1. Introduction
Controlling chaos and nonlinear dynamics is a long-standing issue in various engineering disciplines, including aerospace systems design [
1]; chemical operations [
2]; robotics [
3]; biological sciences [
4]; mechatronics [
5]; and, in particular, microelectronics [
6], especially for circuits systems involving semiconductors that elicit nonlinearity for signal controls [
7,
8]. In mathematics, chaos is characterized by underlying patterns and deterministic laws that are highly sensitive to the initial conditions in dynamical systems and sometimes manifest as solutions for a differential equation (or a representation of the system) that do not converge to a stationary or periodic function of time but continue to exhibit seemingly unpredictable behavior [
9]. Controlling chaotic nonlinear dynamics has a simple objective: implementing the desired command in the system to make it behave “as we wish” or at least make it predictable so that helpless impotence can be eliminated. However arduous [
10], nonlinear control problems are ubiquitous in nature, occurring in fluid flows, heartbeat irregularities, weather, and climate [
11,
12,
13]. Hence, addressing such a problem is worthwhile.
Traditionally, proportional–integral–derivative controllers (PID) are used for controlling nonlinear systems [
14,
15], where closed-loop feedback errors are tuned using linearized versions of nonlinear, chaotic equations seeking to come as close to the targeted trajectory as possible [
16]. Such methods remain commonplace in industry. Notably, with such wide applications, PID control experiences sluggish and systematic performance due to the integral term, and increasing the order can lead to system instability [
17]. Admittedly, reducing PID to PI (proportional–integral) or P (proportional) might either increase the speed or system stability, but neither can learn the features of nonlinear systematic data, which allows more advanced self-adjust control behavior. Another common approach is to model the chaotic behaviors as periodic ones and implement trigonometric commands in hopes of producing predictable periodic system behavior [
18]. Model predictive controllers incorporate statistics seeking good results for fuzzy systems [
19].
In recent decades, the skyrocketing usage of big data, assisted by advanced computing technologies such as GPU computing [
20], has led to the enhancement of machine learning algorithms—specifically, deep neural networks [
21]. Deep neural networks can learn and capture features from highly nonlinear data for accurate predictions, indicating their huge potential and attracting a great deal of attention in various fields. Encoding physics information in the losses of a deep neural network (NN) promises the faster, accurate learning of physics with neural networks by respecting the basic laws of physics using less labeled data, commonly recognized as Physics-Informed Neural Networks (PINNs) [
22,
23]. One of the most celebrated characteristics of PINNs is their ability to learn from sparse data [
24]. Upon the proposed PINN framework, various PINNs designed for disparate engineering applications have emerged. Perhaps their most renowned use is in predicting fluid fields [
25,
26], but other notable uses include electronics applications [
27,
28]. Notably, there have been a few attempts to use the PINN-based method to learn and predict nonlinear dynamical systems and chaos [
29,
30,
31,
32], with a notable good attempt by Antonelo et al. [
33] to modify PINN to adjust systematic controls based on the predictions of PINN. Furthermore, PINN has been used to learn controls for a series of optimal planar orbit transfer problems [
34]. However, most applications focus on the “learning” and “discovery” of dynamics with PINNs, while few actually focus on “controlling” the system—that is, guiding the system to behave as human-desired signals. Attempts have been made to use NN for controls as far back as the 1990s [
35,
36,
37], but these attempts were limited to replacing a block or parts of the closed-loop framework with an NN rather than directly using the NN-based framework for signal controls.
Acknowledging the limitations of PINNs and other NN-based controls, a question emerges: can control signals be incorporated in PINNs for chaotic nonlinear dynamical systems? To investigate this, we focus on a system proposed by Balthasar van der Pol in 1920 when he was an engineer working for the Philips Company (in the Netherlands) while studying oscillating circuits [
38,
39,
40]. The van der Pol system exhibits highly chaotic behavior encompassing wide applications in biology, biochemistry, and microelectronics [
41,
42,
43]. The traditional control of the van der Pol system usually includes linearizing the system and adding a forcing term based on the linearized system to impose control [
44,
45,
46,
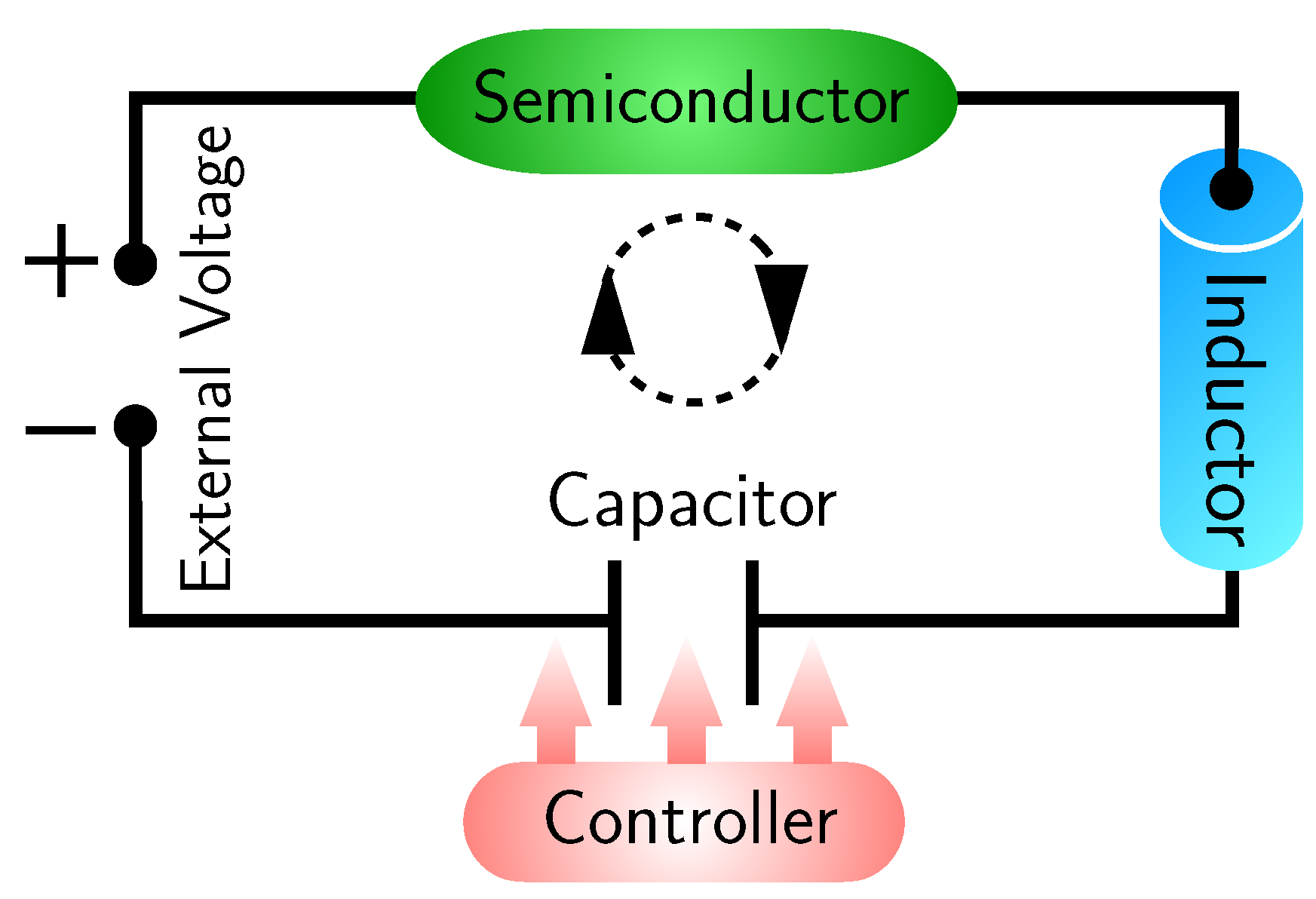
47]. A basic setup of the oscillating van der Pol circuit is illustrated in
Figure 1: an external voltage excites the circuit, inducing a current that can be converted to a charge through the capacitor [
48]. If the semiconductor as indicated in green is equipped, the circuit will display highly nonlinear behavior that is hard to control and predict. Designing a controller (red block) for controlling the chaotic, nonlinear behavior in such circuits is our main goal.
Inspired by [
47] and seeking to compare the application of PINNs [
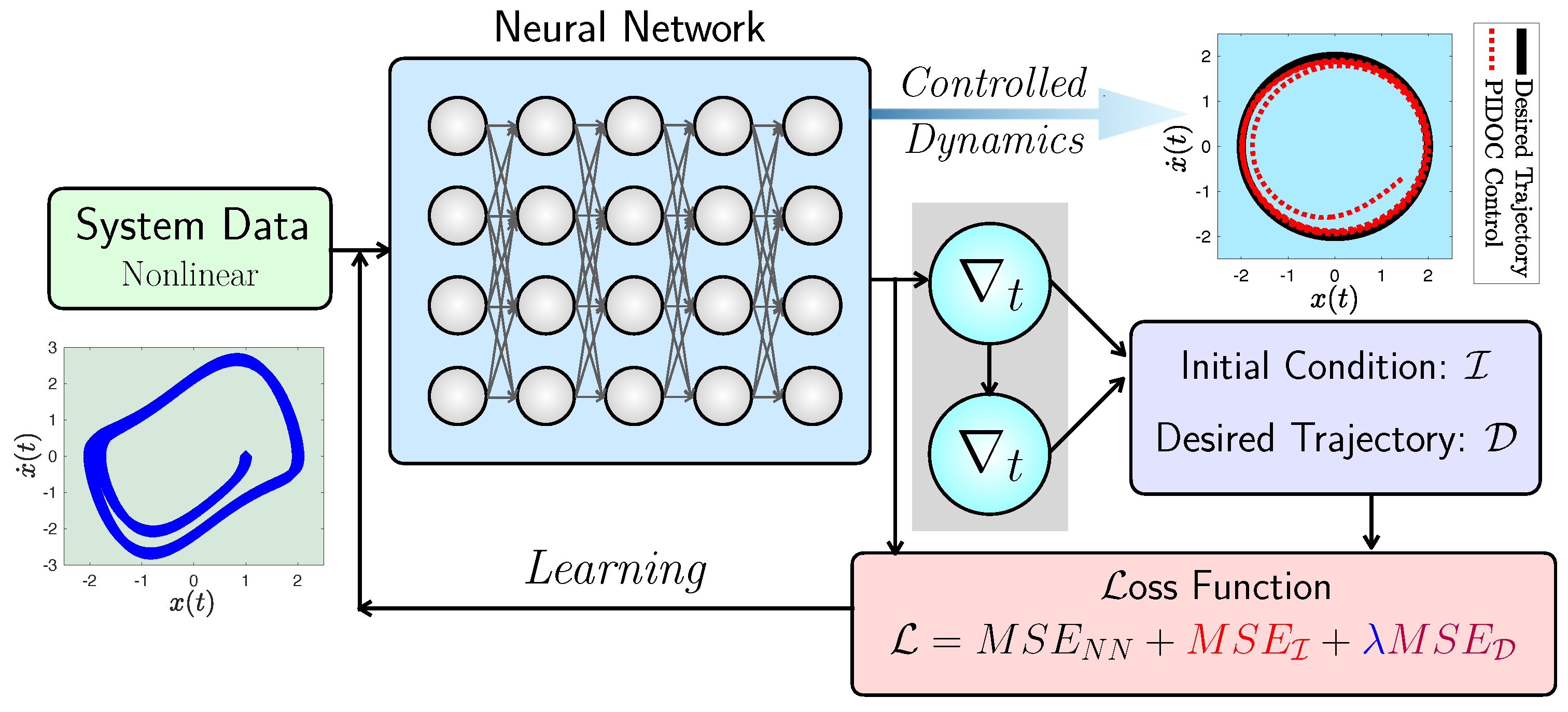
22] to the van der Pol system, we propose Physics-Informed Deep Operator Control (PIDOC), a PINN-based control method that incorporates into the loss function of a PINN the generation losses of NN, the desired control signal, and the initial position of the system. The framework is tested based on its behavior and its ability to deal with the highly nonlinear system, while the hyperparameters are also investigated for the better interpretation and potential application of PIDOC.
The manuscript is arranged as follows: in
Section 2 we first formulate the problem of a van der Pol system and controls (
Section 2.1), elaborating the basic system setup in
Section 2.2. In
Section 3, the detailed methodologies of formulating and learning with PIDOC are described, consisting of deep learning (
Section 3.1) and physics-informed control (
Section 3.2). The numerical experiments conducted are briefly summarized in
Section 3.3. Next,
Section 4 shows the results and discussion of PIDOC.
Section 4.1 analyzes the behavior of PIDOC given a benchmark problem followed by an in-depth estimation of the nonlinearity of trajectory convergence in
Section 4.2, the estimation of the amplitude of control signals (
Section 4.2.1), the influence of initial positions (
Section 4.2.2), and a nonlinearity analysis (
Section 4.2.3). The hyperparameters of the NN (
Section 4.3.1) and the weight of the control signal in PINN is described in
Section 4.3.2.
5. Concluding Remarks and Future Works
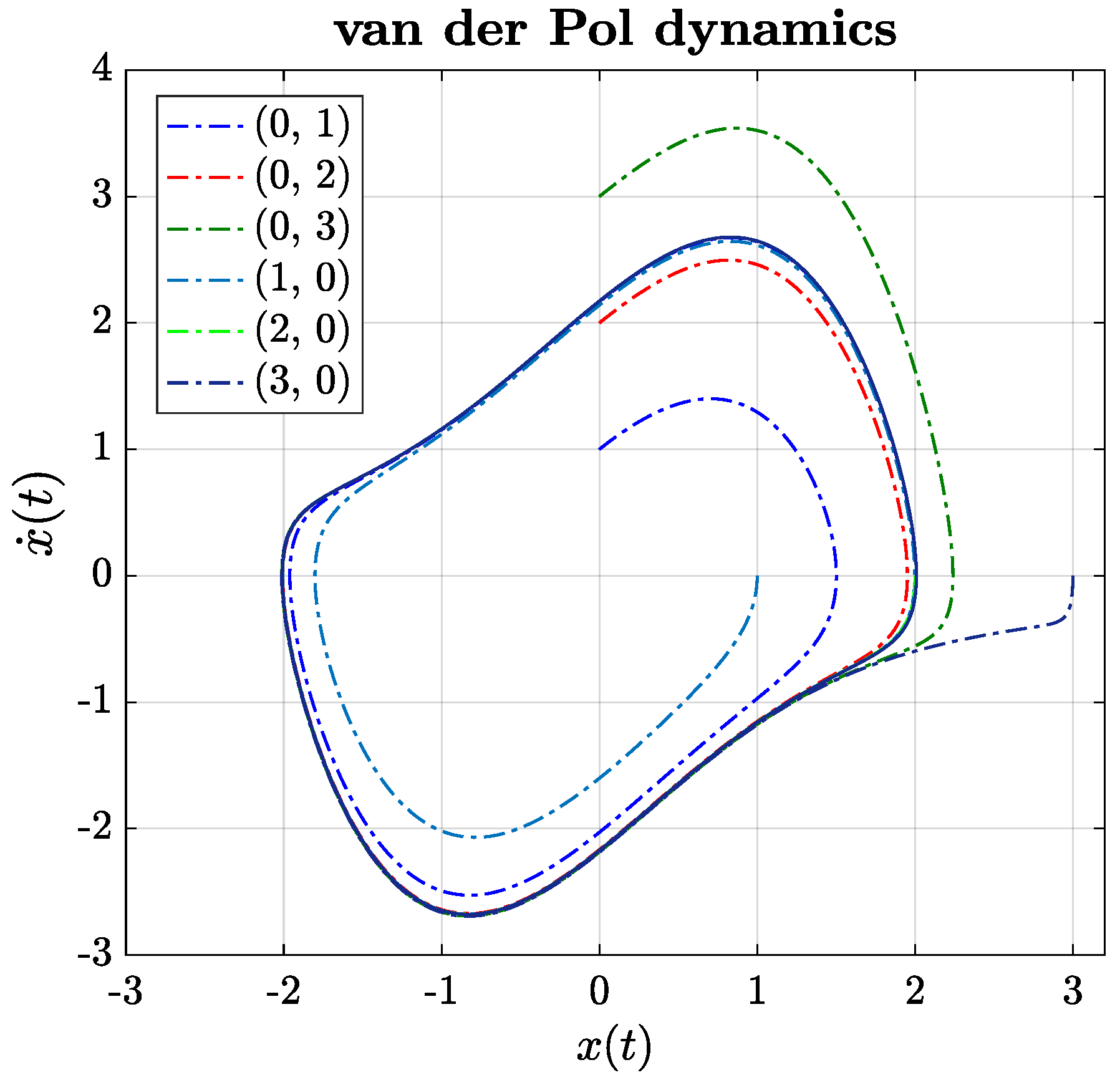
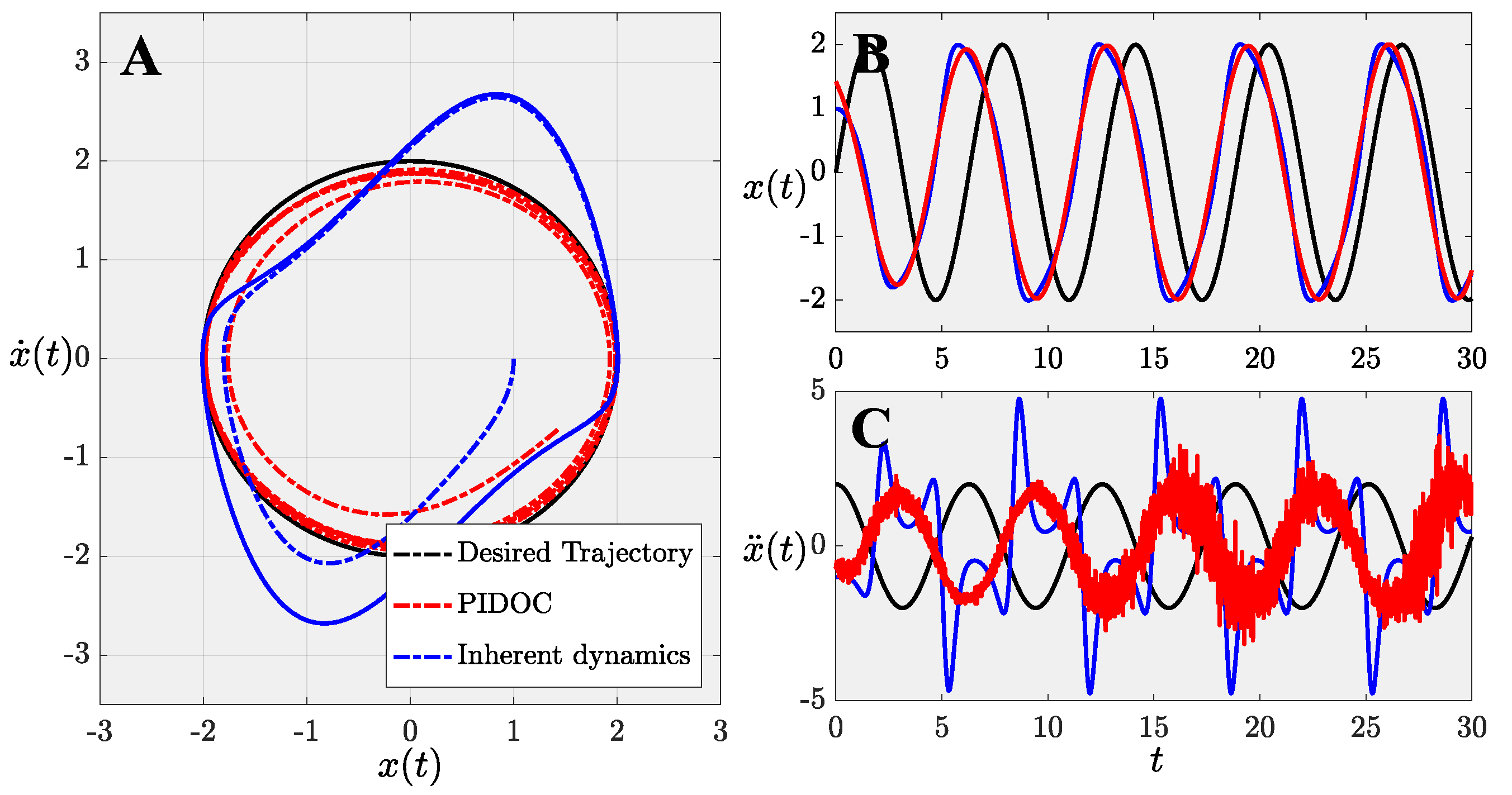
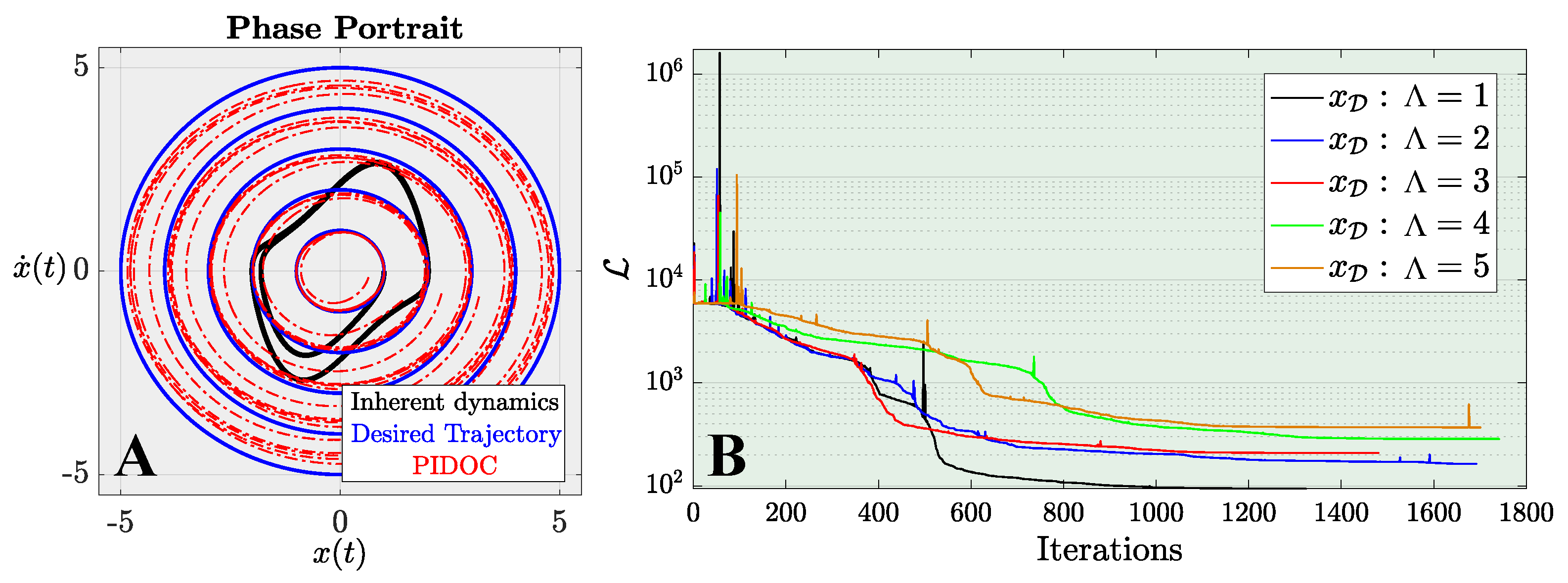
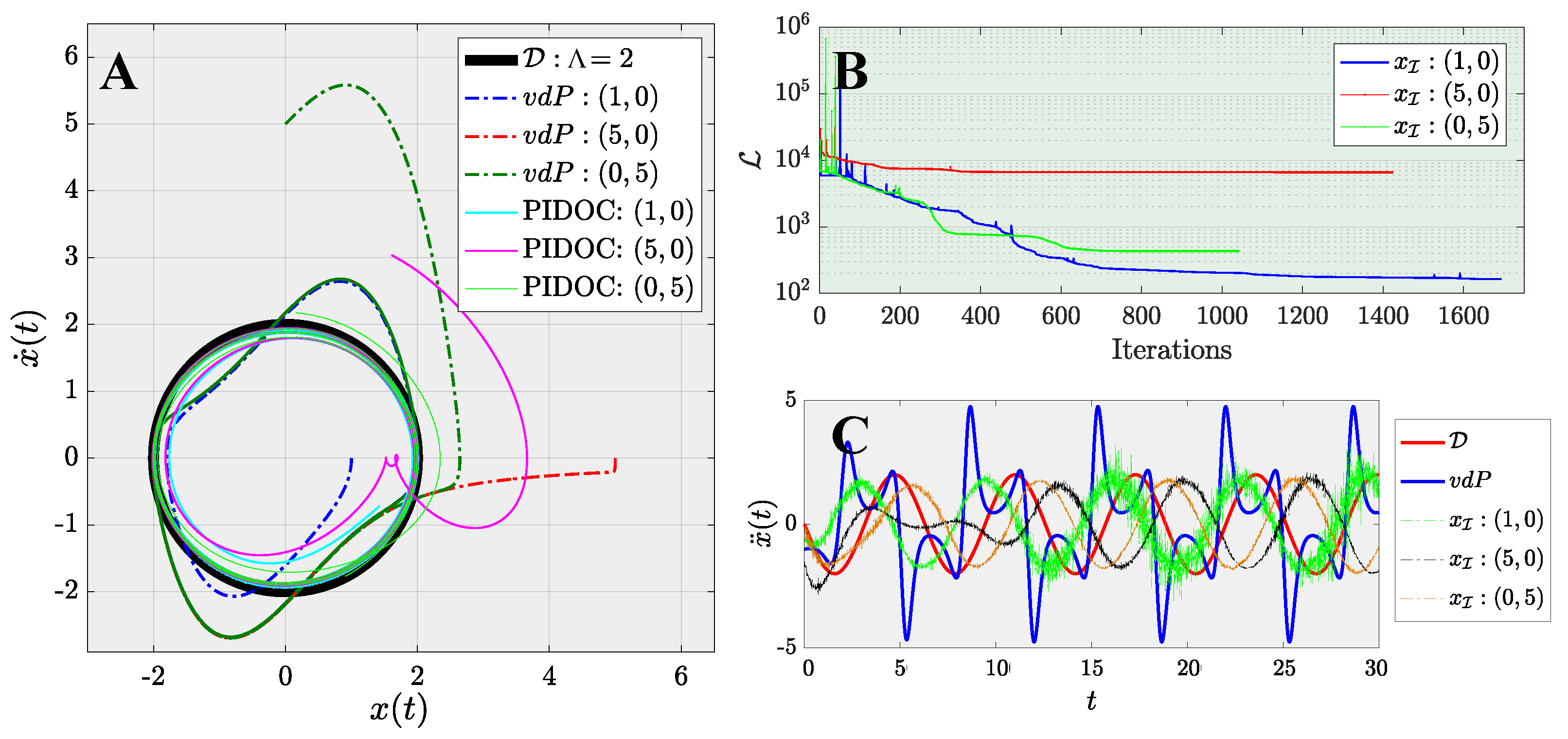
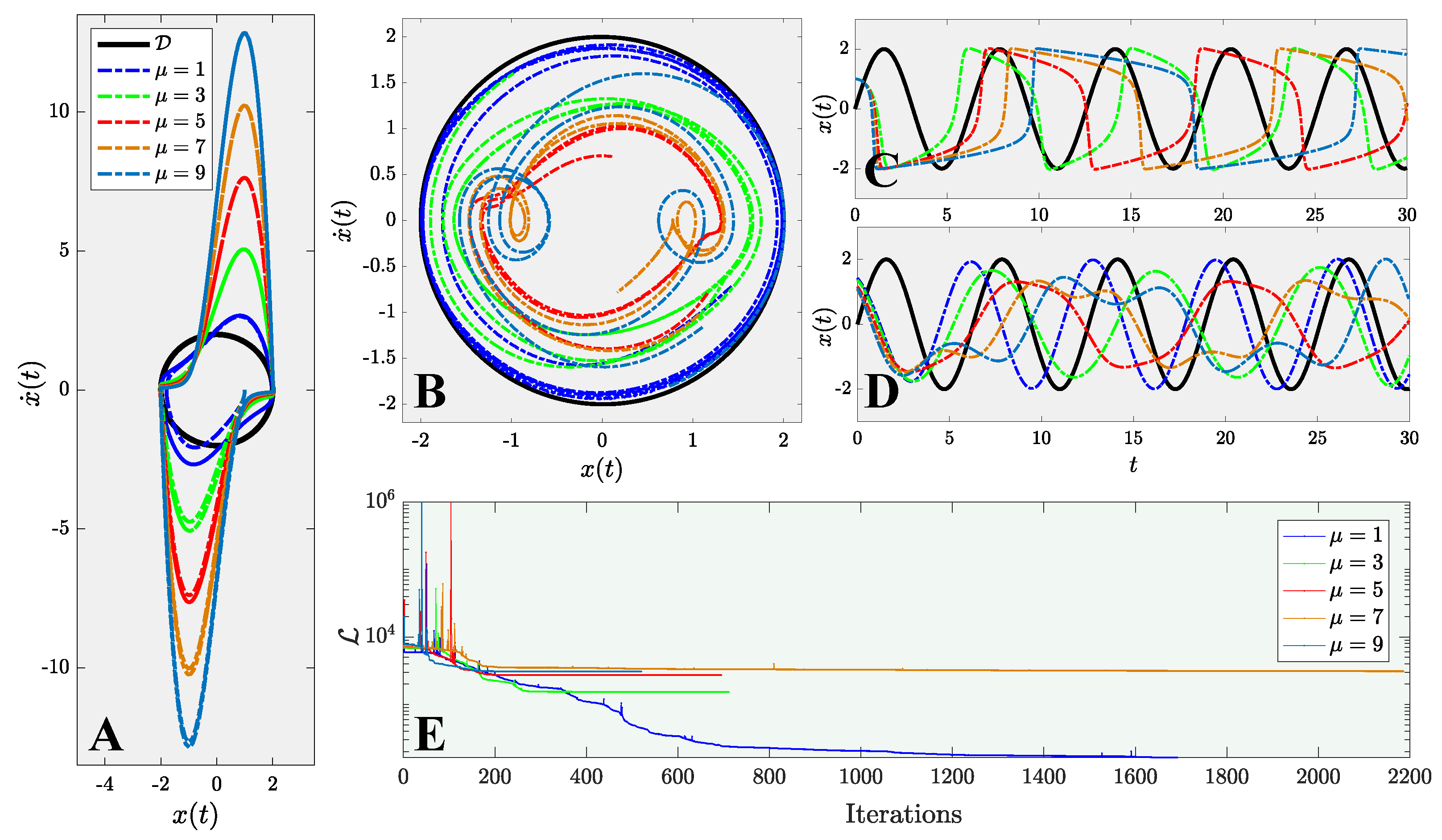
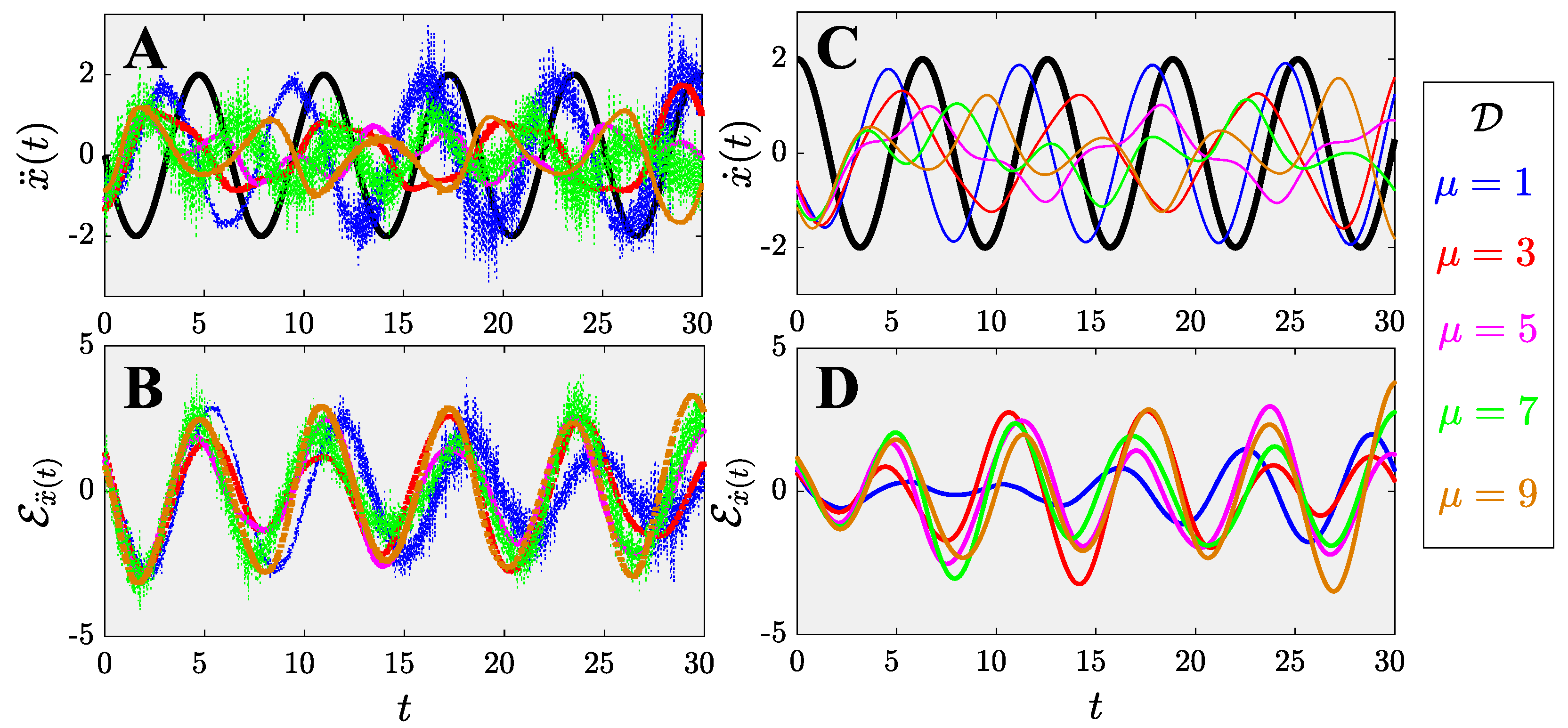
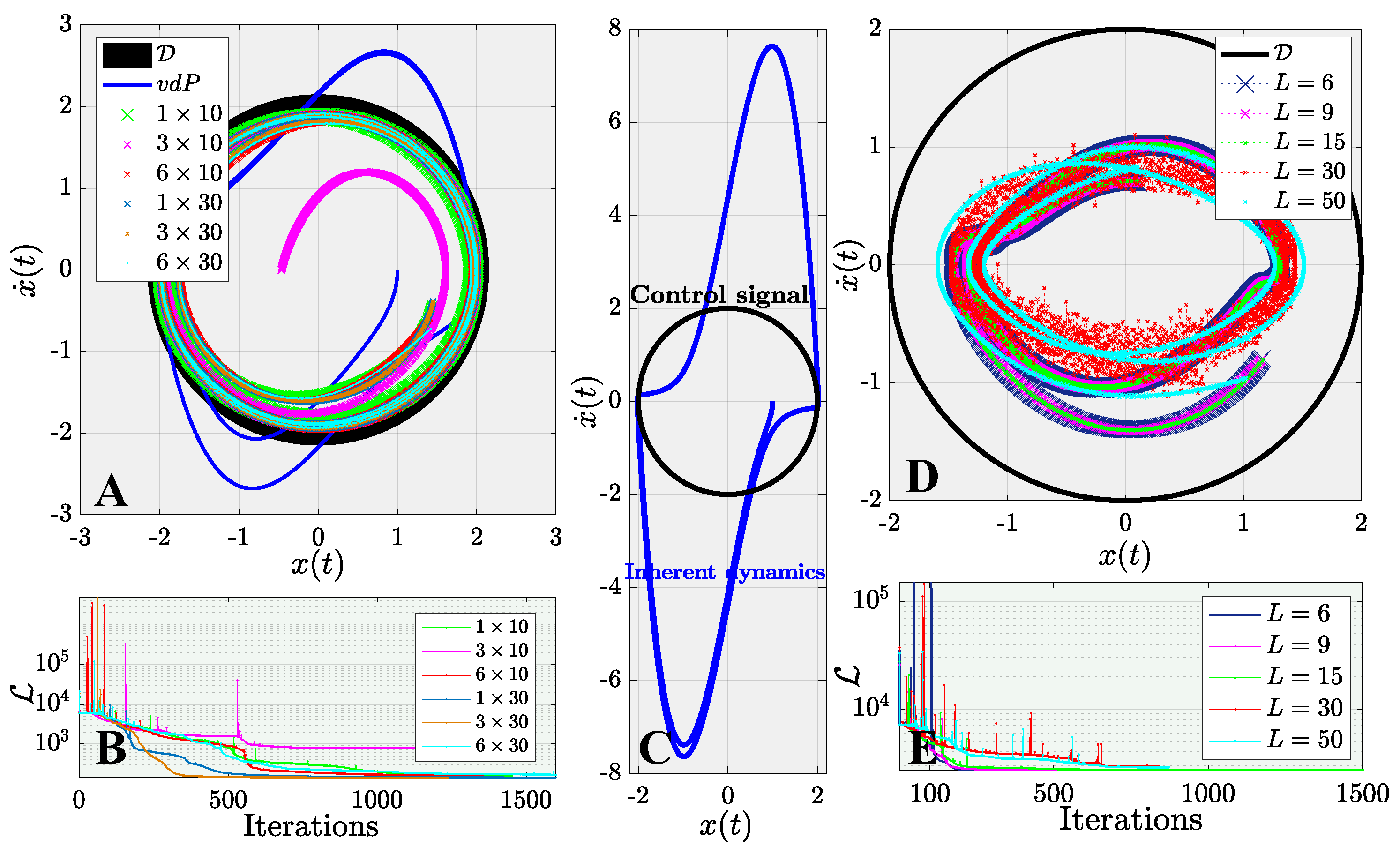
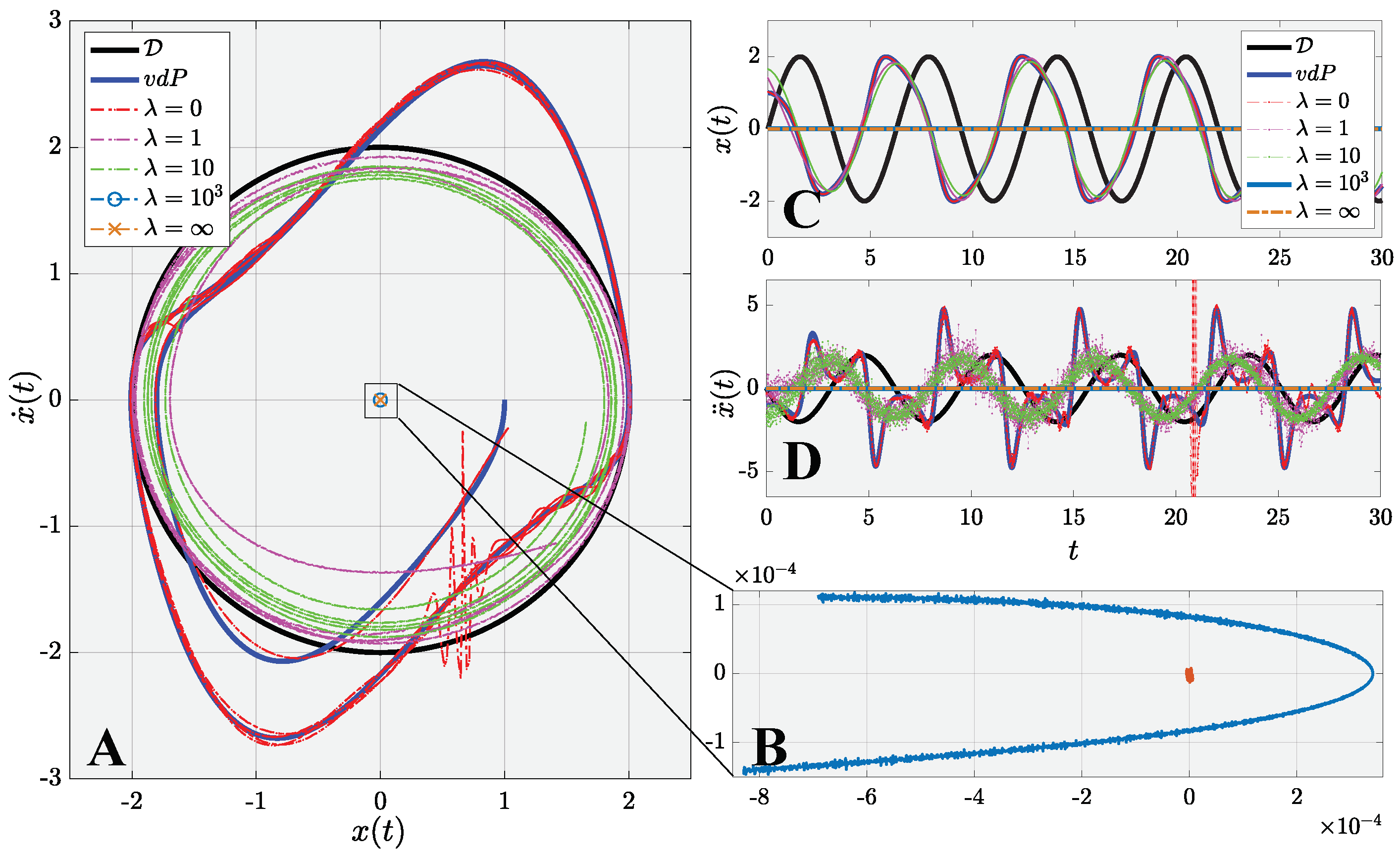
This manuscript describes a century-old yet widely encountered problem: controlling a nonlinear van der Pol dynamical system with a novel approach using physics-informed neural networks. Instead of adopting the traditional paradigm of learning and predicting using physics-informed neural networks, we use such networks for controlling nonlinear systems. A new framework based on physics-informed neural networks Physics-Informed Deep Operator Control (PIDOC) is presented, which consists of a deep neural network and physics-informed control, including the desired control trajectories and initial positions. PIDOC is fed with systematic nonlinear data to control the van der Pol circuits and output the controlled signals. To investigate the behavior and properties of PIDOC, we first tackled benchmark control problems for systematic analysis, then designed three sets of numerical experiments for testing the effects of the amplitudes of desired trajectories , different initial points , and system nonlinearities, as represented by . We then tuned the hyper-parameters to change the neurons and layers of the neural network to study two questionss: (1) Does a neural network with a smaller volume still show the same capability for controls applied to the benchmark problem? (2) Can increasing the neural network volume lead to better capabilities with regard to controlling van der Pol systems with high nonlinearities? We also intended to verify the ability of single-hidden-layer neural networks to approximate nonlinear systems for part of the control. We also changed the Lagrange multiplier to a weight factor to check how the desired trajectories guide PIDOC as control signals.
Our results indicate that PIDOC controls exhibit a higher stochasticity for higher-order terms, which can be attributed to the stochastic nature of deep learning, with the successful implementation of the desired trajectory on the benchmark problem. PIDOC also demonstrates the ability to increase the trajectory amplitudes with lower absolute mean errors. For systems with different initial points, our numerical experiments show that for points that are further away, PIDOC can still successfully implement controls with higher fluctuations at the initial stage. However, as we increase the system nonlinearities, the PIDOC outputs become less ideal than the benchmark problems, as two vortex-linked structures occur on the phase portrait, with an evidently higher loss observed for systems with high nonlinearities. A neural network with a decreased PIDOC volume also shows a good control implementation with the van der Pol system of , while increasing the layers does not cause systems with high nonlinearity to follow the desired trajectory as well as the benchmark problem. It should be noted that increasing the layers does generate an improvement in the output-controlled signals, as the vortex-linked structures in phase portrait vanished, making the system more predictive. Increasing the weights of the control signals in PIDOC does not improve the control qualities based on the output. Even when the systematic data are nonlinear and chaotic, they still contribute greatly to the PIDOC, as the method is intrinsically a deep learning-based control method.
Considering the successful implementation of the van der Pol systems, further investigations on using PIDOC to impose control on other systems such as the Lorentz system could provide more insight. Additionally, a comparison of the control properties based on PIDOC and deterministic controls—i.e., Cooper et al. [
47]—could also be a potential direct research. Specifically, comparing PIDOC with idealized nonlinear feedforward (open-loop), linearized feedback, and combined approaches could lead to unveiling more properties of PIDOC. Improvements in PIDOC or the development of further models tackling systems with high nonlinearities are significant goals to be addressed in future research.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}