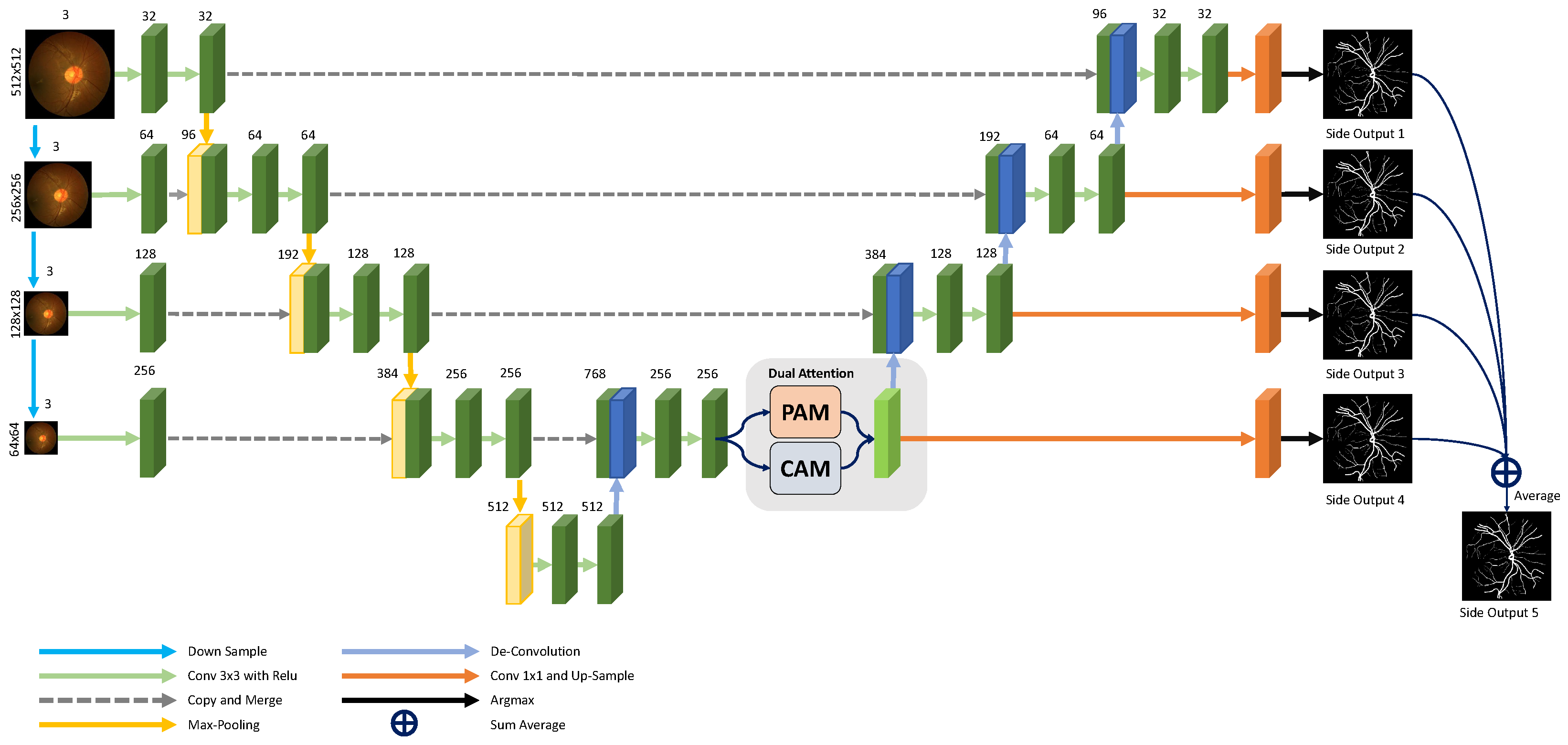
4.4. Performance Evaluation
In this section, we compare our method with other state-of-the-art methods on DRIVE and CHASEDB1 datasets. The methods include U-Net [
4], Zhang et al. [
21], Liskowski et al. [
22], DRIU [
23], Yan et al. [
24], CE-Net [
25], LadderNet [
26], DU-Net [
27], Bo Liu et al. [
28], VesselNet [
29], Yue et al. [
14], DA-Net [
6] and Yin et al. [
17].
Table 1 shows the performance on the DRIVE dataset.
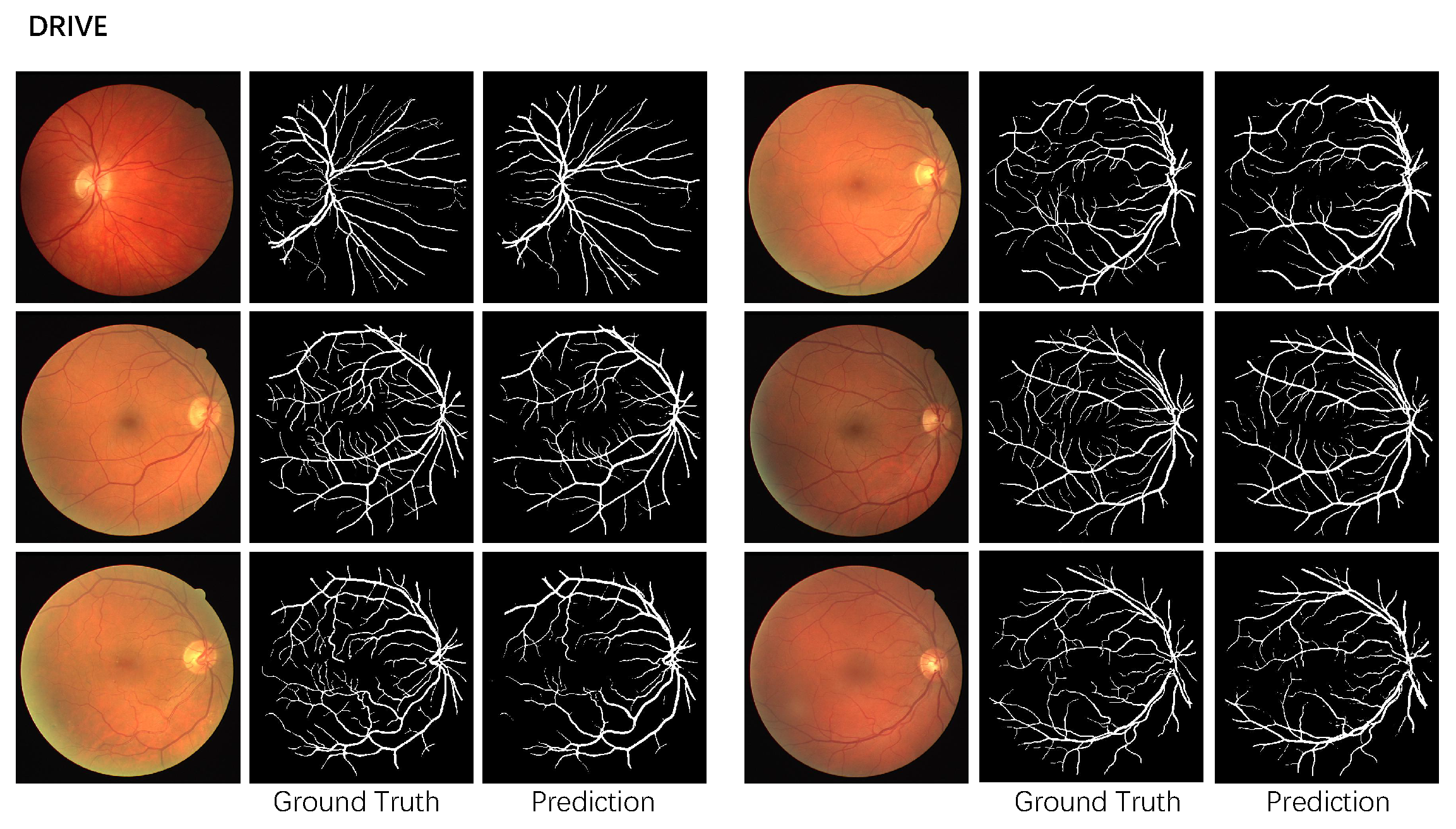
Figure 3 shows the prediction of the proposed method on the DRIVE dataset. DRIU [
23] extracts side feature maps and designs specialized layers to perform blood vessel segmentation. DRIU does not take advantage of multiscale information. Liskowski et al. [
22] design a convolutional neural network that contains three convolutional layers, one pooling layer, and two fully connected layers. Liskowski et al. train the network on image patches, and the improvement is mainly due to the elaborately designed image pre-processing method such as global contrast normalization and zero-phase whitening. Our network improves the result mainly due to the effective network architecture. Yan et al. [
24] improve the performance by jointly adopting both the segment-level and the pixel-wise losses. LadderNet [
26] has multiple pairs of encoder–decoder branches and can be viewed as a chain of multiple U-Nets. Our method further adds an attention mechanism to discard irrelevant information. DU-Net [
27] contains two encoders: a spatial path with a large kernel to preserve the spatial information and a context path with a multiscale convolution block to capture more semantic information. Our method incorporates multiscale information by sending multiscale input to each encoder and adopting an attention mechanism to capture important information. VesselNet [
29] proposes a lightweight deep learning model by injecting the inception residual convolutional block inside a U-like encoder–decoder architecture for vessel segmentation. The method adopts multi-path supervision just like our network; however, VesselNet lacks multiscale information, and our network further utilizes an attention mechanism to highlight important regions. Sine-Net [
30] applies up-sampling and then down-sampling to catch thin and thick vessel features. Guo et al. [
31] propose a channel attention double residual block to enhance the discriminative ability of the network by considering the interdependence between feature maps. Guo et al. learn channel maps by 1D convolutions. Our network performs self-attention to learn channel maps. Gao et al. [
32] utilize shuffle attention [
33] multiple times to explore the feature dependencies in both spatial and channel dimensions. The authors also adopt ECA-Net [
34] to reduce the model complexity while maintaining performance. Our method also utilizes spatial and channel attention to explore inter-relationship between locations and channels. The attention map of our method is calculated from the global image, and Gao et al. extract attention from the local patch. Our method further adopts multiscale input to encode multiscale information and multiple side-outputs to receive more supervision. Jiang et al. [
35] propose using conditional deep convolutional generative adversarial networks to segment the retinal vessels. Jiang et al. introduce residual modules to the generator for better representation learning ability. Li et al. [
36] propose an attention module built on U-Net to capture global information and to enhance features by placing it in the process of feature fusion. The attention module proposed by Li et al. only considers the spatial locations; our network takes both channel and spatial information into consideration.
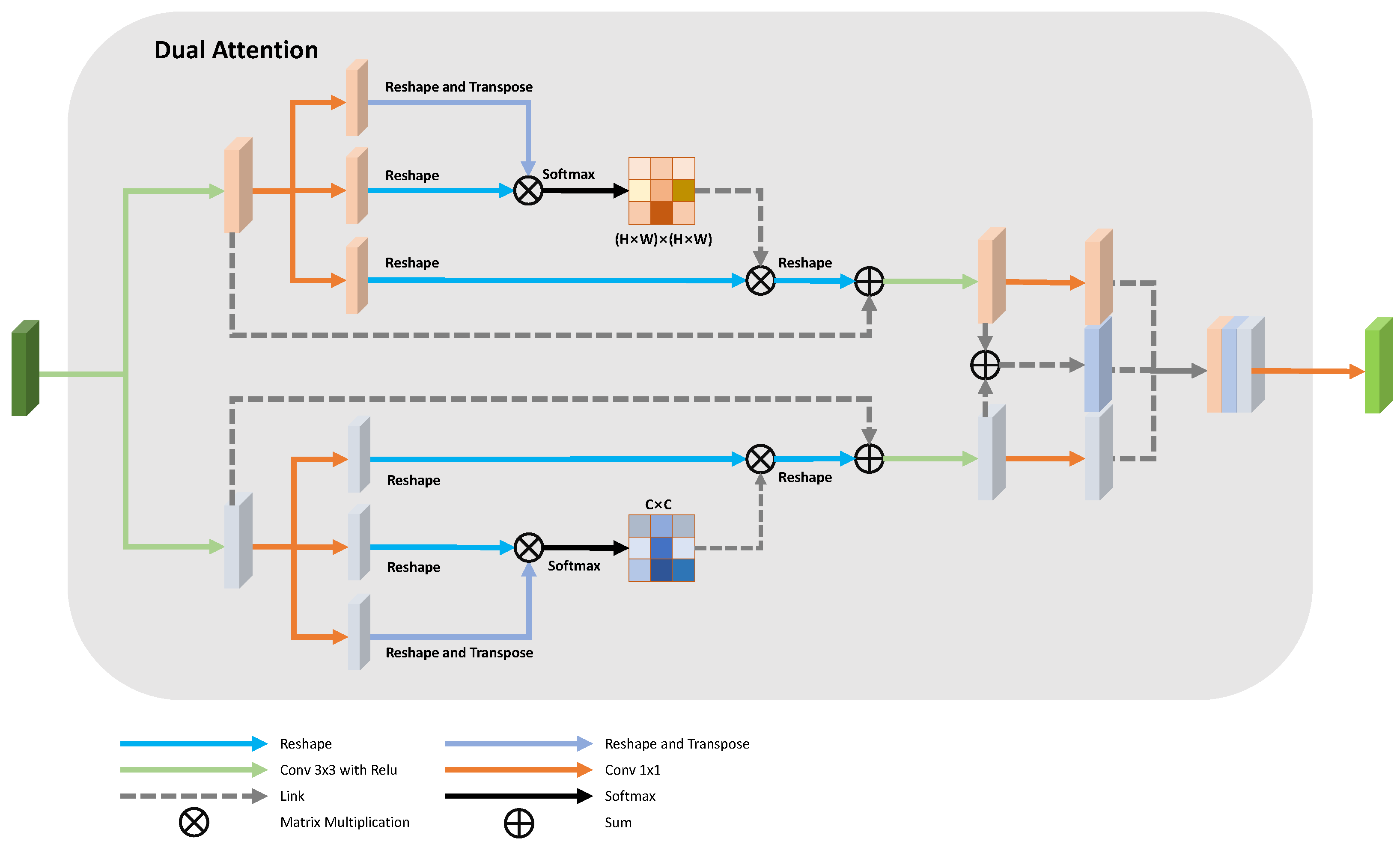
Our proposed method achieves the highest AUC compared to other methods. The proposed attention module gathers global context information from the feature map with one-eighth of the original image size, while the input image size of the proposed network is . DA-Net directly up-samples the attention map as the output and does not consider adopting skip-connections to recover the spatial information loss caused by down-sampling layers. The attention module used in our method is also different from DA-Net. We concatenate the spatial attention map, the channel attention map, and the sum of these two maps together to form a more discriminate feature representation. Yue et al. also aggregate multiscale context information. Our method not only takes advantage of multiscale context, but also provides the network with multiscale supervision through multiple side-outputs. Our method performs much better than Yue et al.
Table 2 shows the performance evaluation on the CHASEDB1 dataset.
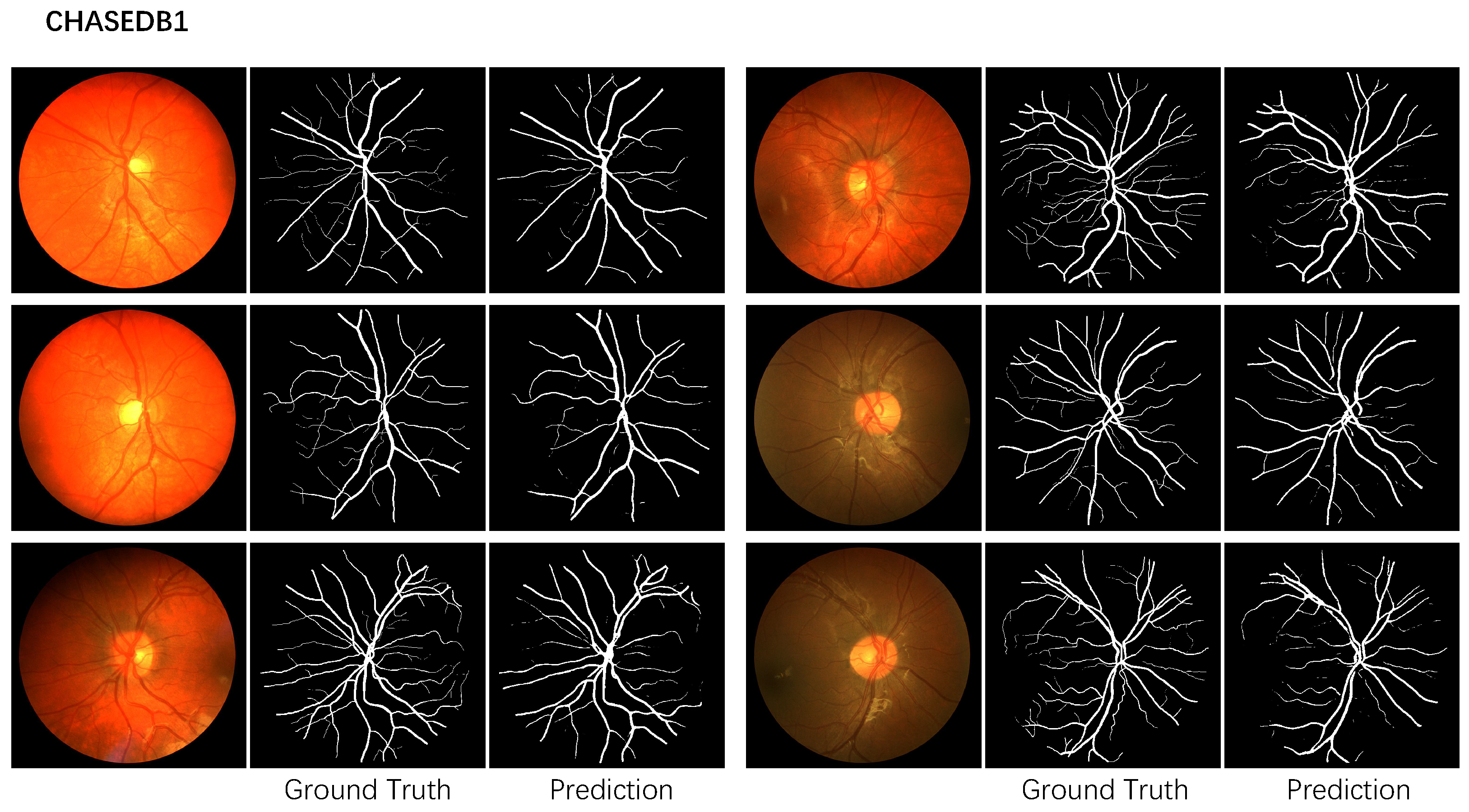
Figure 4 shows the corresponding prediction. Our method surpasses all the other methods. Yin et al. [
17] provide the network with more edge information through a guided filter module. Our multiscale network adopts dual attention to aggregate the relationship between pixels and channels. Our network is built on U-Net and can detect vessels in various shapes and sizes. Our method improves Yin et al. for all the metrics.
4.5. Ablative Studies
This section evaluates the performance of each part of the network.
Table 3 and
Table 4 show the performance of the proposed network using different modules on the DRIVE dataset and the CHASEDB1 dataset, respectively. The evaluation metrics include the mean IOU (mean intersection over union) commonly used in semantic segmentation. The multiscale architecture significantly improves the performance compared to our UNet backbone, and the attention mechanism further improves the performance. All the results are obtained on the testing set for fair comparison to other methods.
For the DRIVE dataset, we first perform Shapiro–Wilk test to verify distribution normality. For our UNet backbone, the p for ACC, AUC, SPE, SEN, and MIOU are 0.56, 0.19, 0.36, 0.92, and 0.23, respectively. For the proposed network, the p for ACC, AUC, Spe, Sen, and MIOU are 0.98, 0.16, 0.67, 0.41, and 0.48, respectively. The result of the multiscale structure also satisfies the distribution normality. The p for ACC, AUC, Spe, Sen, and MIOU are 0.77, 0.15, 0.72, 0.74, and 0.78, respectively. We also conduct a paired sample T-Test and calculate Cohen’s d to evaluate the significance of the performance improvement. The entire network significantly improves our UNet backbone in terms of Acc, AUC, Sen, Spe, and MIOU by 0.0146 (), 0.0262 (), 0.1420 (), 0.0024 (), and 0.0031 (), respectively. The effect size for Acc, AUC, Sen, Spe, and MIOU are 2.69, 3.99, 1.72, 0.4, and 2.55 respectively. The multiscale structure improves the performance of our UNet backbone in terms of Acc, AUC, Sen, Spe, and MIOU by 0.0145 (), 0.0259 (), 0.1379 (), 0.0024 (), and 0.1237 (), respectively. The corresponding effect size for Acc, AUC, Sen, Spe, and MIOU are 2.67, 3.90, 1.71, 0.32, and 2.52 respectively. The attention module further improves the performance compared to the multiscale architecture in terms AUC, Sen, and MIOU by 0.0003 (), 0.0041 () and 0.0017 () with effect size 0.3, 1.3, and 0.8, respectively. The attention module slightly improves ACC and SPE compared to the multiscale architecture.
For the CHASEDB1 dataset, we also perform Shapiro–Wilk test to verify distribution normality. For our UNet backbone, the p for ACC, AUC, Spe, Sen, and MIOU are 0.18, 0.72, 0.75, 0.40, and 0.70, respectively. For the proposed network, the p for ACC, AUC, Spe, Sen, and MIOU are 0.36, 0.70, 0.31, 0.71, and 0.43, respectively. The result of the multiscale structure also satisfies the distribution normality. The p for ACC, AUC, Spe, Sen, and MIOU are 0.84, 0.64, 0.76, 0.84, and 0.49, respectively. We also conduct a paired sample T-Test and calculate Cohen’s d to evaluate the significance of the performance improvement. The entire network significantly improves the our UNet backbone in terms of Acc, AUC, Sen, Spe, and MIOU by 0.0107 (), 0.0420 (), 0.3323 (), 0.0054 (), and 0.2318 (), respectively. The effect size for Acc, AUC, Sen, and Spe are 2.01, 3.44, 5.71, 1.1, and 3.74, respectively. The multiscale input improves the performance of baseline U-Net in terms of Acc, AUC, Sen, Spe, and MIOU by 0.0105 (), 0.0408 (), 0.3316 (), 0.0054 (), and 0.2276 (), respectively. The corresponding effect size for Acc, AUC, Sen, Spe, and MIOU are 2.09, 3.35, 5.56, 1.30, and 3.74, respectively. The attention module significantly improves the performance compared to the multiscale architecture in terms of AUC, Sen, and MIOU by 0.0012 (), 0.007 (), and 0.0042 () with effect size 0.5, 0.3, and 1.8, respectively. The attention module slightly improves ACC and Spe compared to the multiscale architecture.
Table 5 and
Table 6 show the performance of the proposed method for each sample. For the DRIVE dataset, the best case ACC, AUC, Sen, and Spe are 0.9719, 0.9930, 0.8809, and 0.9914, respectively, and the worst case measures are 0.9533, 0.9809, 0.6972, and 0.9778, respectively. For the CHASEDB1 dataset, the best case ACC, AUC, Sen, and Spe are 0.9861, 0.9930, 0.884, and 0.9932, respectively, and the worst case measures are 0.9735, 0.9856, 0.7665, and 0.9805, respectively. The AUC of our method is the highest for two datasets compared to other methods, The multiscale architecture lets the network learn a vessel feature from a different scale, and the attention module further lets the network discard irregular region and focus on the most discriminative region.








{kind=link}
{kind=link}
{kind=link}
{kind=link}