
Mathematical Expressiveness of Graph Neural Networks


Abstract
:1. Introduction
2. Basic Definitions and Notations
3. Graph Neural Network and Expressiveness
3.1. Graph Neural Network
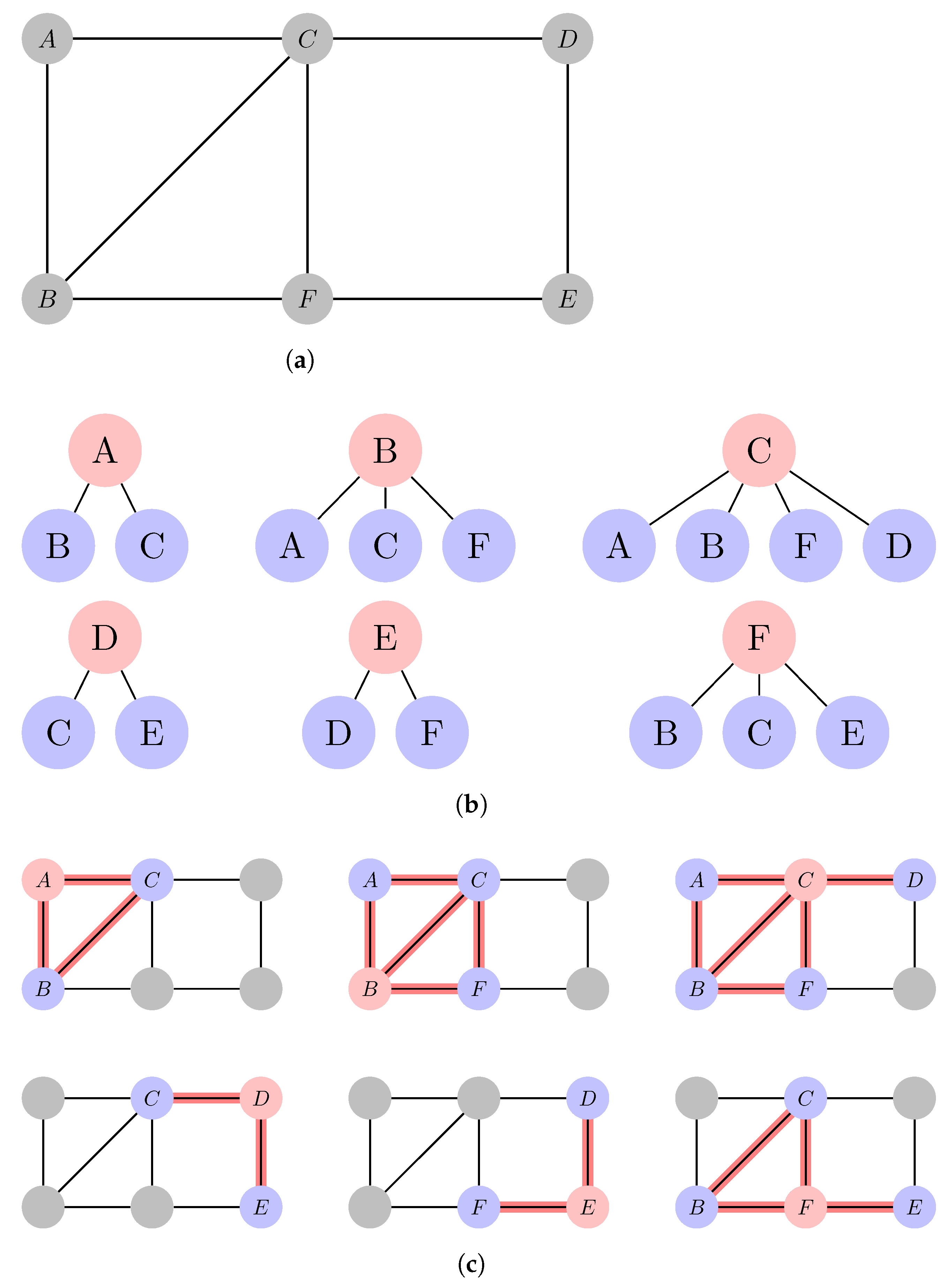
3.2. Graph Isomorphism and Weisfeiler–Leman
4. Higher Order Networks and Universal Approximation
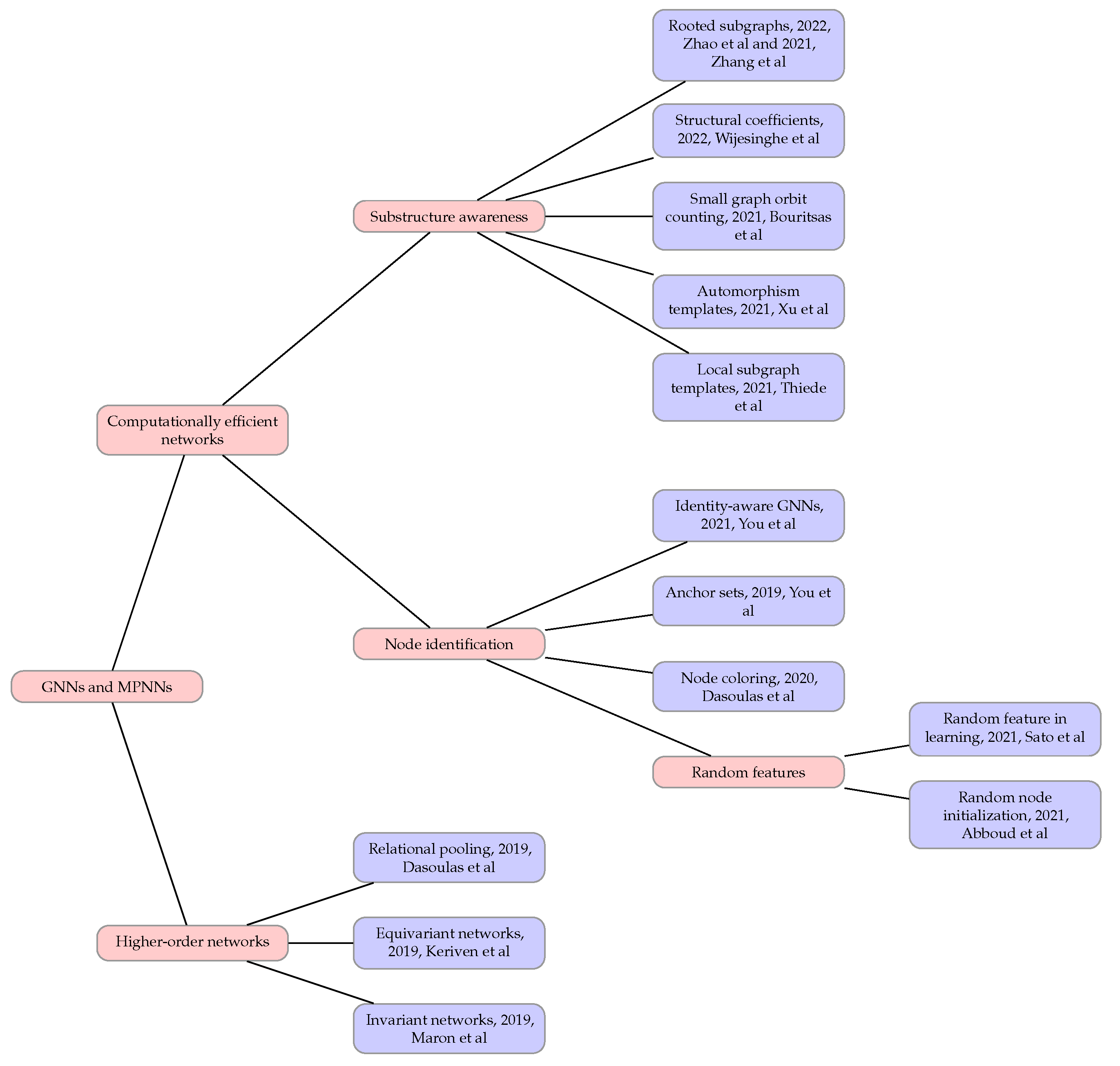
5. Computationally Efficient and Powerful Networks
5.1. Node Identification
5.2. Substructure Awareness
6. Summary
7. Conclusions and Future Works
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| GNN | Graph Neural Network |
| MPNN | Message Passing Neural Network |
| WL | Weisfeiler–Leman |
| DDOS | Distributed Denial Of Service |
References
- Scarselli, F.; Gori, M.; Tsoi, A.C.; Hagenbuchner, M.; Monfardini, G. The Graph Neural Network Model. IEEE Trans. Neural Netw. 2009, 20, 61–80. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhou, J.; Cui, G.; Hu, S.; Zhang, Z.; Yang, C.; Liu, Z.; Wang, L.; Li, C.; Sun, M. Graph Neural Networks: A Review of Methods and Applications. AI Open 2020, 1, 57–81. [Google Scholar] [CrossRef]
- Gilmer, J.; Schoenholz, S.S.; Riley, P.F.; Vinyals, O.; Dahl, G.E. Neural Message Passing for Quantum Chemistry. In Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6–11 August 2017; Volume 70, pp. 1263–1272. [Google Scholar]
- Xu, K.; Hu, W.; Leskovec, J.; Jegelka, S. How Powerful Are Graph Neural Networks? In Proceedings of the 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, 6–9 May 2019.
- Morris, C.; Ritzert, M.; Fey, M.; Hamilton, W.L.; Lenssen, J.E.; Rattan, G.; Grohe, M. Weisfeiler and Leman Go Neural: Higher-Order Graph Neural Networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 4602–4609. [Google Scholar] [CrossRef] [Green Version]
- Maron, H.; Ben-Hamu, H.; Serviansky, H.; Lipman, Y. Provably Powerful Graph Networks. In Proceedings of the Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, Vancouver, BC, Canada, 8–14 December 2019; pp. 2153–2164. [Google Scholar]
- Barceló, P.; Kostylev, E.V.; Monet, M.; Pérez, J.; Reutter, J.L.; Silva, J.P. The Logical Expressiveness of Graph Neural Networks. In Proceedings of the 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017. [Google Scholar]
- Maron, H.; Fetaya, E.; Segol, N.; Lipman, Y. On the Universality of Invariant Networks. In Proceedings of the 36th International Conference on Machine Learning, ICML 2019, Long Beach, CA, USA, 9–15 June 2019; Volume 97, pp. 4363–4371. [Google Scholar]
- Murphy, R.L.; Srinivasan, B.; Rao, V.A.; Ribeiro, B. Relational Pooling for Graph Representations. In Proceedings of the 36th International Conference on Machine Learning, ICML 2019, Long Beach, CA, USA, 9–15 June 2019; Volume 97, pp. 4663–4673. [Google Scholar]
- Dasoulas, G.; Santos, L.D.; Scaman, K.; Virmaux, A. Coloring Graph Neural Networks for Node Disambiguation. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, IJCAI 2020, Yokohama, Japan, 7–15 January 2021; pp. 2126–2132. [Google Scholar] [CrossRef]
- Thiede, E.H.; Zhou, W.; Kondor, R. Autobahn: Automorphism-based Graph Neural Nets. In Proceedings of the Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, Virtual, 6–14 December 2021; pp. 29922–29934. [Google Scholar]
- Keriven, N.; Peyré, G. Universal Invariant and Equivariant Graph Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, Vancouver, BC, Canada, 8–14 December 2019; pp. 7090–7099. [Google Scholar]
- Zhao, L.; Jin, W.; Akoglu, L.; Shah, N. From Stars to Subgraphs: Uplifting Any GNN with Local Structure Awareness. In Proceedings of the Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, 25–29 April 2022. [Google Scholar]
- Zhang, M.; Li, P. Nested Graph Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, Virtual, 6–14 December 2021; pp. 15734–15747. [Google Scholar]
- Wijesinghe, A.; Wang, Q. A New Perspective on “How Graph Neural Networks Go Beyond Weisfeiler-Lehman?”. In Proceedings of the Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, 25–29 April 2022. [Google Scholar]
- Bouritsas, G.; Frasca, F.; Zafeiriou, S.; Bronstein, M.M. Improving Graph Neural Network Expressivity via Subgraph Isomorphism Counting. arXiv 2021, arXiv:2006.09252. [Google Scholar] [CrossRef] [PubMed]
- Xu, F.; Yao, Q.; Hui, P.; Li, Y. Automorphic Equivalence-Aware Graph Neural Network. In Proceedings of the Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, Virtual, 6–14 December 2021; pp. 15138–15150. [Google Scholar]
- You, J.; Selman, J.M.G.; Ying, R.; Leskovec, J. Identity-Aware Graph Neural Networks. In Proceedings of the Thirty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2021, Thirty-Third Conference on Innovative Applications of Artificial Intelligence, IAAI 2021, the Eleventh Symposium on Educational Advances in Artificial Intelligence, EAAI 2021, Virtual Event, 2–9 February 2021; pp. 10737–10745. [Google Scholar]
- You, J.; Ying, R.; Leskovec, J. Position-Aware Graph Neural Networks. In Proceedings of the 36th International Conference on Machine Learning, ICML 2019, Long Beach, CA, USA, 9–15 June 2019; Volume 97, pp. 7134–7143. [Google Scholar]
- Sato, R.; Yamada, M.; Kashima, H. Random Features Strengthen Graph Neural Networks. In Proceedings of the 2021 SIAM International Conference on Data Mining, SDM 2021, Virtual Event, 29 April–1 May 2021; pp. 333–341. [Google Scholar] [CrossRef]
- Abboud, R.; Ceylan, İ.İ.; Grohe, M.; Lukasiewicz, T. The Surprising Power of Graph Neural Networks with Random Node Initialization. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, IJCAI 2021, Virtual Event, 19–27 August 2021; pp. 2112–2118. [Google Scholar] [CrossRef]
- Ma, Y.; Tang, J. Deep Learning on Graphs; Cambridge University Press: Cambridge, UK, 2021. [Google Scholar]
- Velickovic, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; Bengio, Y. Graph Attention Networks. In Proceedings of the 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Hamilton, W.L.; Ying, R.; Leskovec, J. Inductive Representation Learning on Large Graphs. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 1025–1035. [Google Scholar]
- Battaglia, P.W.; Hamrick, J.B.; Bapst, V.; Sanchez-Gonzalez, A.; Zambaldi, V.; Malinowski, M.; Tacchetti, A.; Raposo, D.; Santoro, A.; Faulkner, R.; et al. Relational Inductive Biases, Deep Learning, and Graph Networks. arXiv 2018, arXiv:1806.01261. [Google Scholar]
- Bruna, J.; Zaremba, W.; Szlam, A.; LeCun, Y. Spectral Networks and Locally Connected Networks on Graphs. In Proceedings of the 2nd International Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Defferrard, M.; Bresson, X.; Vandergheynst, P. Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering. In Proceedings of the 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 3844–3852. [Google Scholar]
- Wu, F.; de Souza, A.H., Jr.; Zhang, T.; Fifty, C.; Yu, T.; Weinberger, K.Q. Simplifying Graph Convolutional Networks. In Proceedings of the 36th International Conference on Machine Learning, ICML 2019, Long Beach, CA, USA, 9–15 June 2019; Volume 97, pp. 6861–6871. [Google Scholar]
- Balcilar, M.; Renton, G.; Héroux, P.; Gaüzère, B.; Adam, S.; Honeine, P. Analyzing the Expressive Power of Graph Neural Networks in a Spectral Perspective. In Proceedings of the 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, 3–7 May 2021. [Google Scholar]
- Wu, Z.; Pan, S.; Chen, F.; Long, G.; Zhang, C.; Yu, P.S. A Comprehensive Survey on Graph Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 4–24. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, Z.; Cui, P.; Zhu, W. Deep Learning on Graphs: A Survey. IEEE Trans. Knowl. Data Eng. 2022, 34, 249–270. [Google Scholar] [CrossRef] [Green Version]
- Bronstein, M.M.; Bruna, J.; Cohen, T.; Veličković, P. Geometric Deep Learning: Grids, Groups, Graphs, Geodesics, and Gauges. arXiv 2021, arXiv:2104.13478. [Google Scholar]
- Dwivedi, V.P.; Joshi, C.K.; Laurent, T.; Bengio, Y.; Bresson, X. Benchmarking Graph Neural Networks. arXiv 2020, arXiv:2003.00982. [Google Scholar]
- Chen, L.; Chen, Z.; Bruna, J. On Graph Neural Networks versus Graph-Augmented MLPs. In Proceedings of the 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, 3–7 May 2021. [Google Scholar]
- Loukas, A. What Graph Neural Networks Cannot Learn: Depth vs Width. In Proceedings of the 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Weisfeiler, B.Y.; Leman, A.A. The reduction of a graph to canonical form and the algebra which appears therein. NTI Ser. 1968, 2, 12–16. [Google Scholar]
- Morris, C.; Lipman, Y.; Maron, H.; Rieck, B.; Kriege, N.M.; Grohe, M.; Fey, M.; Borgwardt, K. Weisfeiler and Leman Go Machine Learning: The Story so Far. arXiv 2021, arXiv:2112.09992. [Google Scholar]
- Cai, J.Y.; Fürer, M.; Immerman, N. An Optimal Lower Bound on the Number of Variables for Graph Identification. Combinatorica 1992, 12, 389–410. [Google Scholar] [CrossRef]
- Douglas, B.L. The Weisfeiler-Lehman Method and Graph Isomorphism Testing. arXiv 2011, arXiv:1101.5211. [Google Scholar]
- Maron, H.; Ben-Hamu, H.; Shamir, N.; Lipman, Y. Invariant and Equivariant Graph Networks. In Proceedings of the 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Azizian, W.; Lelarge, M. Expressive Power of Invariant and Equivariant Graph Neural Networks. In Proceedings of the 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, 3–7 May 2021. [Google Scholar]
- Chen, Z.; Chen, L.; Villar, S.; Bruna, J. Can Graph Neural Networks Count Substructures? In Proceedings of the Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, Virtual, 6–12 December 2020.
- Li, P.; Wang, Y.; Wang, H.; Leskovec, J. Distance Encoding: Design Provably More Powerful Neural Networks for Graph Representation Learning. In Proceedings of the Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, Virtual, 6–12 December 2020. [Google Scholar]
- Bevilacqua, B.; Frasca, F.; Lim, D.; Srinivasan, B.; Cai, C.; Balamurugan, G.; Bronstein, M.M.; Maron, H. Equivariant Subgraph Aggregation Networks. In Proceedings of the Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, 25–29 April 2022. [Google Scholar]
- Bodnar, C.; Frasca, F.; Otter, N.; Wang, Y.; Liò, P.; Montúfar, G.F.; Bronstein, M.M. Weisfeiler and Lehman Go Cellular: CW Networks. In Proceedings of the Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, Virtual, 6–14 December 2021; pp. 2625–2640. [Google Scholar]



{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| Set of nodes | |
| Set of edges | |
| Graph | |
| N | Number of nodes, i.e. |
| d | Feature vector dimension |
| activation function at layer l | |
| Node feature matrix | |
| S | Spectre related matrix. Usually, or . |
| A | Adjacency matrix |
| Laplacian matrix | |
| D | Degree matrix of |
| Hidden representation of at layer l | |
| multiset | |
| hash function |
| Architecture | Expressiveness |
|---|---|
| GIN [4] | 1-WL |
| k-GNN [5] | (k-1)-WL |
| RP-GNN [10] | strictly superior to GIN |
| PPGN [6] | 3-WL |
| [11] | universal approximator |
| ID-GNN [19] | >1-WL |
| rGIN [21] | >1-WL, universal approximator |
| PGNN [20] | greater than MPNN |
| Autobahn [12] | depends on the templates, can achieve k-GNN performance |
| GRAPE [18] | stricly more powerful than MPNN |
| GSN [17] | more powerful than MPNN and 1-WL under conditions. |
| GraphSNN [16] | |
| GNN-AK [14] | >2-WL, ≥ 3-WL |
| NGNN [15] | > 1-WL |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lachaud, G.; Conde-Cespedes, P.; Trocan, M. Mathematical Expressiveness of Graph Neural Networks. Mathematics 2022, 10, 4770. https://doi.org/10.3390/math10244770
Lachaud G, Conde-Cespedes P, Trocan M. Mathematical Expressiveness of Graph Neural Networks. Mathematics. 2022; 10(24):4770. https://doi.org/10.3390/math10244770
Chicago/Turabian StyleLachaud, Guillaume, Patricia Conde-Cespedes, and Maria Trocan. 2022. "Mathematical Expressiveness of Graph Neural Networks" Mathematics 10, no. 24: 4770. https://doi.org/10.3390/math10244770