
Hybrid GPU–CPU Efficient Implementation of a Parallel Numerical Algorithm for Solving the Cauchy Problem for a Nonlinear Differential Riccati Equation of Fractional Variable Order



Abstract
:1. Introduction
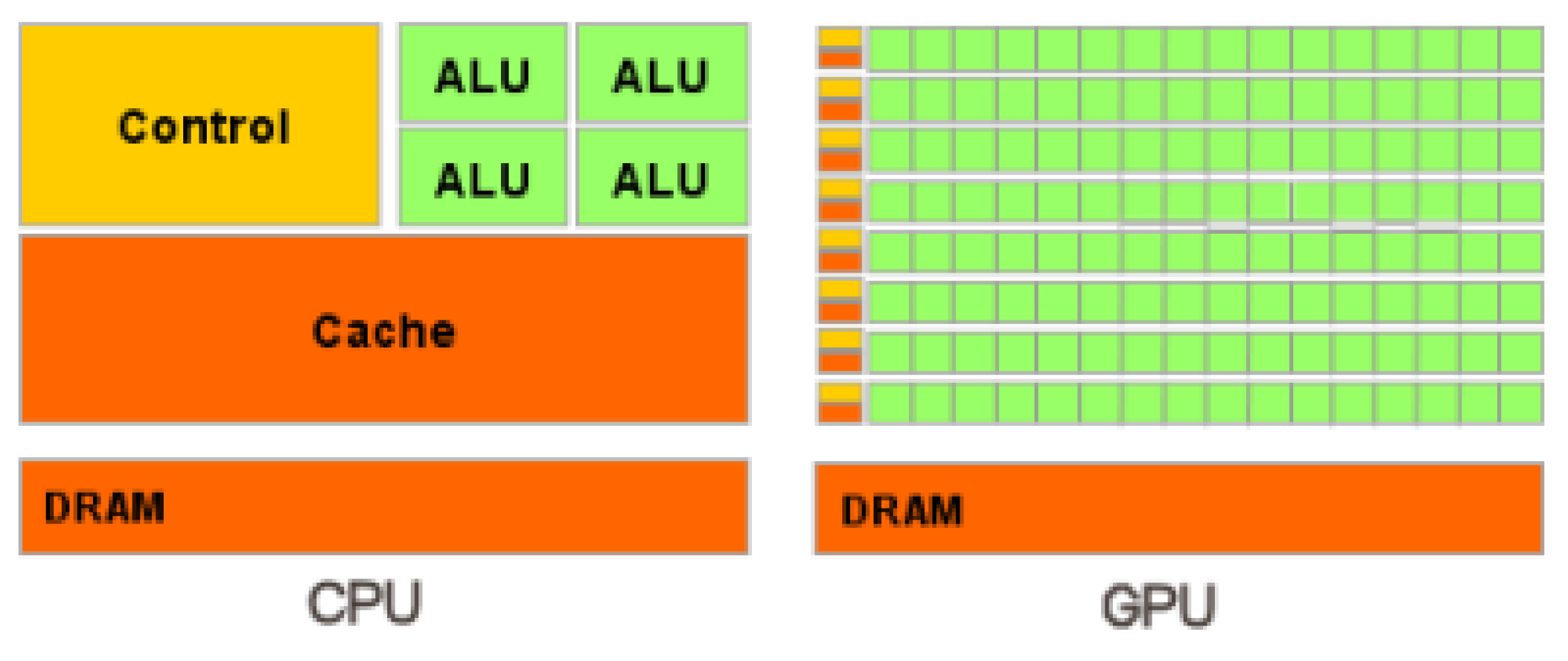
2. About Organization of Parallel Computations on CPU and GPU Nodes of a Computing System
3. Mathematical Problem Statement
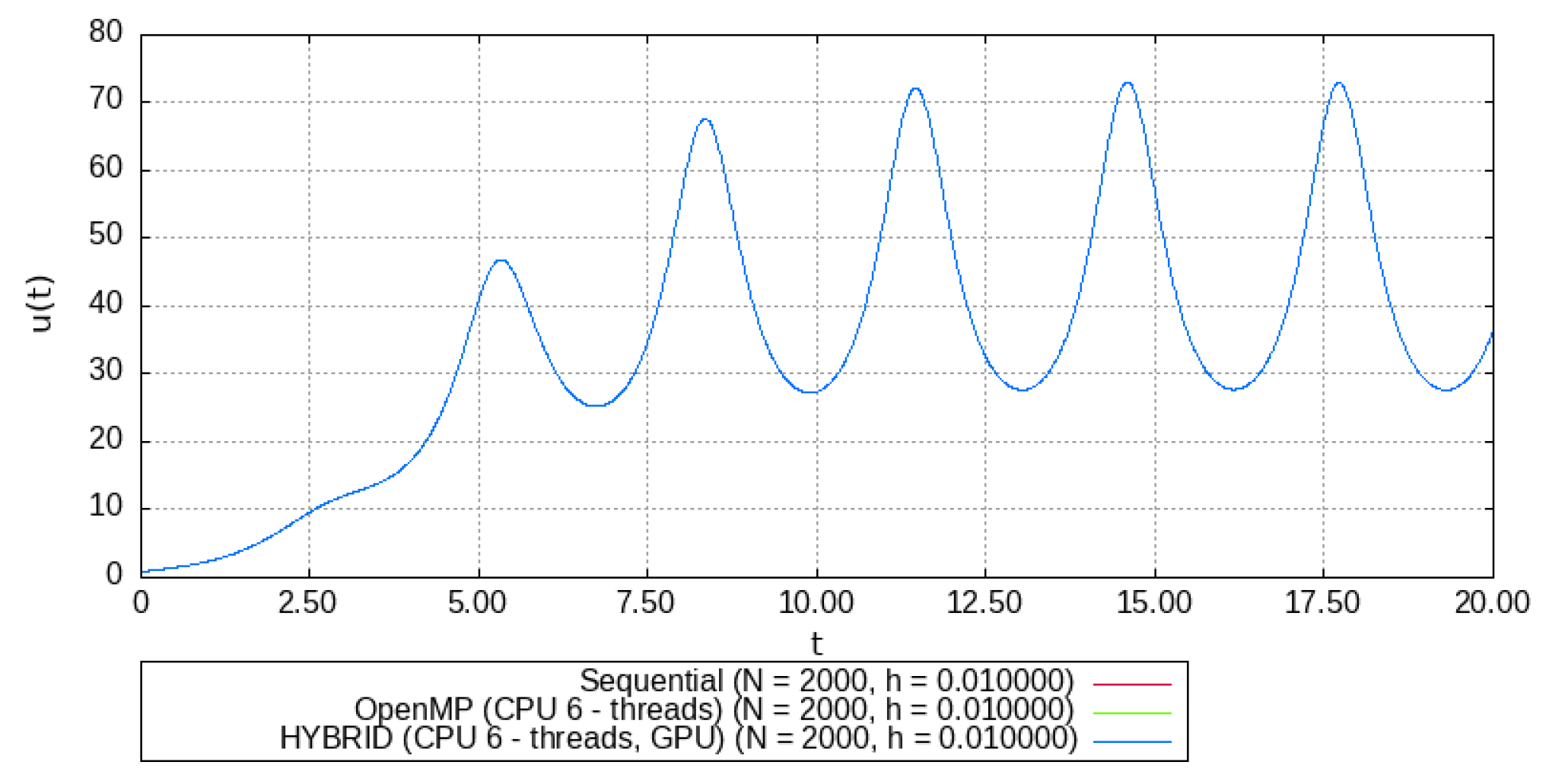
4. Software Implementation of the Hybrid EFDS Algorithm

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| typedef struct input { int T; // time of numerical experement. int N; // number cells of grid (lattice). float u_0; // start point, for Cauchy poblem. char type_method[CHAR_LEN]; //= EFDS \ IFDS char type_algorithm[CHAR_LEN]; //= sequential \ parallel(OpenMP) // parallel(HYBRID) int num_threads_CPU; // num threads parallel (OpenMP) int num_threads_GPU; // num threads parallel (CUDA), char num_GPU_using[CHAR_LEN]; // num GPU device : best GPU char current_method[CHAR_LEN]; //= EFDS \ IFDS } INP_PAR; |
| typedef struct output { int T; int N; float u_0; char type_method[CHAR_LEN]; char type_algorithm[CHAR_LEN]; int num_threads_CPU; int num_threads_GPU; char num_GPU_using[CHAR_LEN]; float h; // step of discretisation. float ∗res; // result calculation. float mem_aloc_CPU; // value memory was allocated on CPU (RAM). float mem_aloc_GPU; // value memory was allocated for GPU (DRAM). } OUT_RES; |
| typedef struct mesure_all_times_calc { float time_calc_res_m_3; struct timeval tv1, tv2, dtv; char location[CHAR_LEN]; // where fields MATC object was filled } MATC; MATC measure_PARA; // FOR mesure time working Parallel part code MATC measure_SEQU; // FOR mesure time working Sequenitial part code MATC measure_MAIN; // FOR mesure time working All part’s code |
| MATC tic( MATC measure ) { gettimeofday( &measure.tv1, NULL ); // most accuracy method ! return measure; } |
| MATC toc( MATC measure ) { gettimeofday( &measure.tv2, NULL ); measure.dtv.tv_sec = measure.tv2.tv_sec - measure.tv1.tv_sec; measure.dtv.tv_usec = measure.tv2.tv_usec - measure.tv1.tv_usec; if( measure.dtv.tv_usec < 0 ) { measure.dtv.tv_sec--; measure.dtv.tv_usec += 1000000; } float elapsed_dtv = measure.dtv.tv_sec ∗ 1000 + measure.dtv.tv_usec / 1000; measure.time_calc_res_m_3 = (double)elapsed_dtv / 1000; return measure; } |
| #define CHAR_LEN 256 // default num char elements ∗char[] massive #define EPSILON 1e-2 // numerical methods accuracy #define ZERO 0 #define def_min(a,b) (a<b?a:b) #define def_max(a,b) (a>b?a:b) |
4.1. Code for Parallel EFDS Implementation
| OUT_RES EFDS_parallel_HYBRID( INP_PAR input ) { memcpy( input.current_method, (char ∗)"EFDS", CHAR_LEN ); |
| int T = input.T; // time of numerical experement. int N = input.N; // number cells of grid (lattice). float h = (float)T / (float)N; // step of discretisation. float u_0 = input.u_0; // start point for Cauchy poblem. OUT_RES output; int N_p1 = N + 1; float a[ N ]; // massive value ’a(t)’. float b[ N ]; // massive value ’b(t)’. float c[ N ]; // massive value ’c(t)’. float alpha[ N_p1 ]; // massive value ’alpha(t)’ float A[ N ]; // 1-st Weight coefficient ’A’ float w_1[ N ]; float u[ N_p1 ]; // solve. ( + 1 because u[0] include) float summ_diff_u; float ∗w; w = (float∗) malloc( (N ∗ N) ∗ sizeof(float) ); float mem_aloc_CPU = sizeof u + sizeof a + sizeof b + sizeof c + sizeof alpha + sizeof A + sizeof w_1; mem_aloc_CPU += (( (float)N ∗ (float)N ) ∗ 4); // sizeof w |
| float ∗dev_a; cudaMalloc( (void∗∗)&dev_a, N ∗ sizeof(float) ); float ∗dev_b; cudaMalloc( (void∗∗)&dev_b, N ∗ sizeof(float) ); float ∗dev_c; cudaMalloc( (void∗∗)&dev_c, N ∗ sizeof(float) ); float ∗dev_alpha; cudaMalloc( (void∗∗)&dev_alpha, N_p1 ∗ sizeof(float) ); float ∗dev_A; cudaMalloc( (void∗∗)&dev_A, N ∗ sizeof(float) ); float ∗dev_w; cudaMalloc( (void∗∗)&dev_w, (N ∗ N) ∗ sizeof(float) ); float ∗dev_w_1; cudaMalloc( (void∗∗)&dev_w_1, N ∗ sizeof(float) ); float mem_aloc_GPU = sizeof a + sizeof b + sizeof c+ sizeof alpha + sizeof A + sizeof w_1; mem_aloc_GPU += (( (float)N ∗ (float)N ) ∗ 4);// sizeof w |
| // START mesure time working : ( only Parallel code ) measure_PARA = tic( measure_PARA ); // START mesure time working : ( All numerical method ) measure_MAIN = measure_PARA; |
| // Initialization calculation grid : CUDA , OpenMP printf( "\n ---- Initialize calculation grid ----\n" ); // set STATIC num Thread printf( "\n OpenMP : " ); omp_set_num_threads( input.num_threads_CPU ); #pragma omp parallel printf( "\n omp_get_num_threads() = %d", omp_get_num_threads() ); // 1-D grid PAG pg; pg = gpu_calc_param_grid( (char ∗)"1D", N, 1 ); dim3 threads( pg.thread_each_dim_block ); dim3 blocks( pg.block_each_dim_grid ); // 2-D grid PAG pg_2 = gpu_calc_param_grid( (char ∗)"2D", N, 1 ); dim3 threads_2( pg_2.thread_each_dim_block, pg_2.thread_each_dim_block ); dim3 blocks_2( pg_2.block_each_dim_grid, pg_2.block_each_dim_grid ); printf( "\n ---- grid done. ----\n\n" ); |
| printf( " START : CUDA : kernel_EFDS_1d_coeff : " ); kernel_EFDS_1d_coeff<<< blocks, threads >>>( T, N, h, dev_a, dev_b, dev_c, dev_alpha, dev_A ); // copy the array back from the GPU to the CPU cudaMemcpy( a, dev_a, N ∗ sizeof(float), cudaMemcpyDeviceToHost ); cudaMemcpy( b, dev_b, N ∗ sizeof(float), cudaMemcpyDeviceToHost ); cudaMemcpy( c, dev_c, N ∗ sizeof(float), cudaMemcpyDeviceToHost ); cudaMemcpy( alpha, dev_alpha, N_p1 ∗ sizeof(float), cudaMemcpyDeviceToHost ); cudaMemcpy( A, dev_A, N ∗ sizeof(float), cudaMemcpyDeviceToHost ); // free the memory allocated on the GPU cudaFree( dev_a ); cudaFree( dev_b ); cudaFree( dev_c ); cudaFree( dev_A ); printf( " \ldots sucsessfull END \n" ); |
| printf( "\n START : CUDA : kernel_EFDS_2d_w : " ); kernel_EFDS_2d_w<<< blocks_2, threads_2 >>>( N, dev_alpha, dev_w ); // copy the array back from the GPU to the CPU cudaMemcpy( w, dev_w, (N ∗ N) ∗ sizeof(float), cudaMemcpyDeviceToHost ); // free the memory allocated on the GPU cudaFree( dev_w ); printf( " \ldots sucsessfull END \n" ); |
| // END mesure time working : ( only Parallel code ) measure_PARA = toc( measure_PARA ); memcpy( measure_PARA.location, (char ∗)"{ EFDS _parallel CUDA_ block(s) }", CHAR_LEN ); |
| printf( "\n START : OpenMP : (threads - %d) ", input.num_threads_CPU); #pragma omp parallel shared( w_1 ) { #pragma omp for schedule( static ) nowait for( int i = 0; i <= N - 1; ++i ) w_1[i] = 0.0; } #pragma omp parallel reduction ( +: w_1 ) { // special value ’w’ for (j = 1) and i = 0 .. N. #pragma omp for schedule( static ) nowait for( int i = 0; i <= N - 1; ++i ) w_1[i] += pow( 2, 1 - alpha[i + 1] ) - pow( 1, 1 - alpha[i + 1] ); } printf( " \ldots sucsessfull END \n" ); |
| // START mesure time working : ( Sequential part code ) measure_SEQU = tic( measure_SEQU ); printf( "\n START : Sequential : "); u[0] = u_0; u[1] = ( ( A[0] ∗ (1 - w_1[0]) + b[0] ) ∗ u[0] - a[0] ∗ pow( u[0], 2 ) + c[0] ) / A[0]; u[2] = ( ( A[1] ∗ (1 - w_1[1]) + b[1] ) ∗ u[1] + A[1] ∗ w_1[1] ∗ u[0] - a[1] ∗ pow( u[1], 2 ) + c[1] ) / A[1]; for( int i = 2; i <= N - 1; ++i ) { summ_diff_u = 0; for( int j = 2; i >= j; ++j ) summ_diff_u += w[i∗N + j] ∗ (u[i - j + 1] - u[i - j]); u[i+1] = ( ( A[i] ∗ (1 - w_1[i]) + b[i] ) ∗ u[i] + A[i] ∗ w_1[i] ∗ u[i-1] - ( A[i] ∗ summ_diff_u ) - a[i] ∗ pow( u[i], 2 ) + c[i] ) / A[i]; } printf( " \ldots sucsessfull END \n" ); |
| // END mesure time working ( Sequential part code ) measure_SEQU = toc( measure_SEQU ); memcpy( measure_SEQU.location, (char ∗)"{ EFDS _sequential_ block }", CHAR_LEN ); // END mesure time working : ( All numerical method ) measure_MAIN = toc( measure_MAIN ); memcpy( measure_MAIN.location , (char ∗)"{ EFDS _all_ algorihm }", CHAR_LEN ); |
| criterion_stability( (char ∗)"EFDS", T, N, h, a, b, c, alpha ); printf( "\n End calc %s. \n", input.current_method ); |
| memcpy( output.type_method, input.type_method, CHAR_LEN ); memcpy( output.type_algorithm, input.type_algorithm, CHAR_LEN ); output.num_threads_CPU = input.num_threads_CPU; output.num_threads_GPU = input.num_threads_GPU; output.mem_aloc_CPU = mem_aloc_CPU; output.mem_aloc_GPU = mem_aloc_GPU; output.T = T; output.N = N; output.u_0 = u[0]; output.h = h; output.res = (float∗) malloc( N_p1 ∗ sizeof(float) ); for( int i = 0; i <= N ; i++ ) output.res[i] = u[i]; return output; } |
4.2. Used GPU Functions
| --global-- void kernel_EFDS_1d_coeff( int T, int N, float h, float ∗a, float ∗b, float ∗c, float ∗alpha, float ∗A ) { int i = threadIdx.x + blockIdx.x ∗ blockDim.x; if( i <= N ) { alpha[i] = 0.9 - (0.1 ∗ (i ∗ h)) / (float)T; a[i] = pow(cos((i) ∗ h),2) / (float)T; b[i] = 1.0 - (0.1 ∗ (i ∗ h)) / (float)T; c[i] = pow(sin(i ∗ h),2) / (float)T; } --syncthreads(); // synchronize threads in this block if( i <= N - 1 ) { A[i] = ( pow( h, - alpha[i + 1] ) ) / ( exp( lgamma( 2 - alpha[i + 1] ) ) ); i += blockDim.x ∗ gridDim.x; } } |
| --global-- void kernel_EFDS_2d_w( int N, float ∗alpha, float ∗w ) { int x = threadIdx.x + blockIdx.x ∗ blockDim.x; int y = threadIdx.y + blockIdx.y ∗ blockDim.y; int i = y; int j = x; int lin_r = i∗(N) + j; --syncthreads(); // synchronize threads in this block if( i <= N - 1 ) { if( j <= i ) { w[lin_r] = pow( j + 1, 1 - alpha[i + 1] ) - pow( j, 1 - alpha[i + 1] ); } } y += blockDim.y ∗ gridDim.y; x += blockDim.x ∗ gridDim.x; } |
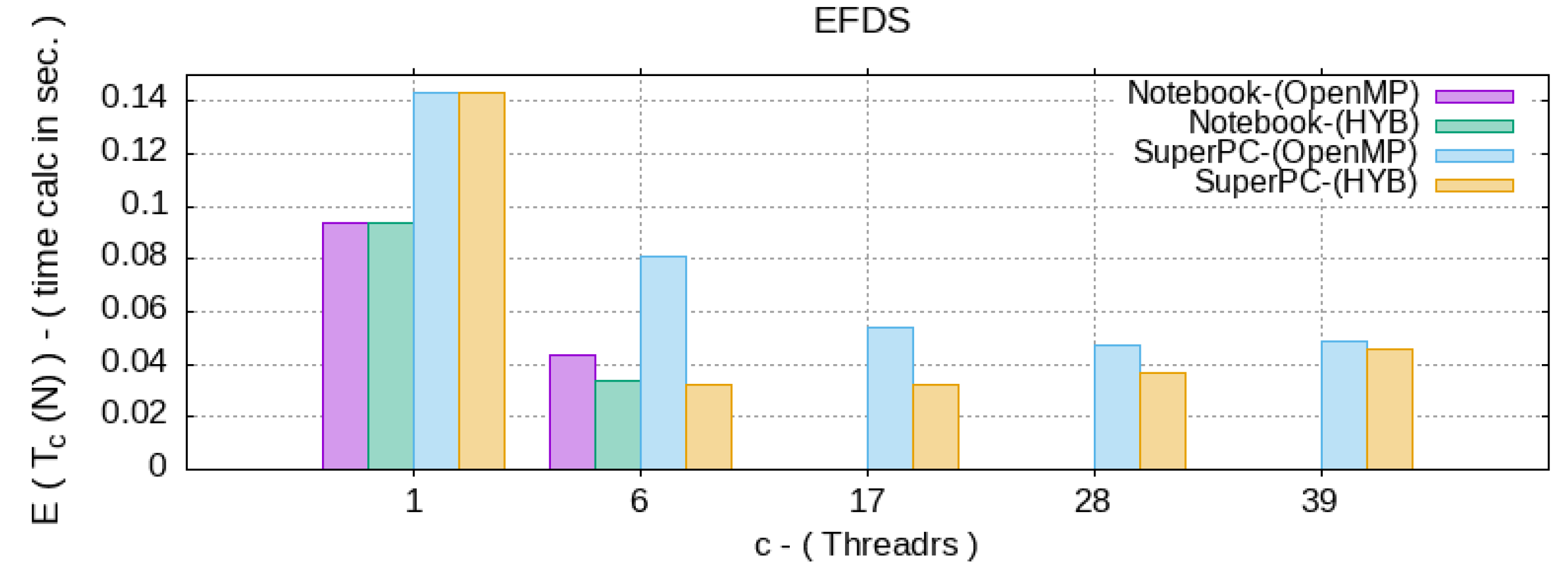
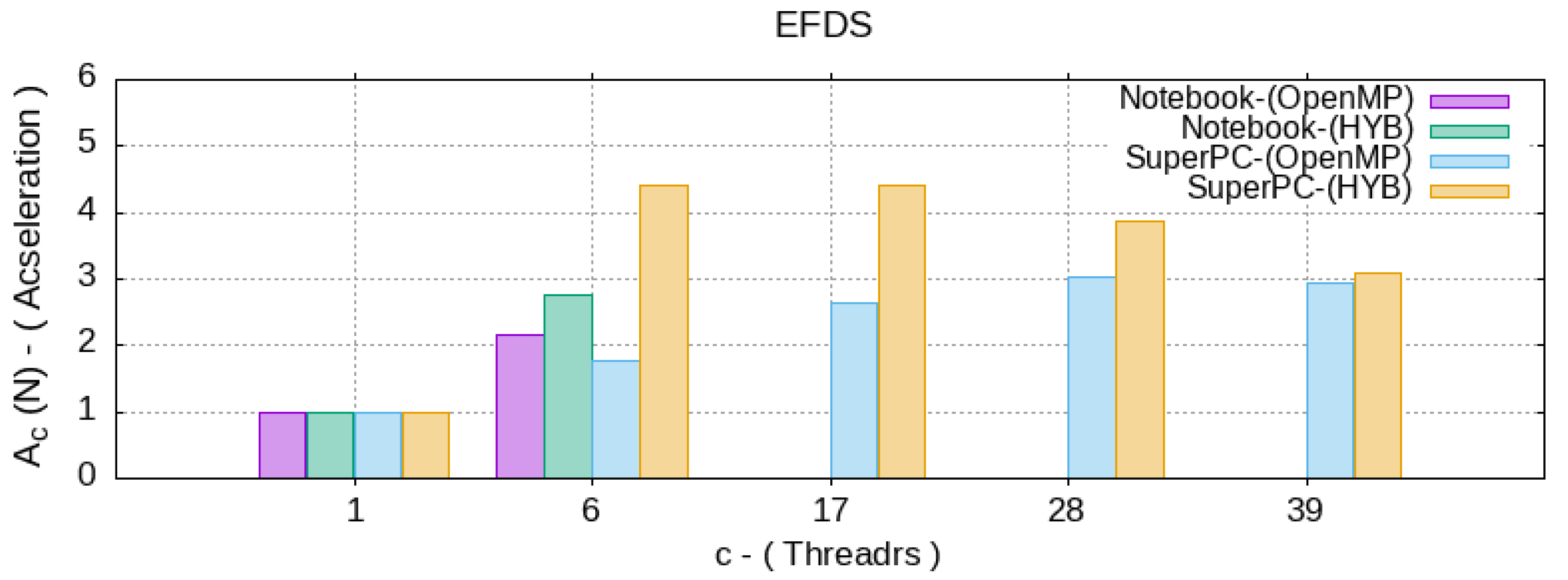
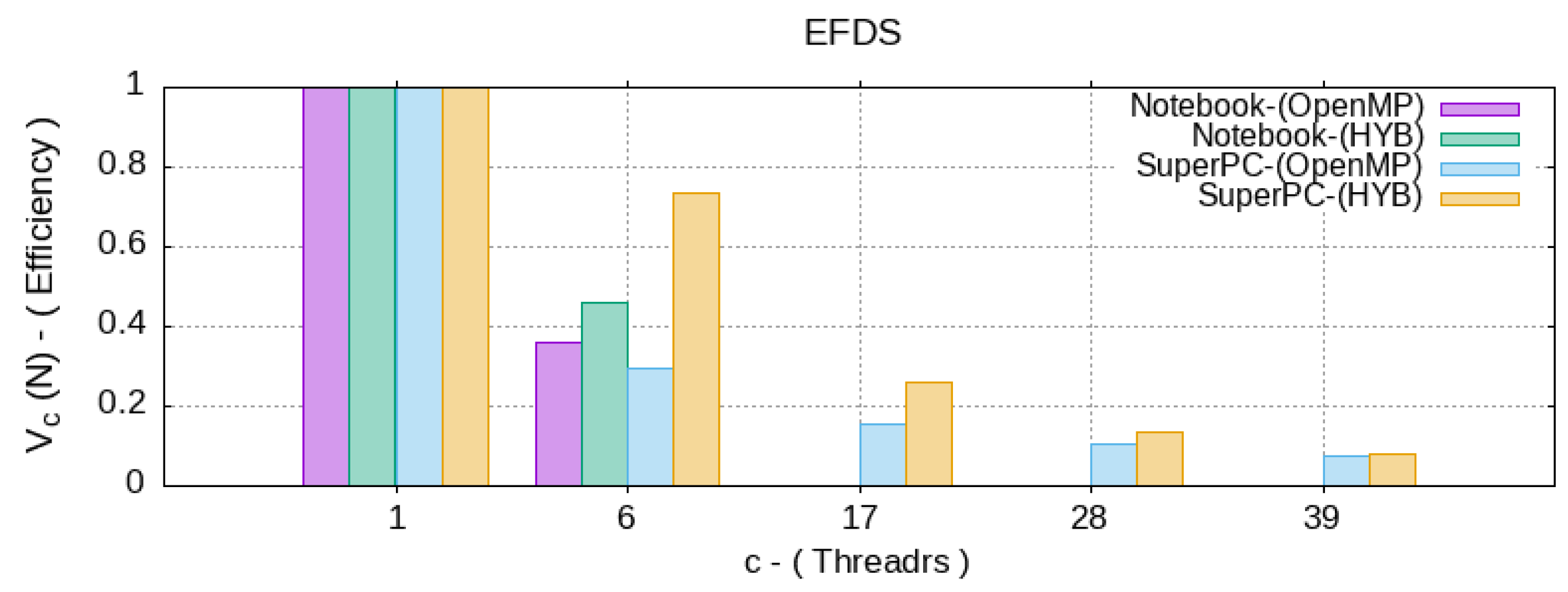
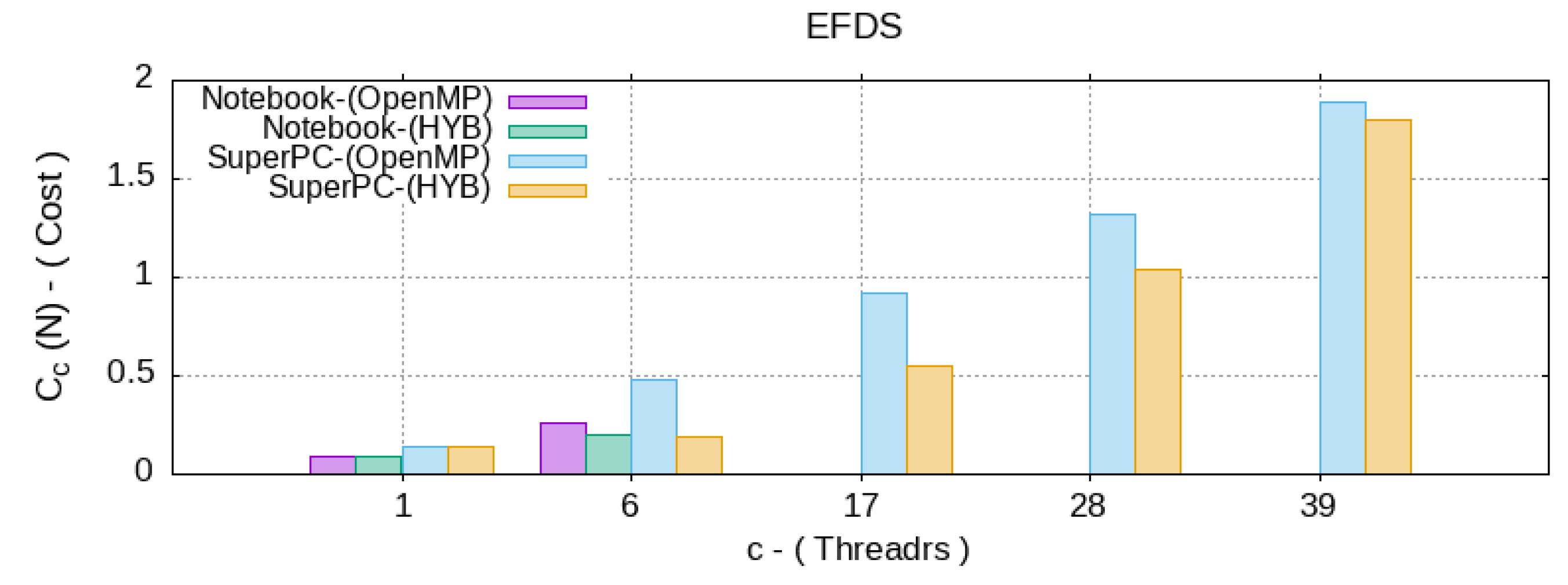
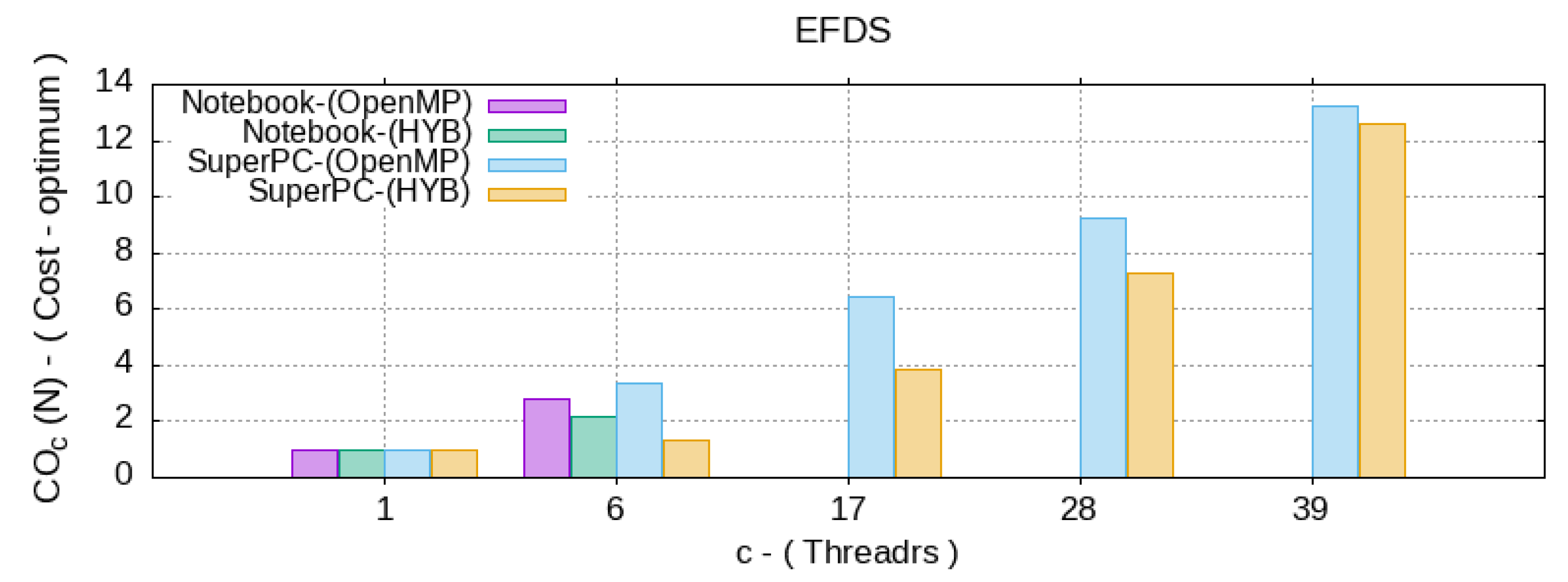
5. Analysis of Computational Efficiency
- —the number of computational grid nodes in the scheme (3), which characterizes the N complexity of the algorithm;
- —the time spent by a sequential algorithm to solve a problem of complexity N;
- —the time taken by the parallel OpenMP algorithm on machine by CPU threads;
- —the time spent by the hybrid algorithm on a machine by CPU threads, with the presence of parallel code blocks like OpenMP and CUDA. Since the user does not control the number of GPU multiprocessors involved, but specifies only the number of thread per block by choosing the optimal one, then g—does not change.
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| CPU | Central Processing Unit |
| GPU | Graphic Processing Unit |
| ALU | Arithmetic Logic Unit |
| PC | Personal Computer |
| EFDS | Explicit Finite-difference Method |
| OpenMP | Open Multi-Processing |
| CUDA | Compute Unified Device Architecture |
| RAM | Random Access Memory |
| PRAM | Parallel Random Access Machine |
| HP | Hewlett-Packard |
References
- Nahushev, A.M. Fractional Calculus and Its Application; Fizmatlit: Moscow, Russia, 2003; p. 272. (In Russian) [Google Scholar]
- Uchaikin, V.V. Fractional Derivatives for Physicists and Engineers. Vol. I. Background and Theory; Springer: Berlin/Heidelberg, Germany, 2013; p. 373. [Google Scholar] [CrossRef] [Green Version]
- Pskhu, A.V. Fractional Partial Differential Equations; Science: Moscow, Russia, 2005; p. 199. (In Russian) [Google Scholar]
- Samko, S.G.; Kilbas, A.A.; Marichev, O.I. Fractional Integrals and Derivatives and Some of Their Applications; Science and Tech: Minsk, Belarus, 1987; p. 688. (In Russian) [Google Scholar]
- Kilbas, A.A.; Srivastava, H.M.; Trujillo, J.J. Theory and Applications of Fractional Differential Equations; Elsevier: Amsterdam, The Netherlands, 2006; p. 523. [Google Scholar]
- Ortigueira, M.D.; Machado, J.T. What is a fractional derivative? J. Comput. Phys. 2015, 321, 4–13. [Google Scholar] [CrossRef]
- Ortigueira, M.D.; Valerio, D.; Machado, J.T. Variable order fractional systems. Commun. Nonlinear Sci. Numer. Simul. 2019, 71, 231–243. [Google Scholar] [CrossRef]
- Patnaik, S.; Hollkamp, J.P.; Semperlotti, F. Applications of variable-order fractional operators: A review. Proc. R. Soc. A 2020, 476, 20190498. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mandelbrot, B.B. The Fractal Geometry of Nature; W.H. Freeman and Co.: New York, NY, USA, 1982; p. 468. [Google Scholar]
- Volterra, V. Sur les équations intégro-différentielles et leurs applications. Acta Math. 1912, 35, 295–356. [Google Scholar] [CrossRef]
- Volterra, V. Theory of Functionals and of Integral and Integro-Differential Equations; Dover Publications: New York, NY, USA, 1959; p. 226. [Google Scholar]
- Petras, I. Fractional-Order Nonlinear Systems: Modeling, Analysis and Simulation; Springer: Berlin/Heidelberg, Germany, 2011; p. 218. [Google Scholar]
- Sun, H.; Chang, A.; Zhang, Y.; Chen, W. A review on variable-order fractional differential equations: Mathematical foundations, physical models, numerical methods and applications. Fract. Calc. Appl. Anal. 2019, 22, 27–59. [Google Scholar] [CrossRef] [Green Version]
- Tarasov, V.E. Mathematical Economics: Application of Fractional Calculus. Mathematics 2020, 8, 660. [Google Scholar] [CrossRef]
- Jeng, S.; Kilicman, A. Fractional Riccati Equation and Its Applications to Rough Heston Model Using Numerical Methods. Symmetry 2020, 12, 959. [Google Scholar] [CrossRef]
- Rossikhin, Y.A.; Shitikova, M.V. Application of fractional calculus for dynamic problems of solid mechanics: Novel trends and recent results. Appl. Mech. Rev. 2010, 63, 010801. [Google Scholar] [CrossRef]
- Jamil, B.; Anwar, M.S.; Rasheed, A.; Irfan, M. MHD Maxwell flow modeled by fractional derivatives with chemical reaction and thermal radiation. Chin. J. Phys. 2020, 67, 512–533. [Google Scholar] [CrossRef]
- Acioli, P.S.; Xavier, F.A.; Moreira, D.M. Mathematical Model Using Fractional Derivatives Applied to the Dispersion of Pollutants in the Planetary Boundary Layer. Bound.-Layer Meteorol. 2019, 170, 285–304. [Google Scholar] [CrossRef]
- Fellah, M.; Fellah, Z.E.A.; Mitri, F.; Ogam, E.; Depollier, C. Transient ultrasound propagation in porous media using Biot theory and fractional calculus: Application to human cancellous bone. J. Acoust. Soc. Am. 2013, 133, 1867–1881. [Google Scholar] [CrossRef]
- Mainardi, F. Fractional Calculus and Waves in Linear Viscoelastisity: An Introduction to Mathematical Models, 2nd ed.; World Scientific Publishing Company: Singapore, 2022; p. 625. [Google Scholar]
- Cai, M.; Li, C. Theory and Numerical Approximations of Fractional Integrals and Derivatives; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2020; p. 317. [Google Scholar] [CrossRef] [Green Version]
- Bogaenko, V.A.; Bulavatskiy, V.M.; Kryvonos, I.G. On Mathematical modeling of Fractional-Differential Dynamics of Flushing Process for Saline Soils with Parallel Algorithms Usage. J. Autom. Inf. Sci. 2016, 48, 1–12. [Google Scholar] [CrossRef]
- Bogaenko, V.O. Parallel finite-difference algorithms for three-dimensional space-fractional diffusion equation with phi–Caputo derivatives. Comput. Appl. Math. 2020, 39, 163. [Google Scholar] [CrossRef]
- Gerasimov, A.N. Generalization of linear deformation laws and their application to internal friction problems. Appl. Math. Mech. 1948, 12, 529–539. [Google Scholar]
- Caputo, M. Linear models of dissipation whose Q is almost frequency independent—II. Geophys. J. Int. 1946, 13, 529–539. [Google Scholar] [CrossRef]
- Daintith, J.; Wright, E. A Dictionary of Computing; Oxford University Press: Oxford, UK; p. 583.
- Miller, R.; Boxer, L. Algorithms Sequential and Parallel: A Unified Approach, 3rd ed.; Cengage Learning: Boston, MA, USA, 2013; p. 417. [Google Scholar]
- Borzunov, S.V.; Kurgalin, S.D.; Flegel, A.V. Workshop on Parallel Programming: A Study Guide; BVH: Saint Petersburg, Russia, 2017; p. 236. (In Russian) [Google Scholar]
- Kalitkin, N.N. Numerical Methods, 2nd ed.; BVH: Saint Petersburg, Russia, 2011; p. 592. (In Russian) [Google Scholar]
- Sanders, J.; Kandrot, E. CUDA by Example: An Introduction to General-Purpose GPU Programming; Addison-Wesley Professional: London, UK, 2010; p. 311. [Google Scholar]
- Okrepilov, V.V.; Makarov, V.L.; Bakhtizin, A.R.; Kuzmina, S.N. Application of Supercomputer Technologies for Simulation of Socio-Economic Systems. R-Economy 2015, 1, 340–350. [Google Scholar] [CrossRef] [Green Version]
- Il’in, V.P.; Skopin, I.N. About performance and intellectuality of supercomputer modeling. Program. Comput. Softw. 2016, 42, 5–16. [Google Scholar] [CrossRef]
- Machado, J.T.; Kiryakova, V.; Mainardi, F. Recent history of fractional calculus. Commun. Nonlinear Sci. Numer. Simul. 2011, 16, 1140–1153. [Google Scholar] [CrossRef] [Green Version]
- Tverdyi, D.A.; Parovik, R.I. Investigation of Finite-Difference Schemes for the Numerical Solution of a Fractional Nonlinear Equation. Fractal Fract. 2022, 6, 23. [Google Scholar] [CrossRef]
- Tvyordyj, D.A. Hereditary Riccati equation with fractional derivative of variable order. J. Math. Sci. 2021, 253, 564–572. [Google Scholar] [CrossRef]
- Tverdyi, D.A.; Parovik, R.I. Application of the Fractional Riccati Equation for Mathematical Modeling of Dynamic Processes with Saturation and Memory Effect. Fractal Fract. 2022, 6, 163. [Google Scholar] [CrossRef]
- Tverdyi, D.A.; Parovik, R.I. Fractional differential model of physical processes with saturation and its application to the description of the dynamics of COVID-19. Bull. KRASEC Phys. Math. Sci. 2022, 40, 119–137. [Google Scholar] [CrossRef]
- Tverdyi, D.A.; Parovik, R.I. Mathematical modeling in MATLAB of solar activity cycles according to the growth-decline of the Wolf number. Bull. KRASEC Phys. Math. Sci. 2022, 41, 47–64. [Google Scholar] [CrossRef]
- Taogetusang, S.; Li, S. New application to Riccati equation. Chin. Phys. B 2010, 19, 080303. [Google Scholar] [CrossRef]
- Parovik, R.I. Mathematical models of oscillators with memory. In Oscillators—Recent Developments; IntechOpen: London, UK, 2019; pp. 3–21. [Google Scholar] [CrossRef] [Green Version]
- Tverdyi, D.A.; Makarov, E.O.; Parovik, R.I. Hereditary Mathematical Model of the Dynamics of Radon Accumulation in the Accumulation Chamber. Mathematics 2023, 11, 850. [Google Scholar] [CrossRef]
- Sun, H.; Chen, W.; Li, C.; Chen, Y. Finite difference schemes for variable-order time fractional diffusion equation. Int. J. Bifurc. Chaos 2012, 22, 1250085. [Google Scholar] [CrossRef] [Green Version]
- Parovik, R.I. On a finite-difference scheme for an hereditary oscillatory equation. J. Math. Sci. 2021, 253, 547–557. [Google Scholar] [CrossRef]
- Brent, R.P. The parallel evaluation of general arithmetic expressions. J. Assoc. Comput. Mach. 1974, 21, 201–206. [Google Scholar] [CrossRef] [Green Version]
- Corman, T.H.; Leiserson, C.E.; Rivet, R.L.; Stein, C. Introduction to Algorithms, 3rd ed.; The MIT Press: Cambridge, UK, 2009; p. 1292. [Google Scholar]
- Shao, J. Mathematical Statistics, 2nd ed.; Springer: New York, NY, USA, 2003; p. 592. [Google Scholar]
- Gergel, V.P.; Strongin, R.G. High Performance Computing for Multi-Core Multiprocessor Systems. Study Guide; Moscow State University Publishing: Moscow, Russia, 2010; p. 544. (In Russian) [Google Scholar]
- Mueller, J.L.; Siltanen, S. Linear and Nonlinear Inverse Problems with Practical Applications; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2012; p. 351. [Google Scholar] [CrossRef]
- Cicerone, R.D.; Ebel, J.E.; Beitton, J. A systematic compilation of earthquake precursors. Tectonophysics 2009, 476, 371–396. [Google Scholar] [CrossRef]
- Firstov, P.P.; Makarov, E.O.; Gluhova, I.P.; Budilov, D.I.; Isakevich, D.V. Search for predictive anomalies of strong earthquakes according to monitoring of subsoil gases at Petropavlovsk-Kamchatsky geodynamic test site. Geosyst. Transit. Zones 2018, 2, 16–32. (In Russian) [Google Scholar] [CrossRef]







| Notebook | Notebook | SuperPC | SuperPC | SuperPC | SuperPC | SuperPC | |
|---|---|---|---|---|---|---|---|
| i | |||||||
| 1 | 0.087 | 0.046 | 0.145 | 0.08 | 0.051 | 0.047 | 0.044 |
| 2 | 0.087 | 0.042 | 0.144 | 0.082 | 0.056 | 0.047 | 0.049 |
| 3 | 0.089 | 0.041 | 0.147 | 0.082 | 0.05 | 0.054 | 0.052 |
| 4 | 0.116 | 0.044 | 0.125 | 0.082 | 0.052 | 0.049 | 0.048 |
| 5 | 0.088 | 0.043 | 0.146 | 0.081 | 0.055 | 0.047 | 0.046 |
| 6 | 0.087 | 0.044 | 0.157 | 0.081 | 0.054 | 0.049 | 0.05 |
| 7 | 0.088 | 0.044 | 0.144 | 0.079 | 0.057 | 0.05 | 0.05 |
| 8 | 0.120 | 0.041 | 0.125 | 0.081 | 0.051 | 0.05 | 0.047 |
| 9 | 0.087 | 0.043 | 0.149 | 0.081 | 0.052 | 0.04 | 0.048 |
| 10 | 0.088 | 0.044 | 0.147 | 0.079 | 0.061 | 0.04 | 0.05 |
| 0.093 | 0.043 | 0.142 | 0.08 | 0.053 | 0.047 | 0.048 | |
| RAM | 0.056 | 8.056 | 0.056 | 8.056 | |||
| Notebook | Notebook | SuperPC | SuperPC | SuperPC | SuperPC | SuperPC | |
|---|---|---|---|---|---|---|---|
| i | |||||||
| 1 | 0.087 | 0.034 | 0.145 | 0.031 | 0.032 | 0.047 | 0.037 |
| 2 | 0.087 | 0.034 | 0.144 | 0.031 | 0.031 | 0.032 | 0.049 |
| 3 | 0.089 | 0.033 | 0.147 | 0.031 | 0.032 | 0.036 | 0.05 |
| 4 | 0.116 | 0.034 | 0.125 | 0.038 | 0.032 | 0.037 | 0.05 |
| 5 | 0.088 | 0.034 | 0.146 | 0.031 | 0.032 | 0.032 | 0.039 |
| 6 | 0.087 | 0.034 | 0.157 | 0.031 | 0.032 | 0.035 | 0.049 |
| 7 | 0.088 | 0.035 | 0.144 | 0.038 | 0.032 | 0.048 | 0.051 |
| 8 | 0.120 | 0.034 | 0.125 | 0.031 | 0.032 | 0.035 | 0.048 |
| 9 | 0.087 | 0.034 | 0.149 | 0.031 | 0.037 | 0.035 | 0.05 |
| 10 | 0.088 | 0.034 | 0.147 | 0.031 | 0.032 | 0.033 | 0.039 |
| 0.093 | 0.034 | 0.1429 | 0.032 | 0.032 | 0.037 | 0.046 | |
| RAM | 0.056 | 16.05 | 0.056 | 16.05 | |||
| RAM (GPU) | - | 16.05 | - | 16.05 | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tverdyi, D.; Parovik, R. Hybrid GPU–CPU Efficient Implementation of a Parallel Numerical Algorithm for Solving the Cauchy Problem for a Nonlinear Differential Riccati Equation of Fractional Variable Order. Mathematics 2023, 11, 3358. https://doi.org/10.3390/math11153358
Tverdyi D, Parovik R. Hybrid GPU–CPU Efficient Implementation of a Parallel Numerical Algorithm for Solving the Cauchy Problem for a Nonlinear Differential Riccati Equation of Fractional Variable Order. Mathematics. 2023; 11(15):3358. https://doi.org/10.3390/math11153358
Chicago/Turabian StyleTverdyi, Dmitrii, and Roman Parovik. 2023. "Hybrid GPU–CPU Efficient Implementation of a Parallel Numerical Algorithm for Solving the Cauchy Problem for a Nonlinear Differential Riccati Equation of Fractional Variable Order" Mathematics 11, no. 15: 3358. https://doi.org/10.3390/math11153358