

A Survey on Deep Transfer Learning and Beyond

Abstract
:1. Introduction
- We introduce over 50 representative approaches of DTL and systematically summarize them into four categories and further subcategories; see Figure 4.
- We present frontier advances in the application of DTL and recent advances in unsupervised TL.
- We provide some potential research directions that can give a good reference for promoting future work in this field.
2. Model-Based DTL
2.1. Fine-Tuning
2.2. Self-Training
- Train a teacher network which minimizes the cross entropy loss on partially labeled images, defined aswhere is a prediction function which predicts labels using network parameter .
- The teacher network is used to predict the unlabeled images, and the predictions are used as pseudo-labels. The mathematical model is given by
- Train a student network which minimizes the cross entropy loss on labeled and pseudo-labeled samples as follows:where is a prediction function. Noises such as dropout, random depth, and data augmentation are added to enhance the representational power of the student network.
- The student network is used as a new teacher network ; then, return to step 2.
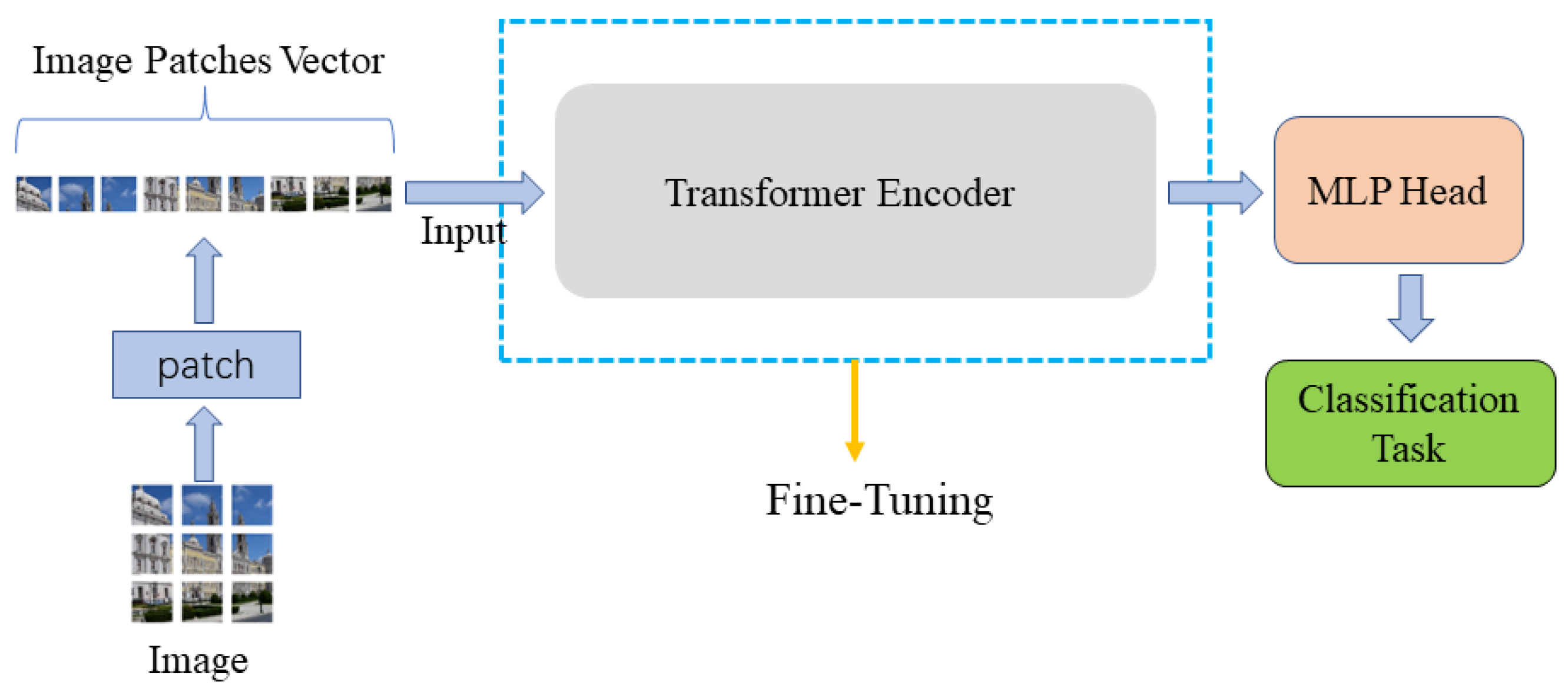
2.3. Transformer Attention Mechanism
3. Discrepancy-Based DTL
3.1. Dual-Stream Architecture
3.2. Operation with Image Features
3.3. Other Approaches of Feature Transfer
4. GAN-Based DTL
4.1. Feature Extraction Approach
4.2. Feature Transformation Approach
4.3. Other Approaches of ATL
5. Relational-Based DTL
6. Extensions and Additions
6.1. TL in Other Fields
6.2. Recent Advances in UTL
7. Summary and Future Prospects
- Interpretability of DTL is a great challenge to be explored. In the field of deep learning, there is a lack of interpretability of the learning process due to the existence of black boxes. The problem continues in the DTL area, and the development of DTL requires further investigation of the interpretability.
- How to reduce the effects of negative transfer while transferring knowledge from source domains to target domains is also an important issue. Therefore, improving TL algorithms and making theoretical innovations to avoid negative transfer should be considered.
- The current work summarizes existing approaches, and we will compare them on datasets/tasks and hopefully give a ranking.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Categories | Subcategories | Solvers | Dataset | Open-Source |
|---|---|---|---|---|
| Model-Based | Fine-Tuning | Fine-Tune Layer-by-Layer Yosinski et al. [45] | ImageNet | http://yosinski.com/transfer |
| Improve Regularization and Robustness Li et al. [50] | ImageNet | https://github.com/NEU-StatsML-Research/Regularized-Self-Labeling | ||
| Self-Training | Discover the Limitations of Pre-Training He et al. [51] | ImageNet, COCO | https://github.com/facebookresearch/detectron | |
| Self-train with Noisy Xie et al. [52] | ImageNet | https://github.com/google-research/noisystudent | ||
| Transferring Attention Transformer | Image Processing Transformer (IPT) Chen et al. [54] | ImageNet | https://github.com/huawei-noah/Pretrained-IPT | |
| Bert Pre-training of Image Transformers (BEiT) Bao et al. [55] | ImageNet | https://github.com/microsoft/unilm/tree/master/beit | ||
| Transferable Vision Transformer (TVT) Yang et al. [57] | Office-31 | https://github.com/uta-smile/TVT | ||
| Cross-domain Transformer (CDTrans) Xu et al. [58] | VisDA-2017, Office-Home, Office-31, DomainNet | https://github.com/cdtrans/cdtrans | ||
| Discrepancy-Based | Dual-Stream Architecture | Deep Correlation Alignment Sun et al. [68] | Office | https://github.com/VisionLearningGroup/CORAL |
| Deep Domain Confusion (DDC) Tzeng et al. [60] | Office-31 | https://github.com/erlendd/ddan | ||
| Deep Adaptation Networks (DAN) Long et al. [62] | Office-31 | http://github.com/thuml/DAN | ||
| Joint adaptation networks (JAN) Long et al. [64] | Office-31, ImageCLEF-DA | http://github.com/thuml/JAN | ||
| Deep Subdomain Adaptation Network (DSAN) Zhu et al. [63] | Office-31, ImageCLEF-DA, Office-Home, VisDA-2017 | https://github.com/easezyc/deep-transfer-learning | ||
| Dynamic Distribution Adaptation Network (DDAN) Wang et al. [65] | USPS+MNIST, Amazon review, Office-31, ImageCLEF-DA, Office-Home | http://transferlearning.xyz | ||
| Central Moment Discrepancy (CMD) Zellinger et al. [66] | Amazon review, Office | https://github.com/wzell/cmd | ||
| Operating on Image Features | Sample-to-Sample Self-Distillation Yoon et al. [74] | Office-Home, DomainNet | https://github.com/userb2020/s3d | |
| Learning to Match (L2M) Yu et al. [75] | ImageCLEF-DA, Office-Home, VisDA2017, Office-31 | https://github.com/jindongwang/transferlearning | ||
| Style-Agnostic Networks (SagNets) Nam et al. [73] | Office-Home, PACS, DomainNet | https://github.com/hyeonseobnam/sagnet | ||
| GAN-Based | Feature Extraction | Domain-Adversarial Training of Neural Networks (DANN) Ganin et al. [76] | Office | https://github.com/ddtm/caffe/tree/grl |
| Conditional Adversarial Domain Adaptation (CADN) Long et al. [77] | Office-31, ImageCLEF-DA, Office-Home, Digits, VisDA-2017 | http://github.com/thuml/CDAN | ||
| Multi-adversarial Domain Adaptation (MADA) Pei et al. [78] | Office-31, ImageCLEF-DA | http://github.com/thuml/MADA | ||
| Dynamic Adversarial Adaptation Network (DAAN) Yu et al. [79] | ImageCLEF-DA, Office-Home | http://transferlearning.xyz | ||
| Cycle-Consistent Adversarial Networks (CycleGAN) Zhu et al. [81] | ImageNet | https://github.com/junyanz/CycleGAN | ||
| Feature Transformation | Maximum Classifier Discrepancy (MCD) Saito et al. [82] | Digits, VisDA, Toy | https://github.com/mil-tokyo/MCD_DA | |
| Adversarial Feature Augmentation Volpi et al. [83] | SVHN, MNIST, NYUD | https://github.com/ricvolpi/adversarial-feature-augmentation | ||
| Adversarial Discriminative Domain Adaptation (ADDA) Tzeng et al. [84] | SVHN, MNIST, USPS | https://github.com/thuml/Transfer-Learning-Library | ||
| Simulated Generative Adversarial Networks SimGAN) Shrivastava et al. [85] | MPIIGaze | https://github.com/0b01/SimGAN-Captcha | ||
| Curriculum based Dropout Discriminator for Domain Adaptation (CD3A) Kurmi et al. [87] | ImageCLE, Office-31, Office-Home | https://github.com/DelTA-Lab-IITK/CD3A | ||
| Region Proposal Network (RPN) Chen et al. [88] | Cityscapes, KITTI, SIM10K | https://github.com/yuhuayc/da-faster-rcnn | ||
| Categorical Consistency Regularization (CCR) Xu et al. [90] | Cityscapes, Foggy Cityscapes, BDD100k, PASCAL, VOC, Clipart1k | https://github.com/Megvii-Nanjing/CR-DA-DET | ||
| Relational-Based | Cross-Domain Relationship | Collaborative Consistency Learning (CCL) Isobe et al. [91] | GTA5, SYNTHIA, Cityscapes, Mapillary | https://github.com/junpan19/MTDA |
References
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A Unified Embedding for Face Recognition and Clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015; pp. 815–823. [Google Scholar]
- Taigman, Y.; Yang, M.; Ranzato, M.; Wolf, L. Deepface: Closing the Gap to Human-Level Performance in Face Verification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 1701–1708. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are We Ready for Autonomous Driving? The Kitti Vision Benchmark Duite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Rajpurkar, P.; Irvin, J.; Zhu, K.; Yang, B.; Mehta, H.; Duan, T.; Ding, D.; Bagul, A.; Langlotz, C.; Shpanskaya, K.; et al. CheXNET: Radiologist-Level Pneumonia Detection on Chest X-Rays with Deep Learning. arXiv 2017, arXiv:1711.05225. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z. Theoretical Guarantees of Transfer Learning. arXiv 2018, arXiv:1810.05986. [Google Scholar]
- Vural, E. Generalization Bounds for Domain Adaptation Via Domain Transformations. In Proceedings of the 2018 IEEE 28th International Workshop on Machine Learning for Signal Processing (MLSP), Providence, RI, USA, 16–21 June 2021. [Google Scholar]
- Wang, W.; Li, B.; Yang, S.; Sun, J.; Ding, Z.; Chen, J.; Dong, X.; Wang, Z.; Li, H. A Unified Joint Maximum Mean Discrepancy for Domain Adaptation. arXiv 2021, arXiv:2101.09979. [Google Scholar]
- Galanti, T.; Benaim, S.; Wolf, L. Risk Bounds for Unsupervised Cross-Domain Mapping with IPMs. J. Mach. Learn. Res. 2021, 22, 90–91. [Google Scholar]
- Phung, T.; Le, T.; Vuong, T.L.; Tran, T.; Tran, A.; Bui, H.; Phung, D. On Learning Domain-Invariant Representations for Transfer Learning with Multiple Sources. Adv. Neural Inf. Process. Syst. 2021, 34, 27720–27733. [Google Scholar]
- Teshima, T.; Sato, I.; Sugiyama, M. Few-Shot Domain Adaptation by Causal Mechanism Transfer. In Proceedings of the PMLR: International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 9458–9469. [Google Scholar]
- Wu, X.; Manton, J.H.; Aickelin, U.; Zhu, J. An Information-Theoretic Analysis for Transfer Learning: Error Bounds and Applications. arXiv 2022, arXiv:2207.05377. [Google Scholar]
- Acuna, D.; Zhang, G.; Law, M.T.; Fidler, S. f-Domain-Adversarial Learning: Theory and Algorithms. In Proceedings of the International Conference on Machine Learning. PMLR, Virtual, 18–24 July 2021; pp. 66–75. [Google Scholar]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A Comprehensive Survey on Transfer Learning. Proc. IEEE 2020, 109, 43–76. [Google Scholar] [CrossRef]
- Wang, J.; Chen, Y. Introduction to Transfer Learning; Electronic Industry Press: Beijing, China, 2021. [Google Scholar]
- Yang, Q.; Zhang, Y. Transfer Learning; Artificial Intelligence Technology Series; Machinery Industry Press: Beijing, China, 2020. [Google Scholar]
- Zadrozny, B. Learning and Dvaluating Classifiers under Sample Selection Bias. In Proceedings of the Twenty-First International Conference on Machine Learning, Banff Alberta, AB, Canada, 4–8 July 2004; p. 114. [Google Scholar]
- Dai, W.; Yang, Q.; Xue, G.R.; Yu, Y. Boosting for Transfer Learning. In Proceedings of the ICML ’07, 24th International Conference on Machine Learning, Corvalis Oregon, OR, USA, 20–24 June 2007; Volume 227, pp. 193–200. [Google Scholar] [CrossRef]
- Yao, Y.; Doretto, G. Boosting for Transfer Learning with Multiple Sources. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 1855–1862. [Google Scholar]
- Huang, J.; Gretton, A.; Borgwardt, K.; Schölkopf, B.; Smola, A. Correcting Sample Selection Bias by Unlabeled Data. Adv. Neural Inf. Process. Syst. 2006, 19, 601–608. [Google Scholar]
- Pan, S.J.; Tsang, I.W.; Kwok, J.T.; Yang, Q. Domain Adaptation Via Transfer Component Analysis. IEEE Trans. Neural Netw. 2010, 22, 199–210. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Long, M.; Wang, J.; Ding, G.; Sun, J.; Yu, P.S. Transfer Feature Learning with Joint Distribution Adaptation. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 2200–2207. [Google Scholar]
- Wang, J.; Feng, W.; Chen, Y.; Yu, H.; Huang, M.; Yu, P.S. Visual Domain Adaptation with Manifold Embedded Distribution Alignment. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Korea, 22–26 October 2018; pp. 402–410. [Google Scholar]
- Gong, B.; Shi, Y.; Sha, F.; Grauman, K. Geodesic Flow Kernel for Unsupervised Domain Adaptation. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2066–2073. [Google Scholar]
- Sun, B.; Feng, J.; Saenko, K. Return of Frustratingly Easy Domain Adaptation. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Fernando, B.; Habrard, A.; Sebban, M.; Tuytelaars, T. Unsupervised Visual Domain Adaptation Using Subspace Alignment. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 2960–2967. [Google Scholar]
- Fei-Fei, L.; Fergus, R.; Perona, P. One-Shot Learning of Object Categories. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 594–611. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bonilla, E.V.; Chai, K.; Williams, C. Multi-Task Gaussian Process Prediction. Adv. Neural Inf. Process. Syst. 2007, 20, 601–608. [Google Scholar]
- Yang, J.; Yan, R.; Hauptmann, A.G. Cross-Domain Video Concept Detection Using Adaptive SVMs. In Proceedings of the 15th ACM International Conference on Multimedia, Augsburg, Germany, 25–29 September 2007; pp. 188–197. [Google Scholar]
- Aytar, Y.; Zisserman, A. Tabula Rasa: Model Transfer for Object Category Detection. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2252–2259. [Google Scholar]
- Mihalkova, L.; Huynh, T.; Mooney, R.J. Mapping and Revising Markov Logic Networks for Transfer Learning. In Proceedings of the AAAI, Vancouver, BC, Canada, 22–26 July 2007; Volume 7, pp. 608–614. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 25, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2016; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Ecognition, Boston, MA, USA, 8–10 June 2016; pp. 770–778. [Google Scholar]
- Csurka, G.; Baradel, F.; Chidlovskii, B.; Clinchant, S. Discrepancy-Based Networks for Unsupervised Domain Adaptation: A Comparative Study. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 2630–2636. [Google Scholar]
- Li, D.; Yang, Y.; Song, Y.Z.; Hospedales, T.M. Deeper, Broader and Artier Domain Generalization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5542–5550. [Google Scholar]
- Donahue, J.; Jia, Y.; Vinyals, O.; Hoffman, J.; Zhang, N.; Tzeng, E.; Darrell, T. DeCAF: A Deep Convolutional Activation Feature for Generic Visual Recognition. In Proceedings of the International Conference on Machine Learning. PMLR, Bejing, China, 22–24 June 2014; pp. 647–655. [Google Scholar]
- Saxena, S.; Verbeek, J. Heterogeneous Face Recognition with CNNs. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–10 October 2016; Springer: New York, NY, USA, 2016; pp. 483–491. [Google Scholar]
- Fernando, B.; Tommasi, T.; Tuytelaars, T. Joint Cross-Domain Classification and Subspace Learning for Unsupervised Adaptation. Pattern Recognit. Lett. 2015, 65, 60–66. [Google Scholar] [CrossRef] [Green Version]
- Long, M.; Wang, J.; Ding, G.; Sun, J.; Yu, P.S. Transfer Joint Matching for Unsupervised Domain Adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 1410–1417. [Google Scholar]
- Chopra, S.; Balakrishnan, S.; Gopalan, R. DLID: Deep Learning for Domain Adaptation by Interpolating between Domains. In Proceedings of the ICML Workshop on Challenges in Representation Learning, Atlanta, GA, USA, 16–21 June 2013; Volume 2. [Google Scholar]
- Wang, M.; Deng, W. Deep visual domain adaptation: A survey. Neurocomputing 2018, 312, 135–153. [Google Scholar] [CrossRef] [Green Version]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How Transferable are features in deep neural networks? Adv. Neural Inf. Process. Syst. 2014, 27, 3320–3328. [Google Scholar]
- Chu, B.; Madhavan, V.; Beijbom, O.; Hoffman, J.; Darrell, T. Best Practices for Fine-tuning Visual Classifiers to New Domains. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–10 October 2016; Springer: New York, NY, USA, 2016; pp. 435–442. [Google Scholar]
- Rozantsev, A.; Salzmann, M.; Fua, P. Beyond Sharing Weights for Deep Domain Adaptation. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 801–814. [Google Scholar] [CrossRef]
- Rozantsev, A.; Salzmann, M.; Fua, P. Residual Parameter Transfer for Deep Domain Adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 19–21 June 2018; pp. 4339–4348. [Google Scholar]
- Guo, Y.; Shi, H.; Kumar, A.; Grauman, K.; Rosing, T.; Feris, R. Spottune: Transfer Learning through Adaptive Fine-tuning. In Proceedings of the IEEE/CVF Conference on Cmputer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 4805–4814. [Google Scholar]
- Li, D.; Zhang, H. Improved Regularization and Robustness for Fine-tuning in Neural Networks. Adv. Neural Inf. Process. Syst. 2021, 34. [Google Scholar] [CrossRef]
- He, K.; Girshick, R.; Dollár, P. Rethinking Imagenet Pre-Training. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27October–2 November 2019; pp. 4918–4927. [Google Scholar]
- Xie, Q.; Luong, M.T.; Hovy, E.; Le, Q.V. Self-Training with Noisy Student Improves Imagenet Classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 14–19 June 2020; pp. 10687–10698. [Google Scholar]
- Zoph, B.; Ghiasi, G.; Lin, T.Y.; Cui, Y.; Liu, H.; Cubuk, E.D.; Le, Q. Rethinking Pre-Training and Self-Training. Adv. Neural Inf. Process. Syst. 2020, 33, 3833–3845. [Google Scholar]
- Chen, H.; Wang, Y.; Guo, T.; Xu, C.; Deng, Y.; Liu, Z.; Ma, S.; Xu, C.; Xu, C.; Gao, W. Pre-Trained Image Processing Transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 12299–12310. [Google Scholar]
- Bao, H.; Dong, L.; Wei, F. Beit: Bert Pre-Training of Image Transformers. arXiv 2021, arXiv:2106.08254. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Yang, J.; Liu, J.; Xu, N.; Huang, J. TVT: Transferable Vision Transformer for Unsupervised Domain Adaptation. arXiv 2021, arXiv:2108.05988. [Google Scholar]
- Xu, T.; Chen, W.; Wang, P.; Wang, F.; Li, H.; Jin, R. Cdtrans: Cross-Domain Transformer for Unsupervised Domain Adaptation. arXiv 2021, arXiv:2109.06165. [Google Scholar]
- Ghifary, M.; Kleijn, W.B.; Zhang, M. Domain Adaptive Neural Networks for Object Recognition. In Proceedings of the Pacific Rim International Conference on Artificial Intelligence, Gold Coast, QLD, Australia, 1–5 December 2014; Springer: New York, NY, USA, 2014; pp. 898–904. [Google Scholar]
- Tzeng, E.; Hoffman, J.; Zhang, N.; Saenko, K.; Darrell, T. Deep Domain Confusion: Maximizing for Domain Invariance. arXiv 2014, arXiv:1412.3474. [Google Scholar]
- Tzeng, E.; Hoffman, J.; Darrell, T.; Saenko, K. Simultaneous Deep Transfer Across Domains and Tasks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 4068–4076. [Google Scholar]
- Long, M.; Cao, Y.; Wang, J.; Jordan, M. Learning Transferable Features with Deep Adaptation Networks. In Proceedings of the PMLR: International Conference on Machine Learning, Lille, France, 1–9 July 2015; pp. 97–105. [Google Scholar]
- Zhu, Y.; Zhuang, F.; Wang, J.; Ke, G.; Chen, J.; Bian, J.; Xiong, H.; He, Q. Deep Subdomain Adaptation Network for Image Classification. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 1713–1722. [Google Scholar] [CrossRef]
- Long, M.; Zhu, H.; Wang, J.; Jordan, M.I. Deep Transfer Learning with Joint Adaptation Networks. In Proceedings of the International Conference on Machine Learning. PMLR, Sydney, Australia, 6–11 August 2017; pp. 2208–2217. [Google Scholar]
- Wang, J.; Chen, Y.; Feng, W.; Yu, H.; Huang, M.; Yang, Q. Transfer Learning with Dynamic Distribution Adaptation. ACM Trans. Intell. Syst. Technol. (TIST) 2020, 11, 1–25. [Google Scholar] [CrossRef] [Green Version]
- Zellinger, W.; Grubinger, T.; Lughofer, E.; Natschläger, T.; Saminger-Platz, S. Central Moment Discrepancy (CMD) for Domain-Invariant Representation Learning. arXiv 2017, arXiv:1702.08811. [Google Scholar]
- Zhu, Y.; Zhuang, F.; Wang, J.; Chen, J.; Shi, Z.; Wu, W.; He, Q. Multi-Representation Adaptation Network for Cross-Domain Image Classification. Neural Netw. 2019, 119, 214–221. [Google Scholar] [CrossRef]
- Sun, B.; Saenko, K. Deep CORAL: Correlation Alignment for Deep Domain Adaptation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–10 October 2016; Springer: New York, NY, USA, 2016; pp. 443–450. [Google Scholar]
- Li, Y.; Wang, N.; Shi, J.; Hou, X.; Liu, J. Adaptive Batch Normalization for Practical Domain Adaptation. Pattern Recognit. 2018, 80, 109–117. [Google Scholar] [CrossRef]
- Shen, J.; Qu, Y.; Zhang, W.; Yu, Y. Wasserstein Distance Guided Representation Learning for Domain Adaptation. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Xu, R.; Liu, P.; Wang, L.; Chen, C.; Wang, J. Reliable Weighted Optimal Transport for Unsupervised Domain Adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 14–19 June 2020; pp. 4394–4403. [Google Scholar]
- Damodaran, B.B.; Kellenberger, B.; Flamary, R.; Tuia, D.; Courty, N. Deepjdot: Deep Joint Distribution Optimal Transport for Unsupervised Domain Adaptation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 447–463. [Google Scholar]
- Nam, H.; Lee, H.; Park, J.; Yoon, W.; Yoo, D. Reducing Domain Gap by Reducing Style Bias. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 8690–8699. [Google Scholar]
- Yoon, J.; Kang, D.; Cho, M. Semi-Supervised Domain Adaptation via Sample-to-Sample Self-Distillation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 4–8 January 2022; pp. 1978–1987. [Google Scholar]
- Yu, C.; Wang, J.; Liu, C.; Qin, T.; Xu, R.; Feng, W.; Chen, Y.; Liu, T.Y. Learning to Match Distributions for Domain Adaptation. arXiv 2020, arXiv:2007.10791. [Google Scholar]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain-Adversarial Training of Neural Networks. J. Mach. Learn. Res. 2016, 17, 1–35. [Google Scholar]
- Long, M.; Cao, Z.; Wang, J.; Jordan, M.I. Conditional Adversarial Domain Adaptation. Adv. Neural Inf. Process. Syst. 2018, 31. [Google Scholar] [CrossRef]
- Pei, Z.; Cao, Z.; Long, M.; Wang, J. Multi-Adversarial Domain Adaptation. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Yu, C.; Wang, J.; Chen, Y.; Huang, M. Transfer Learning with Dynamic Adversarial Adaptation Network. In Proceedings of the 2019 IEEE International Conference on Data Mining (ICDM), Beijing, China, 08–11 November 2019; pp. 778–786. [Google Scholar]
- Xu, M.; Zhang, J.; Ni, B.; Li, T.; Wang, C.; Tian, Q.; Zhang, W. Adversarial Domain Ddaptation with Domain Mixup. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 6502–6509. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Saito, K.; Watanabe, K.; Ushiku, Y.; Harada, T. Maximum Classifier Discrepancy for Unsupervised Domain Adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3723–3732. [Google Scholar]
- Volpi, R.; Morerio, P.; Savarese, S.; Murino, V. Adversarial Feature Augmentation for Unsupervised Domain Adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5495–5504. [Google Scholar]
- Tzeng, E.; Hoffman, J.; Saenko, K.; Darrell, T. Adversarial Discriminative Domain Adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Venice, Italy, 22–29 October 2017; pp. 7167–7176. [Google Scholar]
- Shrivastava, A.; Pfister, T.; Tuzel, O.; Susskind, J.; Wang, W.; Webb, R. Learning from Simulated and Unsupervised Images through Adversarial Training. In Proceedings of the IEEE Conference on Computer Cision and Pattern Recognition, Venice, Italy, 22–29 October 2017; pp. 2107–2116. [Google Scholar]
- Hoffman, J.; Tzeng, E.; Park, T.; Zhu, J.Y.; Isola, P.; Saenko, K.; Efros, A.; Darrell, T. CyCADA: Cycle-Consistent Adversarial Domain Adaptation. In Proceedings of the PMLR: International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 1989–1998. [Google Scholar]
- Kurmi, V.K.; Subramanian, V.K.; Namboodiri, V.P. Exploring Dropout Discriminator for Domain Adaptation. Neurocomputing 2021, 457, 168–181. [Google Scholar] [CrossRef]
- Chen, Y.; Li, W.; Sakaridis, C.; Dai, D.; Van Gool, L. Domain Adaptive Faster R-CNN for Object Detection in the Wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3339–3348. [Google Scholar]
- He, Z.; Zhang, L. Multi-Adversarial Faster-RCNN for Unrestricted Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6668–6677. [Google Scholar]
- Xu, C.D.; Zhao, X.R.; Jin, X.; Wei, X.S. Exploring Categorical Regularization for Domain Adaptive Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 14–19 June 2020; pp. 11724–11733. [Google Scholar]
- Isobe, T.; Jia, X.; Chen, S.; He, J.; Shi, Y.; Liu, J.; Lu, H.; Wang, S. Multi-Target Domain Adaptation with Collaborative Consistency Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 8187–8196. [Google Scholar]
- He, J.; Jia, X.; Chen, S.; Liu, J. Multi-Source Domain Adaptation with Collaborative Learning for Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 11008–11017. [Google Scholar]
- Davis, J.; Domingos, P. Deep Transfer via Second-Order Markov Logic. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; pp. 217–224. [Google Scholar]
- Van Haaren, J.; Kolobov, A.; Davis, J. TODTLER: Two-Order-Deep Transfer Learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; Volume 29. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. Adv. Neural Inf. Process. Syst. 2014, 27, 3104–3112. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seoul, Korea, 27 October–2 November 2019; pp. 3146–3154. [Google Scholar]
- Das, T.; Bruintjes, R.J.; Lengyel, A.; van Gemert, J.; Beery, S. Domain Adaptation for Rare Classes Augmented with Synthetic Samples. arXiv 2021, arXiv:2110.12216. [Google Scholar]
- Xu, Z.; Lee, G.H.; Wang, Y.; Wang, H. Graph-Relational Domain Adaptation. arXiv 2022, arXiv:2202.03628. [Google Scholar]
- Li, X.; Dai, Y.; Ge, Y.; Liu, J.; Shan, Y.; Duan, L.Y. Uncertainty Modeling for Out-of-Distribution Generalization. arXiv 2022, arXiv:2202.03958. [Google Scholar]
- Ghifary, M.; Kleijn, W.B.; Zhang, M.; Balduzzi, D. Domain Generalization for Object Recognition with Multi-Task Autoencoders. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 2551–2559. [Google Scholar]
- Zhu, Y.; Zhuang, F.; Wang, D. Aligning Domain-Specific Distribution and Classifier for Cross-domain Classification from Multiple Dources. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 5989–5996. [Google Scholar]
- Chopra, S.; Hadsell, R.; LeCun, Y. Learning a Similarity Metric Discriminatively, with Application to Face Verification. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 539–546. [Google Scholar]
- Borgwardt, K.M.; Gretton, A.; Rasch, M.J.; Kriegel, H.P.; Schölkopf, B.; Smola, A.J. Integrating Structured Biological Data by Kernel Maximum Mean Discrepancy. Bioinformatics 2006, 22, e49–e57. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dumoulin, V.; Belghazi, I.; Poole, B.; Mastropietro, O.; Lamb, A.; Arjovsky, M.; Courville, A. Adversarially Learned Inference. arXiv 2016, arXiv:1606.00704. [Google Scholar]
- Ma, X.; Zhang, T.; Xu, C. GCAN: Graph Convolutional Adversarial Network for Unsupervised Domain Adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seoul, Korea, 27 October–2 November 2019; pp. 8266–8276. [Google Scholar]
- Kang, G.; Jiang, L.; Yang, Y.; Hauptmann, A.G. Contrastive Adaptation Network for Unsupervised Domain Adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seoul, Korea, 27 October–2 November 2019; pp. 4893–4902. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 580–587. [Google Scholar]
- Yang, G.; Xia, H.; Ding, M.; Ding, Z. Bi-Directional Generation for Unsupervised Domain Adaptation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 6615–6622. [Google Scholar]
- Robbiano, L.; Rahman, M.R.U.; Galasso, F.; Caputo, B.; Carlucci, F.M. Adversarial Branch Architecture Search for Unsupervised Domain Adaptation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, New Orleans, LA, USA, 21–24 June 2022; pp. 2918–2928. [Google Scholar]
- Wang, D.; Shelhamer, E.; Liu, S.; Olshausen, B.; Darrell, T. Tent: Fully Test-Time Adaptation by Entropy Minimization. arXiv 2020, arXiv:2006.10726. [Google Scholar]
- Mitsuzumi, Y.; Irie, G.; Ikami, D.; Shibata, T. Generalized Domain Adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 1084–1093. [Google Scholar]
- Sun, H.; Lin, L.; Liu, N.; Zhou, H. Robust Ensembling Network for Unsupervised Domain Adaptation. In Proceedings of the Pacific Rim International Conference on Artificial Intelligence, Hanoi, Vietnam, 8–12 November 2021; Springer: New York, NY, USA, 2021; pp. 530–543. [Google Scholar]
- Panareda Busto, P.; Gall, J. Open Set Domain Adaptation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 754–763. [Google Scholar]
- Zhang, B.; Chen, C.; Wang, L. Privacy-preserving Transfer Learning via Secure Maximum Mean Discrepancy. arXiv 2020, arXiv:2009.11680. [Google Scholar]
- Zhang, L.; Lei, X.; Shi, Y.; Huang, H.; Chen, C. Federated Learning with Domain Generalization. arXiv 2021, arXiv:2111.10487. [Google Scholar]
- Zhang, Z.; Li, Y.; Wang, J.; Liu, B.; Li, D.; Guo, Y.; Chen, X.; Liu, Y. ReMoS: Reducing Defect Inheritance in Transfer Learning via Relevant Model Slicing. In Proceedings of the 2022 IEEE/ACM 44th International Conference on Software Engineering (ICSE), Pittsburgh, PA, USA, 21–29 May 2022; pp. 1856–1868. [Google Scholar]
- Huang, S.; Yang, W.; Wang, L.; Zhou, L.; Yang, M. Few-shot Unsupervised Domain Adaptation with Image-to-class Sparse Similarity Encoding. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual, 20–24 October 2021; pp. 677–685. [Google Scholar]
- Cheng, Y.C.; Lin, C.S.; Yang, F.E.; Wang, Y.C.F. Few-Shot Classification in Unseen Domains by Episodic Meta-Learning Across Visual Domains. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 434–438. [Google Scholar]
- Zhuang, J.; Chen, Z.; Wei, P.; Li, G.; Lin, L. Open Set Domain Adaptation by Novel Class Discovery. arXiv 2022, arXiv:2203.03329. [Google Scholar]
- Yao, X.; Huang, T.; Wu, C.; Zhang, R.X.; Sun, L. Adversarial Feature Alignment: Avoid Catastrophic Forgetting in Incremental Task Lifelong Learning. Neural Comput. 2019, 31, 2266–2291. [Google Scholar] [CrossRef] [Green Version]
- Van Driessel, G.; Francois-Lavet, V. Component Transfer Learning for Deep RL Based on Abstract Representations. arXiv 2021, arXiv:2111.11525. [Google Scholar]
- Castagna, A.; Dusparic, I. Multi-Agent Transfer Learning in Reinforcement Learning-Based Ride-Sharing Systems. arXiv 2021, arXiv:2112.00424. [Google Scholar]
- Menapace, W.; Lathuilière, S.; Ricci, E. Learning to Cluster Under Domain Shift. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: New York, NY, USA, 2020; pp. 736–752. [Google Scholar]
- Tian, L.; Tang, Y.; Hu, L.; Ren, Z.; Zhang, W. Domain Adaptation by Class Centroid Matching and Local Manifold Self-Learning. IEEE Trans. Image Process. 2020, 29, 9703–9718. [Google Scholar] [CrossRef] [PubMed]
- Deng, W.; Liao, Q.; Zhao, L.; Guo, D.; Kuang, G.; Hu, D.; Liu, L. Joint Clustering and Discriminative Feature Alignment for Unsupervised Domain Adaptation. IEEE Trans. Image Process. 2021, 30, 7842–7855. [Google Scholar] [CrossRef] [PubMed]
- Luo, Y.W.; Ren, C.X. Conditional Bures Metric for Domain Adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 13989–13998. [Google Scholar]
- Huang, Z.; Sheng, K.; Dong, W.; Mei, X.; Ma, C.; Huang, F.; Zhou, D.; Xu, C. Effective Label Propagation for Discriminative Semi-Supervised Domain Adaptation. arXiv 2020, arXiv:2012.02621. [Google Scholar]
- Sun, X.; Buettner, F. Hierarchical Domain Invariant Variational Auto-Encoding with Weak Domain Supervision. arXiv 2021, arXiv:2101.09436. [Google Scholar]
- Sharma, A.; Kalluri, T.; Chandraker, M. Instance Level Affinity-Based Transfer for Unsupervised Domain Adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 5361–5371. [Google Scholar]
- Wu, X.; Zhang, S.; Zhou, Q.; Yang, Z.; Zhao, C.; Latecki, L.J. Entropy Minimization Versus Diversity Maximization for Domain Adaptation. IEEE Trans. Neural Netw. Learn. Syst. 2021, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Qi, L.; Shi, Y.; Gao, Y. More is Better: A Novel Multi-view Framework for Domain Generalization. arXiv 2021, arXiv:2112.12329. [Google Scholar]
- Deng, Z.; Zhou, K.; Yang, Y.; Xiang, T. Domain Attention Consistency for Multi-Source Domain Adaptation. arXiv 2021, arXiv:2111.03911. [Google Scholar]













| DTL Approaches | Subcategories | Brief Description |
|---|---|---|
| Model-Based DTL | Fine-Tuning [43,45,46,47,48,49,50] Self-Training [51,52,53] Transformer Mechanism [54,55,56,57,58] | Share and fine-tune the parameters of deep learning models |
| Discrepancy-Based DTL | Dual-Stream Architecture [59,60,61,62,63,64,65,66,67,68,69,70,71,72] Operate on Image Features [73,74,75] | Reduce feature discrepancies between source and target domains by DNN |
| GAN-Based DTL | Feature Extraction [76,77,78,79,80,81] Feature Transformation [82,83,84,85,86,87,88,89,90] | Extract domain invariant features by generative adversarial networks |
| Relational-Based DTL | Cross-Domain Relationship [91,92] Logical Networks [93,94] | Construct relationship using cross-domain relationship or logical networks |
| Model-Based DTL Approaches | Representatives | Brief Description |
|---|---|---|
| Fine-Tuning | Yosinski et al. [45], DLID [43], Rozantsev et al. [47] | Reuse the different layer parameters of DNN trained in source domains |
| Self-Training | He et al. [51], Xie et al. [52], Zoph et al. [53] | Enhance model performance by using predicted pseudo-labels and noise |
| Transformer Mechanism | BEiT [55], TVT [57], Xu et al. [58] | Share and fine-tune parameters of transformer in target domains |
| Discrepancy-Based DTL Approaches | Representatives | Brief Description |
|---|---|---|
| Dual-Stream Architecture | DDC [60], DAN [62], JAN [64] | Reduce domain differences by introducing adaptation layers in DNN |
| Operate Directly on Image Features | SagNets [73], Yoon et al. [74], Yu et al. [75] | Operate directly on features extracted by DNN to align differences |
| Other Approaches | Das et al. [99], Li et al. [101], Zhu et al. [103] | Optimize the network architecture and improve the feature alignment |
| GAN-Based DTL Approaches | Representatives | Brief Description |
|---|---|---|
| Feature Extraction Approach | DANN [76], DAAN [79], Long et al. [77] | Extract invariant features from the source and target domains in adversarial training |
| Feature Transformation Approach | ADDA [84], SimGAN [85], Zhu et al. [81] | Transform the features for reducing the domain bias by adversarial training |
| Other Approaches | ALI [106], Ma et al. [107], Kang et al. [108] | — |
| TL Approaches | Objective |
|---|---|
| Federated TL [116,117] | Protect the privacy of tasks data when multiple tasks are working together |
| Safe TL [118] | Reduce the aggressiveness inherited from the pre-trained model |
| Few-Shot TL [119,120] | Enhance the association of few labeled samples with unlabeled samples |
| Open Set TL [121] | Solve the problem of inconsistent source and target domain categories |
| Lifelong TL [122] | Use TL techniques to improve the effectiveness of lifelong learning Adaptively |
| Reinforcement TL [123,124] | Reduce the interference of environmental changes on reinforcement learning |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, F.; Xiu, X.; Li, Y. A Survey on Deep Transfer Learning and Beyond. Mathematics 2022, 10, 3619. https://doi.org/10.3390/math10193619
Yu F, Xiu X, Li Y. A Survey on Deep Transfer Learning and Beyond. Mathematics. 2022; 10(19):3619. https://doi.org/10.3390/math10193619
Chicago/Turabian StyleYu, Fuchao, Xianchao Xiu, and Yunhui Li. 2022. "A Survey on Deep Transfer Learning and Beyond" Mathematics 10, no. 19: 3619. https://doi.org/10.3390/math10193619