
Rule Fusion of Privacy Protection Strategies for Co-Ownership Data Sharing



Abstract
:1. Introduction
2. Related Works
2.1. Privacy Protection
2.2. Policy and Privacy Protection Strategies
2.3. Rule Fusion
3. Rule Fusion of Privacy Protection Strategies
3.1. Privacy Protection Rules
3.1.1. Privacy Protection Elements
3.1.2. Privacy Protection Predicate Logic Formula
3.1.3. Logic Model of Privacy Protection Rules
3.2. Privacy Protection Rule Integration
3.2.1. Unified Description of Heterogeneous Rules
| Algorithm 1 Uniform description algorithm of privacy protection rules |
Input: Different forms of privacy protection rules Output: Uniformly described privacy protection rules
|
3.2.2. Fusion of Heterogeneous Rules
| Algorithm 2 Privacy protection rule conflict detection fusion algorithm |
Input: Privacy rules Output: Fusion rules , Conflict rules
|
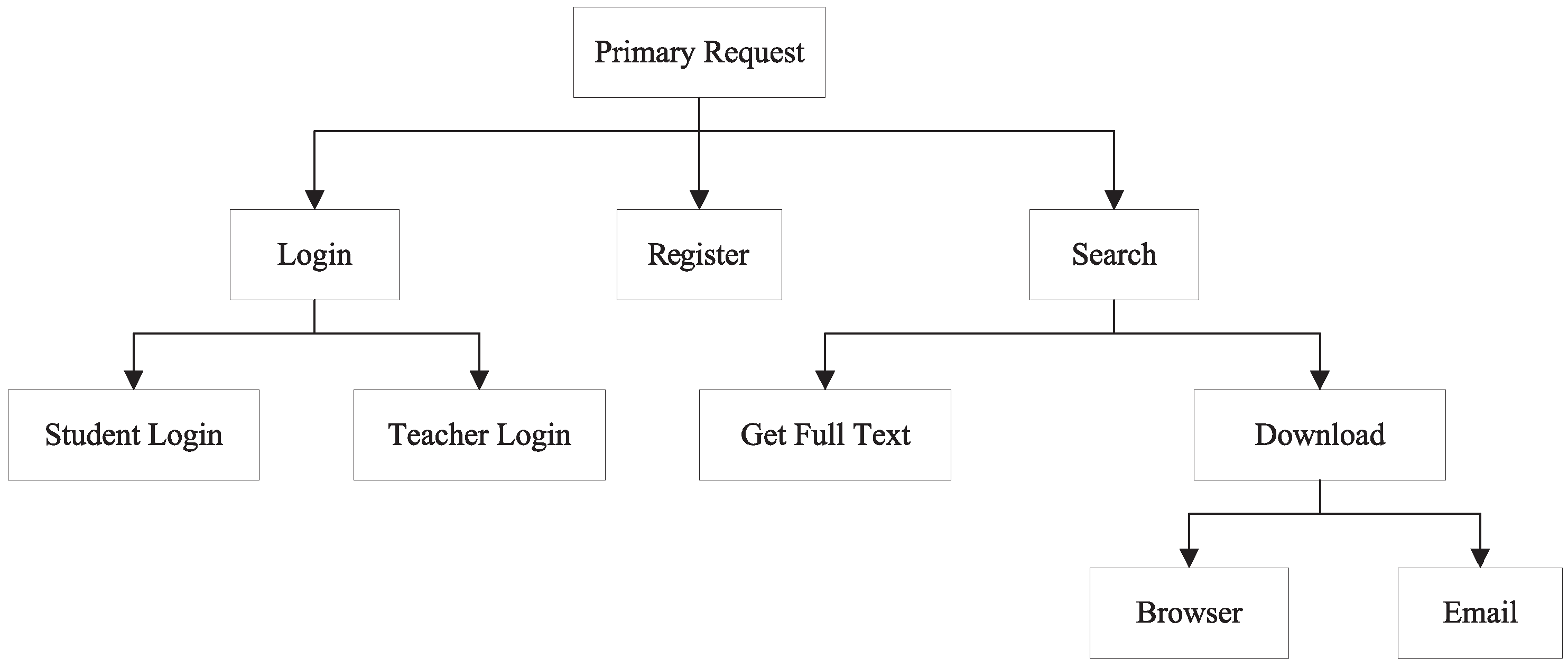
4. Experiments
4.1. Substitutability
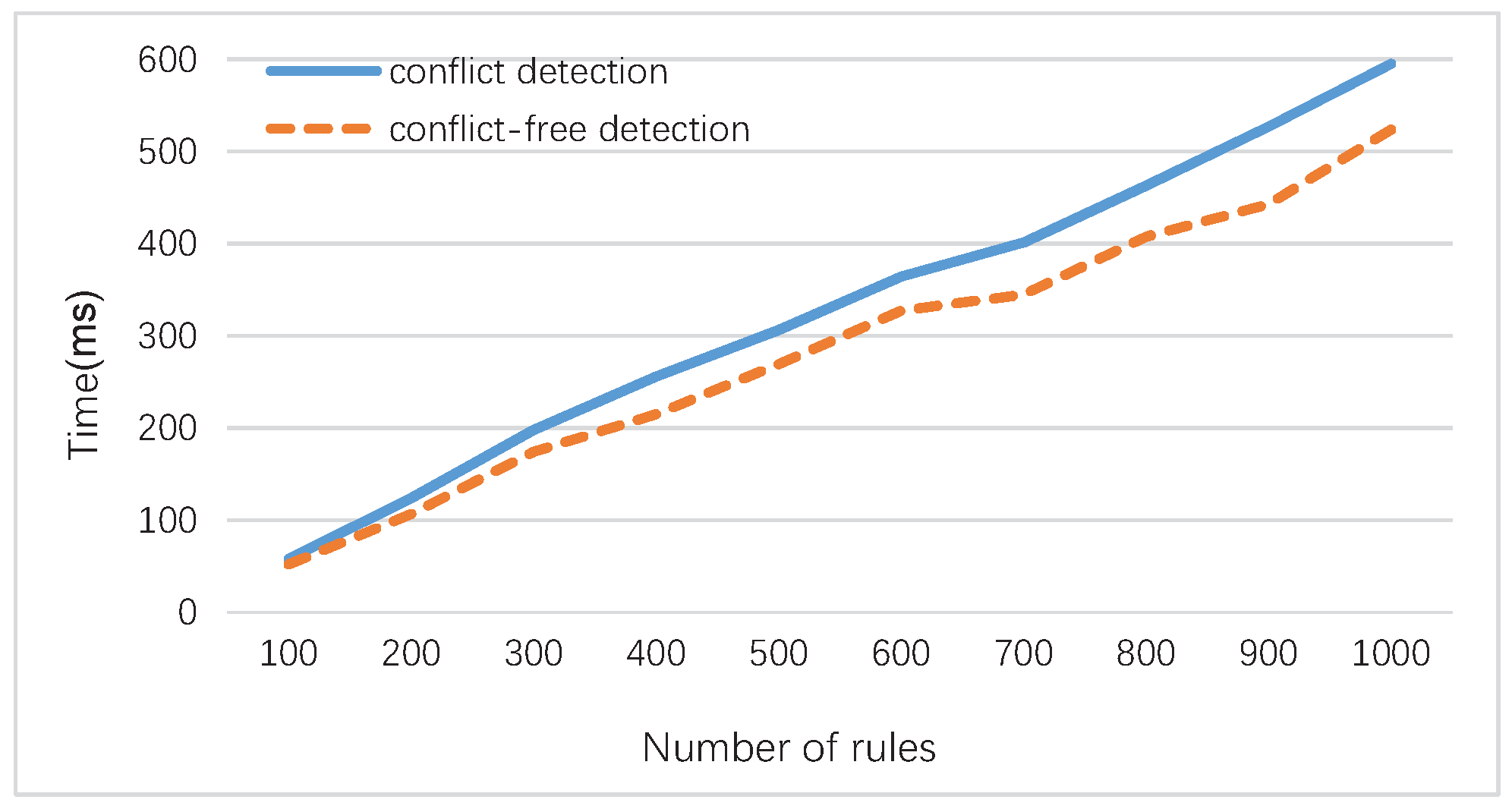
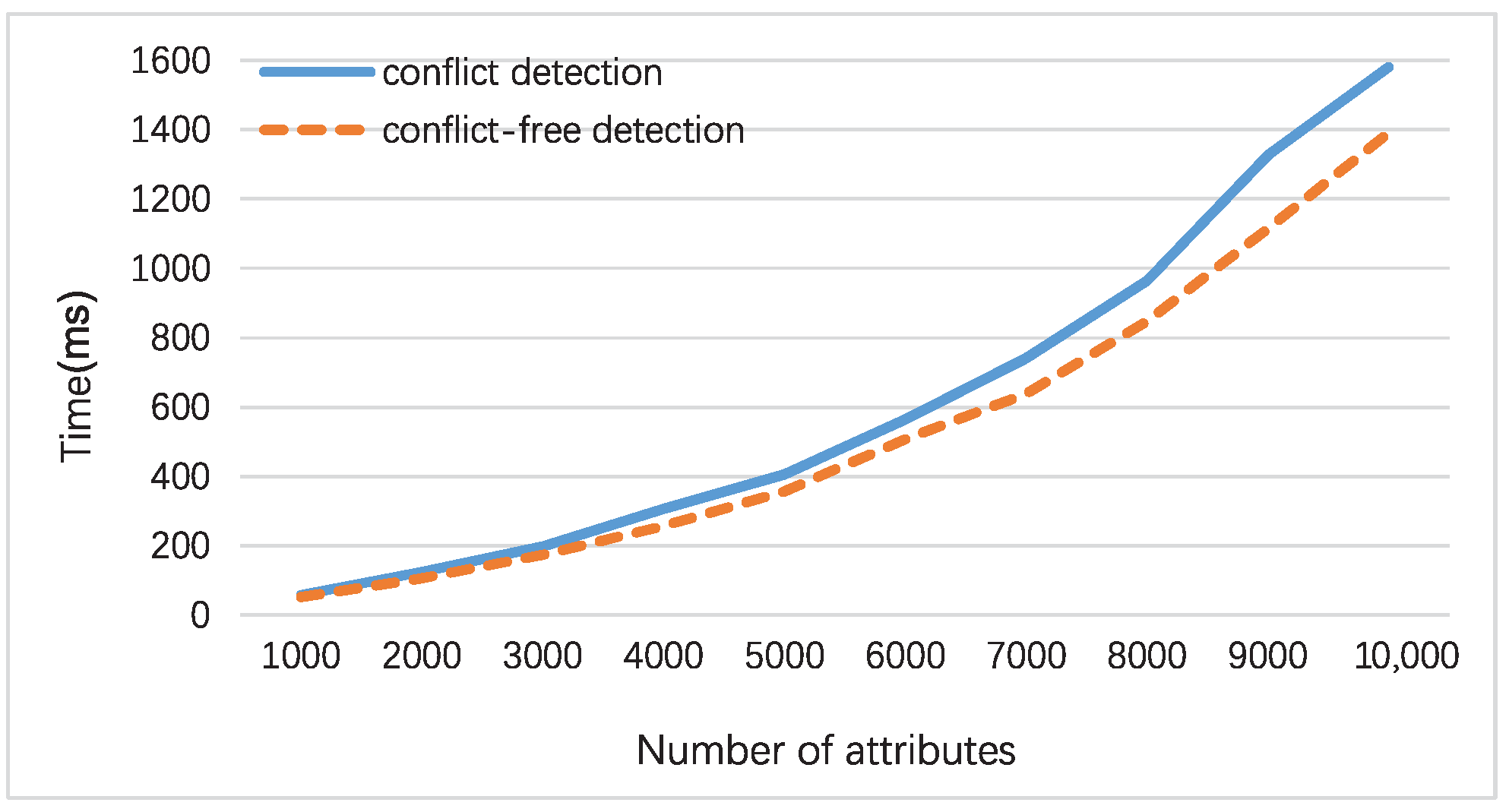
4.2. Time Complexity
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yuan, M.; Chen, L.; Yu, P.S.; Yu, T. Protecting Sensitive Labels in Social Network Data Anonymization. IEEE Trans. Knowl. Data Eng. 2013, 25, 633–647. [Google Scholar] [CrossRef]
- Michota, A.K.; Katsikas, S.K. Designing a seamless privacy policy for social networks. In Proceedings of the 19th Panhellenic Conference on Informatics (PCI 2015), Athens, Greece, 1–3 October 2015; Karanikolas, N.N., Akoumianakis, D., Nikolaidou, M., Vergados, D.D., Xenos, M., Giaglis, G.M., Gritzalis, S., Merakos, L.F., Tsanakas, P., Sgouropoulou, C., Eds.; ACM: New York, NY, USA, 2015; pp. 139–143. [Google Scholar]
- Zhang, L.; Yang, S.; Li, J.; Yu, L. A Particle Swarm Optimization Clustering-Based Attribute Generalization Privacy Protection Scheme. J. Circuits Syst. Comput. 2018, 27, 1850179:1–1850179:21. [Google Scholar] [CrossRef]
- Backstrom, L.; Dwork, C.; Kleinberg, J.M. Wherefore art thou R3579X?: Anonymized social networks, hidden patterns, and structural steganography. Commun. ACM 2011, 54, 133–141. [Google Scholar] [CrossRef]
- Martínez, S.; Sánchez, D.; Valls, A. A semantic framework to protect the privacy of electronic health records with non-numerical attributes. J. Biomed. Inform. 2013, 46, 294–303. [Google Scholar] [CrossRef] [Green Version]
- Xia, Z.; Wang, X.; Zhang, L.; Qin, Z.; Sun, X.; Ren, K. A Privacy-Preserving and Copy-Deterrence Content-Based Image Retrieval Scheme in Cloud Computing. IEEE Trans. Inf. Forensics Secur. 2016, 11, 2594–2608. [Google Scholar] [CrossRef]
- Wang, M.; Liu, D.; Zhu, L.; Xu, Y.; Wang, F. LESPP: Lightweight and efficient strong privacy preserving authentication scheme for secure VANET communication. Computing 2016, 98, 685–708. [Google Scholar] [CrossRef]
- Li, Y.; Dai, W.; Ming, Z.; Qiu, M. Privacy Protection for Preventing Data Over-Collection in Smart City. IEEE Trans. Comput. 2016, 65, 1339–1350. [Google Scholar] [CrossRef]
- Emara, K.; Woerndl, W.; Schlichter, J.H. Vehicle tracking using vehicular network beacons. In Proceedings of the IEEE 14th International Symposium on “A World of Wireless, Mobile and Multimedia Networks” (WoWMoM 2013), Madrid, Spain, 4–7 June 2013; IEEE Computer Society: Washington, DC, USA, 2013; pp. 1–6. [Google Scholar]
- Krontiris, I.; Langheinrich, M.; Shilton, K. Trust and privacy in mobile experience sharing: Future challenges and avenues for research. IEEE Commun. Mag. 2014, 52, 50–55. [Google Scholar] [CrossRef]
- Fu, Z.; Sun, X.; Liu, Q.; Zhou, L.; Shu, J. Achieving Efficient Cloud Search Services: Multi-Keyword Ranked Search over Encrypted Cloud Data Supporting Parallel Computing. IEICE Trans. Commun. 2015, 98-B, 190–200. [Google Scholar] [CrossRef]
- Samarati, P. Protecting Respondents’ Identities in Microdata Release. IEEE Trans. Knowl. Data Eng. 2001, 13, 1010–1027. [Google Scholar] [CrossRef] [Green Version]
- Sweeney, L. k-Anonymity: A Model for Protecting Privacy. Int. J. Uncertain. Fuzziness Knowl. Based Syst. 2002, 10, 557–570. [Google Scholar] [CrossRef] [Green Version]
- Machanavajjhala, A.; Kifer, D.; Gehrke, J.; Venkitasubramaniam, M. L-diversity: Privacy beyond k-anonymity. ACM Trans. Knowl. Discov. Data 2007, 1, 3. [Google Scholar] [CrossRef]
- Li, N.; Li, T.; Venkatasubramanian, S. t-Closeness: Privacy Beyond k-Anonymity and l-Diversity. In Proceedings of the 23rd International Conference on Data Engineering (ICDE 2007), The Marmara Hotel, Istanbul, Turkey, 15–20 April 2007; Chirkova, R., Dogac, A., Özsu, M.T., Sellis, T.K., Eds.; IEEE Computer Society: Washington, DC, USA, 2007; pp. 106–115. [Google Scholar]
- Zhao, J.; Chen, Y.; Zhang, W. Differential Privacy Preservation in Deep Learning: Challenges, Opportunities and Solutions. IEEE Access 2019, 7, 48901–48911. [Google Scholar] [CrossRef]
- Sankar, L.; Rajagopalan, S.R.; Poor, H.V. Utility-Privacy Tradeoffs in Databases: An Information-Theoretic Approach. IEEE Trans. Inf. Forensics Secur. 2013, 8, 838–852. [Google Scholar] [CrossRef] [Green Version]
- Lejun, F.; Yuanzhuo, W.; Xiaolong, J.; Jingyuan, L.; Xueqi, C.; Shuyuan, J.; Francesco, P. Comprehensive Quantitative Analysis on Privacy Leak Behavior. PLoS ONE 2013, 8, e73410. [Google Scholar]
- Kokolakis, S. Privacy attitudes and privacy behaviour: A review of current research on the privacy paradox phenomenon. Comput. Secur. 2017, 64, 122–134. [Google Scholar] [CrossRef]
- Wang, X.; Ishii, H.; He, J.; Cheng, P. Dynamic Privacy-preserving Collaborative Schemes for Average Computation. IFAC-PapersOnLine 2020, 53, 2963–2968. [Google Scholar] [CrossRef]
- Young, A.L.; Quan-Haase, A. Privacy protection strategies on facebook. Inf. Commun. Soc. 2013, 16, 479–500. [Google Scholar] [CrossRef]
- Aghili, S.F.; Sedaghat, M.; Singelée, D.; Gupta, M. MLS-ABAC: Efficient Multi-Level Security Attribute-Based Access Control scheme. Future Gener. Comput. Syst. 2022, 131, 75–90. [Google Scholar] [CrossRef]
- Wang, H.; Sun, L.; Bertino, E. Building access control policy model for privacy preserving and testing policy conflicting problems. J. Comput. Syst. Sci. 2014, 80, 1493–1503. [Google Scholar] [CrossRef]
- Maskell, S.; Everitt, R.G.; Wright, R.; Briers, M. Multi-target out-of-sequence data association: Tracking using graphical models. Inf. Fusion 2006, 7, 434–447. [Google Scholar] [CrossRef]
- Ji, Z.; Wu, Q.M.J. An improved artificial immune algorithm with application to multiple sensor systems. Inf. Fusion 2010, 11, 174–182. [Google Scholar] [CrossRef]
- Yang, S.; Wang, M.; Jiao, L.; Wu, R.; Wang, Z. Image fusion based on a new contourlet packet. Inf. Fusion 2010, 11, 78–84. [Google Scholar] [CrossRef]
- Kinnunen, T.; Li, H. An overview of text-independent speaker recognition: From features to supervectors. Speech Commun. 2010, 52, 12–40. [Google Scholar] [CrossRef] [Green Version]
- Bigot, A.; Chrisment, C.; Dkaki, T.; Hubert, G.; Mothe, J. Fusing different information retrieval systems according to query-topics: A study based on correlation in information retrieval systems and TREC topics. Inf. Retr. 2011, 14, 617–648. [Google Scholar] [CrossRef]
- Macdonald, C. The voting model for people search. SIGIR Forum 2009, 43, 73. [Google Scholar] [CrossRef]
- Wu, S. Applying the data fusion technique to blog opinion retrieval. Expert Syst. Appl. 2012, 39, 1346–1353. [Google Scholar] [CrossRef]
- Nuray, R.; Can, F. Automatic ranking of information retrieval systems using data fusion. Inf. Process. Manag. 2006, 42, 595–614. [Google Scholar] [CrossRef] [Green Version]
- Fox, E.A.; Koushik, M.P.; Shaw, J.A.; Modlin, R.; Rao, D. Combining Evidence from Multiple Searches. In Proceedings of the First Text REtrieval Conference (TREC 1992), Gaithersburg, MD, USA, 4–6 November 1992; Harman, D.K., Ed.; National Institute of Standards and Technology (NIST): Gaithersburg, MD, USA, 1992; Volume 500-207, pp. 319–328. [Google Scholar]
- Vogt, C.C.; Cottrell, G.W. Predicting the Performance of Linearly Combined IR Systems. In Proceedings of the SIGIR ’98: Proceedings of the 21st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Melbourne, Australia, 24–28 August 1998; Croft, W.B., Moffat, A., van Rijsbergen, C.J., Wilkinson, R., Zobel, J., Eds.; ACM: New York, NY, USA, 1998; pp. 190–196. [Google Scholar]
- Wu, S.; McClean, S.I. Performance prediction of data fusion for information retrieval. Inf. Process. Manag. 2006, 42, 899–915. [Google Scholar] [CrossRef]
- Aslam, J.A.; Montague, M.H. Models for Metasearch. In Proceedings of the 24th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, New Orleans, LA, USA, 9–13 September 2001; Croft, W.B., Harper, D.J., Kraft, D.H., Zobel, J., Eds.; ACM: New York, NY, USA, 2001; pp. 275–284. [Google Scholar]
- Montague, M.H.; Aslam, J.A. Condorcet fusion for improved retrieval. In Proceedings of the 2002 ACM CIKM International Conference on Information and Knowledge Management, McLean, VA, USA, 4–9 November 2002; ACM: New York, NY, USA, 2002; pp. 538–548. [Google Scholar]
- Lillis, D.; Zhang, L.; Toolan, F.; Collier, R.W.; Leonard, D.; Dunnion, J. Estimating probabilities for effective data fusion. In Proceeding of the 33rd International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 2010), Geneva, Switzerland, 19–23 July 2010; Crestani, F., Marchand-Maillet, S., Chen, H., Efthimiadis, E.N., Savoy, J., Eds.; ACM: New York, NY, USA, 2010; pp. 347–354. [Google Scholar]
- Wu, S.; Bi, Y.; Zeng, X.; Han, L. Assigning appropriate weights for the linear combination data fusion method in information retrieval. Inf. Process. Manag. 2009, 45, 413–426. [Google Scholar] [CrossRef]
- Wu, S. Linear combination of component results in information retrieval. Data Knowl. Eng. 2012, 71, 114–126. [Google Scholar] [CrossRef]
- Ruiz, M.D.; Gómez-Romero, J.; Molina-Solana, M.; Ros, M.; Martín-Bautista, M.J. Information fusion from multiple databases using meta-association rules. Int. J. Approx. Reason. 2017, 80, 185–198. [Google Scholar] [CrossRef] [Green Version]





{kind=link}
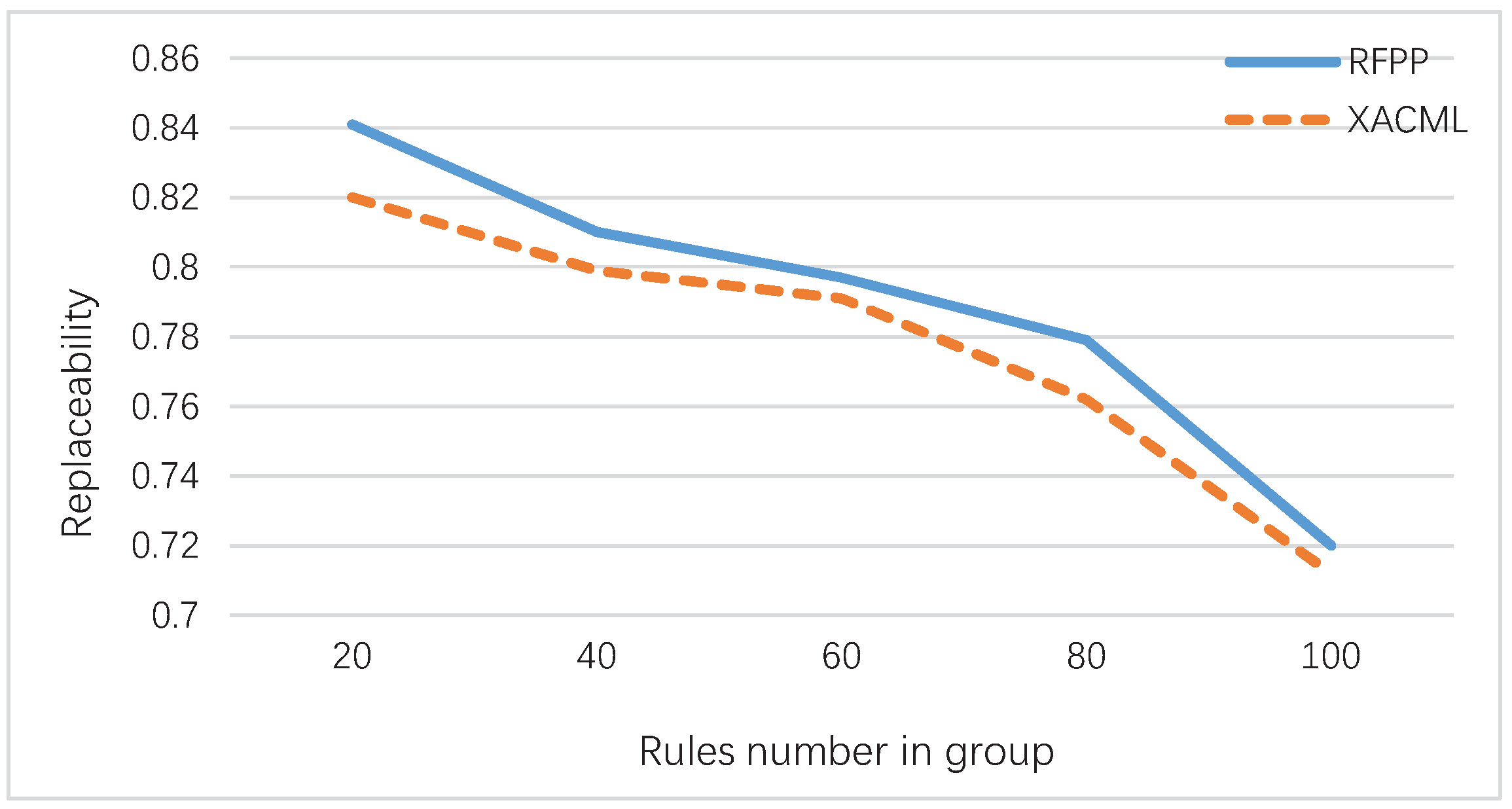{kind=link}
{kind=link}
{kind=link}
| Rule Elements: Object S; User s; Time t. |
|---|
| (1) person(s) ∧ object(S) |
| (2) student(s) ∧school(S) |
| (3) statusIn(s,S) ∧ inCampusNetwork(s, S) |
| (4) timeAfter(9) ∧ timeBefore(21) |
| (5) school(S) ∧ openLibarayAcess(S) requester(s) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, T.; Su, Y.; Rong, H.; Qian, Y.; Al-Nabhan, N. Rule Fusion of Privacy Protection Strategies for Co-Ownership Data Sharing. Mathematics 2022, 10, 969. https://doi.org/10.3390/math10060969
Ma T, Su Y, Rong H, Qian Y, Al-Nabhan N. Rule Fusion of Privacy Protection Strategies for Co-Ownership Data Sharing. Mathematics. 2022; 10(6):969. https://doi.org/10.3390/math10060969
Chicago/Turabian StyleMa, Tinghuai, Yuming Su, Huan Rong, Yurong Qian, and Najla Al-Nabhan. 2022. "Rule Fusion of Privacy Protection Strategies for Co-Ownership Data Sharing" Mathematics 10, no. 6: 969. https://doi.org/10.3390/math10060969