
The ASR Post-Processor Performance Challenges of BackTranScription (BTS): Data-Centric and Model-Centric Approaches

Abstract
:1. Introduction
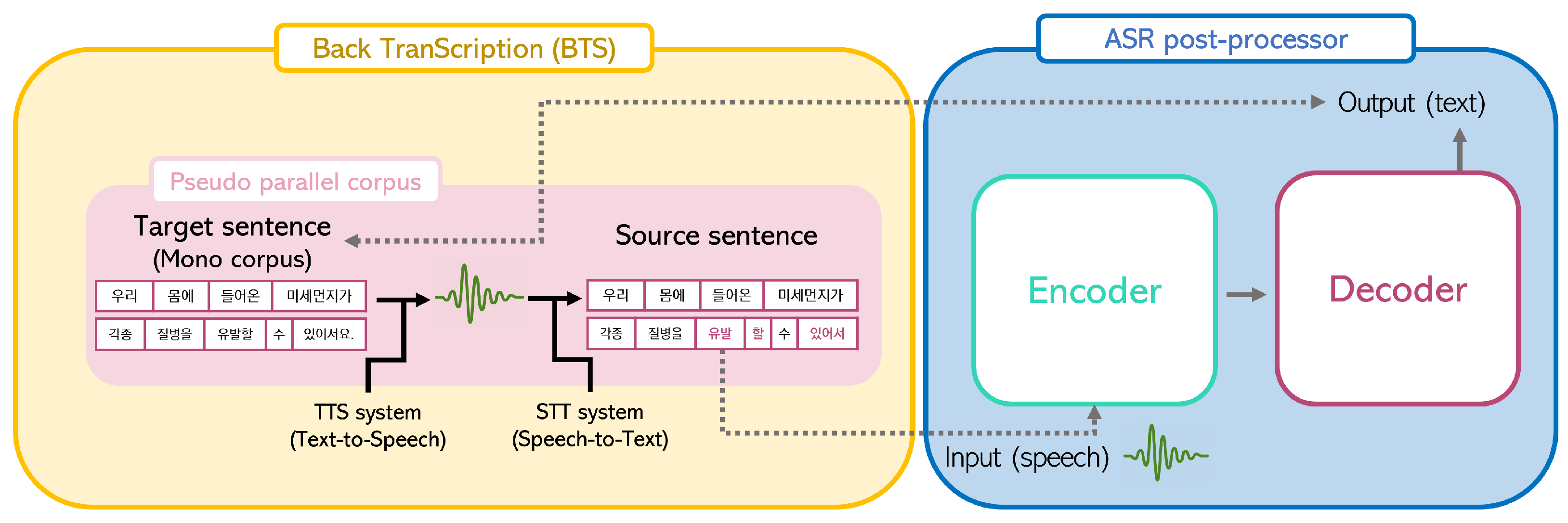
2. What is BTS?
3. Experimental Setup
3.1. Model-Centric Approach
Copy Mechanism for BTS
3.2. Data-Centric Approach
4. Experimental Results
4.1. Main Results: Data-Centric or Model-Centric?
4.2. Insights from the Negative Results of the Model-Centric Approach
4.3. Additional Analysis
4.4. Qualitative Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Stuttle, M.N. A Gaussian Mixture Model Spectral Representation for Speech Recognition. Ph.D. Thesis, University of Cambridge, Cambridge, UK, 2003. [Google Scholar]
- Gales, M.; Young, S. The application of hidden Markov models in speech recognition. Found. Trends Signal Process. 2008, 1, 195–304. [Google Scholar] [CrossRef]
- Baevski, A.; Zhou, H.; Mohamed, A.; Auli, M. wav2vec 2.0: A framework for self-supervised learning of speech representations. arXiv 2020, arXiv:2006.11477. [Google Scholar]
- Hjortnæs, N.; Partanen, N.; Rießler, M.; Tyers, F.M. The Relevance of the Source Language in Transfer Learning for ASR. In Proceedings of the Workshop on Computational Methods for Endangered Languages, Online, 2–3 March 2021; Volume 1, pp. 63–69. [Google Scholar]
- Zhang, Z.Q.; Song, Y.; Wu, M.H.; Fang, X.; Dai, L.R. XLST: Cross-lingual Self-training to Learn Multilingual Representation for Low Resource Speech Recognition. arXiv 2021, arXiv:2103.08207. [Google Scholar]
- Ha, J.W.; Nam, K.; Kang, J.G.; Lee, S.W.; Yang, S.; Jung, H.; Kim, E.; Kim, H.; Kim, S.; Kim, H.A.; et al. ClovaCall: Korean goal-oriented dialog speech corpus for automatic speech recognition of contact centers. arXiv 2020, arXiv:2004.09367. [Google Scholar]
- Voll, K.; Atkins, S.; Forster, B. Improving the utility of speech recognition through error detection. J. Digit. Imaging 2008, 21, 371. [Google Scholar] [CrossRef] [Green Version]
- Liao, J.; Eskimez, S.E.; Lu, L.; Shi, Y.; Gong, M.; Shou, L.; Qu, H.; Zeng, M. Improving readability for automatic speech recognition transcription. arXiv 2020, arXiv:2004.04438. [Google Scholar] [CrossRef]
- Park, C.; Eo, S.; Moon, H.; Lim, H.S. Should we find another model?: Improving Neural Machine Translation Performance with ONE-Piece Tokenization Method without Model Modification. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies: Industry Papers, Virtual Event, 6–11 June 2021; pp. 97–104. [Google Scholar]
- Wu, X.; Xiao, L.; Sun, Y.; Zhang, J.; Ma, T.; He, L. A survey of human-in-the-loop for machine learning. Future Gener. Comput. Syst. 2022, 135, 364–381. [Google Scholar] [CrossRef]
- Roh, Y.; Heo, G.; Whang, S.E. A survey on data collection for machine learning: A big data-ai integration perspective. IEEE Trans. Knowl. Data Eng. 2019, 33, 1328–1347. [Google Scholar] [CrossRef] [Green Version]
- Klein, G.; Zhang, D.; Chouteau, C.; Crego, J.M.; Senellart, J. Efficient and High-Quality Neural Machine Translation with OpenNMT. In Proceedings of the Fourth Workshop on Neural Generation and Translation, Virtual Event, 10 July 2020; pp. 211–217. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Park, C.; Seo, J.; Lee, S.; Lee, C.; Moon, H.; Eo, S.; Lim, H. BTS: Back Transcription for Speech-to-Text Post-Processor using Text-to-Speech-to-Text. In Proceedings of the 8th Workshop on Asian Translation (WAT2021), Bangkok, Thailand, 5–6 August 2021; pp. 106–116. [Google Scholar]
- Koehn, P.; Chaudhary, V.; El-Kishky, A.; Goyal, N.; Chen, P.J.; Guzmán, F. Findings of the WMT 2020 shared task on parallel corpus filtering and alignment. In Proceedings of the Fifth Conference on Machine Translation, Virtual Event, 19–20 November 2020; pp. 726–742. [Google Scholar]
- Gu, J.; Lu, Z.; Li, H.; Li, V.O. Incorporating copying mechanism in sequence-to-sequence learning. arXiv 2016, arXiv:1603.06393. [Google Scholar]
- Luong, M.T.; Pham, H.; Manning, C.D. Effective approaches to attention-based neural machine translation. arXiv 2015, arXiv:1508.04025. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Kudo, T.; Richardson, J. Sentencepiece: A simple and language independent subword tokenizer and detokenizer for neural text processing. arXiv 2018, arXiv:1808.06226. [Google Scholar]
- Polyzotis, N.; Zaharia, M. What can Data-Centric AI Learn from Data and ML Engineering? arXiv 2021, arXiv:2112.06439. [Google Scholar]
- Pan, I.; Mason, L.R.; Matar, O.K. Data-centric Engineering: Integrating simulation, machine learning and statistics. Challenges and opportunities. Chem. Eng. Sci. 2022, 249, 117271. [Google Scholar] [CrossRef]
- Park, C.; Lim, H. A Study on the Performance Improvement of Machine Translation Using Public Korean-English Parallel Corpus. J. Digit. Converg. 2020, 18, 271–277. [Google Scholar]
- Park, C.; Lee, Y.; Lee, C.; Lim, H. Quality, not Quantity? Effect of parallel corpus quantity and quality on Neural Machine Translation. In Proceedings of the 32st Annual Conference on Human & Cognitive Language Technology, Nice, France, 25–29 October 2020; pp. 363–368. [Google Scholar]
- Gale, W.A.; Church, K. A program for aligning sentences in bilingual corpora. Comput. Linguist. 1993, 19, 75–102. [Google Scholar]
- Napoles, C.; Sakaguchi, K.; Post, M.; Tetreault, J. Ground truth for grammatical error correction metrics. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 26–31 July 2015; Volume 2: Short Papers. pp. 588–593. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. BLEU: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting on Association for cComputational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- Choi, J.M.; Kim, J.D.; Park, C.Y.; Kim, Y.S. Automatic Word Spacing of Korean Using Syllable and Morpheme. Appl. Sci. 2021, 11, 626. [Google Scholar] [CrossRef]
- Yi, J.; Tao, J.; Bai, Y.; Tian, Z.; Fan, C. Adversarial transfer learning for punctuation restoration. arXiv 2020, arXiv:2004.00248. [Google Scholar]
- Rajpurkar, P.; Zhang, J.; Lopyrev, K.; Liang, P. SQuAD: 100,000+ Questions for Machine Comprehension of Text. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 2383–2392. [Google Scholar]
- Seo, J.; Lee, S.; Park, C.; Jang, Y.; Moon, H.; Eo, S.; Koo, S.; Lim, H.S. A Dog Is Passing Over The Jet? A Text-Generation Dataset for Korean Commonsense Reasoning and Evaluation. In Proceedings of the Findings of the Association for Computational Linguistics: NAACL 2022, Virtual Event, 10–15 July 2022; pp. 2233–2249. [Google Scholar]
- Kang, M.; Seo, J.; Park, C.; Lim, H. Utilization Strategy of User Engagements in Korean Fake News Detection. IEEE Access 2022, 10, 79516–79525. [Google Scholar] [CrossRef]
- Ranaldi, L.; Fallucchi, F.; Zanzotto, F.M. Dis-Cover AI Minds to Preserve Human Knowledge. Future Internet 2021, 14, 10. [Google Scholar] [CrossRef]


{kind=link}
| Centric | Model | BLEU | GLEU |
|---|---|---|---|
| - | Park et al. [14] | 56.56 | 46.94 |
| Model | Copy-MLP | 48.79 (−7.77) | 39.91 (−7.03) |
| Model | Copy-dot | 48.71 (−7.85) | 40.18 (−6.76) |
| Model | Copy-bilinear | 48.25 (−8.31) | 39.83 (−7.11) |
| Data | No-Filter | 65.29 (+8.73) | 58.52 (+11.58) |
| Data | Filter | 66.43 (+9.87) | 59.20 (+12.26) |
| Model | Type | Spacing | Word Conversion (KO) | Word Conversion (EN) | Punctuation | Overall |
|---|---|---|---|---|---|---|
| Park et al. [14] | Baseline | 91.86 | 54.41 | 23.41 | 61.02 | 70.73 |
| Copy-MLP | Model-Centric | 91.09 (−0.77) | 47.23 (−7.18) | 15.19 (−8.22) | 56.78 (−4.24) | 66.40 (−4.33) |
| Copy-dot | Model-Centric | 91.24 (−0.62) | 47.42 (−6.99) | 15.14 (−8.27) | 58.90 (−2.12) | 66.40 (−4.33) |
| Copy-bilinear | Model-Centric | 91.24 (−0.62) | 47.42 (−6.99) | 15.13 (−8.28) | 58.90 (−2.12) | 66.72 (−4.01) |
| No-Filter | Data-Centric | 94.58 (+2.72) | 65.27 (+10.86) | 44.81 (+21.40) | 74.96 (+13.94) | 78.40 (+7.67) |
| Filter | Data-Centric | 94.59 (+2.73) | 65.41 (+11.00) | 40.36 (+16.95) | 75.25 (+14.23) | 78.41 (+7.68) |
| Input Sentence (Source Text with Errors) | Copy-Bilinear (Model-Centric) | Filter (Data-Centric) | Reference Sentence |
|---|---|---|---|
| 강남역에는 다양한 레스토랑 카페 쇼핑 샵들이 많아 항상 수많은 젊은이들로 붐 빕니다 (Gangnam Station is always crowd ed with many young people because there are many restaurants cafes shopping shops) Spacing & Punctuation Error | 강남역에는, 다양한 레스토랑 카페 쇼핑 샵들이 많아 항상 수많은 젊은이들로 붐_빕니니다. (Gangnam Station is always crowd_ed with many young people because there are many restaurants cafes shopping shops.) | 강남역에는 다양한 레스토랑, 카페, 쇼핑 샵들이 많아 항상 수많은 젊은이들로 붐빕니다. (Gangnam Station is always crowded with many young people because there are many restaurants, cafes, and shopping shops.) | 강남역에는 다양한 레스토랑, 카페, 쇼핑 샵들이 많아 항상 수많은 젊은이들로 붐빕니다.(Gangnam Station is always crowded with many young people because there are many restaurants, cafes, and shopping shops.) |
| 얼마전까진 의사와의 회의 결과 본 계약 예약 시점은 약간 지연 된다고 합니다 (Not too long ago according to a meeting with the doctor the reservation time for this contract will be delayed a little.) Word Conversion (KO) & Punctuation Error | 얼마 전까진 의사와의 회의 결과 본 계약 시점은 약간 지연고 합니다. (Not long ago as a result of the meeting with the doctor the timing of this contract has been dely a little.) | 얼마 전 가진 A사와의 회의 결과, 본 계약 예약 시점은 약간 지연된다고 합니다. (As a result of a recent meeting with A company, the reservation time for this contract is slightly delayed.) | 얼마 전 가진 A사와의 회의 결과, 본계약의 계약 시점은 약간 지연된다고 합니다. (As a result of a recent meeting with A company, the contract timing of this contract is slightly delayed.) |
| 먹방은 먹는 방송이라는 한국 말의 줄임말로 한국방송 개 혜성처럼 등장한 새로운 trend hair (Mukbang is short for eating show in Korean and it’s a new trend hair that has emerged like a Korean broadcasting dog comet.) Word Conversion (EN) & Weird Word Error | 먹방은 먹는 방송이라는 한국 말의 줄임말로 한국방송을 혜성처럼 등장한 새로운 Th-에도요. (Mukbang is short for eating show and it’s a new Th-that appeared like a comet.) | 먹방은 먹는 방송이라는 한국말의 줄임말로 한국 방송계에 혜성처럼 등장한 새로운 트렌드예요. (Mukbang is a new trend that has emerged like a comet in the Korean broadcasting industry, short for eating broadcasting). | 먹방은 먹는 방송이라는 한국말의 줄임말로 한국 방송계에 혜성처럼 등장한 새로운 트렌드예요. (Mukbang is a new trend that has emerged like a comet in the Korean broadcasting industry, short for eating show.) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, C.; Seo, J.; Lee, S.; Lee, C.; Lim, H. The ASR Post-Processor Performance Challenges of BackTranScription (BTS): Data-Centric and Model-Centric Approaches. Mathematics 2022, 10, 3618. https://doi.org/10.3390/math10193618
Park C, Seo J, Lee S, Lee C, Lim H. The ASR Post-Processor Performance Challenges of BackTranScription (BTS): Data-Centric and Model-Centric Approaches. Mathematics. 2022; 10(19):3618. https://doi.org/10.3390/math10193618
Chicago/Turabian StylePark, Chanjun, Jaehyung Seo, Seolhwa Lee, Chanhee Lee, and Heuiseok Lim. 2022. "The ASR Post-Processor Performance Challenges of BackTranScription (BTS): Data-Centric and Model-Centric Approaches" Mathematics 10, no. 19: 3618. https://doi.org/10.3390/math10193618