
High-Pass-Kernel-Driven Content-Adaptive Image Steganalysis Using Deep Learning



Abstract
:1. Introduction
- The proposed scheme amplifies the stego-noise using multiple convolutional layers with predefined kernels. Thirty high-pass SRM kernels and one constant linear kernel are utilized as predefined kernels.
- A layer-specific learning rate higher than the global one is considered in predefined kernels based on convolutional layers. A learning rate variation in the layers boosts the performance of the proposed CNN.
- Each convolutional layer with predefined kernels is followed by three conventional convolutional layers to direct the network correctly.
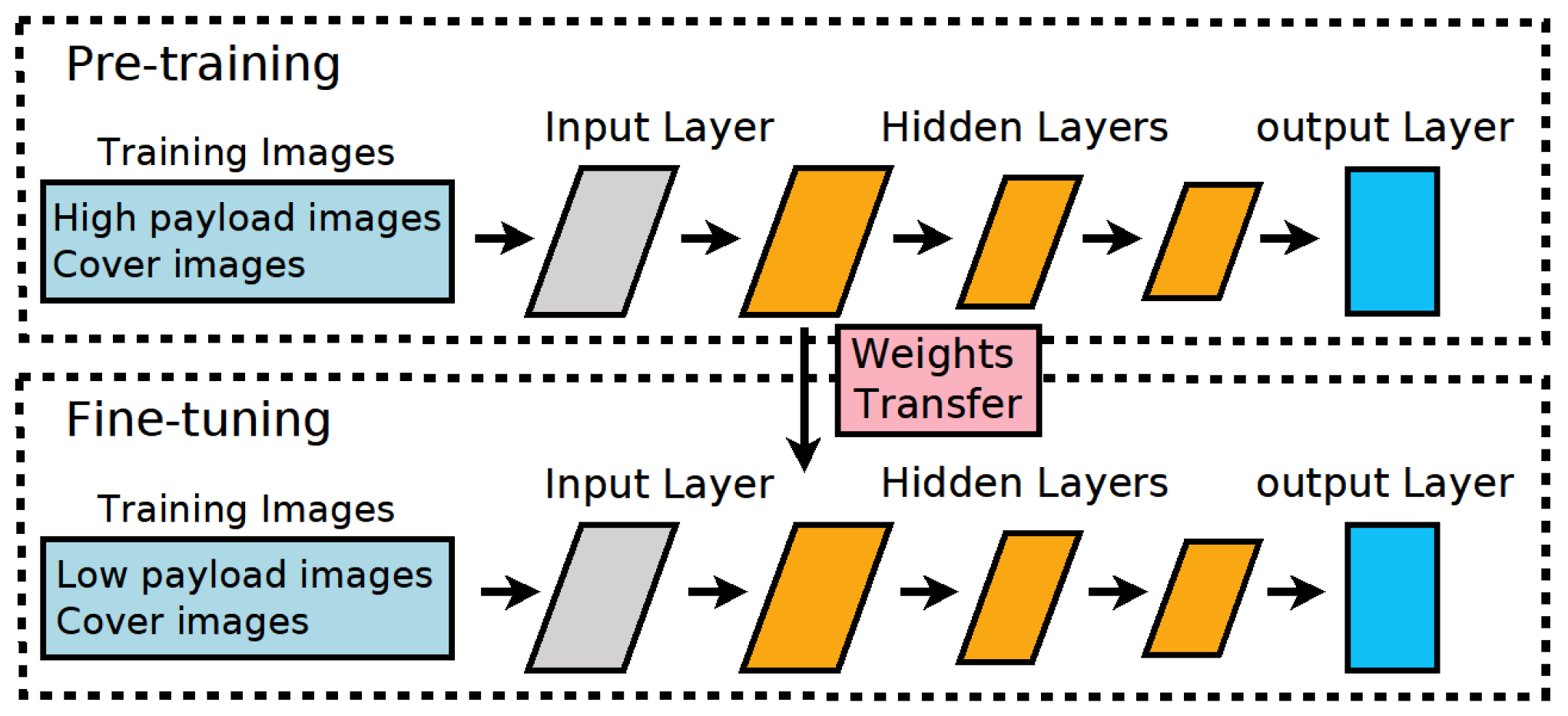
- The weights of the deep network for low-payload stego-images are initialized using the weights of the trained network from high-payload stego-images.
- To maximize the activation of all neurons within the network and thus improve detection performance, the Leaky ReLU layer is preferred over the standard ReLU layer. This strategic choice in activation functions enhances the network’s ability to capture and process relevant features for more effective detection.
- A single global average pooling layer is employed exclusively to extract unprocessed information, and no intermediate pooling layers are integrated between the network layers.
- An experimental analysis is performed to detect HILL, Mi-POD, S-UNIWARD, and WOW stego-images with payloads of 0.2 bpp, 0.3 bpp, and 0.4 bpp.
- The proposed scheme’s detection accuracy is better than the Ye-Net, SRNet, Yedroudj-Net, and Zhu-Net schemes.
2. Proposed Scheme
3. Experimental Results

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Kernels/Payload (bpp) | HILL | Mi-POD | S-UNIWARD | WOW | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.2 | 0.3 | 0.4 | 0.2 | 0.3 | 0.4 | 0.2 | 0.3 | 0.4 | 0.2 | 0.3 | 0.4 | |
| 30 | 59.34 | 64.33 | 69.76 | 63.58 | 71.72 | 73.31 | 65.81 | 74.64 | 79.72 | 71.53 | 78.05 | 81.37 |
| 31 | 60.49 | 65.98 | 71.18 | 64.54 | 72.96 | 74.58 | 66.95 | 76.48 | 81.43 | 72.92 | 79.80 | 82.69 |
| GAP Layer Effect/Payload (bpp) | HILL | Mi-POD | S-UNIWARD | WOW | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.2 | 0.3 | 0.4 | 0.2 | 0.3 | 0.4 | 0.2 | 0.3 | 0.4 | 0.2 | 0.3 | 0.4 | |
| Without GAP | 59.59 | 64.14 | 69.83 | 63.45 | 71.35 | 73.41 | 65.28 | 74.87 | 79.80 | 71.53 | 78.45 | 80.63 |
| GAP | 60.49 | 65.98 | 71.18 | 64.54 | 72.96 | 74.58 | 66.95 | 76.48 | 81.43 | 72.92 | 79.80 | 82.69 |
| Steganalysis Scheme/Payload (bpp) | HILL | Mi-POD | S-UNIWARD | WOW | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.2 | 0.3 | 0.4 | 0.2 | 0.3 | 0.4 | 0.2 | 0.3 | 0.4 | 0.2 | 0.3 | 0.4 | |
| Ye-Net | 52.00 | 56.65 | 61.39 | 55.70 | 60.79 | 63.73 | 57.87 | 65.38 | 71.34 | 66.10 | 69.22 | 75.61 |
| SRNet | 53.15 | 60.62 | 65.07 | 56.41 | 64.25 | 69.92 | 62.97 | 71.31 | 75.73 | 69.50 | 75.80 | 80.36 |
| Yedroudj-Net | 51.79 | 56.39 | 64.96 | 55.86 | 60.47 | 68.43 | 57.61 | 66.07 | 70.40 | 67.32 | 71.72 | 77.15 |
| Zhu-Net | 59.47 | 64.88 | 69.08 | 64.36 | 70.00 | 72.46 | 66.42 | 73.88 | 78.48 | 70.99 | 74.31 | 81.64 |
| Proposed Scheme | 60.49 | 65.98 | 71.18 | 64.54 | 72.96 | 74.58 | 66.95 | 76.48 | 81.43 | 72.92 | 79.80 | 82.69 |
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hong, E.; Lim, K.; Oh, T.-W.; Jang, H. Lightweight image steganalysis with block-wise pruning. Sci. Rep. 2023, 13, 16148. [Google Scholar] [CrossRef]
- Li, B.; Wang, M.; Huang, J.; Li, X. A new cost function for spatial image steganography. In Proceedings of the 2014 IEEE International Conference on Image Processing, ICIP 2014, Paris, France, 27–30 October 2014; pp. 4206–4210. [Google Scholar]
- Sedighi, V.; Cogranne, R.; Fridrich, J. Content-Adaptive Steganography by Minimizing Statistical Detectability. IEEE Trans. Inf. Forensics Secur. 2016, 11, 221–234. [Google Scholar] [CrossRef]
- Holub, V.; Fridrich, J.; Denemark, T. Universal distortion function for steganography in an arbitrary domain. EURASIP J. Inf. Secur. 2014, 2014, 1. [Google Scholar] [CrossRef]
- Holub, V.; Fridrich, J. Designing steganographic distortion using directional filters. In Proceedings of the WIFS 2012—Proceedings of the 2012 IEEE International Workshop on Information Forensics and Security, Costa Adeje, Spain, 2–5 December 2012; pp. 234–239. [Google Scholar]
- Bas, P.; Furon, T. Break Our Watermarking System. 2008. Available online: http://bows2.ec-lille.fr/ (accessed on 12 November 2020).
- Agarwal, S.; Kim, C.; Jung, K.-H. Steganalysis of Context-Aware Image Steganography Techniques Using Convolutional Neural Network. Appl. Sci. 2022, 12, 10793. [Google Scholar] [CrossRef]
- Arya, R.; Vimina, E.R. Local Triangular Coded Pattern: A Texture Descriptor for Image Classification. IETE J. Res. 2023, 69, 3267–3278. [Google Scholar] [CrossRef]
- Agarwal, S.; Jung, K.-H. Median filtering detection using optimal multi-direction threshold on higher-order difference pixels. Multimed. Tools Appl. 2023, 82, 30875–30893. [Google Scholar] [CrossRef]
- Liu, X.; Shi, T.; Zhou, G.; Liu, M.; Yin, Z.; Yin, L.; Zheng, W. Emotion classification for short texts: An improved multi-label method. Humanit. Soc. Sci. Commun. 2023, 10, 306. [Google Scholar] [CrossRef]
- Xiong, G.; Ping, X.; Zhang, T.; Hou, X. Image textural features for steganalysis of spatial domain steganography. J. Electron. Imaging 2012, 21, 033015. [Google Scholar] [CrossRef]
- Fridrich, J.; Kodovsky, J. Rich Models for Steganalysis of Digital Images. IEEE Trans. Inf. Forensics Secur. 2012, 7, 868–882. [Google Scholar] [CrossRef]
- Tang, W.; Li, H.; Luo, W.; Huang, J. Adaptive steganalysis against WOW embedding algorithm. In Proceedings of the 2nd ACM Workshop on Information Hiding and Multimedia Security—IH&MMSec’14, Salzburg, Austria, 11–13 June 2014; pp. 91–96. [Google Scholar]
- Denemark, T.; Sedighi, V.; Holub, V.; Cogranne, R.; Fridrich, J. Selection-channel-aware rich model for Steganalysis of digital images. In Proceedings of the 2014 IEEE International Workshop on Information Forensics and Security, WIFS 2014, Atlanta, GA, USA, 3–5 December 2014; pp. 48–53. [Google Scholar]
- Xu, X.; Dong, J.; Wang, W.; Tan, T. Local correlation pattern for image steganalysis. In Proceedings of the 2015 IEEE China Summit and International Conference on Signal and Information Processing (ChinaSIP), Chengdu, China, 12–15 July 2015; pp. 468–472. [Google Scholar]
- Li, F.; Zhang, X.; Cheng, H.; Yu, J. Digital image steganalysis based on local textural features and double dimensionality reduction. Secur. Commun. Netw. 2016, 9, 729–736. [Google Scholar] [CrossRef]
- Li, B.; Li, Z.; Zhou, S.; Tan, S.; Zhang, X. New Steganalytic Features for Spatial Image Steganography Based on Derivative Filters and Threshold LBP Operator. IEEE Trans. Inf. Forensics Secur. 2018, 13, 1242–1257. [Google Scholar] [CrossRef]
- Li, B.; Ming Wang, M.; Li, X.; Tan, S.; Huang, J. A Strategy of Clustering Modification Directions in Spatial Image Steganography. IEEE Trans. Inf. Forensics Secur. 2015, 10, 1905–1917. [Google Scholar] [CrossRef]
- Wang, P.; Liu, F.; Yang, C. Towards feature representation for steganalysis of spatial steganography. Signal Process. 2020, 169, 107422. [Google Scholar] [CrossRef]
- Ge, H.; Hu, D.; Xu, H.; Li, M.; Zheng, S. New Steganalytic Features for Spatial Image Steganography Based on Non-Negative Matrix Factorization. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: New York, NY, USA, 2020; Volume 12022 LNCS, pp. 337–351. [Google Scholar]
- Yang, S.; Li, Q.; Li, W.; Li, X.; Liu, A.-A. Dual-Level Representation Enhancement on Characteristic and Context for Image-Text Retrieval. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 8037–8050. [Google Scholar] [CrossRef]
- Wang, Y.; Su, Y.; Li, W.; Xiao, J.; Li, X.; Liu, A.-A. Dual-Path Rare Content Enhancement Network for Image and Text Matching. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 6144–6158. [Google Scholar] [CrossRef]
- Qian, Y.; Dong, J.; Wang, W.; Tan, T. Deep learning for steganalysis via convolutional neural networks. In Proceedings of the Media Watermarking, Security, and Forensics 2015, San Francisco, CA, USA, 4 March 2015; p. 94090J. [Google Scholar]
- Qian, Y.; Dong, J.; Wang, W.; Tan, T. Learning and transferring representations for image steganalysis using convolutional neural network. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; p. 7532860. [Google Scholar]
- Xu, G.; Wu, H.-Z.; Shi, Y.-Q. Structural Design of Convolutional Neural Networks for Steganalysis. IEEE Signal Process. Lett. 2016, 23, 708–712. [Google Scholar] [CrossRef]
- Wu, S.; Zhong, S.H.; Liu, Y. Steganalysis via deep residual network. In Proceedings of the International Conference on Parallel and Distributed Systems—ICPADS, Wuhan, China, 13–16 December 2016; pp. 1233–1236. [Google Scholar]
- Wu, S.; Zhong, S.; Liu, Y. Deep residual learning for image steganalysis. Multimed. Tools Appl. 2017, 77, 10437–10453. [Google Scholar] [CrossRef]
- Ye, J.; Ni, J.; Yi, Y. Deep Learning Hierarchical Representations for Image Steganalysis. IEEE Trans. Inf. Forensics Secur. 2017, 12, 2545–2557. [Google Scholar] [CrossRef]
- Boroumand, M.; Chen, M.; Fridrich, J. Deep Residual Network for Steganalysis of Digital Images. IEEE Trans. Inf. Forensics Secur. 2019, 14, 1181–1193. [Google Scholar] [CrossRef]
- Guo, L.; Ni, J.; Shi, Y. Uniform Embedding for Efficient JPEG Steganography. IEEE Trans. Inf. Forensics Secur. 2014, 9, 814–825. [Google Scholar] [CrossRef]
- Yedroudj, M.; Comby, F.; Chaumont, M. Yedrouj-Net: An efficient CNN for spatial steganalysis. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 2092–2096. [Google Scholar] [CrossRef]
- Wu, S.; Zhong, S.; Liu, Y. A Novel Convolutional Neural Network for Image Steganalysis with Shared Normalization. IEEE Trans. Multimed. 2020, 22, 256–270. [Google Scholar] [CrossRef]
- Zhang, R.; Zhu, F.; Liu, J.; Liu, G. Depth-Wise Separable Convolutions and Multi-Level Pooling for an Efficient Spatial CNN-Based Steganalysis. IEEE Trans. Inf. Forensics Secur. 2020, 15, 1138–1150. [Google Scholar] [CrossRef]
- Fu, T.; Chen, L.; Fu, Z.; Yu, K.; Wang, Y. CCNet: CNN model with channel attention and convolutional pooling mechanism for spatial image steganalysis. J. Vis. Commun. Image Represent. 2022, 88, 103633. [Google Scholar] [CrossRef]
- Xiang, Z.; Sang, J.; Zhang, Q.; Cai, B.; Xia, X.; Wu, W. A New Convolutional Neural Network-Based Steganalysis Method for Content-Adaptive Image Steganography in the Spatial Domain. IEEE Access 2020, 8, 47013–47020. [Google Scholar] [CrossRef]
- Wang, Z.; Chen, M.; Yang, Y.; Lei, M.; Dong, Z. Joint multi-domain feature learning for image steganalysis based on CNN. Eurasip J. Image Video Process. 2020, 2020, 28. [Google Scholar] [CrossRef]
- Atamna, M.; Tkachenko, I.; Miguet, S. Improving Generalization in Facial Manipulation Detection Using Image Noise Residuals and Temporal Features. In Proceedings of the 2023 IEEE International Conference on Image Processing (ICIP), Kuala Lumpur, Malaysia, 8–11 October 2023; pp. 3424–3428. [Google Scholar]
- Tan, S.; Chen, B.; Zeng, J.; Li, B.; Huang, J. Hybrid deep-learning framework for object-based forgery detection in video. Signal Process. Image Commun. 2022, 105, 116695. [Google Scholar] [CrossRef]
- Xavier Glorot, Y.B. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the 13th International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Xu, G. Deep convolutional neural network to detect J-UNIWARD. In Proceedings of the IH&MMSec 17: Proceedings of the 5th ACM Workshop on Information Hiding and Multimedia Security, June 2017. [Google Scholar]
- Bas, P.; Filler, T.; Pevný, T. “Break Our Steganographic System”: The Ins and Outs of Organizing BOSS. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2011; Volume 6958 LNCS, pp. 59–70. [Google Scholar]
- Zhang, R.; Dong, S.; Liu, J. Invisible steganography via generative adversarial networks. Multimed. Tools Appl. 2019, 78, 8559–8575. [Google Scholar] [CrossRef]
- Jebadurai, J.; Jebadurai, I.J.; Paulraj, G.J.L.; Samuel, N.E. Learning Based Resolution Enhancement of Digital Images. Int. J. Eng. Adv. Technol. 2019, 8, 3026–3030. [Google Scholar] [CrossRef]








| Layer/Payload (bpp) | HILL | Mi-POD | S-UNIWARD | WOW | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.2 | 0.3 | 0.4 | 0.2 | 0.3 | 0.4 | 0.2 | 0.3 | 0.4 | 0.2 | 0.3 | 0.4 | |
| ReLU | 58.32 | 62.95 | 67.34 | 61.19 | 69.53 | 71.60 | 63.60 | 72.81 | 77.77 | 69.64 | 76.69 | 79.14 |
| Leaky ReLU | 60.49 | 65.98 | 71.18 | 64.54 | 72.96 | 74.58 | 66.95 | 76.48 | 81.43 | 72.92 | 79.80 | 82.69 |
| Steganalysis Scheme/Payload (bpp) | HILL | Mi-POD | S-UNIWARD | WOW | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.2 | 0.3 | 0.4 | 0.2 | 0.3 | 0.4 | 0.2 | 0.3 | 0.4 | 0.2 | 0.3 | 0.4 | |
| Ye-Net | 52.85 | 58.68 | 62.98 | 57.81 | 62.97 | 66.04 | 59.89 | 67.76 | 72.64 | 68.44 | 73.86 | 78.44 |
| SRNet | 56.87 | 63.42 | 66.59 | 59.06 | 66.05 | 71.41 | 64.23 | 73.33 | 77.55 | 73.08 | 79.23 | 83.93 |
| Yedroudj-Net | 54.57 | 60.27 | 65.54 | 57.91 | 62.44 | 70.80 | 60.05 | 68.22 | 72.71 | 69.54 | 76.65 | 81.32 |
| Zhu-Net | 61.44 | 66.54 | 73.12 | 65.87 | 71.73 | 73.82 | 69.18 | 77.41 | 80.89 | 74.63 | 80.99 | 87.46 |
| Proposed Scheme | 62.26 | 69.69 | 74.74 | 67.53 | 73.10 | 76.18 | 70.90 | 79.08 | 82.01 | 77.36 | 82.28 | 88.13 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Agarwal, S.; Kim, H.; Jung, K.-H. High-Pass-Kernel-Driven Content-Adaptive Image Steganalysis Using Deep Learning. Mathematics 2023, 11, 4322. https://doi.org/10.3390/math11204322
Agarwal S, Kim H, Jung K-H. High-Pass-Kernel-Driven Content-Adaptive Image Steganalysis Using Deep Learning. Mathematics. 2023; 11(20):4322. https://doi.org/10.3390/math11204322
Chicago/Turabian StyleAgarwal, Saurabh, Hyenki Kim, and Ki-Hyun Jung. 2023. "High-Pass-Kernel-Driven Content-Adaptive Image Steganalysis Using Deep Learning" Mathematics 11, no. 20: 4322. https://doi.org/10.3390/math11204322