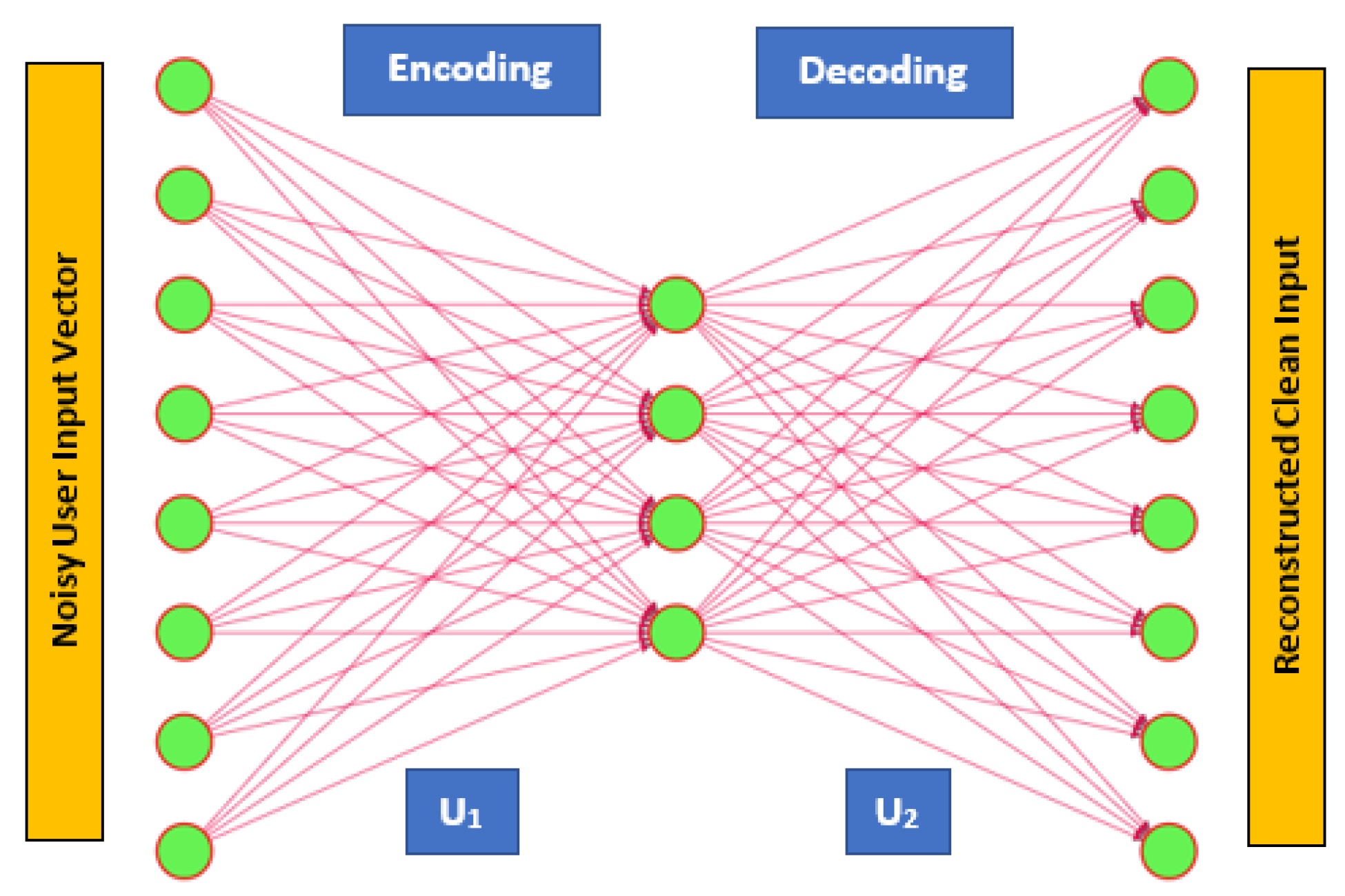
3.2. Denoising Auto-Encoder (DAE)
3.3. Confidence-Integrated Denoising Auto-Encoder (CIDAE)
| Algorithm 1. Pseudocode of the suggested CIDAE method |
| Input: confidence‐aware, corrupted user‐preference vectors Output: clean user-preference vectors for top-N recommendations
|
4. Simulations and Results
4.1. Data Manipulation
4.2. Datasets Particulars
4.3. Simulation Description
4.4. Simulation Settings
4.5. Ranking-Based Evaluation Metrics
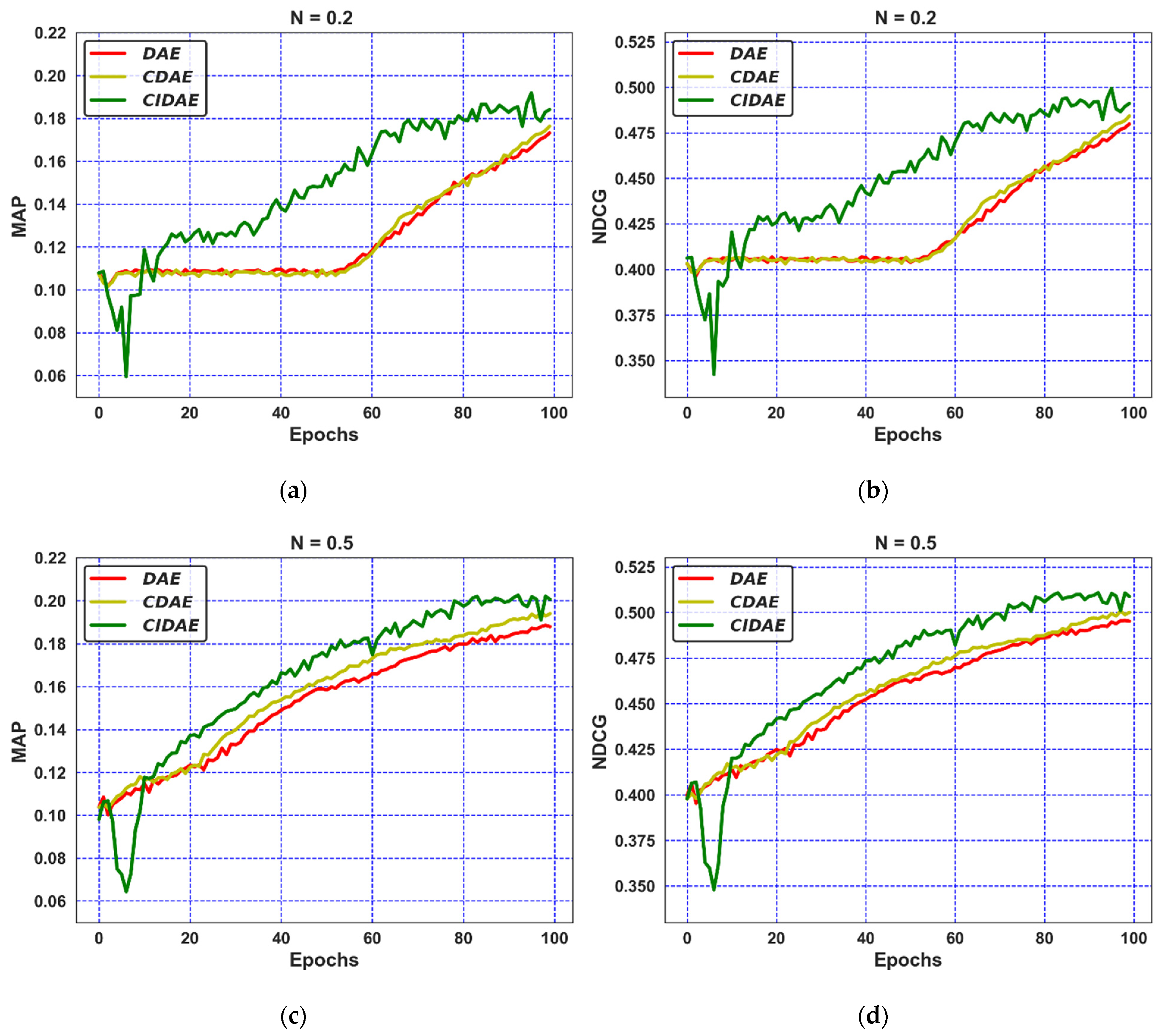
4.6. Results and Discussion
4.6.1. Explanation with Respect to the ML-100K Dataset
4.6.2. Explanation with Respect to the ML-1M Dataset
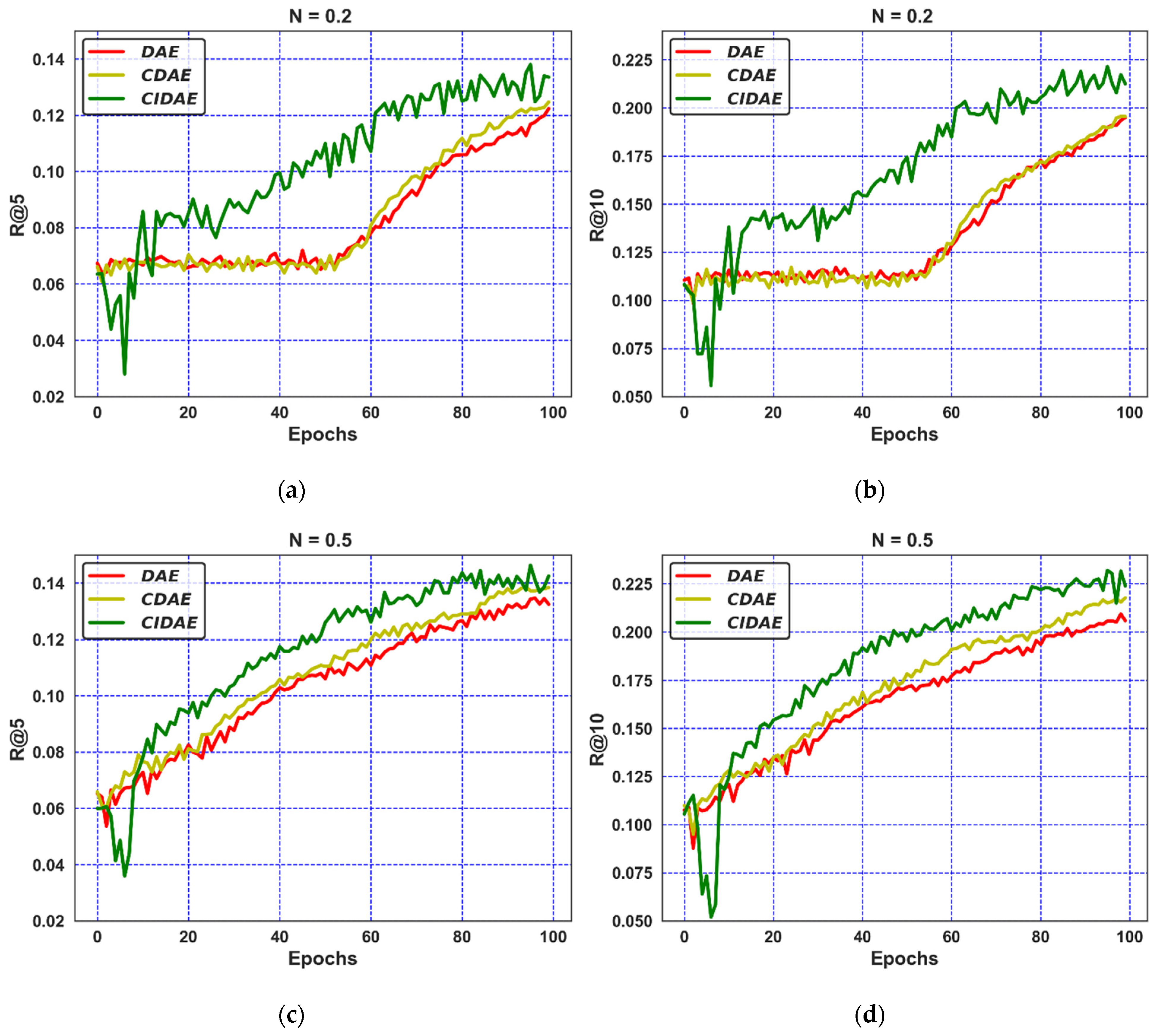
4.7. Critical Observations
- The performance attained by the proposed CIDAE in fewer iterations for both noise variations indicates the improved speed for providing the top-N recommendations;
- The better steady-state performance, regardless of changes in noise levels, confirms the robustness and accuracy of the proposed CIDAE over its counterparts;
- The improved performance of the proposed CIDAE for both datasets verifies the scalability of the model when compared to the DAE and CDAE;
- A noticeable increase in performance in terms of all ranking-based measures is observed with = 0.5 compared to = 0.2 for the proposed CIDAE, which confirms that the CIDAE has the ability to perform better for more randomly overwritten zero values with the probability of = 0.5;
- The relative progress in the performance of the proposed CIDAE for iterations greater than 10 is considerably improved when compared to the two contending auto-encoder-based denoising techniques for noise variations ();
- The CIDAE attains its enhanced, accurate, and speedy performance due to the presence of a confidence-integrated, weighted-objective function which associates the actual ratings (low or high) to a certain confidence value.
4.8. Implications
- Assigning the confidence values to the ratings highlights the importance of an explicit feedback (either high or low) given by a user with a particular state of mind;
- The prediction of missing feedback using higher (positive) and lower (negative) ratings;
- The proposed model provides an opportunity to utilize a full set of observed ratings rather than preferential ratings (positive-only feedback) to exploit the full information hidden in low, intermediate, and high ratings;
- The proposed confidence-aware strategy contributes as a significant addition to the e-commerce industry for increasing the potential of DAE-based recommendation models in term of the speed and accuracy of the recommendations.
5. Conclusions
- We have suggested a confidence-aware denoising auto-encoder model (CIDAE) that exploits a complete set of observed ratings for an enhanced accuracy in providing top-N recommendations to users. The proposed CIDAE showed significantly improved results in terms of the recommendation speed over two denoising auto-encoder variants (DAE and CDAE) for smaller noise values, i.e., = 0.2. This is because a smaller noise value supports the maintenance of a noticeable proportion of users’ confidence with respect to the observed ratings in the dataset, providing useful information to the CIDAE for modeling confidence-aware top-N recommendations correctly;
- The comparison of the developed strategy (CIDAE) with state-of-the-art denoising auto-encoders (DAE and CDAE) with respect to standard, ranking-based evaluation metrics indicates a relatively improved performance of the CIDAE for suggesting top-N recommendations to the candidate users;
- The proposed CIDAE achieved a substantial steady-state performance for both noise levels with the ML-100K dataset, whereas the CIDAE attained improved results on the ML-1M dataset for a low noise level ( = 0.2) and comparable results for a high noise level ( = 0.5). Such behavior confirms the robustness and scalability of the proposed CIDAE over its counterparts.
Author Contributions
Funding
Conflicts of Interest
References
- Aggarwal, C.C. An Introduction to Recommender Systems. In Recommender Systems; Springer International Publishing: Cham, Switzerland, 2016; pp. 1–28. [Google Scholar]
- Bobadilla, J.; Ortega, F.; Hernando, A.; Gutiérrez, A. Recommender systems survey. Knowl.-Based Syst. 2013, 46, 109–132. [Google Scholar] [CrossRef]
- Konstan, J.A. Introduction to recommender systems. In Proceedings of the ACM SIGMOD International Conference on Management of Data; Springer US: Boston, MA, USA, 2008; p. 1373, ISBN 9781605581026. [Google Scholar]
- Jayalakshmi, S.; Ganesh, N.; Čep, R.; Senthil Murugan, J. Movie Recommender Systems: Concepts, Methods, Challenges, and Future Directions. Sensors 2022, 22, 4904. [Google Scholar] [CrossRef]
- Heimbach, I.; Gottschlich, J.; Hinz, O. The value of user’s Facebook profile data for product recommendation generation. Electron. Mark. 2015, 25, 125–138. [Google Scholar] [CrossRef]
- Salau, L.; Hamada, M.; Prasad, R.; Hassan, M.; Mahendran, A.; Watanobe, Y. State-of-the-Art Survey on Deep Learning-Based Recommender Systems for E-Learning. Appl. Sci. 2022, 12, 11996. [Google Scholar] [CrossRef]
- Alhijawi, B.; Kilani, Y. The recommender system: A survey. Int. J. Adv. Intell. Paradig. 2020, 15, 229. [Google Scholar] [CrossRef]
- Venkatesan, R. Sabari A Issues in various recommender system in e-commerce—A survey. J. Crit. Rev. 2020, 7, 604–608. [Google Scholar]
- Karimi, M.; Jannach, D.; Jugovac, M. News recommender systems—Survey and roads ahead. Inf. Process. Manag. 2018, 54, 1203–1227. [Google Scholar] [CrossRef]
- Eirinaki, M.; Gao, J.; Varlamis, I.; Tserpes, K. Recommender Systems for Large-Scale Social Networks: A review of challenges and solutions. Future Gener. Comput. Syst. 2018, 78, 413–418. [Google Scholar] [CrossRef]
- Amato, F.; Moscato, V.; Picariello, A.; Piccialli, F. SOS: A multimedia recommender System for Online Social networks. Future Gener. Comput. Syst. 2019, 93, 914–923. [Google Scholar] [CrossRef]
- Chamoso, P.; Rivas, A.; Rodríguez, S.; Bajo, J. Relationship recommender system in a business and employment-oriented social network. Inf. Sci. 2018, 433–434, 204–220. [Google Scholar] [CrossRef]
- Xiong, P.; Zhang, L.; Zhu, T.; Li, G.; Zhou, W. Private collaborative filtering under untrusted recommender server. Future Gener. Comput. Syst. 2020, 109, 511–520. [Google Scholar] [CrossRef]
- Kaur, H.; Kumar, N.; Batra, S. An efficient multi-party scheme for privacy preserving collaborative filtering for healthcare recommender system. Future Gener. Comput. Syst. 2018, 86, 297–307. [Google Scholar] [CrossRef]
- Hong, M.; Jung, J.J. Multi-Sided recommendation based on social tensor factorization. Inf. Sci. 2018, 447, 140–156. [Google Scholar] [CrossRef]
- Yu, W.; Li, S. Recommender systems based on multiple social networks correlation. Future Gener. Comput. Syst. 2018, 87, 312–327. [Google Scholar] [CrossRef]
- Meng, S.; Qi, L.; Li, Q.; Lin, W.; Xu, X.; Wan, S. Privacy-preserving and sparsity-aware location-based prediction method for collaborative recommender systems. Futur. Gener. Comput. Syst. 2019, 96, 324–335. [Google Scholar] [CrossRef]
- Cui, C.; Qin, J.; Ren, Q. Deep Collaborative Recommendation Algorithm Based on Attention Mechanism. Appl. Sci. 2022, 12, 10594. [Google Scholar] [CrossRef]
- Salter, J.; Antonopoulos, N. CinemaScreen Recommender Agent: Combining Collaborative and Content-Based Filtering. IEEE Intell. Syst. 2006, 21, 35–41. [Google Scholar] [CrossRef]
- Mobasher, B. Data Mining for Web Personalization. In The Adaptive Web; Springer: Berlin/Heidelberg, Germany, 2007; Volume 4321 LNCS, pp. 90–135. ISBN 3540720782. [Google Scholar]
- Aslanian, E.; Radmanesh, M.; Jalili, M. Hybrid Recommender Systems based on Content Feature Relationship. IEEE Trans. Ind. Inform. 2016, 1. [Google Scholar] [CrossRef]
- Peng, D.; Yuan, W.; Liu, C. HARSAM: A Hybrid Model for Recommendation Supported by Self-Attention Mechanism. IEEE Access 2019, 7, 12620–12629. [Google Scholar] [CrossRef]
- Köhler, S.; Wöhner, T.; Peters, R. The impact of consumer preferences on the accuracy of collaborative filtering recommender systems. Electron. Mark. 2016, 26, 369–379. [Google Scholar] [CrossRef]
- He, C.; Parra, D.; Verbert, K. Interactive recommender systems: A survey of the state of the art and future research challenges and opportunities. Expert Syst. Appl. 2016, 56, 9–27. [Google Scholar] [CrossRef]
- Chen, R.; Hua, Q.; Chang, Y.S.; Wang, B.; Zhang, L.; Kong, X. A survey of collaborative filtering-based recommender systems: From traditional methods to hybrid methods based on social networks. IEEE Access 2018, 6, 64301–64320. [Google Scholar] [CrossRef]
- Cunha, T.; Soares, C.; de Carvalho, A.C.P.L.F. Metalearning and Recommender Systems: A literature review and empirical study on the algorithm selection problem for Collaborative Filtering. Inf. Sci. 2018, 423, 128–144. [Google Scholar] [CrossRef]
- Li, J.; Zhang, K.; Yang, X.; Wei, P.; Wang, J.; Mitra, K.; Ranjan, R. Category Preferred Canopy–K-means based Collaborative Filtering algorithm. Futur. Gener. Comput. Syst. 2019, 93, 1046–1054. [Google Scholar] [CrossRef]
- Hayakawa, M. MF Techniques. In Earthquake Prediction with Radio Techniques; Wiley: Hoboken, NJ, USA, 2015; pp. 199–207. [Google Scholar] [CrossRef]
- Colace, F.; Conte, D.; De Santo, M.; Lombardi, M.; Santaniello, D.; Valentino, C. A content-based recommendation approach based on singular value decomposition. Conn. Sci. 2022, 34, 2158–2176. [Google Scholar] [CrossRef]
- Ben Schafer, J.; Konstan, J.A.; Riedl, J. E-commerce recommendation applications. Data Min. Knowl. Discov. 2001, 5, 115–153. [Google Scholar] [CrossRef]
- Wang, J.; de Vries, A.P.; Reinders, M.J.T. On Combining User-based and Item-based Collaborative Filtering. In Proceedings of the Twenty-Seventh Symposium on Information Theory in the Benelux, Noordwijk, The Netherlands, 8–9 June 2006; 2006; pp. 307–315. [Google Scholar]
- Hernández-Lobato, J.M.; Houlsby, N.; Ghahramani, Z. Probabilistic matrix factorization with non-random missing data. In Proceedings of the International Conference on Machine Learning 2014, Beijing, China, 21–26 June 2014; 2014; Volume 4, pp. 3394–3436. [Google Scholar]
- Wang, S.; Tang, J.; Wang, Y.; Liu, H. Exploring hierarchical structures for recommender systems. IEEE Trans. Knowl. Data Eng. 2018, 30, 1022–1035. [Google Scholar] [CrossRef]
- Ning, X.; Desrosiers, C.; Karypis, G. A Comprehensive Survey of Neighborhood-Based Recommendation Methods. In Recommender Systems Handbook; Springer US: Boston, MA, USA, 2015; pp. 37–76. ISBN 9781489976376. [Google Scholar]
- Pan, Y.; He, F.; Yu, H. A novel Enhanced Collaborative Autoencoder with knowledge distillation for top-N recommender systems. Neurocomputing 2019, 332, 137–148. [Google Scholar] [CrossRef]
- Park, M.-H.; Hong, J.-H.; Cho, S.-B. Location-Based Recommendation System Using Bayesian User’s Preference Model in Mobile Devices. In Ubiquitous Intelligence and Computing; Springer: Berlin/Heidelberg, Germany, 2007; pp. 1130–1139. [Google Scholar]
- Linqi, G.; Congdong, L. Hybrid personalized recommended model based on genetic algorithm. In Proceedings of the 2008 4th International Conference on Wireless Communications, Networking and Mobile Computing, Dalian, China, 12–14 October 2008; pp. 1–4. [Google Scholar] [CrossRef]
- Luo, X.; Xia, Y.; Zhu, Q. Incremental Collaborative Filtering recommender based on Regularized Matrix Factorization. Knowl.-Based Syst. 2012, 27, 271–280. [Google Scholar] [CrossRef]
- Casillo, M.; Gupta, B.B.; Lombardi, M.; Lorusso, A.; Santaniello, D.; Valentino, C. Context Aware Recommender Systems: A Novel Approach Based on Matrix Factorization and Contextual Bias. Electronics 2022, 11, 1003. [Google Scholar] [CrossRef]
- Bokde, D.; Girase, S.; Mukhopadhyay, D. Matrix Factorization Model in Collaborative Filtering Algorithms: A Survey. Procedia Comput. Sci. 2015, 49, 136–146. [Google Scholar] [CrossRef]
- Zhang, L.; Luo, T.; Zhang, F.; Wu, Y. A Recommendation Model Based on Deep Neural Network. IEEE Access 2018, 6, 9454–9463. [Google Scholar] [CrossRef]
- Dong, X.; Yu, L.; Wu, Z.; Sun, Y.; Yuan, L.; Zhang, F. A Hybrid Collaborative Filtering Model with Deep Structure for Recommender Systems. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Kali, Y.; Linn, M. Science. In International Encyclopedia of Education; Elsevier: Amsterdam, The Netherlands, 2010; Volume 313, pp. 468–474. ISBN 9780080448947. [Google Scholar]
- Chae, D.-K.; Shin, J.A.; Kim, S.-W. Collaborative Adversarial Autoencoders: An Effective Collaborative Filtering Model Under the GAN Framework. IEEE Access 2019, 7, 37650–37663. [Google Scholar] [CrossRef]
- Alfarhood, M.; Cheng, J. Deep Learning-Based Recommender Systems. In Advances in Intelligent Systems and Computing; Springer: Berlin/Heidelberg, Germany, 2021; Volume 1232, pp. 1–23. [Google Scholar]
- Batmaz, Z.; Yurekli, A.; Bilge, A.; Kaleli, C. A review on deep learning for recommender systems: Challenges and remedies. Artif. Intell. Rev 2018, 52, 1–37. [Google Scholar] [CrossRef]
- Zhang, G.; Liu, Y.; Jin, X. A survey of autoencoder-based recommender systems. Front. Comput. Sci. 2020, 14, 430–450. [Google Scholar] [CrossRef]
- He, M.; Meng, Q.; Zhang, S. Collaborative Additional Variational Autoencoder for Top-N Recommender Systems. IEEE Access 2019, 7, 5707–5713. [Google Scholar] [CrossRef]
- Chen, M.; Xu, Z.; Weinberger, K.; Sha, F. Marginalized Denoising Autoencoders for Domain Adaptation. arXiv 2012, arXiv:1206.4683. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Sedhain, S.; Menony, A.K.; Sannery, S.; Xie, L. AutoRec: Autoencoders meet collaborative filtering. In Proceedings of the WWW’15 Companion: Proceedings of the 24th International Conference on World Wide Web, New York, NY, USA, 18–22 May 2015; pp. 111–112. [Google Scholar] [CrossRef]
- Strub, F.; Gaudel, R.; Mary, J. Hybrid Recommender System based on Autoencoders. In Proceedings of the 1st Workshop on Deep Learning for Recommender Systems—DLRS 2016, Boston, MA, USA, 15 September 2016; pp. 11–16. [Google Scholar]
- Sachdeva, N.; Manco, G.; Ritacco, E.; Pudi, V. Sequential Variational Autoencoders for Collaborative Filtering. In Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining, Melbourne, VIC, Australia, 11–15 February 2019; ACM: New York, NY, USA, 2019; pp. 600–608. [Google Scholar]
- Wu, Y.; DuBois, C.; Zheng, A.X.; Ester, M. Collaborative Denoising Auto-Encoders for Top-N Recommender Systems. In Proceedings of the Ninth ACM International Conference on Web Search and Data Mining, San Francisco, CA, USA, 22–25 February 2016; ACM: New York, NY, USA, 2016; pp. 153–162. [Google Scholar]
- Khan, Z.A.; Zubair, S.; Imran, K.; Ahmad, R.; Butt, S.A.; Chaudhary, N.I. A New Users Rating-Trend Based Collaborative Denoising Auto-Encoder for Top-N Recommender Systems. IEEE Access 2019, 7, 141287–141310. [Google Scholar] [CrossRef]
- Ouyang, Y.; Liu, W.; Rong, W.; Xiong, Z. Autoencoder-Based Collaborative Filtering. In Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2014; Volume 8836, pp. 284–291. ISBN 9783319126425. [Google Scholar]
- Wang, H.; Wang, N.; Yeung, D.-Y. Collaborative Deep Learning for Recommender Systems. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, NSW, Australia, 10–13 August 2015; ACM: New York, NY, USA, 2015; pp. 1235–1244. [Google Scholar]
- Wang, H.; Shi, X.; Yeung, D.-Y. Relational Stacked Denoising Autoencoder for Tag Recommendation. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence; AAAI Press: Menlo Park, CA, USA, 2015. [Google Scholar]
- Li, X.; She, J. Collaborative Variational Autoencoder for Recommender Systems. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; ACM: New York, NY, USA, 2017; pp. 305–314. [Google Scholar]
- Zhang, S.; Yao, L.; Sun, A.; Tay, Y. Deep Learning Based Recommender System. ACM Comput. Surv. 2019, 52, 1–38. [Google Scholar] [CrossRef]
- Loni, B.; Pagano, R.; Larson, M.; Hanjalic, A. Top-N Recommendation with Multi-Channel Positive Feedback using Factorization Machines. ACM Trans. Inf. Syst. 2019, 37, 15. [Google Scholar] [CrossRef]
- VerstrepenKoen; BhaduriyKanishka; CuleBoris; GoethalsBart Collaborative Filtering for Binary, Positiveonly Data. ACM SIGKDD Explor. Newsl. 2017, 19, 1–21. [CrossRef]
- Vincent, P.; Larochelle, H.; Bengio, Y.; Manzagol, P.-A. Extracting and composing robust features with denoising autoencoders. In Proceedings of the 25th international conference on Machine learning—ICML ’08, New York, NY, USA, 5–9 July 2008; ACM Press: New York, New York, USA, 2008; pp. 1096–1103. [Google Scholar]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.-A. Stacked Denoising Autoencoders: Learning Useful Representations in a Deep Network with a Local Denoising Criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Harper, F.M.; Konstan, J.A. The MovieLens Datasets. ACM Trans. Interact. Intell. Syst 2015, 5, 1–19. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Total Ratings (R) | Number of Users (U) | Number of Items (I) | Density (%) R/(U*I) * 100 | Min (R/U) |
|---|---|---|---|---|---|
| ML-100K | 100K | 943 | 1682 | 6.30 | 20 |
| ML-1M | 1M | 6040 | 3706 | 4.47 | 20 |
| Hyper-Parameters Used | Notation | Tested Hyper-Parameter Values | Values Chosen for CIDAE | Values Chosen for DAE | Values Chosen for CDAE |
|---|---|---|---|---|---|
| Latent Features | 50 | 50 | 50 | 50 | |
| Learning Rate | 0.001, 0.005, 0.01, 0.05, 0.06, 0.07, 0.08, 0.1, 0.5 | 0.06 | 0.01 | 0.01 | |
| Noise | 0.2, 0.5, 0.8, 0.10 | 0.2, 0.5 | 0.2, 0.5 | 0.2, 0.5 | |
| Regularization Rate | 0.01 | 0.01 | 0.01 | 0.01 | |
| Confidence Value | 0.1 | 0.1 | 0.1 | 0.1 |
| Metric | = 0.2 | = 0.5 | ||||
|---|---|---|---|---|---|---|
| CIDAE | CDAE | DAE | CIDAE | CDAE | DAE | |
| P@10 | 0.1839 | 0.1809 | 0.1807 | 0.1987 | 0.1945 | 0.1911 |
| R@10 | 0.2125 | 0.1955 | 0.1950 | 0.2239 | 0.2177 | 0.2058 |
| R@5 | 0.1335 | 0.1247 | 0.1223 | 0.1425 | 0.1384 | 0.1324 |
| MAP | 0.1841 | 0.1763 | 0.1732 | 0.2006 | 0.1939 | 0.1878 |
| NDCG | 0.4911 | 0.4842 | 0.4799 | 0.5087 | 0.4999 | 0.4952 |
| NDCG@10 | 0.2519 | 0.2497 | 0.2460 | 0.2741 | 0.2693 | 0.2618 |
| Metrics | = 0.2 | = 0.5 | ||||
|---|---|---|---|---|---|---|
| CIDAE | CDAE | DAE | CIDAE | CDAE | DAE | |
| P@10 | 0.2011 | 0.2048 | 0.1993 | 0.2056 | 0.2162 | 0.1960 |
| R@10 | 0.1589 | 0.1441 | 0.1400 | 0.1608 | 0.1583 | 0.1338 |
| R@5 | 0.1004 | 0.0904 | 0.0880 | 0.0999 | 0.1000 | 0.0837 |
| MAP | 0.1632 | 0.1539 | 0.1504 | 0.1629 | 0.1679 | 0.1457 |
| NDCG | 0.5001 | 0.4876 | 0.4826 | 0.5001 | 0.5042 | 0.4771 |
| NDCG@10 | 0.2498 | 0.2507 | 0.2442 | 0.2574 | 0.2670 | 0.2388 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, Z.A.; Chaudhary, N.I.; Abbasi, W.A.; Ling, S.H.; Raja, M.A.Z. Design of Confidence-Integrated Denoising Auto-Encoder for Personalized Top-N Recommender Systems. Mathematics 2023, 11, 761. https://doi.org/10.3390/math11030761
Khan ZA, Chaudhary NI, Abbasi WA, Ling SH, Raja MAZ. Design of Confidence-Integrated Denoising Auto-Encoder for Personalized Top-N Recommender Systems. Mathematics. 2023; 11(3):761. https://doi.org/10.3390/math11030761
Chicago/Turabian StyleKhan, Zeshan Aslam, Naveed Ishtiaq Chaudhary, Waqar Ali Abbasi, Sai Ho Ling, and Muhammad Asif Zahoor Raja. 2023. "Design of Confidence-Integrated Denoising Auto-Encoder for Personalized Top-N Recommender Systems" Mathematics 11, no. 3: 761. https://doi.org/10.3390/math11030761