1. Introduction
In Bayesian analysis and decision theory, the loss function plays an important role as it can be used to describe the overestimation and underestimation in analysis. Conventionally used loss functions include symmetric loss and asymmetric loss. In the symmetric loss function, the estimation treats overestimation and underestimation equally, whereas the asymmetric loss function gives different weights to overestimation and underestimation. Compared with the symmetric loss, the asymmetric loss is more realistic and useful in practical applications. For example, in reliability and survival analysis, overestimation of the reliability function or average failure time is usually much more serious than underestimation of the reliability function or mean failure time. Similarly, an underestimate of the failure rate results in more serious consequences than an overestimate of the failure rate. Moreover, many other authors, including Zellner [
1], Chang and Huang [
2] and Khatun and Matin [
3], also pointed out that commonly used symmetric loss functions such as squared error (SE) loss may be inappropriate in practical applications. In consequence, asymmetric loss functions are widely applied in statistical inference; see, for example, Ali [
4,
5]. One of the most useful asymmetric loss functions is called LINEX loss, first introduced by Klebanov [
6] and used by Varian [
7] in his study of real estate assessment. The LINEX loss function rises approximately exponentially on one side of zero and approximately linearly on the other side.
Let
be the unknown parameter to be estimated and
be an estimate of
; in this case, the LINEX loss function can be written as
From (
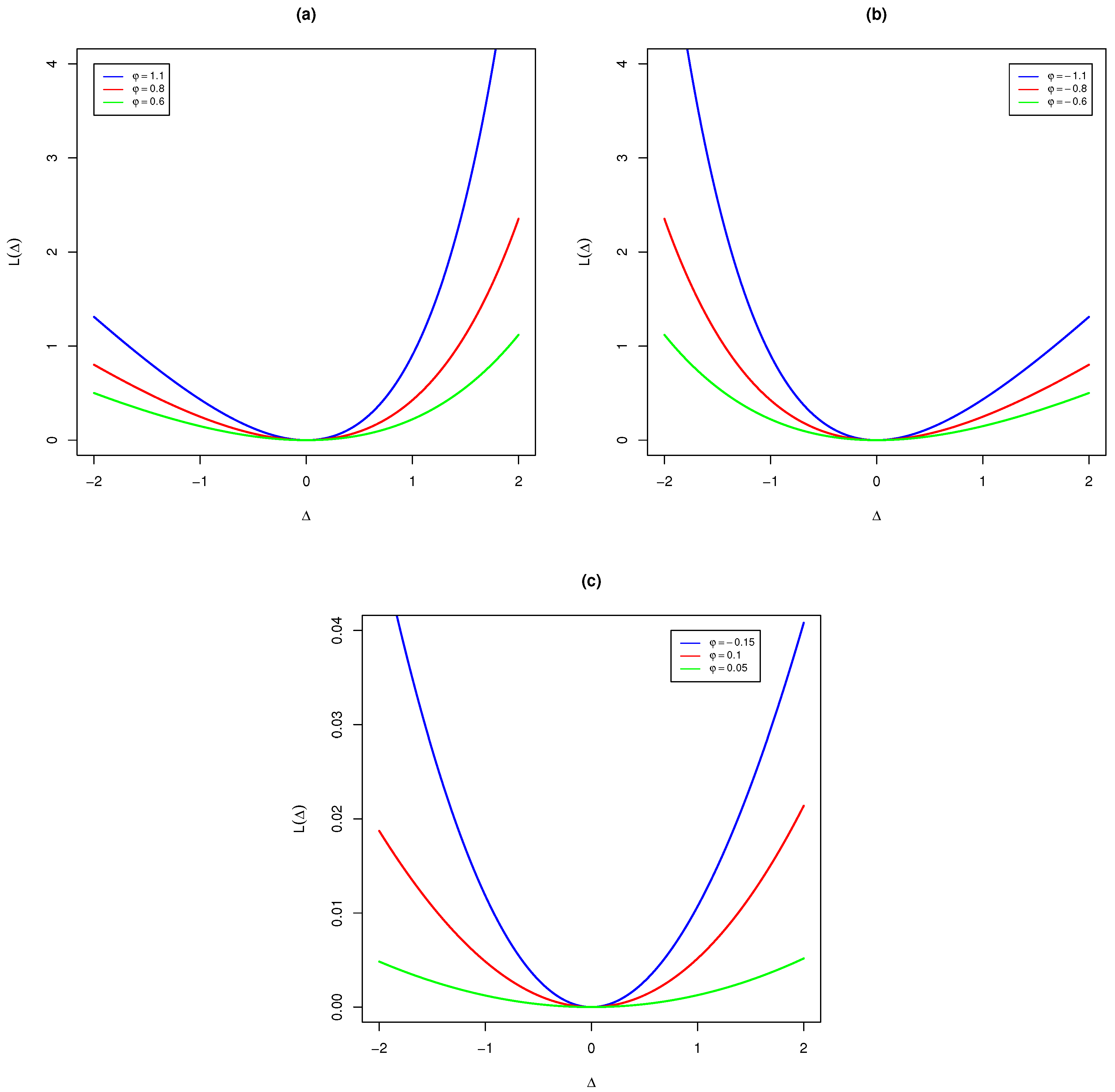
1), the sign and magnitude of the shape parameter
represent the direction and degree of symmetry of LINEX loss. Several comments are necessary regarding (1). First, for
, overestimation is more serious than underestimation, and vice versa. When
is close to zero, the LINEX loss is approximately the squared error loss and therefore almost symmetric. For clarity of illustration, various plots of the LINEX loss function
with
are presented in
Figure 1 under different choices of parameter
. The plots also demonstrate that positive, negative and small values of
give more weight for overestimating, underestimating and almost equal estimation, respectively. It is observed from
Figure 1a that, for positive values of
, the function is completely asymmetric, with overestimation being more harmful than underestimation. For negative values of
, as in
Figure 1b, the function grows approximately exponentially when
and almost linearly when
. Moreover, when
tends towards zero, as in
Figure 1c, the function is approximately symmetric as the squared error loss function.
Let
be the posterior distribution of the parameter
; then, the Bayesian estimator of
using the LINEX loss function, denoted by
, is given by
where
is the expectation with respect to
.
Due to the practicality of the asymmetric LINEX loss in many applications, including reliability, economic and social studies, among others, many authors have studied the Bayesian inference and decision analysis problems using the LINEX loss function. Dey et al. [
8] explored the robustness properties of classes of LINEX losses under exponential and discrete power series families of distributions. Soliman [
9] compared the Bayesian estimators of the parameters and reliability characteristics for Rayleigh distribution using quadratic and LINEX loss functions. Misra and Meulen [
10] investigated the estimation of the mean of two normal populations with unknown means and common known variance using the LINEX loss function. Micheas [
11] investigated robustness to loss functions employing the LINEX loss function and applied the methods to standard examples. Hoque et al. [
12] analyzed the performance of the unrestricted estimator and preliminary test estimator of the linear regression model based on the LINEX loss function. Kazmi et al. [
13] studied the properties of Bayesian estimators of the parameter of a class of lifetime distributions, employing various loss functions, including the LINEX loss, through simulation and real data. Theoretical results were obtained for various lifetime distributions under different data types by many authors; see, for example, the works of Pandey et al. [
14], Jaheen [
15], Azimi et al. [
16], Ahmed [
17,
18], Ashour and Nassar [
19], Nassar et al. [
20], Kotb and Raqab [
21], Chen and Gui [
22] and Nassar et al. [
23], among others. From practical perspectives, due to its flexibility of measuring the overestimation and underestimation and its more appropriate data fitting feature in data analysis, the LINEX loss is also widely used in many practical discussions. For instance, in order to estimate the mean of the selected normal population from two normal populations with unknown means and common known variance, Misra and Meulen [
10] proposed some admissibility results for a subclass of equivalent estimators, and a sufficient condition for the inadmissibility of an arbitrary equivalent estimator was also provided. In the classical Taguchi quality model, Chang and Hung [
2] used the LINEX loss to measure the loss of quality to determine optimum process parameters for the product quality. By inheriting the asymmetric merit of LINEX loss, Tang et al. [
24] proposed a general multi-view LINEX SVM framework to improve the performance of multi-view learning. Estimation of the costs of non-conforming products is one of the most important inputs in the economic design of control charts. Abolmohammadi et al. [
25] proposed an extending control chart by considering the LINEX loss on the basis of the Markov chain approach, and the results showed that the practical VSIX control chart based on the LINEX loss was more efficient in terms of the expected cost per hour. However, it should be mentioned here that, after extensive documentation retrieval, the statistical inferential results were obtained under LINEX loss with fixed parameter
, where a random chosen positive or negative
was taken for indicating overestimation and underestimation, respectively, but there was no discussion on how to choose a proper value for the LINEX parameter
.
In the practical Bayesian inferential approach, with respect to LINEX loss and even other asymmetric losses, it is an inevitable challenge issue to choose the values of the LINEX parameter in practice. To balance the overestimation and underestimation for practical data analysis and to give relatively explicit weights between over- and underestimation, the value(s) of the LINEX parameter are usually determined through historical information, expert experience, as well as some other strategies. Obviously, inference using a fixed parametrization has limitations and the randomly given value of the parameter merely provides overestimation or underestimation in general and cannot provide a proper balance between overestimation and underestimation in practice. To overcome this drawback, it is more reasonable to take the idea that there are many values of the parameter in a given issue, and these potential values feature different weights. Therefore, it is assumed that the LINEX parameter is a random variable. In Bayesian inference, the main advantage of such an assumption is that, if the number of choices for the parameter is sufficient, the subjective prefixed value of parameter can be viewed as a good choice in analysis. However, within the extensive literature research and empirical illustrations, such an arbitrary subjective approach may lead to poor inferential results if there is not enough information available. The value of the parameter is given randomly in many practical studies, and the final “proper value” may be determined by empirical comparison and cross-validation approaches. Therefore, compared with the conventional subjective procedure, it is necessary and important to adopt an alternative method for the determination of the parameter , where relatively objective value(s) of will provide a more effective balance between overestimation and underestimation in Bayesian inference. It should be mentioned here that, from the perspective of physical application, for complex macroscopical or microcosmic systems, the system has multiple normal states in its operating cycle, and the observed condition is the superposition across different detailed state combinations. Therefore, the presented approach may have potential benefits in studies of statistical physics.
Motivated by such reasons, the main aim of this paper is to introduce an alternative Bayesian analysis for parameter estimation with respect to the LINEX loss function. To overcome the subjective method for the choice of the parameter , it is assumed that the parameter is denoted by a random variable with a proper probability distribution. By taking the expectation of the Bayesian estimator using the usual LINEX loss function over the distribution of , the proposed Bayesian estimator can be obtained in consequence. The new Bayesian estimator is called the Bayesian estimator using the expected LINEX loss function. When the lifetime data come from an exponential distribution, Bayesian estimation using the expected LINEX loss is discussed and empirical illustrations are carried out to show the associated effect in the estimator(s) behavior compared with some arbitrary considered value(s) of the parameter .
The concept of the loss (or cost) function is employed in different optimization procedures in statistical theory and the decision-making process to scheme an event in a real number and the associated loss or cost. An optimization problem always aims to minimize a loss function. As shown by the empirical results in
Section 4 and
Section 5, the expected LINEX loss function provides Bayesian estimators with minimum loss as measured through the Bayes risks. Therefore, we can conclude that the Bayesian estimators obtained based on the suggested technique are good estimators and can be used effectively in various fields, including reliability analysis, estimation processes, financial investment, forecasting and decision-making processes.
The rest of this paper is organized as follows. The expected LINEX and model description are discussed in
Section 2. In
Section 3, we obtain the Bayesian estimator of the exponential distribution using the expected LINEX loss function as well as the Bayes risk. Extensive simulation studies are presented in
Section 4.
Section 5 demonstrates the usefulness of the new estimators by analyzing three real data sets. Finally, the paper is concluded in
Section 6.
2. Expected LINEX and Model Description
Let
be the probability density function (PDF) of
with range
; then, from (
2), one can obtain the Bayesian estimator of the unknown parameter
using the expected LINEX loss function as follows:
where
is the Bayesian estimator of the unknown parameter
given by (2). One can choose a proper probability model
to reflect being symmetric, positive or negatively skewed, which will, in turn, give proper weights to balance overestimation and underestimation. It is noted that, compared with the conventional prefixed choice of the parameter
, the Bayesian estimation (3) under expected LINEX loss takes all possible values of the parameter
into account, and gives different probabilistic weights to each value. Then, the overall balance between overestimation and underestimation is characterized by the weighted sum in the full range
of the parameter
, which may be more objective and robust than the conventional approach in Bayesian analysis.
Let
X be a random variable following the exponential distribution with parameter
with the PDF
where
is the scale parameter. Suppose that
is a random sample of size
n from the exponential distribution (4), and
is the associated observation of
. Then, the likelihood function of
can be written as
By direct computation, it is known that the maximum likelihood estimator (MLE) of the parameter
is
To obtain the Bayesian estimator of the parameter
, we need to determine the prior distribution, say
, of
. In this paper, a conjugate prior distribution of
is used as the gamma distribution with density function
It is seen that the prior distribution in (7) is a natural conjugate prior because it generates a posterior distribution that relates to the same family. Furthermore, the posterior distribution generated from the natural conjugate prior can be easily mathematically manipulated. The researcher can select the values of the hyper-parameters
a and
b to accommodate the prior knowledge. Moreover, the Jeffreys prior can be derived as a special case of (7) by replacing
; for more details, see Kundu and Howlader [
26]. Then, the posterior distribution of
is given by
Under the symmetric squared error (SE) loss function, the Bayesian estimator of
is the posterior mean, i.e.,
Similarly, the Bayesian estimator of
using the LINEX loss function can be written from (2) as
Further, to obtain the Bayesian estimator of
using the expected LINEX loss function, we propose the following three probabilistic distributions for the parameter
as
From (11), it is noted that
is the generalized logistic type-I (this type has also been called the “skew-logistic”) distribution with shape parameter
c,
is the normal distribution with scale parameter 1 and location parameter
, and
is the standard Gumbel or extreme value distribution with location parameter
d. It is seen that, in different distributions
and
, the parameter
features different probability weights at different values in full range
, and that overestimation and underestimation could be well modeled by choosing constants
and
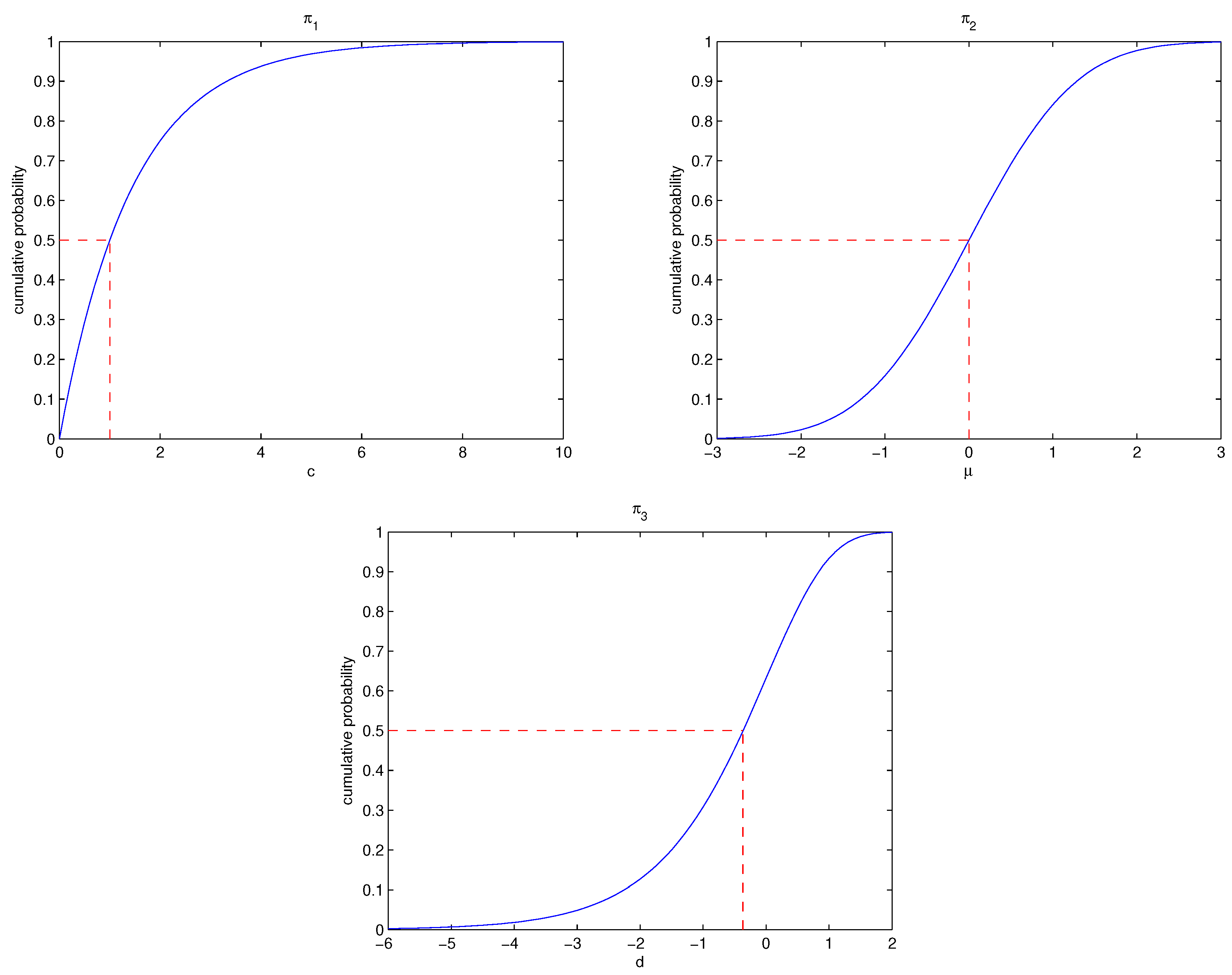
d properly. For illustration, the cumulative probability weight for the parameter
is calculated and the associated plots are presented in
Figure 2 with a change in parameters
and
d, respectively. One could see that when parameters
and
, the weights of overestimation are more serious than underestimation using distributions
,
and
, respectively. The distributions in (11) will be used to obtain the Bayesian estimator of the parameter
using the expected LINEX loss function in the next section.
Remark 1. It should be mentioned here that the choice of the distribution for the parameter φ is a tricky issue in practice. The main principle is that the model of φ should be a distribution with full range . On this basis, due to historical information and expert experience, among others, if there are sufficient extra data used regarding φ, one could use a goodness-of-fit technique to find a proper model from among different candidates, whereas, if there is scarce information about φ’s distributional characteristics, one could use a skewed distribution with concise expression from an ease of computation perspective. Further, one could also refer to the maximum likelihood and moment methods to give proper estimates for parameters and d, respectively, by using the information of φ in consequence.
Remark 2. A proper probability model provides weights to balance between overestimation and underestimation compared with fixed ϕ. In general, when the random model is available, the optimal Bayesian estimator of θ from a decision-making perspective can be obtained as follows:where is the loss function, δ is the estimator of parameter θ, denotes the expectation with the posterior distribution of θ, and denotes the expectation with the random model of ϕ. Under this approach, it is clear that the proposed expected Bayesian estimator can be viewed as the mixture of conventional Bayesian estimation under the weight at each value of ϕ, and that the estimator refers to (3) under the expected LINEX loss from the decision-making procedure. 4. Simulation Study
In this section, in order to investigate and compare the performance of different Bayesian estimators using the expected LINEX loss function, along with those based on SE and LINEX loss functions, extensive Monte Carlo simulations are carried out for illustration. The simulation procedure can be described by the following steps.
- Step 1
Determine the value of the parameter and the sample size n.
- Step 2
Generate a random sample from the exponential distribution, where , where .
- Step 3
For given values of gamma hyper-parameters a and b, generate from the gamma prior density (7).
- Step 4
The Bayesian estimates and the associated Bayesian estimates using the expected LINEX loss of the parameter are computed.
- Step 5
Based on multiple replications, the performance of the different Bayesian estimates is evaluated in terms of criteria quantities of the mean relative estimate (MRE) and mean square error (MSE) as well as the Bayes risks.
In this procedure, the simulation is performed by considering different values of
and sample sizes
, respectively. Meanwhile, the gamma hyper-parameters are chosen in such a way that the prior mean becomes the expected value of the corresponding parameters. We assume
for
and
for
in this simulation. Further, the Bayesian estimates with respect to the LINEX loss function are calculated with selected
in all the settings, whereas the Bayesian estimates using the expected LINEX loss function are obtained under different parameter values
and
d of distributions
, respectively. For each
, five configurations (Conf) are proposed, as shown in
Table 1. As mentioned before, when
and
, the weights of overestimation are more serious than underestimation employing the distributions
,
and
, respectively. Therefore, the values in
Table 1 are selected to reflect the impact of these parameters on the performance of the different estimates using the expected LINEX loss function. Based on 1000 replications, the criteria quantities MRE, MSE and the Bayes risks are displayed in
Table 2,
Table 3 and
Table 4 for
and
, respectively.
With the increase in sample size n, the MREs tend towards one and the criteria MSEs and Bayesian risks of both Bayesian estimates under common and expected losses decrease, which indicates the consistency of the associated estimates when the sample sizes increase;
For a fixed sample size, the Bayesian estimates obtained under common LINEX loss have relatively smaller MSE than that from SE loss, whereas the associated Bayesian risks perform similarly under these two cases in general;
In terms of minimum MSE, we can conclude that the Bayesian estimates using the expected LINEX loss function perform better than all other estimates for with when ;
The Bayesian estimates using with have the smallest MSE among all other estimates when ;
The Bayesian estimates using the expected LINEX loss function using with have the minimum Bayes risk when compared with all other estimates.
It can be observed that when , reduces to the standard normal distribution. In this case, we can see that, although the distribution does not contain any parameter, it gives the best result based on the minimum Bayes risks in all cases. This is because, when we obtain the Bayesian estimate using the expected LINEX loss function, we take the expectation over all possible values for the parameter . The same result can also be noted when in , where the Bayes risk obtained based on the expected LINEX loss function is smaller than that based on the common LINEX loss. Therefore, when the researcher does not have any information about the parameter , one could take the expectation over all possible values for the parameter to obtain the Bayesian estimate using the expected LINEX loss.
5. Data Analysis
In this section, three real life data sets are used to show the applicability of the proposed estimators based on the expected LINEX loss function.
Example One. (Software reliability data) The first data set represents the time-between-failures (time unit in milliseconds) of software reliability. The original data were firstly presented by Lyu [
31] and analyzed recently by Alotaibi et al. [
32] and are also available in the
reliaR package. The complete data set that is transformed from time-between-failures to failure times is presented in
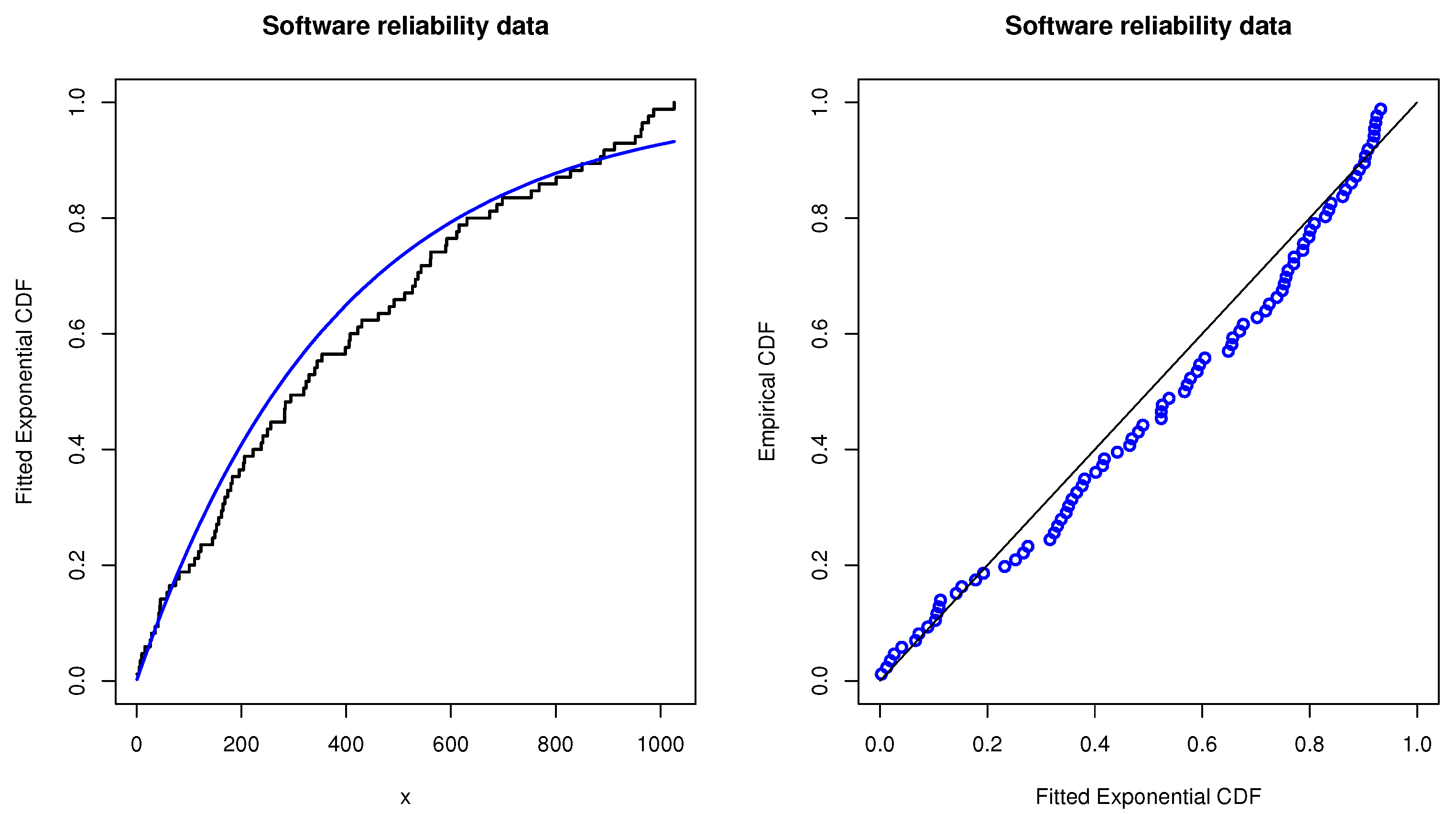
Table A1. Before proceeding further, we first check the validity of the exponential distribution to model these data by using the Kolmogorov–Smirnov (K-S) distance and the associated
p-value based on the MLE of the parameter
. By direct computation, it is noted that the MLE of
is
, the K-S distance is 0.0788 and the corresponding
p-value is 0.6591. Therefore, it is found that the exponential distribution could be used as an appropriate model to fit the mentioned software reliability data. For further illustration, the empirical cumulative distribution function (CDF) plot with overlaid theoretical exponential distribution and the probability–probability (P-P) plot are also shown in
Figure 3 to check the goodness of fit for the software reliability data. It is also shown that the exponential distribution can be viewed as a proper model.
Based on the software reliability data set, to find the different Bayesian estimates, we select the hyper-parameters to be
and
in all the cases, where such choices are obtained by equating the first two moments of the gamma distribution obtained from the data with the corresponding theoretical moments. Using similarly designed scenarios given in
Table 1, various Bayesian estimates are presented in
Table 5 under common SE, LINEX and the proposed expected LINEX losses, respectively. Comparing the performance of the different estimates, we can conclude that the Bayesian estimate using the expected LINEX loss function using
with
performs better than other estimates in terms of minimum Bayes risk.
Example Two. (Breakdown of insulating fluid data) The second data set is taken from Nelson [
33] and has been analyzed by many authors (see, e.g., Balakrishnan and Cramer [
34], Dey and Nassar [
35]). The data describe the times to breakdown of an insulating fluid subjected to a voltage of 34 kV, and the detailed lifetime data are presented in
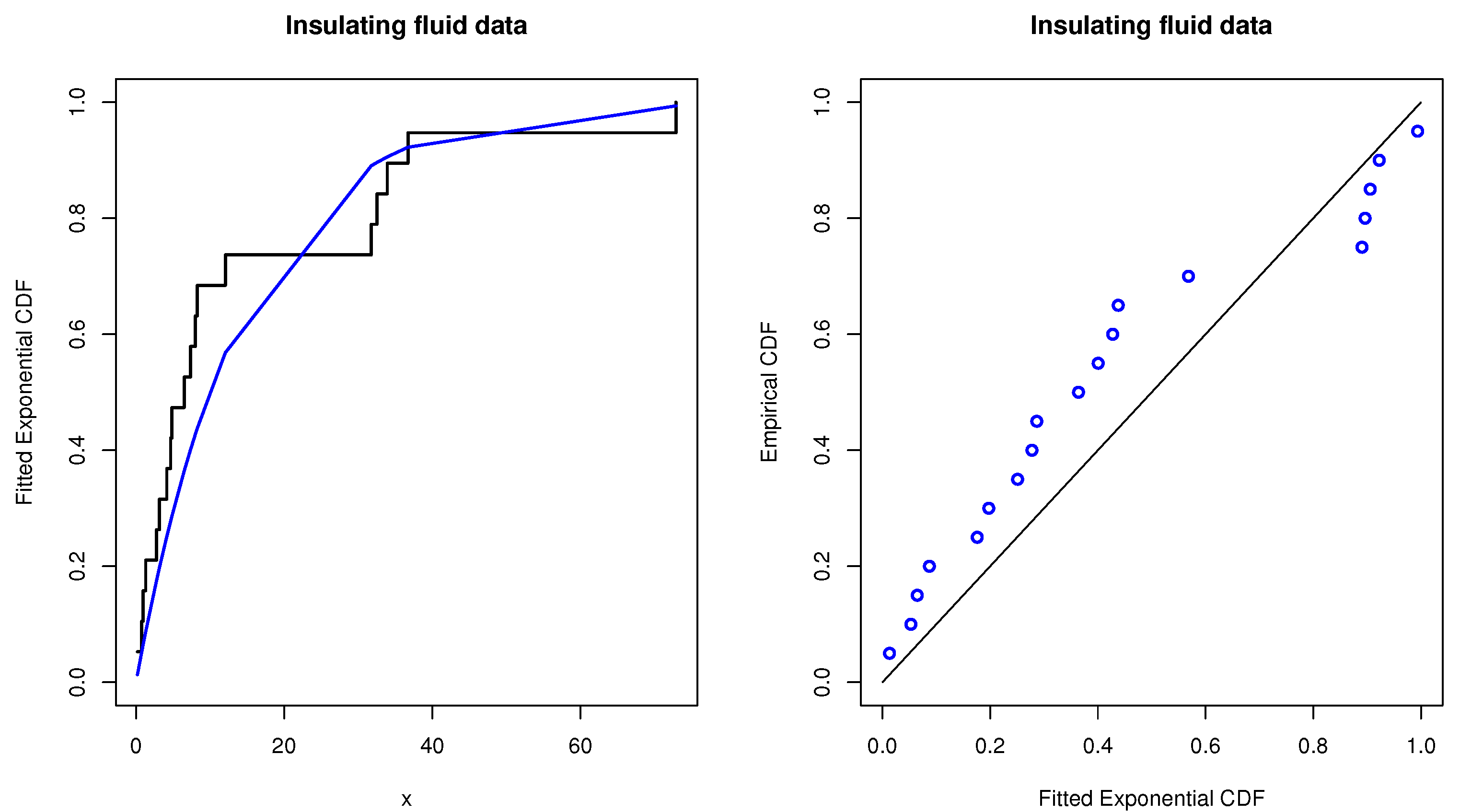
Table A2. By direct calculation, the MLE of the parameter
for these data is
. The K-S distance and the corresponding
p-value are obtained as 0.2464 and 0.1990, respectively. Therefore, the exponential distribution is a suitable model to fit these data. For comparison, the associated empirical CDF plot with overlaid theoretical exponential distribution and the P-P plot are provided in
Figure 4 as well. They also indicate that the exponential distribution is an acceptable model to fit the data.
Using the breakdown data of an insulating fluid, and following a similar approach as for example one, different Bayesian estimates are obtained under various designed scenarios. The results are presented in
Table 6, where the hyper-parameters are chosen as
and
by equating the first two moments of the gamma distribution obtained from the data with the corresponding theoretical moments. Based on the listed results in
Table 6, one could also observe that the Bayesian estimate using the expected LINEX loss function using
with
has the smallest Bayes risk among all other estimates.
Example Three. (COVID-19 data) The third data set consists of the COVID-19 recovery cases in Pakistan from 24 March 2020 to 1 May 2020. This data set was originally analyzed by Ali et al. [
36]. The complete data set is presented in
Table A3. From the data, the MLE of
is
. Based on this result, the K-S distance and the corresponding
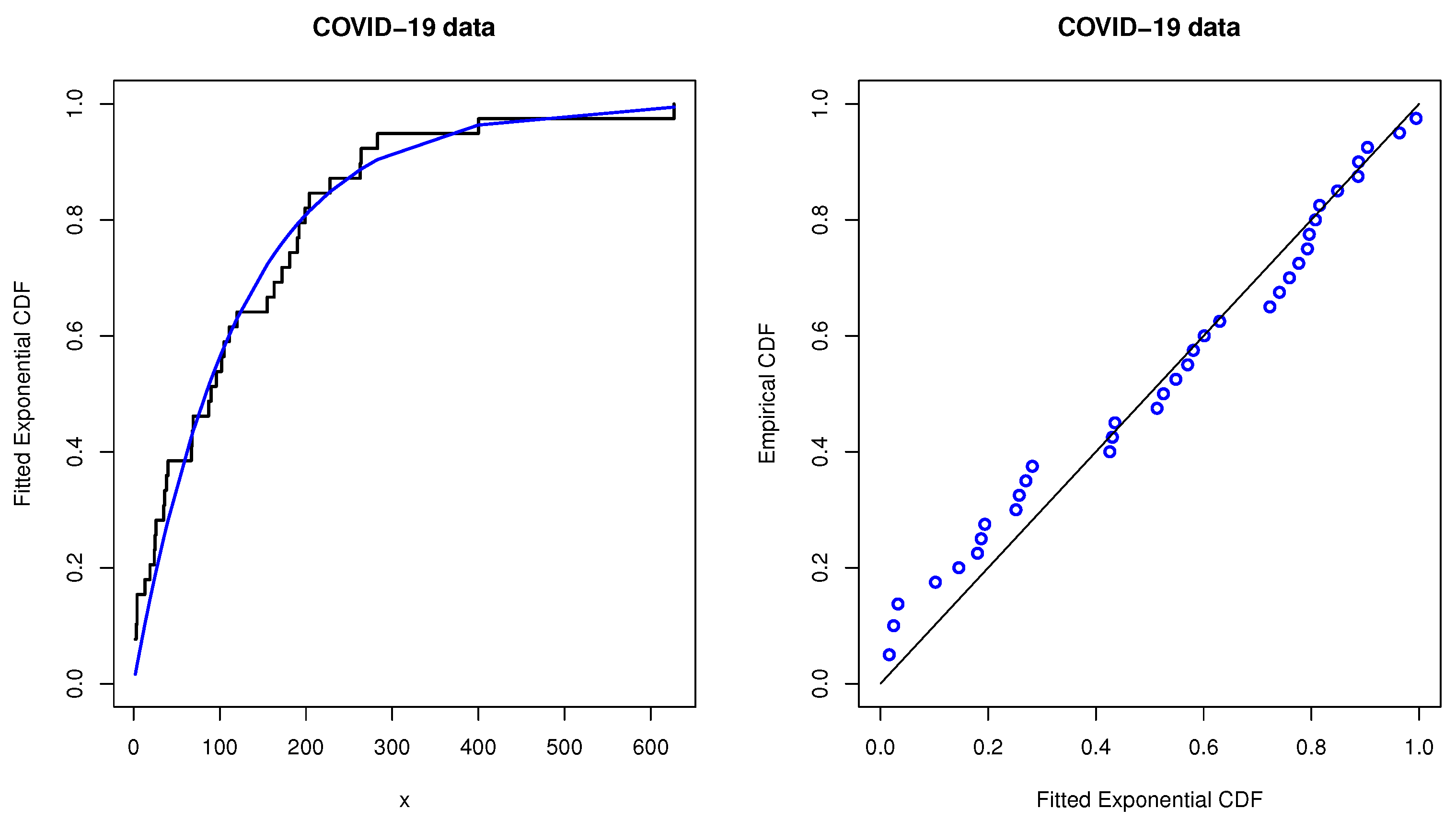
p-value are 0.1213 and 0.6149, respectively. Hence, the exponential distribution is an appropriate model to fit these data. Moreover, the empirical CDF plot with overlaid theoretical exponential distribution and the P-P plot are presented in
Figure 5.
Figure 5 shows that the exponential distribution is an adequate model to fit the data.
To acquire the different Bayesian estimates, we set the hyper-parameter values to be
and
, which are obtained by equating the first two moments of the gamma distribution got from the data with the associated theoretical moments. The different Bayesian estimates as well as the corresponding Bayes risks are tabulated in
Table 7. From the detailed outcomes in
Table 7, one could also observe that the Bayesian estimate using the expected LINEX loss function employing
with
has the smallest Bayes risk among all other estimates.
The simulation outcomes as well as the analysis of the three real data sets show that the performance of the Bayesian estimation using the expected LINEX loss function is superior to that of the common Bayesian approach in terms of MSE and Bayes risks. The proposed expected Bayesian estimation is a robust estimation approach that provides a weight estimation for the common Bayesian estimates. The results also show that if we select an appropriate probability distribution for , we can reduce the MSE and Bayes risk of an estimator. The superiority of the Bayesian estimators using the expected LINEX loss function can be interpreted based on the concept of the expected value, because this estimator is obtained as the arithmetic mean of a large number of independent realizations of . On the other hand, the usual Bayesian estimator using the LINEX loss function is obtained by choosing an arbitrary value for . The new offered technique can be utilized significantly in different fields; for instance, one can obtain accurate estimators for some reliability indices, including reliability and hazard rate function. Moreover, in regression analysis, new estimators of the regression models can be derived using the proposed technique. Furthermore, the expected LINEX loss function can be employed in volatility forecasting.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




