1. Introduction
Most manufacturers are currently dedicated to optimizing their product performance to increase demand and establish trust with their customers. However, during the product development process, producers encounter several challenges, including difficulties in managing product failures within the allocated test duration for reliability estimation. In industrial operations, typical operating conditions often result in long periods required to observe unit failures, leading to extended average product failure times. This misalignment with modern industrial practices and technology standards prompted the adoption of accelerated life testing (ALT) by experimenters to expedite responses in such scenarios. ALT involves subjecting the test units to stress levels higher than standard values to accelerate the failure process. Typically, experimenters use data from accelerated tests to estimate the failure distribution of these units. Consequently, there are two categories of ALTs: fully accelerated life tests, where the relationship between life and stress is known, and partially accelerated life tests, where this relationship is either unknown or cannot be assumed. To estimate the lifespan distribution under typical usage conditions, a statistically relevant model is employed to extrapolate data obtained from these accelerated settings.
As outlined by [
1], ALT encompasses various stress loading methods, namely constant stress, step stress, and progressive stress. In constant-stress ALT, sample units endure a sustained stress level until they either fail or undergo censoring, whichever occurs first. However, constant-stress testing may become impractical in certain scenarios due to the broad spectrum of failure times. In such cases, there is a need for a method that ensures faster failure occurrence. Step-stress testing, which proves to be more efficient and practical compared to continuous stress, appears to address this issue effectively. In step-stress testing, the test unit is exposed to a specific stress level for a predefined duration until it fails. Should it not fail within this period, the stress level is incrementally increased until the unit eventually fails or reaches the censored condition. In progressive-stress ALT, test units experience continuously increasing stress levels over time. Various researchers have investigated these three stress-loading methods using a variety of distributions (refer to [
2,
3,
4,
5,
6,
7]).
Given the known or assumed relationship between product life and stress, the fundamental presumption in ALT is that data acquired under accelerated conditions can be extrapolated to reflect performance under normal usage conditions. Nevertheless, it has been observed that, in certain situations, particularly when dealing with new test units, it becomes challenging to ascertain or make a reliable assumption about this relationship. Consequently, in such cases, partial accelerated life tests (PALT) are frequently employed. PALT finds its utility in test environments where it is challenging to collect lifetimes for highly reliable items with extended lifespans using conventional test conditions. PALT typically falls into two distinct categories: step-stress PALT (SS-PALT) and constant-stress PALT (CS-PALT). In CS-PALT, all groups of test units are individually exposed to accelerated conditions and usage profiles. Conversely, in SS-PALT, the usage conditions for the remaining components of the experiment transition from normal use to higher stress levels at predetermined times or after a predefined number of failures. Recent research in the field of PALT has yielded numerous studies, some of which are exemplified by references [
8,
9,
10,
11,
12,
13,
14].
While the primary objective of PALT is to shorten the duration of the testing experiment, experimenters often face substantial downtime as they wait for all test units to fail. To mitigate this challenge, working with censored data becomes essential, aiming to reduce both the cost and duration of the test. Two commonly employed types of censorship are type-I and type-II censoring. In the former, units are simultaneously tested for a predetermined duration, and during this period, some units experience failure; subsequently, the remaining units are withdrawn from the test at its conclusion (refer to [
15,
16]). Conversely, in the latter, units are tested concurrently until a predefined number of failures occur, at which point the remaining units are removed (as described in [
17]). However, these earlier approaches lack flexibility in terms of removing test units mid-test. To address this limitation, a progressive type-II censoring (PTIIC) scheme is proposed as a more versatile censoring method to overcome this challenge. In PTIIC, predetermined units are removed from the test at the moment of a single unit’s failure, and the test proceeds at this pace until a fixed number of units experience failure. Upon reaching this point (the last failed unit), the remaining surviving units are then removed (refer to [
18,
19,
20]).
At times, the duration of the control experiment can become excessively long due to product aging issues. A life test method introduced by [
21] offers experimenters the flexibility to segregate the test units into distinct groups and simultaneously run each group until the first failure occurs within each group. This form of censorship is referred to as ‘first-failure censoring’. However, under this censoring approach, the researcher cannot remove experimental groups from the test until the first failure is observed. To address this limitation, ref. [
22] devised a life testing approach that combines first-failure censoring with progressive type-II censoring, resulting in what is known as a ‘progressive first-failure censoring’ (PFFC) scheme, which will be discussed in the upcoming section. Let us now briefly delve into the progressive first-failure filtering system. Let us put
n-independent groups each with
k units to the test in real life. Start removing
number of groups as soon as
encounters its first failure. Repeat after the second failure time
deleting
groups at random from the experiment as well as the group where the second failure was noticed. The experimenter keeps going in the same way until all live
groups that are still active and the group where the
failure has taken place have been eliminated. The observed failures
are referred to as progressive first failure censored order statistics, whereas the progressive censoring scheme is known as
. Recent years have seen an increase in the amount of literature on PFFC, including in [
23,
24,
25,
26,
27,
28,
29,
30].
In the realm of lifetime data analysis and the modeling of failure processes, parametric models play a crucial role and are widely employed due to their demonstrated utility across diverse scenarios. Among the various univariate models, a select few distributions hold a prominent position for their proven effectiveness in a wide array of situations. Notably, the exponential, Weibull, gamma, and log-normal distributions stand out in this regard. Another versatile model for lifetime distribution, capable of fitting well with certain sets of failure data, is the power hazard function distribution (PHFD). Reference [
31] delved into the application of the PHFD and illustrated its suitability for assessing the reliability of electrical components. Through analyses of reliability and hazard functions, they demonstrated that the PHFD outperforms the exponential, log-normal, and Weibull distributions in this context. As an alternative to the Weibull, Rayleigh, and exponential distributions, Reference [
32] explored the two-parameter version of PHFD, denoted as PHFD(
), and investigated its various characteristics. If
X is a continuous random variable that obeys a PHFD with shape and scale parameters
and
, respectively, the probability density function (PDF) and its related cumulative distribution function (CDF) can be written as
and
respectively. Additionally, the failure rate (FR) and survival functions (SF) can be represented as
and
where
and
. When
, this distribution’s FR function increases, and when
, it decreases. This distribution is a very adaptable model, and when its parameters are altered, it approaches various models. It includes the following specific models: PHFD relates to Rayleigh(
) when
and
, PHFD lowers to Weibull(
) when
, and PHFD is an exponential distribution with mean
when
. Because of these characteristics, this model was utilized by multiple writers to model data, particularly censored observations. Due to its practical significance in the wide range of alternative fields, as noted in numerous references, this distribution’s verification throughout this work serves as our inspiration. These references include in [
33,
34,
35,
36,
37].
The paper is structured and organized as follows:
Section 2 introduces the model description and lays out the fundamental assumptions. In
Section 3, we delve into the most common estimations, including maximum likelihood estimates (MLEs) and the construction of approximate confidence intervals for unknown parameters.
Section 4 is dedicated to the discussion of percentile bootstrap and bootstrap-t algorithms.
Section 5 outlines the process of generating Bayes point estimates using the squared error loss function and provides insights into the associated credible intervals. In
Section 6, we conduct a simulation study using Monte Carlo methods.
Section 7 illustrates the application of our methodology with a real engineering example. Finally,
Section 8 presents some concluding remarks.
3. Maximum Likelihood Estimation
One of the most significant and popular statistical techniques is the maximum likelihood estimate (MLE). The maximum likelihood (ML) technique produces estimates of parameters with favorable statistical properties, such as consistency, asymptotic unbiasedness, asymptotic efficiency, and asymptotic normality. To obtain the parameter estimates with the maximum likelihood, one must calculate the estimates of the parameter that maximizes the probability of the sample data. The MLEs are consistent and asymptotically normal for large samples, which are other desired characteristics. Let
for
represent the two PFFC samples from the two populations whose PDFs and CDFs are as indicated in (1), (2), and (6), (7) with censoring scheme
Without a normalized constant, the logarithm likelihood function can be written as
where
By computing the first derivatives of (9) with respect to
,
, and
and then setting them equal to zero, the resulting simultaneous equations are represented as follows
where
and
A system of three non-linear equations in three unknowns , , and are formally represented by the equations that come before them. The previous non-linear equations are challenging to provide closed-form solutions to theoretically. In order to obtain the MLEs of , the numerical Newton–Raphson approach will be used to solve these simultaneous equations to obtain the estimates. The algorithm is described as follows:
- (1)
Use the method of moments or any other methods to estimate the parameters and as starting point of iteration, denote the estimates as , and set .
- (2)
Calculate
and the observed Fisher information matrix
given in
Section 3.
- (3)
- (4)
Set , and then go back to Step (1).
- (5)
Continue the iterative steps until is smaller than a threshold value. The final estimates of , and are the MLE of the parameters, denoted as and .
To delve deeper into the topic, refer to [
20] for additional information. For distributions that are expressed using more than one parameter, the second derivatives are crucial for a number of reasons. They will confirm that maxima have been found for one of those reasons. The second partial derivatives of the likelihood function in our situation can be written as
and
where
The Fisher information matrix (FIM) is obtained by arranging the second partial derivatives (15)–(20) in a matrix structure. The FIM being negative semi-definite is a necessary requirement in an optimization context for a stationary point to be a maximum. The asymptotic variances–covariances of the maximum likelihood estimators
, and
of the parameters
and
are obtained by the elements of the inverse of the FIM. The observed asymptotic variance-covariance matrix for the ML estimators is obtained as
Therefore, using the asymptotic normality of the ML findings of intervals determined, the approximate
confidence intervals (ACIs) for
,
, and
are obtained according to
Here,
is the percentile of the conventional normal model with a right-tail probability of
. The problem with applying a normal approximation of the MLE is that when the sample size is small, the normal approximation may be poor. However, a different transformation of the MLE can be used to correct the inadequate performance of the normal approximation. Reference [
38] presented a log-transformation as a way to enhance the performance of the normal approximation. Therefore, for the parameters being considered, ACIs of
are provided as
3.1. Consistent and Asymptotically Normal Estimators
3.1.1. Consistency characteristic
Consider as the true parameter value of a statistical model, and let represent the MLE of . The MLE is considered consistent when converges to in probability as the sample size n grows. To establish the MLE’s consistency, we can employ the following theorem.
Theorem 1. Assuming that the log-likelihood function exhibits continuity with respect to θ and meets the subsequent criteria:
- 1.
is differentiable in θ for all x in the sample space.
- 2.
The expected value of the score function is zero at the true parameter value, i.e., for .
- 3.
The FIM is positive definite at the true parameter value, i.e., .
Then, the is a consistent estimator of θ.
Proof. Consider
as any chosen positive value. Applying the Chebyshev inequality, we obtain
Utilizing the central limit theorem, it’s established that the distribution of
tends toward a normal distribution with a mean of
and a variance of
as the sample size
n grows. Consequently, we can express this as
where
is a term that goes to zero as
n increases. Substituting this into the Chebyshev inequality, we obtain
As the sample size n increases, the term diminishes to zero, and the denominator in the inequality grows towards infinity. Consequently, the probability of approaches zero, thereby confirming the consistency of the with respect to . □
3.1.2. Asymptotic Normality Characteristic
We describe the as exhibiting asymptotic normality when its distribution approximates a normal distribution with a mean of and a variance of as the sample size n grows. To establish the MLE’s asymptotic normality, we can utilize the following theorem.
Theorem 2. If the log-likelihood function fulfills the conditions outlined in the consistency theorem mentioned earlier, then the demonstrates asymptotic normality.
Proof. According to the central limit theorem, it is established that the distribution of the score function
tends towards a normal distribution with a mean of zero and a variance of
as the sample size
n grows. As a result, we can express it as follows:
here,
represents a term that diminishes to zero with the increasing value of
n. Utilizing the Taylor series expansion, we can express this as
Replacing the preceding equation into the score function’s asymptotic normality, we obtain
This demonstrates that as the sample size n increases, the distribution of tends toward a normal distribution with a mean of zero and a variance of , thereby confirming the asymptotic normality of the . It is essential to emphasize that the consistency and asymptotic normality properties of MLEs are valid under specific regularity conditions. While these conditions are generally met in numerous statistical models, it is crucial to verify their satisfaction before employing the MLE approach. □
5. Bayesian Estimation
Bayesian estimation is a powerful technique for determining unknown parameters from measurable data. Its foundation is the Bayes theorem, a concept in probability theory that allows the probability of a hypothesis to be updated as new information is gathered. This approach provides a number of benefits over traditional MLE strategies because it may account for prior knowledge while estimating. It also has the ability to assess the degree of uncertainty surrounding each parameter. For Bayesian deduction to work, the priors for the parameters must be chosen correctly. The authors of Reference [
41] argue that it is evident that from a properly Bayesian standpoint, one cannot assert that one prior is superior to all others. One must undoubtedly accept their own subjective past with all of its flaws. However, if we have enough information about the parameter(s), employing informative priors that are unquestionably preferred over all other options is preferable. If not, using ambiguous or non-descriptive priors may be appropriate; for more details, see [
42]. The family of gamma distributions is known to be simple and flexible enough to suit a variety of the experimenter’s preexisting ideas, according to [
43]. Consider the case in which the unknown parameters,
and
, are stochastically independent and have conjugate gamma priors. Specifically, gamma
and gamma
. Additionally, a vague prior is selected for the acceleration factor
with the following PDF
As a result, the joint prior of the parameters
,
, and
together can be stated as follows
In order to present the joint posterior distribution of
,
, and
, one must combine the joint prior distribution
in (38) with the likelihood function
supplied in (8) as
where
and
are given in (10). In the Bayes technique, one should select a loss function that corresponds to each of the potential estimators in order to arrive at the best estimator. Here, the squared error loss function estimations, which we can express as
, and Bayes estimate
are calculated. The inability to derive the joint posterior in a closed form, which would allow us to compute Bayes estimates of the unknown parameters
,
, and
, may be seen in relation (29). The MCMC technique, which enables us to acquire simulated samples from the posterior distributions of the parameters, will therefore be used in order to obtain these estimations. Calculations for the point and interval estimate of unidentified parameters will be made using these generated samples. As for how this approach operates, it is based on the calculation of conditional posterior functions, where the conditional distribution of
given
and
can be represented as
Similarly, the conditional distribution of
given
and
can be reported as
Additionally, the conditional distribution of
given
and
can be stated as
Gamma densities and are evident. As a result, samples of and can be produced using a gamma generator. Additionally, cannot be reduced for directly drawing samples using conventional techniques. The gamma distribution was chosen as the prior distribution of the parameters because it is the most appropriate one that matches the maximum likelihood function. Moreover, they are from the same family. The evidence for this is that two of the full conditional posterior distributions of the parameters and resulted in a gamma distribution, which proves the validity of the choice. In addition, choosing another prior distribution or dependent prior will increase the complexity and difficulty of mathematical equations. Gamma distribution is one of the rich distributions, as when changing its parameters (hyper-parameters), we obtain new data with new information, so it is the focus of attention of most statisticians. A special case is that when all hyper-parameters of gamma distribution are zero, we obtain the Jaffrey prior in the form , and .
In this scenario, we can utilize the Metropolis–Hastings (M-H) algorithm model, which is suggested by [
44], to derive Bayes’ estimate for using one of the well-known MCMC methods. To reduce the rejection rate as much as feasible in this algorithm, we can select either a symmetric or non-symmetric proposal distribution. The normal distribution is included as a symmetric proposal distribution since the marginal distribution of
is not well known. The M-H steps are additionally incorporated into the Gibbs sampler to update
, while
as well as
is updated straight from its full conditional; see [
45] as follows:
Start with an , and set .
Generate from .
Generate according to the following:
- (a)
Generate from normal distribution where the variance of given in (22).
- (b)
Compute .
- (c)
Generate a sample from the distribution.
- (d)
If set ; otherwise, .
Generate from .
Set .
To collect the required number of samples, repeat Steps 2–5 M times.
The original
sample count from the burn-in process is discarded, and we use the
samples that are still there to derive estimations. As a result, the Bayes estimate of
under the squared error loss function can be viewed as the average of the samples that were obtained from the posterior densities as follows:
In order to create the highest posterior density (HPD) credible intervals (CRIs) of
using generated MCMC sampling procedure, we first refer to the ordered random sample produced by the previous algorithm in the form
. Then, the
two-sided CRIs of
can be constructed as
6. Simulation Study
In this section, some computations in line with Monte Carlo simulation experiments are carried out using
Mathematica ver. 13 in an effort to assess the performance of the offered approaches. In light of the proposed algorithm proposed in [
18] with the distribution function
, 1000 PFFC samples were generated under both normal and acceleration conditions from the PHF
and PHF
distributions, respectively, with the parameters
. The effectiveness of the obtained estimates of
, and
from the various proposed approaches (MLE, two parametric bootstrap, and MCMC technique) is compared in terms of point and interval estimates. In order to achieve this, mean squared errors (MSEs) are taken into account for point estimates, whereas the average widths (AWs) of
confidence/HPD credible intervals and
coverage probabilities (CPs) of the parameters based on the simulation are taken into account for interval estimates. For the purpose of conducting our investigation, multiple combinations of
(group size),
(number of groups), and
(observed data) are taken into consideration with various censoring schemes (CSs)
. For ease, three categories of CSs are taken into consideration, namely
To resolve the non-linear Equations (11)–(14) and obtain the MLEs of the parameter values, we used the NMaximize command of the Mathematica 13 package. Additionally, the
, and
are produced utilizing the MLE’s invariance feature. A total of 1000 replicates were used in the investigation. Each replication makes use of 1000 bootstrap (Boot-p and Boot-t) samples. The first 2000 values are deleted as “burn-in” while computing Bayes estimates (BEs) and highest posterior density CRIs in a Bayesian framework utilizing 12,000 MCMC samples. Furthermore, we take into account informative gamma priors with the following hyper-parameter values:
, and
. The parameter values for the informative priors are chosen such that their mean is equal to the parameter values themselves.
Table 1,
Table 2,
Table 3,
Table 4 and
Table 5 show the outcomes of the Monte Carlo simulation study. These tables allow us to draw the following conclusions:
In every instance, as would be expected, the MSEs and AWs of all estimates decrease as sample sizes increase. It verifies the consistency features of each estimation method.
With n and m keeping invariant, k increases both MSEs and AWs increase.
In terms of decreased MSEs and AWs, the first scheme (I) performs the best when sample sizes are fixed and failures are observed.
The MSE and AW both increase when removals are delayed.
In terms of MSEs and AWs, Bayes estimation using MCMC performs better than the other approaches (ML, Boot-p, Boot-t).
Due to having the smallest MSE and narrowest width, MCMC CRIs are, overall, the most satisfactory.
Bootstrap methods outperform the ML approach in terms of MSEs and AWs. Furthermore, Boot-t performs better than Boot-p in terms of MSEs and AWs.
The estimates produced by the ML, bootstrap, and Bayesian approaches are highly similar and have high CPs (around ).
In spite of the fact that the Bayes estimators perform better than all other estimators, the simulation results show that all point and interval estimator approaches are efficient. The Bayes technique may be chosen if one has sufficient prior knowledge. If past knowledge of the topic being studied cannot be accessed, bootstrap approaches that primarily rely on MLEs are preferred.
7. Practical Analysis of Engineering Data
In this section, we want to see how the estimate algorithms suggested for the accelerated data set perform as described in the aforementioned sections. The effectiveness of the suggested inferential approaches is displayed and demonstrated using a genuine data set that represents the observed failure rates in a life test of the light-emitting diode (LED). References [
46,
47] recently conducted an analysis of this data that was initially conducted by [
48]. The observed failure samples were created in both normal and accelerated conditions, and they include the following:
Normal use condition: 0.18, 0.19, 0.19, 0.34, 0.36, 0.40, 0.44, 0.44, 0.45, 0.46, 0.47,0.53, 0.57, 0.57, 0.63, 0.65, 0.70, 0.71, 0.71, 0.75, 0.76, 0.76, 0.79,0.80, 0.85, 0.98, 1.01, 1.07, 1.12, 1.14, 1.15, 1.17, 1.20, 1.23, 1.24,1.25, 1.26, 1.32, 1.33, 1.33, 1.39, 1.42, 1.50, 1.55, 1.58, 1.59, 1.62, 1.68, 1.70, 1.79, 2.00, 2.01, 2.04, 2.54, 3.61, 3.76, 4.65, 8.97.
Accelerated stress condition: 0.13, 0.16, 0.20, 0.20, 0.21, 0.25, 0.26, 0.28, 0.28, 0.30, 0.31, 0.33, 0.35, 0.35, 0.35, 0.39, 0.50, 0.52, 0.58, 0.60, 0.60, 0.62, 0.63, 0.67, 0.71, 0.73, 0.75, 0.75, 0.78, 0.80, 0.80, 0.86, 0.90, 0.91, 0.93, 0.93, 0.94, 0.98, 0.99, 1.01, 1.03, 1.06, 1.06, 1.10, 1.22, 1.22, 1.24, 1.28, 1.39, 1.39, 1.46, 1.48, 1.52, 1.74, 1.95, 2.46, 3.02, 5.16.
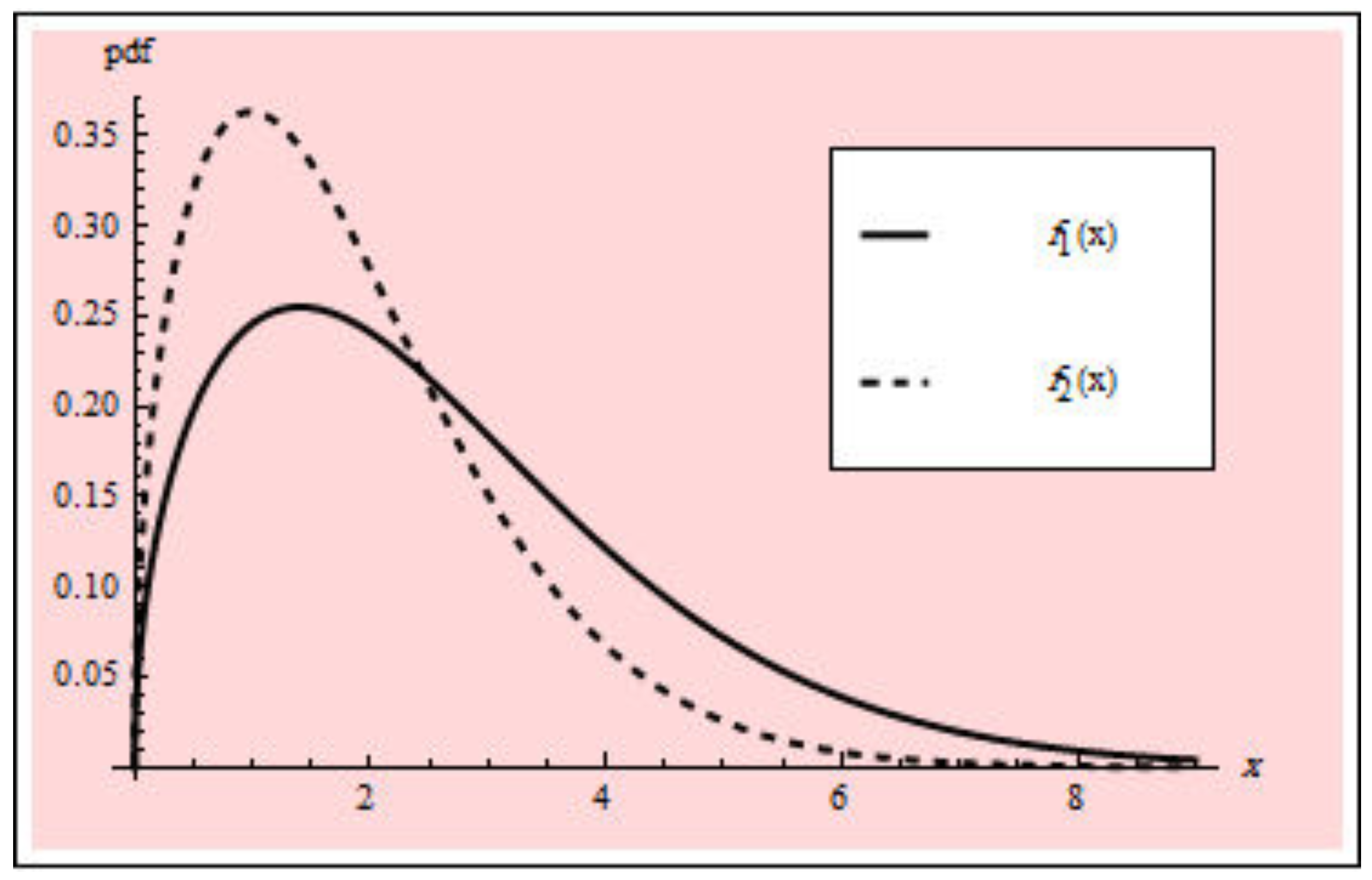
Before moving on, we first determine whether the PHFD can be employed as a suitable model to match the data set using the goodness-of-fit statistic, known as the Kolmogorov–Smirnov (K-S) statistic. The calculated K-S distances and
p-values for the data set under the normal and accelerated stress conditions are
and
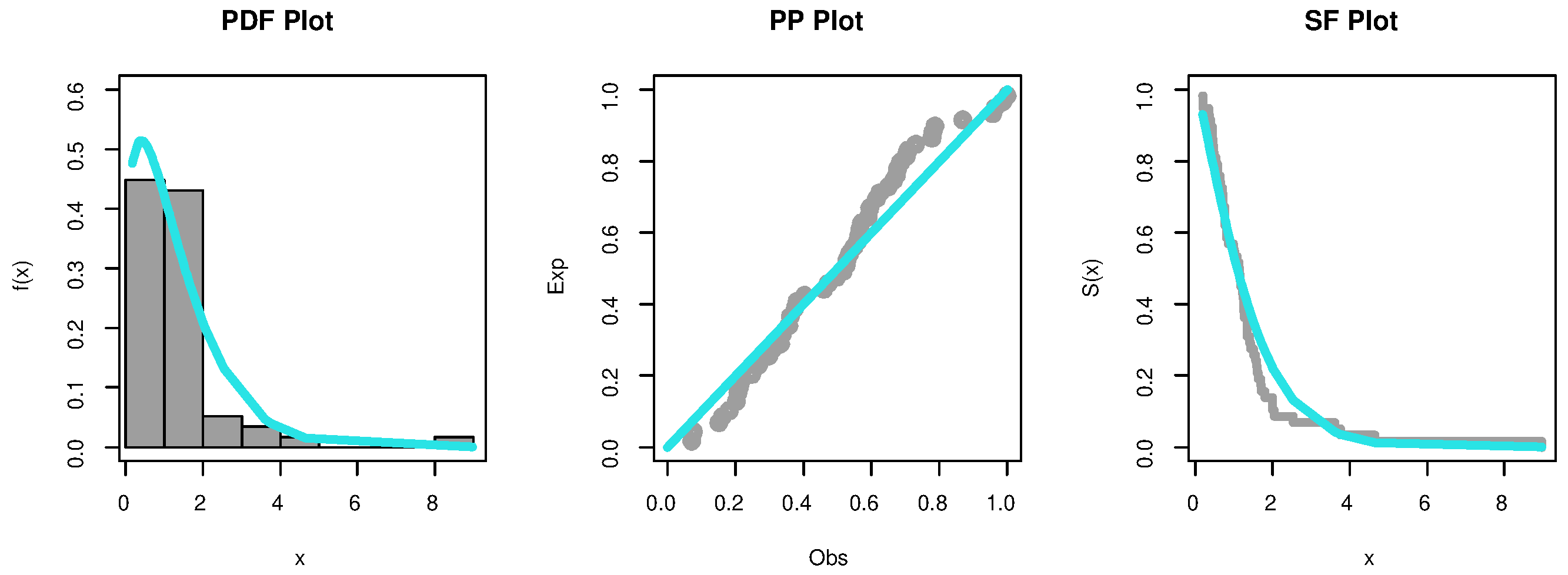
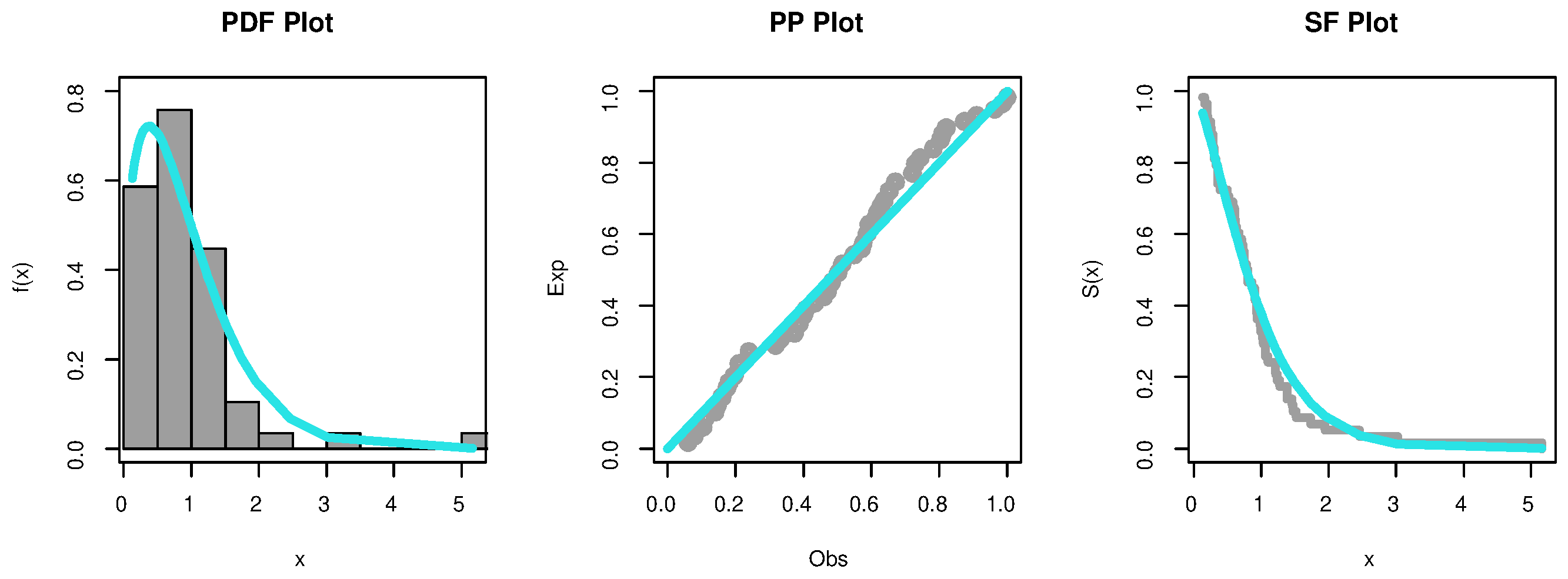
, respectively. The PHFD was found to be a suitable model for this set of data. Further, the empirical PDF, P-P, and SF plots which are shown in
Figure 2 and
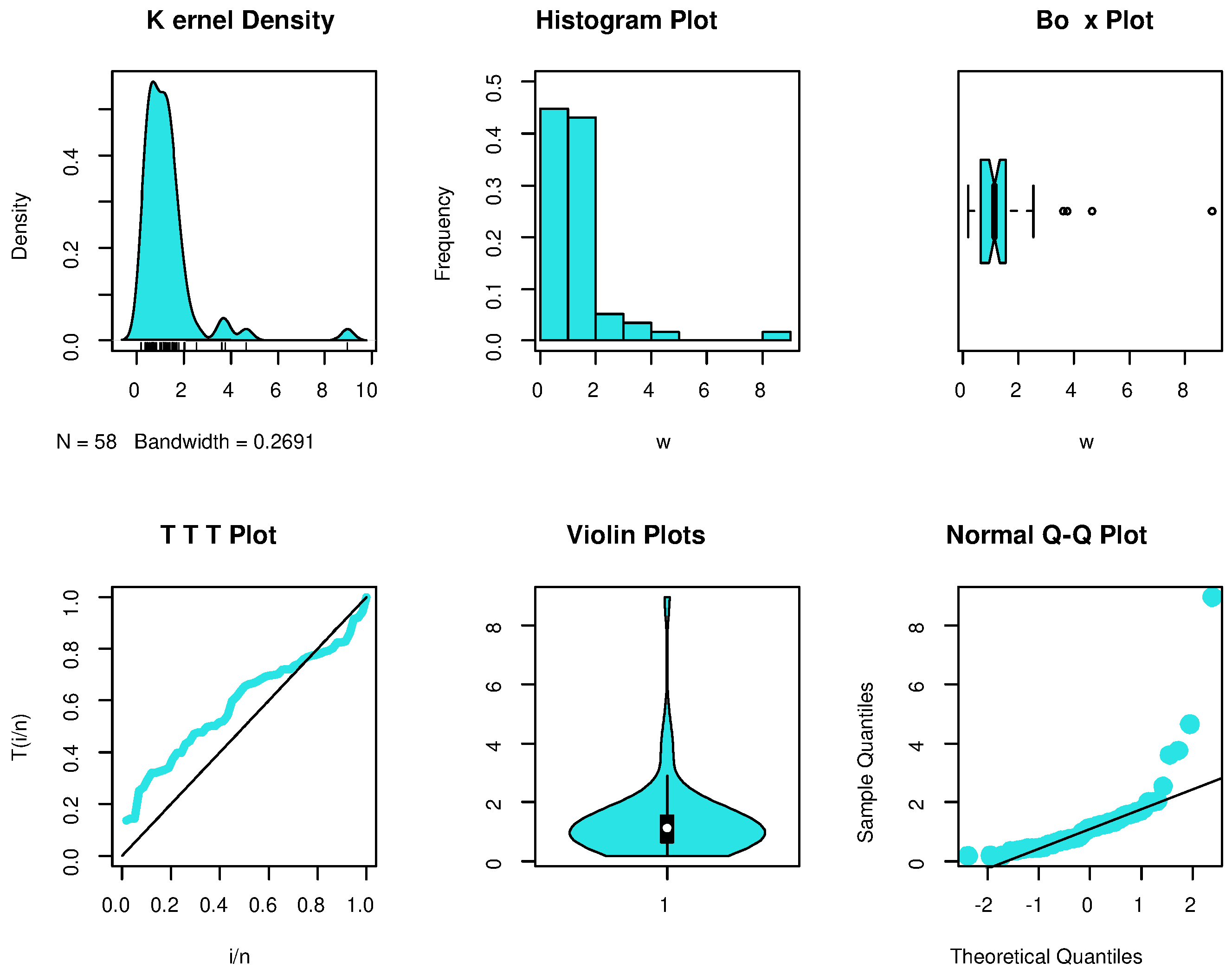
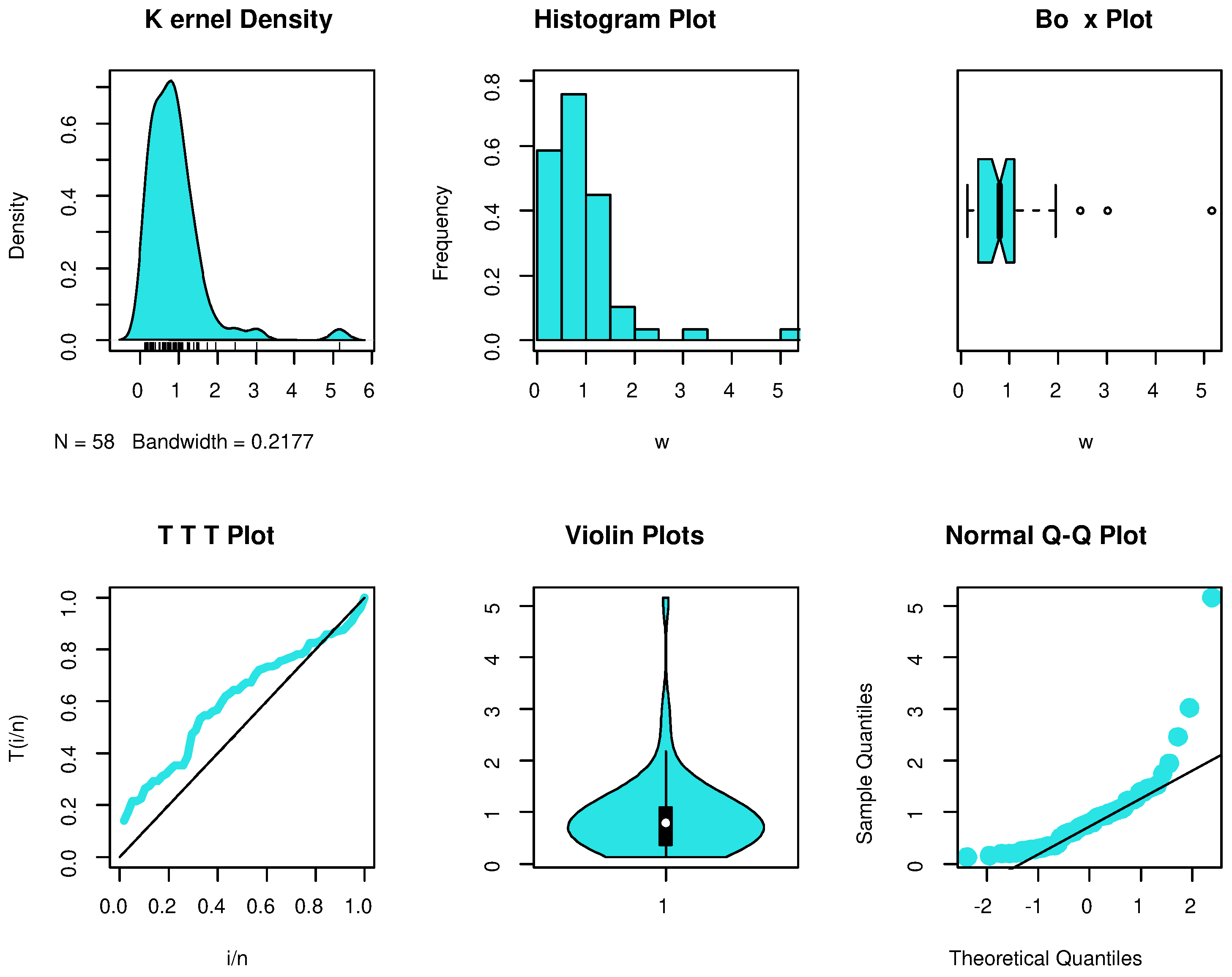
Figure 3 provide additional proof that the PHFD provides a strong fit to the data. Non-parametric approaches, such as histograms, kernel densities, box, violin, TTT, and standard Q-Q plots, are used in
Figure 4 and
Figure 5 to depict the initial shape. The asymmetry of the data and the validity of some outlier observations should be highlighted.
By implementing the technique outlined in
Section 2, PFFC samples are obtained. The original data under both normal use and accelerated stress conditions are separated into groups of a specific size under the use of CSs. Refer to the details presented in
Table 6.
The ML and two parametric Bootstrap point estimates as well as the associated ACIs are obtained and listed in
Table 7. By moving to Bayes estimates, since no previous knowledge of the unknown population parameters is provided, the non-informative (or vague) gamma priors are adequate in this situation. In this instance, the hyper-parameters are set to zero
. As previously mentioned, the Gibbs algorithm relies on Metropolis to produce 12,000 MCMC samples using the
,
and
as initial values at the beginning of the algorithm. Additionally, the Bayes estimates are computed and recorded in
Table 7. Finally, we can say that the estimated PHFD offers a superb fit for the provided data and that Bayes estimates performs better than MLEs and bootstrap.


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}