
Statistical Inference and Optimal Design of Accelerated Life Testing for the Chen Distribution under Progressive Type-II Censoring


Abstract
:1. Introduction
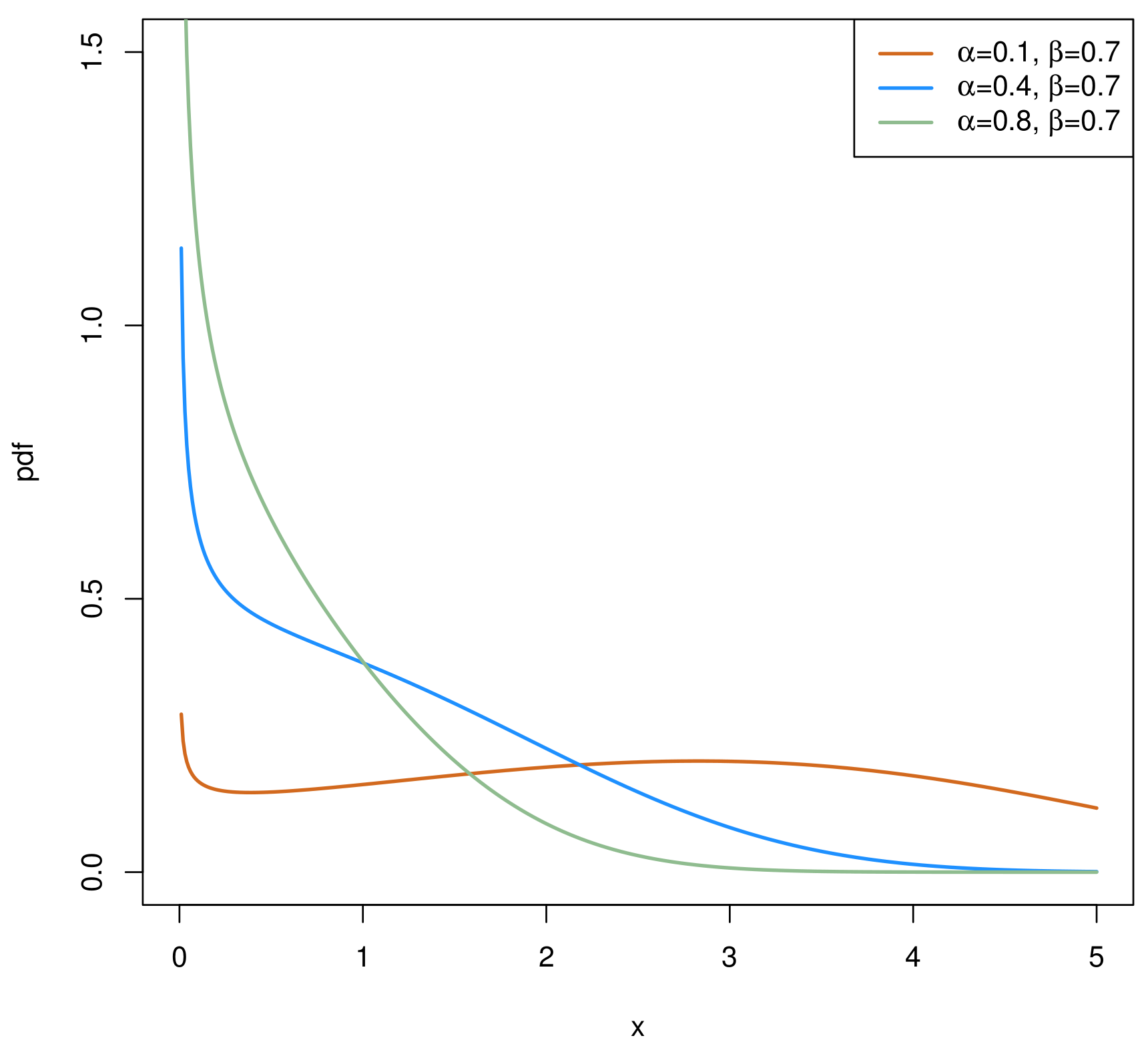
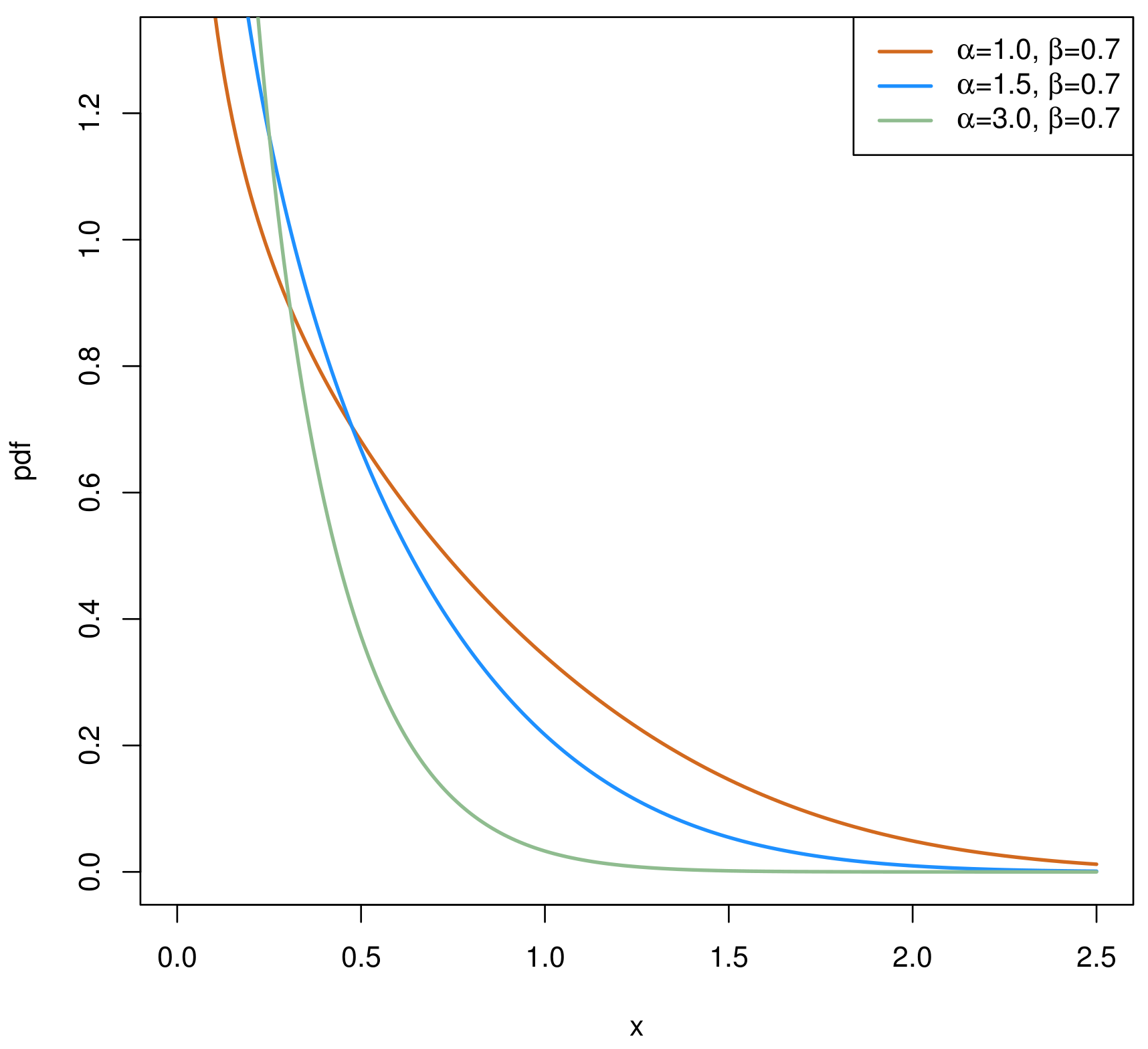
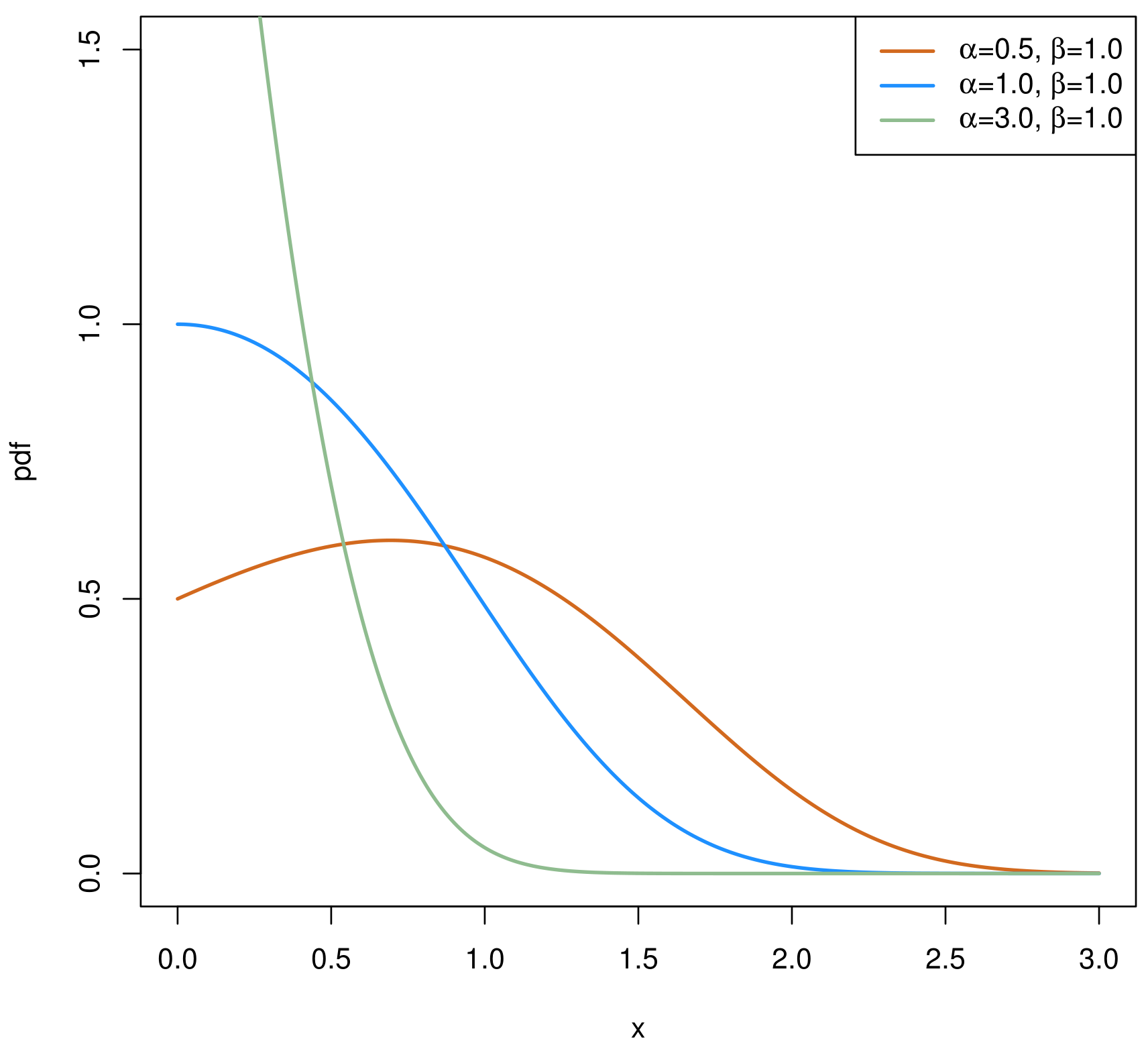
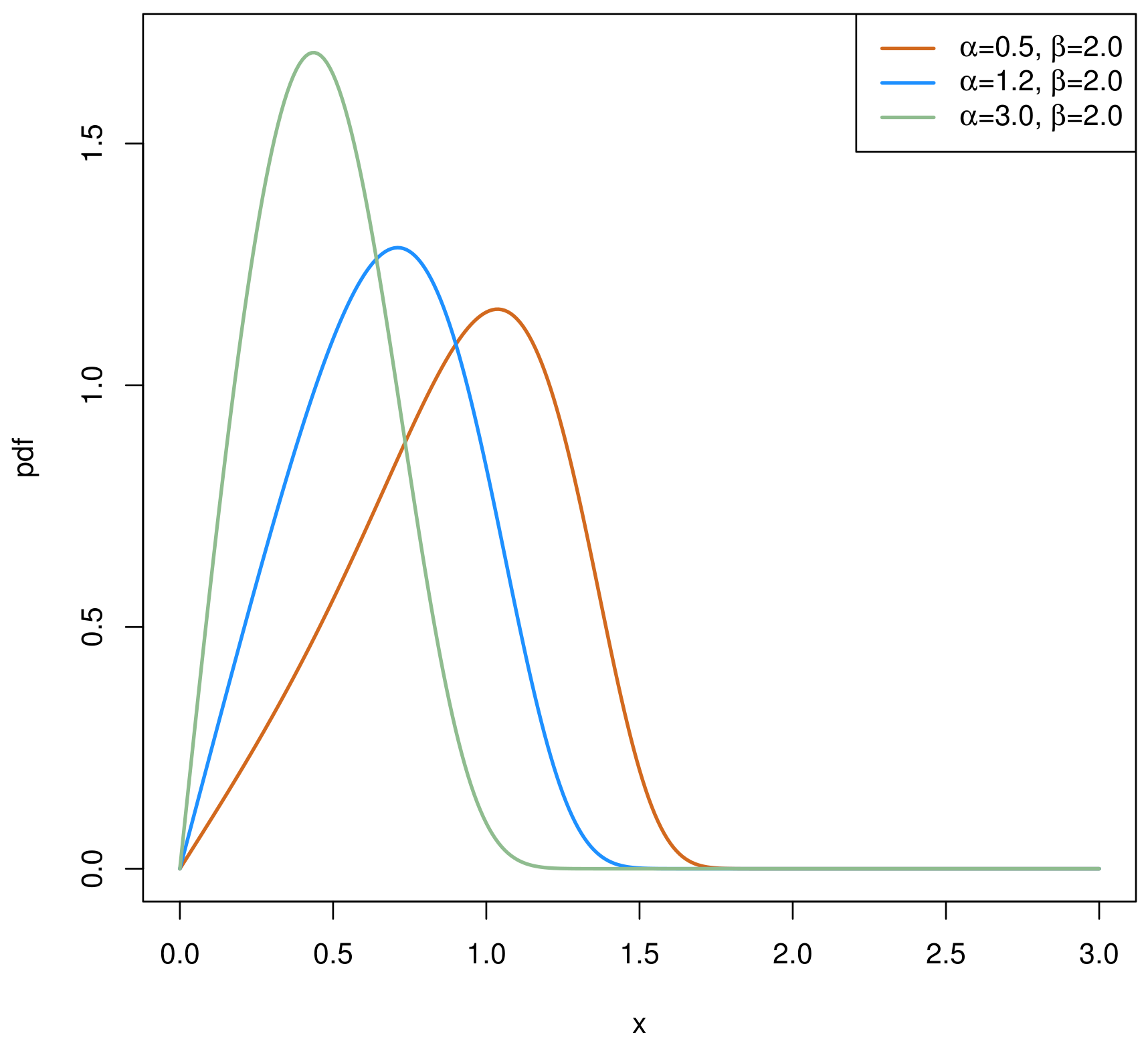
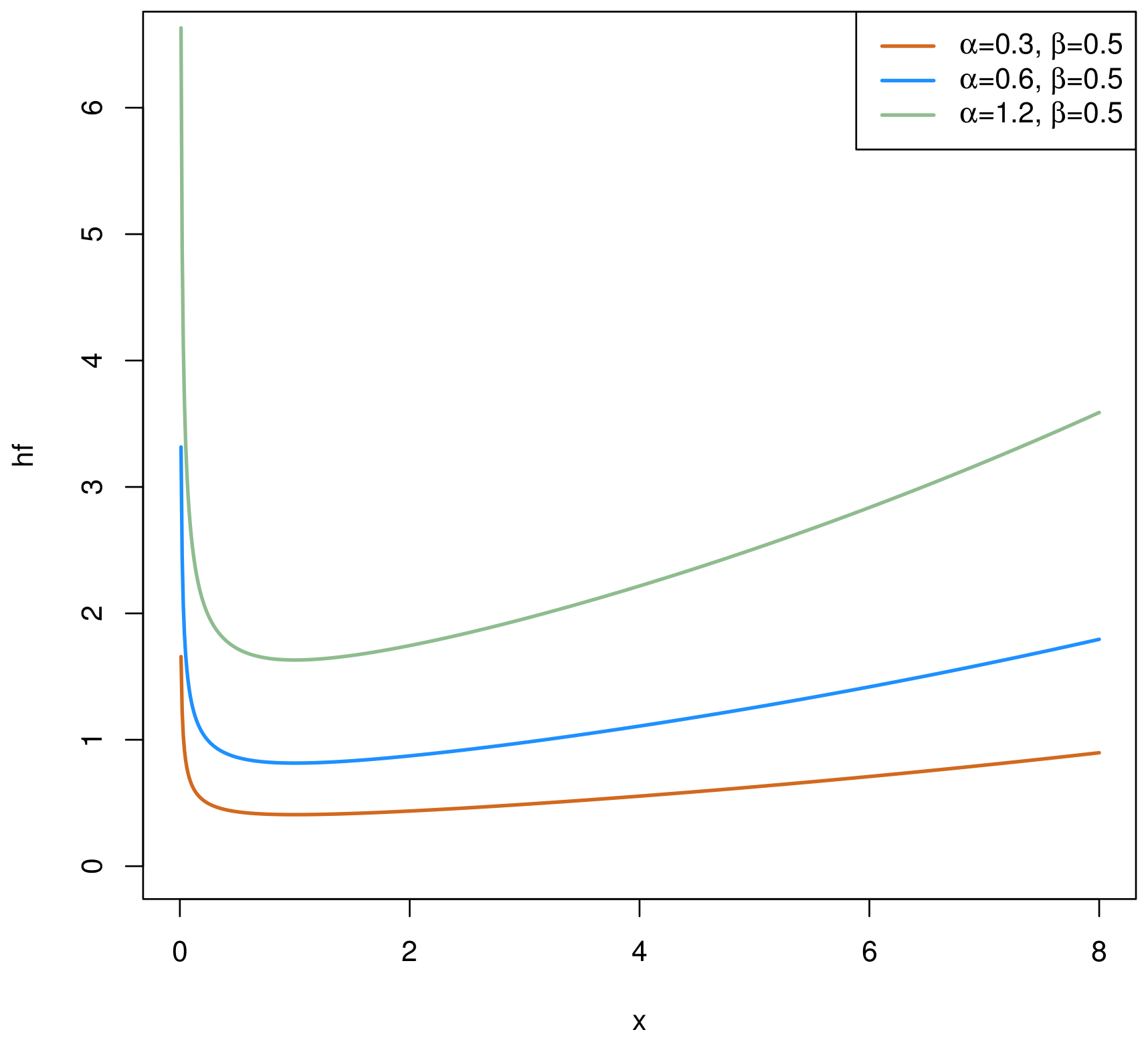
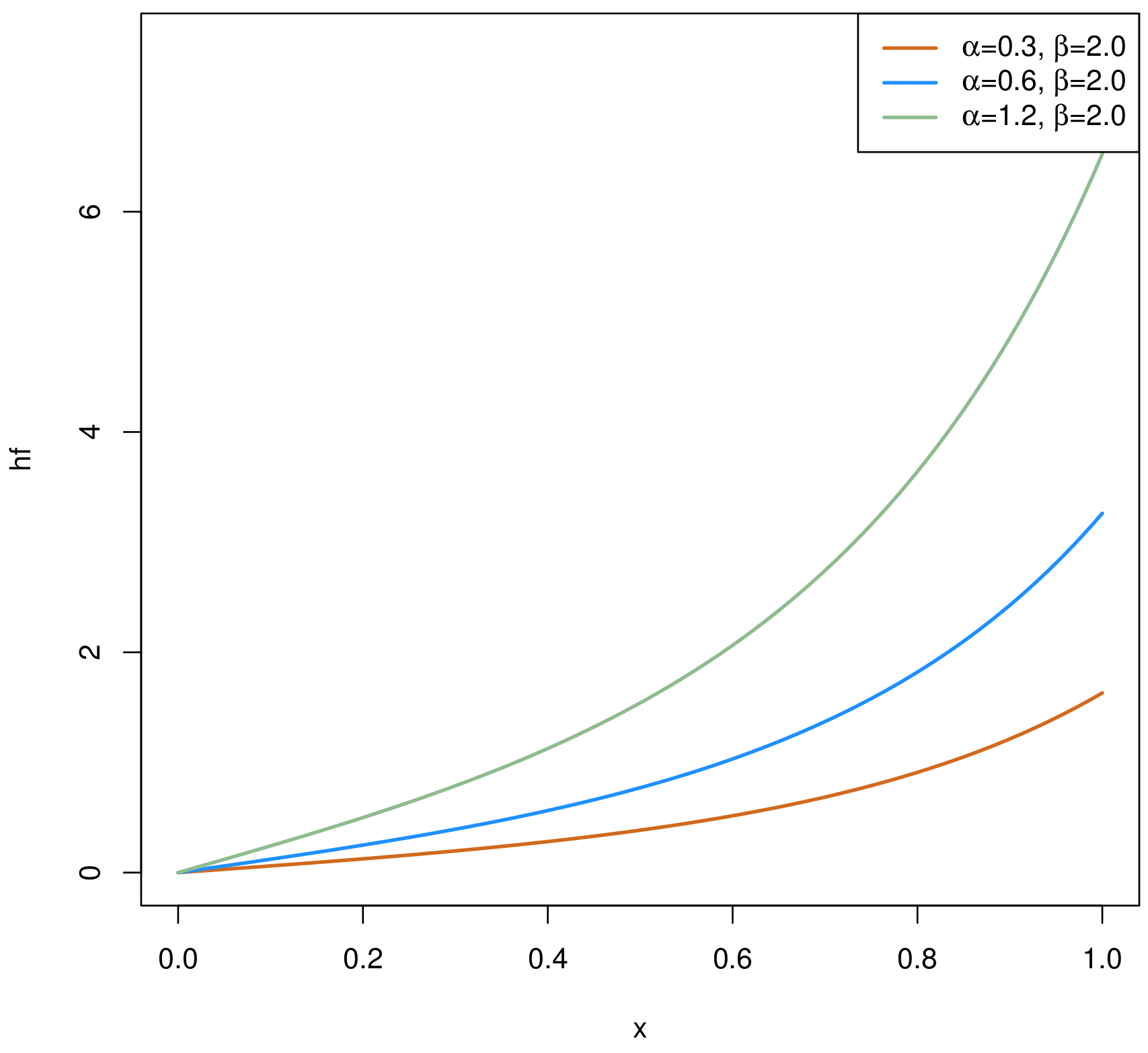
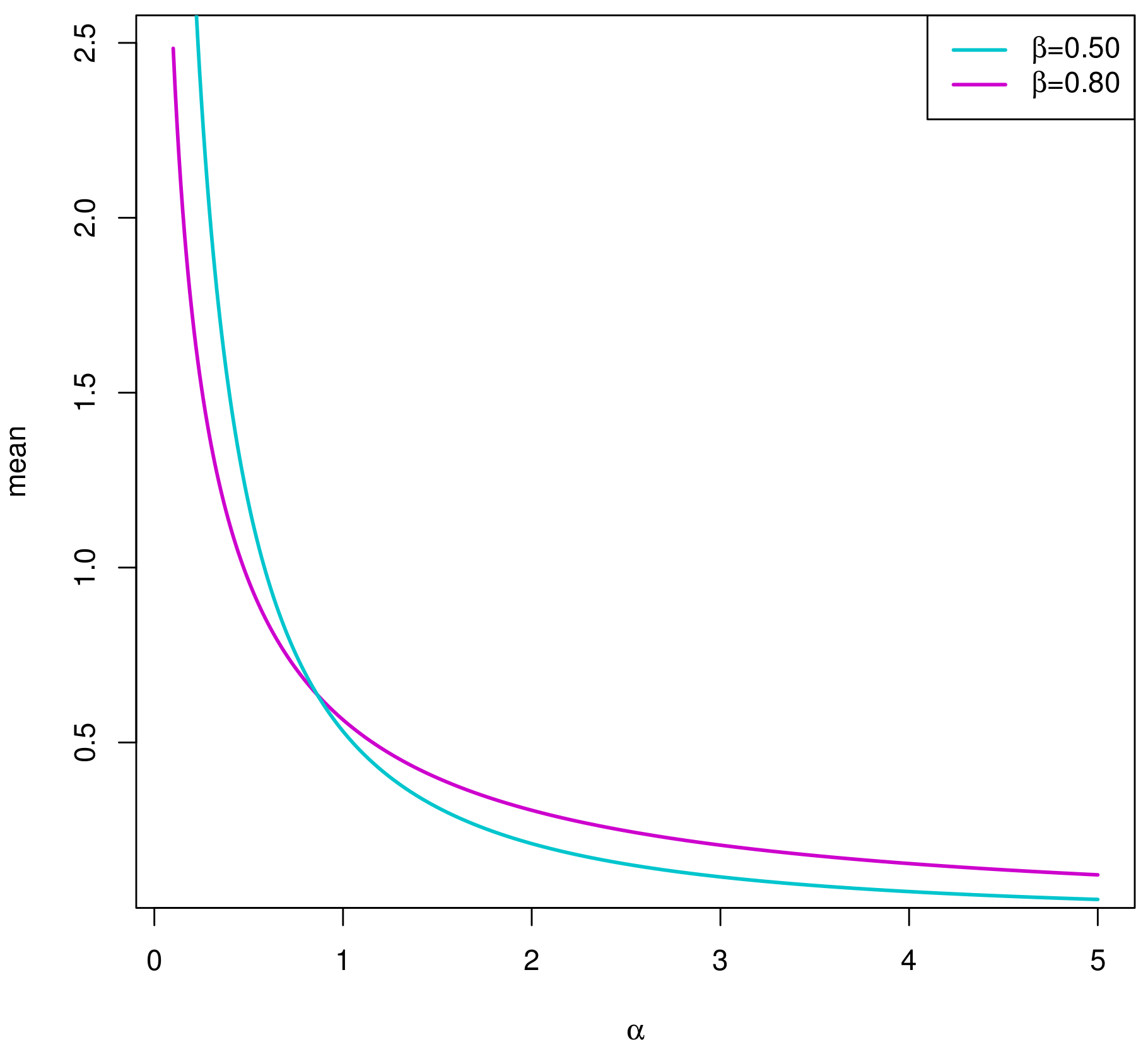
2. The Chen Distribution
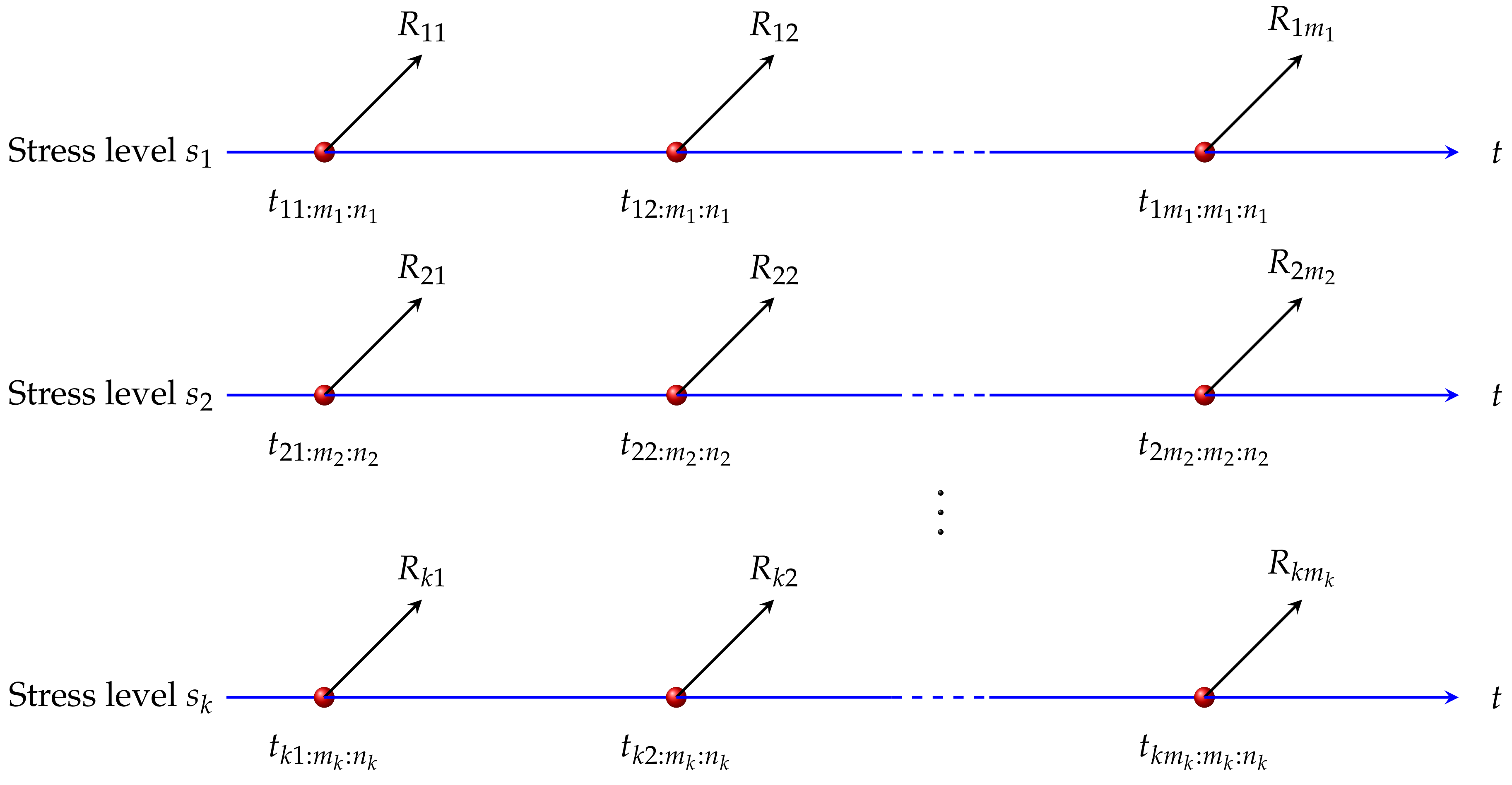
3. Model Assumptions
- (1)
- Under stress level , , the lifetimes of the units follow
- (2)
- The relationship between the stress level and the lifetime distribution parameter iswhere is an incremental function of . and are unknown parameters.
4. Maximum Likelihood Estimation
5. Fisher Information Matrix
6. Parametric Bootstrap Intervals
6.1. The Bootstrap Percentile Confidence Interval
- -
- Step 1: Utilize the progressive censored sample to compute the MLE .
- -
- Step 2: Generate a progressive censored sample by regarding as the parameter values for the Chen distribution.
- -
- Step 3: Compute the MLE using the samples from Step 2.
- -
- Step 4: Repeat Step 2 and 3, B times.
- -
- Step 5: Estimate the cdf of by where is or and let be the inverse of for a given x .
6.2. The Bootstrap-t Confidence Interval
- -
- Steps 1 and 2 are the same as those in the algorithm of the bootstrap percentile confidence interval.
- -
- Step 3: Compute the MLE using the progressive censored samples from Step 2 where is or . Then, obtain the statistic
- -
- Step 4: Repeat Step 2 and 3, B times.
- -
- Step 5: Estimate the cdf of by and let for a given x .
7. Bayesian Estimation
7.1. Tierney and Kadane Technique
7.2. Lindley’s Approximation
8. Optimal Design
8.1. D-Optimality
8.2. A-Optimality
9. Simulation Study
- (1)
- According to Table 1, Table 2, Table 3, Table 4, Table 5 and Table 6, the parameter estimation under different progressive censoring schemes all roughly follows the pattern of better performance with increasing sample size. Different censoring schemes have different performance in different estimation methods. As the censoring scheme of withdrawing one surviving unit for each unit observed to fail from the beginning of the test (for example, ), the performance in point estimation is poor, especially when the sample size is relatively small and the estimation bias is relatively large. However, this censoring scheme has no obvious difference from other schemes in interval estimation.
- (2)
- According to the results of the point estimates in Table 1, Table 2 and Table 3, the estimated values are all close to the true values and, roughly, the MSE decreases as the sample size increases, so all the point estimation methods mentioned are valid. Based on the MSEs of the parameter estimators, the three methods perform similarly when the progressive censoring scheme is determined. For the estimation of , the BE obtained from the Lindley’s approximation performs better than BE obtained from the Tierney and Kadane technique. Additionally, BE obtained from the Tierney and Kadane technique performs slightly better than MLE. For estimation, BE obtained from the Lindley’s approximation performs best, and the BE obtained from the Tierney and Kadane technique and MLE perform similarly. For estimation, BE obtained from the Lindley’s approximation performs best, followed by BE obtained from Lindley’s approximation and MLE. Overall, BE obtained from the Lindley’s approximation performs well for all three parameters.
- (3)
- According to the results of the interval estimation in Table 4, Table 5 and Table 6, generally speaking, the asymptotic confidence intervals perform best. The bootstrap percentile confidence intervals and the bootstrap-t confidence intervals perform similarly when the progressive censoring scheme is determined. For all three interval estimation methods, the AIL of is longer than those of and . The COVP of the intervals of outperforms those of both and in parametric bootstrap intervals.
- (4)
- According to Table 7 and Table 8 for the optimal transformed stress level, the values based on A-optimality are smaller than those based on D-optimality. For a similar censoring scheme, the results based on D-optimality become larger as the sample size increases. However, the results based on A-optimality are the opposite. In general, the optimal transformed stress levels do not differ significantly in each of the optimal criteria.
10. Real Data Analysis
- (1)
- The point estimates of and obtained from the three different point estimation methods are similar, but the point estimates of are slightly different. For estimation, the MLE is maximal, followed by the BE obtained from the Lindley’s approximation and the BE obtained from the Tierney and Kadane technique;
- (2)
- In terms of AIL, the results obtained by the three interval estimation methods do not differ significantly. The bootstrap-t confidence intervals outperform slightly the asymptotic confidence intervals and the bootstrap percentile confidence intervals. This is consistent with the pattern that parametric bootstrap intervals outperform asymptotic intervals when the sample size is small.
- (3)
- For the bounds of the interval estimates of , the bootstrap percentile confidence intervals and the bootstrap-t confidence intervals are similar. For the interval estimates of , the upper and lower bounds of the asymptotic confidence intervals are significantly larger than those of the bootstrap percentile confidence intervals and the bootstrap-t confidence intervals. The bounds of the bootstrap-t confidence intervals are slightly larger than those of the bootstrap percentile confidence intervals. For the bounds on the interval estimates of , the results obtained by the three methods are similar.
11. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- McCool, J.I. Confidence limits for Weibull regression with censored data. IEEE Trans. Reliab. 1980, 29, 145–150. [Google Scholar] [CrossRef]
- Nelson, W.B. Accelerated Testing: Statistical Models, Test Plans, and Data Analysis; Wiley: New York, NY, USA, 1990. [Google Scholar]
- Miller, R.; Nelson, W. Optimum simple step-stress plans for accelerated life testing. IEEE Trans. Reliab. 1983, 32, 59–65. [Google Scholar] [CrossRef]
- Ismail, A.A. Reliability analysis under constant-stress partially accelerated life tests using hybrid censored data from Weibull distribution. Hacet. J. Math. Stat. 2016, 45, 181–193. [Google Scholar] [CrossRef]
- El-Din, M.M.M.; Abu-Youssef, S.E.; Ali, N.S.A.; El-Raheem, A.M.A. Optimal plans of constant-stress accelerated life tests for the Lindley distribution. J. Test. Eval. 2017, 45, 1463–1475. [Google Scholar]
- El-Din, M.M.M.; Abu-Youssef, S.E.; Ali, N.S.A.; El-Raheem, A.M.A. Parametric inference on step-stress accelerated life testing for the extension of exponential distribution under progressive type-II censoring. Commun. Stat. Appl. Methods 2016, 23, 269–285. [Google Scholar] [CrossRef] [Green Version]
- Chandra, N.; Khan, M.A. Analysis and optimum plan for 3-step step-stress accelerated life tests with Lomax model under progressive type-I censoring. Commun. Math. Stat. 2018, 6, 73–90. [Google Scholar]
- Abdel-Hamid, A.H.; Abushal, T.A. Inference on progressive-stress model for the exponentiated exponential distribution under type-II progressive hybrid censoring. J. Stat. Comput. Simul. 2015, 85, 1165–1186. [Google Scholar] [CrossRef]
- Balakrishnan, N.; Aggarwala, R. Progressive Censoring: Theory, Methods, and Applications; Birkhäuser: Boston, MA, USA, 2000. [Google Scholar]
- Balakrishnan, N. Progressive censoring methodology: An appraisal. Test 2007, 16, 211–259. [Google Scholar] [CrossRef]
- Jaheen, Z.F.; Moustafa, H.M.; Abd El-Monem, G.H. Bayes inference in constant partially accelerated life tests for the generalized exponential distribution with progressive censoring. Commun. Stat.-Theory Methods 2014, 43, 2973–2988. [Google Scholar] [CrossRef]
- Basak, I.; Balakrishnan, N. Prediction of censored exponential lifetimes in a simple step-stress model under progressive Type II censoring. Comput. Stat. 2017, 32, 1665–1687. [Google Scholar] [CrossRef]
- Abd El-Raheem, A.M. Inference and optimal design of multiple constant-stress testing for generalized half-normal distribution under type-II progressive censoring. J. Stat. Comput. Simul. 2019, 89, 3075–3104. [Google Scholar] [CrossRef]
- Algarni, A.; Almarashi, A.M.; Okasha, H.; Ng, H.K.T. E-bayesian estimation of Chen distribution based on type-I censoring scheme. Entropy 2020, 22, 636. [Google Scholar] [CrossRef] [PubMed]
- Chen, Z. A new two-parameter lifetime distribution with bathtub shape or increasing failure rate function. Stat. Probab. Lett. 2000, 49, 155–161. [Google Scholar] [CrossRef]
- Hjorth, U. A reliability distribution with increasing, decreasing, constant and bathtub-shaped failure rates. Technometrics 1980, 22, 99–107. [Google Scholar] [CrossRef]
- Olkin, I. Life distributions: A brief discussion. Commun. Stat.-Simul. Comput. 2016, 45, 1489–1498. [Google Scholar] [CrossRef]
- Sarhan, A.M.; Hamilton, D.C.; Smith, B. Parameter estimation for a two-parameter bathtub-shaped lifetime distribution. Appl. Math. Model. 2012, 36, 5380–5392. [Google Scholar] [CrossRef]
- Rastogi, M.K.; Tripathi, Y.M. Estimation using hybrid censored data from a two-parameter distribution with bathtub shape. Comput. Stat. Data Anal. 2013, 67, 268–281. [Google Scholar] [CrossRef]
- Ahmed, E.A. Bayesian estimation based on progressive Type-II censoring from two-parameter bathtub-shaped lifetime model: An Markov chain Monte Carlo approach. J. Appl. Stat. 2014, 41, 752–768. [Google Scholar] [CrossRef]
- Ahmed, E.A.; Alhussain, Z.A.; Salah, M.M.; Ahmed, H.H.; Eliwa, M.S. Inference of progressively type-II censored competing risks data from Chen distribution with an application. J. Appl. Stat. 2020, 47, 2492–2524. [Google Scholar] [CrossRef]
- MacDonald, I.L. Does Newton–Raphson really fail? Stat. Methods Med. Res. 2014, 23, 308–311. [Google Scholar] [CrossRef]
- Tierney, L.; Kadane, J.B. Accurate approximations for posterior moments and marginal densities. J. Am. Stat. Assoc. 1986, 81, 82–86. [Google Scholar] [CrossRef]
- Lindley, D.V. Approximate Bayesian methods. Trab. Estadística Y Investig. Oper. 1980, 31, 223–245. [Google Scholar] [CrossRef]
- Jung, M.; Chung, Y. Bayesian inference of three-parameter bathtub-shaped lifetime distribution. Commun. Stat.-Theory Methods 2018, 47, 4229–4241. [Google Scholar] [CrossRef]
- Balakrishnan, N.; Sandhu, R.A. A simple simulational algorithm for generating progressive type-II censored samples. Am. Stat. 1995, 49, 229–230. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| EV | MSE | EV | MSE | EV | MSE | ||
|---|---|---|---|---|---|---|---|
| (, 15, ) | |||||||
| (, , ) | |||||||
| () | |||||||
| (, 20, ) | |||||||
| (, , ) | |||||||
| (, ) | |||||||
| (, 25, ) | |||||||
| (, , ) | |||||||
| (, ) |
| EV | MSE | EV | MSE | EV | MSE | ||
|---|---|---|---|---|---|---|---|
| (, 15, ) | 0.4957 | 0.0291 | 2.0937 | 0.0715 | 0.7386 | 0.0130 | |
| (, , ) | 0.4957 | 0.0299 | 2.1003 | 0.0779 | 0.7397 | 0.0139 | |
| () | 0.4953 | 0.0315 | 2.1187 | 0.0902 | 0.7476 | 0.0166 | |
| (, 20, ) | 0.4744 | 0.0147 | 2.0541 | 0.0330 | 0.7229 | 0.0067 | |
| (, , ) | 0.4747 | 0.0150 | 2.0563 | 0.0350 | 0.7236 | 0.0069 | |
| (, ) | 0.4750 | 0.0142 | 2.0556 | 0.0345 | 0.7244 | 0.0071 | |
| (, 25, ) | 0.4669 | 0.0093 | 2.0368 | 0.0220 | 0.7157 | 0.0047 | |
| (, , ) | 0.4664 | 0.0096 | 2.0364 | 0.0223 | 0.7154 | 0.0046 | |
| (, ) | 0.4664 | 0.0098 | 2.0401 | 0.0235 | 0.7172 | 0.0049 |
| EV | MSE | EV | MSE | EV | MSE | ||
|---|---|---|---|---|---|---|---|
| (, 15, ) | 0.4869 | 0.0270 | 2.0424 | 0.0491 | 0.7117 | 0.0098 | |
| (, , ) | 0.4825 | 0.0265 | 2.0425 | 0.0514 | 0.7099 | 0.0105 | |
| () | 0.4826 | 0.0258 | 2.0462 | 0.0593 | 0.7119 | 0.0125 | |
| (, 20, ) | 0.4699 | 0.0126 | 2.0290 | 0.0269 | 0.7088 | 0.0058 | |
| (, , ) | 0.4704 | 0.0138 | 2.0290 | 0.0285 | 0.7089 | 0.0060 | |
| (, ) | 0.4708 | 0.0133 | 2.0286 | 0.0304 | 0.7085 | 0.0065 | |
| (, 25, ) | 0.4632 | 0.0088 | 2.0190 | 0.0192 | 0.7059 | 0.0042 | |
| (, , ) | 0.4648 | 0.0087 | 2.0189 | 0.0196 | 0.7054 | 0.0042 | |
| (, ) | 0.4660 | 0.0096 | 2.0171 | 0.0194 | 0.7051 | 0.0042 |
| Parameter | LB | UB | AIL | COVP | ||
|---|---|---|---|---|---|---|
| (, 15, ) | 0.2015 | 0.7859 | 0.5844 | 0.9422 | ||
| 1.6609 | 2.5389 | 0.8779 | 0.9556 | |||
| 0.5503 | 0.9425 | 0.3922 | 0.9403 | |||
| (, , ) | 0.2020 | 0.7876 | 0.5856 | 0.9451 | ||
| 1.6553 | 2.5524 | 0.8971 | 0.9595 | |||
| 0.5470 | 0.9495 | 0.4025 | 0.9436 | |||
| () | 0.2018 | 0.7889 | 0.5871 | 0.9476 | ||
| 1.6240 | 2.6262 | 1.0022 | 0.9649 | |||
| 0.5285 | 0.9863 | 0.4578 | 0.9404 | |||
| (, 20, ) | 0.2565 | 0.6871 | 0.4306 | 0.9467 | ||
| 1.7324 | 2.3861 | 0.6538 | 0.9535 | |||
| 0.5784 | 0.8780 | 0.2995 | 0.9465 | |||
| (, , ) | 0.2569 | 0.6878 | 0.4309 | 0.9461 | ||
| 1.7296 | 2.3883 | 0.6587 | 0.9546 | |||
| 0.5768 | 0.8793 | 0.3026 | 0.9456 | |||
| (, ) | 0.2553 | 0.6840 | 0.4287 | 0.9446 | ||
| 1.7270 | 2.3995 | 0.6725 | 0.9546 | |||
| 0.5742 | 0.8847 | 0.3106 | 0.9470 | |||
| (, 25, ) | 0.2860 | 0.6448 | 0.3588 | 0.9461 | ||
| 1.7700 | 2.3133 | 0.5433 | 0.9535 | |||
| 0.5940 | 0.8454 | 0.2514 | 0.9474 | |||
| (, , ) | 0.2856 | 0.6437 | 0.3581 | 0.9444 | ||
| 1.7683 | 2.3144 | 0.5461 | 0.9523 | |||
| 0.5935 | 0.8465 | 0.2531 | 0.9486 | |||
| (, ) | 0.2853 | 0.6447 | 0.3594 | 0.9422 | ||
| 1.7675 | 2.3144 | 0.5468 | 0.9562 | |||
| 0.5927 | 0.8471 | 0.2544 | 0.9491 |
| Parameter | LB | UB | AIL | COVP | ||
|---|---|---|---|---|---|---|
| (, 15, ) | 0.2748 | 1.0015 | 0.7267 | 0.9180 | ||
| 1.8041 | 2.9166 | 1.1125 | 0.8520 | |||
| 0.6093 | 1.0612 | 0.4519 | 0.8560 | |||
| (, , ) | 0.2762 | 1.0105 | 0.7343 | 0.9320 | ||
| 1.7954 | 2.9324 | 1.1370 | 0.8680 | |||
| 0.6050 | 1.0685 | 0.4635 | 0.8540 | |||
| () | 0.2760 | 1.0237 | 0.7476 | 0.9260 | ||
| 1.7939 | 3.0883 | 1.2945 | 0.8800 | |||
| 0.5961 | 1.1200 | 0.5238 | 0.8800 | |||
| (, 20, ) | 0.3040 | 0.7959 | 0.4919 | 0.9260 | ||
| 1.8200 | 2.5674 | 0.7474 | 0.8980 | |||
| 0.6171 | 0.9435 | 0.3265 | 0.8900 | |||
| (, , ) | 0.3056 | 0.8003 | 0.4947 | 0.9220 | ||
| 1.8125 | 2.5607 | 0.7482 | 0.9040 | |||
| 0.6144 | 0.9442 | 0.3298 | 0.9000 | |||
| (, ) | 0.3134 | 0.8193 | 0.5059 | 0.9120 | ||
| 1.7963 | 2.5448 | 0.7484 | 0.9180 | |||
| 0.6068 | 0.9414 | 0.3346 | 0.8960 | |||
| (, 25, ) | 0.3188 | 0.7094 | 0.3906 | 0.9460 | ||
| 1.8287 | 2.4219 | 0.5932 | 0.9180 | |||
| 0.6188 | 0.8854 | 0.2666 | 0.9060 | |||
| (, , ) | 0.3184 | 0.7082 | 0.3898 | 0.9420 | ||
| 1.8368 | 2.4402 | 0.6035 | 0.9040 | |||
| 0.6251 | 0.8957 | 0.2706 | 0.8820 | |||
| (, ) | 0.3144 | 0.7022 | 0.3878 | 0.9200 | ||
| 1.8367 | 2.4400 | 0.6032 | 0.9020 | |||
| 0.6219 | 0.8917 | 0.2699 | 0.8880 |
| Parameter | LB | UB | AIL | COVP | ||
|---|---|---|---|---|---|---|
| (, 15, ) | 0.2779 | 1.0088 | 0.7309 | 0.9180 | ||
| 1.8004 | 2.8922 | 1.0919 | 0.8660 | |||
| 0.6098 | 1.0624 | 0.4526 | 0.8460 | |||
| (, , ) | 0.2803 | 1.0228 | 0.7425 | 0.9140 | ||
| 1.7986 | 2.9278 | 1.1293 | 0.8640 | |||
| 0.6091 | 1.0729 | 0.4639 | 0.8580 | |||
| () | 0.2862 | 1.0585 | 0.7723 | 0.9260 | ||
| 1.7877 | 3.0774 | 1.2897 | 0.8680 | |||
| 0.5981 | 1.1247 | 0.5266 | 0.8540 | |||
| (, 20, ) | 0.2991 | 0.7843 | 0.4851 | 0.9300 | ||
| 1.8251 | 2.5750 | 0.7499 | 0.8900 | |||
| 0.6203 | 0.9461 | 0.3257 | 0.8760 | |||
| (, , ) | 0.3063 | 0.8031 | 0.4968 | 0.9240 | ||
| 1.8170 | 2.5678 | 0.7508 | 0.9180 | |||
| 0.6151 | 0.9446 | 0.3295 | 0.9020 | |||
| (, ) | 0.3135 | 0.8194 | 0.5059 | 0.9180 | ||
| 1.8088 | 2.5659 | 0.7571 | 0.9100 | |||
| 0.6123 | 0.9485 | 0.3362 | 0.8860 | |||
| (, 25, ) | 0.3255 | 0.7213 | 0.3957 | 0.9280 | ||
| 1.8254 | 2.3876 | 0.5623 | 0.9060 | |||
| 0.6194 | 0.8699 | 0.2505 | 0.9120 | |||
| (, , ) | 0.3182 | 0.7099 | 0.3917 | 0.9460 | ||
| 1.8306 | 2.4291 | 0.5984 | 0.9020 | |||
| 0.6199 | 0.8886 | 0.2687 | 0.9040 | |||
| (, ) | 0.3173 | 0.7077 | 0.3904 | 0.9260 | ||
| 1.8339 | 2.4316 | 0.5977 | 0.9160 | |||
| 0.6227 | 0.8927 | 0.2700 | 0.9120 |
| (, 15, ) | 8.2396 | (, , ) | 8.1901 | () | 7.7286 | |
| (, 20, ) | 8.6145 | (, , ) | 8.5932 | (, ) | 8.5267 | |
| (, 25, ) | 8.7662 | (, , ) | 8.7874 | (, ) | 8.7212 |
| (, 15, ) | 6.7736 | (, , ) | 6.7567 | () | 6.7330 | |
| (, 20, ) | 6.7087 | (, , ) | 6.7015 | (, ) | 6.6857 | |
| (, 25, ) | 6.6858 | (, , ) | 6.6738 | (, ) | 6.6786 |
| Stress Level | Data Set | K-S Statistic | p-Value |
|---|---|---|---|
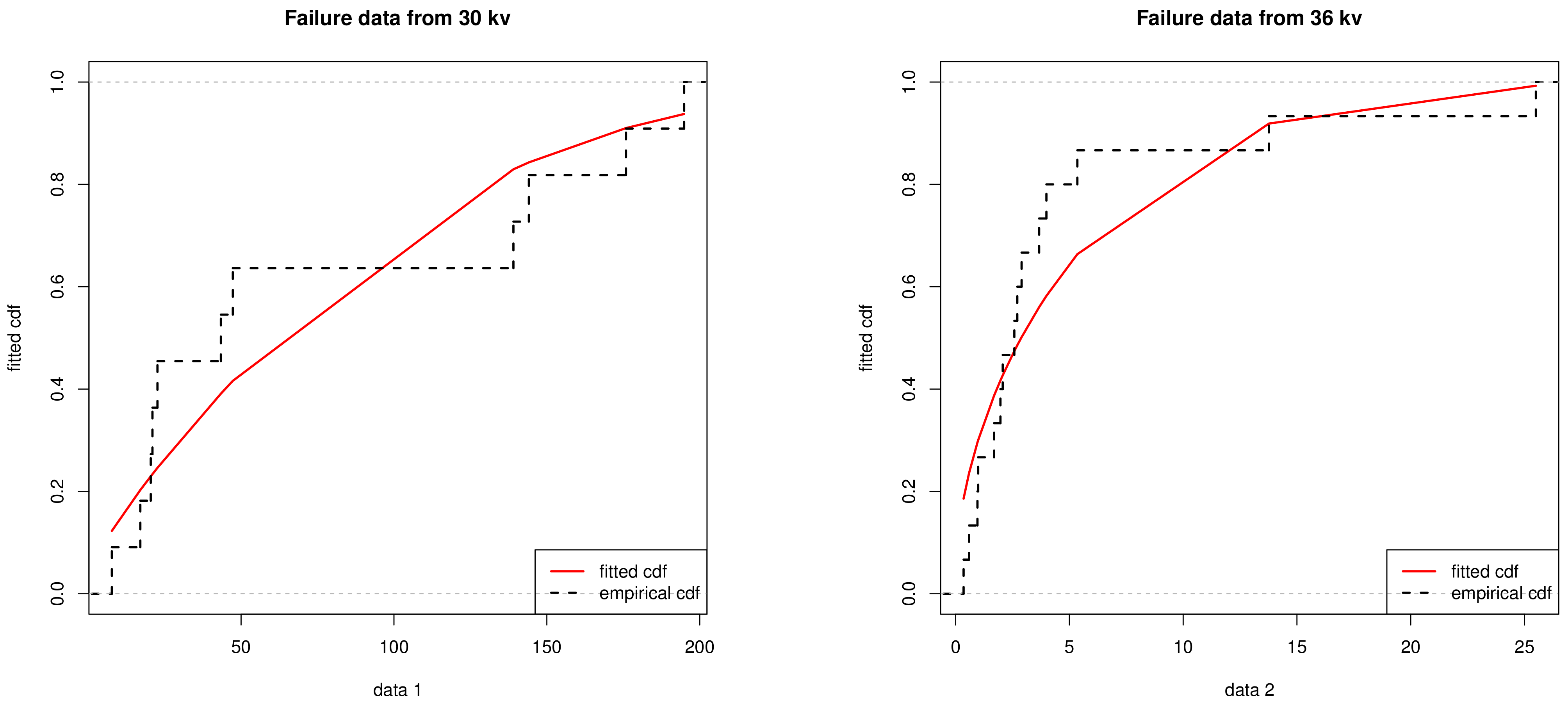
| 30 kV | 7.74, 17.05, 20.46, 21.02, 22.66, 43.40, 47.30, 139.07, 144.12, 175.88, 194.90 | 0.2203 | 0.5858 |
| 36 kV | 0.35, 0.59, 0.96, 0.99, 1.69, 1.97, 2.07, 2.58, 2.71, 2.90, 3.67, 3.99, 5.35, 13.77, 25.50 | 0.2179 | 0.4154 |
| Stress Level | Censored Data | |||
|---|---|---|---|---|
| 30 kV | 1 | (, 1, ) | 7.74, 17.05, 20.46, 21.02, 22.66, 47.30, 139.07, 144.12, 175.88, 194.90 | |
| 36 kV | 1.44966 | (, 1, ) | 0.35, 0.59, 0.96, 0.99, 1.69, 1.97, 2.07, 2.58, 2.90, 3.67, 3.99, 5.35, 13.77, 25.50 |
| Parameter | MLE | ||
|---|---|---|---|
| 0.0025 | 0.0032 | 0.0026 | |
| 22.8063 | 20.4310 | 21.3963 | |
| 0.2639 | 0.2605 | 0.2673 |
| Parameter | ACI | Boot-p | Boot-t |
|---|---|---|---|
| (0.0012, 0.0039) 0.0027 | (0.0025, 0.0218) 0.0193 | (0.0025, 0.0043) 0.0018 | |
| (9.9884, 35.6241) 25.6356 | (4.8530, 28.3640) 23.5111 | (6.0894, 28.2857) 22.1964 | |
| (0.2292, 0.2986) 0.0694 | (0.2162, 0.2848) 0.0686 | (0.2259, 0.2812) 0.0553 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, W.; Gui, W. Statistical Inference and Optimal Design of Accelerated Life Testing for the Chen Distribution under Progressive Type-II Censoring. Mathematics 2022, 10, 1609. https://doi.org/10.3390/math10091609
Zhang W, Gui W. Statistical Inference and Optimal Design of Accelerated Life Testing for the Chen Distribution under Progressive Type-II Censoring. Mathematics. 2022; 10(9):1609. https://doi.org/10.3390/math10091609
Chicago/Turabian StyleZhang, Wenjie, and Wenhao Gui. 2022. "Statistical Inference and Optimal Design of Accelerated Life Testing for the Chen Distribution under Progressive Type-II Censoring" Mathematics 10, no. 9: 1609. https://doi.org/10.3390/math10091609