We constructed a modular simulation model that mimics the operation of a real allocation system.
4.3.2. Kidney-Transplant Components
All key components are registered to the simulation engine and have a process function that will be invoked at each step of the simulation.
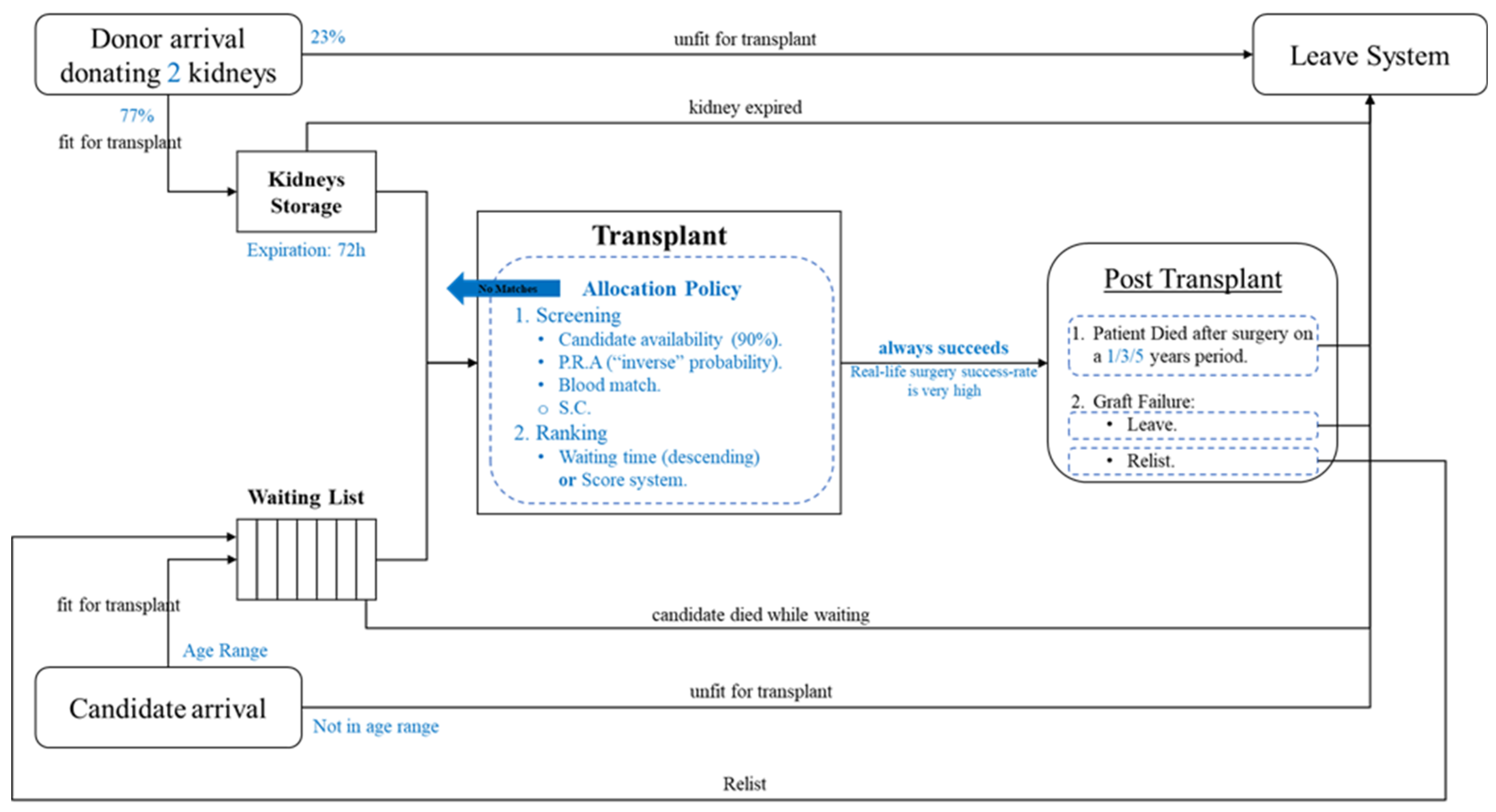
The candidates’ initialization component is based on the OPTN data report. We initialize a set of candidates before the simulation starts with distributed waiting times.
The candidate generation component is based on the OPTN data report. We set the candidates’ arrival times using an exponential distribution and generate synthetic data for each candidate, e.g., age, blood type, gender, etc. (
Appendix D).
The candidate aging component: each candidate arrives at the model at a specific time and age, and as the simulation advances, the age changes appropriately. If a candidate becomes too old for transplantation, s/he is removed from the system.
The waiting-list death component: in our model, we simulate a patient’s death on the waiting list. According to [
2], 6.8% died while waiting between 2016 and 2019. To simulate that, we set inter-arrival death time:
When the time comes and death occurs, we remove a random patient from the waiting list. In our model, we assume that all patients on the waiting list have an equal chance of dying, regardless of their attributes (age, health condition, etc.). The health condition, a crucial factor, is not considered in the simulation, as it is unknown to us.
The post-transplant component: over time, two events can occur after a kidney is transplanted into a candidate. (1) organic death (death of a patient with a functioning graft) leading to leaving the system or (2) organ failure, which can result in a re-list (putting the patient back on the waiting list) or in a decision to leave. The transplanted candidates have a checkup period of 1 year, and we simulate the events for expanded times (next year).
The donor generation component: this is based on the OPTN data report. We set the donors’ arrival times using an exponential distribution and generate synthetic data, e.g., blood type, antigens, gender, etc. For each donor, two kidneys are extracted, but only a portion is fit for transplant; in our simulation, only 77% of the kidneys are suitable for transplant.
The kidney expiration component: in our model, we simulate the shelf-life of an extracted kidney. Each kidney is available for 72 h after extraction (donor arrival time). When the kidney’s shelf-life passes, it is removed from the organ storage (leaving the system) and cannot be allocated anymore.
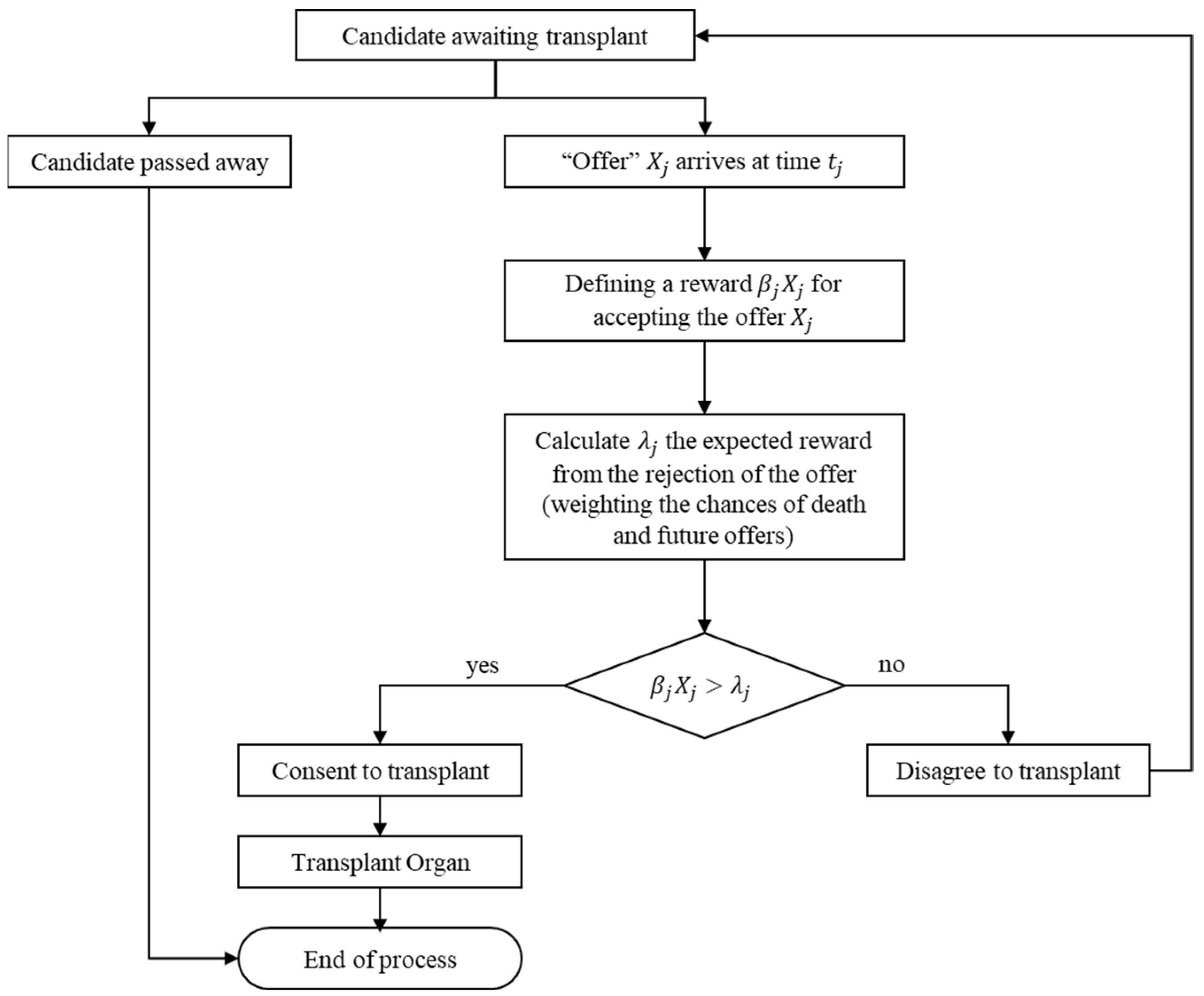
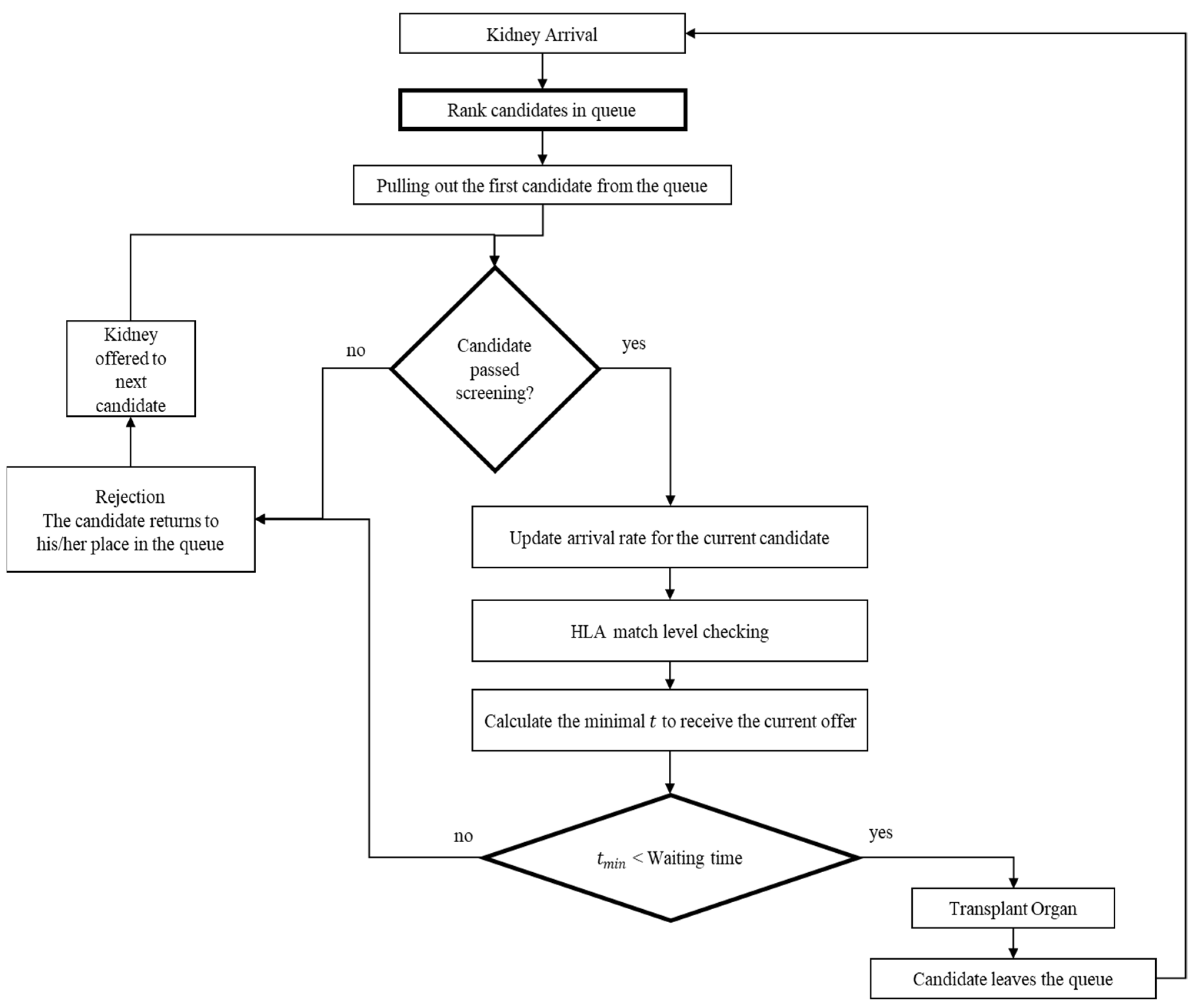
The organ allocation component: the waiting list is sorted by the patient’s arrival time in this model. According to EDY, the organ is offered to the first candidate on the waiting list. Then three actions are performed: in the first stage, the kidney blood type compatibility with the candidate is checked. The second step, called “crossmatch”, must be passed for the candidate to accept the kidney. The third step is the “candidate decision”. The candidates contemplate if they should accept the offer (kidney) and leave the system or wait for the next arrival. This decision is made using mathematical calculations that combine the “single-candidate algorithm” and EDY. If the kidney successfully goes through those three steps, the candidate receives the kidney and leaves the waiting list. If it does not, the next candidate on the list goes through the above steps. Finally, if none of the candidates decides to take the kidney before it passes its shelf-life, it is disposed of and logged in a file.
The statistics component: at the end of each step of the simulation (default: end of the day), we generate statistics for waiting times, waiting-list size, number of deaths, number of arrivals, etc. Additional data during the simulation is recorded using “recorders”, based on an observer design pattern for each component.
The metrics component: at the end of each simulation step (default: end of the day), we record the data needed to calculate metrics (for clinical efficiency and equity) at each segment.
For statistical analysis of the results, we divided the simulation into 20-time segments, so the calculation of each metric refers only to the specific time segment and not to the ones before it.
4.3.3. Further Assumptions
The lifetime distribution of kidneys is Gamma with shape parameters and the scale parameter . To simplify calculations, we assume , bearing in mind that the time unit is 2.5 years. μ is the rate of kidney offers for 2.5 years.
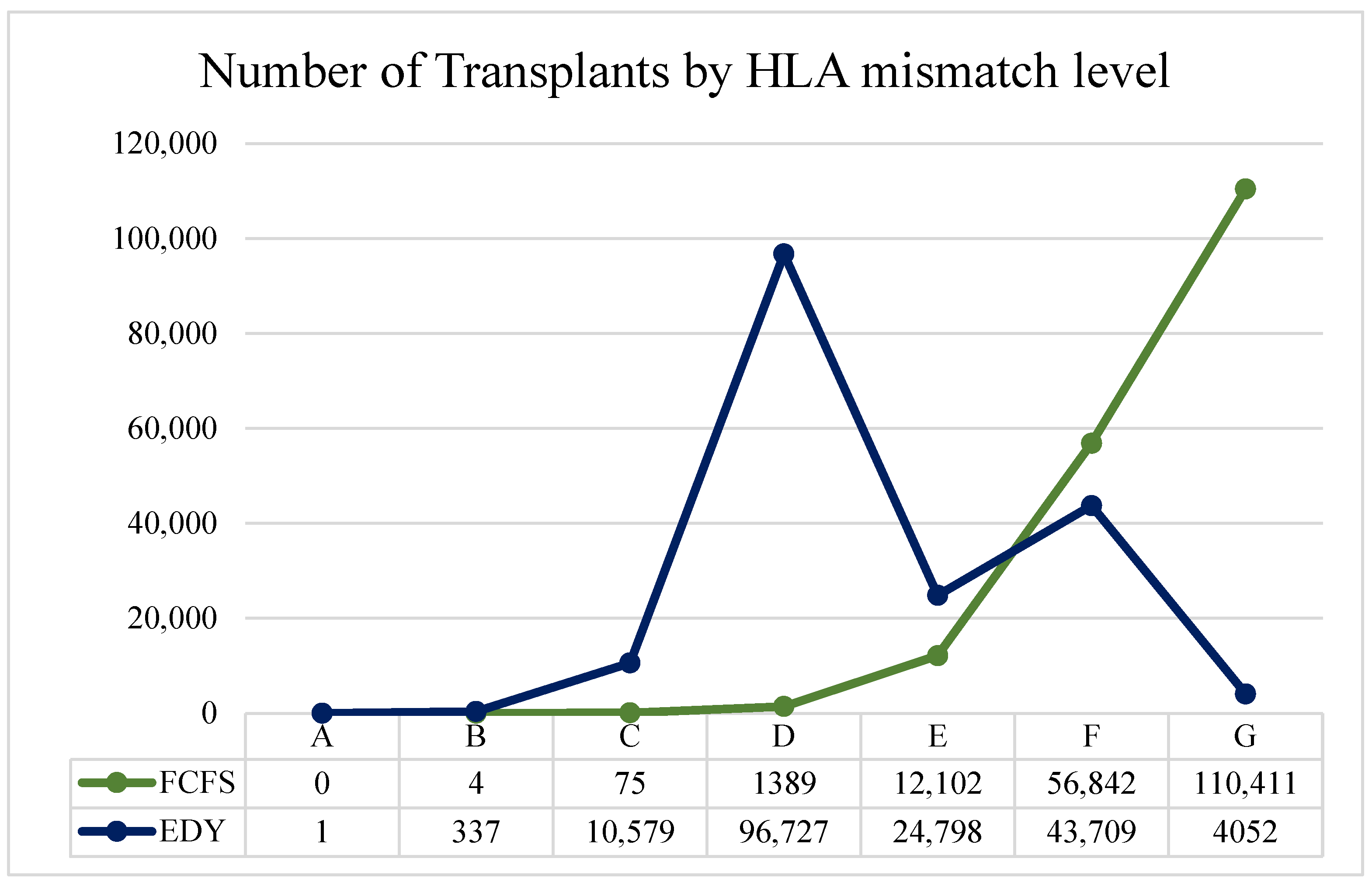
Each kidney arrival results in an A, B, C, D, E, F, or G Match, as in
Table 2.
Table 3 depicts the blood type distribution according to the OPTN website.
It is important to note that candidates unavailable when the kidney arrives are not considered. Furthermore, candidates, organs’ attributes, and arrival times are taken from OPTN’s past data. The PRA of the candidates does not change during the simulation. Matching the blood type is performed according to
Table 4.
When death is supposed to occur, a random candidate is chosen and removed from the waiting list. Additionally, rejection will not cause a candidate who underwent a kidney transplant to return to the waiting list.



{kind=link}
{kind=link}
{kind=link}
{kind=link}



