
Clustering Based on Continuous Hopfield Network

Abstract
:1. Introduction
- The clustering problem is reformulated as an integer optimization problem and solved by the continuous Hopfield neural network.
- By comparing to the other clustering algorithms, our clustering algorithm achieves the better clustering performance.
2. Preliminaries
2.1. Dissimilarity Coefficients
2.2. Continuous Hopfield Neural Network
- The diagonal element T should be all zeros.
- The T should be symmetric.
2.3. Problem Formulations
2.3.1. Objection Function
2.3.2. Problem Reformulation
3. Algorithm Description

4. Experiment
4.1. Experimental Setups
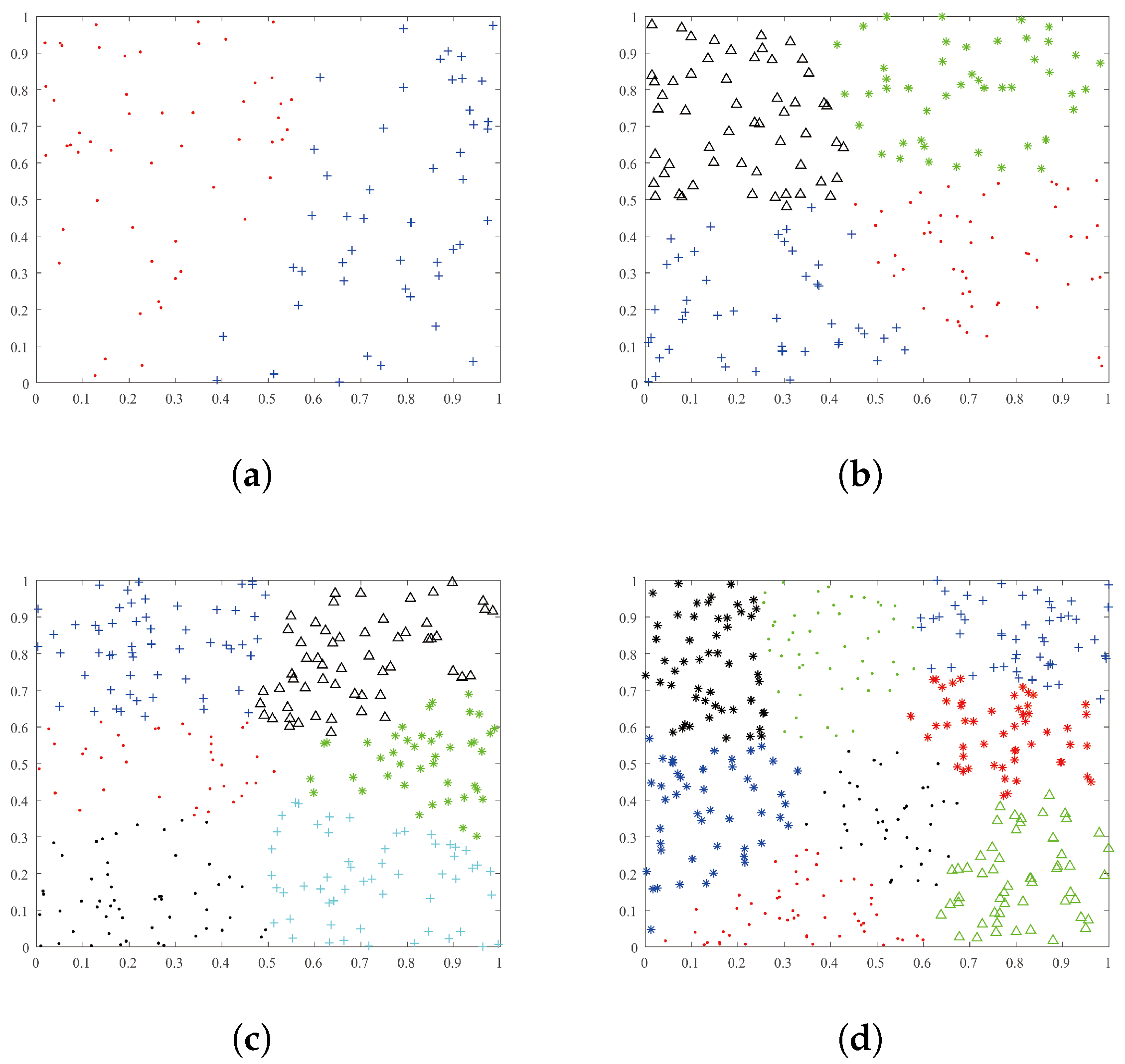
4.2. Numerical Experiment
- The clustering result of our method is satisfactory for different instances with different classes.
- Our method obtains ideal clustering results for multi-class instances.
4.3. Real Datasets Experiment
4.3.1. Evaluation Indices
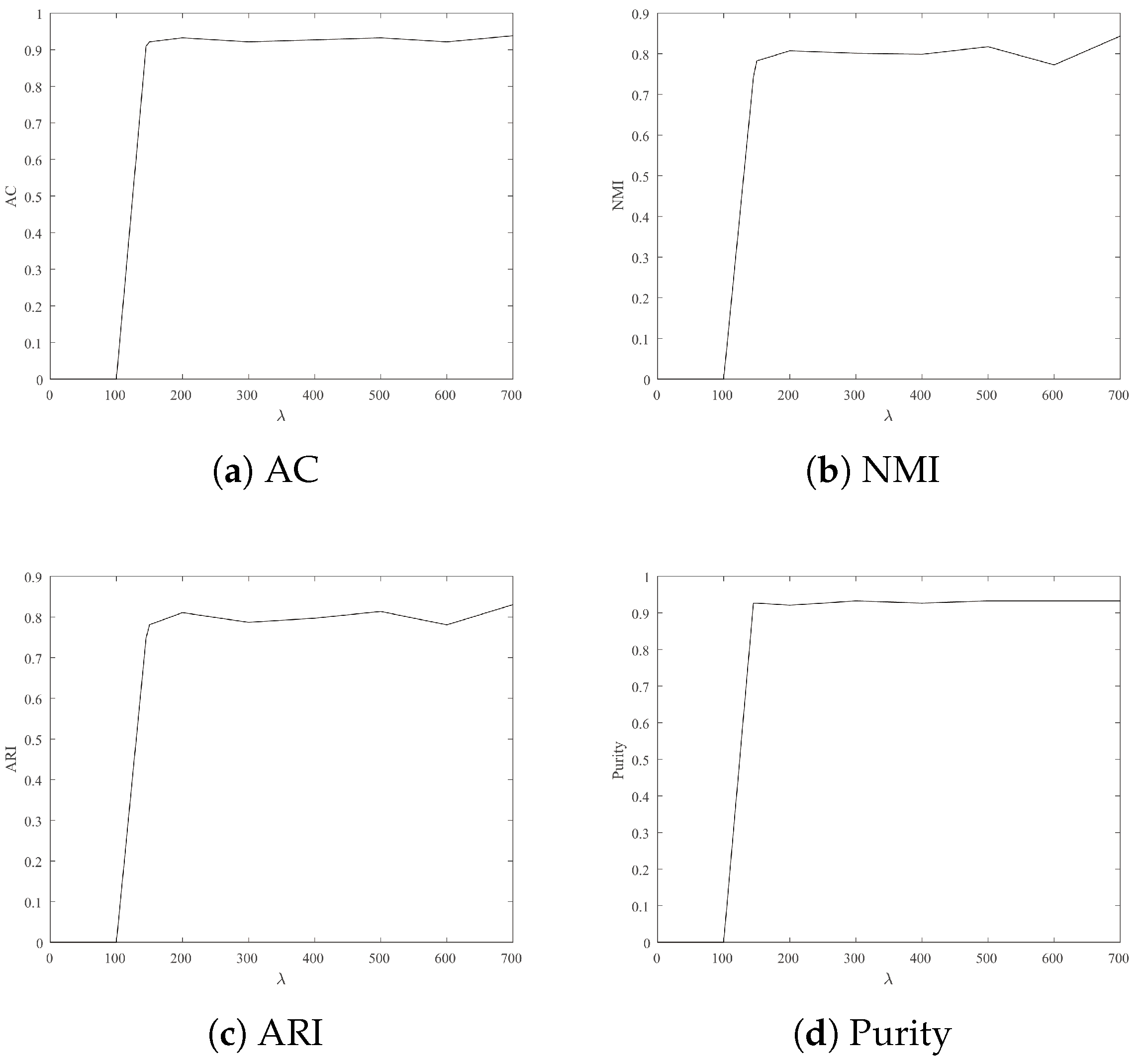
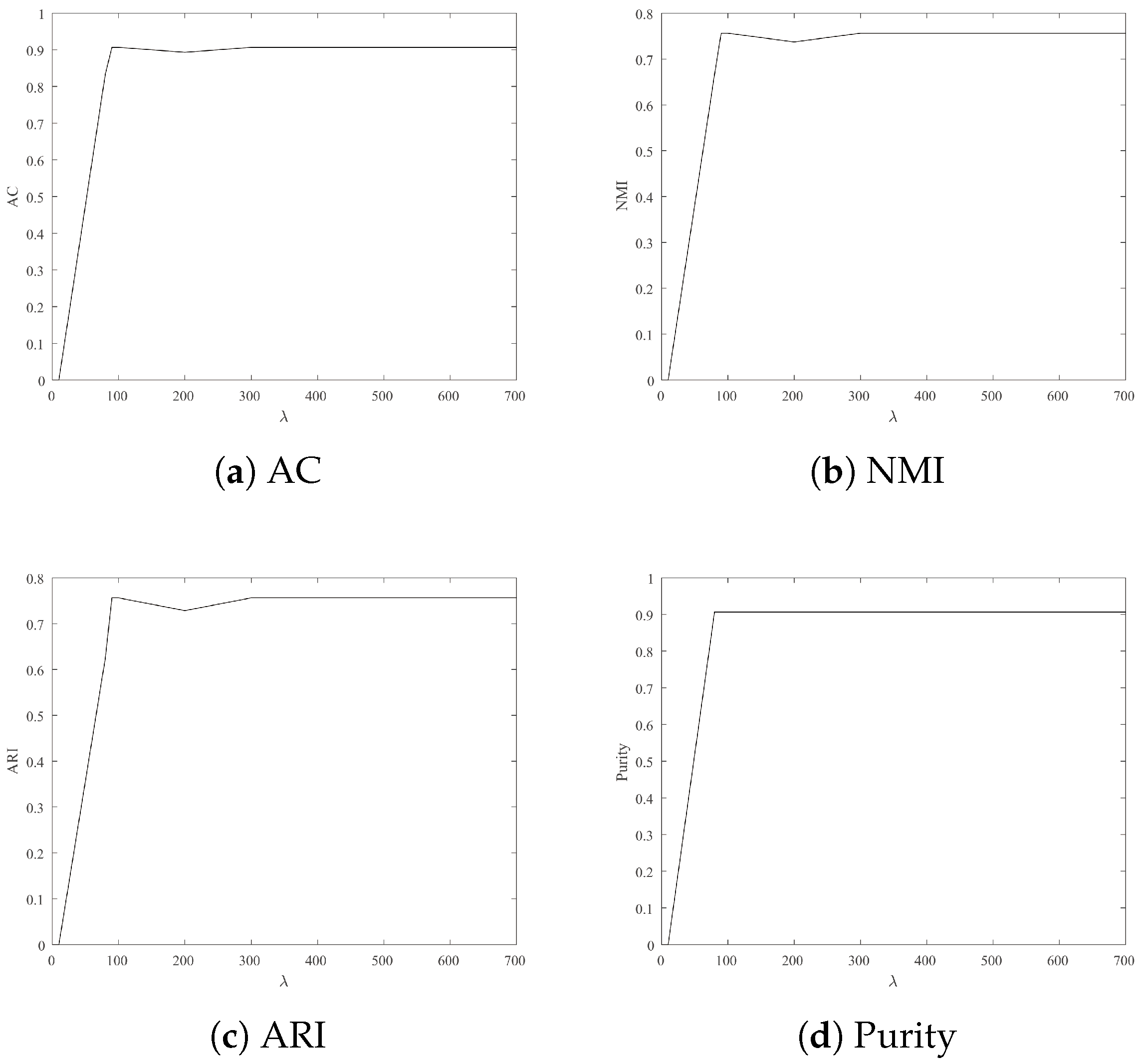
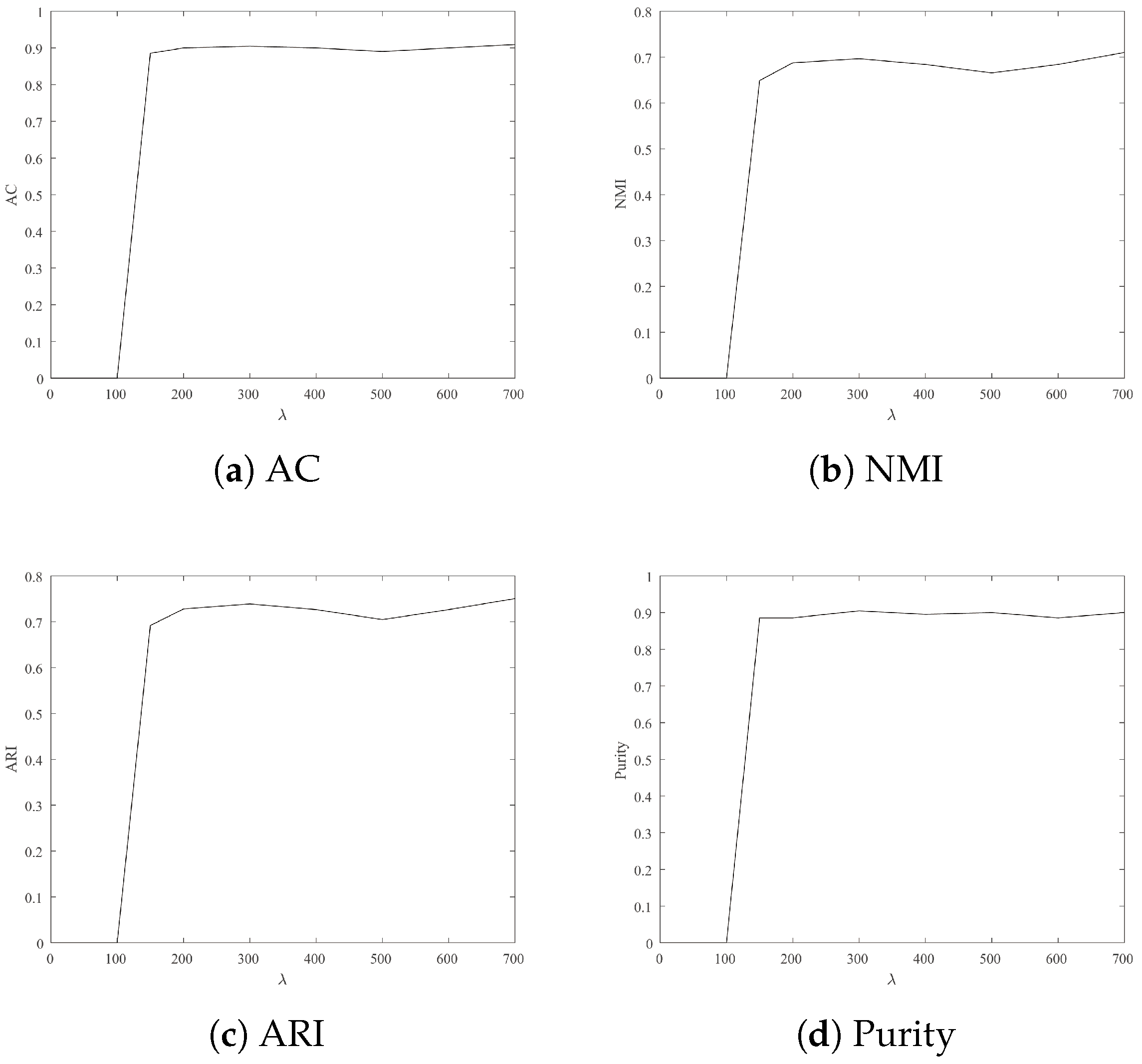
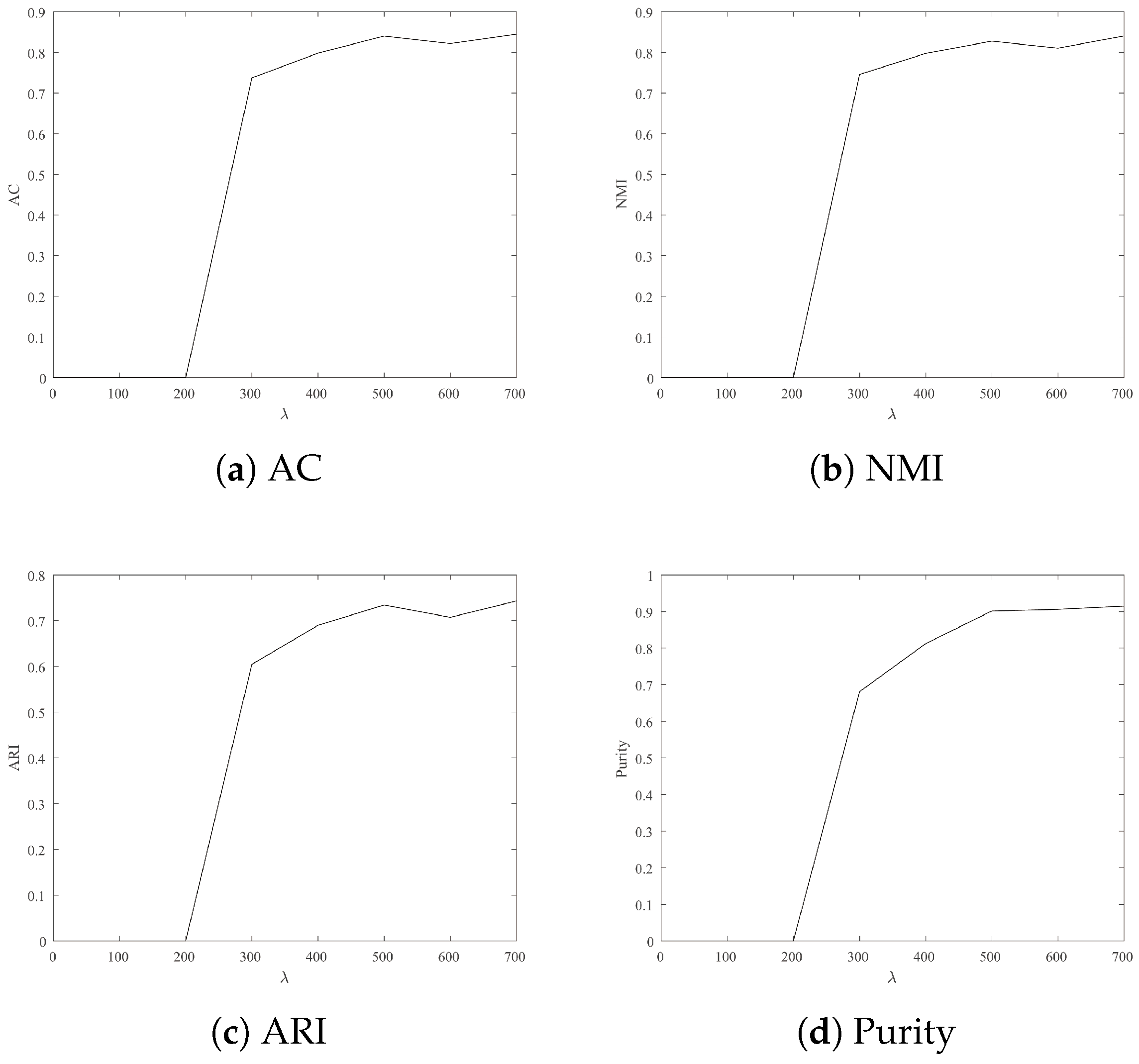
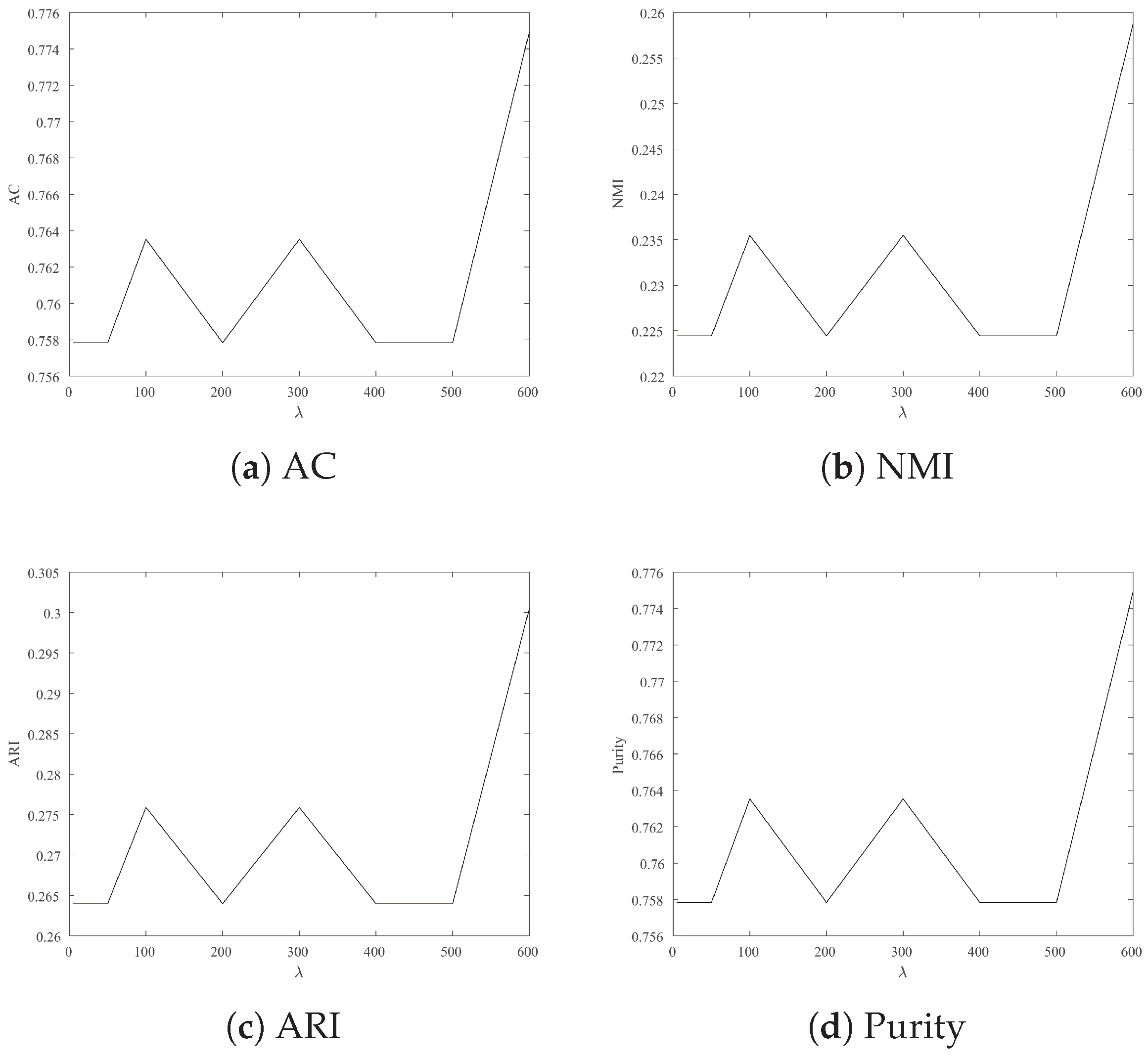
4.3.2. Parameter Sensitivity
- For Wine, Iris and Seeds, the clustering results are more satisfactory when is 700.
- For Jacc_face and Ionosphere, the larger leads to better clustering results.
4.3.3. Experiment Results
5. Conclusions and Future Work
- Other neural networks can be used to solve clustering problems.
- We are exploring how to effectively combine Hopfield Neural Network with Swarm Intelligence methods.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shaheen, M.; ur Rehman, S.; Ghaffar, F. Correlation and congruence modulo based clustering technique and its application in energy classification. Sustain. Comput. Inform. Syst. 2021, 30, 100561. [Google Scholar] [CrossRef]
- Abdullah, D.; Susilo, S.; Ahmar, A.S.; Rusli, R.; Hidayat, R. The application of K-means clustering for province clustering in Indonesia of the risk of the COVID-19 pandemic based on COVID-19 data. Qual. Quant. 2021; Online ahead of print. [Google Scholar] [CrossRef]
- Yeoh, J.M.; Caraffini, F.; Homapour, E.; Santucci, V.; Milani, A. A clustering system for dynamic data streams based on metaheuristic optimisation. Mathematics 2019, 7, 1229. [Google Scholar] [CrossRef] [Green Version]
- Ng, A.Y.; Jordan, M.I.; Weiss, Y. On spectral clustering: Analysis and an algorithm. Adv. Neural Inf. Process. Syst. 2002, 14, 849–856. [Google Scholar]
- Chen, W.Y.; Song, Y.; Bai, H.; Lin, C.J.; Chang, E.Y. Parallel spectral clustering in distributed systems. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 568–586. [Google Scholar] [CrossRef] [PubMed]
- Chan, P.K.; Schlag, M.D.; Zien, J.Y. Spectral k-way ratio-cut partitioning and clustering. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 1994, 13, 1088–1096. [Google Scholar] [CrossRef]
- Shi, J.; Malik, J. Normalized cuts and image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 888–905. [Google Scholar]
- Ding, C.H.; He, X.; Zha, H.; Gu, M.; Simon, H.D. A min-max cut algorithm for graph partitioning and data clustering. In Proceedings of the 2001 IEEE International Conference on Data Mining, San Jose, CA, USA, 29 November–2 December 2001; pp. 107–114. [Google Scholar]
- Nie, F.; Wang, X.; Huang, H. Clustering and projected clustering with adaptive neighbors. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 977–986. [Google Scholar]
- Wang, Y.; Wu, L. Beyond low-rank representations: Orthogonal clustering basis reconstruction with optimized graph structure for multi-view spectral clustering. Neural Netw. 2018, 103, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Fang, Z. Parallel clustering algorithms. Parallel Comput. 1989, 11, 275–290. [Google Scholar] [CrossRef]
- Grygorash, O.; Zhou, Y.; Jorgensen, Z. Minimum spanning tree based clustering algorithms. In Proceedings of the 18th IEEE International Conference on Tools with Artificial Intelligence (ICTAI’06), Arlington, VA, USA, 13–15 November 2006; pp. 73–81. [Google Scholar]
- Dai, X.; Zhang, K.; Li, J.; Xiong, J.; Zhang, N. Robust Graph Regularized Non-negative Matrix Factorization for Image Clustering. ACM Trans. Knowl. Discov. Data 2020, 3, 244–250. [Google Scholar]
- Dai, X.; Zhang, N.; Zhang, K.; Xiong, J. Weighted Nonnegative Matrix Factorization for Image Inpainting and Clustering. Int. J. Comput. Intell. Syst. 2020, 13, 734–743. [Google Scholar] [CrossRef]
- Malinen, M.I.; Fränti, P. Balanced K-Means for Clustering. In Joint Iapr International Workshops on Statistical Techniques in Pattern Recognition (SPR) and Structural and Syntactic Pattern Recognition (SSPR); Springer: Berlin/Heidelberg, Germany, 2014; pp. 32–41. [Google Scholar]
- Bauckhage, C.; Piatkowski, N.; Sifa, R.; Hecker, D.; Wrobel, S. A QUBO Formulation of the k-Medoids Problem. In Proceedings of the LWDA/KDML 2019, Berlin, Germany, 30 September–2 October 2019. [Google Scholar]
- Date, P.; Arthur, D.; Pusey-NAzzaro, L. QUBO Formulations for Training Machine Learning Models. Sci. Rep. 2020, 11, 10029. [Google Scholar] [CrossRef] [PubMed]
- Hopfield, J.J.; Tank, D.W. Computing with neural circuits: A model. Science 1986, 233, 625–633. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kamgar-Parsi, B.; Gualtieri, J.; Devaney, J.; Kamgar-Parsi, B. Clustering with neural networks. Biol. Cybern. 1990, 63, 201–208. [Google Scholar] [CrossRef]
- Mulder, S.A.; Wunsch, D.C. Million city traveling salesman problem solution by divide and conquer clustering with adaptive resonance neural networks. Neural Netw. 2003, 16, 827–832. [Google Scholar] [CrossRef]
- Bakker, B.; Heskes, T. Clustering ensembles of neural network models. Neural Netw. 2003, 16, 261–269. [Google Scholar] [CrossRef]
- Du, K.L. Clustering: A neural network approach. Neural Netw. 2010, 23, 89–107. [Google Scholar] [CrossRef] [PubMed]
- Xu, J.; Xu, B.; Wang, P.; Zheng, S.; Tian, G.; Zhao, J. Self-taught convolutional neural networks for short text clustering. Neural Netw. 2017, 88, 22–31. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Talaván, P.M.; Yáñez, J. The generalized quadratic knapsack problem. A neuronal network approach. Neural Netw. 2006, 19, 416–428. [Google Scholar] [CrossRef]
- Zhang, H.; Wang, Z.; Liu, D. A Comprehensive Review of Stability Analysis of Continuous-Time Recurrent Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2014, 25, 1229–1262. [Google Scholar] [CrossRef]
- Talavan, P.M.; Yanez, J. A continuous Hopfield network equilibrium points algorithm. Comput. Oper. Res. 2005, 32, 2179–2196. [Google Scholar] [CrossRef]
- Wold, S.; Esbensen, K.; Geladi, P. Principal component analysis. Chemom. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar] [CrossRef]
- Hartigan, J.A.; Wong, M.A. Algorithm AS 136: A k-means clustering algorithm. J. R. Stat. Soc. Ser. C Appl. Stat. 1979, 28, 100–108. [Google Scholar] [CrossRef]
- Arthur, D.; Vassilvitskii, S. k-means++: The advantages of careful seeding. In Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, New Orleans, LO, USA, 7–9 January 2007. [Google Scholar]
- Ball, G.H.; Hall, D.J. ISODATA, a Novel Method of Data Analysis and Pattern Classification; Stanford Research Institute: Menlo Park, CA, USA, 1965. [Google Scholar]
- Cai, D.; He, X.; Han, J. Document clustering using locality preserving indexing. IEEE Trans. Knowl. Data Eng. 2005, 17, 1624–1637. [Google Scholar] [CrossRef] [Green Version]
- Santos, J.M.; Embrechts, M. On the use of the adjusted rand index as a metric for evaluating supervised classification. In International Conference on Artificial Neural Networks; Springer: Berlin/Heidelberg, Germany, 2009; pp. 175–184. [Google Scholar]
- Rendon, E.; Abundez, I.; Arizmendi, A.; Quiroz, E.M. Internal versus external cluster validation indexes. Int. J. Comput. Commun. 2011, 5, 27–34. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Instances | Class | Dimensions |
|---|---|---|---|
| Ionosphere | 252 | 2 | 30 |
| Wine | 178 | 3 | 13 |
| Iris | 150 | 3 | 4 |
| Seeds | 210 | 3 | 4 |
| Jaffe_face | 213 | 10 | 676 |
| Datasets | iter | ||||
|---|---|---|---|---|---|
| Wine | 700 | 0.025 | 0.0025 | 15,000 | 1.5 |
| Iris | 700 | 0.025 | 0.0021 | 10,000 | 0.08 |
| Seeds | 700 | 0.025 | 0.0026 | 15,000 | 0.2 |
| Jacc_face | 700 | 0.03 | 0.00091 | 20,000 | 0.2 |
| Ionosphere | 600 | 0.025 | 0.0025 | 20,000 | 0.5 |
| Index | Definition | Rule to Indicate the Best Clusters |
|---|---|---|
| Normalized Mutual Information (NMI) | where | max |
| Accuracy (AC) | where | max |
| Adjusted Rand Index (ARI) | max | |
| Purity | max |
| Algorithm | CHN | Kmeans | Kmeans | Isodata |
|---|---|---|---|---|
| NMI(%) | 81.40/84.35/77.27 ± 2.10 | 67.36/77.53/38.50 ± 11.94 | 67.43/77.53/60.44 ± 7.03 | 46.93/72.57/30.52 ± 13.48 |
| AC(%) | 93.09/93.82/92.13 ± 0.53 | 84.66/93.26/55.05 ± 11.63 | 85.62/93.26/81.46 ± 5.30 | 66.97/92.13/54.49 ± 13.08 |
| ARI(%) | 80.96/83.04/78.08 ± 1.47 | 63.83/79.61/29.99 ± 16.47 | 62.59/79.61/55.52 ± 11.79 | 38.86/76.84/17.61 ± 17.84 |
| Purity(%) | 93.09/93.82/92.13 ± 0.53 | 85.84/93.25/66.85 ± 8.46 | 85.62/93.25/81.46 ± 5.30 | 69.72/92.13/59.55 ± 11.04 |
| Algorithm | CHN | Kmeans | Kmeans | Isodata |
|---|---|---|---|---|
| NMI(%) | 26.25/22.44/23.26 ± 1.19 | 20.67/20.38/20.55 ± 0.15 | 20.67/20.38/20.58 ± 0.14 | 25.30/2.69/14.35 ± 8.69 |
| AC(%) | 77.78/75.78/76.21 ± 0.62 | 64.10/63.81/63.99 ± 0.15 | 64.10/63.81/64.10 ± 0.14 | 68.37/53.00/60.60 ± 3.94 |
| ARI(%) | 30.68/26.39/27.30 ± 1.32 | 6.48/6.12/6.33 ± 0.18 | 6.48/6.12/6.37 ± 0.17 | 12.55/−4.79/1.52 ± 5.41 |
| Purity(%) | 77.77/75.78/76.21 ± 0.62 | 64.10/64.10/64.10 ± 0 | 64.10/64.10/64.10 ± 0 | 68.37/64.10/64.52 ± 1.35 |
| Algorithm | CHN | Kmeans | Kmeans | Isodata |
|---|---|---|---|---|
| NMI(%) | 26.25/22.44/23.26 ± 1.19 | 20.67/20.38/20.55 ± 0.15 | 20.67/20.38/20.58 ± 0.14 | 25.30/2.69/14.35 ± 8.69 |
| AC(%) | 77.78/75.78/76.21 ± 0.62 | 64.10/63.81/63.99 ± 0.15 | 64.10/63.81/64.10 ± 0.14 | 68.37/53.00/60.60 ± 3.94 |
| ARI(%) | 30.68/26.39/27.30 ± 1.32 | 6.48/6.12/6.33 ± 0.18 | 6.48/6.12/6.37 ± 0.17 | 12.55/−4.79/1.52 ± 5.41 |
| Purity(%) | 77.77/75.78/76.21 ± 0.62 | 64.10/64.10/64.10 ± 0 | 64.10/64.10/64.10 ± 0 | 68.37/64.10/64.52 ± 1.35 |
| Algorithm | CHN | Kmeans | Kmeans | Isodata |
|---|---|---|---|---|
| NMI(%) | 67.35/71.02/64.90 ± 2.09 | 65.37/66.32/64.90 ± 0.68 | 65.75/66.32/64.90 ± 0.73 | 48.94/68.49/39.94 ± 8.35 |
| AC(%) | 89.57/90.95/88.57 ± 0.82 | 88.91/89.52/88.57 ± 0.45 | 89.14/89.53/88.57 ± 0.49 | 71.52/88.57/54.76 ± 10.71 |
| ARI(%) | 71.62/75.06/69.19 ± 2.01 | 69.99/71.47/69.19 ± 1.08 | 70.56/71.47/69.19 ± 1.18 | 46.18/69.64/35.33 ± 10.84 |
| Purity(%) | 89.57/90.95/88.57 ± 0.82 | 88.90/89.52/88.57 ± 0.45 | 89.14/89.52/88.57 ±0.49 | 72.90/88.57/62.38 ± 8.90 |
| Algorithm | CHN | Kmeans | Kmeans | Isodata |
|---|---|---|---|---|
| NMI(%) | 75.54/75.64/74.65 ± 0.31 | 74.76/75.14/74.50 ± 0.33 | 74.82/75.15/74.51 ± 0.33 | 63.21/78.37/47.81 ± 9.56 |
| AC(%) | 90.60/90.67/90 ± 0.21 | 89.33/89.33/89.33 ± 0 | 89.33/89.33/89.33 ± 0 | 76.00/92.00/51.33 ± 11.89 |
| ARI(%) | 75.47/75.64/74.20 ± 0.45 | 72.97/73.02/72.94 ± 0.04 | 72.98/73.02/72.94 ± 0.04 | 57.63/78.64/38.43 ± 12.47 |
| Purity(%) | 90.67/90.67/90.67 ± 0 | 89.33/89.33/89.33 ± 0 | 89.33/92.67/89.33 ± 1.27 | 77.60/92.67/66.67 ± 8.73 |
| Algorithm | CHN | Kmeans | Kmeans | Isodata |
|---|---|---|---|---|
| NMI(%) | 83.41/89.41/74.41 ± 4.45 | 82.19/88.88/74.16 ± 4.81 | 80.43/89.38/70.15 ± 5.57 | 70.38/83.43/50.79 ± 10.57 |
| AC(%) | 83.10/91.50/69.50 ± 6.67 | 76.85/87.00/65.00 ± 7.06 | 70.75/91.00/54.50 ± 9.58 | 64.75/81.00/38.00 ± 14.01 |
| ARI(%) | 73.83/83.79/58.28 ± 7.43 | 68.72/82.42/52.98 ± 9.15 | 65.08/81.52/48.12 ± 9.01 | 53.48/73.37/24.32 ± 15.67 |
| Purity(%) | 83.75/91.50/72.00 ± 5.76 | 79.85/87.50/73.00 ± 5.23 | 75.60/91.00/63.50 ± 7.59 | 69.30/83.50/46.50 ± 11.73 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiao, Y.; Zhang, Y.; Dai, X.; Yan, D. Clustering Based on Continuous Hopfield Network. Mathematics 2022, 10, 944. https://doi.org/10.3390/math10060944
Xiao Y, Zhang Y, Dai X, Yan D. Clustering Based on Continuous Hopfield Network. Mathematics. 2022; 10(6):944. https://doi.org/10.3390/math10060944
Chicago/Turabian StyleXiao, Yao, Yashu Zhang, Xiangguang Dai, and Dongfang Yan. 2022. "Clustering Based on Continuous Hopfield Network" Mathematics 10, no. 6: 944. https://doi.org/10.3390/math10060944