Three experimental data sets of different scales, Hepth, Enron and Bitcon, were selected to form a social network graph. The significance of the multivariate features and potential structural features of MF-PSF feature sets in community evolution prediction was elucidated through experiments, and the effectiveness of the feature sets constructed by MF-PSF method in improving the accuracy of community evolution prediction were verified by comparative analysis with the feature sets constructed by other community evolution prediction methods.
5.2. Multivariate Feature Set Importance Analysis
The Random Forest prediction model was used to predict community evolution combined with the extracted multivariate feature set in this paper. Random Forest is an effective machine learning algorithm for classification and regression problems. It is flexible and simple to use. The Random Forest algorithm has high accuracy, is excellent at handling high-dimensional data and can rank the importance of features. Six community evolution events are predicted by using four extracted features: core node features, community structural features, community sequential features and community behavior features. The importance of the extracted features in predicting each evolution event is studied. The importance of each feature in the Hepth data set in predicting each evolutionary event is shown in
Figure 2. Dissolving, continuing, growing, merging, shrinking and splitting are the six types of community evolutionary events depicted on the horizontal axis, and the four categories of community features extracted are depicted on the vertical axis. The depth of the color in the figure represents the importance of the feature in the process of community evolution prediction. The darker the color, the more important the feature is in predicting the community evolution events.
It can be seen from
Figure 2 that the importance of each feature is different when predicting different evolutionary events. In the Hepth dataset, for predicting dissolving events, the four features of EdgeRatio, SizeRatio, Preform and LifeSpan are more important, while the other features are less important. For continuing events, the community sequential features and community behavior features are more important in the prediction process, and the number of features that play an important role is more than that of other evolutionary events. For shrinking and splitting events, the community structural features that play an important role are more distributed in the community structural features, and the LifeSpan feature also plays an important role in the prediction process.
The importance of the features of the Enron data set in predicting evolutionary events is illustrated in
Figure 3. In the Enron data set, the five characteristics of SizeRatio, EdgeRatio, AverageInDegree, LifeSpan and PreForm are relatively important for predicting dissolving, continuing and growing events, while the other characteristics are less important. The overall importance of each feature in the process of dissolving event prediction is similar to that in the Hepth data set. Community sequential features and community behavior features play important roles in predicting continuing events, which are different from those in the Hepth data set. For shrinking and splitting events, the community structural features that play an important role in the prediction of shrinking events are mostly distributed in the community structural features, while the community sequential features that play an important role in the prediction of splitting events are more distributed in the community structural features.
Figure 4 illustrates the significance of each Bitcoin data set attribute in predicting each evolutionary event. When predicting dissolving events, the core node features and community structural features are crucial and the AverageExDegree, the SizeRatio and the EdgeRatio are the most significant features.Community sequential features and community behavior features play important roles in predicting continuing events. For the prediction of growing events, shrinking events and splitting events, the community behavior features play a little role, and the important features are distributed among the core node features, community structural features and community sequential features.
In the prediction processes of the Hepth, Enron and Bitcon data sets, the analysis shows that the importance of features in each evolutionary event varies depending on the dataset. For different community evolution events in the same data set, the importance of extracted community features is different. The experimental results show that it is very important to extract sufficient and comprehensive features of community evolution in the process of community evolution prediction.
5.3. Importance Analysis of Potential Structural Features
Based on the analysis of the importance of each feature in the multivariate community feature set, the importance of the community potential structural features extracted that contain information on the internal topology of the community is analyzed. A new feature set is jointly constructed to predict community evolutionary events using the four types of community features in the multivariate feature set, combined with the extracted community potential structural features, and the importance of the features in the five new types of feature sets is analyzed to verify the effectiveness of the potential structural feature. The experimental results are shown in
Figure 5,
Figure 6 and
Figure 7.
The horizontal axis shows the five types of community features, core node features, community structural features, community sequential features, community behavior features and community potential structural features, while the vertical axis shows the prediction of six types of community evolution events: dissolving, continuing growing, merging, shrinking, and splitting. The shade of the color in the graph represents the importance of the features in the prediction process, with the darker the color indicating that the features are more essential in predicting community evolutionary events.
Figure 5 shows the importance distribution of various features in the Hepth dataset in predicting various evolutionary events. It can be seen that in the process of predicting community evolutionary events, the importance of the five extracted features in predicting each evolutionary event is significant. For the four types of community evolution events, i.e., dissolving, growing, merging, and splitting, the potential structure of community is the most important feature in evolutionary prediction, followed by the community structure. For shrinking events, community structural features are the most important type of features, and other features are of similar importance. For continuing events, community core node features, community structural features, community sequential features and community potential structural features are similar in importance.
Figure 6 shows the importance distribution of various features of the Enron dataset in predicting evolutionary events. According to the experimental results, for the five types of community evolution events, including dissolving, continuing, growing, merging and splitting, the potential structural features of the community are the most important features in the prediction process. For shrinking events, community structural features are the most important in the prediction process, and the importance of the other four features is similar.
Figure 7 shows the importance distribution of each type of feature in the Bitcon dataset for predicting each evolutionary event. For the three types of community evolutionary events (dissolving, growing and splitting), the potential structural features are the most important features in the prediction process. For shrinking, merging and continuing events, the importance of potential structural features, community structural features and community sequential features are similar in the prediction process.
The experimental results show that the extracted multivariate features play a certain degree of role in predicting each evolutionary event, and that the extracted potential structural features are the most important in predicting most evolutionary prediction events, indicating that the potential structural features extracted are effective in evolutionary prediction in this paper.
5.4. Evolutionary Prediction Results
The proposed community evolution prediction method MF-PSF constructs a feature set including four types of features in the multivariate feature set and the extracted community potential structural features. In order to verify the effectiveness of the feature set extracted by the MF-PSF method, a Random Forest prediction model was used, and the average F1 value was calculated by the ten-fold crossover algorithm. The feature set F_1 in reference [
18], F_2 in reference [
7], F_3 in reference [
6] and F_4 extracted by the MF-PSF method were extracted for experiments, and the influence of each feature set on the prediction accuracy of community evolution events was compared and analyzed.
The Random Forest classifier has higher accuracy compared to the KNN and SVM classifiers, while the KNN and SVM classifiers also have the drawback of high computational complexity. Due to the characteristics of our data sets, linear classifiers also cannot play a good role in community evolutionary event prediction. As a result, the Random Forest classifier is used in this paper. As shown by the F1 values, better prediction results for each data set are achieved based on the Random Forest classifier.
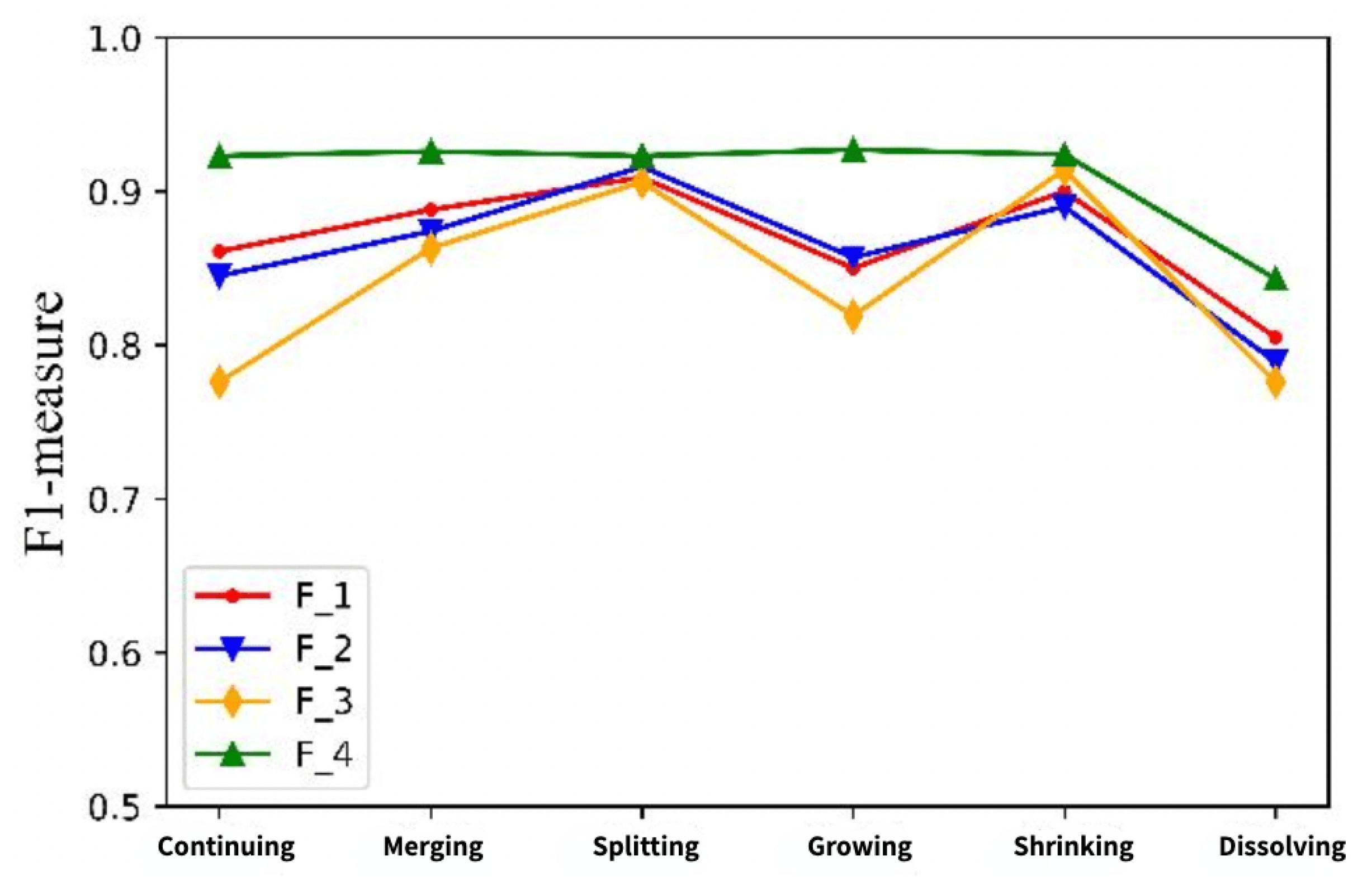
Figure 8 shows the comparison of the evolution results of each feature set predicted by the Hepth data set. It can be seen that the accuracy of F_4 extracted by the MF-PSF method is higher than the other feature sets in predicting all kinds of evolutionary events.
For continuing events, the F_4 feature set constructed by the MF-PSF method is used to predict community evolution, and the predicted F1 value is 0.870, which is 0.5%, 7.5% and 4% higher than that of the F_1, F_2 and F_3 feature sets, respectively. For merging events, the prediction F1 value of F_4 extracted by the MF-PSF method is 0.913, which is 3.7% higher than that of the F_2 feature set, with a better prediction result. For splitting events, the predicted F1 value of F_4 extracted by the MF-PSF method was 0.924, which was 3.4%, 2.8% and 0.7% higher than that of F_1, F_2 and F_3, respectively. For growing events, the F_4 feature set constructed by the MF-PSF method is significantly better than the F_1, F_2 and F_3 feature sets, and the predicted F1 value increased by 6.8%, 6% and 9.8%, respectively. For shrinking events, the prediction results of the F_1, F_2 and F_3 feature sets are similar, and the F_4 extracted by the MF-PSF method is improved by about 4% compared with other methods. For dissolving events, the prediction accuracy of the four feature sets is slightly lower than that of other evolution events. Compared with F_1, F_2 and F_3, the prediction evaluation value of F_4 extracted by the MF-PSF method increased by 7.8%, 1.6% and 13.4%, respectively.
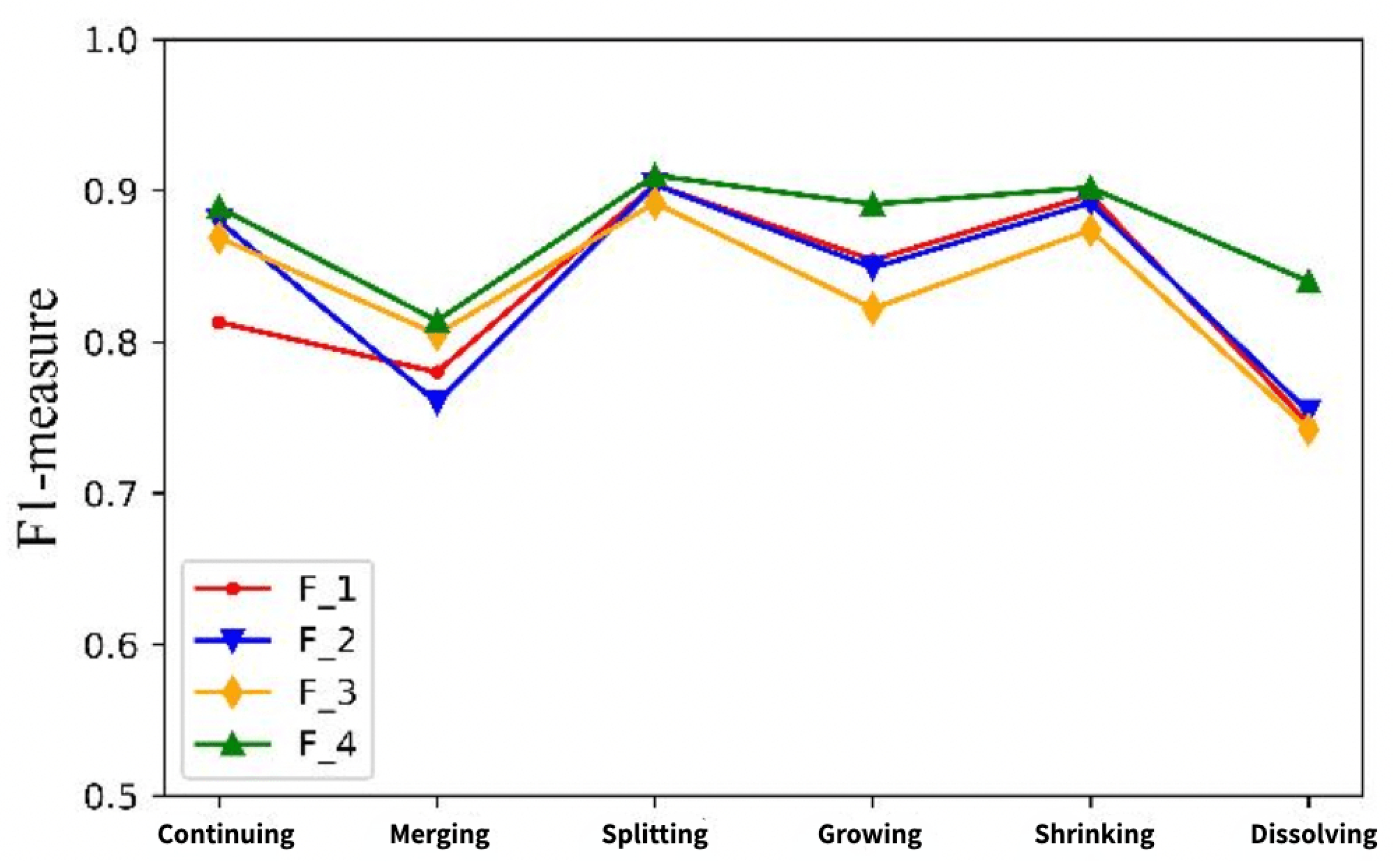
Figure 9 shows a comparison of the predicted community evolution results for each feature set in the Enron data set. For continuing events, the F_4 feature set constructed by the MF-PSF method is used to predict community evolution, and the predicted F1 value is 0.923, which is 6.2%, 7.8% and 14.7% higher than that of the F_1, F_2 and F_3 feature sets, respectively. Therefore, it can be seen that the feature set F_4 improves the accuracy of continuing event prediction. For merging events, the predicted F1 value of the F_4 feature set was 0.926, which was 3.8%, 5.2% and 6.3% higher than that of the other three feature sets, respectively. For splitting events, the F1 values predicted by the four feature sets are all above 0.9, but the prediction result of F_4 extracted by the MF-PSF method is 0.923. The F_4 feature set constructed by the MF-PSF method is superior to the F_1, F_2 and F_3 feature sets in terms of prediction results, and the predicted F1 values are increased by 7.7%, 7% and 10.8%, respectively. For the shrinking event, the predicted F1 values of the four feature sets are similar, but the F_4 feature set constructed by the MF-PSF method is still higher than the other three feature sets. For dissolving events, the prediction accuracy of the four feature sets was slightly lower than that of other evolution events. Compared with F_1, F_2 and F_3, the prediction evaluation value of F_4 extracted by the MF-PSF method improved by 3.8%, 5.4% and 6.7%, respectively.
Figure 10 shows the comparison of the evolution results of each feature set predicted by the Bitcon data set. For continuing events, the F_4 feature set constructed by the MF-PSF method is used to predict community evolution, and the predicted F1 value is 0.889, which is 9.3%, 1.0% and 2.3% higher than that of the F_1, F_2 and F_3 feature sets, respectively. For growing events, the predicted F1 value of the F_4 feature set was 0.891, which was 4.3%, 4.9% and 8.3% higher than that of the other three feature sets, respectively. For splitting events and shrinking events, the predicted F1 values of the four feature sets are similar, but the F_4 feature set constructed by the MF-PSF method is still higher than the other three feature sets. For dissolving events, the F_4 feature set constructed by the MF-PSF method is used to predict community evolution, and the predicted F1 value is 0.840, which is 12.6%, 11.4% and 13.2% higher than that of the F_1, F_2 and F_3 feature sets, respectively. Therefore, it can be seen that the feature set F_4 improves the accuracy of dissolving event prediction. For merging events, the F_4 feature set constructed by the MF-PSF method is significantly better than the F_1, F_2 and F_3 feature sets, and the predicted F1 value increases by 4.3%, 7.1% and 1.1%, respectively.
According to the experimental results, the Random Forest classifier is also used to predict various community evolution events in different data sets. The feature set constructed by MF-PSF based on multivariate feature set and potential structural features could describe community characteristics more effectively and improve the accuracy of community evolution prediction.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}