
Real-Time Video Smoke Detection Based on Deep Domain Adaptation for Injection Molding Machines

 ,
,
Abstract
:1. Introduction
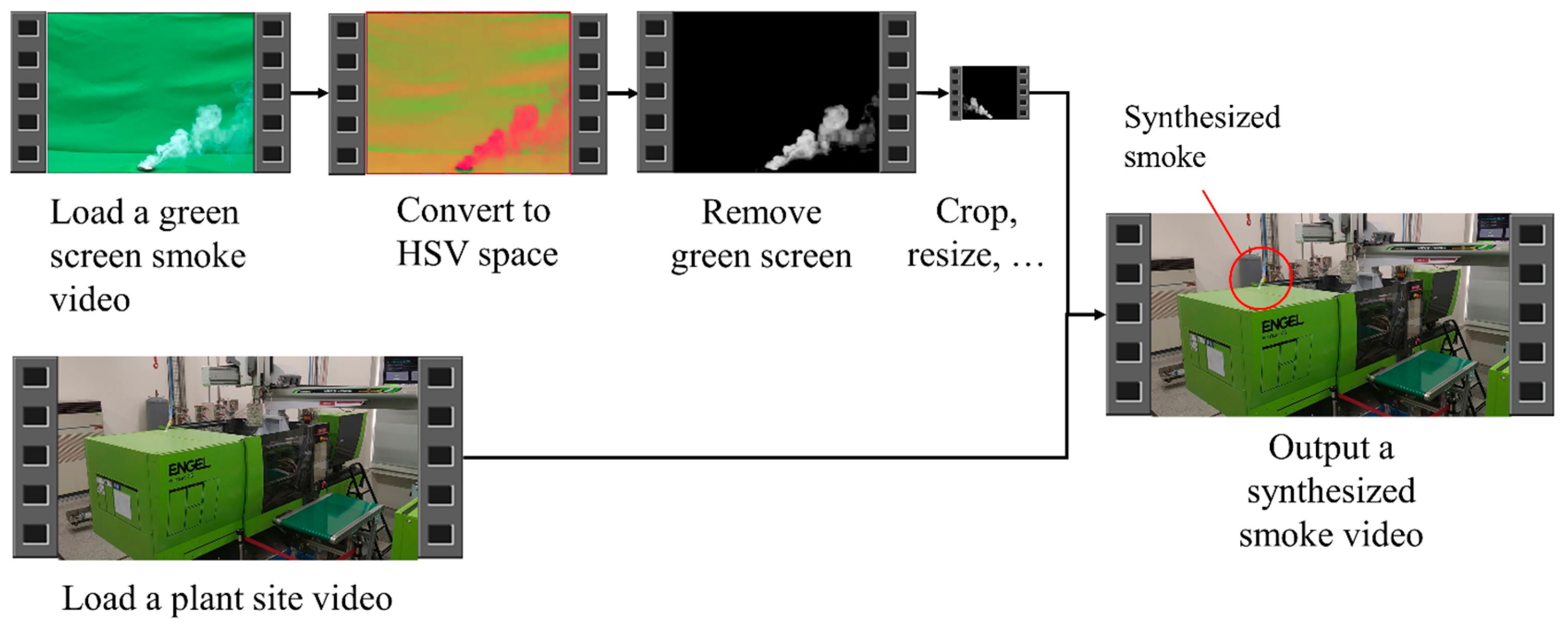
- Real smoke creation, extraction, and synthesis: The injection molding production line usually maintains a stable production status, so it is difficult to obtain real smoke images in practice. Repeated experiments have shown that artificial smoke, produced by burning “smoke cakes”, has the characteristics of low cost, low risk, and high similarity to real smoke. By producing artificial smoke against a green screen as a background, the DIP method is used to extract the smoke image and combine it with the background of the injection molding area. This creates an image of the smoke in the injection molding area, which is then used as training data for the smoke classification CNN algorithm.
- Smoke classification via CNN algorithm: We embedded a smoke classification CNN algorithm in visual fire alarms above the production line. By leveraging frame differences with DIP and motion detection, as well as using an attention mechanism, the CNN tracks moving object features, pinpointing smoke characteristics.
- Integration of CNN with DA: The injection molding production lines in the smart factories discussed in this research have similar features. Using the DA method means that the CNN algorithm does not need to be retrained for different injection molding lines. Applying the CNN algorithm to an injection molding line only requires the synthesis of smoke images with the scene of the injection molding production line to complete the auto-annotation and algorithm training steps. This saves the effort and time of re-labeling smoke images and retraining the algorithm.
2. Research Methods
2.1. Videos of Scene and Smoke Acquisition
2.2. Video Pre-Processing
2.3. Smoke Detection with CNN
2.4. Domain Adaptation
2.5. Model Evaluation Metrics
3. Experiment Results
3.1. Preprocessing and Features of Video Datasets
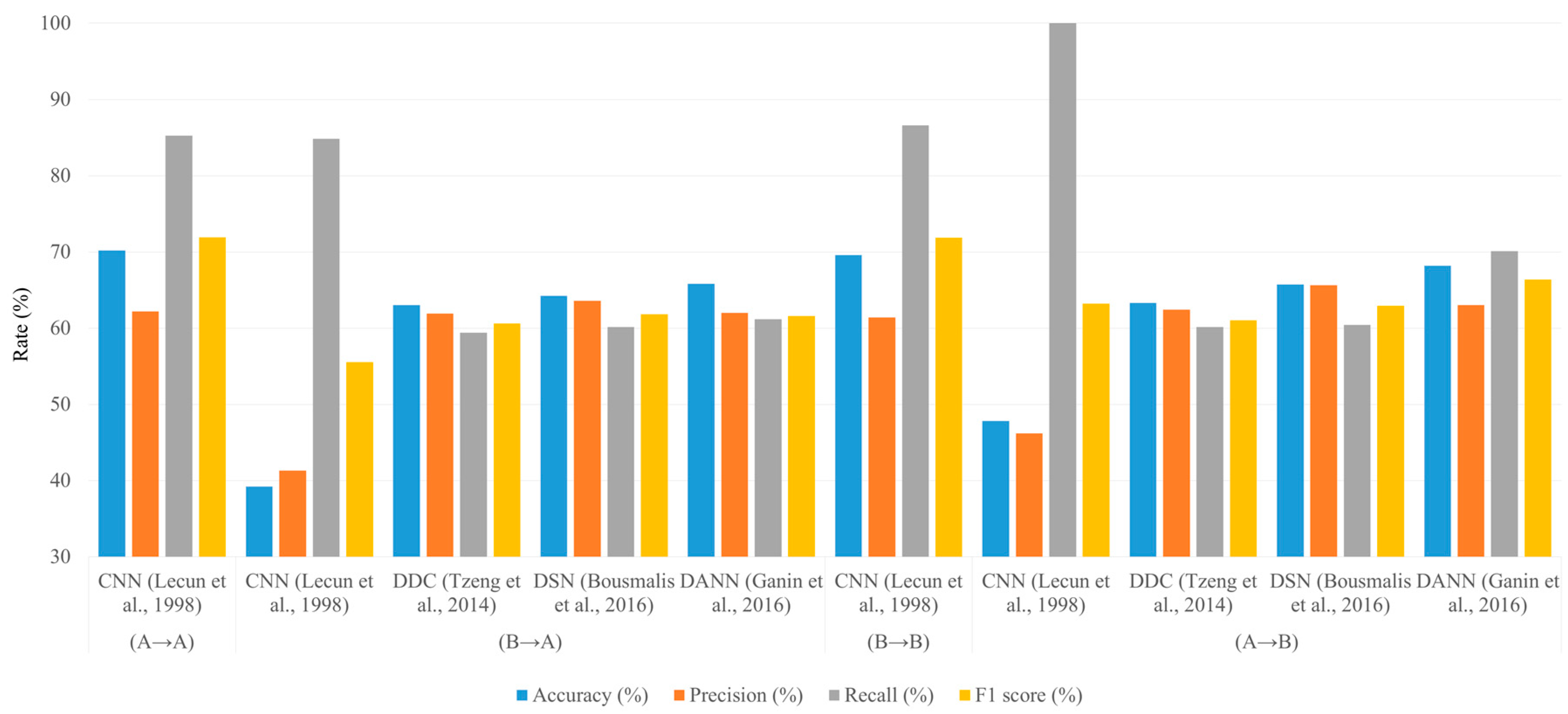
3.2. Model Spot Checking
3.3. Ablation Study
3.3.1. Design of Experiment (DOE)
- Motion detection: MOG is used to extract a moving object in the image, and its level is divided into default mode and custom parameter mode. The default mode of the MOG’s parameters are: 500 frames of background image, threshold of variation as 16, and dynamically adjusted learning rate; the custom mode of the MOG parameters reduces the number of background images to 100 due to interference of the noise of the light source, and it increases the threshold of variation to 25. In addition, it is necessary to have the MOG stop updating the background modeling as MOG detects enough moving pixels, i.e., the learning rate is set to 0 with consideration of the lower diffusion of smoke. Then, MOG will return to the dynamic adjustment until the abnormal state is resolved.
- Image sources: The residual mask obtained from the original video through moving object detection is an input image source for CNN. However, since the number of moving object pixels in an image is not so obvious compared to the background, the residual mask was further converted into a grayscale histogram, ignoring background in the grayscale histogram, such that CNN can learn the information of moving pixels more effectively. In this way, CNN can be more capable of expressing feature information as another input image source for CNN.
- Information fusion: The data set in this research is time-series data, and the multi-frame information fusion technology of the input image can make CNN evolve from only considering spatial information to considering spatial-temporal information. In the experiment, single-frame and three-frame are set as the level configuration of this factor.
- Confusion coefficient: DANN uses GRL technology to confuse the data distribution of the source and target domain when the error is back-propagated. In the initial stage of training, it is necessary to use iteration for the domain classifier such that the domain classifier is not able to determine the data from the domain sources. Then, the domain adaptation is achieved. In the experiment, the confusion coefficient is 0.001 and 0.01 as the level configuration, respectively.
- Optimizer: The choice of optimizer is closely related to the updating of model weights. The default optimizer of DANN for weight learning is SGD. In the experiment, Adam is also employed as an alternative optimizer for weight learning so that the optimizer would further consider gradient speed adjustment, learning rate adjustment, and parameter deviation correction in the analysis. This optimizer makes the updating process of the model weight more stable.
3.3.2. Early Stopping Mechanism
3.3.3. Reconfirm Mechanism
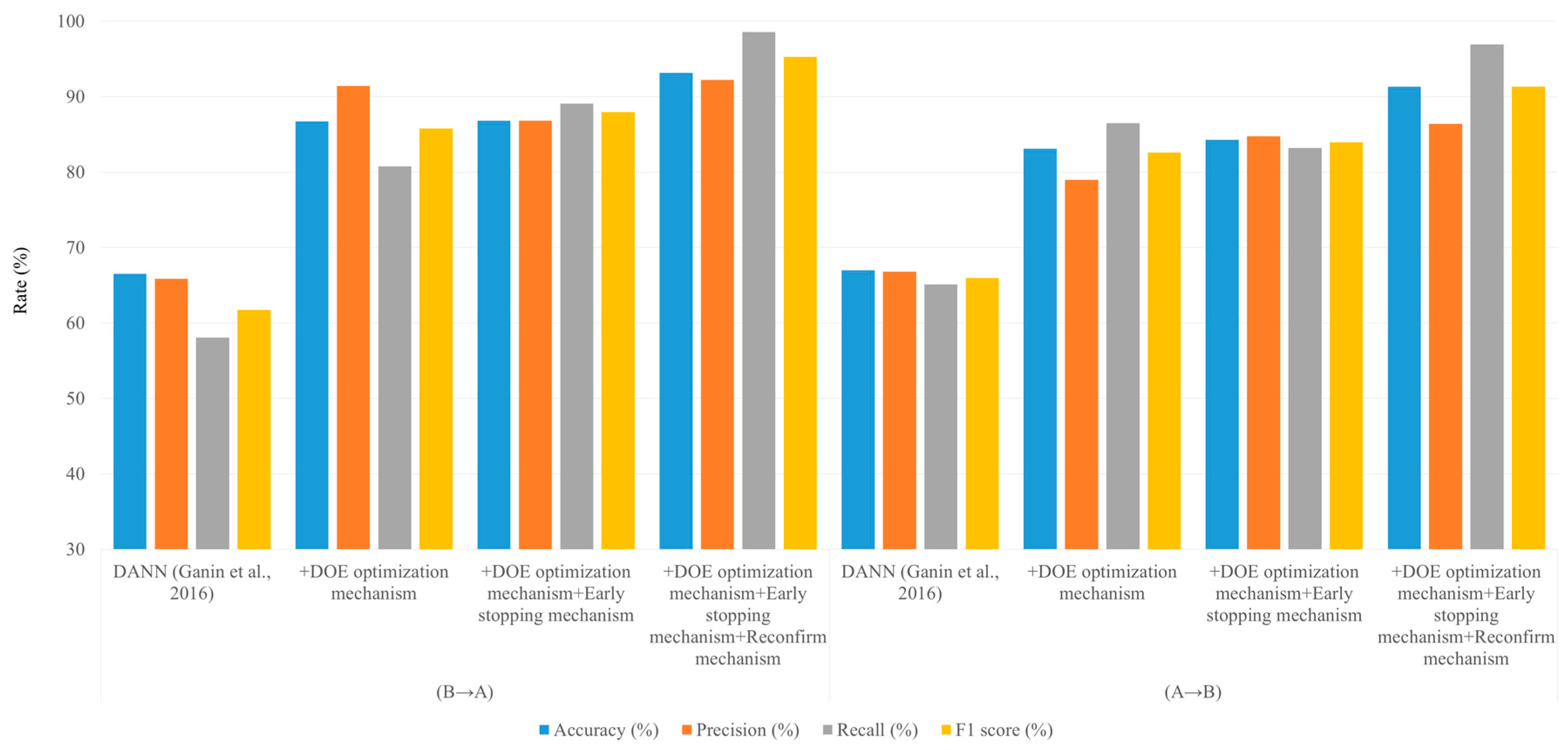
3.3.4. Results of the Ablation Experiment
3.4. Feature Distributions of DANN
3.5. Demonstration of Model Inference
4. Conclusions
- Domain adaptation of smoke: The work of two injection molding machines adapting to each other is realized by using DANN network. There is no need of labeling for target domain data, so the model possesses the characteristics of automatic labeling, two domain knowledge, and the function of no retraining for the target domain. The model can be used as pre-trained weights for transfer learning, in other injection molding domains, to save manpower and time.
- Hyper-parameter DOE optimization experiment: The best combination of hyper-parameters is found using custom MOG parameter, three-frame grayscale histogram fusion, a confusion coefficient setting of 0.001, and optimizer setting of Adam. The average classification accuracy rate of the two scenarios can reach 84.90%, compared to that of 65% for the original size image as input.
- The effects of the early stopping mechanism and the reconfirm mechanism: The training process and prediction of DANN is stabilized with the combination of these two mechanisms. More importantly, these two mechanisms help to increase the classification accuracy rate to more than 90%.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Mutar, A.F.; Dway, D.H.G. Smoke detection based on image processing by using grey and transparency features. J. Theor. Appl. Inf. Technol. 2018, 96, 6995–7006. [Google Scholar]
- Wu, X.; Lu, X.; Leung, H. A Video Based Fire Smoke Detection Using Robust AdaBoost. Sensors 2018, 18, 3780. [Google Scholar] [CrossRef] [PubMed]
- Prema, C.E.; Suresh, S. Local binary pattern based hybrid texture descriptors for the classification of smoke images. Int. J. Eng. Res. Technol. 2019, 7, 1–7. [Google Scholar]
- Wang, H.; Zhang, Y.; Fan, X. Rapid Early Fire Smoke Detection System Using Slope Fitting in Video Image Histogram. Fire Technol. 2020, 56, 695–714. [Google Scholar] [CrossRef]
- Gagliardi, A.; Saponara, S. AdViSED: Advanced Video SmokE Detection for Real-Time Measurements in Antifire Indoor and Outdoor Systems. Energies 2020, 13, 2098. [Google Scholar] [CrossRef]
- Shees, A.; Ansari, M.S.; Varshney, A.; Asghar, M.N.; Kanwal, N. FireNet-v2: Improved lightweight fire detection model for real-time IoT applications. Procedia Comput. Sci. 2023, 218, 2233–2242. [Google Scholar] [CrossRef]
- Cao, Y.; Tang, Q.; Lu, X. STCNet: Spatiotemporal cross network for industrial smoke detection. Multimed. Tools Appl. 2022, 81, 10261–10277. [Google Scholar] [CrossRef]
- Wu, Y.; Chen, M.; Wo, Y.; Han, G. Video smoke detection base on dense optical flow and convolutional neural network. Multimed. Tools Appl. 2020, 80, 35887–35901. [Google Scholar] [CrossRef]
- Almeida, J.S.; Huang, C.; Nogueira, F.G.; Bhatia, S.; de Albuquerque, V.H.C. EdgeFireSmoke: A Novel Lightweight CNN Model for Real-Time Video Fire–Smoke Detection. IEEE Trans. Ind. Inform. 2022, 18, 7889–7898. [Google Scholar] [CrossRef]
- Zhang, Q.-X.; Lin, G.-H.; Zhang, Y.-M.; Xu, G.; Wang, J.-J. Wildland Forest Fire Smoke Detection Based on Faster R-CNN using Synthetic Smoke Images. Procedia Eng. 2018, 211, 441–444. [Google Scholar] [CrossRef]
- Saponara, S.; Elhanashi, A.; Gagliardi, A. Real-time video fire/smoke detection based on CNN in antifire surveillance systems. J. Real-Time Image Process. 2020, 18, 889–900. [Google Scholar] [CrossRef]
- Huo, Y.; Zhang, Q.; Jia, Y.; Liu, D.; Guan, J.; Lin, G.; Zhang, Y. A Deep Separable Convolutional Neural Network for Multiscale Image-Based Smoke Detection. Fire Technol. 2022, 58, 1445–1468. [Google Scholar] [CrossRef]
- Chen, X.; Xue, Y.; Zhu, Y.; Ma, R. A novel smoke detection algorithm based on improved mixed Gaussian and YOLOv5 for textile workshop environments. IET Image Process. 2023, 17, 1991–2004. [Google Scholar] [CrossRef]
- Wang, Z.; Wu, L.; Li, T.; Shi, P. A Smoke Detection Model Based on Improved YOLOv5. Mathematics 2022, 10, 1190. [Google Scholar] [CrossRef]
- Yuan, F.; Zhang, L.; Xia, X.; Wan, B.; Huang, Q.; Li, X. Deep smoke segmentation. Neurocomputing 2019, 357, 248–260. [Google Scholar] [CrossRef]
- Gupta, T.; Liu, H.; Bhanu, B. Early wildfire smoke detection in videos. In Proceedings of the 2020 25th International Conference on Pattern Recognition, Milan, Italy, 10–15 January 2021; pp. 8523–8530. [Google Scholar]
- Zhou, F.; Wen, G.; Ma, Y.; Wang, Y.; Ma, Y.; Wang, G.; Pan, H.; Wang, K. Multilevel feature cooperative alignment and fusion for unsupervised domain adaptation smoke detection. Front. Phys. 2023, 11, 1136021. [Google Scholar] [CrossRef]
- Pan, S.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Xu, G.; Zhang, Y.; Zhang, Q.; Lin, G.; Wang, J. Deep domain adaptation based video smoke detection using synthetic smoke images. Fire Saf. J. 2017, 93, 53–59. [Google Scholar] [CrossRef]
- Xu, G.; Zhang, Q.; Liu, D.; Lin, G.; Wang, J.; Zhang, Y. Adversarial Adaptation From Synthesis to Reality in Fast Detector for Smoke Detection. IEEE Access 2019, 7, 29471–29483. [Google Scholar] [CrossRef]
- Mao, J.; Zheng, C.; Yin, J.; Tian, Y.; Cui, W. Wildfire Smoke Classification Based on Synthetic Images and Pixel- and Feature-Level Domain Adaptation. Sensors 2021, 21, 7785. [Google Scholar] [CrossRef]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain-Adversarial Training of Neural Networks. J. Mach. Learn. Res. 2016, 17, 1–35. [Google Scholar]
- Tzeng, E.; Hoffman, J.; Zhang, N.; Saenko, K.; Darrell, T. Deep domain confusion: Maximizing for domain invariance. arXiv 2014, arXiv:1412.3474. [Google Scholar]
- Bousmalis, K.; Trigeorgis, G.; Silberman, N.; Krishnan, D.; Erhan, D. Domain separation networks. Adv. Neural Inf. Process. Syst. 2016, 29, 343–351. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Factors | Motion Detection | Image Sources | Information Fusion | Confusion Coefficient | Optimizer |
|---|---|---|---|---|---|
| Level 1 | Default | Residual mask | Single-frame | 0.001 | SGD |
| Level 2 | Custom | Grayscale histogram | Multi-frame | 0.01 | Adam |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, S.-H.; Jang, J.-H.; Youh, M.-J.; Chou, Y.-T.; Kang, C.-H.; Wu, C.-Y.; Chen, C.-M.; Lin, J.-S.; Lin, J.-K.; Liu, K.F.-R. Real-Time Video Smoke Detection Based on Deep Domain Adaptation for Injection Molding Machines. Mathematics 2023, 11, 3728. https://doi.org/10.3390/math11173728
Chen S-H, Jang J-H, Youh M-J, Chou Y-T, Kang C-H, Wu C-Y, Chen C-M, Lin J-S, Lin J-K, Liu KF-R. Real-Time Video Smoke Detection Based on Deep Domain Adaptation for Injection Molding Machines. Mathematics. 2023; 11(17):3728. https://doi.org/10.3390/math11173728
Chicago/Turabian StyleChen, Ssu-Han, Jer-Huan Jang, Meng-Jey Youh, Yen-Ting Chou, Chih-Hsiang Kang, Chang-Yen Wu, Chih-Ming Chen, Jiun-Shiung Lin, Jin-Kwan Lin, and Kevin Fong-Rey Liu. 2023. "Real-Time Video Smoke Detection Based on Deep Domain Adaptation for Injection Molding Machines" Mathematics 11, no. 17: 3728. https://doi.org/10.3390/math11173728