1. Introduction
In this study, which is an extension of previous work [
1], a problem of minimizing a convex, not necessarily differentiable function
(where
is a finite-dimensional Euclidean space) is discovered. Such a problem is quite common in the field of machine learning (ML), where optimization methods, in particular, gradient descent, are widely used to minimize the loss function during training stage. In the era of the digital economy, such functions arise in many engineering applications. First of all, training and regularizing the artificial neural networks of a simple structure (e.g., radial or sigmoidal) may lead to the application of a loss function in a high-dimensional space, which are often non-smooth. When working with more complex networks, such functions can be non-convex.
While a number of efficient machine learning tools exist to learn smooth functions with high accuracy from a finite data sample, the accuracy of these approaches becomes less satisfactory for nonsmooth objective functions [
2]. In a machine learning context, it is quite common to have an objective function with a penalty term that is non-smooth such as the Lasso [
3] or Elastic Net [
4] linear regression models. Common loss functions, such as the hinge loss [
5] for binary classification, or more advanced loss functions, such as the one arising in classification with a reject option, are also nonsmooth [
6], as well as some widely used activation functions (ReLU) [
7] in the field of deep learning. Modern convolutional networks, incorporating rectifiers and max-pooling, are neither smooth nor convex. However, the absence of differentiability creates serious theoretical difficulties on different levels (optimality conditions, definition and computation of search directions, etc.) [
8].
Modern literature offers two main approaches to building nonsmooth optimization methods. The first is based on creating smooth approximations for nonsmooth functions [
9,
10,
11,
12,
13]. On this basis, various methods intended for solving convex optimization problems, problems of composite and stochastic composite optimization [
9,
10,
11,
14] were theoretically substantiated.
The second approach is based on subgradient methods that have their origins in the works of N. Z. Shor [
15] and B.T. Polyak [
16], the results of which can be found in [
17]. Initially, relaxation subgradient minimization methods (RSMMs) were considered in [
18,
19,
20]. They were later developed into a number of effective approaches such as the subgradient method with space dilation in the subgradient direction [
21,
22] that involve relaxation by distance to the extremum [
17,
23,
24]. The idea of space dilation is to change the metric of the space at each iteration with a linear transformation and to use the direction opposite to that of the subgradient in the space with the transformed metric.
Embedding the ideas of machine learning theory [
25] into such optimization methods made it possible to identify the principles of organizing RSMM with space dilation [
26,
27,
28,
29]. The problem of finding the descent direction in the RSMM can be reduced to the problem of solving a system of inequalities on subgradient sets, mathematically formulated as a problem of minimizing a quality functional. This means that a new learning algorithm is embedded into the basis of some new RSMM algorithm. Thus, the convergence rate of the minimization method is determined by the properties of the learning algorithm.
Rigorous investigation of the approximation capabilities of various neural networks has received much research interest [
30,
31,
32,
33,
34,
35,
36] and is widely applied to problems of system identification, signal processing, control, pattern recognition and many others [
37]. Due to universal approximation theorem [
30], a feedforward network with a single hidden layer and a sigmoidal activation function can arbitrarily well approximate any continuous function on a compact set [
38]. The studies of learning theory on unbounded sets can be found in [
39,
40,
41].
The stability of the neural network solutions can be improved by introducing a regularizing term in the minimized functional [
42], which stabilizes the solution using some auxiliary non-negative function carrying information on the solution obtained earlier (a priori information). The most common form of a priori information is the assumption of the function smoothness in the sense that the same input signal corresponds to the same output. Commonly used regularization types include:
1. Quadratic Tikhonov regularization (or ridge regression,
). In the case of approximation by a linear model, the Tikhonov regularizer [
42] is used:
where parameters of the linear part of the model are included, and
k is the number of vector
U components. The regularizer
is mainly used to suppress large components of the vector
U to prevent overfitting the model.
2. Modular linear regularization (Tibshirani Lasso,
). The regularizer proposed in [
3] is mainly used to suppress large and small components of the vector
U:
3. Non-smooth regularization (
) [
3,
43]:
The use of led to the suppression of small (“weak”) components of the vector U. This property of enables us to reduce to zero weak components that are not essential for the description of data.
The aim of our work is to outline an approach to accelerating the convergence of learning algorithms in RSMM with space dilation and to give an example of the implementation of such an algorithm, confirming the effectiveness of theoretical constructions.
In the RSMM, successive approximations [
18,
19,
20,
26,
28,
44] are:
where
k is the iteration number,
is the stepsize,
is a given starting point, and the descent direction
is a solution of a system of inequalities on
[
20]:
Hereinafter, is a dot product of vectors, and G is a set of subgradients calculated on the descent trajectory of the algorithm at a point .
Denote as
a set of solutions to inequality (
5), as
is a subgradient set at point
x. If the function is convex and
is an
-subgradient set at point
, and
is an arbitrary solution of system (
5), then the function will be reduced by at least
after iteration (
4) [
20].
Since there is no explicit specification of
-subgradient sets, the subgradients
are used as elements of the set
G, calculated on the descent trajectory of the minimization algorithm. These vectors must satisfy the condition:
Inequality (
6) means that for the vectors used, condition (
5) is not satisfied. The choice of learning vectors is made according to this principle in the perceptron method [
25,
45], for instance.
A sequence of vectors
is not predetermined, but determined during minimization (
4) with a built-in method for finding the vector
at each iteration of minimization by a ML algorithm.
Let vector
be a solution of the system of inequalities (
5) for the subgradient set of some neighborhood of the current minimum
. Then, as a result of iteration (
4), we go beyond this neighborhood with a simultaneous function decrease, since vector
forms an acute angle with each of the subgradients of the set.
In this work, we present a formalized model of subgradient sets, which enables us, taking into account their specificity, to formulate stronger learning relations and quality functionals, which leads to acceleration in the convergence rate of learning algorithms designed to form the direction of descent in the RSMM.
As a result of theoretical analysis, an effective learning algorithm has been developed. For the proposed ML algorithm, the convergence in a finite number of iterations is proved when solving problem (
5) on separable sets. Based on the learning algorithm, we proposed a method for minimizing nonsmooth functions. Its convergence on convex functions was substantiated. It is shown that on quadratic functions, the minimization method generates a sequence of minimum approximations identical to the sequence of the conjugate gradient method. We also proposed a minimization algorithm with a specific one-dimensional search method. A computational experiment confirmed its effectiveness for problems of neural network approximations, where the technology of uninformative model component suppression with regularizers similar to the Tibshirani LASSO was used [
46]. The result of our work is an optimization algorithm applicable for solving neuron network regularization and other machine learning problems which, in turn, contains an embedded machine learning algorithm for finding the most promising descent direction. In the problems used for comparison, the objective function forms an elongated multidimensional ravine. As with other subgradient algorithms, our new algorithm proved to be efficient for such problems. Moreover, the new algorithm outperforms known relaxation subgradient and quasi-Newtonian algorithms.
The rest of this article is organized as follows. In
Section 2, we consider a problem of acceleration of the learning algorithms convergence using relaxation subgradient methods. In
Section 3, we make assumptions regarding the parameters of subgradient sets that affect the convergence rate of the proposed learning algorithm. In
Section 4, we formulate and justify a machine learning algorithm for finding the descent direction in the subgadient method. In
Section 5, we give a description of the minimization method. In
Section 6, we establish the identity of the sequences generated by the conjugate gradient method and the relaxation subgradient method with space dilation on the minimization of quadratic functions. In
Section 7 and
Section 8, we consider a one-dimensional minimization algorithm and its implementation, respectively. In
Section 9 and
Section 10, we present experimental results for the considered algorithms. In
Section 9, we show a computational experiment on complex large-sized function minimization. In
Section 10, we consider experiments with training neural network models, where it is required to remove insignificant neurons.
Section 11 contains a summary of the work.
2. Acceleration of the Learning Algorithm’s Convergence in Relaxation Subgradient Methods
To use more efficient learning algorithms, a relation stronger than (
5) can be written for the descent direction. We make an additional assumption about the properties of the set
G.
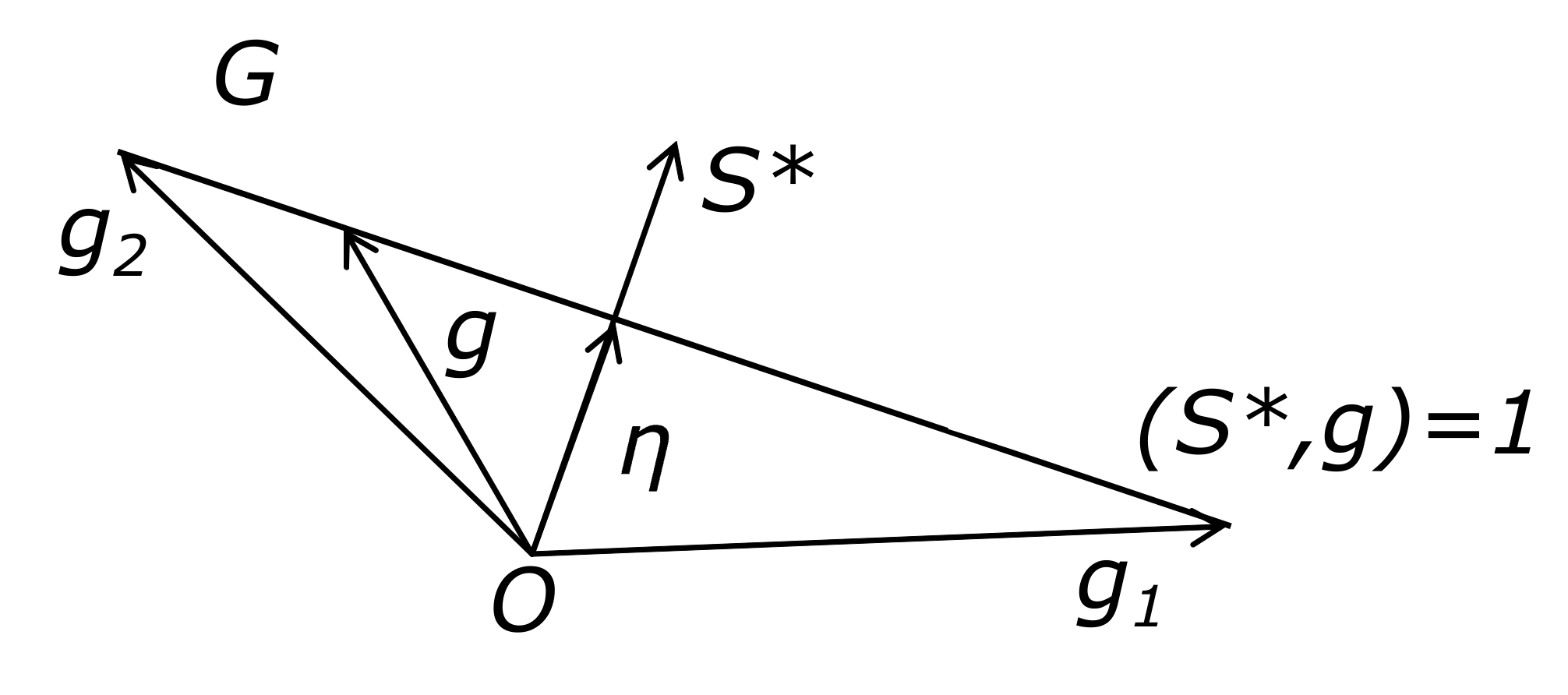
Assumption 1. Let a convex set belong to a hyperplane; its minimal length vector η is also the minimal length vector of this hyperplane. Then, a solution of the system is also a solution of (5) [26]. It can be found as a solution to a system of equations using a sequence of vectors from G [26]: It is easy to see that the solution to system (7) in s is the vector . Figure 1 shows the subgradient set in the form of a segment lying on a straight line. Equalities (7) can be solved by a least squares method. For example, using the quadratic quality functionalit is possible to implement a gradient machine learning algorithm,where is a gradient method step. Hence, when choosing , we obtain the well-known Kaczmarz algorithm [47], The found direction satisfies the learning equality . To ensure the possibility of decreasing the function as a result of iteration (4), the new descent direction in the minimization method must be consistent with the current subgradient, i.e., satisfy inequality . Process (8) corresponds to this condition. To propose a faster algorithm, consider the interpretation of process (
8). Let Assumption 1 be fulfilled. The step of process (
8) is equivalent to the step of one-dimensional minimization of the function
from point
in the direction
. Let the current approximation
be obtained using a vector
and satisfy the condition
.
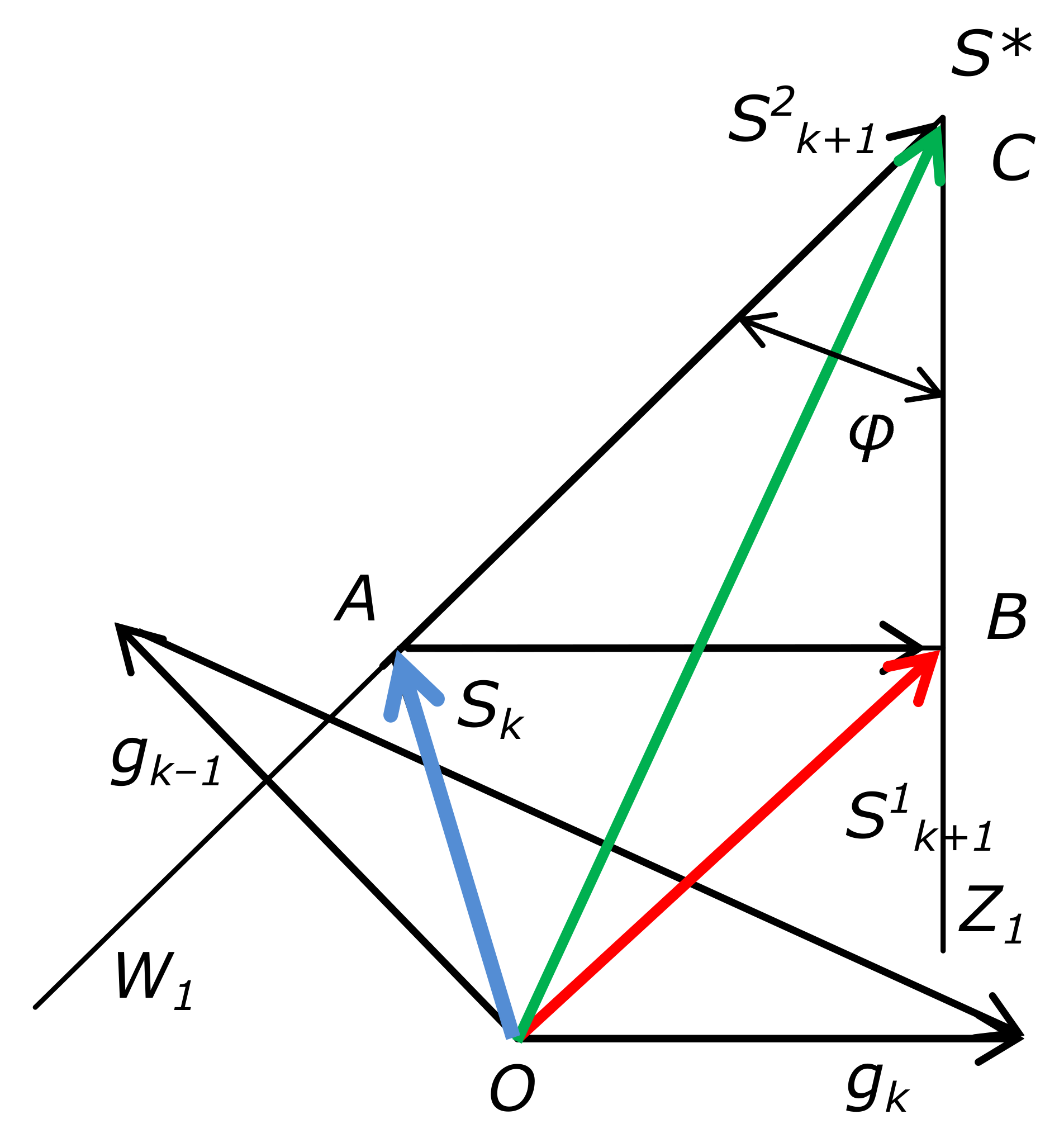
Figure 2 shows the projections of the current approximation
and the required vector
on the plane of vectors
. Straight lines
and
are hyperplane projections for vectors
s, given by the equalities
and
. Vector
is a projection of the approximation obtained from the iteration (
8).
If
, then the angle between subgradients is obtuse, and the angle
is acute (
Figure 2). In this case, it is possible to completely extinguish the projection of the residual between
and
in the plane of vectors
, passing from point
A to point
C along vector
, perpendicular to the vector
, i.e., along vector
:
In this case, the iteration has the form
In
Figure 2, this vector is denoted as
. The vector
, obtained by formula (
10), satisfies the equalities
,
and coincides with the projection
of the optimum of the function
. At small angles
between the straight lines
and
, the acceleration of convergence for process (
10) becomes essential. In this work, process (
10) will be used to accelerate the convergence in the metric of the iterative least squares method.
Using learning information (
7), one of the possible solutions to the system of inequalities (
5) can be found in the form
, where
Such a solution can be obtained by the iterative least squares method (ILS). With weight factors
, after the arrival of new data
, the transition from the previously found solution
to a new solution
in ILS is made as follows:
Note that, in contrast to the usual ILS, there is a regularizing component
in
, which allows us to use transformations (
11) and (
12) from the initial iteration, setting
and
.
In [
26], based on ILS (
11) and (
12), an iterative process is proposed for solving the system of inequalities (
5) using learning information (
7):
Here, is a space dilation parameter.
Consider the rationale for the method of obtaining formulas (
13) and (
14). Using processes (
11) and (
12) for scaled data, we obtain
where scaling factor
. The latter is equivalent to introducing the weight factors
in
. Then, after returning to the original data
, we obtain the expressions:
The transformation of matrices (
16) is practically equivalent to (
14) after the appropriate choice of the parameter
q. For transformation (
15), the condition
providing the condition for the possibility of decreasing the function in the course of iteration (
4) along the direction
may not be satisfied. Therefore, the transformation (
13) is used with
, which ensures equality
. Transformation (
13) can be interpreted as the Kaczmarz algorithm in the corresponding metric. As a result, we obtain processes (
13) and (
14). Methods [
18,
19,
20] of the class under consideration possess the properties of the conjugate gradient method. The noted properties expand the area of effective application of such methods.
The higher the convergence rate of processes (
13) and (
14), the greater the value of the permissible value
in (
14) [
26], which depends on the set
G’s characteristics. In algorithms (
13) and (
14), we distinguish 2 stages: the correction stage (
13). reducing the residual between the optimal solution
and the current approximation
, and the space dilation stage (
14), resulting in the increase in the residual in the transformed space without exceeding its initial value, which limits the magnitude of the space dilation parameter. To create more efficient algorithms for solving systems of inequalities, we have to choose the direction of correction in such a way that the reduction of the residual is higher than that of process (
13). The direction of space dilation should be chosen so that it becomes possible to increase the space dilation parameter value due to this choice.
This paper presents one of the special cases of the implementation of the correction stage and space dilation stage. It was proposed to use linear combinations of vectors
in transformation (
13) instead of a vector
when it is appropriate:
Transformations (
17) and (
18) are similar to the previously discussed transformations (
9) and (
10) carried out in the transformed space.
In the matrix transformation, we use equation (
14) instead of vector
. We also use vector
such that
As shown below, the discrepancy between the optimal solution
and the current approximation
along the vector
is small, which makes it possible to use large parameters of space dilation
in (
19). Iterations (
18) and (
19) are conducted under the condition:
In the next section, assumptions will be made regarding the parameters of subgradient sets that affect the convergence rate of the proposed learning algorithm and determine the permissible parameters of space dilation. This allows us to formulate and justify a machine learning algorithm for finding the descent direction in the subgradient method. Note that the described parameterization of the sets does not impose any restrictions on the subgradient sets but is used only for the purpose of developing constraints on the learning algorithm parameters.
4. Machine Learning Algorithm with Space Dilation for Solving Systems of Inequalities on Separable Sets
In this section, we briefly introduce an algorithm for solving systems of inequalities from [
1] and theoretically justify iterations (
18) and (
19). Specific operators will be used for transformations (
13), (
14) and (
17)–(
19). Denote by
transformation (
18)’s operator, where the correspondence is used for the eponymous components. Then, for example, Formula (
13) can be represented as
. Similarly, for (
14) and (
19), we introduce the operator
. Formula (
19) can be represented as
.
For a chain of approximations
, we form the residual vector
. Until vector
is not a solution to (
5), for vectors
selected at step 2 of Algorithm 1, from (
6) and (
22), the following inequality holds:
The transformation equation for matrix
is as follows [
1]:
where
. For vectors
and
of Algorithm 1:
where
, and
is a symmetric, strictly positive, definite matrix.
| Algorithm 1 Method for solving systems of inequalities. |
- 1:
Set , , , . Set as the limit for choosing the admissible value of the parameter for transformations ( 13) and ( 14) - 2:
Find , satisfying the condition ( 6) - 3:
If such a vector does not exist, then
end if - 4:
If or condition ( 20) is not satisfied, then
end if - 5:
Compute vector and perform transformation ( 18) . Compute the limit of the admissible values of the space dilation parameter for the combination of transformations ( 18) and ( 19) - 6:
If, then
else compute the limit of the admissible values of the space dilation parameter for the combination of transformations ( 18), ( 14); set satisfying the inequalities and perform transformation ( 14) . Go to step 8
end if
- 7:
Set and perform transformations ( 13), ( 14) , - 8:
Increase k by one and go to step 2
|
Inequality (
28) is essential in justifying the convergence rate of the methods we study for solving systems of inequalities (
5). The main idea of the algorithm formation is the point that the values of
do not increase when the values of
decrease with a geometric progression speed. In such a case, after a finite number of iterations, the right side of (
28) becomes less than one. The resulting contradiction means that problem (
5) is solved, and there is no more possibility of finding a vector
satisfying condition (
6).
For the decreasing rate of the sequence
,
, the following theorem is known [
26].
Theorem 1. Let a sequence be a transformation (14) result with and arbitrary . Then This theorem does not impose restrictions on the choice of vectors
. Therefore, regardless of which of equations (
14) or (
19) is used to transform the matrices, the result (
29) is valid for a sequence of vectors composed of
or
, depending on which one of them is used to transform the matrices. Let us show that for Algorithm 1 with fixed values of parameter
, estimates similar to (
29) are valid, and we obtain expressions for the admissible parameters
in (
14), (
19), at which the values
do not increase.
In order to obtain the visually analyzed operation of the algorithm, similarly to the analysis of iterations of the process (
9), (
10) carried out on the basis of
Figure 2, we pass to the coordinate system
. In this new coordinate system, corresponding vectors and matrices of iterations (
13), (
14) and (
18), (
19) are transformed as follows [
1]:
For expressions (
17), (
18) and (
27):
Inequality (
22) for new variables is:
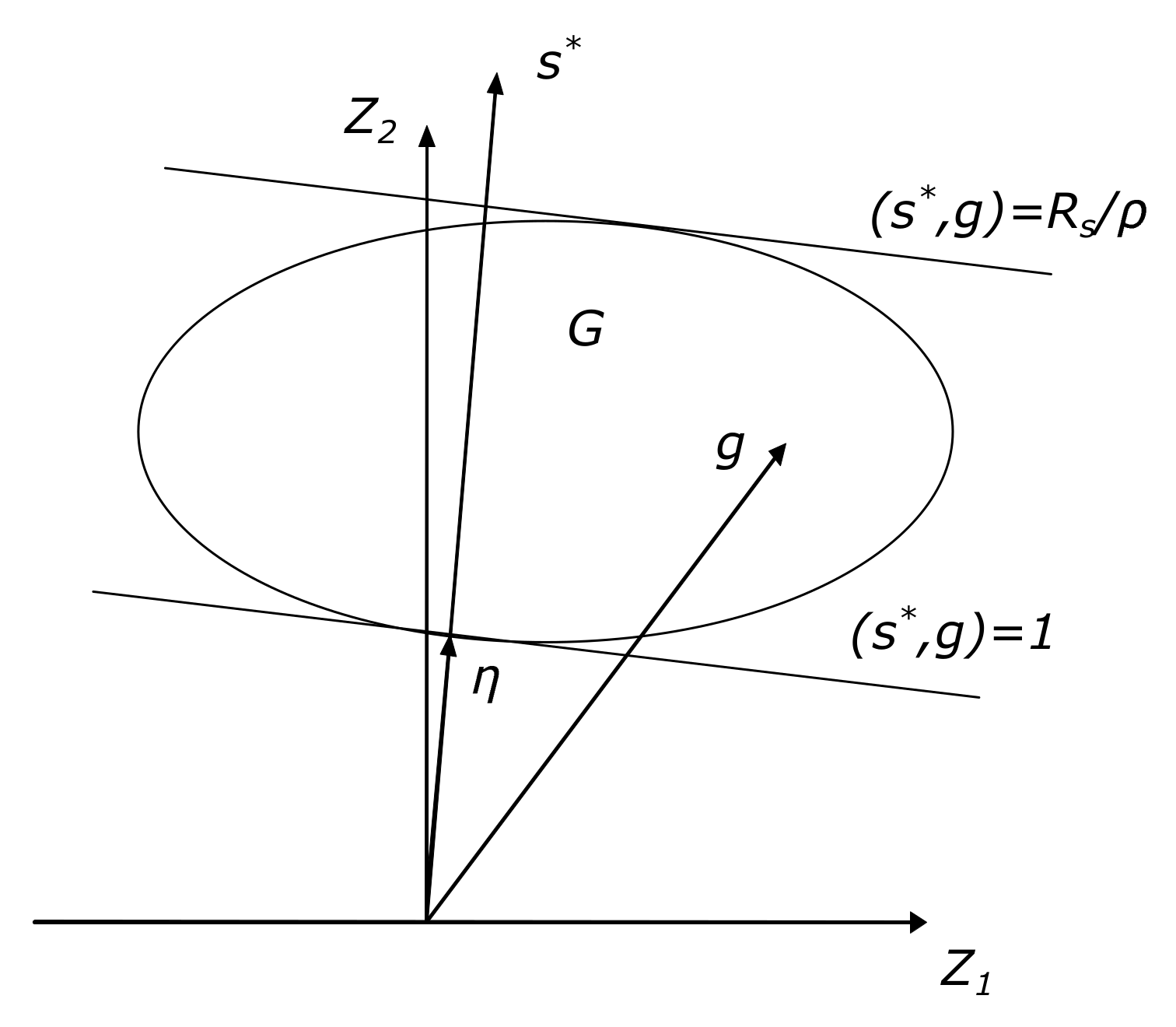
In
Figure 5, characteristics of set
in the plane
Z formed by the vectors
are shown. Straight lines
,
are projections of hyperplanes, i.e., corresponding inequality (
37) boundaries for possible positions of the vector
projections defined by the normal
. Straight lines
,
are boundaries of inequality (
37) for vector
possible projection positions defined by the normal
.
Let
be the angle between vectors
and
. Since in
Figure 5, this angle is obtuse, then condition (
20) holds:
Consequently, angle
in
Figure 5 is acute. Due to the fact that vectors
,
are normals for the straight lines
and
, we obtain the relations [
1]:
The following lemmas [
1] allow us to estimate the admissible values of space dilation parameters.
Lemma 1. Let the values a, b, c, β satisfy the constraints , and ; then: The proofs of Lemmas 1–6, as well as the proofs of Theorems 2–5, can be found in [
1].
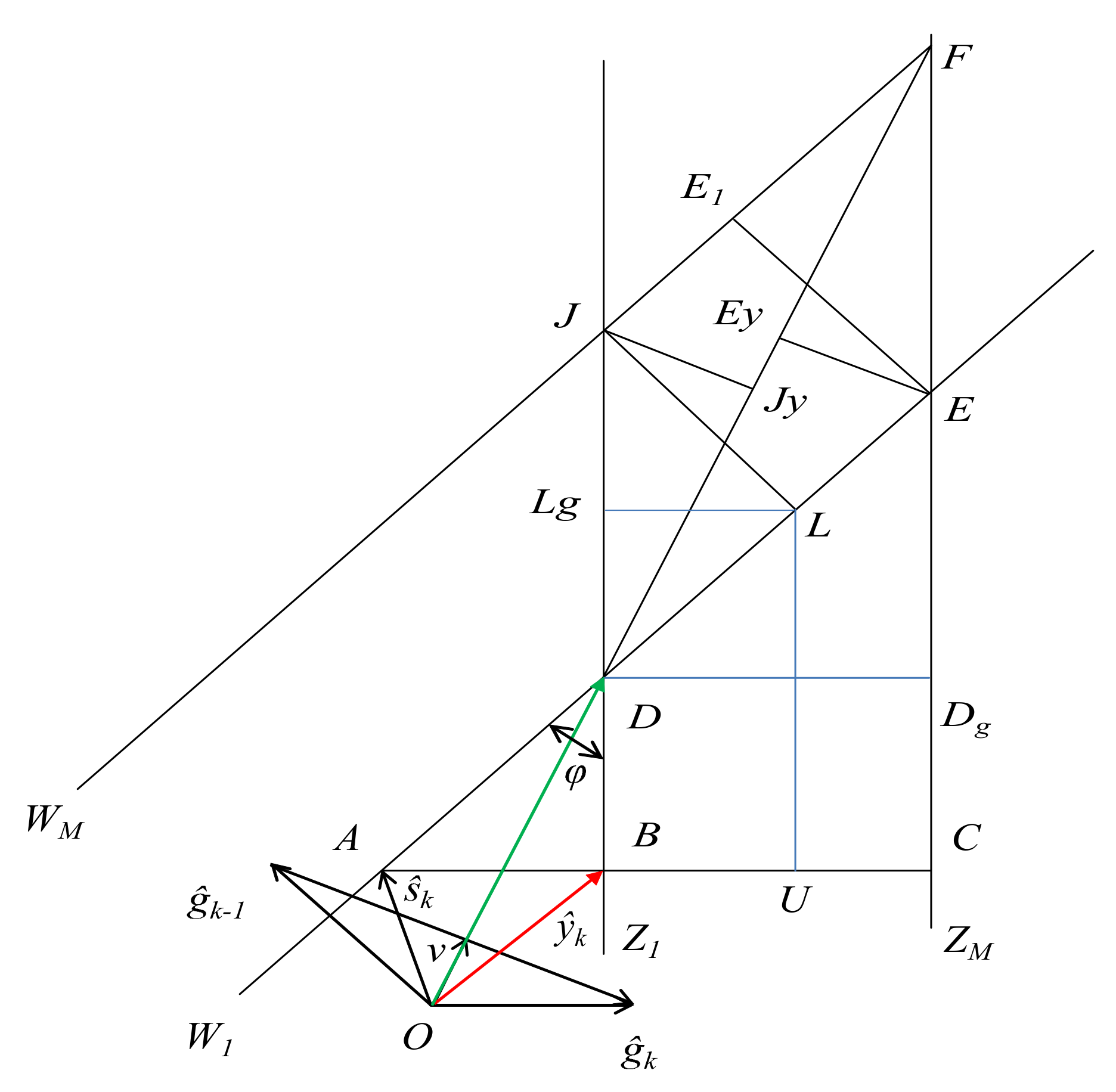
Lemma 2. Let vectors , and g be linked by equalities , . Let the difference of vectors be collinear to the vector p, and let ξ be an angle between vectors p and g; then: Lemma 3. As a result of transformation (13) at step 7 of Algorithm 1, the following equality holds:and as a result of (18) at step 5, (42) will hold, and the equality is as follows: Lemma 4. Let set G satisfy Assumption 2. Then, the limit α of the admissible parameter value in Algorithm 1 providing inequality in the case of transformations (13) and (14) is Lemma 5. Let set G satisfy Assumption 2. Then, the limit of the admissible parameter value at step 5 of Algorithm 1, providing inequality in the case of transformations (18), (14) is given by the equation:where Lemma 6. Let set G satisfy Assumption 2. Then, the limit for the admissible value of parameter at step 5 of Algorithm 1 providing inequality in the case of transformations (18) and (19) is given aswhere The value is defined in (39), and . In matrix transformations (
14) and (
19) of Algorithm 1, vectors
and
are used, which does not allow for directly using estimate (
29) of Theorem 1 in the case when expression
involves some vector
. In the next theorem, an estimate similar to (
29) is obtained directly for subgradients
generated by Algorithm 1.
Theorem 2. Let set G satisfy Assumption 1 and let the sequencebe calculated based on the characteristics of Algorithm 1 for fixed values of the space dilation parametersspecified at steps 5 and 6, where parameter α is specified according to (44). Then:where . Theorem 3. Let set G satisfy Assumption 1 and let the sequence be calculated based on the characteristics of Algorithm 1. Let dilation parameter α satisfy constraint (44) and let the admissible value be given by (47). Then: For fixed values of the space dilation parameter with respect to the convergence of Algorithm 1, the following theorem holds.
Theorem 4. Let set G satisfy Assumption 2. Let the values of the space dilation parameters in Algorithm 1 specified at steps 5 and 6 be fixed as , and let parameter α be given according to constraint (44). Then, the solution to system (5) will be found by Algorithm 1 in a finite number of iterations, which does not exceed , the minimum integer number k satisfying the inequality Herewith, until a solution is found, and the following inequalities hold: According to (
21), parameters
and
characterize the deviation of the component vectors
along the vector
. If
, there is a set
G in plane with normal
. Such a structure of the set
G allows one to specify large values of the parameter
(
44) in Algorithm 1 and, according to (
52), to obtain a solution in a small number of iterations.
In the minimization algorithm (
4) on the descent trajectory, due to the exact one-dimensional search, it is always possible to choose a subgradient from the subgradient set satisfying condition (
6), including at the minimum point. Therefore, we will impose constraints on the subgradient sets of functions to be minimized, similar to those for the set
G. Due to the biases in the minimization algorithm, we need to define the constraints, taking into account the union of subgradient sets in the neighborhood of the current minimum point
, and use these characteristics based on Theorem 4 results to develop a stopping criterion for the algorithm for solving systems of inequalities.
5. Minimization Algorithm
Since in the subgradient set at point
an exact one-dimensional search is performed, there is always a subgradient satisfying condition (
6):
. For example, for smooth functions, the equality
holds. Therefore, vector
can be used in Algorithm 1 to find a new descent vector approximation. In the built-in algorithm for solving systems of inequalities, the dilation parameter is chosen to solve the system of inequalities for the union of subgradient sets in some neighborhood of current approximation
. This allows the minimization algorithm to leave the neighborhood after a finite number of iterations.
Due to possible significant biases during the operation of the minimization algorithm, the shell of the subgradient set involved in the learning may contain a zero vector. To avoid situations when there is no solution similar to (
5) for the subgradient set from the operational area of the algorithm, we introduce an update to the algorithm of solving systems of inequalities. To track the updates, we used a stopping criterion, formulated based on Theorem 4’s results.
To accurately determine the parameters of the algorithm involved in the calculation of the dilation parameters
and
, we define their calculation in the form of operators. Denote by
the operator of calculation
according to (
45) and (
46) in Lemma 5, which is
. For
’s calculation according to expressions (
47)–(
49) in Lemma 6, we introduce operator
, where parameters
correspond to set
.
A description of the minimization method is given in Algorithm 2.
| Algorithm 2. |
- 1:
Set . Set , parameters , and the limit for the dilation parameter according to equality ( 44). Compute . - 2:
Ifthen
end if - 3:
Ifthen update
end if - 4:
If or then
end if - 5:
Compute vector and perform transformation ( 18) . Compute the limit of the admissible value of the dilation parameter for the combination of transformations ( 18) and ( 19) - 6:
Ifthen
else compute the limit of the admissible value of the dilation parameter for the combination of transformations ( 18) and ( 14), set satisfying the inequalities and perform transformation ( 14) . Go to step 8
end if
- 7:
Set and perform transformations ( 13), ( 14) , - 8:
Find a new approximation of the minimum point , - 9:
Compute subgradient , based on the condition . - 10:
Increase k and l by one and go to step 2
|
At step 9, due to the condition of the exact one-dimensional descent at step 8, the sought subgradient always exists. This follows from the condition for the extremum of the one-dimensional function. For the sequence of approximations of the algorithm, due to the exact one-dimensional descent at step 8, the following lemma holds [
20].
Lemma 7. Let function be strictly convex on , let set be limited, and let the sequence be such that . Then, .
Denote
. Let
be a minimum point of function and let
be limit points of the sequence
generated by Algorithm 2 (
). The existence of limit points of a sequence
when the set
is bounded follows from
. Concerning the convergence of the algorithm, we formulate the following theorem [
1].
Theorem 5. Let function be strictly convex on ; let set be bounded, and for ,where parameters M, r and α of Algorithm 2 are given according to the equalitiesand parameters , set at steps 5 and 7, are fixed as . In this case, if , then any limit point of the sequence generated by Algorithm 2 () is a minimum point on . 7. One-Dimensional Search Algorithm
Consider a one-dimensional minimization algorithm for process (
4). Computational experience shows that the one-dimensional search algorithm in relaxation subgradient methods should have the following properties:
An overly accurate one-dimensional search in subgradient methods leads to poor convergence. The search should be adequately rough.
At the iteration of the method, the search step should be large enough to leave a sufficiently large neighborhood of the current minimum.
To ensure the position of the previous paragraph, it should be possible to increase the search step faster than the possibilities of decreasing it.
In PCM, a one-dimensional search should provide over-relaxation, that is, overshoot the point of a one-dimensional minimum along the direction of descent when implementing iteration (
4). This provides condition (
6), which is necessary for the learning process.
When implementing one-dimensional descent along the direction at iteration (
4), as a new approximation of the minimum, one can take the points with the smallest value of the function, and for training, one can take the points that ensure condition (
6).
We use the implementation of the one-dimensional minimization procedure proposed in [
26]. The set of input parameters is
, where
x is the current minimum approximation point,
s is the descent direction,
is the initial search step, and
,
; moreover, the necessary condition for the possibility of decreasing the function along the direction
must be satisfied. Its output parameters are
. Here,
is a step to the new minimum approximation point
where
is a step along
s, such that at the point
for subgradient
, inequality
holds. This subgradient is used in the learning algorithm. The output parameter
is the initial descent step for the next iteration. Step
is adjusted in order to reduce the number of calls to the procedure for calculating the function and the subgradient.
In the minimization algorithm, vector is used to solve the system of inequalities, and point is a new minimum approximation point.
Denote the call to the procedure of one-dimensional minimization as
;
. Here is a brief description of it. We introduce the one-dimensional function
. To localize its minimum, we take an increasing sequence
and
with
. Here,
is step increase parameter. In most cases,
is set. Denote
,
,
;
l is the number
i at which the relation
holds. Let us determine the parameters of the localization segment
of the one-dimensional minimum
,
,
,
,
,
and find the minimum point
using a cubic approximation of function [
48] on the localization segment using the values of the one-dimensional function and its derivative. Compute
The initial descent step for the next iteration is defined by the rule . Here, is the parameter of the descent step decrease, which, in most cases, is given as . In the overwhelming majority, when solving applied problems, the set of parameters is satisfactory. When solving complex problems with a high degree of level surface elongation, the parameter should be increased.
8. Implementation of the Minimization Algorithm
Algorithm 2 (), as a result of updates at step 3, loses information about the space metric. In the proposed algorithm, the matrix update is replaced by the correction of the diagonal elements, and exact one-dimensional descent by approximate. Denote by the matrix H’s trace and denote by the limit of admissible decrease in the matrix H’s trace. The algorithm sets the initial metric matrix . Since, as a result of transformations, the elements of the matrix decrease, then when the trace of the matrix decreases, , it is corrected using the transformation , where is a lower bound for trace reduction, and n is the space dimension. As an indicator of matrix degeneracy, we use the cosine of the angle between vectors g and . When it decreases to a certain value , which can be done by checking , transformation is performed. Here, I is the identity matrix and is the cosine angle limit. To describe the algorithm, we will use the previously introduced operators.
Let us explain the actions of the algorithm. Since
, then at
, condition (
6) is satisfied, and
and
. Therefore, at step 8, learning iterations (
13) and (
14) will be implemented. According to the algorithm of the
procedure, the subgradient
obtained at step 10 of the algorithm satisfies the condition (
6):
. Therefore, at the next iteration, it is used in learning in steps 6–8.
At step 9, an additional correction of the descent direction is made in order to provide the necessary condition
for the possibility of descent in the direction opposite to
. From the point of view of solving the system of inequalities, this correction also improves the descent vector, which can be shown using
Figure 5. Here, as under the conditions of Lemma 4, the movement is made in the direction
, not from point
A, but from some point of the segment
, where
. Since the projection of the optimal solution is in the area between the straight lines
,
, the shift to point
B, where
, reduces the distance to the optimal vector.
An effective set of parameters for the
in the minimization algorithm is
. The next section presents the results of numerical studies of the presented Algorithm 5.
| Algorithm 5 |
- 1:
Set . Set , , , and the limit for the dilation parameter according to equality ( 44) . Compute . Set , , . - 2:
Ifthen
- 3:
Ifthen
- 4:
Ifthen
- 5:
If or then - 6:
Perform transformations ( 17) and ( 18) for the training system of subgradients: , . Compute the limit of the dilation parameter for the combination of transformations ( 18) and ( 19) - 7:
Ifthen
- 8:
Set and perform transformations ( 13), ( 14) , - 9:
Ifthen
- 10:
Perform one-dimensional minimization ; and compute a new approximation of the minimum point - 11:
Ifthen
else Here, the subgradient is obtained in the procedure and is used as the current approximation of the minimum. Subgradient is also obtained in the procedure. It satisfies condition ( 6) and is further used in training
- 12:
Ifthen
|
9. Computational Experiment Results
In this section, we conduct a computational experiment on minimizing test functions using the following methods: (1) the relaxation method with space dilation in the direction of the subgradient (
) [
26]; (2) the r-algorithm (
) [
22,
26]; (3) the quasi-Newtonian method
implemented with the matrix transformation formula
; (4) algorithm
with the fixed parameter (
), where
; (5) an algorithm with a dynamic way to select the space dilation parameter (
), where
.
As test functions, we took functions with a high degree of level surface elongation, which increases with the dimension:
- (1)
;
- (2)
;
- (3)
;
- (4)
;
- (5)
.
When testing the methods, the values of the function and the subgradient were computed simultaneously. Parameter
for quadratic functions was chosen as a sufficiently small value (
); for non-smooth functions, it was chosen so that the accuracies in terms of variables are approximately the same for different types of functions.
Table 1,
Table 2,
Table 3,
Table 4,
Table 5 and
Table 6 show the number of calculations of the function values and the subgradient values necessary for achieving the required accuracy for the function
. The initial point of minimization
and the value
are given in the description of the function.
The test case contains quadratic and piecewise linear functions. Due to their simplicity and unambiguity, an analysis of the level surface elongation can be carried out easily. This choice of functions is due to the fact that, during minimization, the local representation in the current minimization area, as a rule, has either a quadratic or piecewise linear representation.
Functions 1 and 2 are quadratic, where the ratio of the minimum to maximum eigenvalue is . The ratio of the level surface range along the coordinate axes of the minimum to the maximum is equal to . Function 2, in comparison with function 1, has a higher density of eigenvalues in the region of small values. Function 3 is smooth with a low degree of variation of the level surface elongation. Its complexity is due to the degree above quadratic. Functions 4 and 5 are piecewise. For these functions, the ratio of the level surface range along the coordinate axes of the minimum to the maximum is equal to . the same as for quadratic functions 1 and 2. It is of interest to compare the complexity of minimizing smooth and nonsmooth functions by nonsmooth optimization methods provided that their ratios of the surface range are identical.
None of problems 1, 2, 4 and 5 can be solved by the multistep minimization method [
24] for
, which emphasizes the relevance of methods with a change in the space metric, in particular, space dilation minimization algorithms capable of solving nonsmooth minimization problems with a high degree of level surface elongation.
In order to identify the least costly one-dimensional search in the quasi-Newtonian method, it was implemented in various ways when specifying the initial unit step. Due to the high degree of condition number for functions 1 and 2, for the best of them, the costs of localizing a one-dimensional minimum when minimizing function 1 include about 2–4 steps. This, together with the final iteration of the approximation and finding the minimum on the localized segment, adds up to 3–5 calculations of the function and the gradient. For function 2, the total iteration costs are 5–10 calculations of the function and the gradient.
Table 1,
Table 2 and
Table 3 for the
method show only the number of iterations required to solve the problem.
According to the results of
Table 1 and
Table 2, the
algorithm outperforms the
and
methods on smooth functions. Therefore, the changes in the directions of correction and space dilation have a positive effect on the convergence rate of the new algorithm. In the
algorithm, compared to
, an additional factor of convergence acceleration is involved due to an increase in the space dilation parameter, which, according to the results of
Table 1 and
Table 2, led to an increase in the
algorithm’s convergence rate.
For function 2, the eigenvalues of the Hessian are shifted to the small values area, which has a positive effect on the convergence rate of subgradient methods. Here, the quasi-Newtonian method , taking into account the costs of localizing the minimum in a one-dimensional search, required a larger number of calculations of the function and gradient.
For function 3, the number of iterations of the quasi-Newtonian method turned out to be higher than the number of calculations of the function and the gradient of subgradient methods. Based on the results of minimizing functions 1–3, we can conclude that subgradient methods with space dilation can also be useful in minimizing smooth functions. New methods and show better results here than other algorithms with space dilation.
According to the ratio of the level surface range along the coordinate axes, functions 1, 2, and 4 are similar. Function 4 is difficult to minimize by subgradient methods. Comparing the results of
Table 1 and
Table 4, we can note insignificant differences in the convergence rate of subgradient methods on these functions, which is additional evidence of the method’s effectiveness in solving nonsmooth optimization problems.
To simulate the presence of the thickness of the subgradient set when minimizing function 4, the subgradients
in the process of minimization were generated with interference according to the
, where
is a uniformly distributed random number. The interference negatively affects both the quality of the one-dimensional search and the quality of the descent direction. The results are shown in
Table 5. Here, the maximum possible value of the characteristic of a subgradient set
. Due to the random nature of the quantities
, the value of
M for a set of subgradients on a certain time interval of minimization may have smaller values. According to the results of Lemma 4, the admissible value is
. The calculations were carried out at large values of the space dilation parameter
. The proposed methods also show significantly better results here.
The ratios of the level surface range along the coordinate axes for functions 5 and 1 are similar. The results for function 5 are shown in
Table 6. Here, the RSD method has an advantage due to the fact that the function is separable and all of its subgradients calculated in the minimization procedure are directed along the coordinate axes. Space dilations occur along the coordinate axes, which does not change the eigenvectors of the metric matrix directed along the coordinate axes.
To simulate the presence of the thickness of the subgradient set when minimizing function 5, the subgradients
in the process of minimization were generated with interference according to the
, where
is uniformly distributed random number. The results for function 5 with subgraduient distortion are shown in
Table 7. Here, the maximum possible value of the characteristic of a subgradient set
. The proposed methods show better results here than the
and
methods.
A number of conclusions can be drawn regarding the convergence rate of the presented methods:
Functions 1, 2, 4, 5 have a significant degree of level surface elongation. The problems of minimizing these functions could not be solved by the multistep minimization methods investigated in [
24], which emphasize the relevance of developing methods with a change in the space metric, in particular, space dilation minimization algorithms capable of solving nonsmooth minimization problems with a high degree of level surface elongation.
Based on the results of minimizing smooth functions 1–3, we can conclude that subgradient methods with space dilation can also be useful in minimizing smooth functions. At the same time, the new algorithms and also show significantly better results on smooth functions than other subgradient and methods.
The new methods and significantly outperform the and methods when minimizing nonsmooth functions. In the algorithm, in comparison with the algorithm, an additional factor of convergence acceleration is involved due to an increase in the space dilation parameter, which also leads to a significant increase in the convergence rate.
10. Computational Experiment Results in Approximation by Neural Networks
The purpose of this section is to demonstrate the usefulness of applying the methods of nonsmooth regularization (for example, the “Tibshirani lasso” [
3]) to the problems of the elimination of uninformative variables when constructing mathematical models, where a necessary element of the technology is rapidly converging nonsmooth optimization methods applicable to minimize nonsmooth nonconvex functions. In this section, we will give several examples of approximation by artificial neural networks (ANN) using nonsmooth regularization to remove uninformative neurons. To assess the quality of this approximation technology using nonsmooth regularization, the obtained approximation results are compared with the previously known results. In each of the examples, a study of the effectiveness of the presented nonsmooth optimization methods will be carried out.
Consider the approximation problem
where
are observational data,
are different kinds of regularizers,
are regularization parameters,
is an approximating function,
is a data vector,
is a vector of the tunable parameters, and
p and
n are their dimensions. Formulas (
1)–(
3) can be used as regularizers.
Suppose that in the problem of approximation by a feedforward network, it is required to train a two-layer sigmoidal neural network of the following form using data
D (i.e., evaluate its unknown parameters
w)
For the sigmoidal network
where
are components of vector
,
is a set of parameters, the total number of which is denoted by
n,
is a neuron activation function, and
m is the number of neurons. The unknown parameters
w must be estimated by the least squares method (
64) using one of the regularizers
. To solve problem (
64), we use subgradient methods.
In a radial basis function (RBF) network, we will use the following representation of a neuron
where
are components of vector
, and the network parameters will be as follows:
One of the goals of our study is to compare the effectiveness of subgradient methods in solving the problem of approximating a two-layer sigmoidal ANN under conditions of reducing the number of excess neurons using various regularization functionals. To assess the quality of the solution, we will use the value of the root-mean-square error:
on a test sample of data
uniformly distributed in
.
In the algorithm we use (Algorithm 6), at the initial stage, an approximation of the ANN is found with a fixed position of the neurons’ working areas using the specified centers
,
in the approximation area defined by the data. By neuron working area, we mean the area of significant changes in the neuron activation function. The need for fixation arises due to the possible displacement of the working areas of neurons outside the data area. As a result, the neuron in the data area turns into a constant. For the RBF networks (
65) and (
67), this is easy to do, since the parameters of the centers are present in expression (
67). For RBF networks (
65) and (
66), instead of (
66), the following expression will be used:
where vector
w components do not contain free members. In this case, some center
is located on the central hyperplane of the working band of a sigmoidal neuron. Centers
inside the data area can be found by some data clustering algorithm
, which will ensure that neurons are located in areas with high data density. We use the maximin algorithm [
45] in which two data points that are maximally distant from each other are selected as the first two centers. Each new center is obtained by choosing data point
, the distance from which to the nearest known center is at its maximum. The resulting centers are mainly located on the edges of the data area. Computational experience shows that the use of the k-means method turns out to be ineffective, or effective with a small number of iterations.
| Algorithm 6 Training Algorithm |
- 1:
On the data D, using the maximin algorithm, form the centers , where m is the initial number of neurons. Set the regularization parameter and the type of regularizer . Using a generator of uniformly distributed random numbers for each neuron, determine the initial parameters of the ANN. - 2:
Solve the problem of estimating the parameters W of the neural network ( 64) for an ANN at fixed centers with a regularizer . Create an initial set of parameters for solving the problem of estimating network parameters ( 64) without fixing the centers of neurons. The resulting set of parameters is denoted by . - 3:
Fordo 3.1 Set , where is a neural network obtained as a result of solving problem ( 64) at the current iteration. Perform sequential removal of all neurons for which, after removal, inequality is satisfied, where , is a neural network with removed neurons. If none of the neurons could be removed, then the neuron is removed, leading to the smallest increase in the value . 3.2 If the number of neurons is less than three, then endif 3.3 Using the neural network parameters for the remaining neurons as initial values, obtain a new approximation , solving problem ( 64) for the ANN with regularizer
endfor |
Initially, problem (
64) is solved with an excess number of neurons at fixed centers
for the RBF network in the forms (
65) and (
67) or for a sigmoidal network in the forms (
65) and (
68). Regularization even with an excessive number of parameters in comparison with the amount of data allows, at this stage, to obtain an acceptable solution.
After solving problem (
4) with fixed centers, it is necessary to return to the original description for the sigmoidal network in the forms (
65) and (
66). This can be done through the formation of a free member of the neuron
while leaving the other parameters unchanged. Such an algorithm for finding the initial approximation of the sigmoidal ANN guarantees that the data area will be covered by the working areas of neurons.
Here is a brief description of the algorithm for constructing an ANN. The algorithm first finds the initial approximation for fixed working areas of neurons and then iterates the removal of insignificant neurons, which is followed by training the trimmed network.
With a limited number of data, ANN with a number of parameters n not exceeding N and the smallest value of is selected as the final approximation model.
Consider examples of solving approximation problems.
Table 8,
Table 9 and
Table 10 show the value of
calculated during the operation of the network learning algorithm with the sequential removal of insignificant neurons after network training at step 3.3. The first row of each table contains the function
to be approximated, the initial number of neurons
, number of training data
, the type of regularizer, the regularization parameter
, and the index deduced by rows. The first two columns indicate the number of neurons and the number of ANN parameters. The remaining columns show the values of the index for the tested methods. The values of the index with the limiting order of accuracy are highlighted in bold. This allows one to see a segment of maintaining a high quality of the network with a decrease in the number of neurons for each of the presented minimization algorithms. For some of the tables, the last row contains the minimum value of the maximum network deviation for the constructed models on the test data
. The dimensions of problems where the number of model variables exceeds the number of data are underlined. Standard least squares practice recommends having more data than the parameters to be estimated. Good values of the index for this case emphasize the role of regularization in approximation by neural networks.
In [
49], in the domain
the function
was approximated by the cascade correlation method using data uniformly distributed at
N = 500. The maximum deviation of the ANN obtained in [
49] with the number of neurons
on the test sample of 1000 data was
. Such a result is practically very difficult to obtain using the standard ANN learning apparatus. The authors in [
49] did not succeed in obtaining such a result without first fixing the position of the working areas of neurons at the initial stage of the approximation algorithm. In our work, we obtained a series of ANN models with a smaller number of network training data
and with an assessment of the results on a test sample
consisting of 10.000 data with good approximation quality (
for selected index values). For example, for some of the constructed models,
, which is almost an order of magnitude less than the result from [
49].
Table 8 shows the results of the approximation of the function
using a smooth regularizer
. The quasi-Newtonian method (
) was also used here. Using the
,
and
methods, it is possible to obtain a better quality approximation with a smaller number of neurons. The
method is inferior in approximation quality to subgradient methods. Note that in some cases, the number of network parameters exceeds the number of data. At the same time, the network quality index is not worse than in the area with
. For the methods
and
, the best indexes are in the
area.
Table 9 shows the results of approximating function
by the sigmoidal ANN using a nonsmooth regularizer
(“Tibshirani lasso” technique [
3]). Here, the trend in the relative efficiency of the methods continues. Using the
,
and
methods, it is possible to obtain a better-quality approximation with a smaller number of neurons.
Table 10 shows the results of approximating function
by the sigmoidal ANN using a nonsmooth regularizer
. Using the
,
and
methods, it is possible to obtain a better quality approximation with a smaller number of neurons. When using a nonsmooth regularizer to approximate a function, it is possible to obtain an ANN with good approximation quality characteristics with a smaller number of neurons.
Based on the results of
Table 8,
Table 9 and
Table 10, it can be concluded that the use of regularizers makes it possible to obtain a qualitative approximation in the case when the number of parameters of the neural network function exceeds the number of data.
In [
49], on the data at
, formed in the domain
, the generator of uniform random numbers approximated the function:
The maximum deviation of the ANN constructed in [
49], based on RBF, on a test sample of 1000 data was
. Function
is a typical example of a convenient radial basis function for approximating a network. In this work, we obtained a series of ANN models based on RBF with a smaller number of network training data
and with an assessment of the results on the test sample
consisting of 10.000 data, with good quality of approximation. For example, several of the constructed models give a value that is an order of magnitude smaller:
(see
Table 11).
Table 11 shows the value of the index
calculated during the operation of the network learning algorithm with the sequential removal of insignificant neurons after training the network at step 3.3. The initial number of neurons is 36. The first two columns indicate the number of neurons and the number of ANN parameters. The last row of the tables shows the maximum deviation of the network for the constructed models on the test data
. On this function, the methods
,
and
turned out to be equivalent in quality of approximation.
In [
50], for testing purposes, an RBF ANN was built on data uniformly distributed in the domain
for function
with the number of data
. In this case, the achieved value of the root-mean-square error on the training sample is
[
50]. We have built a number of sigmoidal ANNs with several orders of magnitude lower value of the quality index on a test sample. The values of the index
on the test sample, depending on the number of neurons in the ANN, are given in
Table 12. Here, as earlier, algorithms
and
manage to obtain a longer series of ANN models with good quality of approximation.
In this section, the ANN training technology was presented, where nonsmooth optimization methods are its integral component. A specific feature of the ANN approximation problems is the absence of convexity of the minimized functions. The fastest methods and turn out to be more effective in solving problems of ANN approximation and make it possible to obtain models with a smaller number of neurons. Nevertheless, the experience of solving similar problems of approximation suggests that when solving an applied problem, it is better to have several alternatives for choosing a minimization method.


 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}